第G8周:ACGAN任务
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
本周任务:
根据GAN、CGAN、SGAN及它们的框架图,写出ACGAN代码。
框架图

从图中可以看到,ACGAN的前半部分类似于CGAN,后半部分类似于SGAN,因此,代码前半部分模仿CGAN,后半部分模仿SGAN
配置代码
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
import matplotlib.pyplot as plt
import datetime
import argparsedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 128
这里先定义基本常量,作用相当于parser = argparse.ArgumentParser()
class Args:n_epochs = 200batch_size = 64lr = 0.0002b1 = 0.5b2 = 0.999n_cpu = 8latent_dim = 100img_size = 128 # 看图像类型channels = 3 # 看图像类型sample_interval = 400opt = Args()
print(opt)
train_transform = transforms.Compose([transforms.Resize(128),transforms.ToTensor(),transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])train_dataset = datasets.ImageFolder(root="F:/365data/G3/rps/", transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True,num_workers=6)
def show_images(images):fig, ax = plt.subplots(figsize=(20, 20))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images.detach(), nrow=22).permute(1, 2, 0))def show_batch(dl):for images, _ in dl:show_images(images)break
image_shape = (3, 128, 128)
image_dim = int(np.prod(image_shape))
latent_dim = 100n_classes = 3
embedding_dim = 100
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果当前层是卷积层(类名中包含 'Conv' )if classname.find('Conv') != -1:# 使用正态分布随机初始化权重,均值为0,标准差为0.02torch.nn.init.normal_(m.weight, 0.0, 0.02)# 如果当前层是批归一化层(类名中包含 'BatchNorm' )elif classname.find('BatchNorm') != -1:# 使用正态分布随机初始化权重,均值为1,标准差为0.02torch.nn.init.normal_(m.weight, 1.0, 0.02)# 将偏置项初始化为全零torch.nn.init.zeros_(m.bias)
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中# n_classes:条件标签的总数# embedding_dim:嵌入空间的维度self.label_conditioned_generator = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度)# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中# latent_dim:潜在向量的维度self.latent = nn.Sequential(nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射)# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像self.model = nn.Sequential(# 反卷积层1:将合并后的向量映射为64x8x8的特征图nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化nn.ReLU(True), # ReLU激活函数# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内)def forward(self, inputs):noise_vector, label = inputs# 通过条件标签生成器将标签映射为嵌入向量label_output = self.label_conditioned_generator(label)# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并label_output = label_output.view(-1, 1, 4, 4)# 通过潜在向量生成器将噪声向量映射为潜在向量latent_output = self.latent(noise_vector)# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并latent_output = latent_output.view(-1, 512, 4, 4)# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图concat = torch.cat((latent_output, label_output), dim=1)# 通过生成器的主要结构将合并后的特征图生成为RGB图像image = self.model(concat)return image
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)
from torchinfo import summarysummary(generator)
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Generator --
├─Sequential: 1-1 --
│ └─Embedding: 2-1 300
│ └─Linear: 2-2 1,616
├─Sequential: 1-2 --
│ └─Linear: 2-3 827,392
│ └─LeakyReLU: 2-4 --
├─Sequential: 1-3 --
│ └─ConvTranspose2d: 2-5 4,202,496
│ └─BatchNorm2d: 2-6 1,024
│ └─ReLU: 2-7 --
│ └─ConvTranspose2d: 2-8 2,097,152
│ └─BatchNorm2d: 2-9 512
