08-图7 公路村村通(C)
很明显聪明的同学已经发现,这是一个稠密图,所以用邻接矩阵。可以很好的表达,比邻接表有优势,所以,采用邻接矩阵破题,
当然也可以用邻接表,仔细观察我的AC,会发现其实都一样,只是存储形式不一样罢了。
很明显,这是一个最小生成树问题,也可以认为贪心算法,接下来我将分别展示两个实现路径,第一个 prim 算法, 第二个kruskal算法。
第一个 prim 算法,哈哈,原来是我最开始搞错方向了,并未理解prim算法,这下也是让我印象深刻了。
测试点 提示 内存(KB) 用时(ms) 结果 得分 0 sample换数字,各种回路判断 192 4 答案正确
15 / 15 1 M<N-1,不可能有生成树 192 4 答案正确
2 / 2 2 M达到N-1,但是图不连通 192 4 答案正确
2 / 2 3 最大N和M,连通 4284 8 答案正确
5 / 5 4 最大N和M,不连通 4160 7 答案正确
6 / 6
第二个kruskal算法,实际应用很简单,果然馒头嚼碎也不见得好吸收,一点点啃食的过程,也是非常锻炼计算思维。
按道理来说,应该是kruskal算法快,但是也就一个O(N^2) 与O(NlogN),可以看出来在1000个数据点(最大N(1000),M(3000))下,区别还是有的。
测试点 提示 内存(KB) 用时(ms) 结果 得分 0 sample换数字,各种回路判断 188 4 答案正确
15 / 15 1 M<N-1,不可能有生成树 188 4 答案正确
2 / 2 2 M达到N-1,但是图不连通 188 4 答案正确
2 / 2 3 最大N和M,连通 4156 7 答案正确
5 / 5 4 最大N和M,不连通 4160 6 答案正确
6 / 6
现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。
输入格式:
输入数据包括城镇数目正整数 n(≤1000)和候选道路数目 m(≤3n);随后的 m 行对应 m 条道路,每行给出 3 个正整数,分别是该条道路直接连通的两个城镇的编号以及该道路改建的预算成本。为简单起见,城镇从 1 到 n 编号。
输出格式:
输出村村通需要的最低成本。如果输入数据不足以保证畅通,则输出 −1,表示需要建设更多公路。
输入样例:
6 15 1 2 5 1 3 3 1 4 7 1 5 4 1 6 2 2 3 4 2 4 6 2 5 2 2 6 6 3 4 6 3 5 1 3 6 1 4 5 10 4 6 8 5 6 3输出样例:
12
第一个 prim 算法,我的AC:
采用了,最小堆 + prim,.
#include<stdio.h> #include<stdlib.h> #include<stdbool.h>#define MaxVertex 1001 #define INFITY 100001 #define MinValue -1typedef struct ENode *Edge; struct ENode{int V1, V2;int Weight; };typedef struct GNode *MGraph; struct GNode{int Nv;int Ne;int G[MaxVertex][MaxVertex]; };typedef struct Sign_Dist_VNode DistNode; struct Sign_Dist_VNode{int V;int Weight; };typedef struct Heap *MinHeap; struct Heap{DistNode *Data;int Size; };MGraph Build_Graph(); MGraph Init_Graph(); void Insert_Graph(MGraph M, Edge E); MinHeap Init_Heap(int N); void Creat_Heap(MGraph M, MinHeap H, int Vertex, bool* Visited, bool *collected); void Push_Heap(MinHeap H, int index, int Weight, bool *collected); void Counterpoise_Heap(MinHeap H, int index, int V, int Weight); bool IsEmpty_Heap(MinHeap H); DistNode Pop_Heap(MinHeap H, bool *collected); void Prim(MGraph M, MinHeap H, bool* Visited, int *dist); void Print_Result(int N, int *dist, bool* Visited);int main() {MGraph M;MinHeap H;int *dist;bool *Visited;M = Build_Graph();H = Init_Heap(M ->Nv);dist = (int*)malloc(sizeof(int) * M ->Nv);Visited = (bool*)calloc(M ->Nv, sizeof(bool));Prim(M, H, Visited, dist);Print_Result(M ->Nv, dist, Visited);return 0; }void Prim(MGraph M, MinHeap H, bool* Visited, int *dist) {int j;bool *collected;collected = (bool*)calloc(M ->Nv, sizeof(bool));for(j = 1; j < M ->Nv; j++){dist[j] = M ->G[0][j];}DistNode Data;Creat_Heap(M, H, 0, Visited, collected);Visited[0] = true;dist[0] = 0;while(Data = Pop_Heap(H, collected), Data.Weight > 0){Visited[Data.V] = true;for(j = 0; j < M ->Nv; j++){if(!Visited[j] && M ->G[Data.V][j] < INFITY && (dist[j] > M ->G[Data.V][j])){dist[j] = M ->G[Data.V][j];Push_Heap(H, j, dist[j], collected);//有人会问,这样不会产生数据重复吗,注意Visited,遵循一次访问原则。