Leetcode 无重复字符的最长子串
算法思想:
- 滑动窗口:通过
start和end来维护一个滑动窗口,start指向当前窗口的起点,end是当前窗口的末尾。滑动窗口中的字符都是无重复的。 - 哈希表
charIndexMap:用于存储每个字符及其最近一次出现的位置。 - 更新起始位置:如果当前字符已经在滑动窗口中出现过(即它在
charIndexMap中),则将窗口的起始位置start更新为该字符上次出现位置的下一个位置。 - 更新最长长度:每次移动
end时,计算当前窗口的长度,并更新最大长度maxLength。 - 时间复杂度:O(n),每个字符最多被访问两次(一次通过
end,一次通过start)。
一个字符如果已经存在于哈希表 charIndexMap 中作为 key,那么它必然已经在滑动窗口中出现过(或者至少在当前遍历之前出现过)
哈希表charIndexMap为什么只存储每个字符最近一次出现的位置?
哈希表 charIndexMap 只存储每个字符最近一次出现的位置是关键的,因为它帮助我们高效地处理字符重复问题。让我们深入分析这个策略的核心原因:
1. 滑动窗口的高效性:
在解决这个问题时,我们使用了滑动窗口的思路,维护窗口中无重复字符的子串。如果当前字符已经出现在窗口中,我们需要将窗口的起始位置 start 移动到这个字符上一次出现的位置之后。
例如,假设我们处理字符串 "abcabcbb",当我们扫描到第二个 'a' 时,我们需要知道第一个 'a' 在字符串中的位置,从而更新 start 位置。如果我们总是记录字符最近一次的位置,就可以通过直接访问 charIndexMap 中的值,快速找到这个字符上次出现的位置,并更新窗口的起始位置。
2. 无重复字符:
为了确保滑动窗口中的子串没有重复字符,我们只关心当前字符的最近一次出现位置。因为滑动窗口始终向右移动,每个字符可能会出现在滑动窗口内一次或多次,但我们只关心最近一次出现时的位置,这样才能根据它来决定是否需要缩小窗口大小。
例子:
考虑字符串 "abca",当我们扫描到第二个 'a' 时,窗口是从 start = 0 到 end = 3。为了保持子串中的字符不重复,我们必须将 start 移动到第一次 'a' 之后,也就是位置 1。所以我们更新 start = charIndexMap['a'] + 1。如果哈希表里记录的不是最近一次出现的 'a',我们就无法正确更新 start 位置,滑动窗口会无法维持无重复的子串。
3. 避免重复计算:
通过记录最近一次出现的位置,我们可以在常数时间内查找每个字符是否在滑动窗口中出现过。如果哈希表里保存的是某个字符的所有出现位置,那么我们需要逐个遍历所有出现的位置,这样会降低算法效率,导致无法在 O(n) 时间内完成。
例如,假设我们使用一个数据结构记录字符所有出现的位置,对于每个新的字符,我们需要检查这个数据结构的所有位置来决定窗口的起点,这样时间复杂度会增加到 O(n^2),大大降低了算法的效率。
4. 滑动窗口的合法性更新:
当我们遇到重复字符时,我们只需要关心这个字符最近一次出现在滑动窗口中的位置,并且根据它来调整窗口的起点。这种做法使得我们能够在一次扫描中动态维护窗口,且保证窗口内的字符始终无重复。
举个例子:
对于字符串 "tmmzuxt",当我们扫描到第二个 'm' 时,窗口变为 "tm",此时遇到重复字符 'm',我们需要更新 start 到第一个 'm' 之后的位置。我们只需要存储每个字符最近出现的索引来做到这一点。
总结:
哈希表 charIndexMap 只存储每个字符最近一次出现的位置,是为了在滑动窗口中快速查找字符的最近出现情况,从而在 O(1) 的时间内决定是否需要更新窗口的起点。这样可以确保算法的时间复杂度为 O(n),在处理大规模输入时仍能高效运行。
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;int lengthOfLongestSubstring(string s) {unordered_map<char, int> charIndexMap; // 存储字符和其索引int maxLength = 0; // 无重复字符子串的最大长度int start = 0; // 滑动窗口的起始位置for (int end = 0; end < s.length(); ++end) {char currentChar = s[end];// 如果当前字符已经在滑动窗口中,更新起始位置到其下一个位置if (charIndexMap.find(currentChar) != charIndexMap.end()) {start = max(start, charIndexMap[currentChar] + 1);}// 更新当前字符的索引charIndexMap[currentChar] = end;// 更新最大长度maxLength = max(maxLength, end - start + 1);}return maxLength;
