16 训练自己语言模型
在很多场景下下,可能微调模型并不能带来一个较好的效果。因为特定领域场景下,通用话模型过于通用,出现多而不精。样样通样样松;本章主要介绍如何在特定的数据上对模型进行预训练;
训练自己的语言模型(从头开始训练)与微调(fine-tuning)预训练模型之间的选择取决于多个因素,包括但不限于数据特性、任务需求、计算资源和时间成本。以下是一些原因,解释为什么有时候你可能想要训练自己的语言模型,而不是仅仅微调现有的预训练模型:
训练自己的语言模型(从头开始训练)与微调(fine-tuning)预训练模型之间的选择取决于多个因素,包括但不限于数据特性、任务需求、计算资源和时间成本。以下是一些原因,解释为什么有时候你可能想要训练自己的语言模型,而不是仅仅微调现有的预训练模型:
1. **领域特异性**:如果你的工作涉及非常专业的领域,如医疗健康、法律或金融,那么现有的预训练模型可能没有包含足够的领域相关数据。在这种情况下,从头开始训练一个模型,使用专门领域的大量文本数据,可以让模型更好地理解和生成专业领域的文本。
2. **数据量大且独特**:如果你拥有大量的专有数据,这些数据具有独特的特点,那么训练一个模型以充分利用这些数据的独特性可能更有意义。预训练模型通常是在广泛的数据集上训练的,可能无法捕捉到特定数据集中存在的细微差别。
3. **控制模型架构**:训练自己的模型允许你完全控制模型架构的选择,包括层数、隐藏单元的数量以及其他超参数。这对于研究或开发新方法特别有用。
4. **避免偏见和数据污染**:预训练模型可能包含了来自其训练数据的某些偏见。如果你希望避免这些偏见,或者你的任务要求极高精度而不能容忍任何潜在的偏见,那么训练一个干净的新模型可能是更好的选择。
5. **数据隐私和安全**:对于处理敏感数据的情况,从头开始训练模型可以确保所有数据都保留在内部系统中,而不必担心将数据发送到外部服务器进行微调。
6. **探索新的模型架构**:对于学术研究来说,开发和训练新型的模型架构是一个重要的方向。这通常需要从零开始训练模型,以便全面地测试和验证新设计的有效性。
7. **资源可用性**:如果你有充足的计算资源(如高性能GPU集群),那么从头训练模型可能并不是一个问题,并且可能带来更好的长期投资回报。
尽管如此,训练自己的语言模型是一项耗时且资源密集型的任务。如果你的数据集不大,或者任务领域与现有预训练模型的数据集重叠较多,那么微调一个预训练模型通常是更为高效和实用的选择。微调可以让你快速地适应特定任务,同时保持较高的准确性和较低的成本。
1 数据准备
选择一个中文为主的语料进行训练。
https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered
 |
2 模型
选择使用BERT模型:
需要注意的是模型类别不同使用的方法也不一样的:
1. Encoder-Decoder Models(编码器-解码器模型):EncoderDecoderModel
典型代表:Transformer(如BERT)、Seq2Seq(如T5) 训练方法:
- 掩码语言建模(Masked Language Modeling, MLM):在训练过程中随机遮盖输入序列的一部分单词,然后让模型预测这些被遮盖的单词。
- 序列到序列任务(Sequence-to-Sequence Tasks):如机器翻译、文本摘要等,输入一个源序列,输出一个目标序列。
2. Decoder-Only Models(解码器模型):AutoModelForCausalLM
典型代表:GPT系列(如GPT-2、GPT-3)、BLOOM 训练方法:
- 因果语言建模(Causal Language Modeling, CLM):在训练过程中,模型预测序列中的下一个词,仅依赖于序列中的先前词。这是一种自回归式的训练方法,即每次预测下一个词时,只看前面的词。
- 文本生成:这类模型非常适合生成连贯的文本序列,因为它们可以逐词生成文本,并且保证生成的文本是连贯的。
3. Encoder-Only Models(编码器模型):AutoModelForMaskedLM
典型代表:RoBERTa 训练方法:
- 掩码语言建模(MLM):类似于BERT,但在训练过程中可能采用不同的掩码策略。
- 句子对预测(Next Sentence Prediction, NSP):虽然RoBERTa不再使用NSP,但在早期的一些模型中,这种方法用于预测两个句子是否相邻。
https://hf-mirror.com/google-bert/bert-base-chinese

