动手学习RAG:迟交互模型colbert微调实践 bge-m3
- 动手学习RAG: 向量模型
- 动手学习RAG: BGE向量模型微调实践]()
- 动手学习RAG: BCEmbedding 向量模型 微调实践]()
- BCE ranking 微调实践]()
- GTE向量与排序模型 微调实践]()
- 模型微调中的模型序列长度]()
- 相似度与温度系数
本文我们来进行ColBERT模型的实践,按惯例,还是以open-retrievals中的代码为蓝本。在RAG兴起之后,ColBERT也获得了更多的关注。ColBERT整体结构和双塔特别相似,但迟交互式也就意味着比起一般ranking模型,交互来的更晚一些。

准备环境
pip install transformers
pip install open-retrievals
准备数据
还是采用C-MTEB/T2Reranking数据。
- 每个样本有query, positive, negative。其中query和positive构成正样本对,query和negative构成负样本对

使用
由于ColBERT作为迟交互式模型,既可以像向量模型一样生成向量,也可以计算相似度。BAAI/bge-m3中的colbert模型是基于XLMRoberta训练而来,因此使用ColBERT可以直接从bge-m3中加载预训练权重。
import transformers
from retrievals import ColBERT
model_name_or_path: str = 'BAAI/bge-m3'
model = ColBERT.from_pretrained(model_name_or_path,colbert_dim=1024, use_fp16=True,loss_fn=ColbertLoss(use_inbatch_negative=True),
)model

- 生成向量的方法
sentences_1 = ["In 1974, I won the championship in Southeast Asia in my first kickboxing match", "In 1982, I defeated the heavy hitter Ryu Long."]
sentences_2 = ['A dog is chasing car.', 'A man is playing a guitar.']output_1 = model.encode(sentences_1, normalize_embeddings=True)
print(output_1.shape, output_1)output_2 = model.encode(sentences_2, normalize_embeddings=True)
print(output_2.shape, output_2)

- 计算句子对 相似度的方法
sentences = [["In 1974, I won the championship in Southeast Asia in my first kickboxing match", "In 1982, I defeated the heavy hitter Ryu Long."],["In 1974, I won the championship in Southeast Asia in my first kickboxing match", 'A man is playing a guitar.'],
]scores_list = model.compute_score(sentences)
print(scores_list)

微调
尝试了两种方法来做,一种是调包自己写代码,一种是采用open-retrievals中的代码写shell脚本。这里我们采用第一种,另外一种方法可参考文章最后番外中的微调
import transformers
from transformers import AutoTokenizer, TrainingArguments, get_cosine_schedule_with_warmup, AdamW
from retrievals import AutoModelForRanking, RerankCollator, RerankTrainDataset, RerankTrainer, ColBERT, RetrievalTrainDataset, ColBertCollator
from retrievals.losses import ColbertLoss
transformers.logging.set_verbosity_error()model_name_or_path: str = 'BAAI/bge-m3'learning_rate: float = 1e-5
batch_size: int = 2
epochs: int = 1
output_dir: str = './checkpoints'train_dataset = RetrievalTrainDataset('C-MTEB/T2Reranking', positive_key='positive', negative_key='negative', dataset_split='dev'
)tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)data_collator = ColBertCollator(tokenizer,query_max_length=64,document_max_length=128,positive_key='positive',negative_key='negative',
)
model = ColBERT.from_pretrained(model_name_or_path,colbert_dim=1024,loss_fn=ColbertLoss(use_inbatch_negative=False),
)optimizer = AdamW(model.parameters(), lr=learning_rate)
num_train_steps = int(len(train_dataset) / batch_size * epochs)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=0.05 * num_train_steps, num_training_steps=num_train_steps)training_args = TrainingArguments(learning_rate=learning_rate,per_device_train_batch_size=batch_size,num_train_epochs=epochs,output_dir = './checkpoints',remove_unused_columns=False,gradient_accumulation_steps=8,logging_steps=100,)
trainer = RerankTrainer(model=model,args=training_args,train_dataset=train_dataset,data_collator=data_collator,
)
trainer.optimizer = optimizer
trainer.scheduler = scheduler
trainer.train()model.save_pretrained(output_dir)
训练过程中会加载BAAI/bge-m3模型权重

