【题目】MySQL选择题
来源:MySQL专项练习选择题
1.有一个User用户表,要删除整张表(指完全删除表数据和结构),下面正确的MySQL语句是:
A.DELETE TABLE User;
B.DROP TABLE User;
C.TRUNCATE TABLE User;
D.DELETE FROM User ;
解析:选B。A选项错在DELETE后面应该是接FROM+表格名,而不是TABLE...;
B选项是完全删除表数据和表结构。
C和D选项仅可以删除表里的数据,但是无法删除表结构。
2.下列操作在视图上无法完成的是?
A.视图数据查询
B.更新视图数据
C.在视图中定义新的基本表
D.在视图中定义新视图
解析:选C。在视图中也可以定义新的视图,却无法创建表,因为视图是个虚表,视图在数据库中没有原本的物理存储,只是相当于临时表。
3.下面哪些字符最可能会导致sql注入?
A.'(单引号)
B./
C."(双引号)
D.$
解析:选A。单引号作为MySQL中的字段值封装方式,最容易被用作注入攻击。SQL注入的关键是单引号的闭合,双引号里不能再放双引号,但单引号里可以放双引号。
4.学生、书店和图书三个实体集之间的联系属于()
A.二元联系
B.多元联系
C.自反联系
D.一对一联系
解析:选B。参与联系的实体集个数大于2个时,为多元联系;A选项,二元联系指只有两个实体集参与的联系;C选项,自反联系描述了同一实体集内两部分实体之间的联系,是一种特殊的二元联系;D选项,是二元联系下的一种细分。
5.假设有一份绝密文件存于某台机器的secretData数据库中的某个表里面,现在出于数据安全的考虑,对于新创建的用户都只能拥有该机器的登录权限,而不能拥有数据库的其他权限,那么新创建tqhf用户满足这一要求的语句是()
A.grant usage on *.* with 'tqhf'@'%';
B.grant usage on secretData.* to 'tqhf'@'%';
C.grant usage on secretData.* with 'tqhf'@'%';
D.grant usage on *.* to 'tqhf'@'%';
解析:选D。数据库赋予登录权限的语句是grant usage on ... to。因此答案A、C都不正确。题目中只说secretData数据库中的某个表有绝密文件,但是对新创建的用户可拥有登录权限,而没有其他权限。并没有说只对secretData数据库,因此题目引入该数据库只是一个干扰信息,所以答案B错误。
6.在STUDENT表中按class_type统计数据行数分组情况后,筛选出数据行数为大于10行的组
A.SELECT class_type,COUNT(*) FROM STUDENT GROUP BY class_type HAVING COUNT(*)>10
B.SELECT class_type,COUNT(*) FROM STUDENT GROUP BY class_type WHERE COUNT(*)=10
C.SELECT class_type,COUNT(*) FROM STUDENT HAVING COUNT(*)>10 GROUP BY class_type
D.SELECT class_type,COUNT(*) FROM STUDENT WHERE COUNT(*) >10 GROUP BY class_type
解析:选A。由题意得,若要筛选出数据行数大于10的,第一时间肯定会想到WHERE子句,但是由于使用GROUP BY后COUNT应该写在HAVING后,因此选A,BCD均属于用法错误,故排除。WHERE不能接聚合函数(MAX、MIN、COUNT、SUM、AVG等)。HAVING后可以接聚合函数。WHERE用在GROUP BY前,先过滤后分组;HAVING用在GROUP BY之后,先分组后过滤。且使用HAVING一定要用到GRUOP BY,但用到GROUP BY不一定有HAVING。顺序:FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY。
7.决定不再使用一张备份数据表waterinfo001表,需永久删除。选出符合要求的语句。
A.DELETE TABLE waterinfo001
B.DELETE FROM TABLE waterinfo001
C.DROP TABLE waterinfo001
D.DROP FROM TABLE waterinfo001
解析:选C。
1. drop是完全删除表,包括表结构
2. delete是删除表数据,保留表的结构,而且可以加where,只删除一行或者多行
3. truncate 只能删除表数据,会保留表结构,而且不能加where
8.在创建完一张数据表后,发现少创建了一列,此时需要修改表结构,应该用哪个语句进行操作?
A.MODIFY TABLE
B.INSERT TABLE
C.ALTER TABLE
D.UPDATE TABLE
解析:选C。由题意得,通过ALTER TABLE进行表结构修改;INSERT是插入语句;MODIFY只是ALTER功能下的一个功能模块,只能修改字段属性;UPDATE是更新语句故不符合题意
9.现在有一个学生表student,需要回收所有机器的tqhf用户对学生表student所在数据库user的update和insert权限,则下列语句中能够实现这一功能的语句是()
A.revoke update,insert on user.* to 'tqhf'@'%';
B.revoke update,insert on *.* to 'tqhf'@'%';
C.revoke update,insert on user.* from 'tqhf'@'%';
D.revoke update,insert on *.* from 'tqhf'@'%';
解析:选C。回收表的操作功能语句revoke ... on ... from。因此答案A、B不正确。由于题目要求是回收所有机器的tqhf用户对user表的update和insert权限,而答案D是回收所有数据库的update和insert权限,因此答案D不正确。@'%' 是表示任何主机的通配符,@:划分用户名和主机,%:代表"任何"。
10.在MySql中进行数据查询时,如果要对查询结果的列名重新命名,将sno列重新命名为学号,则下列语句正确的是( )
