分布式集群下如何做到唯一序列号
优质博文:IT-BLOG-CN
分布式架构下,生成唯一序列号是设计系统常常会遇到的一个问题。例如,数据库使用分库分表的时候,当分成若干个sharding表后,如何能够快速拿到一个唯一序列号,是经常遇到的问题。实现思路如下:
【1】数据库自增长序列或字段:全数据库唯一。
【优点】:简单,代码方便,性能可以接受。数字ID天然排序,对分页后者需要排序的结果很有帮组。适合小应用,无需分表,无高并发性能要求。
【缺点】:不同数据库实现不同,在水平分表时,使用自增ID时可能会出现ID冲突。同时在高并发的情况下需要使用事务。在性能达不到要求的情况下,比较难于扩展。如果多个系统需要合并或者设计到数据迁移会相当痛苦。
【优化】:针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1生成的是1,4,7,10,Master2生成的是2,5,8,11,Master3生成的是3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
【2】UUID:常见的方式。可以利用数据库也可以利用程序生成32位的16进制格式的字符串,唯一性很高。
【优点】:简单,方便,生产ID性能非常好且全球基本唯一,在数据迁移和系统后期合并,或数据库变更等情况下都可应对。
【缺点】:没有排序,无法保证趋势递增。UUID使用字符串存储,查询效率低。存储空间较大,如果数据海量就绪考虑存储量问题,传输数据量大。
UUID是一种标准的128位标识符,几乎可以保证全局唯一。Java中可以使用java.util.UUID来生成:
import java.util.UUID;public class UniqueIDGenerator {public static String generateUUID() {return UUID.randomUUID().toString();}
}
【3】Redis生成ID: 当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作INCR和INCRBY来实现。可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机器确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以防止单点故障(系统中一点失效,就会让整个系统无法运作的部件)的问题。另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
【优点】:不依赖于数据库,灵活方便,且性能优于数据库。数字ID天然排序,对分页或者需要排序的结果很有帮助。
【缺点】:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。需要编码和配置的工作量比较大。
使用Redis的原子操作,如INCR命令,可以生成全局唯一的序列号。Redis的高性能和分布式特性使其成为一个不错的选择
import redis.clients.jedis.Jedis;public class RedisIdGenerator {private Jedis jedis;private String key;public RedisIdGenerator(String redisHost, int redisPort, String key) {this.jedis = new Jedis(redisHost, redisPort);this.key = key;}public long nextId() {return jedis.incr(key);}
}
【4】Twitter(推特) 的snowflake算法: twitter在把存储系统从MySQL迁移到Cassandra(一套开源分布式NoSQL数据库系统)的过程中由于Cassandra没有顺序ID生成机制,于是自己开发了一套全局唯一ID生成服务:Snowflake。
● 41位的时间序列(精确到毫秒,41位的长度可以使用69年)
● 10位的机器标识(10位的长度最多支持部署1024个节点)
● 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号) 最高位是符号位,始终为0
Snowflake的结构如下(每部分用-分开): 一共加起来刚好64位,为一个Long型。(转换成字符串后长度最多19)
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生26万个ID。
【优点】:高性能,低延迟;独立的应用;按时间有序。
【缺点】:需要独立的开发和部署。在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
Java实现的Snowflake算法示例:
public class SnowflakeIdGenerator {private final long twepoch = 1288834974657L;private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private final long sequenceBits = 12L;private final long workerIdShift = sequenceBits;private final long datacenterIdShift = sequenceBits + workerIdBits;private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private final long sequenceMask = -1L ^ (-1L << sequenceBits);private long workerId;private long datacenterId;private long sequence = 0L;private long lastTimestamp = -1L;public SnowflakeIdGenerator(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}protected long timeGen() {return System.currentTimeMillis();}
}
【5】MongoDB的ObjectId: MongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。