}}} } void Print_Result(int N, int *dist, bool* Visited) {int i, cost = 0;for(i = 0; i < N; i++){if(!Visited[i]){printf("-1\n");return ;}cost += dist[i];}printf("%d\n", cost);return ; } MGraph Build_Graph() {MGraph M;Edge E;M = Init_Graph();E = (Edge)malloc(sizeof(struct ENode));for(int i = 0; i < M ->Ne; i++){scanf("%d %d %d", &E ->V1, &E ->V2, &E ->Weight);E ->V1 --; E ->V2 --;Insert_Graph(M, E);}return M; } MGraph Init_Graph() {MGraph M;M = (MGraph)malloc(sizeof(struct GNode));scanf("%d %d", &M ->Nv, &M ->Ne);for(int i = 0; i < (M ->Nv); i++){for(int j = 0; j < (M ->Nv); j++){M ->G[i][j] = INFITY;}}return M; } void Insert_Graph(MGraph M, Edge E) {M ->G[E ->V1][E ->V2] = E ->Weight;M ->G[E ->V2][E ->V1] = E ->Weight; }void Creat_Heap(MGraph M, MinHeap H, int Vertex, bool* Visited, bool *collected) {for(int j = 0; j < M ->Nv; j++){if(M ->G[Vertex][j] < INFITY && !Visited[j]){Push_Heap(H, j, M ->G[Vertex][j], collected);}} } MinHeap Init_Heap(int N) {MinHeap H;H = (MinHeap)malloc(sizeof(struct Heap));H ->Data = (DistNode*)malloc(sizeof(DistNode) * (N + 1));H ->Data[0].Weight = MinValue;H ->Size = 0;return H; } void Push_Heap(MinHeap H, int index, int Weight, bool *collected) {int i;if(collected[index]){for(i = 1; i <= H ->Size; i++){if(index == H ->Data[i].V){H ->Data[i].Weight = Weight;Counterpoise_Heap(H, index, i, Weight);return ;}}}else{i = ++(H ->Size);Counterpoise_Heap(H, index, i, Weight);collected[index] = true;return ;} } void Counterpoise_Heap(MinHeap H, int index, int i, int Weight) {for(; Weight < H ->Data[i/2].Weight; i /= 2){H ->Data[i].Weight = H ->Data[i/2].Weight;H ->Data[i].V = H ->Data[i/2].V;}H ->Data[i].Weight = Weight;H ->Data[i].V = index;return ; } bool IsEmpty_Heap(MinHeap H) {return (H ->Size == 0); } DistNode Pop_Heap(MinHeap H, bool *collected) {DistNode Min, Temp;int Parent, Child;if(IsEmpty_Heap(H)){return H ->Data[0];}Min = H ->Data[1];Temp = H ->Data[H ->Size --];collected[Min.V] = false;for(Parent = 1; Parent *2 < H ->Size; Parent = Child){Child = Parent * 2;if(H ->Data[Child].Weight > H ->Data[Child + 1].Weight){Child++;}if(Temp.Weight <= H ->Data[Child].Weight){break;}else{H ->Data[Parent].Weight = H ->Data[Child].Weight;H ->Data[Parent].V = H ->Data[Child].V;}}H ->Data[Parent].Weight = Temp.Weight;H ->Data[Parent].V = Temp.V;return Min; }