A.select sno as 学号 from T
B.select 学号= sno from T
C.select sno 学号 from T
D.select sno=学号 from T
解析:选AC。as可以做重命名,不过也可以省略as,空格隔开新名称即可。
11.快件信息表waybillinfo(id, waybillno, zonecode, optype, update_time)中存储了快件的所有操作信息,请找出在'中山公园'网点,异常派送(optype='异常派件')次数超过3次的快件(waybillno),正确的sql为()
A.select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
and count(waybillno) >3
B.select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
order by waybillno having count(*) > 3
C.select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
having count(*) > 3
D.select waybillno from waybillinfo where zonecode='中山公园' and optype='异常派件'
group by waybillno having count(*) > 3
解析:选D。
1.having只用来在group by之后,对group by的结果进行筛选,不能单独用
2.分组结果统计需要用group by,每个快件整体作为一组3.where之后不能以函数作为条件
12.请取出 BORROW表中日期(RDATE字段)为当天的所有记录?(RDATE字段为datetime型,包含日期与时间)。SQL语句实现正确的是:()
A.select * from BORROW where datediff(dd,RDATE,getdate())=0
B.select * from BORROW where RDATE=getdate()
C.select * from BORROW where RDATE-getdate()=0
D.select * from BORROW where RDATE > getdate()
解析:选A。DATEDIFF(datepart, startdate, enddate) 函数返回两个日期之间的时间。
题目说RDDATE包括日期和时间,而只需要比较日期,因此需要用datediff检查日期(dd)差,为0 则为当天。
MySQL语法:DATEDIFF(date1,date2),返回两个日期之间的天数
结果:select * from BORROW where datediff(RDATE,curdate())=0;
第一个参数是起始时间,第二个参数是结束时间
13.子查询中,父查询中一般使用IN运算符的是()
A.单列单值嵌套查询
B.单列多值嵌套查询
C.多列多值嵌套查询
D.集合查询
解析:选B。A选项,结果集为一个值,一般使用=、<、>等运算符;C选项,结果类似于一张虚拟表,父查询中只能使用EXISTS或NOT EXISTS;D选项,通常是利用UNION、EXCEPT、INTERSECT集合运算符实现两个表之间的数据查询。IN子查询:内层查询语句仅返回一个数据列,这个数据列的值将供外层查询语句进行比较。子查询:单列多行。
14.已知员工表如下图所示,员工编号依次递增,现需改变相邻员工的编号,当员工总人数为奇数是,不需要改变最后一个员工的编号。下列SQL语句不正确的是()
表employee:
+-----+-----------+
| eno | ename |
+-----+-----------+
| 1 | 小李 |
| 2 | 小王 |
| 3 | 小刚 |
| 4 | 小虎 |
+----+------------+
A.SELECT
ROW_NUMBER() OVER(ORDER BY(eno+1-2*POWER(0,eno%2))) AS eno,ename
FROM employee
B.SELECT
ROW_NUMBER() OVER(ORDER BY(eno-1+2*MOD(0,eno%2))) AS eno,ename
FROM employee
C.SELECT
IF(eno%2=0,eno-1,
IF(eno=(SELECT COUNT(DISTINCT eno) FROM employee),eno,eno+1))
AS eno,ename
FROM employee
ORDER BY eno
D.SELECT
IF(eno%2=0,eno+1,
IF(eno=(SELECT COUNT(DISTINCT eno) FROM employee),eno,eno-1))
AS eno,ename
FROM employee
ORDER BY eno
解析:选C。D选项,运行后所得结果错误,若eno为偶数,应减1而非加1;若eno为奇数,且不为最后一个,应加1而非减1。改变相邻员工编号:| 1 | 小李 | | 2 | 小王 | | 3 | 小刚 | | 4 | 小虎 |更改后就是 | 2 | 小李 | | 1 | 小王 | | 4 | 小刚 | | 3 | 小虎 |。所以如果原来的eno是偶数,应该减1;(如果原来的eno是奇数,而且不是最后一个员工的话,应该加1;如果原来的eno是奇数而且是最后一个,eno不改变)。
15.表结构如下:
CREATE TABLE `score` (`id` int(11) NOT NULL AUTO_INCREMENT,`sno` int(11) NOT NULL,`cno` tinyint(4) NOT NULL,`score` tinyint(4) DEFAULT NULL,PRIMARY KEY (`id`)) ;以下查询语句结果一定相等的是()
A.SELECT sum(score) / count(*) FROM score WHERE cno = 2;
B.SELECT sum(score) / count(id) FROM score WHERE cno = 2;
C.SELECT sum(score) / count(sno) FROM score WHERE cno = 2;