}int main() {string s;cout << "请输入一个字符串: ";cin >> s;int result = lengthOfLongestSubstring(s);cout << "无重复字符的最长子串长度为: " << result << endl;return 0;
}
这一行代码, 为什么需要和start进行max比较而不是直接使用charIndexMap[currentChar] + 1进行更新?
start = max(start, charIndexMap[currentChar] + 1);
这是一个很好的问题!代码中这一行:
在更新滑动窗口的起点 start 时,之所以需要和 start 进行 max 比较,而不是直接使用 charIndexMap[currentChar] + 1,原因在于当前的 start 可能已经在该字符后面了。我们需要确保 start 只会向前移动,而不会回退。下面详细解释这个原因。
详细原因:
1. 字符可能之前已经出现在窗口外:
当我们遇到一个已经在哈希表中存在的字符时,它的上一次出现位置可能已经在当前窗口外,即在 start 之前。例如,如果 start 已经向前移动到了超过该字符上一次出现的位置,我们就不应该让 start 回退到它之前的地方。
举例:
假设我们处理字符串 "abcdaefg"。
- 当
end扫描到第一个'a'时,窗口为"a"。 - 扫描到
"abcda",第二个'a'重复,charIndexMap['a'] = 0,所以我们应该更新start为charIndexMap['a'] + 1 = 0 + 1 = 1,此时窗口变成"bcda"。 - 接着扫描到
'e'和'f',没有问题,窗口为"bcdae"和"bcdaef"。 - 最后扫描到
'g',窗口为"bcdaefg"。
如果你在遇到重复字符 'a' 时直接把 start 更新为 charIndexMap['a'] + 1 = 1,并不需要多此一举,因为 start 本身已经是 1 或更大了。
2. 防止 start 回退:
如果不使用 max 比较,而是直接将 start 更新为 charIndexMap[currentChar] + 1,可能会导致窗口的起点 start 回退,破坏滑动窗口的正确性。
举个详细的例子:
考虑字符串 "abba",滑动窗口的过程如下:
end = 0,start = 0,窗口为"a",无重复。end = 1,start = 0,窗口为"ab",无重复。end = 2,start = 0,遇到重复字符'b',charIndexMap['b'] = 1,所以start = charIndexMap['b'] + 1 = 2,窗口变为"b"。- 接着
end = 3,start = 2,遇到重复字符'a',此时如果直接将start更新为charIndexMap['a'] + 1 = 0 + 1 = 1,则会导致start回退到 1,实际上窗口已经过了位置 1。因此,更新start时需要比较max(start, charIndexMap[currentChar] + 1),保持start不会回退。
通过 max(start, charIndexMap[currentChar] + 1),我们确保 start 只会向右移动,保证滑动窗口合法,并且避免了让 start 回退到一个可能包含重复字符的位置。
3. 总结:
start = max(start, charIndexMap[currentChar] + 1); 的目的是为了防止滑动窗口的起点回退。当我们遇到重复字符时,如果该字符的上次出现位置已经在 start 之前(即窗口外),我们不应该让 start 回退。因此我们需要将 start 与 charIndexMap[currentChar] + 1 进行比较,确保 start 总是向前移动,保持滑动窗口的无重复性。
这个 max 操作确保滑动窗口的正确性,并保证算法的时间复杂度为 O(n)。
关于这一部分代码片段,为什么先更新start,后更新end?是否可以先更新end,后更新start?
