图神经网络介绍3
1. 图同构网络:Weisfeiler-Lehman 测试与图神经网络的表达力
本节介绍一个关于图神经网络表达力的经典工作,以及随之产生的另一个重要的模型——图同构网络。图同构问题指的是验证两个图在拓扑结构上是否相同。Weisfeiler-Lehman 测试是一种有效的检验两个图是否同构的近似方法。当我们要判断两个图是否同构时,先通过聚合节点和它们邻居的标签,再通过散列函数得到节点新的标签,不断重复,直到每个节点的标签稳定不变。如果在某些迭代中,两个图的节点标签不同,则可以判定这两个图是不同的。在Weisfeiler-Lehman测试的过程中,K次迭代之后,我们会得到关于一个节点的高度为K 的子树。Weisfeiler-Lehman子树常被用于核方法中,来计算两个图的相似度。
类似于消息传递网络中所归纳的框架,大部分基于空域的图神经网络都可以归结为两个步骤:聚合邻接点信息和更新节点信息。

与Weisfeiler-Lehman测试一样,在表达网络结构的时候,一个节点的表征会由该节点的父节点的子树信息聚合而成。在图同构网络的论文中,作者证明了Weisfeiler-Lehman测试是图神经网络表征能力的上限。
定理 :设G₁和G₂ 为任意非同构图。如果一个图神经网络遵循领域聚合方案, 将G₁和G₂ 映射到不同的嵌入,则Weisfeiler-Lehman测试也判定G₁和G₂不是同构的。这说明,图神经网络的表达能力不会超过Weisfeiler-Lehman测试的区分能力。那么,我们有没有办法得到和Weisfeiler-Lehman测试一样强大的图神经网络呢?Weisfeiler-Lehman 测试最大的特点是其对每个节点的子树的聚合函数采用的是单射的散列函数。那么,是否将图神经网络的聚合函数也改成单射函数就能达到和Weisfeiler-Lehman测试一样的效果呢?
定理4:设A:G→Rd(上标)是一个遵循邻域聚合方案的图神经网络。通过足够的迭代次数(在图神经网络层数多的情况下),如果满足以下条件,则 A可以通过 Weisfeiler-Lehman测试把非同构的两个图G₁ 和G₂ 映射到不同的嵌入:
(1)A 在每次迭代时所采用的节点状态更新公式:

其中φ是单射函数,f 是一个作用在多重集上的函数,也是单射函数。
(2)从节点嵌入整合到最终的图嵌入时,A 所采用的读取函数运行在节点嵌入的多重集{hvk}上,也是一个单射函数。单射指的是不同的输入值一定会对应到不同的函数值。这个结论说明,要设计与Weisfeiler-Lehman一样强大的图卷积网络,最重要的条件是设计一个单射的聚合函数。
其实,求和函数在多重集上就是一个单射函数。由此,我们得到了一个新模型——图同构网络,只需要把聚合函数改为求和函数,就可以提升图神经网络的表达力:

2.图卷积网络实战
init部分
#导入确保代码在Python 2中也能使用Python 3的特性
from __future__ import print_function
#从layers模块导入所有内容
from __future__ import division
from .layers import *
#从models模块导入所有内容
from .models import *
#utils模块导入所有内容
from .utils import *layers部分
import math
import torch
#从 PyTorch 的 nn 模块中导入 Parameter 类,它用于定义可学习的参数
from torch.nn.parameter import Parameter
#从 PyTorch 的 nn 模块中导入 Module 类,它是所有神经网络模块的基类
from torch.nn.modules.module import Module
#定义一个名为 GraphConvolution 的类,它继承自 Module 类
class GraphConvolution(Module):
#bias=True 是一个常见的参数设置,它用于决定是否在模型的某些层中添加偏置项。偏置项是神经网络中的一个参数,它允许模型在特征空间中进行平移,从而提高模型的灵活性和学习能力
#接收输入特征数 in_features、输出特征数 out_featuresdef __init__(self,in_features,out_features,bias=True):super(GraphConvolution,self).__init__()self.in_features=in_featuresself.out_features=out_features#创建一个权重矩阵 weight,它是一个 Parameter 对象,用于存储可学习的权重参数self.weight=Parameter(torch.FloatTensor(in_features,out_features))if bias:self.bias=Parameter(torch.FloatTensor(out_features))else:#如果 bias 参数为 False,则不创建偏置向量,而是将 bias 注册为一个不存在的参数self.register_parameter('bias',None)#调用 reset_parameters 方法来初始化权重和偏置参数self.reset_parameters()def reset_parameters(self):#计算权重的初始化标准差,使用输出特征数的平方根的倒数stdv=1./math.sqrt(self.weight.size(1))#使用均匀分布初始化权重,范围在 [-stdv, stdv] 之间self.weight.data.uniform_(-stdv,stdv)#定义 forward 方法,它是模型的前向传播方法,接收输入数据 input 和邻接矩阵 adjdef forward(self,input,adj):#定义 forward 方法,它是模型的前向传播方法,接收输入数据 input 和邻接矩阵 adjsupport=torch.mm(input,self.weight)#使用矩阵乘法计算输入数据和权重的乘积,得到变换后的特征output=torch.spmm(adj,support)if self.bias is not None:return output+self.biaselse:return output#定义 __repr__ 方法,用于返回类的字符串表示def __repr__(self):return self.__class__.__name +'('\+str(self.in_features)+'->'\+str(self.out_features)+')'models部分
#导入 PyTorch 的神经网络模块
import torch.nn as nn
#导入 PyTorch 的函数模块,它包含了一些常用的函数,比如激活函数。
import torch.nn.functional as F
#从 pygcn 库中导入 GraphConvolution 类,这是一个图卷积层的实现
from pygcn.layers import GraphConvolution
#定义了一个名为 GCN 的类,它继承自 nn.Module
class GCN(nn.Module):#nfeat:输入特征的数量,nhid:隐藏层的特征数量#nclass:输出类别的数量,dropout:Dropout 层的丢弃概率def __init__(self,nfeat,nhid,nclass,dropout):super(GCN,self).__init__()
#self.gc1=GraphConvolution(nfeat,nhid):创建第一个图卷积层,将输入特征从 nfeat 转换到 nhid。self.gc1=GraphConvolution(nfeat,nhid)
#self.gc2=GraphConvolution(nhid,nclass):创建第二个图卷积层,将隐藏层特征从 nhid 转换到输出类别 nclassself.gc2=GraphConvolution(nhid,nclass)
#将Dropout 层的丢弃概率设置为传入的 dropout 参数self.dropout=dropout#定义了模型的前向传播函数,它接收两个参数#x:输入的特征矩阵,adj:邻接矩阵,表示图结构def forward(self,x,adj):#通过第一个图卷积层 gc1 传递 x 和 adj,然后应用 ReLU 激活函数x=F.relu(self.gc1(x,adj))#在激活后的特征上应用 Dropout 层x=F.dropout(x,self.dropout,training=self.training)#通过第二个图卷积层 gc2 传递 x 和 adjx=self.gc2(x,adj)
#在最后一层上应用 log-softmax 函数,得到每个类别的对数概率,并返回结果
#Softmax 目的是将一个向量或一个批量的向量中的元素值转换成概率分布return F.log_softmax(x,dim=1)utils部分(函数或代码模块)
import numpy as np
#导入 SciPy 库中的稀疏矩阵模块,用于处理稀疏矩阵sparse稀疏矩阵
import scipy.sparse as sp
import torch
#定义一个函数,将标签编码为 one-hot 格式
def encode_onehot(labels):classes=set(labels)#从标签中提取所有唯一的类别classes_dict={c:np.identity(len(classes))[i,:] for i,c in enumerate(classes)}labels_onehot=np.array(list(map(classes_dict.get,labels)),dtype=np.int32)#将所有标签转换为 one-hot 编码格式return labels_onehot
#返回 one-hot 编码的标签数组