D.SELECT sum(score) / count(score) FROM score WHERE cno = 2;
E.SELECT sum(score) / count(1) FROM score WHERE cno = 2;
F.SELECT avg(score) FROM score WHERE cno = 2;
解析:DF相等,ABCE相等。
1. count(*)包括所有列,相当于行数。统计结果时不会忽略某些列值为NULL的行。
2. count(1)用1代表代码行,忽略所有列值。统计结果时统计所有行,效果同count(*)。
3. count(列名)只包括列名对应一列,统计结果时会忽略列值为空的行。
本题中只有score列可能为空,其他列均设置了NOT NULL,因此只有count(score)和avg(score)会忽略score为空的列。
16.某打车公司要将驾驶里程(drivedistanced)超过5000里的司机信息转存到一张称为seniordrivers的表中,他们的详细情况被记录在表drivers中,正确的sql语句为()
A.insert into seniordrivers where drivedistanced>=5000 from drivers
B.insert into seniordrivers(drivedistanced) values from drivers where drivedistanced>=5000
C.insert into seniordrivers(drivedistanced) where values>=5000 from drivers
D.select * into seniordrivers from drivers where drivedistanced >=5000
解析:选D。
INSERT INTO语句用于向一张表中插入新的行。
INSERT-SELECT-FROM将表的列插入其他表的列
SELECT-INTO-FROM语句从一张表中选取数据插入到另一张表中。常用于创建表的备份复件或者用于对记录进行存档。
INSERT-SELECT-UNION语句合并数据进行多行插入
17.关于解决事务的脏读的最简单的方法,下列选项正确的是()
A.修改时加排他锁,直到事务提交后释放,读取时加共享锁
B.读取数据时加共享锁,写数据时加排他锁,都是事务提交才释放锁
C.修改时加共享锁,直到事务提交后释放,读取时加排他锁
D.读取数据时加排他锁,写数据时加共享锁,都是事务提交才释放锁
解析:选A。B选项,是对不可重复读或幻读的解决方法;CD选项,各过程添加了错误锁。
18.写一段SQL,已知衬衫表SHIRTABLE,请你实现通过窗口函数实现,根据不同的衬衫种类shirt_type,按照销售单价shirt_price从低到高的顺序创建排序表()
A.SELECT shirt_name, shirt_type, shirt_price,
RANK() OVER (PARTITION BY shirt _type ORDER BY shirt_price) AS ranking
FROM SHIRTABLE
B.SELECT shirt _name, shirt_type, shirt _price,
PARTITION BY shirt _type ORDER BY shirt _price AS ranking
FROM SHIRTABLE
C.SELECT shirt _name, shirt_type, shirt _price,
RANK (PARTITION BY shirt _type ORDER BY shirt _price) AS ranking
FROM SHIRTABLE
D.SELECT shirt _name, shirt_type, shirt _price,
RANK() OVER (PARTITION BY shirt_type) AS ranking
FROM SHIRTABLE
解析:选A。窗口函数over()函数中包括三个函数:分区partition by 列名、排序order by 列名、指定窗口范围rows between开始位置 and 结束位置(可用\可以不用)。rank() 按照值排序时产生一个自增编号,值相等时会重复。dense_rank() 按照值排序时产生一个自增编号,值相等时会重复,不会产生空位。row_number() 按照值排序时产生一个自增编号,不会重复
19.在SQL中语法规范中,having子句的使用下面描述正确的是:()
A.having子句即可包含聚合函数作用的字段也可包括普通的标量字段
B.使用having的同时不能使用where子句
C.having子句必须于group by 子句同时使用,不能单独使用
D.使用having子句的作用是限定分组条件
解析:选AC。Group by才用来分组,作用是限定分组条件。而Having则是对Group by中分出来的组进行条件筛选。
20.“确保事务可以多次从一个字段中读取相同的值,在此事务持续期间,禁止其他事务对此字段的更新”是对下列选项哪一个事务隔离级别的描述()
A.Read uncommitted
B.Read committed
C.Repeatable Read
D.Serializable
解析:选C。A选项,读未提交是事务隔离级别的最低级别;B选项,读已提交,可避免脏读情况发生;D选项,最严格的事务隔离级别,要求所有事物被串行执行,不能并发执行,可避免脏读、不可重复读,幻读情况的发生。
21.Mysql中表student_info(id,name,birth,sex),字段类型都是varchar,插入如下记录:('1014' , '张三' , '2002-01-06' , '男');SQL错误的是()
A.insert into student_info values('1014' , '张三' , '2002-01-06' , '男');
B.insert into table student_info values('1014' , '张三' , '2002-01-06' , '男');
C.insert into student_info(id,name,birth,sex) values('1014' , '张三' , '2002-01-06' , '男');
