Transformer学习(2):自注意力机制
回顾
注意力机制

自注意力机制

自注意力机制中同样包含QKV,但它们是同源(Q≈K≈V),也就是来自相同的输入数据X,X可以分为 ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn)。
而通过输入嵌入层(input embedding), ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn)变为 ( a 1 , a 2 , . . , a n ) (a_1,a_2,..,a_n) (a1,a2,..,an)这些向量,通过X来寻找X中的关键点。
而对于每个 a i a_i ai都会有对应 q i , k i , v i q_i,k_i,v_i qi,ki,vi,Q不再是共用的。
Q = { q 1 , q 2 , . . . , q n } ; K = { k 1 , k 2 , . . . , k n } ; V = { v 1 , v 2 , . . . , v n } Q = \{q_1,q_2,...,q_n\};K = \{k_1,k_2,...,k_n\};V = \{v_1,v_2,...,v_n\} Q={q1,q2,...,qn};K={k1,k2,...,kn};V={v1,v2,...,vn}
在自注意力机制中,以输入数据X自身中的 x i x_i xi作为查询对象(注意力机制中的Q),自身的其他 x x x作为被查询对象V。也就是自己作为查询与被查询对象。
计算过程
① 计算QKV:
要得到QKV,则需要使用三个参数 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV,这三个参数都是可训练的,而且所有 a a a共享。
公式:
q i = a i ∗ W Q q_i = a_i*W_Q qi=ai∗WQ
k i = a i ∗ W K k_i = a_i*W_K ki=ai∗WK
v i = a i ∗ W V v_i = a_i*W_V vi=ai∗WV

而这个计算过程可以写为矩阵乘法,实现并行计算。

② 计算Q与K相似度(概率):
每个 q i q_i qi都有一次作为查询对象,所有的 k k k计算与其的相似度(与它相同的概率)。
计算相似度的方法与注意力机制是相同,都是q与k进行点乘与scale得到相似度,其中 d k d_k dk为k的尺寸,也就是向量 k k k包含多少个数据。

计算过程如图所示,每个 q i q_i qi都计算与所有 k k k的相似度。

计算过程也可以表示为矩阵运算

③ 汇总权重,得到包含注意力信息的结果
计算出Q与K的相似度,也就是得到了对于 q i q_i qi,各个 v i v_i vi的权重。
最后将得到的权重 a ^ \widehat{a} a 与每个 v i v_i vi进行点乘运算再将结果相加,就可以得到包含了对于 q i q_i qil来说哪些重要与不重要的数据 b i b_i bi,然后用 b i b_i bi来代替 a i a_i ai

计算过程也可以转换为矩阵运算

与注意力机制的不同
注意力机制是一个很宽泛(宏大)的一个概念,QKV 相乘就是注意力,但是他没有规定 QKV是怎么来的,他只规定 QKV 怎么做。
Q 可以是任何一个东西,V 也是任何一个东西, K往往是等同于 V 的(同源),K和 V 不同源不相等可不可以。
而自注意力机制,特别狭隘,属于注意力机制的,注意力机制包括自注意力机制的,他不仅规定了 QKV 同源,而且固定了 QKV 的做法,规定了QKV是如何得到的。
总结
自注意力机制是规定了数据自身来作为查询对象与被查询对象。
相关文章:
Transformer学习(2):自注意力机制
回顾 注意力机制 自注意力机制 自注意力机制中同样包含QKV,但它们是同源(Q≈K≈V),也就是来自相同的输入数据X,X可以分为 ( x 1 , x 2 , . . , x n ) (x_1,x_2,..,x_n) (x1,x2,..,xn)。 而通过输入嵌入层(input embedding),…...

分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序
分类预测|基于粒子群优化径向基神经网络的数据分类预测Matlab程序PSO-RBF 多特征输入多类别输出 含基础RBF程序 文章目录 一、基本原理1. 粒子群优化算法(PSO)2. 径向基神经网络(RBF)PSO-RBF模型流程总结 二、实验结果三、核心代码…...