│ └─ReLU: 2-10 --
│ └─ConvTranspose2d: 2-11 524,288
│ └─BatchNorm2d: 2-12 256
│ └─ReLU: 2-13 --
│ └─ConvTranspose2d: 2-14 131,072
│ └─BatchNorm2d: 2-15 128
│ └─ReLU: 2-16 --
│ └─ConvTranspose2d: 2-17 3,072
│ └─Tanh: 2-18 --
=================================================================
Total params: 7,789,308
Trainable params: 7,789,308
Non-trainable params: 0
=================================================================
以上基本上是CGAN代码的前半部分,到生成器代码为止,以下为SGAN代码的部分
class Discriminator(nn.Module):def __init__(self, in_channels=3):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)
summary(discriminator)
adversarial_loss = nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()def generator_loss(fake_output, label):gen_loss = adversarial_loss(fake_output, label)return gen_lossdef discriminator_loss(output, label):disc_loss = adversarial_loss(output, label)return disc_losscuda = torch.cuda.is_available()
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
learning_rate = 0.0002optimizer_G = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
for epoch in range(opt.n_epochs):for i, (imgs, labels) in enumerate(train_loader):batch_size = imgs.shape[0]# Adversarial ground truthsvalid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)# Configure inputreal_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))# -----------------# Train Generator# -----------------optimizer_G.zero_grad()# Sample noise and labels as generator inputz = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))# Generate a batch of imagesgen_imgs = generator((z,labels))# Loss measures generator's ability to fool the discriminatorvalidity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()# Loss for real imagesreal_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# Loss for fake imagesfake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2# Total discriminator lossd_loss = (d_real_loss + d_fake_loss) / 2# Calculate discriminator accuracypred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch * len(train_loader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"% (epoch, opt.n_epochs, i, len(train_loader), d_loss.item(), 100 * d_acc, g_loss.item()))
运行过程
e:\anaconda3\envs\PGPU\lib\site-packages\torch\nn\modules\container.py:139: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.input = module(input)
[Epoch 0/50] [Batch 19/20] [D loss: 1.455980, acc: 40%] [G loss: 0.490490]
[Epoch 1/50] [Batch 19/20] [D loss: 1.222127, acc: 72%] [G loss: 0.681366]
[Epoch 2/50] [Batch 19/20] [D loss: 1.224287, acc: 63%] [G loss: 0.916321]
[Epoch 3/50] [Batch 19/20] [D loss: 1.111225, acc: 70%] [G loss: 1.007028]
[Epoch 4/50] [Batch 19/20] [D loss: 1.184606, acc: 75%] [G loss: 0.696607]
[Epoch 5/50] [Batch 19/20] [D loss: 1.352154, acc: 55%] [G loss: 0.747507]
[Epoch 6/50] [Batch 19/20] [D loss: 1.403305, acc: 52%] [G loss: 0.869919]
[Epoch 7/50] [Batch 19/20] [D loss: 1.311451, acc: 50%] [G loss: 0.880048]
[Epoch 8/50] [Batch 19/20] [D loss: 1.413715, acc: 50%] [G loss: 0.674482]
[Epoch 9/50] [Batch 19/20] [D loss: 1.326531, acc: 54%] [G loss: 0.609503]
[Epoch 10/50] [Batch 19/20] [D loss: 1.449468, acc: 48%] [G loss: 0.620321]