第二个kruskal算法, 最小堆+并查树+Kruskal。
#include<stdio.h> #include<stdlib.h> #include<stdbool.h>#define MaxVertex 1001 #define INFITY 100001 #define MinValue -1typedef struct ENode Edge; struct ENode{int V1, V2;int Weight; };typedef struct GNode *MGraph; struct GNode{int Nv;int Ne;int G[MaxVertex][MaxVertex]; };typedef struct Heap *MinHeap; struct Heap{Edge *Data;int Size; };//便于并查树算法理解,有心吧。 typedef struct UnionFind *UF; struct UnionFind{int Parent; };MGraph Build_Graph(); MGraph Init_Graph(); void Insert_Graph(MGraph M, Edge E); MinHeap Init_Heap(int N); MinHeap Creat_Heap(MGraph M); void Push_Heap(MinHeap H, int V1, int V2, int Weight); bool IsEmpty_Heap(MinHeap H); Edge Pop_Heap(MinHeap H); UF Init_UnionFind(int VertexNum); void Union_Value(UF T, int V1, int V2); int Find_Root(UF T, int V); bool Check_Loop(UF T, int V1, int V2); void Kruskal(MGraph M, MinHeap H, UF T, bool *Visited, int *dist);int main() {MGraph M;MinHeap H;UF T;int *dist;bool *Visited;M = Build_Graph();H = Creat_Heap(M); T = Init_UnionFind(M ->Nv);dist = (int*)malloc(sizeof(int) * M ->Nv);Visited = (bool*)calloc(M ->Nv, sizeof(bool));Kruskal(M, H, T, Visited, dist);return 0; } void Kruskal(MGraph M, MinHeap H, UF T, bool *Visited, int *dist) {Edge Data;int i = 1;int cost = 0;while(Data = Pop_Heap(H), (Data.Weight > 0 && i < M ->Nv)){if(!Check_Loop(T, Data.V1, Data.V2)){Union_Value(T, Data.V1, Data.V2);cost += Data.Weight;i++;}}if(i != M ->Nv){printf("-1\n");}else{printf("%d\n", cost);} }MGraph Build_Graph() {MGraph M;Edge E;M = Init_Graph();for(int i = 0; i < M ->Ne; i++){scanf("%d %d %d", &E.V1, &E.V2, &E.Weight);E.V1 --; E.V2 --;Insert_Graph(M, E);}return M; } MGraph Init_Graph() {MGraph M;M = (MGraph)malloc(sizeof(struct GNode));scanf("%d %d", &M ->Nv, &M ->Ne);for(int i = 0; i < (M ->Nv); i++){for(int j = 0; j < (M ->Nv); j++){M ->G[i][j] = INFITY;}}return M; } void Insert_Graph(MGraph M, Edge E) {M ->G[E.V1][E.V2] = E.Weight;M ->G[E.V2][E.V1] = E.Weight; }MinHeap Creat_Heap(MGraph M) {MinHeap H;H = Init_Heap(M ->Ne);for(int i = 0; i < M ->Nv; i++)for(int j = i + 1; j < M ->Nv; j++){if(M ->G[i][j] < INFITY){Push_Heap(H, i, j, M ->G[i][j]);}}return H; } MinHeap Init_Heap(int N) {MinHeap H;H = (MinHeap)malloc(sizeof(struct Heap));H ->Data = (Edge*)malloc(sizeof(Edge) * (N + 1));H ->Data[0].Weight = MinValue;H ->Size = 0;return H; } void Push_Heap(MinHeap H, int V1, int V2, int Weight) {int i;i = ++(H ->Size);for(; Weight < H ->Data[i/2].Weight; i /= 2){H ->Data[i].Weight = H ->Data[i/2].Weight;H ->Data[i].V1 = H ->Data[i/2].V1;H ->Data[i].V2 = H ->Data[i/2].V2;}H ->Data[i].Weight = Weight;H ->Data[i].V1 = V1;H ->Data[i].V2 = V2;return ; }bool IsEmpty_Heap(MinHeap H) {return (H ->Size == 0); } Edge Pop_Heap(MinHeap H) {Edge Min, Temp;int Parent, Child;if(IsEmpty_Heap(H)){return H ->Data[0];}Min = H ->Data[1];Temp = H ->Data[H ->Size --];for(Parent = 1; Parent *2 < H ->Size; Parent = Child){Child = Parent * 2;if(H ->Data[Child].Weight > H ->Data[Child + 1].Weight){Child++;}if(Temp.Weight <= H ->Data[Child].Weight){break;}else{H ->Data[Parent].Weight = H ->Data[Child].Weight;H ->Data[Parent].V1 = H ->Data[Child].V1;H ->Data[Parent].V2 = H ->Data[Child].V2;}}H ->Data[Parent].Weight = Temp.Weight;H ->Data[Parent].V1 = Temp.V1;H ->Data[Parent].V2 = Temp.V2;return Min; } UF Init_UnionFind(int VertexNum) {UF T;T = (UF)malloc(sizeof(struct UnionFind) * (VertexNum + 1));for(int i = 0; i < VertexNum; i++){T[i].Parent = -1;}return T; } void Union_Value(UF T, int V1, int V2) {int Root1, Root2;Root1 = Find_Root(T, V1);Root2 = Find_Root(T, V2);if(T[Root1].Parent < T[Root2].Parent){T[Root1].Parent += T[Root2].Parent;T[Root2].Parent = Root1;}else{T[Root2].Parent += T[Root1].Parent;T[Root1].Parent = Root2;} } int Find_Root(UF T, int V) {if(T[V].Parent < 0){return V;}return Find_Root(T, T[V].Parent); } bool Check_Loop(UF T, int V1, int V2) {if(Find_Root(T, V1) == Find_Root(T, V2)){return true;}else{return false;} }
2024.9.6-错误借鉴,哈哈,我竟然,好吧,就是没有好好听课,不是最短路,而是最小边,之前的样例我感觉只是运气吧。
测试点 提示 内存(KB) 用时(ms) 结果 得分 0 sample换数字,各种回路判断 184 4 答案正确
15 / 15 1 M<N-1,不可能有生成树 188 4 答案正确
2 / 2 2 M达到N-1,但是图不连通 316 4 答案正确
2 / 2 3 最大N和M,连通 4156 8 答案错误
0 / 5 4 最大N和M,不连通 4156 7 答案正确
6 / 6 void Prim(MGraph M, MinHeap H, bool* Visited, int *dist) {int j;bool *collected;collected = (bool*)calloc(M ->Nv, sizeof(bool));for(j = 0; j < M ->Nv; j++){dist[j] = INFITY;}DistNode Data;Creat_Heap(M, H, 0, Visited, collected);Visited[0] = true;dist[0] = 0;while(Data = Pop_Heap(H, collected), Data.Weight > 0){if(!Visited[Data.V] && dist[Data.V] > Data.Weight){dist[Data.V] = Data.Weight;}Visited[Data.V] = true;for(j = 0; j < M ->Nv; j++){if(!Visited[j] && M ->G[Data.V][j] < INFITY && (dist[j] > dist[Data.V] + M ->G[Data.V][j])){dist[j] = M ->G[Data.V][j];Push_Heap(H, j, dist[j], collected);//有人会问,这样不会产生数据重复吗,注意Visited,遵循一次访问原则。}}} }
相关文章:
)
08-图7 公路村村通(C)
很明显聪明的同学已经发现,这是一个稠密图,所以用邻接矩阵。可以很好的表达,比邻接表有优势,所以,采用邻接矩阵破题, 当然也可以用邻接表,仔细观察我的AC,会发现其实都一样,只是存储…...
、wait()、join()、yield()的区别)
Java-sleep()、wait()、join()、yield()的区别
关于线程,作为八股文面试中必问点,我们需要充分了解sleep()、wait()、join()以及yield()的区别。在正式开始之前先让我们了解两个概念:锁池和等待池 1.锁池 所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中…...