前4 个字节是从标准纪元开始的时间戳,单位为秒。时间戳,与随后的5个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,这意味着ObjectId大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4个字节也隐含了文档创建的时间。绝大多数客户端类库都会公开一个方法从ObjectId获取这个信息。
接下来的3字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
为了确保在同一台机器上并发的多个进程产生的ObjectId是唯一的,接下来的两字节来自产生ObjectId的进程标识符PID。
前9字节保证了同一秒钟不同机器不同进程产生的ObjectId是唯一的。后3字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId也是不一样的。同一秒钟最多允许每个进程拥有2563(16 777 216)个不同的ObjectId。
【6】Zookeeper: Zookeeper可以用来实现分布式唯一ID生成器。通过创建顺序节点,可以确保每个节点的名称是唯一且递增的。
【7】其他一些方案: 比如京东淘宝等电商的订单号生成。因为订单号和用户id在业务上的区别,订单号尽可能要多些冗余的业务信息,比如:滴滴:时间+起点编号+车牌号 淘宝订单:时间戳+用户ID 其他电商:时间戳+下单渠道+用户ID,有的会加上订单第一个商品的ID。而用户ID,则要求含义简单明了,包含注册渠道即可,尽量短。
相关文章:
分布式集群下如何做到唯一序列号
优质博文:IT-BLOG-CN 分布式架构下,生成唯一序列号是设计系统常常会遇到的一个问题。例如,数据库使用分库分表的时候,当分成若干个sharding表后,如何能够快速拿到一个唯一序列号,是经常遇到的问题。实现思…...

在 Vue 2 中使用 Axios 发起 POST 和 GET 请求
Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 node.js,它提供了一种非常方便的方式来发送异步 HTTP 请求。在 Vue 2 应用中,Axios 可以帮助我们轻松地与后端 API 进行通信。本文将介绍如何在 Vue 2 项目中引入 Axios,并…...
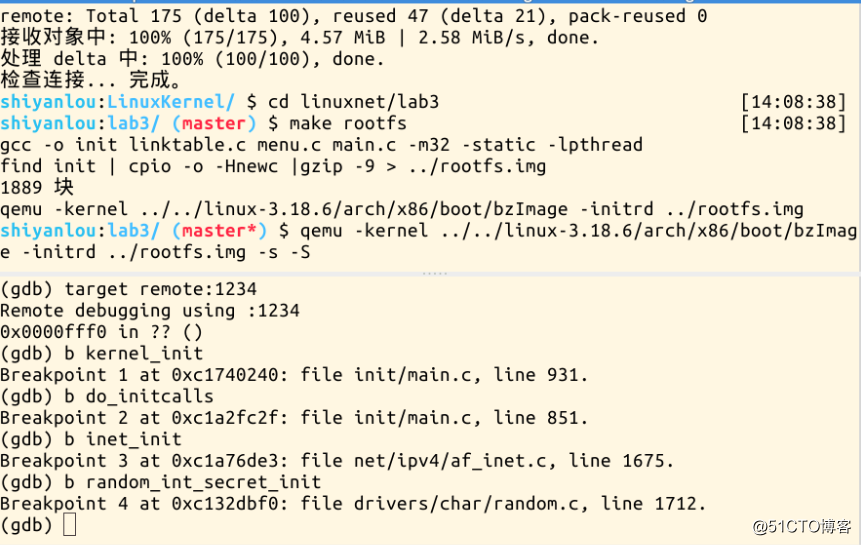
Linux内核初始化过程中加载TCP/IP协议栈
Linux内核初始化过程中加载TCP/IP协议栈 Linux内核初始化过程中加载TCP/IP协议栈,从start_kernel、kernel_init、do_initcalls、inet_init,找出Linux内核初始化TCP/IP的入口位置,即为inet_init函数。 Linux内核启动过程 之前的实验中我们设…...

Mysql树形结构表-查询所有子集数据
表结构,这里只是个例子,所有的树形结构表均可用: CREATE TABLE zhkt_course_chapter (id bigint NOT NULL COMMENT 唯一id,course_id bigint NOT NULL COMMENT 所属课程id,name varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general…...

Vue 3 Composition API进阶指南
在上一篇文章中,我们介绍了Vue 3的Composition API基础,包括如何使用setup函数、ref和reactive来创建响应式数据,以及使用watchEffect来监控数据变化。本文将继续深入探讨Composition API的高级用法,帮助你更好地理解和利用Vue 3的…...