def load_data(path="../data/cora/",dataset='cora'):print('Loading {} dataset ...'.format(dataset))idx_features_labels=np.genfromtxt("{}{}.content".format(path,dataset),dtype=np.dtype(str))#从文件中加载节点的特征和标签 sp.csr_matriX稀疏矩阵features=sp.csr_matrix(idx_features_labels[:,1,-1],dtype=np.int32)#创建一个稀疏矩阵,包含节点的特征idx_map={j:i for i,j in enumerate(idx)}#创建一个映射,将索引映射到一个新值edges_unorded=np.genformtxt("{}{}.cites".format(path,dataset),dtype=np.int32)#从文件中加载引用(边)信息edges=np.array(list(map(idx_map.get,edges_unorded.flatten())),dtype=np.int32).reshape(edges_unorded.shape)shape=(labels.shape[0],labels.shape[0]), dtype=np.float32)#创建一个 COO 格式的稀疏邻接矩阵adj=sp.coo_matrix((np.ones(edges.shape[0]),(edges[:,0],edges[:,1])),shape=(labels.shape[0],labels.shape[0]),dtype=np.float32)#构建对称邻接矩阵是图数据处理中的一个常见步骤adj=adj+adj.T.multiply(adj.T>adj)-adj.multiply(adj.T>adj)#确保邻接矩阵是对称的features=normalize(features)#对特征矩阵进行归一化处理,归一化:数据按照一定的比例缩放,使其落在特定的区间内adj=normalize(adj+sp.eye(adj.shape[0]))
#对邻接矩阵进行归一化,并添加自环,添加自环是指在图中添加一条边,使得这条边连接一个顶点和它自身。idx_train=range(140)
#定义训练集的索引idx_val=range(200,500)
#定义验证集的索引idx_test=range(500,1500)
#定义测试集的索引features=torch.FloatTensor(np.array(features.todense()))
#将特征矩阵转换为 PyTorch 的 FloatTensorlabels=torch.LongTensor(np.where(labels)[1])
#将标签转换为 PyTorch 的 LongTensoradj=sparse_mx_to_torch_sparse_tensor(adj)
#将稀疏邻接矩阵转换为 PyTorch 的稀疏张量idx_train=torch.LongTensor(idx_train)
#将训练集索引转换为 PyTorch 的 LongTensoridx_val=torch.LongTensor(idx_val)
#将验证集索引转换为 PyTorch 的 LongTensoridx_test=torch.LongTensor(idx_test)
#将测试集索引转换为 PyTorch 的 LongTensor。return adj,features,labels,idx_train,idx_val,idx_test
def normalize(mx):#定义一个函数,用于归一化矩阵rowsum=np.array(mx.sum(1))#计算每一行的和r_inv=np.power(rowsum,-1).flatten()#计算每一行的倒数r_mat_inv=sp.diags(r_inv)#创建一个对角矩阵,对角线上是行的倒数mx=r_mat_inv.dot(mx)#用对角矩阵乘以原矩阵,进行归一化,#mx=r_mat_inv.dot(mx)是矩阵乘法操作return mx
def accuracy(output,labels):#定义一个函数,用于计算准确率preds=output.max(1)[1].type_as(labels)#获取预测的类别correct=preds.eq(labels).double()#计算预测正确的数量correct=correct.sum()#将正确的数量相加return correct/len(labels)
#返回准确率
def sparse_mx_to_torch_sparse_tensor(sparse_mx):#定义一个函数,将 SciPy 的稀疏矩阵转换为 PyTorch 的稀疏张量sparse_mx=sparse_mx.tocoo().astype(np.float32)#将稀疏矩阵转换为 COO 格式indices=torch.from_numpy(np.vstack((sparse_mx.row,sparse_mx.col)).astype(np.int64))#创建一个包含行和列索引的张量values=torch.from_numpy(sparse_mx.data)#创建一个包含数据值的张量shape=torch.Size(sparse_mx.shape)return torch.sparse.FloatTensor(indices,values,shape)
#返回一个 PyTorch 的稀疏 FloatTensortrain部分
from __future__ import division
#从 __future__ 模块导入 division,使得除法 / 总是产生浮点数结果
from __future__ import print_function
#从 __future__ 模块导入 print_function,确保在 Python 2 中使用 Python 3 的打印语法
import time
import argparse
#导入argparse模块,用于解析命令行参数
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
#从 torch 导入 optim 模块,提供优化算法
from pygcn.utils import load_data, accuracy
#从 pygcn 包的 utils 模块导入 load_data 和 accuracy 函数
from pygcn.models import GCN
#从 pygcn 包的 models 模块导入 GCN 类
parser = argparse.ArgumentParser()
#创建一个 ArgumentParser 对象,用于解析命令行参数
parser.add_argument('--no-cuda', action='store_true', default=False,help='Disables CUDA training.')
#添加一个命令行参数,用于禁用 CUDA 训练
parser.add_argument('--fastmode', action='store_true', default=False,help='Validate during training pass.')
#添加一个命令行参数,用于在训练过程中进行验证
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
#添加一个命令行参数,用于设置随机种子
parser.add_argument('--epochs',type=int,default=42,help='Random seed.')
#添加一个命令行参数,用于设置训练的轮数
parser.add_argument('--lr',type=float,default=0.01,help='Inital learning rate.')
#添加一个命令行参数,用于设置初始学习率
parser.add_argument('--weight_deacy',type=float,default=5e-4,help='Weight deacy(L2 loss on parameters).')
#添加一个命令行参数,用于设置权重衰减
