二开ihoneyBakFileScan备份扫描
优点:可以扫描根据域名生成的扫描备份的扫描工具
二开部分:默认网址到字典(容易被封),二开字典到网址(类似test404备份扫描规则),同时把被封不能扫描的网址保存到waf_url.txt 中,换个热点线程调低继续开扫。
用法:
大备份字典:
python38 ihoneyBakFileScan_Modify_fx_big.py -t 10 -f url.txt -o result_big.txt
# -*- coding: UTF-8 -*-import requests
import logging
from argparse import ArgumentParser
from copy import deepcopy
from datetime import datetime
from hurry.filesize import size
from fake_headers import Headers
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import urllib.parse
from tqdm import tqdm # 引入 tqdm 库requests.packages.urllib3.disable_warnings()logging.basicConfig(level=logging.WARNING, format="%(message)s")# 存放不存活 URL 的集合,用于跳过重复的 URL
dead_urls = set()# 检查 URL 是否存活的函数
def check_url_status(url, retries=3):for _ in range(retries):try:response = requests.head(url, timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)if 200 <= response.status_code < 600:return response.status_codeexcept Exception:passtime.sleep(1) # 等待 1 秒后重试return None# 执行 URL 扫描的函数
def vlun(urltarget, retries=3):# 如果 URL 在不存活 URL 列表中,直接返回if urltarget in dead_urls:returnfor _ in range(retries):try:if proxies:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)else:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False)if r.status_code == 200 and all(keyword not in r.headers.get('Content-Type', '') for keyword in ['html', 'image', 'xml', 'text', 'json', 'javascript']):tmp_rarsize = int(r.headers.get('Content-Length', 0))rarsize = str(size(tmp_rarsize))if int(rarsize[:-1]) > 0:logging.warning('[ success ] {} size:{}'.format(urltarget, rarsize))with open(outputfile, 'a') as f:try:f.write(str(urltarget) + ' ' + 'size:' + str(rarsize) + '\n')except Exception as e:logging.warning(f"[ error ] Writing result failed: {e}")else:logging.warning('[ fail ] {}'.format(urltarget))returnelse:logging.warning('[ fail ] {}'.format(urltarget))returnexcept Exception as e:logging.warning('[ fail ] {}'.format(urltarget))time.sleep(1) # 等待 1 秒后重试# URL 不存活,记录根地址root_url = urllib.parse.urljoin(urltarget, '/')if root_url not in dead_urls:dead_urls.add(root_url)with open('waf_url.txt', 'a') as f:f.write(root_url + '\n')# 处理 URL 检查的函数
def urlcheck(target=None, ulist=None):if target is not None and ulist is not None:if target.startswith('http://') or target.startswith('https://'):if target.endswith('/'):ulist.append(target)else:ulist.append(target + '/')else:line = 'http://' + targetif line.endswith('/'):ulist.append(line)else:ulist.append(line + '/')return ulist# 分发处理 URL 的函数
def dispatcher(url_file=None, url=None, max_thread=20, dic=None):urllist = []if url_file is not None and url is None:with open(str(url_file)) as f:while True:line = str(f.readline()).strip()if line:urllist = urlcheck(line, urllist)else:breakelif url is not None and url_file is None:url = str(url.strip())urllist = urlcheck(url, urllist)else:passwith open(outputfile, 'a'):passcheck_urllist = []for u in urllist:cport = Noneif u.startswith('http://'):ucp = u.lstrip('http://')elif u.startswith('https://'):ucp = u.lstrip('https://')if '/' in ucp:ucp = ucp.split('/')[0]if ':' in ucp:cport = ucp.split(':')[1]ucp = ucp.split(':')[0]www1 = ucp.split('.')else:www1 = ucp.split('.')wwwlen = len(www1)wwwhost = ''for i in range(1, wwwlen):wwwhost += www1[i]current_info_dic = deepcopy(dic)suffixFormat = ['.7z','dede','admin','sys','_sys','system','_system','manage','_manage','manager','_manager','_dede','_admin','.backup','.bak','.gz','.jar','.rar','.sql','.sql.gz','.tar','.tar.bz2','.tar.gz','.tar.tgz','.tgz','.txt','.war','.zip']domainDic = [ucp, ucp.replace('.', ''), ucp.replace('.', '_'), wwwhost, ucp.split('.', 1)[-1],(ucp.split('.', 1)[1]).replace('.', '_'), www1[0], www1[1]]domainDic = list(set(domainDic))for s in suffixFormat:for d in domainDic:current_info_dic.extend([d + s])current_info_dic = list(set(current_info_dic))for info in current_info_dic:url = str(u) + str(info)check_urllist.append(url)urlist_len = len(urllist)check_urllist_len = len(check_urllist)per_distance = int(check_urllist_len / urlist_len)l = []p = ThreadPoolExecutor(max_thread)# 使用 tqdm 显示进度条with tqdm(total=check_urllist_len, desc="Scanning URLs") as pbar:futures = []for index1 in range(0, per_distance):for index2 in range(0, urlist_len):index = index2 * per_distance + index1if index < check_urllist_len:url = check_urllist[index]futures.append(p.submit(vlun, url))for future in as_completed(futures):future.result() # 等待任务完成pbar.update(1) # 更新进度条p.shutdown()if __name__ == '__main__':usageexample = '\n Example: python3 ihoneyBakFileScan_Modify.py -t 100 -f url.txt -o result.txt\n'usageexample += ' 'usageexample += 'python3 ihoneyBakFileScan_Modify.py -u https://www.example.com/ -o result.txt'parser = ArgumentParser(add_help=True, usage=usageexample, description='A Website Backup File Leak Scan Tool.')parser.add_argument('-f', '--url-file', dest="url_file", help="Example: url.txt", default="url.txt")parser.add_argument('-t', '--thread', dest="max_threads", nargs='?', type=int, default=1, help="Max threads")parser.add_argument('-u', '--url', dest='url', nargs='?', type=str, help="Example: http://www.example.com/")parser.add_argument('-d', '--dict-file', dest='dict_file', nargs='?', help="Example: dict.txt")parser.add_argument('-o', '--output-file', dest="output_file", help="Example: result.txt", default="result.txt")parser.add_argument('-p', '--proxy', dest="proxy", help="Example: socks5://127.0.0.1:1080")args = parser.parse_args()tmp_suffixFormat = ['.7z','dede','admin','sys','_sys','system','_system','manage','_manage','manager','_manager','_dede','_admin','.backup','.bak','.gz','.jar','.rar','.sql','.sql.gz','.tar','.tar.bz2','.tar.gz','.tar.tgz','.tgz','.txt','.war','.zip']tmp_info_dic = ['%e5%95%86%e5%9f%8e','%e5%a4%87%e4%bb%bd','%e5%ae%89%e8%a3%85%e6%96%87%e4%bb%b6','%e6%95%b0%e6%8d%ae','%e6%95%b0%e6%8d%ae%e5%a4%87%e4%bb%bd','%e6%95%b0%e6%8d%ae%e5%ba%93','%e6%95%b0%e6%8d%ae%e5%ba%93%e5%a4%87%e4%bb%bd','%e6%95%b0%e6%8d%ae%e5%ba%93%e6%96%87%e4%bb%b6','%e6%95%b4%e7%ab%99','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(1)','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(2)','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(3)','%e6%96%b0%e5%bb%ba%e6%96%87%e6%9c%ac%e6%96%87%e6%a1%a3','%e6%9c%8d%e5%8a%a1%e5%99%a8','%e6%a8%a1%e6%9d%bf','%e6%ba%90%e7%a0%81','%e7%a8%8b%e5%ba%8f','%e7%ab%99%e7%82%b9','%e7%bd%91%e7%ab%99','%e7%bd%91%e7%ab%99%e5%a4%87%e4%bb%bd','%e8%af%b4%e6%98%8e','1','10','11','111','111111','123','123123','1234','12345','123456','127.0.0.1','1314','1980','1981','1982','1983','1984','1985','1986','1987','1988','1989','1990','1991','1992','1993','1994','1995','1996','1997','1998','1999','2','2000','2001','2002','2003','2004','2005','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015','2016','2017','2018','2019','2020','2021','2022','2023','2024','2025','2026','2027','2028','2029','2030','3','4','5','520','6','7','7z','8','9','__zep__/js','a','aboard','access.log','add','addr','address','adm','admin','ajax','alditor','alditorimage','app','archive','asp','aspx','attach','auth','b','back','backup','backupdata','backups','bak','bb','bbs','beian','beifen','bf','bin','bin/bin','bin/bin1','bin/bin2','bin/dll','bin/dll1','bin/dll2','bin1','bin2','board','boss','browser','bz2','c','captcha','ceshi','cgi','cheditor','cheditor4','cheditor5','chximage','chxupload','ckeditor','clients','cms','code','com','common','config','connectors','contents','copy','copy05','cust','customers','d','dat','data','databack','databackup','databak','databakup','database','databasebak','datad','daumeditor','db','dbadmin','dbcon','dbmysql','dede','dedecms','default','dev','dingdan','div','dll','dntb','do','doc','download','dump','dz','e','edit','editor','email','emfo','engine','entries','error','error_log','example','ezweb','f','faisunzip','fck2','fckeditor','file','filemanager','filename','files','fileswf','fileupload','fileuploadsubmit','flash','flashfxp','form','forum','fourm','ftp','ftp1','g','gbk','gg','good','gz','h','hdocs','help','home','htdocs','htm','html','htmleditor','http','i','idcontent','idx','iis','iisweb','image','imageeditor','imagefrm','images','imageup','imageupload','img','imgupload','inc','include','index','insert','install','ir1','j','joomla','js','jsp','k','keycode','kind2','kneditor','l','lib','library','like','line','list','local','localhost','log','m','mail','manageadmin','master','material','mdb','media','members','message','min','mng','modify','multi','my','mysql','n','navereditor','new','newwebadmin','o','oa','ok','old','openwysiwyg','orders','p','paper','pass','password','photo','php','phpcms','phpmyadmin','pic','plugin','plus','pma','pop','popup','popups','popupsgecko','post','prcimageupload','productedit','q','quick','r','raineditor','rar','release','resource','root','s','s111','sales','sample','samples','scm','se2','seditordemo','seed','sell','server','shop','shu','shuju','shujuku','site','siteweb','sj','sjk','smart','smarteditor','smarteditor2','smarteditor2skin','spac','sql','sqldata','src0811','store','swf','swfupload','system','t','tar','tdi','tdmain','temp','template','test','tgz','tv','txt','typeimage0','u','ueditor','update','upfile','upfiles','upload','uploadaspx','uploader','uploadpic','uploadpopup','uploadtest','upphoto','upphoto2','user','userlist','users','v','v14','vb','vip','w','wangzhan','web','web1','webadmin','webbak','webconfig','webedit','webmysql','webroot','webservice','website','wm123','wordpress','wp','write','ww','wwroot','www','wwwroot','wx','wysiwyg','wz','x','xxx','y','ysc','z','z9v8flashfxp','z9v8ftp','zip','商城','备份','安装文件','数据','数据备份','数据库','数据库备份','数据库文件','整站','新建文件夹','新建文件夹(1)','新建文件夹(2)','新建文件夹(3)','新建文本文档','服务器','模板','源码','程序','站点','网站','网站备份','说明','1','10','11','111','111111','123','123123','1234','12345','123456','127.0.0.1','1314','1980','1981','1982','1983','1984','1985','1986','1987','1988','1989','1990','1991','1992','1993','1994','1995','1996','1997','1998','1999','2','2000','2001','2002','2003','2004','2005','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015','2016','2017','2018','2019','2020','2021','2022','2023','2024','2025','2026','2027','2028','2029','2030','3','4','5','520','6','7','7z','8','9','__zep__/js','A','Aboard','Access.log','Add','Addr','Address','Adm','Admin','Ajax','Alditor','Alditorimage','App','Archive','Asp','Aspx','Attach','Auth','B','Back','Backup','Backupdata','Backups','Bak','Bb','Bbs','Beian','Beifen','Bf','Bin','Bin/bin','Bin/bin1','Bin/bin2','Bin/dll','Bin/dll1','Bin/dll2','Bin1','Bin2','Board','Boss','Browser','Bz2','C','Captcha','Ceshi','Cgi','Cheditor','Cheditor4','Cheditor5','Chximage','Chxupload','Ckeditor','Clients','Cms','Code','Com','Common','Config','Connectors','Contents','Copy','Copy05','Cust','Customers','D','Dat','Data','Databack','Databackup','Databak','Databakup','Database','Databasebak','Datad','Daumeditor','Db','Dbadmin','Dbcon','Dbmysql','Dede','Dedecms','Default','Dev','Dingdan','Div','Dll','Dntb','Do','Doc','Download','Dump','Dz','E','Edit','Editor','Email','Emfo','Engine','Entries','Error','Error_log','Example','Ezweb','F','Faisunzip','Fck2','Fckeditor','File','Filemanager','Filename','Files','Fileswf','Fileupload','Fileuploadsubmit','Flash','Flashfxp','Form','Forum','Fourm','Ftp','Ftp1','G','Gbk','Gg','Good','Gz','H','Hdocs','Help','Home','Htdocs','Htm','Html','Htmleditor','Http','I','Idcontent','Idx','Iis','Iisweb','Image','Imageeditor','Imagefrm','Images','Imageup','Imageupload','Img','Imgupload','Inc','Include','Index','Insert','Install','Ir1','J','Joomla','Js','Jsp','K','Keycode','Kind2','Kneditor','L','Lib','Library','Like','Line','List','Local','Localhost','Log','M','Mail','Manageadmin','Master','Material','Mdb','Media','Members','Message','Min','Mng','Modify','Multi','My','Mysql','N','Navereditor','New','Newwebadmin','O','Oa','Ok','Old','Openwysiwyg','Orders','P','Paper','Pass','Password','Photo','Php','Phpcms','Phpmyadmin','Pic','Plugin','Plus','Pma','Pop','Popup','Popups','Popupsgecko','Post','Prcimageupload','Productedit','Q','Quick','R','Raineditor','Rar','Release','Resource','Root','S','S111','Sales','Sample','Samples','Scm','Se2','Seditordemo','Seed','Sell','Server','Shop','Shu','Shuju','Shujuku','Site','Siteweb','Sj','Sjk','Smart','Smarteditor','Smarteditor2','Smarteditor2skin','Spac','Sql','Sqldata','Src0811','Store','Swf','Swfupload','System','T','Tar','Tdi','Tdmain','Temp','Template','Test','Tgz','Tv','Txt','Typeimage0','U','Ueditor','Update','Upfile','Upfiles','Upload','Uploadaspx','Uploader','Uploadpic','Uploadpopup','Uploadtest','Upphoto','Upphoto2','User','Userlist','Users','V','V14','Vb','Vip','W','Wangzhan','Web','Web1','Webadmin','Webbak','Webconfig','Webedit','Webmysql','Webroot','Webservice','Website','Wm123','Wordpress','Wp','Write','Ww','Wwroot','Www','Wwwroot','Wx','Wysiwyg','Wz','X','Xxx','Y','Ysc','Z','Z9v8flashfxp','Z9v8ftp','Zip','7Z','__ZEP__/JS','A','ABOARD','ACCESS.LOG','