下面是一个去掉部分词的标签:

from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForMaskedLM, DataCollatorForLanguageModeling, TrainingArguments, Trainerds = Dataset.load_from_disk("../data/wiki_chines_filter/")
ds#ds[1]#定义一个过滤函数
def filter_function(example):# 确保返回布尔值if 'completion' in example and isinstance(example['completion'], str) and example['completion']:return Truereturn Falseds = ds.filter(lambda example: filter_function(example))
dstokenizer = AutoTokenizer.from_pretrained("../bert-base-chinese/")def process_func(examples):#print(examples)contents = [e + tokenizer.sep_token for e in examples["completion"]]return tokenizer(contents, max_length=384, truncation=True)
# try:
# contents = [e + tokenizer.eos_token for e in examples["completion"]]
# return tokenizer(contents, max_length=384, truncation=True)
# except:#print(examples['completion'])#exit()
tokenized_ds = ds.map(process_func, batched=True, remove_columns=ds.column_names)
tokenized_dsfrom torch.utils.data import DataLoader
dl = DataLoader(tokenized_ds, batch_size=2, collate_fn=DataCollatorForLanguageModeling(tokenizer, mlm=False))model = AutoModelForMaskedLM.from_pretrained("../bert-base-chinese/")args = TrainingArguments(output_dir="./causal_lm",per_device_train_batch_size=2,gradient_accumulation_steps=16,logging_steps=10,num_train_epochs=1,#fp16=True
)
trainer = Trainer(args=args,model=model,tokenizer=tokenizer,train_dataset=tokenized_ds,data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15)
)
trainer.train()相关文章:
16 训练自己语言模型
在很多场景下下,可能微调模型并不能带来一个较好的效果。因为特定领域场景下,通用话模型过于通用,出现多而不精。样样通样样松;本章主要介绍如何在特定的数据上对模型进行预训练; 训练自己的语言模型(从头开…...

udp网络通信 socket
套接字是实现进程间通信的编程。IP可以标定主机在全网的唯一性,端口可以标定进程在主机的唯一性,那么socket通过IP端口号就可以让两个在全网唯一标定的进程进行通信。 套接字有三种: 域间套接字:实现主机内部的进程通信的编程 …...