损失函数下降

{'loss': 7.4858, 'grad_norm': 30.484981536865234, 'learning_rate': 4.076305220883534e-06, 'epoch': 0.6024096385542169}
{'loss': 1.18, 'grad_norm': 28.68316650390625, 'learning_rate': 3.072289156626506e-06, 'epoch': 1.2048192771084336}
{'loss': 1.1399, 'grad_norm': 14.203865051269531, 'learning_rate': 2.068273092369478e-06, 'epoch': 1.8072289156626506}
{'loss': 1.1261, 'grad_norm': 24.30337905883789, 'learning_rate': 1.0642570281124499e-06, 'epoch': 2.4096385542168672}
{'train_runtime': 471.8191, 'train_samples_per_second': 33.827, 'train_steps_per_second': 1.055, 'train_loss': 2.4146631079984, 'epoch': 3.0}
评测
在C-MTEB中进行评测。微调前保留10%的数据集作为测试集验证
from datasets import load_datasetdataset = load_dataset("C-MTEB/T2Reranking", split="dev")
ds = dataset.train_test_split(test_size=0.1, seed=42)ds_train = ds["train"].filter(lambda x: len(x["positive"]) > 0 and len(x["negative"]) > 0
)ds_train.to_json("t2_ranking.jsonl", force_ascii=False)
微调前的指标:

微调后的指标:

{"dataset_revision": null,"mteb_dataset_name": "CustomReranking","mteb_version": "1.1.1","test": {"evaluation_time": 221.45,"map": 0.6950128151840831,"mrr": 0.8193114944390455}
}
番外:从语言模型直接训练ColBERT
之前的例子里是从BAAI/bge-m3继续微调,这里再跑一个从hfl/chinese-roberta-wwm-ext训练一个ColBERT模型
- 注意,从头跑需要设置更大的学习率与更多的epochs
MODEL_NAME='hfl/chinese-roberta-wwm-ext'
TRAIN_DATA="/root/kaggle101/src/open-retrievals/t2/t2_ranking.jsonl"
OUTPUT_DIR="/root/kaggle101/src/open-retrievals/t2/ft_out"cd /root/open-retrievals/srctorchrun --nproc_per_node 1 \--module retrievals.pipelines.rerank \--output_dir $OUTPUT_DIR \--overwrite_output_dir \--model_name_or_path $MODEL_NAME \--tokenizer_name $MODEL_NAME \--model_type colbert \--do_train \--data_name_or_path $TRAIN_DATA \--positive_key positive \--negative_key negative \--learning_rate 5e-5 \--bf16 \--num_train_epochs 5 \--per_device_train_batch_size 32 \--dataloader_drop_last True \--query_max_length 128 \--max_length 256 \--train_group_size 4 \--unfold_each_positive false \--save_total_limit 1 \--logging_steps 100 \--use_inbatch_negative False
微调后指标
{"dataset_revision": null,"mteb_dataset_name": "CustomReranking","mteb_version": "1.1.1","test": {"evaluation_time": 75.38,"map": 0.6865308507184888,"mrr": 0.8039965986394558}
}
相关文章:
动手学习RAG:迟交互模型colbert微调实践 bge-m3
动手学习RAG: 向量模型动手学习RAG: BGE向量模型微调实践]()动手学习RAG: BCEmbedding 向量模型 微调实践]()BCE ranking 微调实践]()GTE向量与排序模型 微调实践]()模型微调中的模型序列长度]()相似度与温度系数 本文我们来进行ColBERT模型的实践,按惯例ÿ…...

springboot 整合quartz定时任务
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pom的配置1.加注解 二、使用方法1.工程图2.创建工具类 三、controller 实现 前言 提示:这里可以添加本文要记录的大概内容: 提示&a…...

erlang学习: Mnesia Erlang数据库3
Mnesia数据库删除实现和事务处理 -module(test_mnesia). -include_lib("stdlib/include/qlc.hrl").-record(shop, {item, quantity, cost}). %% API -export([insert/3, select/0, select/1, delete/1, transaction/1,start/0, do_this_once/0]). start() ->mnes…...

善于善行——贵金属回收
在当今社会,贵金属回收已成为一项日益重要的产业。随 着科技的不断进步和人们对资源可持续利用的认识逐渐提高,贵金属回收的现状也备受关注。 目前,贵金属回收市场呈现出蓬勃发展的态势。一方面,贵金属如金、银、铂、钯等在众多领…...

用CSS 方式设置 table 样式
在现代Web开发中,使用CSS来设置table的样式是一种常见且强大的方法,它能让你的表格数据既美观又易于阅读。下面我将通过一个示例来展示如何使用现代CSS技巧来美化表格。 效果图 HTML 结构 首先,我们定义一个基本的HTML表格结构:…...

Elasticsearch7.x 集群迁移文档
一、集群样例信息 集群名称:escluster-ali-test 1、源集群:(source_cluster) 节点IP节点名称节点角色是否为master节点10.200.112.149es2.gj1.china-job.cndata,master是10.200.112.151es1.gj1.china-job.cndata,master否10.200.112.153es…...