ADD','ADDR','ADDRESS','ADM','ADMIN','AJAX','ALDITOR','ALDITORIMAGE','APP','ARCHIVE','ASP','ASPX','ATTACH','AUTH','B','BACK','BACKUP','BACKUPDATA','BACKUPS','BAK','BB','BBS','BEIAN','BEIFEN','BF','BIN','BIN/BIN','BIN/BIN1','BIN/BIN2','BIN/DLL','BIN/DLL1','BIN/DLL2','BIN1','BIN2','BOARD','BOSS','BROWSER','BZ2','C','CAPTCHA','CESHI','CGI','CHEDITOR','CHEDITOR4','CHEDITOR5','CHXIMAGE','CHXUPLOAD','CKEDITOR','CLIENTS','CMS','CODE','COM','COMMON','CONFIG','CONNECTORS','CONTENTS','COPY','COPY05','CUST','CUSTOMERS','D','DAT','DATA','DATABACK','DATABACKUP','DATABAK','DATABAKUP','DATABASE','DATABASEBAK','DATAD','DAUMEDITOR','DB','DBADMIN','DBCON','DBMYSQL','DEDE','DEDECMS','DEFAULT','DEV','DINGDAN','DIV','DLL','DNTB','DO','DOC','DOWNLOAD','DUMP','DZ','E','EDIT','EDITOR','EMAIL','EMFO','ENGINE','ENTRIES','ERROR','ERROR_LOG','EXAMPLE','EZWEB','F','FAISUNZIP','FCK2','FCKEDITOR','FILE','FILEMANAGER','FILENAME','FILES','FILESWF','FILEUPLOAD','FILEUPLOADSUBMIT','FLASH','FLASHFXP','FORM','FORUM','FOURM','FTP','FTP1','G','GBK','GG','GOOD','GZ','H','HDOCS','HELP','HOME','HTDOCS','HTM','HTML','HTMLEDITOR','HTTP','I','IDCONTENT','IDX','IIS','IISWEB','IMAGE','IMAGEEDITOR','IMAGEFRM','IMAGES','IMAGEUP','IMAGEUPLOAD','IMG','IMGUPLOAD','INC','INCLUDE','INDEX','INSERT','INSTALL','IR1','J','JOOMLA','JS','JSP','K','KEYCODE','KIND2','KNEDITOR','L','LIB','LIBRARY','LIKE','LINE','LIST','LOCAL','LOCALHOST','LOG','M','MAIL','MANAGEADMIN','MASTER','MATERIAL','MDB','MEDIA','MEMBERS','MESSAGE','MIN','MNG','MODIFY','MULTI','MY','MYSQL','N','NAVEREDITOR','NEW','NEWWEBADMIN','O','OA','OK','OLD','OPENWYSIWYG','ORDERS','P','PAPER','PASS','PASSWORD','PHOTO','PHP','PHPCMS','PHPMYADMIN','PIC','PLUGIN','PLUS','PMA','POP','POPUP','POPUPS','POPUPSGECKO','POST','PRCIMAGEUPLOAD','PRODUCTEDIT','Q','QUICK','R','RAINEDITOR','RAR','RELEASE','RESOURCE','ROOT','S','S111','SALES','SAMPLE','SAMPLES','SCM','SE2','SEDITORDEMO','SEED','SELL','SERVER','SHOP','SHU','SHUJU','SHUJUKU','SITE','SITEWEB','SJ','SJK','SMART','SMARTEDITOR','SMARTEDITOR2','SMARTEDITOR2SKIN','SPAC','SQL','SQLDATA','SRC0811','STORE','SWF','SWFUPLOAD','SYSTEM','T','TAR','TDI','TDMAIN','TEMP','TEMPLATE','TEST','TGZ','TV','TXT','TYPEIMAGE0','U','UEDITOR','UPDATE','UPFILE','UPFILES','UPLOAD','UPLOADASPX','UPLOADER','UPLOADPIC','UPLOADPOPUP','UPLOADTEST','UPPHOTO','UPPHOTO2','USER','USERLIST','USERS','V','V14','VB','VIP','W','WANGZHAN','WEB','WEB1','WEBADMIN','WEBBAK','WEBCONFIG','WEBEDIT','WEBMYSQL','WEBROOT','WEBSERVICE','WEBSITE','WM123','WORDPRESS','WP','WRITE','WW','WWROOT','WWW','WWWROOT','WX','WYSIWYG','WZ','X','XXX','Y','YSC','Z','Z9V8FLASHFXP','Z9V8FTP','ZIP']info_dic = []for a in tmp_info_dic:for b in tmp_suffixFormat:info_dic.extend([a + b])global outputfileif args.output_file:outputfile = args.output_fileelse:outputfile = 'result.txt'global proxiesif args.proxy:proxies = {'http': args.proxy,'https': args.proxy}else:proxies = ''header = Headers(headers=False)timeout = 10try:if args.dict_file:custom_dict = list(set([i.replace("\n", "") for i in open(str(args.dict_file), "r").readlines()]))info_dic.extend(custom_dict)if args.url:dispatcher(url=args.url, max_thread=args.max_threads, dic=info_dic)elif args.url_file:dispatcher(url_file=args.url_file, max_thread=args.max_threads, dic=info_dic)else:print("[!] Please specify a URL or URL file name")except Exception as e:print(e)
小备份字典:
python38 ihoneyBakFileScan_Modify_fx_smart.py -t 10 -f url.txt -o result_smart.txt
# -*- coding: UTF-8 -*-import requests
import logging
from argparse import ArgumentParser
from copy import deepcopy
from datetime import datetime
from hurry.filesize import size
from fake_headers import Headers
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import urllib.parse
from tqdm import tqdm # 引入 tqdm 库requests.packages.urllib3.disable_warnings()logging.basicConfig(level=logging.WARNING, format="%(message)s")# 存放不存活 URL 的集合,用于跳过重复的 URL
dead_urls = set()# 检查 URL 是否存活的函数
def check_url_status(url, retries=3):for _ in range(retries):try:response = requests.head(url, timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)if 200 <= response.status_code < 600:return response.status_codeexcept Exception:passtime.sleep(1) # 等待 1 秒后重试return None# 执行 URL 扫描的函数
def vlun(urltarget, retries=3):# 如果 URL 在不存活 URL 列表中,直接返回if urltarget in dead_urls:returnfor _ in range(retries):try:if proxies:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)else:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False)if r.status_code == 200 and all(keyword not in r.headers.get('Content-Type', '') for keyword in ['html', 'image', 'xml', 'text', 'json', 'javascript']):tmp_rarsize = int(r.headers.get('Content-Length', 0))rarsize = str(size(tmp_rarsize))if int(rarsize[:-1]) > 0:logging.warning('[ success ] {} size:{}'.format(urltarget, rarsize))with open(outputfile, 'a') as f:try:f.write(str(urltarget) + ' ' + 'size:' + str(rarsize) + '\n')except Exception as e:logging.warning(f"[ error ] Writing result failed: {e}")else:logging.warning('[ fail ] {}'.format(urltarget))returnelse:logging.warning('[ fail ] {}'.format(urltarget))returnexcept Exception as e:logging.warning('[ fail ] {}'.format(urltarget))time.sleep(1) # 等待 1 秒后重试# URL 不存活,记录根地址root_url = urllib.parse.urljoin(urltarget, '/')if root_url not in dead_urls:dead_urls.add(root_url)with open('waf_url.txt', 'a') as f:f.write(root_url + '\n')# 处理 URL 检查的函数
def urlcheck(target=None, ulist=None):if target is not None and ulist is not None:if target.startswith('http://') or target.startswith('https://'):if target.endswith('/'):ulist.append(target)else:ulist.append(target + '/')else:line = 'http://' + targetif line.endswith('/'):ulist.append(line)else:ulist.append(line + '/')return ulist# 分发处理 URL 的函数