parser.add_argument('--hidden',type=int,default=16,help='Number of hidden units.')
#添加一个命令行参数,用于设置隐藏层单元的数量
parser.add_argument('--dropout',type=float,default=0.5,help='Dropout rate (1-keep probability).')
#添加一个命令行参数,用于设置 dropout 率
args=parser.parse_args()
#解析命令行参数
args.cuda=not args.no_cuda and torch.cuda.is_available()
#设置 cuda 标志,如果命令行参数 --no-cuda 没有被设置且 CUDA 可用,则启用 CUDA
np.random.seed(args.seed)
#设置 NumPy 的随机种子
torch.manual_seed(args.seed)
#设置 PyTorch 的随机种子
if args.cuda:torch.cuda.manual_seed(args.seed)#如果使用 CUDA,则设置 CUDA 的随机种子
#load data
adj,features,labels,idx_train,idx_val,idx_test=load_data()
#调用 load_data 函数加载数据
#model and optimizer
model =GCN(nfeat=features.shape[1],#nfeat:特征的数量nhid=args.hidden,#nhid:隐藏层的单元数nclass=labels.max().item+1,#nclass:类别的数量dropout=args.dropout)#dropout 比率,用于正则化以防止过拟合
#创建一个 GCN 模型实例,并设置相应的参数
optimizer=optim.Adam(model.parameters(),lr=args.lr,weight_deacy=args.weight_deacy)
#创建一个 Adam 优化器实例,并设置学习率和权重衰减
if args.cuda:model.cuda()features=features.cuda()adj=adj.cuda()labels=labels.cuda()idx_train=idx_train.cuda()idx_val=idx_val.cuda()idx_test=idx_test.cuda()#如果使用 CUDA,则将模型和数据迁移到 GPU
def train(epoch):#定义 train 函数,用于执行一个训练周期t=time.time()#记录训练开始的时间model.train()#设置模型为训练模式optimizer.zero_grad()#清空优化器的梯度output=model(features,adj)#前向传播,计算模型输出loss_train=F.nll_loss(output[idx_train],labels[idx_train])#计算训练集上的损失acc_train=accuracy(output[idx_train],labels[idx_train])#计算训练集上的准确率loss_train.backward()#反向传播,计算梯度optimizer.step()#更新模型参数if not args.fastmode:#(fast mode)通常是指一种优化的执行模式,旨在提高程序的运行速度,通常是以牺牲一些功能或降低准确性为代价model.eval()output=model(features,adj)loss_val=F.nll_loss(output[idx_val],labels[idx_val])acc_val=accuracy(output[idx_val],labels[idx_val])print('Epoch:{:04d}'.format(loss_train.item()),'loss_train:{:.4f}'.format(loss_train.item()),'acc_train:{:.4f}'.format(acc_train.item()),'loss_val:{:.4f}'.format(acc_val.item()),'time:{:.4f}s'.format(time.time()-t))#如果不使用快速模式,则在每个训练周期后进行验证,并计算验证集上的损失和准确率
def test():#定义 test 函数,用于测试模型model.eval()#设置模型为评估模式output=model(features,adj)#前向传播,计算模型输出loss_test=F.nll_loss(output[idx_test],labels[idx_test])#计算测试集上的损失print("Test set results:","loss={:.4f}".format(acc_test.item()))#打印测试集的结果
t_total=time.time()
#记录总的开始时间
for epoch in range(args.epochs):train(epoch)#进行指定次数的训练周期
print("Optimization Finished!")
#训练完成后打印信息
print('Total time elapsed:{:.4f}s'.format(time.time()-t_total))
#打印总的执行时间
test()
#调用 test 函数进行测试
#前向传播是模型评估和预测的基础,它使得模型能够根据训练过程中学到的权重和偏差来对新的输入数据做出响应
#1.在训练过程中,前向传播用于计算预测值,然后通过反向传播算法计算损失函数的梯度,并更新模型的权重
# 2.在模型部署或推理阶段,前向传播用于生成最终的预测结果先在第一层图卷积网络后面加上非线性激活函数ReLU, 再加一层dropout防止过拟合;第二层图卷积网络则直接加上softmax, 输出多分类的结果。对于大部分标准数据,两层图卷 积网络即可达到很好的效果,叠加更多的层并不一定能提升模型的表现,反而 可能导致过平滑的问题。 Softmax 函数是一种在机器学习和深度学习中常用的激活函数,特别是在处理多分类问题时。它的主要作用是将一个向量或一组实数转换为概率分布,使得每个元素的值都在0到1之间,并且所有元素的和为1。这使得softmax函数非常适合用于分类任务中,作为输出层的激活函数。
在这个简单的图卷积网络实现中,没有使用批处理的方式进行训练,因为 这样实现更容易。对于大部分数据集来说,这种实现方式是没有问题的, 但对于一些大规模的数据集(如Reddit), 因为节点数过多,如果不采用 批处理或采样的方式进行训练,就会出现内存爆炸等问题。
"内存爆炸"通常用来描述计算机系统中内存使用量急剧增加,以至于系统无法正常工作或性能严重下降的情况。
早停是一种在机器学习模型训练过程中用来防止过拟合的技术。过拟合是指模型在训练数据上表现得很好,但是在新的、未见过的数据上表现不佳,即模型的泛化能力差。早停的目的是提前结束训练过程,以避免模型在训练数据上过度拟合。
沿着图神经网络的发展脉络介绍了主要的两类图神经网络模型:谱域图神经网络和空域图神经网络。谱域图神经网络的方法以图论傅里叶变换为基础,通过在谱域定义卷积来实现图信号的处理;而空域图神经网络则可以视为图上节点的消息传递和聚合。之后发展出的各种各样的图神经网络大都可以归于这两种框架(即基于“谱域卷积”的方式或基于“消息传递”的方式)
相关文章:
图神经网络介绍3
1. 图同构网络:Weisfeiler-Lehman 测试与图神经网络的表达力 本节介绍一个关于图神经网络表达力的经典工作,以及随之产生的另一个重要的模型——图同构网络。图同构问题指的是验证两个图在拓扑结构上是否相同。Weisfeiler-Lehman 测试是一种有效的检验两…...