D.insert into student_info(id,name,sex,birth) values('1014' , '张三' , '男','2002-01-06' );
解析:选B。A插入全部字段时可以省略字段名;B插入时,如果`table`不是表名,不能带table关键字,会报错;如果table就是表名,需要用`table`才行。CD可以指定插入哪些字段,同时字段顺序与字段值顺序一致即可。所以B错误。
多条一次性插入:INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...
22.修改表test_tbl字段i的缺省值为1000,可以使用SQL语句()
A.ALTER TABLE test_tbl ALTER i SET DEFAULT 1000;
B.ALTER TABLE test_tbl i SET DEFAULT 1000;
C.ALTER TABLE test_tbl MODIFY i SET DEFAULT 1000;
D.ALTER TABLE test_tbl CHANGE i SET DEFAULT 1000;
解析:选A。修改表:ALTER TABLE 表名 修改选项。修改选项如下:
{ ADD COLUMN <列名> <类型> -- 增加列
| CHANGE [COLUMN] <旧列名> <新列名> <新列类型> -- 修改列名或类型
| ALTER [COLUMN] <列名> { SET DEFAULT <默认值> | DROP DEFAULT } -- 修改/删除 列的默认值
| MODIFY [COLUMN] <列名> <类型> -- 修改列类型,修改字段类型
| DROP [COLUMN] <列名> -- 删除列
| RENAME TO <新表名> -- 修改表名
| CHARACTER SET <字符集名> -- 修改字符集
| COLLATE <校对规则名> } -- 修改校对规则(比较和排序时用到)
23.下列选项中关于数据库事务的特性描述正确的是()
A.事务允许继续分割
B.多个事务在执行事务前后对同一个数据读取的结果是不同的
C.一个事务对数据库中数据的改变是暂时的
D.并发访问数据库时,各并发事务之间数据库是独立的
解析:选D。此题考查数据库事务的原子性、一致性、隔离性和持久性。A选项,事务是最小的执行单位,不允许分割;B选项,执行事务前后,数据保持一致,对同一数据读取的结果相同;C选项,一个事务被提交后对数据库中数据的改变是持久的。D选项满足隔离性。
24.SQL中,下面对于数据定义语言DDL描述正确的是()
A.DDL关心的是数据库中的数据
B.联盟链
C.控制对数据库的访问
D.定义数据库的结构
解析:选D。(1)数据定义(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。(2)数据操纵(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。(3)数据控制(DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。(4)嵌入式SQL的使用规定(TCL)涉及到SQL语句嵌入在宿主语言程序中使用的规则。
25.下列说法错误的是?
A.模糊查询中,*表示全部信息
B.可以用统计函数avg()计算平均值
C.在使用insert语句插入数据时,表达式的数据类型和表格中对应各列的数据类型不一定需要一致
D.视图是数据库对象,可以使用SELECT等语句
解析:选C。由题意得,在使用insert语句插入数据时,表达式的数据类型和表格中对应各列的数据类型必须一一对应,故C错误。
26.关于返回受上一个SQL语句影响的行数,下列SQL语句正确的是()
A.SELECT @@ERROR
B.SELECT @@IDENTITY
C.SELECT @@ROWCOUNT
D.SELECT @@MAX_CONNECTIONS
解析:A选项,是返回最后一个T_SQL错误的错误号;B选项,返回最后一个插入的标识值;D选项,显示可以创建的同时链接的最大数目。
27.下列函数语句得不到相同数值结果的选项是()
A.SELECT ROUND(2.35)
B.SELECT ROUND(1.96,1)
C.SELECT TRUNCATE(1.99,1)
D.SELECT TRUNCATE(2.83,0)
解析:选C。A选项,对参数四舍五入保留整数,结果为2;选项B对前面参数进行四舍五入操作并保留至小数点后1位,结果为2.0;C选项,对前面参数进行截取操作,截至小数点后一位,结果为1.9;D选项,对前面参数进行截取操作,截至小数点,结果为2;只有C选项的结果数值不为2。
ROUND()函数用于把数值字段舍入为指定的小数位数;
TRUNCATE()函数是按照小数位数进行数值截取,没有四舍五入。
28.运动会比赛信息的数据库,有如下三个表:
运动员ATHLETE(运动员编号 Ano,姓名Aname,性别Asex,所属系名 Adep), 项目 ITEM (项目编号Ino,名称Iname,比赛地点Ilocation), 成绩SCORE (运动员编号Ano,项目编号Ino,积分Score)。写出目前总积分最高的系名及其积分,SQL语句实现正确的是:()
A.SELECT Adep,SUM(Score)FROM ATHLETE,SCORE
WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=ANY
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)
B.SELECT Adep,SUM(Score)FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=SOME
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)
C.SELECT Adep,SUM(Score)FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score) IN
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)
D.SELECT Adep,SUM(Score)FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=ALL