C++学习,多继承
多继承,一个子类可以有多个父类,它继承了多个父类的特性。这种机制提供了强大的灵活性,但也带来了复杂性,特别是当涉及到基类中的同名成员(包括成员函数和变量)时。 C 类从多个类继承成员,语法如…...
,并将其与UTF-8表示进行比较)
苹果研究人员提出了一种新颖的AI算法来优化字节级表示以自动语音识别(ASR),并将其与UTF-8表示进行比较
端到端(E2E)神经网络已成为多语言自动语音识别(ASR)的灵活且准确的模型。然而,随着支持的语言数量增加,尤其是像中文、日语、韩语(CJK)这样大字符集的语言,输出层的大小显…...

2024年重磅报告!国内AI大模型产业飞速发展!
伴随人工智能技术的加速演进,AI 大模型已成为全球科技竞争的新高地、未来产业的新赛道、经济发展的新引擎,发展潜力大、应用前景广。近年来,我国高度重视人工智能的发展,将其上升为国家战略,出台一系列扶持政策和规划&…...

Sentinel 安装
一、下载jar包 下载地址:Releases alibaba/Sentinel GitHub 二、运行 将jar包放在任意非中文、不包含特殊字符的目录下,启动 启动命令:运行cmd 使用一下命令 java -Dserver.port8090 -Dcsp.sentinel.dashboard.serverlocalhost:8090 -D…...
大佬,简单解释下“嵌入式软件开发”和“嵌入式硬件开发”的区别
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「嵌入式的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!首先,嵌入式硬…...

04 奇偶分家
题目: 代码: #include<iostream> using namespace std; #include<stdlib.h> #include<stdio.h>int main() {int N;cin>>N;int jicount0,oucount0;for(int i0;i<N;i){int temp;cin>>temp;if(temp%20){oucount;}else if…...

普通人秒变AI专家:李沐创业同款RAG微调实战,打造专属外卖评论大模型
8月14日晚上,李沐发布了一篇关于他创业一年的复盘文章《创业一年,人间三年》,引起了广泛关注。这篇文章中,李沐分享了从创业初期到现在的心路历程,许多读者读后都倍感激动。 创业之初,李沐的团队原本打算利用大语言模型(LLM)开发生产力工具。然而,在张一鸣的建议下,…...

微模块冷通道动环监控:智能化数据中心管理利器@卓振思众
在现代数据中心和机房管理中,微模块冷通道动环监控系统的引入,标志着对冷却和环境管理的新纪元。这一系统不仅提升了数据中心的运维效率,还对设备的安全性和稳定性提供了强有力的保障。本文将详细探讨微模块冷通道动环监控的功能和其在数据中…...

【Linux】进程调度与切换
【Linux】进程调度与切换 1. 基本概念2. 进程切换3. 进程调度3.1运行队列实现优先级设计3.2 处理效率问题3.3 活动队列与过期队列3.4 如何解决饥饿问题3.5 active指针和expired指针 1. 基本概念 竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个&am…...

SAM 2:分割图像和视频中的任何内容
文章目录 摘要1 引言2 相关工作3 任务:可提示视觉分割4 模型5 数据5.1 数据引擎5.2 SA-V数据集6 零样本实验6.1 视频任务6.1.1 提示视频分割6.1.2 半监督视频对象分割6.1.3 公平性评估6.2 图像任务7 与半监督VOS的最新技术的比较8 数据和模型消融8.1 数据消融8.2 模型架构消融…...

【免越狱】iOS任意版本号APP下载
下载地址 https://pan.quark.cn/s/570e928ee2c4 软件介绍 下载iOS旧版应用,简化繁琐的抓包流程。一键生成去更新IPA(手机安装后,去除App Store的更新检测)。 软件界面 使用方法 一、直接搜索方式 搜索APP,双击选…...

告别植物神经紊乱,这5种运动让你身心平衡,活力满满!♀️✨
Hey小伙伴们~👋 最近是不是感觉压力山大,晚上辗转反侧,白天又无精打采?😴😔 这可能是植物神经紊乱在悄悄作祟哦!别怕,今天就来给大家种草几个超有效的运动方式,帮你找回那…...