def dispatcher(url_file=None, url=None, max_thread=20, dic=None):urllist = []if url_file is not None and url is None:with open(str(url_file)) as f:while True:line = str(f.readline()).strip()if line:urllist = urlcheck(line, urllist)else:breakelif url is not None and url_file is None:url = str(url.strip())urllist = urlcheck(url, urllist)else:passwith open(outputfile, 'a'):passcheck_urllist = []for u in urllist:cport = Noneif u.startswith('http://'):ucp = u.lstrip('http://')elif u.startswith('https://'):ucp = u.lstrip('https://')if '/' in ucp:ucp = ucp.split('/')[0]if ':' in ucp:cport = ucp.split(':')[1]ucp = ucp.split(':')[0]www1 = ucp.split('.')else:www1 = ucp.split('.')wwwlen = len(www1)wwwhost = ''for i in range(1, wwwlen):wwwhost += www1[i]current_info_dic = deepcopy(dic)suffixFormat = ['.zip','.rar','.txt','.tar.gz','.tgz','.gz']domainDic = [ucp, ucp.replace('.', ''), ucp.replace('.', '_'), wwwhost, ucp.split('.', 1)[-1],(ucp.split('.', 1)[1]).replace('.', '_'), www1[0], www1[1]]domainDic = list(set(domainDic))for s in suffixFormat:for d in domainDic:current_info_dic.extend([d + s])current_info_dic = list(set(current_info_dic))for info in current_info_dic:url = str(u) + str(info)check_urllist.append(url)urlist_len = len(urllist)check_urllist_len = len(check_urllist)per_distance = int(check_urllist_len / urlist_len)l = []p = ThreadPoolExecutor(max_thread)# 使用 tqdm 显示进度条with tqdm(total=check_urllist_len, desc="Scanning URLs") as pbar:futures = []for index1 in range(0, per_distance):for index2 in range(0, urlist_len):index = index2 * per_distance + index1if index < check_urllist_len:url = check_urllist[index]futures.append(p.submit(vlun, url))for future in as_completed(futures):future.result() # 等待任务完成pbar.update(1) # 更新进度条p.shutdown()if __name__ == '__main__':usageexample = '\n Example: python3 ihoneyBakFileScan_Modify.py -t 100 -f url.txt -o result.txt\n'usageexample += ' 'usageexample += 'python3 ihoneyBakFileScan_Modify.py -u https://www.example.com/ -o result.txt'parser = ArgumentParser(add_help=True, usage=usageexample, description='A Website Backup File Leak Scan Tool.')parser.add_argument('-f', '--url-file', dest="url_file", help="Example: url.txt", default="url.txt")parser.add_argument('-t', '--thread', dest="max_threads", nargs='?', type=int, default=1, help="Max threads")parser.add_argument('-u', '--url', dest='url', nargs='?', type=str, help="Example: http://www.example.com/")parser.add_argument('-d', '--dict-file', dest='dict_file', nargs='?', help="Example: dict.txt")parser.add_argument('-o', '--output-file', dest="output_file", help="Example: result.txt", default="result.txt")parser.add_argument('-p', '--proxy', dest="proxy", help="Example: socks5://127.0.0.1:1080")args = parser.parse_args()tmp_suffixFormat = ['.zip','.rar','.txt','.tar.gz','.tgz','.gz']tmp_info_dic = ['%e5%95%86%e5%9f%8e','%e5%a4%87%e4%bb%bd','%e5%ae%89%e8%a3%85%e6%96%87%e4%bb%b6','%e6%95%b0%e6%8d%ae','%e6%95%b0%e6%8d%ae%e5%a4%87%e4%bb%bd','%e6%95%b0%e6%8d%ae%e5%ba%93','%e6%95%b0%e6%8d%ae%e5%ba%93%e5%a4%87%e4%bb%bd','%e6%95%b0%e6%8d%ae%e5%ba%93%e6%96%87%e4%bb%b6','%e6%95%b4%e7%ab%99','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(1)','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(2)','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9(3)','%e6%96%b0%e5%bb%ba%e6%96%87%e6%9c%ac%e6%96%87%e6%a1%a3','%e6%9c%8d%e5%8a%a1%e5%99%a8','%e6%a8%a1%e6%9d%bf','%e6%ba%90%e7%a0%81','%e7%a8%8b%e5%ba%8f','%e7%ab%99%e7%82%b9','%e7%bd%91%e7%ab%99','%e7%bd%91%e7%ab%99%e5%a4%87%e4%bb%bd','%e8%af%b4%e6%98%8e','__zep__/js','1','10','11','111','111111','123','123123','1234','12345','123456','127.0.0.1','1314','1980','1981','1982','1983','1984','1985','1986','1987','1988','1989','1990','1991','1992','1993','1994','1995','1996','1997','1998','1999','2','2000','2001','2002','2003','2004','2005','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015','2016','2017','2018','2019','2020','2021','2022','2023','2024','2025','2026','2027','2028','2029','2030','3','4','5','520','6','7','7z','8','9','a','aboard','access.log','add','addr','address','adm','admin','ajax','alditor','alditorimage','app','archive','asp','aspx','attach','auth','b','back','backup','backupdata','backups','bak','bb','bbs','beian','beifen','bf','bin','bin/bin','bin/bin1','bin/bin2','bin/dll','bin/dll1','bin/dll2','bin1','bin2','board','boss','browser','bz2','c','captcha','ceshi','cgi','cheditor','cheditor4','cheditor5','chximage','chxupload','ckeditor','clients','cms','code','com','common','config','connectors','contents','copy','copy05','cust','customers','d','dat','data','databack','databackup','databak','databakup','database','databasebak','datad','daumeditor','db','dbadmin','dbcon','dbmysql','dede','dedecms','default','dev','dingdan','div','dll','dntb','do','doc','download','dump','dz','e','edit','editor','email','emfo','engine','entries','error','error_log','example','ezweb','f','faisunzip','fck2','fckeditor','file','filemanager','filename','files','fileswf','fileupload','fileuploadsubmit','flash','flashfxp','form','forum','fourm','ftp','ftp1','g','gbk','gg','good','gz','h','hdocs','help','home','htdocs','htm','html','htmleditor','http','i','idcontent','idx','iis','iisweb','image','imageeditor','imagefrm','images','imageup','imageupload','img','imgupload','inc','include','index','insert','install','ir1','j','joomla','js','jsp','k','keycode','kind2','kneditor','l','lib','library','like','line','list','local','localhost','log','m','mail','manageadmin','master','material','mdb','media','members','message','min','mng','modify','multi','my','mysql','n','navereditor','new','newwebadmin','o','oa','ok','old','openwysiwyg','orders','p','paper','pass','password','photo','php','phpcms','phpmyadmin','pic','plugin','plus','pma','pop','popup','popups','popupsgecko','post','prcimageupload','productedit','q','quick','r','raineditor','rar','release','resource','root','s','s111','sales','sample','samples','scm','se2','seditordemo','seed','sell','server','shop','shu','shuju','shujuku','site','siteweb','sj','sjk','smart','smarteditor','smarteditor2','smarteditor2skin','spac','sql','sqldata','src0811','store','swf','swfupload','system','t','tar','tdi','tdmain','temp','template','test','tgz','tv','txt','typeimage0','u','ueditor','update','upfile','upfiles','upload','uploadaspx','uploader','uploadpic','uploadpopup','uploadtest','upphoto','upphoto2','user','userlist','users','v','v14','vb','vip','w','wangzhan','web','web1','webadmin','webbak','webconfig','webedit','webmysql','webroot','webservice','website','wm123','wordpress','wp','write','ww','wwroot','www','wwwroot','wx','wysiwyg','wz','x','xxx','y','ysc','z','z9v8flashfxp','z9v8ftp','zip','安装文件','备份','程序','服务器','模板','商城','数据','数据备份','数据库','数据库备份','数据库文件','说明','网站','网站备份','新建文本文档','新建文件夹','新建文件夹(1)','新建文件夹(2)','新建文件夹(3)','源码','站点','整站']info_dic = []for a in tmp_info_dic:for b in tmp_suffixFormat:info_dic.extend([a + b])global outputfileif args.output_file:outputfile = args.output_fileelse:outputfile = 'result.txt'global proxiesif args.proxy:proxies = {'http': args.proxy,'https': args.proxy}else:proxies = ''header = Headers(headers=False)timeout = 10try:if args.dict_file:custom_dict = list(set([i.replace("\n", "") for i in open(str(args.dict_file), "r").readlines()]))info_dic.extend(custom_dict)if args.url:dispatcher(url=args.url, max_thread=args.max_threads, dic=info_dic)elif args.url_file:dispatcher(url_file=args.url_file, max_thread=args.max_threads, dic=info_dic)else:print("[!] Please specify a URL or URL file name")except Exception as e:print(e)