[Epoch 11/50] [Batch 19/20] [D loss: 1.367987, acc: 53%] [G loss: 0.717428]
[Epoch 12/50] [Batch 19/20] [D loss: 1.286323, acc: 55%] [G loss: 0.748294]
[Epoch 13/50] [Batch 19/20] [D loss: 1.374772, acc: 51%] [G loss: 0.849943]
[Epoch 14/50] [Batch 19/20] [D loss: 1.303872, acc: 55%] [G loss: 0.887458]
[Epoch 15/50] [Batch 19/20] [D loss: 1.338245, acc: 59%] [G loss: 0.566128]
[Epoch 16/50] [Batch 19/20] [D loss: 1.386614, acc: 59%] [G loss: 0.737729]
[Epoch 17/50] [Batch 19/20] [D loss: 1.378518, acc: 55%] [G loss: 0.559435]
[Epoch 18/50] [Batch 19/20] [D loss: 1.421224, acc: 53%] [G loss: 0.639280]
[Epoch 19/50] [Batch 19/20] [D loss: 1.314460, acc: 54%] [G loss: 0.695454]
[Epoch 20/50] [Batch 19/20] [D loss: 1.279016, acc: 56%] [G loss: 0.810150]
[Epoch 21/50] [Batch 19/20] [D loss: 1.364004, acc: 53%] [G loss: 0.736294]
[Epoch 22/50] [Batch 19/20] [D loss: 1.364638, acc: 52%] [G loss: 0.990328]
[Epoch 23/50] [Batch 19/20] [D loss: 1.322828, acc: 53%] [G loss: 0.731904]
[Epoch 24/50] [Batch 19/20] [D loss: 1.317570, acc: 50%] [G loss: 0.839391]
[Epoch 25/50] [Batch 19/20] [D loss: 1.330042, acc: 55%] [G loss: 0.755845]
[Epoch 26/50] [Batch 19/20] [D loss: 1.354234, acc: 55%] [G loss: 0.652750]
[Epoch 27/50] [Batch 19/20] [D loss: 1.383858, acc: 55%] [G loss: 0.677340]
[Epoch 28/50] [Batch 19/20] [D loss: 1.384538, acc: 52%] [G loss: 0.621817]
[Epoch 29/50] [Batch 19/20] [D loss: 1.314232, acc: 54%] [G loss: 0.783550]
[Epoch 30/50] [Batch 19/20] [D loss: 1.328900, acc: 54%] [G loss: 0.709978]
[Epoch 31/50] [Batch 19/20] [D loss: 1.326728, acc: 54%] [G loss: 0.804180]
[Epoch 32/50] [Batch 19/20] [D loss: 1.346232, acc: 52%] [G loss: 0.775322]
[Epoch 33/50] [Batch 19/20] [D loss: 1.290386, acc: 56%] [G loss: 0.939839]
[Epoch 34/50] [Batch 19/20] [D loss: 1.395943, acc: 50%] [G loss: 0.582599]
[Epoch 35/50] [Batch 19/20] [D loss: 1.394045, acc: 52%] [G loss: 0.716685]
[Epoch 36/50] [Batch 19/20] [D loss: 1.391289, acc: 51%] [G loss: 0.747493]
[Epoch 37/50] [Batch 19/20] [D loss: 1.369082, acc: 50%] [G loss: 0.719075]
[Epoch 38/50] [Batch 19/20] [D loss: 1.401712, acc: 53%] [G loss: 0.645679]
[Epoch 39/50] [Batch 19/20] [D loss: 1.279735, acc: 57%] [G loss: 0.710965]
[Epoch 40/50] [Batch 19/20] [D loss: 1.363157, acc: 56%] [G loss: 0.589386]
[Epoch 41/50] [Batch 19/20] [D loss: 1.334075, acc: 53%] [G loss: 0.774654]
[Epoch 42/50] [Batch 19/20] [D loss: 1.358592, acc: 51%] [G loss: 0.726460]
[Epoch 43/50] [Batch 19/20] [D loss: 1.389814, acc: 50%] [G loss: 0.703020]
[Epoch 44/50] [Batch 19/20] [D loss: 1.363462, acc: 53%] [G loss: 0.691942]
[Epoch 45/50] [Batch 19/20] [D loss: 1.362092, acc: 55%] [G loss: 0.727146]
[Epoch 46/50] [Batch 19/20] [D loss: 1.360469, acc: 53%] [G loss: 0.696875]
[Epoch 47/50] [Batch 19/20] [D loss: 1.385563, acc: 52%] [G loss: 0.661834]
[Epoch 48/50] [Batch 19/20] [D loss: 1.376729, acc: 50%] [G loss: 0.753325]
[Epoch 49/50] [Batch 19/20] [D loss: 1.370506, acc: 51%] [G loss: 0.687326]
总结
- 从框架图上看,ACGAN就是由CGAN和SGAN结合而来
- 因此结合的代码也可以成功运行
- 所以,ACGAN的输入为随机噪声z+条件信息C,而最终输出为真(真1、真2…) 或假也就是SGAN中的分类器功能
相关文章:
第G8周:ACGAN任务
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 本周任务: 根据GAN、CGAN、SGAN及它们的框架图,写出ACGAN代码。 框架图 从图中可以看到,ACGAN的前半部分类似于CGAN&#…...