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)
解析:选D。
All():对所有数据都满足条件,整个条件才成立,>=all()等价于max,<=all()等价于min;
Any:只要有一条数据满足条件,整个条件成立,>any()等价于>min,<any()等价于<max;
some的作用和Any一样
29.关于MySQL常见索引的描述正确是()
A.创建UNIQUE索引,索引列的值必须唯一,不允许有空值
B.一个表中可以创建多个全文索引
C.为提高效率可建立组合索引,遵循“最左前缀”原则
D.使用非聚集索引需要将物理数据页中的数据按列重新排序
解析:选C。A选项,唯一索引不允许两行具有相同的索引值,包括NULL值,允许有空值;B选项,每个表只允许有一个全文索引;D选项,非聚集索引具有完全独立于数据行的结构,所以不需要将物理数据页中的数据按列重新排序。
30.下面哪一个是MySQL查询语句的正确执行顺序:
A.SELECT ---> FROM(including JOINs) ---> WHERE ---> GROUP BY ---> HAVING ---> DISTINCT ---> ORDER BY ---> LIMIT/OFFSET
B.SELECT ---> DISTINCT ---> FROM(including JOINs) ---> WHERE ---> GROUP BY ---> HAVING ---> ORDER BY ---> LIMIT/OFFSET
C.FROM(including JOINs) ---> WHERE ---> GROUP BY ---> HAVING ---> SELECT ---> DISTINCT ---> ORDER BY ---> LIMIT/OFFSET
D.FROM(including JOINs) ---> WHERE ---> GROUP BY ---> HAVING ---> DISTINCT ---> SELECT ---> ORDER BY ---> LIMIT/OFFSET
解析:选C。
31.有一张Person表包含如下信息:现要选取居住地址Address不以'C'或'O'开头的人员信息,下列MySQL查询语句正确的是:
A.SELECT * FROM Person Address REGEXP '^[^CO]';
B.SELECT * FROM Person Address LIKE '[!CO]%';
C.SELECT * FROM Person Address LIKE '[^CO]%';
D.SELECT * FROM Person Address REGEXP '^[CO]';
解析:选A。MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
[^charlist] 通配符表示 不在字符列中的任一单一字符。
MySQL中选取不以charlist中任一字符开头的语法为:
SELECT * FROM tab_name WHERE col_name REGEXP '^[charlist]';
同理,不以某、或另一某字符开头的语法为:
SELECT * FROM tab_name WHERE col_name REGEXP '^[^charlist]';
SELECT * FROM tab_name WHERE col_name NOT REGEXP '^[charlist]';
所以本题选不以'C'或'O'开头的人员信息,只有A选项是正确的;
B和C错在LIKE的误用;
D错在该语句表示的是选取以'C'或'O‘开头的人员信息,刚好和题意相反!
正则表达式 选项 说明 例子 示例 ^ 匹配文本的开始字符 '^b' 匹配以字母 b 开头 的字符串 bike [^] 匹配不在括号中的任何字符 '[^abc]’ 匹配任何不包 含 a、b 或 c 的字符串 egg
32. 声明游标语法中的INSENSITIVE参数,表示声明一个静态游标。当发生下列选项中的哪一项时,游标将会自动设定INSENSITIVE选项()
A.在SELECT语句中使用WHERE语句
B.使用INNER JOIN
C.所选取的任意表存在索引
D.将实数值当作选取的列
解析:选D。A选项,当SELECT语句中使用DISTINCT、GROUP BY、HAVING UNION语句时游标将会自动设定INSENSITIVE选项;B选项,应为使用OUTER JOIN;C选项,应为所选取的任意表没有索引。
33.批处理是指包含一条或多条T-SQL语句的语句组,下列选项中,关于批处理的规则描述正确的是()
A.定义一个check约束后,可以在同一个批处理中使用
B.修改一个表中的字段名后,不可以在同一个批处理中引用这个新字段
C.Create default,Create rule等语句同一个批处理中可以同时提交多个
D.把规则和默认值绑定到表字段或自定义字段上之后,可以在同一个批处理中使用
解析:选B。 A选项,不能定义一个check约束后,立即在同一个批处理中使用;C选项,Create default,Create rule,Create trigger,Create procedure,Create view等语句同一个批处理中只能提交一个;D选项,不能把规则和默认值绑定到表字段或自定义字段上之后,立即在同一个批处理中使用。
34.关于维护参照完整性约束的策略,下列选项描述不正确的是()
A.对于任何违反了参照完整性约束的数据更新,系统一概拒绝执行
B.当删除被参照表的一个元组造成了与参照表的不一致,则删除参照表中的所有造成不一致的元组
C.当修改被参照表的一个元组造成了与参照表的不一致,则修改被参照表中的所有造成不一致的元组
D.当删除或修改被参照表的一个元组造成了不一致,则将参照表中的所有造成和不一致的元组的对应属性设置为空值
解析:选C。参照完整性共分四种模式:不执行操作、级联、置空、设置默认值。
B选项对应级联操作,即主键列(被参照表)删除同时外键列(参照列)对应列也被删除;
C选项也对应级联操作,但应为修改外键列(参照表)中的数据;
D选项对应置空,即主键列数据删除或者修改时外键列对应数据被置为空值;设置默认值模式为主键列的修改和删除使对应外键列数据被置为设定的默认值
相关文章:

【题目】MySQL选择题
来源:MySQL专项练习选择题 1.有一个User用户表,要删除整张表(指完全删除表数据和结构),下面正确的MySQL语句是: A.DELETE TABLE User; B.DROP TABLE User; C.TRUNCATE TABLE User; D.DELETE FROM User …...

自然语言处理系列六十三》神经网络算法》LSTM长短期记忆神经网络算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列六十三神经网络算法》LSTM长短期记忆神经网络算…...

亚马逊IP关联及其解决方案
在电子商务领域,亚马逊作为全球领先的在线购物平台,吸引了众多商家和个人的参与。然而,随着业务规模的扩大,商家在使用亚马逊服务时可能会遇到IP关联的问题,这不仅影响账户的正常运营,还可能带来一系列不利…...

Definition and Detection of Defects in NFT Smart Contracts论文解读、复现
背景知识\定义 NFT 是数字或物理资产所有权的区块链表示。不仅限于数字图片,视频和画作等艺术品也可以转化为 NFT 进行交易。近年来受到广泛关注,2021 年 NFT 交易额达到约 410 亿美元。 智能合约 是在区块链上运行的图灵完备程序。支持各种去中心化…...
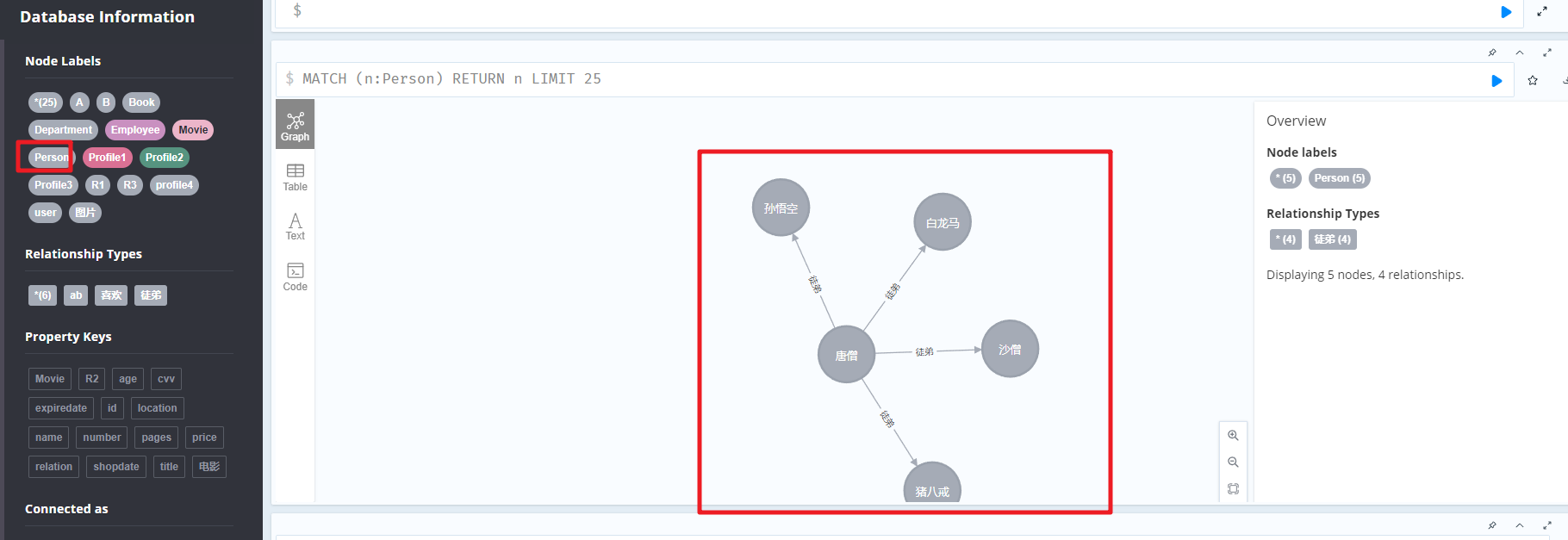
Neo4j图数据库
文章目录 一、Neo4J相关介绍1.为什么需要图数据库方案1:Google方案2:Facebook 2.特定和优势3.什么是Neo4j4.Neo4j数据模型图论基础属性图模型Neo4j的构建元素 5.软件安装 二、CQL语句1.CQL简介2.CREATE 命令3.MATCH 命令4.RETURN 子句5.MATCH和RETURN6.C…...