LG AI研究开源EXAONE 3.0:一个7.8B双语语言模型,擅长英语和韩语,在实际应用和复杂推理中表现出色
EXAONE 3.0介绍:愿景与目标 EXAONE 3.0是LG AI研究所在语言模型发展中的一个重要里程碑,特别是在专家级AI领域。 “EXAONE”这个名称源自于“ EX pert A I for Every ONE”,反映了LG AI研究所致力于将专家级别的人工智能能力普及化的承诺。这…...
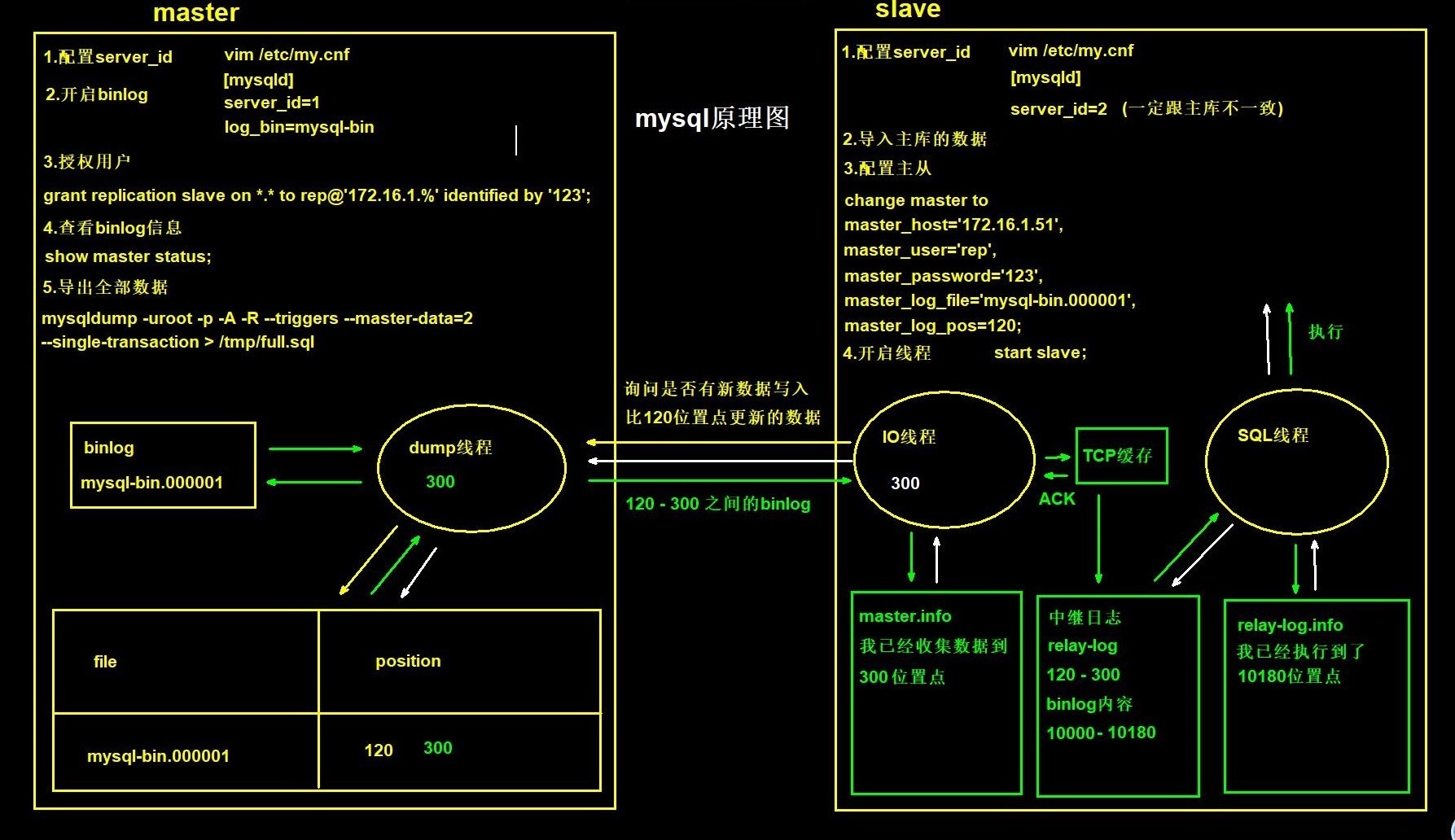
【mysql】mysql之主从部署以及介绍
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...
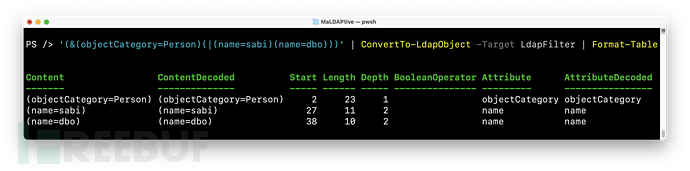
Invoke-Maldaptive:一款针对LDAP SearchFilter的安全分析工具
关于Invoke-Maldaptive MaLDAPtive 是一款针对LDAP SearchFilter的安全分析工具,旨在用于对LDAP SearchFilter 执行安全解析、混淆、反混淆和安全检测。 其基础是 100% 定制的 C# LDAP 解析器,该解析器处理标记化和语法树解析以及众多自定义属性&#x…...

QT 读取Excel表
一、QAxObject 读取excel表的内容,其仅在windows下生效,当然还有其他跨平台的方案。 config qaxcontainer #include <QAxObject>QStringList GetSheets(const QString& strPath) {QAxObject* excel new QAxObject("Excel.Application&…...