自己的字典:dicc.txt 就用自己的吧,
python38 ihoneyBakFileScan_Modify_fx_dir.py -t 10 -f url.txt -o results_dir.txt
# -*- coding: UTF-8 -*-import requests
import logging
from argparse import ArgumentParser
from copy import deepcopy
from datetime import datetime
from hurry.filesize import size
from fake_headers import Headers
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import urllib.parse
from tqdm import tqdm # 引入 tqdm 库requests.packages.urllib3.disable_warnings()logging.basicConfig(level=logging.WARNING, format="%(message)s")# 存放不存活 URL 的集合,用于跳过重复的 URL
dead_urls = set()# 自定义404页面路径
custom_404_path = '/8krrotrejtwejt3563657sewWWER'# 常见404页面的关键词和特征
common_404_keywords = ['404', 'not found', 'page not found', 'error 404', 'page does not exist']# 自定义404页面判断函数
def is_custom_404(url, retries=3):for _ in range(retries):try:response = requests.get(url + custom_404_path, timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)# 200 或 301 状态码视为自定义404if response.status_code in [200, 301]:return Trueexcept Exception:passtime.sleep(1) # 等待 1 秒后重试return False# 判断是否为常见404页面
def is_common_404(response):# 检查响应状态码if response.status_code == 404:# 解析响应内容content = response.text.lower()# 检查内容中是否包含常见404的关键词for keyword in common_404_keywords:if keyword in content:return Truereturn False# 执行 URL 扫描的函数
def vlun(urltarget, retries=3):# 如果 URL 在不存活 URL 列表中,直接返回if urltarget in dead_urls:returnfor _ in range(retries):try:if proxies:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False, proxies=proxies)else:r = requests.get(url=urltarget, headers=header.generate(), timeout=timeout, allow_redirects=False, stream=True, verify=False)# 检查是否为自定义404页面if is_custom_404(urltarget):logging.warning('[ fail ] {} (Custom 404 page detected)'.format(urltarget))return# 其他成功或失败的判断if r.status_code == 200 and all(keyword not in r.headers.get('Content-Type', '') for keyword in ['html', 'image', 'xml', 'text', 'json', 'javascript']):tmp_rarsize = int(r.headers.get('Content-Length', 0))rarsize = str(size(tmp_rarsize))if int(rarsize[:-1]) > 0:logging.warning('[ success ] {} size:{}'.format(urltarget, rarsize))with open(outputfile, 'a') as f:try:f.write(str(urltarget) + ' ' + 'size:' + str(rarsize) + '\n')except Exception as e:logging.warning(f"[ error ] Writing result failed: {e}")else:logging.warning('[ fail ] {}'.format(urltarget))returnelse:# 检查是否为常见的404页面if is_common_404(r):logging.warning('[ fail ] {} (Common 404 page detected)'.format(urltarget))else:logging.warning('[ fail ] {}'.format(urltarget))returnexcept Exception as e:logging.warning('[ fail ] {}'.format(urltarget))time.sleep(1) # 等待 1 秒后重试# URL 不存活,记录根地址root_url = urllib.parse.urljoin(urltarget, '/')if root_url not in dead_urls:dead_urls.add(root_url)with open('waf_url.txt', 'a') as f:f.write(root_url + '\n')# 处理 URL 检查的函数
def urlcheck(target=None, ulist=None):if target is not None and ulist is not None:if target.startswith('http://') or target.startswith('https://'):if target.endswith('/'):ulist.append(target)else:ulist.append(target + '/')else:line = 'http://' + targetif line.endswith('/'):ulist.append(line)else:ulist.append(line + '/')return ulist# 从字典文件中读取字典项
def load_dict_file(dict_file='dicc.txt'):dic = []with open(dict_file, 'r') as f:for line in f:stripped_line = line.strip()if stripped_line:dic.append(stripped_line.lstrip('/'))return dic# 生成所有扫描 URL
def generate_combinations(url, dic):combinations = []for entry in dic:full_url = urllib.parse.urljoin(url, entry)combinations.append(full_url)return combinationsdef dispatcher(url_file=None, url=None, max_thread=20, dic=None):urllist = []if url_file is not None and url is None:with open(str(url_file)) as f:while True:line = str(f.readline()).strip()if line:urllist = urlcheck(line, urllist)else:breakelif url is not None and url_file is None:url = str(url.strip())urllist = urlcheck(url, urllist)else:passwith open(outputfile, 'a'):passcheck_urllist = []for u in urllist:# 先检查根 URL 是否为自定义 404 页面if is_custom_404(u):logging.warning(f'[ fail ] {u} (Custom 404 page detected)')continue# 生成所有需要扫描的 URLcheck_urllist.extend(generate_combinations(u, dic))urlist_len = len(urllist)check_urllist_len = len(check_urllist)per_distance = int(check_urllist_len / urlist_len)l = []p = ThreadPoolExecutor(max_thread)# 使用 tqdm 显示进度条with tqdm(total=check_urllist_len, desc="Scanning URLs") as pbar:# 任务执行的代码futures = []for index1 in range(0, per_distance):for index2 in range(0, urlist_len):index = index2 * per_distance + index1if index < check_urllist_len:url = check_urllist[index]futures.append(p.submit(vlun, url))for future in as_completed(futures):future.result() # 等待任务完成pbar.update(1) # 更新进度条p.shutdown()if __name__ == '__main__':usageexample = '\n Example: python3 ihoneyBakFileScan_Modify.py -t 100 -f url.txt -o result.txt\n'usageexample += ' 'usageexample += 'python3 ihoneyBakFileScan_Modify.py -u https://www.example.com/ -o result.txt'parser = ArgumentParser(add_help=True, usage=usageexample, description='A Website Backup File Leak Scan Tool.')parser.add_argument('-f', '--url-file', dest="url_file", help="Example: url.txt", default="url.txt")parser.add_argument('-t', '--thread', dest="max_threads", nargs='?', type=int, default=1, help="Max threads")parser.add_argument('-u', '--url', dest='url', nargs='?', type=str, help="Example: http://www.example.com/")parser.add_argument('-o', '--output-file', dest="output_file", help="Example: result.txt", default="result.txt")parser.add_argument('-p', '--proxy', dest="proxy", help="Example: socks5://127.0.0.1:1080")args = parser.parse_args()# 从默认字典文件中加载自定义字典info_dic = load_dict_file('dicc.txt')global outputfileif (args.output_file):outputfile = args.output_fileelse:outputfile = 'result.txt'# 添加代理global proxiesif (args.proxy):proxies = {'http': args.proxy,'https': args.proxy}else:proxies = ''header = Headers(# generate any browser)timeout = 5 # Define the timeout valuedispatcher(url_file=args.url_file, url=args.url, max_thread=args.max_threads, dic=info_dic)
python38 -m pip install -r pip.txt
fake_headers==1.0.2
hurry==1.1
hurry.filesize==0.9
requests==2.31.0相关文章:

二开ihoneyBakFileScan备份扫描
优点:可以扫描根据域名生成的扫描备份的扫描工具 二开部分:默认网址到字典(容易被封),二开字典到网址(类似test404备份扫描规则),同时把被封不能扫描的网址保存到waf_url.txt 中&am…...

leetcode21. 合并两个有序链表
思路: 用一个新链表来表示合并后的有序链表, 每次比较两个链表,将较小的那个结点存储至新链表中 # Definition for singly-linked list. # class ListNode(object): # def __init__(self, val0, nextNone): # self.val val # …...

搭建 WordPress 及常见问题与解决办法
浪浪云活动链接 :https://langlangy.cn/?i8afa52 文章目录 环境准备安装 LAMP 堆栈 (Linux, Apache, MySQL, PHP)配置 MySQL 数据库 安装 WordPress配置 WordPress常见问题及解决办法数据库连接错误白屏问题插件或主题冲突内存限制错误 本文旨在介绍如何在服务器上…...
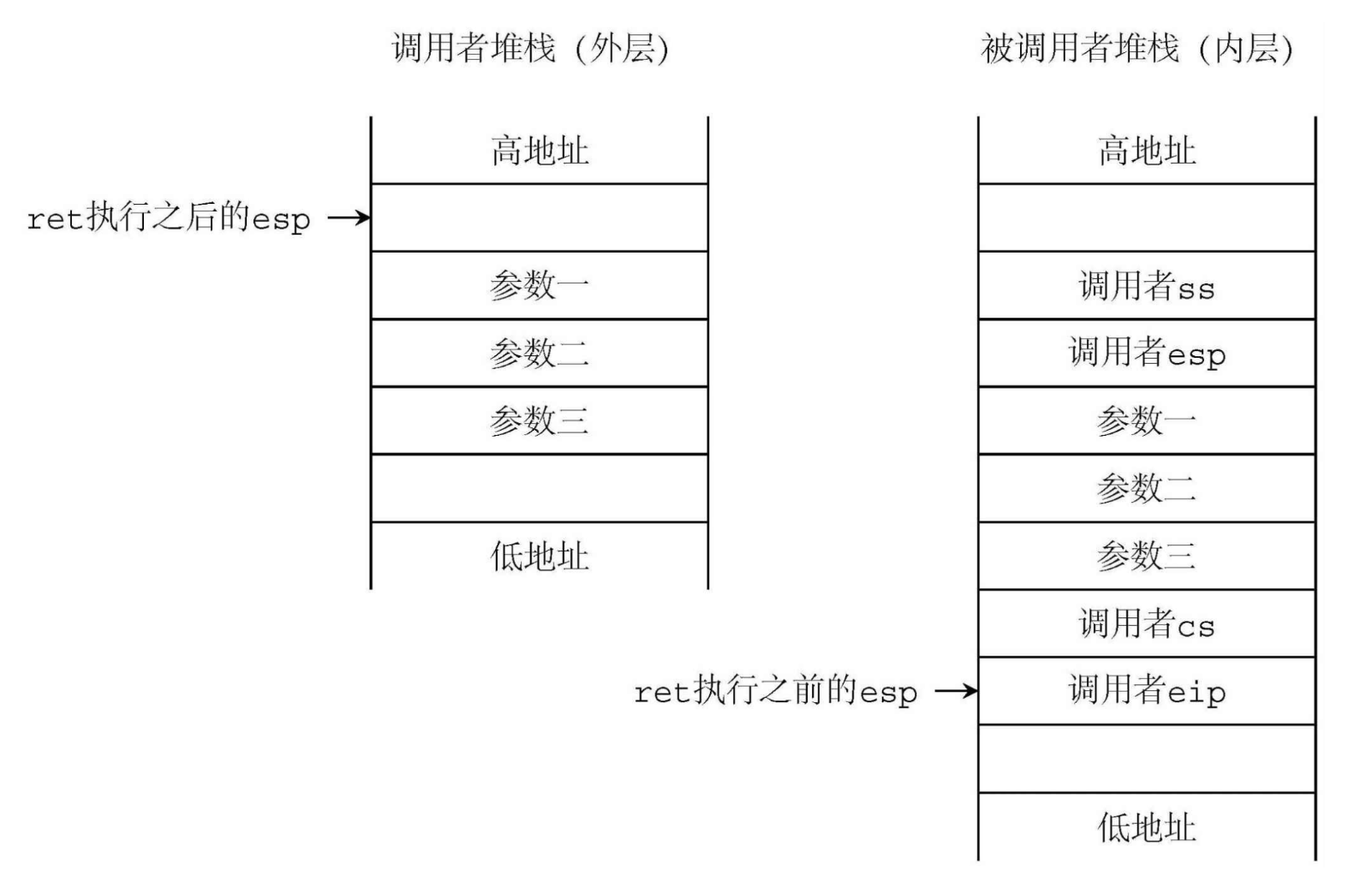
《ORANGE‘s 一个操作系统的实现》--保护模式进阶
保护模式进阶 大内存读写 GDT段 ;GDT [SECTION .gdt] ; 段基址, 段界限 , 属性 LABEL_GDT: Descriptor 0, 0, 0 ; 空描述符 LABEL_DESC_NORMAL: Descriptor 0, 0ffffh, DA_DRW ; Normal 描…...