k8s API资源对象
API资源对象Deployment 最小的资源是pod,deployment是多个pod的集合(多个副本实现高可用、负载均衡等)。 使用yaml文件来配置、部署资源对象。 Deployment YAML示例: vi ng-deploy.yaml apiVersion: apps/v1 kind: Deployment…...

GB/T28181规范解读之编码规则详解
GB/T28181,即《安全防范视频监控联网系统信息传输、交换、控制技术要求》,是我国安防行业的重要标准之一。该标准详细规定了城市监控报警联网系统中信息传输、交换、控制的互联结构、通信协议结构,以及传输、交换、控制的基本要求和安全性要求…...

Vue封装的过度与动画(transition-group、animate.css)
目录 1. Vue封装的过度与动画1.1 动画效果11.2 动态效果21.3 使用第三方动画库animate.css 1. Vue封装的过度与动画 作用:在插入、更新或移除DOM元素时,在合适的时候给元素添加样式类名 1.1 动画效果1 Test1.vue: transition内部只能包含一个子标签。…...

免费云服务器申请教程
免费云服务器的申请流程通常包括以下几个步骤,但请注意,不同云服务提供商的具体步骤可能略有不同。以下是一个通用的申请流程: 一、选择合适的云服务提供商 首先,需要选择一家提供免费云服务器服务的云服务提供商。 免费云服务器汇…...

Spring Cloud Gateway中的常见配置
问题 最近用到了Spring Cloud Gateway,这里记录一下这个服务的常见配置。 spring:data:redis:host: ${REDIS_HOST:xxx.xxx.xxx.xxx}port: ${REDIS_PORT:2345wsd}password: ${REDIS_PASS:sdfsdfgh}database: ${REDIS_DB:8}session:redis:flush-mode: on_savenamespa…...
SelectDB 多计算集群核心设计要点揭秘与场景应用
需求起源 SelectDB 设计多计算集群架构初衷主要源于两类典型的使用场景: 写入与读取隔离:传统数仓架构中,数据的写入和读取在同一个计算集群,当遇到业务写入高峰期或突增的写入压力时,容易因资源相互抢占影响查询服务…...

Docker 清理和查看镜像与容器占用情况
查看容器占用磁盘大小 docker system df 查看单个image、container大小: docker system df -v 清理所有废弃镜像与Build Cache docker system prune -a...