深入理解 Vue 组件样式管理:Scoped、Deep 和 !important 的使用20240909
深入理解 Vue 组件样式管理:Scoped、Deep 和 !important 的使用 在前端开发中,样式的管理与组件化开发之间的平衡一直是一个难题。Vue.js 提供了一些强大的工具来帮助开发者在开发复杂的应用时管理样式。这篇文章将详细介绍 Vue 中的 scoped、:deep() 和…...

C语言内存函数(21)
文章目录 前言一、memcpy的使用和模拟实现二、memmove的使用和模拟实现三、memset函数的使用四、memcmp函数的使用总结 前言 正文开始,发车! 一、memcpy的使用和模拟实现 函数模型:void* memcpy(void* destination, const void* source, size…...

三高基本概念之-并发和并行
并行和并发是计算机科学中两个重要但容易混淆的概念,它们之间的主要区别可以从以下几个方面进行阐述: 一、定义与含义 并行(Parallel):并行是指两个或多个事件在同一时刻发生,即这些事件在微观和宏观上都…...

宝塔面板FTP连接时“服务器发回了不可路由的地址。使用服务器地址代替。”
参考 https://blog.csdn.net/neizhiwang/article/details/106628899 错误描述 我得服务器是腾讯,然后使用宝塔建了个HTML网站,寻思用ftp上传,结果报错: 状态: 连接建立,等待欢迎消息... 状态: 初始化 TLS 中... 状…...

面试的一些小小经验
无论何时,找到合适的满意的工作(距离住处的地理位置,薪资,工作氛围)并不是一件容易的事情。个人能力与职位的适配性永远是有误差的客观存在。 十全十美难得,满足个人的个体化优先级才是客观的存在。 1.投简…...

IV转换放大器原理图及PCB设计分析
【前言】 今天给大家分享一下关于IV转换放大器的相关电路设计心得。IV转换使用的场合非常之多,尤其是电流型输出的传感器,比如光敏二极管、硅光电池等等,这些传感器输出的电流信号非常微弱,我们如果需要检测它们,首先得…...

【数学建模经验贴】一个研赛数模老手的经验
我(非C君,是一个朋友)参加了3次“深圳杯”数模,1次全国大学生数模,以及1次全国研究生数模,2016年参加了全国研究生数模的交流会,但没有参加过美赛,应该算是一个江湖老手了吧。下面内…...
vivo手机已删除的短信还能恢复吗?
虽然现在我们很少使用vivo手机的短信功能,但是我们偶尔还会通过vivo手机短信功能接收一些重要的信息。如果我们在清理垃圾短信的时候误删了vivo手机重要短信,该怎么恢复呢? 方法一:通过vivo云服务恢复 1、确保您已开启vivo云服务…...

[网络][CISCO]CISCO IOS升级
CISCO IOS升级-(转)2008-06-27 15:35IOS 升级 在介绍CISCO路由器IOS升级方法前,有必要对Cisco路由器的存储器的相关知识作以简单介绍。路由器与计算机相似,它也有内存和操作系统。在Cisco路由器中,其操作系统叫做互连…...
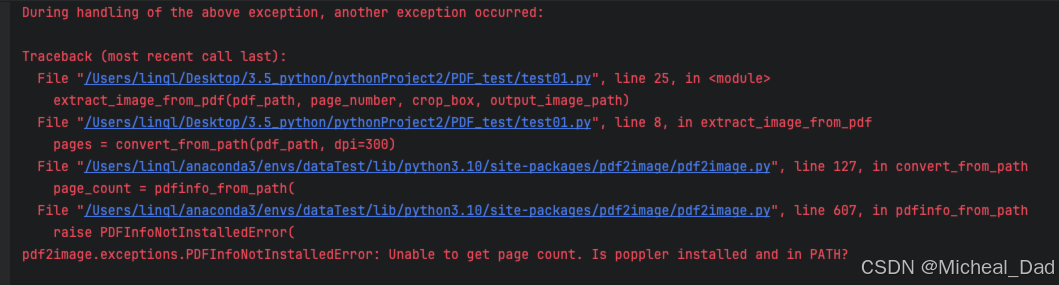
通过python提取PDF文件指定页的图片
整体思路 要从 PDF 文件中提取指定页和指定位置的图片,可以分几个步骤来实现: 1.1 准备所需工具与库 在 Python 中处理 PDF 和图像时,需要使用几个库: PyMuPDF (fitz):用于读取和处理 PDF 文件,可以精确…...
)
Leetcode Hot 100刷题记录 -Day12(轮转数组)
轮转数组 问题描述: 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4]解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向…...
)
GitHub每日最火火火项目(9.13)
以下是对这些项目的详细介绍: fishaudio 的 fish-speech: 基本信息:这是一种全新的语音技术解决方案,属于文本到语音(Text-to-Speech,TTS)技术范畴。技术特点: 多语言支持ÿ…...