// 如果当前字符已经在滑动窗口中,更新起始位置到其下一个位置if (charIndexMap.find(currentChar) != charIndexMap.end()) {start = max(start, charIndexMap[currentChar] + 1);}// 更新当前字符的索引charIndexMap[currentChar] = end;
在这段代码中,更新 start 和更新 end 的顺序是非常重要的。让我们分析为什么必须先更新 start,再更新 end,以及如果反过来会导致什么问题。
代码逻辑回顾:
// 如果当前字符已经在滑动窗口中,更新起始位置到其下一个位置
if (charIndexMap.find(currentChar) != charIndexMap.end()) {start = max(start, charIndexMap[currentChar] + 1);
}// 更新当前字符的索引
charIndexMap[currentChar] = end;
为什么要先更新 start 再更新 end?
-
滑动窗口需要维持无重复字符的状态:
当我们发现当前字符currentChar已经在charIndexMap中(说明之前已经出现过),为了确保滑动窗口中的子串不包含重复字符,必须先更新窗口的起点start,使窗口“跳过”重复的字符。- 如果我们先更新
end,然后再处理start的话,charIndexMap[currentChar]将会被更新为当前的end,那么它就代表了字符currentChar的最新位置,导致无法获取该字符之前出现的位置。这会破坏我们本该依据字符之前出现位置来调整start的逻辑,最终导致窗口中可能会保留重复字符。
举个例子:
- 假设字符串为
"abcba",我们正在处理字符'b'。 charIndexMap['b']的值本来是1(第一次出现位置)。- 如果我们先更新
end,那么charIndexMap['b']就变成了当前的4(第二次出现的位置),这样后面判断重复字符的时候,我们就不能正确获取b的第一次出现位置(索引1),从而不能正确更新start。
- 如果我们先更新
-
start是根据字符的旧位置来更新的:
只有在更新start之前,字符currentChar在charIndexMap中的值才是它上一次出现的索引。如果我们提前更新charIndexMap[currentChar],就会丢失这个关键信息。因此,必须先利用charIndexMap[currentChar]获取字符的旧位置,然后更新start,之后再将charIndexMap[currentChar]更新为end(最新的索引)。
如果先更新 end,会出现什么问题?
假设我们反过来写成:
// 先更新当前字符的索引
charIndexMap[currentChar] = end;// 如果当前字符已经在滑动窗口中,更新起始位置到其下一个位置
if (charIndexMap.find(currentChar) != charIndexMap.end()) {start = max(start, charIndexMap[currentChar] + 1);
}
问题:如果你先更新 charIndexMap[currentChar] = end,那么 charIndexMap[currentChar] 将会被更新为当前字符的最新位置,导致后面的 start = max(start, charIndexMap[currentChar] + 1) 其实是在基于当前字符的最新位置来更新 start。这样你会丢失该字符上次出现时的索引信息,滑动窗口中的字符不会被正确地排除掉,可能导致窗口中保留了重复字符。
举例:
假设处理字符串 "abcb",当 end = 3 时,遇到重复的 'b':
- 如果我们先更新
charIndexMap['b'] = 3,那么charIndexMap['b']现在指向的是最新的3,而不是上一次'b'出现的位置1。 - 当你之后再试图更新
start时,charIndexMap['b'] + 1 = 3 + 1 = 4,导致start被更新到超出当前窗口范围的地方,错误地跳过了整个窗口,这显然是错误的。
总结:
- 先更新
start是为了确保我们使用的是字符上次出现的位置,从而调整滑动窗口,保持无重复字符的子串。 - 再更新
end是为了记录当前字符的新位置,为后续的判断做好准备。 - 如果反过来操作,先更新
end会导致我们丢失字符上次出现的位置,从而不能正确更新start,最终滑动窗口无法保证无重复字符。
因此,先更新 start,后更新 end 是必要的顺序,保证了逻辑正确性。
相关文章:

Leetcode 无重复字符的最长子串
算法思想: 滑动窗口:通过 start 和 end 来维护一个滑动窗口,start 指向当前窗口的起点,end 是当前窗口的末尾。滑动窗口中的字符都是无重复的。哈希表 charIndexMap:用于存储每个字符及其最近一次出现的位置。更新起始…...

用命令行的方式启动.netcore webapi
用命令行的方式启动.netcore web项目 进入指定的项目文件夹,比如我发布后的代码放在下面文件夹中 在此地址栏中输入“cmd”,打开命令提示符,进入到发布代码目录 命令行启动.netcore项目的命令为: dotnet 项目启动文件.dll --urls"ht…...

Spring6详细学习笔记(IOC+AOP)
一、Spring系统架构介绍 1.1、定义 Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器(框架)。Spring官网 Spring是一款主流的Java EE 轻量级开源框架,目的是用于简化Java企业级引用的开发难度和开发周期。从简单性、可测试性和松耦…...

@RequestMapping 基于哪个库进行通信
RequestMapping 是 Spring Framework 中用于处理 HTTP 请求的注解,主要用于定义控制器方法的请求映射。它并不直接基于某个特定的通信库,而是依赖于 Spring MVC 框架的核心功能。 1. Spring MVC RequestMapping 是 Spring MVC 的一部分,Spr…...

GPIO(General Purpose Input/Output)输入/输出
GPIO最简单的功能是输出高低电平;GPIO还可以被设置为输入功能,用于读取按键等输入信号;也可以将GPIO复用成芯片上的其他外设的控制引脚。 STM32F407ZGT6有8组IO。分别为GPIOA~GPIOH,除了GPIOH只有两个IO,其余每组IO有…...
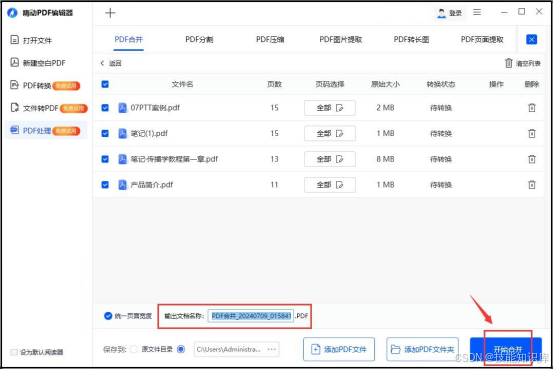
两个pdf合并成一个pdf,这些pdf合并小技巧了解下
在日常工作和学习中,我们经常会遇到需要将多个PDF文件合并成一个文件的情况。这不仅可以提高文件管理的效率,还能让信息展示更加集中和便捷。今天就来给大家分享几种非常简单便捷的PDF合并小技巧,一起来学习下吧。 方法一:WPS WP…...

Transformer学习(2):自注意力机制
回顾 注意力机制 自注意力机制 自注意力机制中同样包含QKV,但它们是同源(Q≈K≈V),也就是来自相同的输入数据X,X可以分为 ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn)。 而通过输入嵌入层(input embedding),…...

分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序
分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序 文章目录 一、基本原理1. 粒子群优化算法(PSO)2. 径向基神经网络(RBF)PSO-RBF模型流程总结 二、实验结果三、核心代码…...

【React】Vite 构建 React
项目搭建 vite 官网:Vite 跟着文档走即可,选择 react ,然后 ts swc。 着重说一下 package-lock.json 这个文件有两个作用: 锁版本号(保证项目在不同人手里安装的依赖都是相同的,解决版本冲突的问题&am…...

算法刷题:300. 最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
300. 最长递增子序列 1.dp定义:dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度 2.递推公式:if (nums[i] > nums[j]) dp[i] max(dp[i], dp[j] 1); 注意这里不是要dp[i] 与 dp[j] 1进行比较,而是我们要取dp[j] 1的最大值…...