如何在Android 12 aosp系统源码中添加三指下滑截图功能
如何在Android 12 aosp系统源码中添加三指下滑截图功能 系统中截图api非常简单: private static ScreenshotHelper sScreenshotHelper;sScreenshotHelper new ScreenshotHelper(mContext);//调用 sScreenshotHelper.takeScreenshot(WindowManager.TAKE_SCREENSHO…...

使用SQL语句查询MySQL数据表
6.1 创建单表基本查询 1.Select 语句的语法格式及其功能 (1)Select 语句的一般格式。 Select < 字段名称或表达式列表 > From < 数据表名称或视图名称 > [ Where < 条件表达式 > ] [ Group By < 分组的字段名称…...

【AI绘画、换脸、写作、办公】从零开始:使用AIStarter启动器发布AI应用
随着人工智能技术的快速发展,越来越多的开发者希望通过自己的创意来构建和分享AI应用。AIStarter启动器正是为此而设计的一个强大工具,它可以帮助开发者轻松打包并发布自己的AI应用项目。本文将详细介绍如何使用AIStarter启动器来实现这一目标。 注册账…...

eeprom使用 cubemx STM32F407ZGT6【IIC驱动AT24C02】
存储器的简单介绍 ROM(只读存储器)、RAM(随机存取存储器)、Flash(闪存)、和EEPROM(电可擦可编程只读存储器)是四种不同类型的存储介质。ROM用于存储固件或永久数据,不易…...

STL-stack/queue/deque(容器适配器)
目录 编辑 STL-stack 150. 逆波兰表达式求值 stack queue std::stack deque 性能测试 结构 STL-stack 栈的压入、弹出序列_牛客题霸_牛客网输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假。题目…...

NVDLA专题15:Runtime environment-核心模式驱动
核心模式驱动(Kernel Mode Driver) KMD主入口点在内存中接收一个推理作业,从多个可用的作业中选择要执行的作业(如果在多进程系统上),并将其提交给核心引擎调度程序。该核心引擎调度程序负责处理来自NVDLA的中断,调度每…...

计算机毕业设计选题推荐-班级管理系统-教务管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

推荐一款开源、高效、灵活的Redis桌面管理工具:Tiny RDM!支持调试与分析功能!
1、引言 在大数据和云计算快速发展的今天,Redis作为一款高性能的内存键值存储系统,在数据缓存、实时计算、消息队列等领域发挥着重要作用。然而,随着Redis集群规模的扩大和复杂度的增加,如何高效地管理和运维Redis数据库成为了许…...

Windows上运行安卓应用:APK安装器完整指南
Windows上运行安卓应用:APK安装器完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,却不想安装笨重的…...

CodeGPT高级代理系统:10个实用工具助你高效编程的完整指南
CodeGPT高级代理系统:10个实用工具助你高效编程的完整指南 【免费下载链接】CodeGPT The leading open-source AI copilot for JetBrains. Connect to any model in any environment, and customize your coding experience in any way you like. 项目地址: https…...

RK3568扩展模块实战:4G/Wi-Fi 6/多串口集成与Linux驱动适配
1. 项目概述:当“小”模块遇上“大”平台最近在折腾一块瑞芯微的RK3568开发板,这板子性能不错,四核A55加上独立的NPU,做边缘计算、多媒体网关或者轻量级服务器都挺合适。但在实际项目落地时,我遇到了一个几乎所有硬件开…...

COLMAP稠密点云太稀疏?OpenMVS点云又太密?试试这个‘黄金搭档’配置方案
COLMAP与OpenMVS混合重建:如何实现点云密度与计算效率的黄金平衡 在三维重建领域,我们常常面临一个两难选择:COLMAP生成的稠密点云往往过于稀疏,导致最终网格模型细节不足;而OpenMVS自带的稠密重建又容易产生过度密集的…...

突破性技术:CXPatcher如何在Mac上实现CrossOver性能极限的完整指南
突破性技术:CXPatcher如何在Mac上实现CrossOver性能极限的完整指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 对于在macOS上运行Windows应…...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...

免费开源!掌握AMD Ryzen处理器深度调试:SMUDebugTool终极指南
免费开源!掌握AMD Ryzen处理器深度调试:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项…...

一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失
一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾有过…...

大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票
大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为心仪演唱会门票秒光而烦恼吗?还在为黄牛高…...

Vue3组合式API进阶:深入理解和高效使用Composition API
Vue3组合式API进阶:深入理解和高效使用Composition API 前言 大家好,我是前端老炮儿!今天咱们来聊聊Vue3组合式API的进阶用法。 你以为ref和reactive就够了?那你可太天真了!Vue3的Composition API远比你想象的更强大。…...