nvm拉取安装node包时报错的解决办法
问题一:用nvm安装某个版本node包时,node正确安装了,但是对应的npm无法安装 原因:原系统中node.js没有卸载干净, 解决办法:先把原系统中node.js卸载干净。再安装nvm和node包 问题二:nvm无法拉取…...

PyTorch 和 TensorFlow
PyTorch 和 TensorFlow 是目前最流行的两个深度学习框架。它们各自有不同的特点和优势,适合不同的使用场景。以下是对这两个框架的详细比较和介绍。 1. PyTorch 简介 PyTorch 是由 Facebook AI Research (FAIR) 开发的开源深度学习框架,以其易用性和灵…...

数据库视图和索引
参考链接: 数据库的视图和索引的概念和区别_索引和视图的区别-CSDN博客 MySQL 数据库--索引(理论详解及实例演示)_数据库索引-CSDN博客 1.视图 视图是从一个或多个表中导出来的表,是一种不是一种真正存在的概念。这样…...

哈希表的底层实现(1)---C++版
目录 哈希表的基本原理 哈希表的优点 哈希表的缺点 应用场景 闭散列法 开散列法 开放定值法Open Addressing——线性探测的模拟实现 超大重点部分评析 链地址法Separate Chaining——哈希桶的模拟实现 哈希表(Hash Table)是一种数据结构&#x…...

如何使用PTK一键安装opengaussdb 5.0
1、关于PTK工具 MogDB数据库是云和恩墨基于openGauss开源数据库打造,安稳易用的企业级关系型数据库。 PTK是云和恩墨出品的一款工具,帮助用户更便捷地部署管理MogDB数据库。 1.1 使用场景 开发人员快速启动多个本地 MogDB 环境用户通过 PTK 快速安装…...

跟李沐学AI:长短期记忆网络LSTM
输入们、遗忘门和输出门 LSTM引入输入门、忘记门和输出门 输入门计算公式为:。 遗忘门计算公式为:。 输出门计算公式为:。 它们由三个具有sigmoid激活函数的全连接层处理, 以计算输入门、遗忘门和输出门的值。 因此,…...

【BIM模型数据】BIM模型的数据如何存储,BIM大模型数据云端存储,需要考虑哪些因素,BIM模型数据存储和获取
【BIM模型数据】BIM模型的数据如何存储,BIM大模型数据云端存储,需要考虑哪些因素,BIM模型数据存储和获取 BIM文件的结构化数据和非结构化数据的存储方式,需要根据数据的特性和使用需求来选择。以下是一些推荐的存储策略࿱…...

【LLM大模型】大模型架构:layer\_normalization
2.layer_normalization 1.Normalization 1.1 Batch Norm 为什么要进行BN呢? 在深度神经网络训练的过程中,通常以输入网络的每一个mini-batch进行训练,这样每个batch具有不同的分布,使模型训练起来特别困难。Internal Covariat…...

PON光模块的独特类型和特性
在当前互联网需求快速增长的背景下,PON光模块已成为实现光纤网络高速数据传输的重要组成部分。从住宅宽带到各种企业应用程序解决方案,PON光模块始终致力于实现高质量的数据传输与无缝通信。了解PON光模块的类型和特性对于深入理解现代网络基础设施至关重…...
架构与业务的一致性应用:实现企业战略目标和合规管理的全面指南
在当今快速变化的数字经济中,信息架构已成为企业实现其业务目标、优化运营效率和确保数据安全的关键工具。 一个成功的信息架构不仅要与企业的战略目标紧密对齐,还必须遵循日益严格的合规性要求,以保护敏感数据并满足法规规定。《信息架构&a…...