浅谈 React Fiber
想象一下,你正在搭建一个乐高积木城堡。 传统的搭建方式:一次性把所有积木拼好,如果中途发现某个地方拼错了,就需要拆掉重新拼。这个过程就像 React 15 之前的版本,一旦开始渲染,就很难中断,效…...

Winform实现石头剪刀布小游戏
1、电脑玩家类 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace RockScissorsClothApp {public class Computer{public Card Play(){Random random new Random();int num random.Next(0, 3…...

计算机的错误计算(九十)
摘要 计算机的错误计算(八十九)探讨了反双曲余切函数 acoth(x)在 附近的计算精度问题。本节讨论绝对值为大数的反双曲余切函数值的计算精度问题。 Acoth(x) 函数的定义为: 其中 x 的绝对值大于 1 . 例1. 计算 acoth(1.000000000002e15) .…...

对游戏语音软件Oopz遭遇DDoS攻击后的一些建议
由于武汉天气太热,因此周末两天就没怎么出门。一直在家打《黑神话:悟空》,结果卡在广智这里一直打不过去,本来想找好友一起讨论下该怎么过,但又没有好的游戏语音软件。于是在网上搜索了一些信息,并偶然间发…...

解锁Android开发利器:MVVM架构_android的mvvm
// 从网络或其他数据源获取天气数据return Weather(city, "25C") }} 2.定义View:class WeatherActivity : AppCompatActivity() { private lateinit var viewModel: WeatherViewModel override fun onCreate(savedInstanceState: Bundle?) {super.onCre…...

llama.cpp demo
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp 修改Makefile使能mfma参数 MK_CFLAGS -mfma -mf16c -mavx MK_CXXFLAGS -mfma -mf16c -mavx 安装python3依赖 cat ./requirements/requirements-convert_legacy_llama.txt numpy~1.26.4 sentencepie…...

OpenCV结构分析与形状描述符(19)查找二维点集的最小面积外接旋转矩形函数minAreaRect()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 找到一个包围输入的二维点集的最小面积旋转矩形。 该函数计算并返回指定点集的最小面积边界矩形(可能是旋转的)。开发者…...

