深入解析全连接层:PyTorch 中的 nn.Linear、nn.Parameter 及矩阵运算
文章目录
- 数学概念(全连接层,线性层)
- nn.Linear()
- nn.Parameter()
- Q
- 1. 为什么 self.weight 的权重矩阵 shape 使用 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features)而不是 ( in_features , out_features ) (\text{in\_features}, \text{out\_features}) (in_features,out_features)?
- 2. 为什么是`torch.matmul(x, self.weight.T) + self.bias` 而不是`torch.matmul(self.weight, x) + self.bias`?
- 3. 为什么不直接设置`self.weight = nn.Parameter(torch.randn(input_dim, output_dim))`?
- 计算过程的细分:`torch.matmul()` vs `@` 运算符
- 使用 `F.linear()`
这篇文章会从基础的一个数学概念到对应的代码实现,你将了解到:
- 为什么
nn.Parameter()接受 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features)作为参数?- 为什么不是
torch.matmul(self.weight, x) + self.bias?- 如何使用
torch.matmul(),@或F.linear()去等价地实现nn.Linear()的输出。
数学概念(全连接层,线性层)
线性变化是数学中一个基础的概念,它描述了如何通过线性变换将输入映射到输出。在线性代数中,线性变化通常表示为矩阵乘法。在神经网络中,线性层的核心就是实现这样的矩阵运算。
数学公式:
给定一个输入向量 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn 和一个输出向量 y ∈ R m \mathbf{y} \in \mathbb{R}^m y∈Rm,线性变化通过矩阵 W ∈ R m × n \mathbf{W} \in \mathbb{R}^{m \times n} W∈Rm×n 和偏置项 b ∈ R m \mathbf{b} \in \mathbb{R}^m b∈Rm 进行变换,其公式为:
y = W x + b \mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b} y=Wx+b
- W \mathbf{W} W:是权重矩阵,维度为 m × n m \times n m×n,它决定了输入向量如何线性变换到输出空间;
- x \mathbf{x} x:是输入向量,维度为 n n n,表示特征数据;
- b \mathbf{b} b:是偏置向量,维度为 m m m,用来调整线性变换的输出;
- y \mathbf{y} y:是输出向量,维度为 m m m,是变换后的结果。
例子:
如果输入向量 x \mathbf{x} x 有 3 个特征,输出向量 y \mathbf{y} y 有 2 个特征,则权重矩阵 W \mathbf{W} W 的形状为 2 × 3 2 \times 3 2×3。假设:
W = [ 1 2 3 4 5 6 ] , x = [ 1 2 3 ] , b = [ 0 1 ] \mathbf{W} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}, \quad \mathbf{x} = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}, \quad \mathbf{b} = \begin{bmatrix} 0 \\ 1 \end{bmatrix} W=[142536],x= 123 ,b=[01]
线性变换计算为:
y = W x + b = [ 1 2 3 4 5 6 ] [ 1 2 3 ] + [ 0 1 ] = [ 14 32 ] + [ 0 1 ] = [ 14 33 ] \mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} + \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 14 \\ 32 \end{bmatrix} + \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 14 \\ 33 \end{bmatrix} y=Wx+b=[142536] 123 +[01]=[1432]+[01]=[1433]
矩阵运算过程:
[ 1 2 3 4 5 6 ] [ 1 2 3 ] = [ ( 1 × 1 ) + ( 2 × 2 ) + ( 3 × 3 ) ( 4 × 1 ) + ( 5 × 2 ) + ( 6 × 3 ) ] = [ 14 32 ] \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} = \begin{bmatrix} (1 \times 1) + (2 \times 2) + (3 \times 3) \\ (4 \times 1) + (5 \times 2) + (6 \times 3) \end{bmatrix} = \begin{bmatrix} 14 \\ 32 \end{bmatrix} [142536] 123 =[(1×1)+(2×2)+(3×3)(4×1)+(5×2)+(6×3)]=[1432]
nn.Linear()
nn.Linear() 会自动创建一个权重矩阵(Weight)和偏置项(Bias),并将它们应用到输入上。
代码示例:
import torch
import torch.nn as nn# 定义一个输入为3,输出为2的线性层
linear_layer = nn.Linear(3, 2)# 打印权重矩阵和偏置项
print("权重矩阵 W:")
print(linear_layer.weight)print("偏置项 b:")
print(linear_layer.bias)# 模拟输入向量
input_vector = torch.tensor([1.0, 2.0, 3.0])
output_vector = linear_layer(input_vector)
print("输出向量 y:")
print(output_vector)
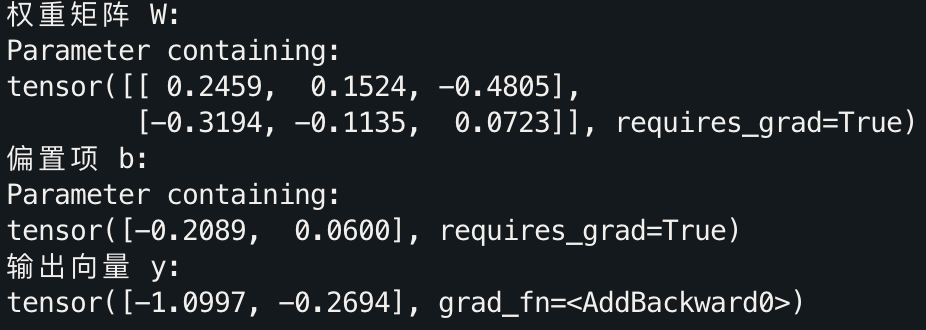
在这里,nn.Linear(3, 2) 创建了一个 2×3 的权重矩阵和一个 2 维的偏置向量。通过 linear_layer(input_vector),可以直接获得输入向量经过线性变换后的输出。
nn.Parameter()
在 PyTorch 中,nn.Linear() 自动处理了权重和偏置项的初始化和更新,但有时你可能希望对这些参数自定义一些操作,比如 LoRA。这时,我们可以使用 nn.Parameter() 来自定义权重和偏置,其实 nn.Linear() 本身就是使用的nn.Parameter(),感兴趣的话可以看官方源码。
以自定义线性层为例:
class CustomLinearLayer(nn.Module):def __init__(self, input_dim, output_dim):super(CustomLinearLayer, self).__init__()# 使用 nn.Parameter 手动定义权重和偏置self.weight = nn.Parameter(torch.randn(output_dim, input_dim))self.bias = nn.Parameter(torch.randn(output_dim))def forward(self, x):# 手动实现线性变换 y = Wx + breturn torch.matmul(x, self.weight.T) + self.bias# 使用自定义的线性层
custom_layer = CustomLinearLayer(3, 2)
output = custom_layer(input_vector)
print(output)