又一个iPhone时代开始
今年的苹果秋季发布会在昨晚召开了,今天早上我们也看到了很多相关的新闻。我猜你看完后的感觉可能是,这不过又是一次普普通通的参数升级。又是提升了百分之多少,又是增加了多少倍——非常简单的一些更新。比如说芯片升级了、相机的摄像头一会…...

在 CentOS 中永久关闭防火墙的步骤
在 CentOS 中永久关闭防火墙的步骤 在 CentOS 系统中,防火墙通常由 firewalld 服务管理。如果你希望在系统中永久关闭防火墙,可以按照以下步骤操作: 1. 停止防火墙服务 首先,你需要停止当前正在运行的防火墙服务。可以使用以下…...

【数据库】详解基本SQL语句用法
一、SELECTING DATA FROM TABLES【查询数据】 SELECT命令是表上所有查询的基础,因此给出它的完整描述以显示它的功能。在描述之后提供各种格式的示例。 1.1 整体描述 SELECT column1, column2, ... FROMtable1 [INNER | LEFT | RIGHT] JOIN table2 on conditions…...
)
别再被Windows权限卡脖子!用`--user`参数搞定pip安装报错(附详细排查步骤)
彻底解决Windows下Python包安装权限问题:从--user参数到环境配置全攻略 在Windows系统上进行Python开发时,许多开发者都曾遭遇过这样的尴尬时刻:当你满怀期待地输入pip install package_name准备安装一个新工具时,屏幕上却突然跳出…...

探索Depth Anything V2:单目深度估计技术的新纪元
探索Depth Anything V2:单目深度估计技术的新纪元 【免费下载链接】Depth-Anything-V2 [NeurIPS 2024] Depth Anything V2. A More Capable Foundation Model for Monocular Depth Estimation 项目地址: https://gitcode.com/gh_mirrors/de/Depth-Anything-V2 …...

Nodejs后端服务接入Taotoken实现AI功能的具体配置步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务接入 Taotoken 实现 AI 功能的具体配置步骤 对于 Node.js 开发者而言,将大模型能力集成到后端服务中&…...
)
409.最长回文串(数学算法)
题目 给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的 回文串 的长度。 在构造过程中,请注意 区分大小写 。比如 "Aa" 不能当做一个回文字符串。 题目链接如下: https://leetcode.cn/problems/longe…...

透明计费如何帮助精准预测与控制AI功能月度开支
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费如何帮助精准预测与控制AI功能月度开支 1. 项目背景:深度集成AI的网站 我们负责一个内容创作辅助网站&#x…...

别只仿真了!手把手教你将Proteus里的AT89C52温控风扇代码烧录进实物单片机
从Proteus仿真到实物落地:AT89C52温控风扇全流程实战指南 当你成功在Proteus中完成了AT89C52温控风扇的仿真,看到虚拟环境中风扇随着温度变化自动启停时,那种成就感不言而喻。但仿真终究只是第一步,真正的挑战在于如何将这个系统…...

别再只盯着业务代码了!SpringBoot应用层安全之Tomcat连接管理实战
SpringBoot应用层安全实战:Tomcat连接管理的三驾马车 当我们在讨论SpringBoot应用安全时,业务代码的漏洞修复往往占据了大部分注意力。然而,真正的安全防线远不止于此——应用层基础设施的配置与优化同样至关重要。想象一下,你的应…...

抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案
抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

ceshi1
进入2026年,企业数字化转型已从“流程数字化”全面转向“认知自动化”。 据最新行业数据显示,企业内部超过85%的数据以PDF、图片、音视频、扫描件等非结构化形式存在。 这些数据曾被视为“沉默的资产”,因为传统OCR或规则引擎难以处理其复杂的…...

别再只会插卡开机了!手把手带你用APDU命令探索手机SIM卡里的文件迷宫
解码SIM卡文件系统:用APDU命令探索移动通信的微观世界 当你把SIM卡插入手机时,它就像一把打开移动网络大门的钥匙。但鲜为人知的是,这张小小的芯片内部运行着一个完整的文件系统,其复杂程度堪比微型操作系统。本文将带你用APDU命令…...