【可变参模板】可变参类模板
可变参类模板也和可变参函数模板一样,允许模板定义含有0到多个(任意个)模板参数。可变参类模板参数包的展开方式有多种,以下介绍几种常见的方法。 一、递归继承展开 1.1类型模板参数包的展开 首先先看下面的代码: /…...

Linux 递归删除大量的文件
一般情况下 在 Ubuntu 中,递归删除大量文件和文件夹可以通过以下几种方式快速完成。常用的方法是使用 rm 命令,配合一些适当的选项来提高删除速度和效率。 1. 使用 rm 命令递归删除 最常见的方式是使用 rm 命令的递归选项 -r 来删除目录及其所有内容。…...

设计一个算法,找出由str1和str2所指向两个链表共同后缀的起始位置
假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,则可共享相同的后缀存储空间,例如,’loading’和’being’的存储映像如下图所示。 设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为 data…...

Python中如何判断一个变量是否为None
在Python中,判断一个变量是否为None是一个常见的需求,特别是在处理可选值、默认值或者是在函数返回结果可能不存在时。虽然这个操作本身相对简单,但围绕它的讨论可以扩展到Python的哲学、类型系统、以及如何在不同场景下优雅地处理None值。 …...

表观遗传系列1:DNA 甲基化以及组蛋白修饰
1. 表观遗传 表观遗传信息很多为化学修饰,包括 DNA 甲基化以及组蛋白修饰,即DNA或蛋白可以通过化学修饰添加附加信息。 DNA位于染色质(可视为微环境)中,并不是裸露的,因此DNA分子研究需要跟所处环境结合起…...

Android 跳转至各大应用商店应用详情页
测试通过机型品牌: 华为、小米、红米、OPPO、一加、Realme、VIVO、IQOO、荣耀、魅族、三星 import android.content.ActivityNotFoundException; import android.content.Context; import android.content.Intent; import android.content.pm.PackageInfo; import …...

Pywinauto鼠标操作指南
Pywinauto是一个强大的Python库,用于自动化Windows桌面应用程序的测试。它提供了一系列工具和API来模拟用户输入,包括键盘、鼠标事件,以及与各种窗口控件交互的能力。本文将详细介绍如何使用Pywinauto来执行鼠标操作,并通过一些示…...

VRAY云渲染动画怎么都是图片?
动画实际上是由一系列连续的静态图像(帧)组成的,当这些帧快速连续播放时,就形成了动画效果。每一帧都是一个单独的图片,需要单独渲染。 云渲染农场的工作方式: 1、用户将3D场景文件和动画设置上传到云渲染…...
)
共享内存(C语言)
目录 一、引言 二、共享内存概述 1.什么是共享内存 2.共享内存的优势 三、共享内存的实现 1.创建共享内存 2.关联共享内存 3.访问共享内存 4.解除共享内存关联 5.删除共享内存 四、共享内存应用实例 五、总结 本文将深入探讨C语言中的共享内存技术,介绍其原理、…...

《JavaEE进阶》----16.<Mybatis简介、操作步骤、相关配置>
本篇博客讲记录: 1.回顾MySQL的JDBC操作 2..Mybatis简介、Mybatis操作数据库的步骤 3.Mybatis 相关日志的配置(日志的配置、驼峰自动转换的配置) 前言 之前学习应用分层时我们知道Web应用程序一般分为三层,Controller、Service、D…...

HuggingFists算子能力扩展-PythonScript
HuggingFists作为一个低代码平台,很多朋友会关心如何扩展平台算子能力。扩展平台尚不支持的算子功能。本文就介绍一种通过脚本算子扩展算子能力的解决方案。 HuggingFists支持Python和Javascript两种脚语言的算子。两种语言的使用方式相同,使用者可以任选…...

WInform记录的添加和显示
1、程序 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;namespace ComboBoxApp {public part…...

★ C++基础篇 ★ string类的实现
Ciallo~(∠・ω< )⌒☆ ~ 今天,我将继续和大家一起学习C基础篇第五章下篇----string类的模拟实现 ~ 上篇:★ C基础篇 ★ string类-CSDN博客 C基础篇专栏:★ C基础篇 ★_椎名澄嵐的博客-CSDN博客 目录 一 基础结构 二 迭代器 …...

rman compress
级别 初始 备完 耗时 low 1804 3572 0:10 High 1812 3176 2:00 MEDIUM 1820 3288 0:13 BASIC 1828 3444 0:56 ---不如MEDIUM,时间还长 NO COMPRESS 1820 5924 0:5 R…...