Linux命令的补全和自动完成完全开启
前言 在安装好RockyLinux8.8后,输入dn后,按下“TAB”能自动提示,但在输入dnf make后,按下“TAB”不能实现自动补全,如果要使Linux的Bash支持完整的自动提示和补全功能,还需要执行一些其它操作。 内容 1、…...

Deep Active Contours for Real-time 6-DoF Object Tracking
这篇论文解决了从RGB视频进行实时6自由度(6-DoF)物体跟踪的问题。此前的基于优化的方法通过对齐投影模型与图像来优化物体姿态,这种方法依赖于手工设计的特征,因此容易陷入次优解。最近的基于学习的方法使用神经网络来预测姿态&am…...

IDEA安装教程配置java环境(超详细)
引言 IntelliJ IDEA 是一款功能强大的集成开发环境(IDE),广泛用于 Java 开发,但也支持多种编程语言,如 Kotlin、Groovy 和 Scala。本文将为你提供一步一步的指南,帮助你在 Windows 系统上顺利安装 Intelli…...

Excel文档的读取(1)
熟悉使用Excel的同学应该都知道,在单个Excel表格里想要分商品计算总销售额,使用数据透视表也可以非常快速方便的获得结果。但当有非常大量的Excel文件需要处理时,每一个Excel文件单独去做数据透视也会消耗大量的时间。就算使用Power Query这样…...

Linux:体系结构和操作系统管理
目录 一、冯诺依曼体系结构 1.问题1 2.问题2 二、操作系统管理 一、冯诺依曼体系结构 本章将会谈论一下对冯诺依曼计算机体系结构的理解。 在2024年,几乎所有的计算机,都遵守冯诺依曼体系结构。 冯诺依曼体系结构是应用在硬件层面的,而硬…...

c++ install boost lib
同步系统上的软件包列表 sudo apt-update 整个库安装: sudo apt-get install libboost-all-dev 安装部分库: sudo apt-get install libboost-thread-dev sudo apt-get install libboost-filesystem-dev 链接时加上: -lboost_filesystem -lboost_system 例如: g -Wall -o bo…...

文件加密最简单的方法有哪些?十个电脑文件加密方法【超详细】
在当今数字化和信息化的时代,数据已成为企业最重要的资产之一。内部数据外泄不仅可能导致商业秘密的丧失,还可能对企业的声誉和财务健康造成严重影响。为了有效防止内部数据外泄,企业需要实施综合的防泄密解决方案。以下是十大最佳防泄密解决…...

IPv6地址的表示方法
IPv6地址总长度为128比特,通常分为8组,每组为4个十六进制数的形式,每组十六进制数间用冒号分隔。 例如:2409:8745:039a:c700:0000:0000:0162,这是IPv6地址的首选格式。 为了书写方便,IPv6还提供了压缩格式…...
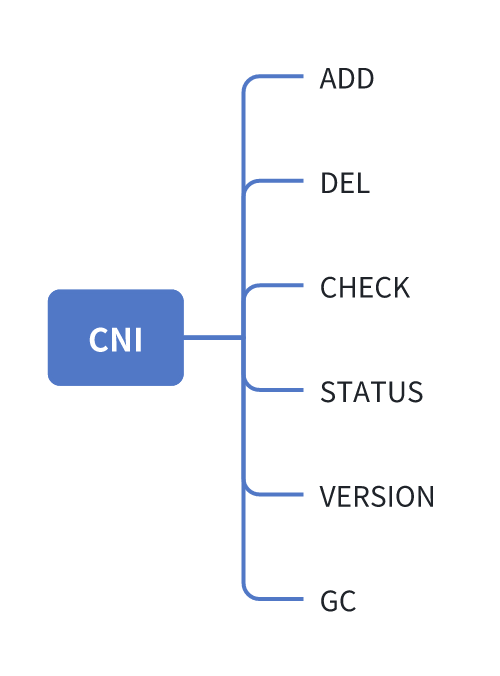
Kubernetes 之 kubelet 与 CRI、CNI 的交互过程
序言 当一个新的 Pod 被提交创建之后,Kubelet、CRI、CNI 这三个组件之间进行了哪些交互? Kubelet -> CRI -> CNI 如上图所示: Kubelet 从 kube-api-server 处监听到有新的 pod 被调度到了自己的节点且需要创建。Kubelet 创建 sandbo…...