力扣--649.Dota2参议院
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇) Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参…...

vim 安装与配置教程(详细教程)
vim就是一个功能非常强大的文本编辑器,可以自己DIY的那种 ,不但可以写代码 ,还可编译 ,可以让你手不离键盘的完成鼠标的所有操作。 如果想要了解vim的的发展历史和详细解说,可以自行上网搜索,我主要是记录一…...

3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式
3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在当今数字内容时代ÿ…...

深度神经网络参数安全与Hessian-aware训练防御技术
1. 深度神经网络参数安全威胁现状深度神经网络(DNN)在内存中的参数面临着严重的比特翻转安全威胁。这种威胁主要来自两个方面:自然发生的硬件故障和人为发起的攻击行为。在IEEE-754 32位浮点数表示中,一个比特的翻转可能导致参数值发生灾难性变化。例如&…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...

【BK3633】从规格书到实战:解锁蓝牙5.2双模芯片的十大核心应用场景
1. BK3633芯片核心特性解析 第一次拿到BK3633规格书时,我被它的参数惊艳到了——这简直是为物联网设备量身定制的瑞士军刀。作为博通集成推出的蓝牙5.2双模芯片,它完美兼顾了高性能与低功耗这对"冤家"。实测下来,全速运行电流仅5mA…...
)
MATLAB调用C/C++库报错?手把手教你配置Visual Studio 2022编译器(含低版本MATLAB适配指南)
MATLAB调用C/C库报错?手把手教你配置Visual Studio 2022编译器(含低版本MATLAB适配指南) 当你在MATLAB中尝试调用C/C库时,突然弹出一个令人头疼的错误提示:"未找到支持的编译器或 SDK"。这种情况在工程开发和…...

FPGA开发入门:从零开始用Vivado实现LED流水灯项目
1. 项目概述与核心价值最近在后台和社群里,看到不少刚接触FPGA开发的朋友,特别是从单片机或嵌入式软件转过来的,对于如何上手第一个完整的FPGA项目感到有些迷茫。大家常问:“我学了Verilog语法,也跑过仿真了࿰…...
GalTransl代码架构分析:理解多进程插件系统的设计原理
GalTransl代码架构分析:理解多进程插件系统的设计原理 【免费下载链接】GalTransl 支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案 Automated translation solution for visual novels supporting GPT-4/Claude/Deepseek/Sakura 项目地…...

书匠策AI到底怎么帮你“生“出毕业论文?一个论文博主的拆解笔记
各位深夜还在跟Word较劲的同学们,我是那个天天教别人写论文、自己也被论文折磨过的教育博主。 今天不讲写作技巧,讲一个我自己反复用、觉得真能帮到人的工具——书匠策AI。 官网直达 官网直达:www.shujiangce.com微信搜一搜"书匠策AI…...

通过curl命令直接测试Taotoken聊天补全接口的配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与调用 在对接大模型服务时,有时我们希望在引入完整SDK之前ÿ…...

离线语音技术如何重塑智能照明:从核心原理到产品实战
1. 从“在线”到“离线”:智能照明交互的范式转变作为一名在智能家居领域摸爬滚打了十来年的从业者,我亲眼见证了智能照明从最初的手机APP遥控,到后来的智能音箱联动,再到如今离线语音技术的兴起。每次技术迭代,都不仅…...