创建一个Oracle版本的JDK的Docker镜像
背景说明 OpenJDK 和Oracle JDK 一般情况下我们选择OpenJDK,两者针对大部分场景都可以满足,有些地方例如反射技术获得某些包路径下的类对象等,有时候选择OpenJDK会导致空指针异常。 两者在底层实现方面有部分区别。 创建镜像 这里是Linux…...
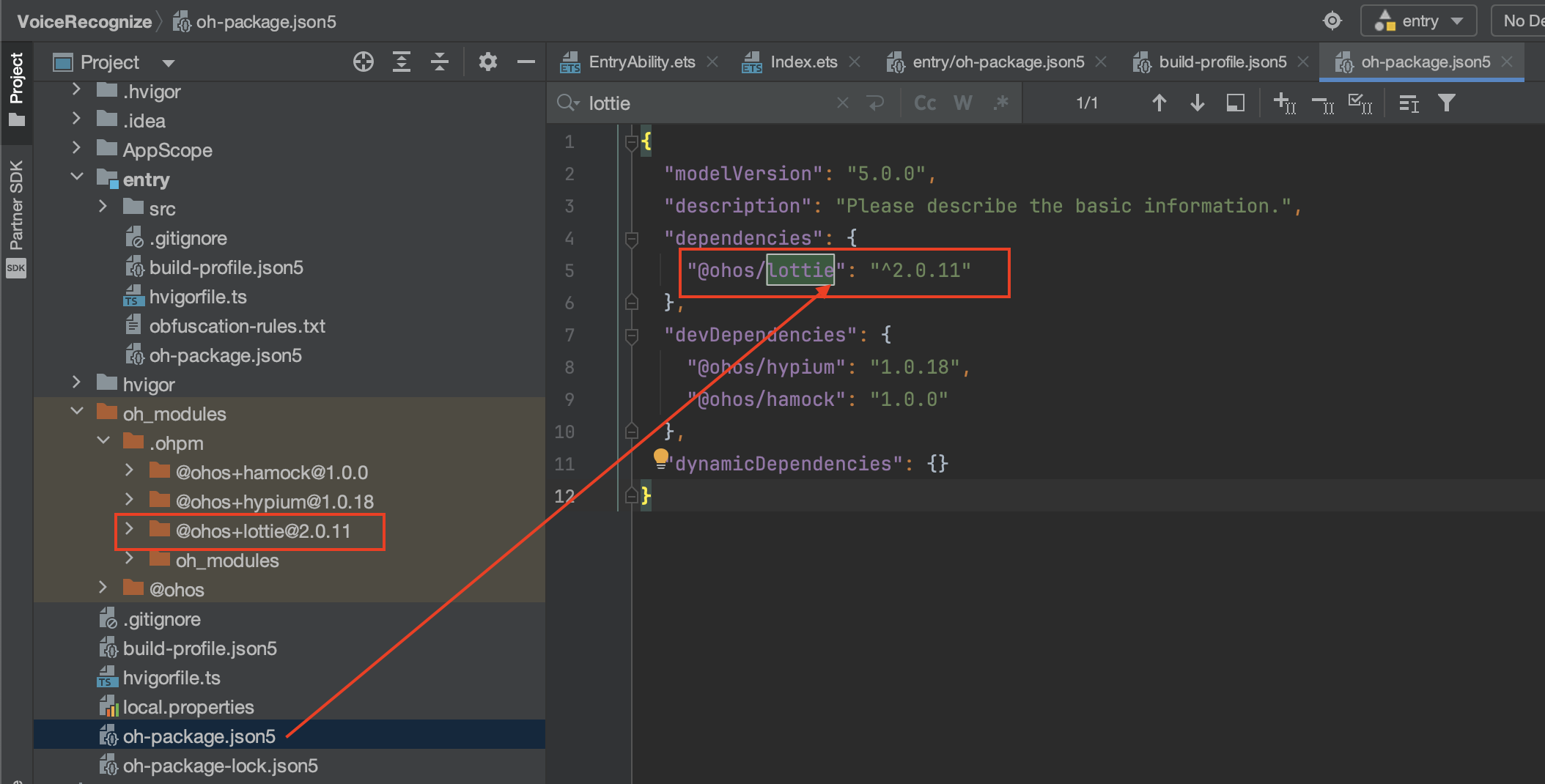
Harmony OS DevEco Studio 如何导入第三方库(以lottie为例)?-- HarmonyOS自学2
在做鸿蒙开发时,离不开第三方库的引入 一.有哪些支持的Harmony OS的 第三方库? 第三方库下载地址: 1 tpc_resource: 三方组件资源汇总 2 OpenHarmony三方库中心仓 二. 如何加入到DevEco Studio工程 以 lottie为例 OpenHarmony-TPC/lot…...

40希尔排序 - 以递减间距进行插入排序
希尔排序 - 以递减间距进行插入排序 040希尔排序:用长距离跳跃打破速度壁垒📰 5W1H 发明者故事 Who(何人)- 发明者是谁? 发明者:唐纳德希尔(Donald L. Shell) 背景:希尔…...

矩阵键盘原理与实战:从扫描算法到Arduino/CircuitPython驱动指南
1. 项目概述:为什么我们需要矩阵键盘? 在嵌入式项目里,给设备加几个按钮是再常见不过的需求。但如果你需要10个、12个甚至16个独立的按键呢?按照传统思路,一个按键对应一个微控制器的数字输入引脚,那你的Ar…...

创业团队如何利用多模型聚合平台优化产品开发流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用多模型聚合平台优化产品开发流程 对于小型创业团队而言,在快速迭代产品的过程中,大模型能…...

Minimax算法在技能学习中的应用:构建抗风险技术成长路径
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫justl9169/minimax-skills。光看名字,你可能会联想到“最小化-最大化”算法,也就是博弈论里那个经典的Minimax。没错,这个项目的核心灵感确实来源于此,但…...

2026年临沂GEO优化,哪家专业公司脱颖而出?
在当今数字化飞速发展的时代,GEO生成式引擎优化对于企业的重要性日益凸显。它能够让客户在第一时间找到公司、产品、品牌以及理念等。那么在2026年的临沂,哪家专业公司会在GEO优化领域脱颖而出呢?一、用户痛点亟待解决目前,众多企…...

微信数据库解密全攻略:3步解锁你的数字记忆宝库
微信数据库解密全攻略:3步解锁你的数字记忆宝库 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 微信数据库解密工具WechatDecrypt让你重新掌控被加密的聊天记录,实现个人数据的自主…...
)
告别迷茫!在嵌入式Linux上用libwebsockets v4.0实现WebSocket客户端(含SSL配置避坑)
嵌入式Linux实战:libwebsockets v4.0客户端开发与SSL避坑指南 当树莓派的GPIO引脚需要与云端实时同步数据时,WebSocket往往是嵌入式开发者的首选协议。但面对内存仅512MB的ARMv7开发板,选用一个既支持SSL加密又能兼容C99标准的轻量级库&#…...

OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程
OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

飞书自动化开发实战:从脚本编写到事件驱动架构设计
1. 项目概述:飞书自动化,从“手动挡”到“自动驾驶”的进化 如果你每天的工作,有超过30%的时间是在飞书里重复着“点击-填写-发送”的枯燥操作,比如手动拉取数据生成日报、定时向群聊推送消息、或者根据特定条件审批流程…...