【React】Vite 构建 React
项目搭建 vite 官网:Vite 跟着文档走即可,选择 react ,然后 ts swc。 着重说一下 package-lock.json 这个文件有两个作用: 锁版本号(保证项目在不同人手里安装的依赖都是相同的,解决版本冲突的问题&am…...

算法刷题:300. 最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
300. 最长递增子序列 1.dp定义:dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度 2.递推公式:if (nums[i] > nums[j]) dp[i] max(dp[i], dp[j] 1); 注意这里不是要dp[i] 与 dp[j] 1进行比较,而是我们要取dp[j] 1的最大值…...

【linux】一种基于虚拟串口的方式使两个应用通讯
在Linux系统中,两个应用之间通过串口(Serial Port)进行通信是一种常见的通信方式,特别是在嵌入式系统、工业自动化等领域。串口通信通常涉及到对串口设备的配置和读写操作。以下是一个基本的步骤指南,说明如何在Linux中…...
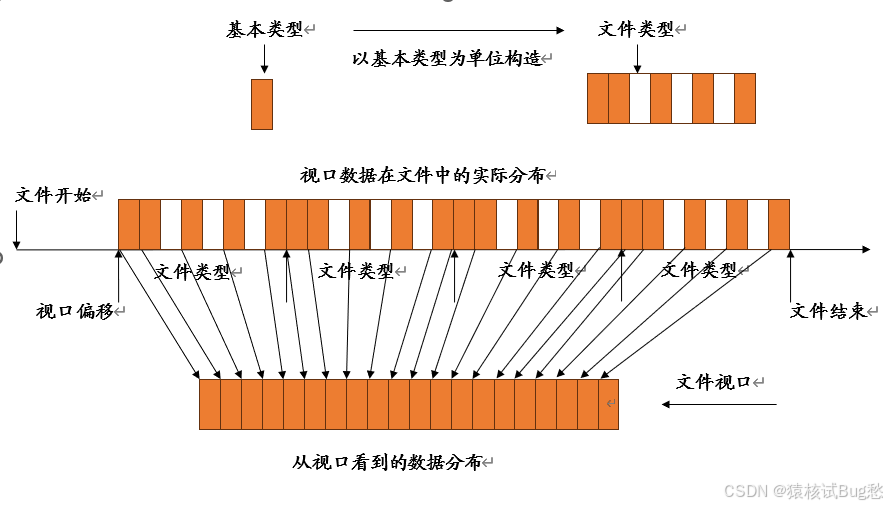
并行程序设计基础——并行I/O(3)
目录 一、多视口的并行文件并行读写 1、文件视口与指针 1.1 MPI_FILE_SET_VIEW 1.2 MPI_FILE_GET_VIEW 1.3 MPI_FILE_SEEK 1.4 MPI_FILE_GET_POSTION 1.5 MPI_FILE_GET_BYTE_OFFSET 2、阻塞方式的视口读写 2.1 MPI_FILE_READ 2.2 MPI_FILE_WRITE 2.3 MPI_FILE_READ_…...

性能测试-jmeter脚本录制(十五)
一、jmeter脚本录制(不推荐)简介: 二、jmeter脚本录制步骤 1、添加代理服务器和线程组 2、配置http代理服务器的端口和目标线程组 3修改本机浏览器代理 4、点击启动 5、每次操作页面前,修改提示文字...

关系型数据库 - MySQL I
MySQL 数据库 MySQL 是一种关系型数据库。开源免费,并且方便扩展。在 Java 开发中常用于保存和管理数据。默认端口号 3306。 MySQL 数据库主要分为 Server 和存储引擎两部分,现在最常用的存储引擎是 InnoDB。 指令执行过程 MySQL 数据库接收到用户指令…...
解锁AI写作新境界:5款工具让你的论文创作事半功倍
在这个数字化飞速发展的时代,人工智能(AI)已经不再是科幻小说中的幻想,而是实实在在地融入了我们的日常生活。特别是在学术领域,AI技术的介入正在改变传统的论文写作方式。你是否还在为撰写论文而熬夜苦战?…...
一文读懂多组学联合分析产品在医学领域的应用
疾病的发生和发展通常涉及多个层面的生物学过程,包括基因表达、蛋白质功能、代谢物变化等。传统的单一组学研究只能提供某一层面的信息,而多组学关联分析能够综合多个层面的数据,提供更全面、更深入的疾病理解。例如,通过分析患者…...