高空抛物检测算法的应用场景解析
高空抛物事件频发,对公众安全构成严重威胁。无论是居民区还是商业中心,从高层建筑中丢弃物品都可能导致人员伤亡和财产损失。传统的监控手段多以事后追溯为主,无法在事发时及时预警和干预。为应对这一难题,视觉分析技术的发展为高…...

Leetcode 无重复字符的最长子串
算法思想: 滑动窗口:通过 start 和 end 来维护一个滑动窗口,start 指向当前窗口的起点,end 是当前窗口的末尾。滑动窗口中的字符都是无重复的。哈希表 charIndexMap:用于存储每个字符及其最近一次出现的位置。更新起始…...

用命令行的方式启动.netcore webapi
用命令行的方式启动.netcore web项目 进入指定的项目文件夹,比如我发布后的代码放在下面文件夹中 在此地址栏中输入“cmd”,打开命令提示符,进入到发布代码目录 命令行启动.netcore项目的命令为: dotnet 项目启动文件.dll --urls"ht…...

Spring6详细学习笔记(IOC+AOP)
一、Spring系统架构介绍 1.1、定义 Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器(框架)。Spring官网 Spring是一款主流的Java EE 轻量级开源框架,目的是用于简化Java企业级引用的开发难度和开发周期。从简单性、可测试性和松耦…...

@RequestMapping 基于哪个库进行通信
RequestMapping 是 Spring Framework 中用于处理 HTTP 请求的注解,主要用于定义控制器方法的请求映射。它并不直接基于某个特定的通信库,而是依赖于 Spring MVC 框架的核心功能。 1. Spring MVC RequestMapping 是 Spring MVC 的一部分,Spr…...

GPIO(General Purpose Input/Output)输入/输出
GPIO最简单的功能是输出高低电平;GPIO还可以被设置为输入功能,用于读取按键等输入信号;也可以将GPIO复用成芯片上的其他外设的控制引脚。 STM32F407ZGT6有8组IO。分别为GPIOA~GPIOH,除了GPIOH只有两个IO,其余每组IO有…...
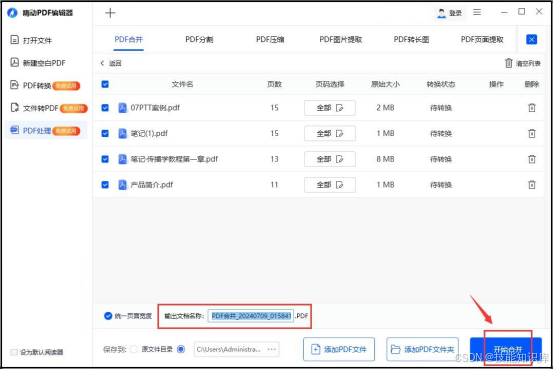
两个pdf合并成一个pdf,这些pdf合并小技巧了解下
在日常工作和学习中,我们经常会遇到需要将多个PDF文件合并成一个文件的情况。这不仅可以提高文件管理的效率,还能让信息展示更加集中和便捷。今天就来给大家分享几种非常简单便捷的PDF合并小技巧,一起来学习下吧。 方法一:WPS WP…...

Transformer学习(2):自注意力机制
回顾 注意力机制 自注意力机制 自注意力机制中同样包含QKV,但它们是同源(Q≈K≈V),也就是来自相同的输入数据X,X可以分为 ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn)。 而通过输入嵌入层(input embedding),…...

分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序
分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序 文章目录 一、基本原理1. 粒子群优化算法(PSO)2. 径向基神经网络(RBF)PSO-RBF模型流程总结 二、实验结果三、核心代码…...

【React】Vite 构建 React
项目搭建 vite 官网:Vite 跟着文档走即可,选择 react ,然后 ts swc。 着重说一下 package-lock.json 这个文件有两个作用: 锁版本号(保证项目在不同人手里安装的依赖都是相同的,解决版本冲突的问题&am…...

算法刷题:300. 最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
300. 最长递增子序列 1.dp定义:dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度 2.递推公式:if (nums[i] > nums[j]) dp[i] max(dp[i], dp[j] 1); 注意这里不是要dp[i] 与 dp[j] 1进行比较,而是我们要取dp[j] 1的最大值…...