在看完代码后,你可能会产生两个疑惑:
Q
1. 为什么 self.weight 的权重矩阵 shape 使用 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features)而不是 ( in_features , out_features ) (\text{in\_features}, \text{out\_features}) (in_features,out_features)?
实际这正是我写这篇博客分享的原因,现在进入正题,因为这个疑惑完全不应该产生。
让我们重新使用 in_features \text{in\_features} in_features和 out_features \text{out\_features} out_features来重现之前的数学定义:
对于输入向量 x ∈ R in_features \mathbf{x} \in \mathbb{R}^{\text{in\_features}} x∈Rin_features,全连接层的输出为:
y = W x + b \mathbf{y} = W\mathbf{x} + \mathbf{b} y=Wx+b
其中:
- W ∈ R out_features × in_features W \in \mathbb{R}^{\text{out\_features} \times \text{in\_features}} W∈Rout_features×in_features 是权重矩阵,
- b ∈ R out_features \mathbf{b} \in \mathbb{R}^{\text{out\_features}} b∈Rout_features 是偏置项。
在线性变换中,输入向量 x \mathbf{x} x 的维度是 in_features \text{in\_features} in_features,而输出向量 y \mathbf{y} y 的维度是 out_features \text{out\_features} out_features。根据矩阵乘法的规则,要将输入 x \mathbf{x} x 映射到输出 y \mathbf{y} y,权重矩阵 W W W 的形状应该是 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features),因为矩阵乘法中 W x W\mathbf{x} Wx的维度要求是:
( out_features × in_features ) × ( in_features × 1 ) = ( out_features × 1 ) (\text{out\_features} \times \text{in\_features}) \times (\text{in\_features} \times 1) = (\text{out\_features} \times 1) (out_features×in_features)×(in_features×1)=(out_features×1)
这保证了输出 y \mathbf{y} y 的维度是 out_features \text{out\_features} out_features。
如果权重矩阵的形状是 ( in_features , out_features ) (\text{in\_features}, \text{out\_features}) (in_features,out_features),矩阵乘法的维度将不匹配,无法实现线性变换。
现在是不是感觉清晰了?不要 nn.Linear(in_feature, out_feature) 用多了就将权重矩阵当作是 ( in_features , out_features ) (\text{in\_features}, \text{out\_features}) (in_features,out_features)遗忘了线性代数的概念,数学才是这一切的基石。
2. 为什么是torch.matmul(x, self.weight.T) + self.bias 而不是torch.matmul(self.weight, x) + self.bias?
主要原因还是在于 输入张量 x 的形状 和 矩阵乘法规则。
一般来说,模型的输入 x 实际上并不是 ( in_features , 1 ) (\text{in\_features}, 1) (in_features,1),而是 ( batch_size , in_features ) (\text{batch\_size}, \text{in\_features}) (batch_size,in_features),而权重矩阵 self.weight 的形状是 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features),我们需要实现的线性变换是:
y = W x + b y = W x + b y=Wx+b
根据矩阵乘法规则,第一个矩阵的列数必须等于第二个矩阵的行数,这意味着我们不能直接计算 torch.matmul(self.weight, x),因为这样会导致维度不匹配:
self.weight形状为 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features),x形状为 ( batch_size , in_features ) (\text{batch\_size}, \text{in\_features}) (batch_size,in_features)。torch.matmul(self.weight, x)的维度计算规则将要求x的形状为 ( in_features , batch_size ) (\text{in\_features}, \text{batch\_size}) (in_features,batch_size),但这与模型的输入不匹配。
因此,正确的矩阵乘法应该是 torch.matmul(x, self.weight.T),其中 self.weight.T 表示 self.weight 的转置矩阵,此时的形状为 ( in_features , out_features ) (\text{in\_features}, \text{out\_features}) (in_features,out_features)。
这样,torch.matmul(x, self.weight.T) 的维度计算为:
( batch_size , in_features ) × ( in_features , out_features ) = ( batch_size , out_features ) (\text{batch\_size}, \text{in\_features}) \times (\text{in\_features}, \text{out\_features}) = (\text{batch\_size}, \text{out\_features}) (batch_size,in_features)×(in_features,out_features)=(batch_size,out_features)
这就得到了正确的输出形状 ( batch_size , in_features ) (\text{batch\_size}, \text{in\_features}) (batch_size,in_features)。
3. 为什么不直接设置self.weight = nn.Parameter(torch.randn(input_dim, output_dim))?
这样不就可以不转置直接使用torch.matmul(x, self.weight)了吗?的确如此,或许是因为 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features) 对于矩阵运算 W x W\mathbf{x} Wx 来讲更符合直觉吧。
计算过程的细分:torch.matmul() vs @ 运算符
在 PyTorch 中,torch.matmul() 用于实现矩阵乘法,而 @ 是其简洁的符号形式,是 Python 的语法糖,二者在功能上是等价的。
示例代码:
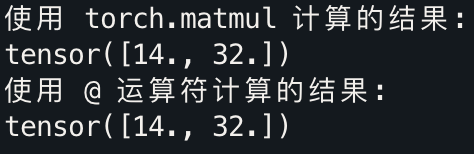
import torch# 定义权重矩阵 W 和输入向量 input_vector
W = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
input_vector = torch.tensor([1.0, 2.0, 3.0])# 使用 torch.matmul 实现矩阵乘法
result1 = torch.matmul(W, input_vector)# 使用 @ 运算符
result2 = W @ input_vectorprint("使用 torch.matmul 计算的结果:")
print(result1)print("使用 @ 运算符计算的结果:")
print(result2)
结果:
使用 F.linear()
PyTorch 提供了 F.linear() 作为函数式接口,它与 nn.Linear() 类似,但不需要创建一个线性层对象。F.linear() 可以接受线性层的权重和偏置作为输入,在下一篇有关 LoRA 的文章中,你将看到使用范例。
示例代码:
import torch.nn.functional as F# 使用 F.linear 进行线性变换
output = F.linear(input_vector, linear_layer.weight, linear_layer.bias)
print(output)