js react 笔记 2
起因, 目的: 记录一些 js, react, css 1. 生成一个随机的 uuid // 需要先安装 crypto 模块 const { randomUUID } require(crypto);const uuid randomUUID(); console.log(uuid); // 输出类似 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d 2. 使用 props, 传递参数…...

快速使用react 全局状态管理工具--redux
redux Redux 是 JavaScript 应用中管理应用状态的工具,特别适用于复杂的、需要共享状态的中大型应用。Redux 的核心思想是将应用的所有状态存储在一个单一的、不可变的状态树(state tree)中,状态只能通过触发特定的 action 来更新…...

活动系统开发之采用设计模式与非设计模式的区别-非设计模式
1、父类Base.php <?php /*** 初始化控制器* User: Administrator* Date: 2022/9/26* Time: 18:00*/ declare (strict_types 1); namespace app\controller; use app\model\common\Token; use app\BaseController; use app\BaseError; use OpenSSL\Encrypt; use app\model…...

JVM面试(六)垃圾收集器
目录 概述STW收集器的并发和并行 Serial收集器ParNew收集器Parallel Scavenge收集器Serial Old收集器Parallel Old收集器CMS收集器Garbage First(G1)收集器 概述 上一章我们分析了垃圾收集算法,那这一章我们来认识一下这些垃圾收集器是如何运…...
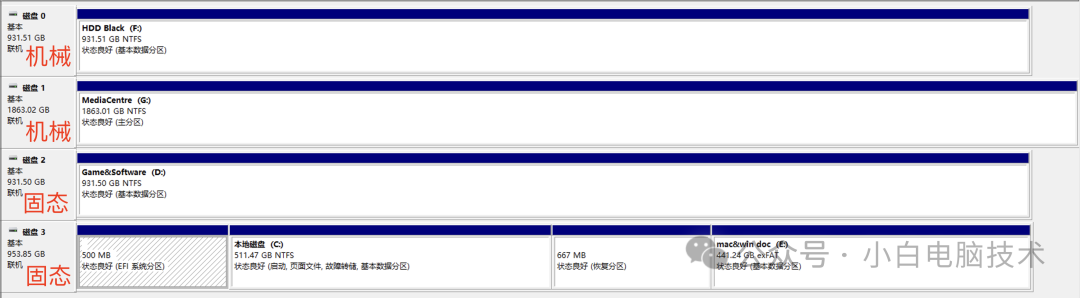
固态硬盘装系统有必要分区吗?
前言 现在的新电脑有哪一台是不使用固态硬盘的呢?这个好像很少很少了…… 有个朋友买了一台新的笔记本电脑,开机之后,电脑只有一个分区(系统C盘500GB)。这时候她想要给笔记本分区…… 这个真的有必要分区吗…...

网络安全架构师
网络安全架构师负责构建全面的安全框架,以保护组织的数字资产免受侵害,确保组织在数字化转型的同时维持强大的安全防护。 摩根大通的网络安全运营副总裁兼安全架构总监Lester Nichols强调,成为网络安全架构师对现代企业至关重要,…...

如何本地部署Ganache并使用内网穿透配置公网地址远程连接测试网络
目录 前言 1. 安装Ganache 2. 安装cpolar 3. 创建公网地址 4. 公网访问连接 5. 固定公网地址 作者简介: 懒大王敲代码,计算机专业应届生 今天给大家聊聊如何本地部署Ganache并使用内网穿透配置公网地址远程连接测试网络,欢迎大家点赞 &a…...