时尚穿搭想换就换,各种风格一键完美搭配!亲测在线虚拟试衣换装平台效果超赞!
随着科技的发展,时尚领域也迎来了新的革命。传统的试衣方式逐渐被现代科技所取代,虚拟试衣间的出现使得用户可以在舒适的家中轻松体验不同的服装风格。 先前给大家也介绍过一些虚拟试衣的技术,例如AnyFit或者OutfitAnyone等,今天…...
)
【C++】C++ 标准库string类介绍(超详细解析,小白必看系列)
C 标准库中的 std::string 类是一个非常强大的工具,用于处理和操作字符串。它属于 <string> 头文件,并提供了一套丰富的功能和方法。以下是 std::string 类的一些主要特性和常用操作: 1 string简介 字符串是表示字符序列的类 标准的字…...

若依RuoYi项目环境搭建教程(RuoYi-Vue + RuoYi-Vue3版本)
文章目录 一、开发脚手架选择二、RuoYi框架1、介绍2、版本发展3、为什么选择若依4、优缺点5、项目内置功能 三、后端项目部署1、拉取源码2、环境要求3、Maven构建4、MySQL相关(1)导入SQL脚本(2)配置信息 5、Redis相关(…...

Java 后端接口入参 - 联合前端VUE 使用AES完成入参出参加密解密
加密效果: 解密后的数据就是正常数据: 后端:使用的是spring-cloud框架,在gateway模块进行操作 <dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30…...
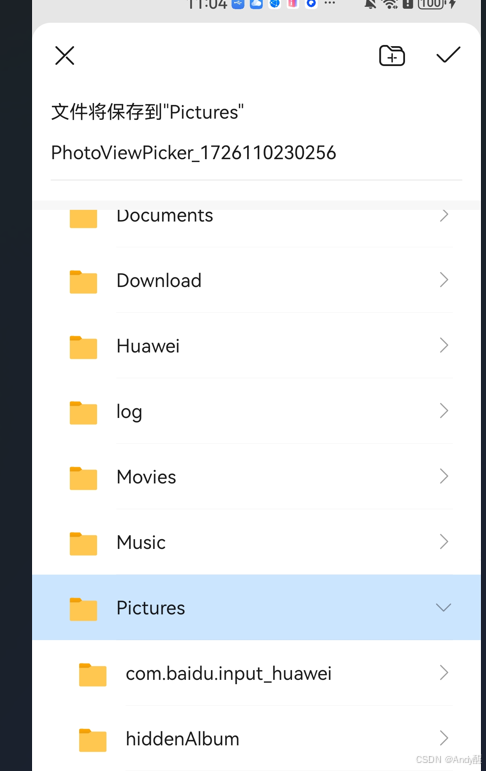
HarmonyOS开发之使用PhotoViewPicker(图库选择器)保存图片
一:效果图 二:添加依赖 import fs from ohos.file.fs;//文件管理 import picker from ohos.file.picker//选择器 三:下载,保存图片的实现 // 下载图片imgUrldownloadAndSaveImage(imgUrl: string) {http.createHttp().request(…...

跨境独立站支付收款常见问题排雷篇1.0丨出海笔记
最近小伙伴们在社群讨论挺多关于独立站支付问题的,鉴于不少朋友刚接触独立站,我整理了一些独立站支付相关的问题和解决方案,供大家参考,百度网上一堆媒体的那些软文大家就别看了,都是软广或者抄来抄去,让大…...

uni-app实现web-view和App之间的相互通信
双向实时 如果app端部署成网站,则web-view就是iframe,使用也可以双向通讯 https://uniapp.dcloud.net.cn/component/web-view.html APP端代码 index.vue: <template><web-viewid"m-webview":fullscreen"true":src"…...

HTB-Vaccine(suid提权、sqlmap、john2zip)
前言 各位师傅大家好,我是qmx_07,今天来为大家讲解Vaccine靶机 渗透过程 信息搜集 服务器开放了 21FTP服务、22SSH服务、80HTTP服务 通过匿名登录FTP服务器 通过匿名登录到服务器,发现backup.zip文件,可能存在账号密码 发现b…...