相关文章:
深入解析全连接层:PyTorch 中的 nn.Linear、nn.Parameter 及矩阵运算
文章目录 数学概念(全连接层,线性层)nn.Linear()nn.Parameter()Q1. 为什么 self.weight 的权重矩阵 shape 使用 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features)而不是 ( in_featur…...

缓存对象反序列化失败
未定义serialVersionUID,会自动生成序列化号 新增了属性,序列号就变了,导致缓存对象反序列化失败。 所有缓存对象必须指定序列化id! 那我如何找到未添加字段前 对象的序列化号呢?默认的序列化号是如何生成的呢&#…...

F28335的存储器与寄存器
1 存储器及CMD文件的编写 1 F28335的存储器 1.1 F28335存储器的结构 1.2 F28335存储器的映像 存储器本身不具有地址信息,它的地址是由芯片厂商或用户分配,给存储器分配地址的过程称为存储器映射,如果再分配一个地址就叫重映射。 我们将《tms320f28335 数据手册》中“3.1…...
方面的应用探讨)
Python在AOIP(Audio Over IP)方面的应用探讨
Python在AOIP(Audio Over IP)方面的应用探讨 引言 随着网络技术的发展,音频传输逐渐向基于IP的解决方案迁移。音频通过互联网进行传输被称为音频过IP(Audio Over IP,简称AOIP)。这种技术在广播、现场活动…...

C++20标准对线程库的改进:更安全、更高效的并发编程
引言 C20 是 C 语言的一个重要里程碑,它引入了许多新特性,其中就包括对线程库(thread)的重大改进。这些改进不仅增强了语言的并发编程能力,还解决了先前版本中的一些痛点问题。本文将详细介绍 C20 在线程方面的改进&a…...

外包干了三年,快要废了。。。
先简单说一下自己的情况,普通本科,在外包干了3年多的功能测试,这几年因为大环境不好,我整个人心惊胆战的,怕自己卷铺盖走人了,我感觉自己不能够在这样蹉跎下去了,长时间呆在一个舒适的环境真的会…...

微服务网关终极进化:设计模式驱动的性能与可用性优化(四)
时间:2024年09月12日 作者:小蒋聊技术 邮箱:wei_wei10163.com 微信:wei_wei10 希望大家帮个忙!如果大家有工作机会,希望帮小蒋推荐一下,小蒋希望遇到一个认真做事的团队,一起努力…...

Java中的服务端点日志记录:AOP与SLF4J
Java中的服务端点日志记录:AOP与SLF4J 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 在Java后端服务开发中,日志记录是监控和调试应用的关键手段。通过合理使用AOP&…...
黑马头条第八天实战(上)
D8 1)登录功能需求说明 用户根据用户名和密码登录密码需要手动加盐验证需要返回用户的token和用户信息 2)模块搭建思路步骤 2.1)模块作用 先捋一下之前搭模块干了啥 feign-api 远程调用 自媒体保存时调用远程客户端进行增加文章&#x…...

swift qwen2-vl推理及加载lora使用案例
参考: https://swift.readthedocs.io/zh-cn/latest/Instruction/LLM%E5%BE%AE%E8%B0%83%E6%96%87%E6%A1%A3.html#%E5%BE%AE%E8%B0%83%E5%90%8E%E6%A8%A1%E5%9E%8B https://blog.csdn.net/weixin_42357472/article/details/142150209 SWIFT支持300+ LLM和50+ MLLM(多模态大模型…...

如何使用 Choreographer 进行帧率优化
Choreographer 是 Android 提供的一个工具类,专门用来协调 UI 帧的渲染。你可以通过 Choreographer 来精确控制帧的绘制时机,以优化帧率,确保应用的流畅度。以下是如何使用 Choreographer 进行帧率优化的详细步骤: 1. 理解 Chore…...