[SWPU2019]Web1 超详细教程
老规矩先看源码,没找到啥提示,后面就是登录口对抗 弱口令试了几个不行,就注册了个账户登录进去 可以发布广告,能造成xss,但是没啥用啊感觉 查看广告信息的时候,注意到url当中存在id参数,可能存…...

【区块链通用服务平台及组件】基于向量数据库与 LLM 的智能合约 Copilot
智能合约是自动执行、无需信任的代码,可以在区块链上运行,确保了数据和程序的透明性和不可篡改性。然而, 智能合约的编写、调试和优化仍然是一个具有挑战性的过程,因为它需要高度的技术专长,且发布后的智能合约代码通常…...

mfc140u.dll丢失有啥方法能够进行修复?分享几种mfc140u.dll丢失的解决办法
你是否曾遇到过这样的情况:当你满怀期待地打开一个应用程序时,却被一个错误提示拦住了去路,提示信息中指出 mfc140u.dll 文件丢失。这个问题可能会让你感到困惑和无助,但是不要担心,本文将为你详细解读 mfc140u.dll 丢…...
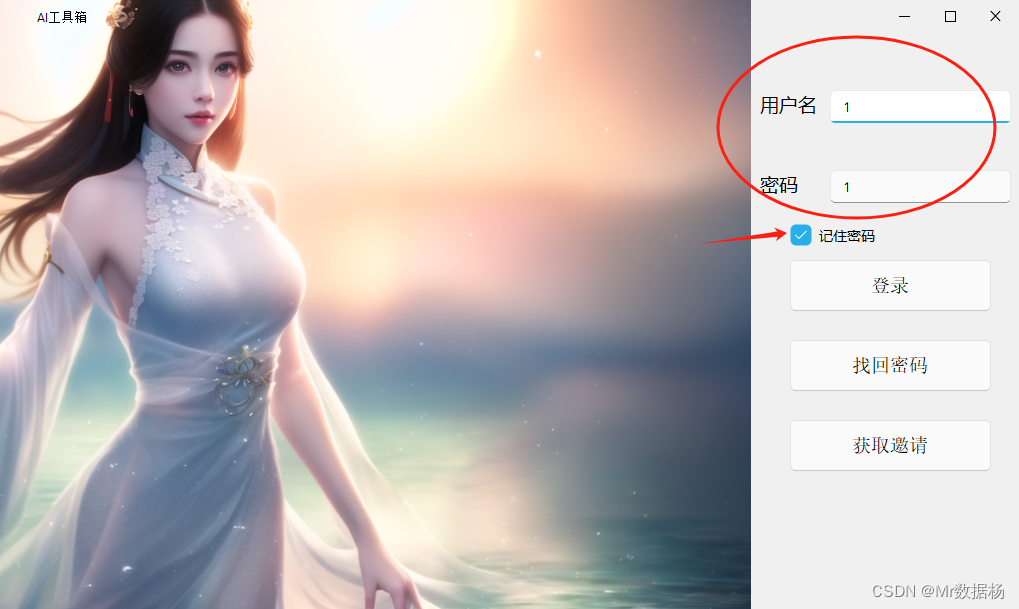
【PyQt6 应用程序】在用户登录界面实现密码密文保存复用
在开发现代应用程序中,为用户提供既安全又便捷的登录体验是至关重要的。特别是在那些需要用户认证的应用中,实现一个功能丰富且用户友好的登录界面不仅能增强用户满意度,还能提升整体的安全性。基于PyQt6框架和QtDesigner,本文将展示如何在已有的用户登录页面基础上,进一步…...

赋能百业:多模态处理技术与大模型架构下的AI解决方案落地实践
赋能百业:多模态处理技术与大模型架构下的AI解决方案落地实践 AI 语音交互大模型其实有两种主流的做法: All in LLM多个模块组合, ASR+LLM+TTS实际应用中,这两种方案并不是要对立存在的,像永劫无间这种游戏的场景,用户要的是低延迟,无障碍交流。并且能够触发某些动作技…...

游戏论坛网站|基于Springboot+vue的游戏论坛网站系统游戏分享网站(源码+数据库+文档)
游戏论坛|游戏论坛系统|游戏分享网站 目录 基于Springbootvue的游戏论坛网站系统游戏分享网站 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大…...

【go】pprof 性能分析
前言 go pprof是 Go 语言提供的性能分析工具。它可以帮助开发者分析 Go 程序的性能问题,包括 CPU 使用情况、内存分配情况、阻塞情况等。 主要功能 CPU 性能分析 go pprof可以对程序的 CPU 使用情况进行分析。它通过在一定时间内对程序的执行进行采样࿰…...