【linux】一种基于虚拟串口的方式使两个应用通讯
在Linux系统中,两个应用之间通过串口(Serial Port)进行通信是一种常见的通信方式,特别是在嵌入式系统、工业自动化等领域。串口通信通常涉及到对串口设备的配置和读写操作。以下是一个基本的步骤指南,说明如何在Linux中…...
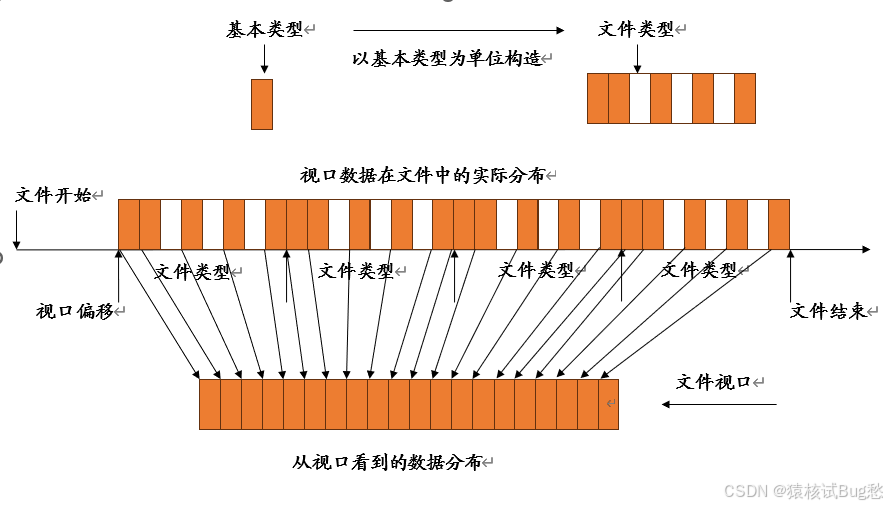
并行程序设计基础——并行I/O(3)
目录 一、多视口的并行文件并行读写 1、文件视口与指针 1.1 MPI_FILE_SET_VIEW 1.2 MPI_FILE_GET_VIEW 1.3 MPI_FILE_SEEK 1.4 MPI_FILE_GET_POSTION 1.5 MPI_FILE_GET_BYTE_OFFSET 2、阻塞方式的视口读写 2.1 MPI_FILE_READ 2.2 MPI_FILE_WRITE 2.3 MPI_FILE_READ_…...

性能测试-jmeter脚本录制(十五)
一、jmeter脚本录制(不推荐)简介: 二、jmeter脚本录制步骤 1、添加代理服务器和线程组 2、配置http代理服务器的端口和目标线程组 3修改本机浏览器代理 4、点击启动 5、每次操作页面前,修改提示文字...

关系型数据库 - MySQL I
MySQL 数据库 MySQL 是一种关系型数据库。开源免费,并且方便扩展。在 Java 开发中常用于保存和管理数据。默认端口号 3306。 MySQL 数据库主要分为 Server 和存储引擎两部分,现在最常用的存储引擎是 InnoDB。 指令执行过程 MySQL 数据库接收到用户指令…...
解锁AI写作新境界:5款工具让你的论文创作事半功倍
在这个数字化飞速发展的时代,人工智能(AI)已经不再是科幻小说中的幻想,而是实实在在地融入了我们的日常生活。特别是在学术领域,AI技术的介入正在改变传统的论文写作方式。你是否还在为撰写论文而熬夜苦战?…...
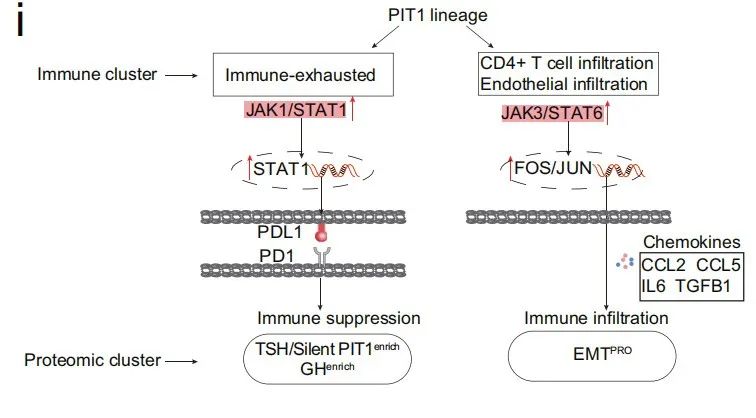
一文读懂多组学联合分析产品在医学领域的应用
疾病的发生和发展通常涉及多个层面的生物学过程,包括基因表达、蛋白质功能、代谢物变化等。传统的单一组学研究只能提供某一层面的信息,而多组学关联分析能够综合多个层面的数据,提供更全面、更深入的疾病理解。例如,通过分析患者…...

js react 笔记 2
起因, 目的: 记录一些 js, react, css 1. 生成一个随机的 uuid // 需要先安装 crypto 模块 const { randomUUID } require(crypto);const uuid randomUUID(); console.log(uuid); // 输出类似 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d 2. 使用 props, 传递参数…...