算法岗/开发岗 实况
深信服算法岗一面 第一题 树的直径有哪些解法 两次dfs和树形dp,讲了一下树形dp的思路 因为我的简历写的比较少,所以面试官问我一些个人信息和擅长哪方面。 我说:ACM大一下打到大三,然后去考研。dp写的多一点,还有思维…...

Nginx跨域运行案例:云台控制http请求,通过 http server 代理转发功能,实现跨域运行。(基于大华摄像头WEB无插件开发包)
文章目录 引言I 跨域运行案例开发资源测试/生产环境,Nginx代理转发,实现跨域运行本机开发运行II nginx的location指令Nginx配置中, 获取自定义请求header头Nginx 配置中,获取URL参数引言 背景:全景监控 需求:感知站点由于云台相关操作为 http 请求,http 请求受浏览器…...

【数据分析预备】Pandas
Pandas 构建在NumPy之上,继承了NumPy高性能的数组计算功能,同时提供更多复杂精细的数据处理功能 安装 pip install pandas导入 import pandas as pdSeries 键值对列表 # 创建Series s1 pd.Series([5, 17, 3, 26, 31]) s10 5 1 17 2 3 3 26 4 31 dt…...

从8251A芯片实战出发:手把手教你用8086汇编完成串口通信初始化编程
从8251A芯片实战出发:手把手教你用8086汇编完成串口通信初始化编程 在嵌入式系统与硬件接口开发领域,掌握串口通信编程是工程师的必修技能。8251A作为经典的通用同步/异步收发器(USART)芯片,至今仍在教学和工业控制领域广泛应用。本文将带您从…...

暗物质暗能量本质,分享给各位玩家
通过百度网盘分享的文件:A First-…等3个文件链接:https://pan.baidu.com/s/1FVDfTxTDAslqLtN17ulQ1w?pwd516r 复制这段内容打开「百度网盘APP 即可获取」...

终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势
终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势 【免费下载链接】gerbv Maintained fork of gerbv, carrying mostly bugfixes 项目地址: https://gitcode.com/gh_mirrors/ge/gerbv 还在为PCB设计文件的查看和验证而烦恼吗?Gerbv这款强…...

终极免费开源项目管理指南:如何用GanttProject高效规划复杂项目?
终极免费开源项目管理指南:如何用GanttProject高效规划复杂项目? 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 想要免费、开源且功能强大的项目管理工具吗&#…...

2025届毕业生推荐的AI辅助论文网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,学术研究越发受到人们的重视,在此种背景状况之下,论…...

从电机控制到服务器电源:详解功率MOSFET栅极外加电容CGS与CGD的选型计算与布局要点
功率MOSFET栅极电容设计实战:从电机驱动到服务器电源的差异化策略 在电力电子系统的核心地带,功率MOSFET如同精密交响乐团的指挥,其开关性能直接决定整个系统的效率与可靠性。当我们面对电机驱动系统要求快速切换以降低损耗,或是服…...

InstructPix2Pix:5分钟掌握AI图像编辑的终极指南
InstructPix2Pix:5分钟掌握AI图像编辑的终极指南 【免费下载链接】instruct-pix2pix 项目地址: https://gitcode.com/gh_mirrors/in/instruct-pix2pix 你是否曾经幻想过,只需一句话就能让图片中的对象变成你想要的样子?比如把普通的大…...

Spring Boot Microservices故障排查:10个常见问题及解决方案
Spring Boot Microservices故障排查:10个常见问题及解决方案 【免费下载链接】spring-boot-microservices Spring Boot Template for Micro services Architecture - Show cases how to use Zuul for API Gateway, Spring OAuth 2.0 as Auth Server, Multiple Resou…...

APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案
APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在电脑和手机之间来回传…...

如何用OpenWebRTC实现音视频通话:完整开发教程
如何用OpenWebRTC实现音视频通话:完整开发教程 【免费下载链接】openwebrtc A cross-platform WebRTC client framework based on GStreamer 项目地址: https://gitcode.com/gh_mirrors/op/openwebrtc OpenWebRTC是一个基于GStreamer的跨平台WebRTC客户端框架…...