【python】OpenCV—Age and Gender Classification
文章目录 1、任务描述2、网络结构2.1 人脸检测2.2 性别分类2.3 年龄分类 3、代码实现4、结果展示5、参考 1、任务描述 性别分类和年龄分类预测 2、网络结构 2.1 人脸检测 输出最高的 200 个 RoI,每个 RoI 7 个值,(xx,xx&#x…...

python安装换源
安装 python 使用演示的是python 3.8.5 安装完成后,如下操作打开命令行:同时按 “WindowsR” > 输入 “cmd” -> 点击确定 python换源 临时换源: #清华源 pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple # 阿里…...

JavaScript练手小技巧:利用鼠标滚轮控制图片轮播
近日,在浏览网站的时候,发现了一个有意思的效果:一个图片轮播,通过上下滚动鼠标滚轮控制图片的上下切换。 于是就有了自己做一个的想法,顺带复习下鼠标滚轮事件。 鼠标滚轮事件,参考这篇文章:…...

搭建Eureka高可用集群 - day03
全部代码发出来了 搭建服务提供者 步骤: 1.创建项目,引入依赖 2.添加Eureka相关配置 3.添加EnableEurekaClient注解 4.测试运行 步骤1:创建项目,引入依赖 使用Spring Initializr方式创建一个名称为eureka-provider的Sprin…...

并行程序设计基础——并行I/O(2)
目录 一、显式偏移的并行文件读写 1、阻塞方式 1.1 MPI_FILE_READ_AT 1.2 MPI_FILE_WRITE_AT 1.3 MPI_FILE_READ_AT_ALL 1.4 MPI_FILE_WRITE_AT_ALL 2、非阻塞方式 2.1 MPI_FILE_IREAD_AT 2.2 MPI_FILE_IWRITE_AT 3、两步非阻塞组调用 3.1 MPI_FILE_READ_AT_ALL_BEG…...

Java三种创建多线程的方法
线程是什么: 进程是程序的一次动态执行的过程,线程是进程中执行运算最小单位,一个进程在其执行过程中可以产生多个线程,而线程必须在某个进程内执行。 如果在一个进程中同时运行了多个线程(必须包含一个主线程&#…...

828华为云征文 | 云上私人数据管家,jMalCloud个人网盘在华为云Flexus的Docker化部署实践
华为云服务器Flexus X实例介绍 华为云Flexus云服务器X实例,是由国家科技进步奖获得者、华为公司Fellow、华为云首席架构师顾炯炯牵头研发。它基于擎天QingTian架构、瑶光云脑、盘古大模型等根技术创新,是业界首款应用驱动的柔性算力云服务器,…...

C# 开源教程带你轻松掌握数据结构与算法
目录 前言 项目介绍 项目特点 项目展示 1、内容导图 2、部分目录 3、源码示例 项目地址 最后 前言 在项目开发过程中,理解数据结构和算法如同掌握盖房子的秘诀。算法不仅能帮助我们编写高效、优质的代码,还能解决项目中遇到的各种难题。 给大家…...