快速使用react 全局状态管理工具--redux
redux Redux 是 JavaScript 应用中管理应用状态的工具,特别适用于复杂的、需要共享状态的中大型应用。Redux 的核心思想是将应用的所有状态存储在一个单一的、不可变的状态树(state tree)中,状态只能通过触发特定的 action 来更新…...

活动系统开发之采用设计模式与非设计模式的区别-非设计模式
1、父类Base.php <?php /*** 初始化控制器* User: Administrator* Date: 2022/9/26* Time: 18:00*/ declare (strict_types 1); namespace app\controller; use app\model\common\Token; use app\BaseController; use app\BaseError; use OpenSSL\Encrypt; use app\model…...

JVM面试(六)垃圾收集器
目录 概述STW收集器的并发和并行 Serial收集器ParNew收集器Parallel Scavenge收集器Serial Old收集器Parallel Old收集器CMS收集器Garbage First(G1)收集器 概述 上一章我们分析了垃圾收集算法,那这一章我们来认识一下这些垃圾收集器是如何运…...

峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验
峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 在英雄联盟的召唤师峡谷中,每一…...

更换背景图用什么工具?8个月来我测试过50+款产品,这是真实体验分享
买了新手机,想给证件照换个背景;电商运营需要批量处理商品图;自媒体博主要给头像去个背景……这些场景下,"更换背景图用什么工具"可能是你Google搜索框里最常打的一句话。说实话,这个问题看似简单࿰…...

科技中介如何减少重复建设成本,提升服务专业性?
观点作者:科易网-国家科技成果转化(厦门)示范基地 一、现状概述:科技中介服务的成效与短板 在创新驱动发展战略深入实施的时代背景下,科技中介机构作为连接科技创新与产业发展的关键桥梁,其重要性日益凸显。…...

巅峰共鸣,实力同频|盖茨中国热烈祝贺张雪机车WSBK捷克站双冠耀世,改写37年垄断史!
引擎轰鸣震彻赛道,中国红闪耀世界舞台!2026 年 5 月 17 日,WSBK 捷克莫斯特站 WorldSSP 组别圆满落幕,中国品牌张雪机车再创历史,车手 Valentin Debise 驾驶自研 ZX820RR 赛车,包揽两回合冠军,斩…...

国产多模态大模型崛起:技术、场景与未来挑战全解析
国产多模态大模型崛起:技术、场景与未来挑战全解析 引言 在人工智能浪潮席卷全球的背景下,多模态大模型已成为技术竞争的新高地。以GPT-4V、Gemini为代表的国际巨头展现了强大的图文理解与生成能力,而国产模型正凭借对中文场景的深度优化、独…...

独立开发者如何利用 Taotoken 模型广场低成本试错选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 模型广场低成本试错选型 对于资源有限的独立开发者或小型团队而言,在产品开发初期选择合…...

别再手动写上传了!用Layui Upload组件+PHP后端,10分钟搞定带进度条的文件上传功能
10分钟极速集成:Layui UploadPHP打造高体验文件上传模块 每次看到项目里又需要实现文件上传功能时,你是不是已经开始头疼那些重复的代码和调试过程?从进度条显示到文件类型校验,再到后端安全处理,每个环节都可能藏着意…...

杰理之满电后每个耳机功耗在20UA到30UA 处理方法【篇】
下拉200K电阻要开启...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建
NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建 【免费下载链接】NodeJS-Learning This page contains collection of curated links to blog posts, articles, videos, tutorials, books, frameworks, modules, IDEs, testing tools, hosting providers, et…...