【达梦数据库】异构数据库迁移到达梦
目录 1、迁移准备2、正式迁移3、问题处理3.1、return附近出现错误3.1.1、排查过程3.1.2、问题原因3.1.2、解决方法 3.2、对象[XXX]处于无效状态-类型13.2.1、排查过程3.2.2、问题原因3.2.3、解决方法 3.3、对象[XXX]处于无效状态-类型23.3.1、排查过程3.3.2、问题原因3.3.3、解…...
从屏幕取词到智能翻译:CuteTranslation如何重塑Linux用户的跨语言工作流
从屏幕取词到智能翻译:CuteTranslation如何重塑Linux用户的跨语言工作流 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 在Linux生态系统中,多语言处理一直是个技术痛点—…...
的底层技术架构)
深度扒一扒GEO(生成式引擎优化)的底层技术架构
Gartner预测2026年传统搜索流量将下降25%,而国内生成式AI用户已破5亿。 当你的潜在客户都在问豆包、Kimi或DeepSeek“哪个牌子好”时,你的官网排名第一还有用吗?没用。因为AI直接给了答案,用户根本没点进来。 这就是GEOÿ…...

2026年阿里云OpenClaw/Hermes Agent配置Token Plan集成步骤解析
2026年阿里云OpenClaw/Hermes Agent配置Token Plan集成步骤解析。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

别再只盯着业务代码了!SpringBoot应用层安全之Tomcat连接管理实战
SpringBoot应用层安全实战:Tomcat连接管理的三驾马车 当我们在讨论SpringBoot应用安全时,业务代码的漏洞修复往往占据了大部分注意力。然而,真正的安全防线远不止于此——应用层基础设施的配置与优化同样至关重要。想象一下,你的应…...

RVC-WebUI终极指南:5步掌握AI语音克隆与声音转换技术
RVC-WebUI终极指南:5步掌握AI语音克隆与声音转换技术 【免费下载链接】rvc-webui liujing04/Retrieval-based-Voice-Conversion-WebUI reconstruction project 项目地址: https://gitcode.com/gh_mirrors/rv/rvc-webui RVC-WebUI是一个基于检索式语音转换技术…...

北京房山区浇筑阁楼测评:天顺诚达工艺佳但价格略高,适合这类
为了避免违反规则,以下内容去除了联系方式等违规信息。随着对居住空间利用需求的增加,在北京房山区浇筑阁楼成为不少人的选择。本次测评旨在为对北京房山区浇筑阁楼服务感兴趣的人群,客观呈现相关服务的情况。参与本次测评的是北京天顺诚达建…...

如何零风险升级SillyTavern:保护角色数据完整的终极指南
如何零风险升级SillyTavern:保护角色数据完整的终极指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为SillyTavern版本更新而提心吊胆吗?担心升级过程中珍贵…...

CLI-Anything与MCP服务器:打造强大后端的实战教程
CLI-Anything与MCP服务器:打造强大后端的实战教程 【免费下载链接】CLI-Anything "CLI-Anything: Making ALL Software Agent-Native" -- CLI-Hub: https://clianything.cc/ 项目地址: https://gitcode.com/GitHub_Trending/cl/CLI-Anything CLI-A…...

从 SAP Easy Access Menu 到 FLP 一体化入口:重新理解经典事务在 SAP Fiori 中的价值
在很多企业的数字化项目里,SAP Fiori 往往被理解为一套全新的体验层,而 SAP GUI 则被视为必须逐步替换掉的传统界面。这个判断只说对了一半。真正成熟的 Fiori 落地,不是把旧世界一刀切掉,而是让新旧能力在同一个入口里顺滑协作。SAP Easy Access Menu 的意义,恰恰就在这里…...
从NeoPixel到CircuitPython:打造智能LED眼镜的完整硬件与软件实践
1. 项目概述 如果你对可穿戴电子设备、酷炫的LED光效以及用代码创造物理交互感兴趣,那么这个项目绝对能让你兴奋起来。今天要分享的,是如何亲手制作一副灵感来源于电子音乐人REZZ标志性风格的NeoPixel LED眼镜。这不仅仅是一个简单的焊接和组装教程&…...