【linux】一种基于虚拟串口的方式使两个应用通讯
在Linux系统中,两个应用之间通过串口(Serial Port)进行通信是一种常见的通信方式,特别是在嵌入式系统、工业自动化等领域。串口通信通常涉及到对串口设备的配置和读写操作。以下是一个基本的步骤指南,说明如何在Linux中…...
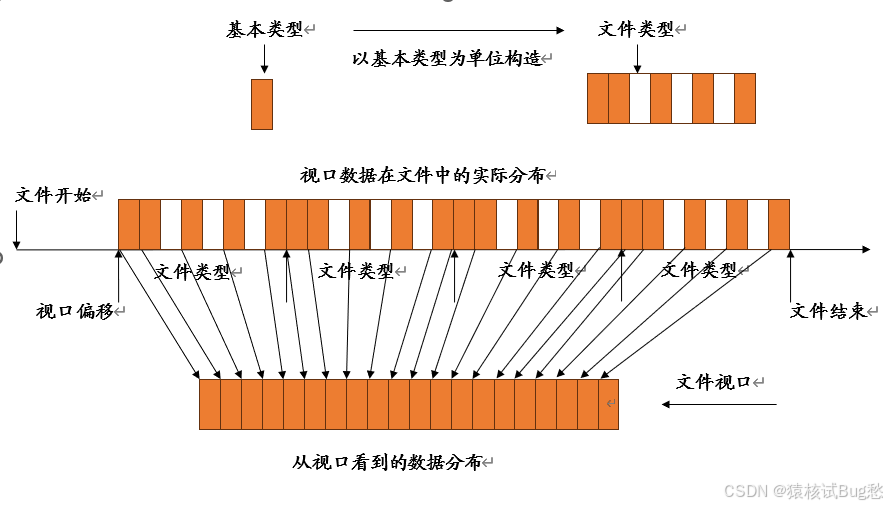
并行程序设计基础——并行I/O(3)
目录 一、多视口的并行文件并行读写 1、文件视口与指针 1.1 MPI_FILE_SET_VIEW 1.2 MPI_FILE_GET_VIEW 1.3 MPI_FILE_SEEK 1.4 MPI_FILE_GET_POSTION 1.5 MPI_FILE_GET_BYTE_OFFSET 2、阻塞方式的视口读写 2.1 MPI_FILE_READ 2.2 MPI_FILE_WRITE 2.3 MPI_FILE_READ_…...

性能测试-jmeter脚本录制(十五)
一、jmeter脚本录制(不推荐)简介: 二、jmeter脚本录制步骤 1、添加代理服务器和线程组 2、配置http代理服务器的端口和目标线程组 3修改本机浏览器代理 4、点击启动 5、每次操作页面前,修改提示文字...

KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南
KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而烦恼吗?Office文档突…...

基于R语言地理加权回归、主成份分析、判别分析等空间异质性数据分析术应用
在自然和社会科学领域有大量与地理或空间有关的数据,这一类数据一般具有严重的空间异质性,而通常的统计学方法并不能处理空间异质性,因而对此类型的数据无能为力。以地理加权回归为基础的一系列方法:经典地理加权回归,…...

光模块PCB设计学习记录01
/*光模块布局,有错误可以指出,有不足可以补充*/ 光模块PCB布局规划 01导入板框与结构约束导入 这里的outline板框一般由机械提供.dxf文件,板框决定PCB尺寸、器件可用区域和接口位置;成功导入dxf文件后,打开Board Geo…...

CodeWF.Markdown:一个基于 Avalonia 12 的 Markdown 渲染控件
今天这篇文章,站长来聊聊我最近基本开发完成的 CodeWF.Markdown。这是一个基于 C# Avalonia 12 Markdig 做的 Markdown 渲染控件。它最早来自 CodeWF.AvaloniaControls,后来我把 Markdown 相关代码单独拆成了一个仓库和一组 NuGet 包:渲染控…...

基于MCP协议构建安全AI支付工具:从原理到实践
1. 项目概述与核心价值最近在折腾AI智能体开发,特别是想给Claude Desktop这类工具增加点“超能力”,比如让它能直接帮我处理支付、查询订单状态,甚至自动对账。这想法听起来挺酷,但真动手去实现,发现最大的拦路虎不是写…...

【硬件实战】从栅极驱动芯片到H桥:MOS管驱动电路设计精要
1. 栅极驱动芯片选型与核心参数解析 第一次用IR2104做H桥驱动时,我犯了个低级错误——没仔细看芯片的驱动能力参数,结果MOS管开关速度慢得像老牛拉车,电机发热严重。这个教训让我明白,选对栅极驱动芯片是H桥设计的首要任务。 目前…...

Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生
Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们都有过这样的经历:在桌…...

探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法
探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想象一下,当你分享一张角色图片时,你实际上是在分享一…...

Kilocode框架:轻量级代码组织与复用架构实践
1. 项目概述:一个面向开发者的轻量级代码组织与复用框架最近在和一些团队交流时,发现一个挺普遍的现象:随着项目迭代,代码库越来越臃肿,不同模块间的依赖关系变得混乱,想复用一段业务逻辑或者工具函数&…...

如何在卡片悬停时添加内边距而不引起布局偏移
本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略,在卡片 hover 时安全添加 padding,避免因盒模型计算导致的布局抖动或相邻卡片位移。 本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略&am…...