稳定驱动之选SiLM5350系列SiLM5350MDBCA-DG单通道隔离栅极驱动器(带内部钳位):工业自动化的可靠伙伴
SiLM5350系列SiLM5350MDBCA-DG是具体有10A峰值输出电流能力,单通道隔离式栅极驱动器。SiLM5350MDBCA-DG可提供内部钳位功能。驱动电源电压为4V至30V。3V至18V的宽输入VDDI范围使驱动器适合与模拟和数字控制器接口。所有电源电压引脚都有欠压锁定 (UVLO) 保护。 SiLM…...

鸿蒙OpenHarmony【轻量系统芯片移植】内核移植
移植芯片架构 芯片架构的移植是内核移植的基础,在OpenHarmony中芯片架构移植是可选过程,如果当前OpenHarmony已经支持对应芯片架构则不需要移植操作,在“liteos_m/arch”目录下可看到当前已经支持的架构,如表1: 表1 …...

多字节字符和宽字符
小时候,买东西的单位是一角、二角和五角,现在的单位是一元、五元和十元。人类社会的发展和计算机发展本质没啥两样,形态不同而已。 编码格式的历史 尽管早期只用ASCII码就可以表达所有字符,但计算机日益推广让其他国家不同语言的…...

C++缺省参数
个人主页:Jason_from_China-CSDN博客 所属栏目:C系统性学习_Jason_from_China的博客-CSDN博客 缺省参数的概念 缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则…...

深度学习中的常用线性代数知识汇总——第一篇:基础概念、秩、奇异值
文章目录 0. 前言1. 基础概念2. 矩阵的秩2.1 秩的定义2.2 秩的计算方法2.3 秩在深度学习中的应用 3. 矩阵的奇异值3.1 奇异值分解(SVD)3.2 奇异值的定义3.3 奇异值的性质3.4 奇异值的意义3.5 实例说明3.6 奇异值在深度学习中的应用 0. 前言 按照国际惯例…...

MATLAB | R2024b更新了哪些好玩的东西?
Hey, 又到了一年两度的MATLAB更新时刻,MATLAB R2024b正式版发布啦!,直接来看看有哪些我认为比较有意思的更新吧! 1 小提琴图 天塌了,我这两天才写了个半小提琴图咋画,MATLAB 官方就出了小提琴图绘制方法。 小提琴图…...

嵌入式硬件基础知识
嵌入式硬件基础知识涵盖了嵌入式系统中的硬件组成及其工作原理,涉及处理器、存储器、外设接口、电源管理等多个方面。这些硬件共同构成了一个完整的嵌入式系统,用于执行特定任务。下面我们来详细介绍嵌入式硬件的基础知识。 1. 嵌入式系统的组成 嵌入式…...

keepalived和lvs高可用集群
keepavlied和lvs高可用集群搭建 主备模式: 关闭防火墙和selinux systemctl stop firewalld setenforce 0部署master负载调度服务器 zyj86 安装ipvsadm keepalived yum install -y keepalived ipvsadm修改主节点配置 vim /etc/keepalived/keepalived.conf! Conf…...

在VMware部署银河麒麟系统
虚拟机镜像安装文件从下面下载: 银河麒麟桌面操作系统V10SP1 2403 下载地址_银河麒麟v10镜像iso下载-CSDN博客 虚拟机安装要求硬盘大小至少40G,我悬着60G 选择桥接网络安装后上不了网并且和本机也互相ping不通,因此选择Nat方式,然后重启,就可以上网 下面开始安装,第一个…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

框架式幕墙与单元式幕墙的价格差异
框架式幕墙与单元式幕墙的价格差异 框架式幕墙与单元式幕墙由于结构及安装方式的不同,在价格方面存着很大的差异。主要表现在以下几个方面: 铝型材的用量: 框架式幕墙铝型材用量一般在7—9 kg/平方米左右。 单元式幕墙铝型材用量一般在13—15kg/平方米左右。 两者每平方…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南
C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南 在C语言开发中,结构体、枚举和联合体是构建复杂数据模型的三大基石。但很多开发者在实际项目中常遇到这样的困惑:为什么结构体占用的内存比预期大?枚举变量在…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...