由一个 SwiftData “诡异”运行时崩溃而引发的钩深索隐(五)
概述 在 WWDC 24 中,苹果推出了数据库框架 SwiftData 2.0 版本。其新加入的历史记录追踪(History Trace)机制着实让秃头码农们“如痴如醉”了一番。 我们在之前的博文中已经介绍了 History Trace 是如何处理数据新增操作的。而在这里,我们将再接再厉来完成数据删除时的全盘…...

从虚拟机到私有云:手把手教你用VirtualBox+CentOS 7搭建个人OpenStack学习环境
从虚拟机到私有云:手把手教你用VirtualBoxCentOS 7搭建个人OpenStack学习环境 在个人电脑上搭建OpenStack环境听起来像是企业级IT工程师的专属领域,但事实上,借助VirtualBox这样的免费虚拟化工具和CentOS 7的稳定性,任何人都可以在…...

JetBrains IDE试用期重置终极指南:如何免费延长30天评估期
JetBrains IDE试用期重置终极指南:如何免费延长30天评估期 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一款专业的开源解…...
)
Win10显示器关闭就锁屏?一个注册表键值让你告别烦人锁屏(附详细路径)
Win10显示器关闭后自动锁屏的终极解决方案:注册表深度优化指南 1. 问题背景与用户痛点 每当我们在Windows 10系统中设置显示器自动关闭以节省能源时,常常会遇到一个令人困扰的现象:显示器关闭后不久,系统就会自动进入锁屏状态。这…...

【免费下载】 解锁潜能,尽在掌握:深入探索VMware17 Unlocker工具
解锁潜能,尽在掌握:深入探索VMware17 Unlocker工具 【下载地址】VMware17Unlocker解锁工具附用法 本仓库提供了一个用于解锁VMware17的工具——VMware17 Unlocker。该工具可以帮助用户解锁VMware17中的某些限制,使其能够更好地使用虚拟机功能…...

ceshi1
进入2026年,企业数字化转型已从“流程数字化”全面转向“认知自动化”。 据最新行业数据显示,企业内部超过85%的数据以PDF、图片、音视频、扫描件等非结构化形式存在。 这些数据曾被视为“沉默的资产”,因为传统OCR或规则引擎难以处理其复杂的…...

长期使用Taotoken聚合API在服务稳定性方面的体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API在服务稳定性方面的体验分享 作为一家长期依赖大模型能力进行产品开发的团队,我们在过去数月里…...

实战心得Laravel 10.x 新特性全解析:解锁 PHP 开发新境界
在 PHP 开发领域,Laravel 一直是备受瞩目的框架之一。它以其优雅的语法、强大的功能和便捷的开发体验,赢得了众多开发者的青睐。随着技术的不断发展,Laravel 也在持续更新和进化。今天,我们就来全面解析 Laravel 10.x 的新特性&am…...

YOLOv8从零部署到实战:一站式环境配置与核心功能解析
1. YOLOv8环境搭建全攻略 第一次接触YOLOv8时,我也被各种依赖项搞得头晕眼花。经过多次实践,我总结出一套最稳妥的安装方案,特别适合刚入门的新手。YOLOv8作为当前最先进的目标检测框架之一,其安装过程确实比传统CV库复杂些&#…...

Fluentd命令行化实践:fluent_cli打造轻量级实时日志处理管道
1. 项目概述:一个高效的命令行日志处理工具最近在折腾一个分布式系统的日志收集链路,发现很多现成的日志处理工具要么太重,要么配置起来太繁琐。尤其是在需要快速查询、过滤和转换不同来源的日志流时,往往需要写一堆脚本ÿ…...

Eviews面板数据回归实战:手把手教你用Hausman检验搞定固定效应与随机效应模型选择
Eviews面板数据回归实战:Hausman检验在固定与随机效应模型选择中的应用 计量经济学研究中,面板数据分析因其能同时捕捉时间和个体维度的信息而备受青睐。但面对固定效应(FE)和随机效应(RE)模型的选择,许多研究者常常陷入困惑。本文将带您深入…...