Python | Leetcode Python题解之第397题整数替换
题目: 题解: class Solution:def integerReplacement(self, n: int) -> int:ans 0while n ! 1:if n % 2 0:ans 1n // 2elif n % 4 1:ans 2n // 2else:if n 3:ans 2n 1else:ans 2n n // 2 1return ans...
JDBC使用
7.2 创建JDBC应用 7.2.1 创建JDBC应用程序的步骤 使用JDBC操作数据库中的数据包括6个基本操作步骤: (1)载入JDBC驱动程序: 首先要在应用程序中加载驱动程序driver,使用Class.forName()方法加载特定的驱动程序…...
)
633. 平方数之和-LeetCode(C++)
633. 平方数之和 2024.9.11 题目 给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 b2 c 。 0 < c < 2的31次方 - 1 示例 示例 1: 输入:c 5 输出:true 解释:1 * 1 2 * 2 5示…...

Linux shell编程学习笔记79:cpio命令——文件和目录归档工具(下)
在 Linux shell编程学习笔记78:cpio命令——文件和目录归档工具(上)-CSDN博客https://blog.csdn.net/Purpleendurer/article/details/142095476?spm1001.2014.3001.5501中,我们研究了 cpio命令 的功能、格式、选项说明 以及 cpi…...

《 C++ 修炼全景指南:七 》优先级队列在行动:解密 C++ priority_queue 的实现与应用
1、引言 在现代编程中,处理动态优先级队列的需求随处可见,例如任务调度、路径规划、数据压缩等应用场景都依赖于高效的优先级管理。C 标准库提供了 priority_queue 这一强大的工具,它的独特之处在于它的排序特性,priority_queue …...

3步掌握Open-Lyrics:如何让AI为你的音频自动生成专业字幕
3步掌握Open-Lyrics:如何让AI为你的音频自动生成专业字幕 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项…...

【软考高级架构】论文范文22——论系统可靠性设计及其应用
论系统可靠性设计及其应用 论系统可靠性设计及其应用,本文结合2014年试题题目进行深入论述,探讨如何在实际项目中进行软件的可靠性设计,确保系统在复杂和高风险环境下的稳定性与高效性。在现代复杂系统中,软件的可靠性设计已成为保障系统高效稳定运行的关键因素之一。随着技…...

终极USB安全弹出解决方案:告别Windows设备占用烦恼
终极USB安全弹出解决方案:告别Windows设备占用烦恼 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portable alternativ…...

【Python自动化】PyAutoGUI构建游戏稳定性测试守护脚本
1. PyAutoGUI在游戏测试中的核心价值 游戏稳定性测试往往需要长时间运行,人工值守既低效又容易遗漏异常。PyAutoGUI作为Python的GUI自动化利器,能完美模拟鼠标键盘操作,配合进程监控和图像识别,构建724小时无人值守的测试环境。我…...

在OpenClaw项目中接入Taotoken实现多模型Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中接入Taotoken实现多模型Agent工作流 对于使用OpenClaw框架构建智能体工作流的开发者而言,如何稳定、灵…...

如何在Windows 11上搭建专业级Android开发环境:WSA完全指南
如何在Windows 11上搭建专业级Android开发环境:WSA完全指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android&…...

3步掌握抖音内容批量下载技巧:无水印视频保存终极指南
3步掌握抖音内容批量下载技巧:无水印视频保存终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

告别论文 “双杀” 困局:okbiye 如何用一套闭环方案,破解重复率与 AIGC 检测双重难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 当你对着导师的红笔批注,第三次修改论文时,有没有想过一个问题:为什么你改了又改的句子,重…...

在OpenClaw项目中配置Taotoken实现多模型Agent的灵活调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中配置Taotoken实现多模型Agent的灵活调用 对于使用OpenClaw框架构建AI Agent的开发者而言,直接接入单一…...

从STM32到STC32G:LCM模块驱动8080接口TFT屏的移植实战
1. 硬件平台迁移的背景与挑战 最近在做一个嵌入式项目时,遇到一个典型场景:手头有一套在STM32上运行良好的TFT液晶屏驱动代码,但客户要求改用STC32G系列MCU。这种硬件平台迁移在嵌入式开发中很常见,特别是当项目需要考虑成本优化时…...