动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习
- 动手学习RAG: 向量模型
- 动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习
- 动手学习RAG:迟交互模型colbert微调实践 bge-m3
1. 环境准备
pip install transformers
pip install open-retrievals
- 注意安装时是
pip install open-retrievals,但调用时只需要import retrievals - 欢迎关注最新的更新 https://github.com/LongxingTan/open-retrievals
2. 使用M3E模型
from retrievals import AutoModelForEmbeddingembedder = AutoModelForEmbedding.from_pretrained('moka-ai/m3e-base', pooling_method='mean')
embedder

sentences = ['* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem','* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练','* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]embeddings = embedder.encode(sentences)for sentence, embedding in zip(sentences, embeddings):print("Sentence:", sentence)print("Embedding:", embedding)print("")

3. deepspeed 微调m3e模型
数据仍然采用之前介绍的t2-ranking数据集
- deepspeed配置保存为
ds_zero2_no_offload.json. 不过虽然设置了zero2,这里我只用了一张卡. 但deepspeed也很容易扩展到多卡,或多机多卡- 关于deepspeed的分布式设置,可参考Tranformer分布式特辑
{"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 100,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1e-10},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 1e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 1e8,"contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
这里稍微修改了open-retrievals这里的代码,主要是修改了导入为包的导入,而不是相对引用。保存文件为embed.py
"""Embedding fine tune pipeline"""import logging
import os
import pickle
from dataclasses import dataclass, field
from pathlib import Path
from typing import List, Optionalimport torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, HfArgumentParser, TrainingArguments, set_seedfrom retrievals import (EncodeCollator,EncodeDataset,PairCollator,RetrievalTrainDataset,TripletCollator,
)
from retrievals.losses import AutoLoss, InfoNCE, SimCSE, TripletLoss
from retrievals.models.embedding_auto import AutoModelForEmbedding
from retrievals.trainer import RetrievalTrainer# os.environ["WANDB_LOG_MODEL"] = "false"
logger = logging.getLogger(__name__)@dataclass
class ModelArguments:model_name_or_path: str = field(metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"})config_name: Optional[str] = field(default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"})tokenizer_name: Optional[str] = field(default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"})cache_dir: Optional[str] = field(default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"})causal_lm: bool = field(default=False, metadata={'help': "Whether the model is a causal lm or not"})lora_path: Optional[str] = field(default=None, metadata={'help': "Lora adapter save path"})@dataclass
class DataArguments:data_name_or_path: str = field(default=None, metadata={"help": "Path to train data"})train_group_size: int = field(default=2)unfold_each_positive: bool = field(default=False)query_max_length: int = field(default=32,metadata={"help": "The maximum total input sequence length after tokenization for passage. Sequences longer ""than this will be truncated, sequences shorter will be padded."},)document_max_length: int = field(default=128,metadata={"help": "The maximum total input sequence length after tokenization for passage. Sequences longer ""than this will be truncated, sequences shorter will be padded."},)query_instruction: str = field(default=None, metadata={"help": "instruction for query"})document_instruction: str = field(default=None, metadata={"help": "instruction for document"})query_key: str = field(default=None)positive_key: str = field(default='positive')negative_key: str = field(default='negative')is_query: bool = field(default=False)encoding_save_file: str = field(default='embed.pkl')def __post_init__(self):# self.data_name_or_path = 'json'self.dataset_split = 'train'self.dataset_language = 'default'if self.data_name_or_path is not None:if not os.path.isfile(self.data_name_or_path) and not os.path.isdir(self.data_name_or_path):info = self.data_name_or_path.split('/')self.dataset_split = info[-1] if len(info) == 3 else 'train'self.data_name_or_path = "/".join(info[:-1]) if len(info) == 3 else '/'.join(info)self.dataset_language = 'default'if ':' in self.data_name_or_path:self.data_name_or_path, self.dataset_language = self.data_name_or_path.split(':')@dataclass
class RetrieverTrainingArguments(TrainingArguments):train_type: str = field(default='pairwise', metadata={'help': "train type of point, pair, or list"})negatives_cross_device: bool = field(default=False, metadata={"help": "share negatives across devices"})temperature: Optional[float] = field(default=0.02)fix_position_embedding: bool = field(default=False, metadata={"help": "Freeze the parameters of position embeddings"})pooling_method: str = field(default='cls', metadata={"help": "the pooling method, should be cls or mean"})normalized: bool = field(default=True)loss_fn: str = field(default='infonce')use_inbatch_negative: bool = field(default=True, metadata={"help": "use documents in the same batch as negatives"})remove_unused_columns: bool = field(default=False)use_lora: bool = field(default=False)use_bnb_config: bool = field(default=False)do_encode: bool = field(default=False, metadata={"help": "run the encoding loop"})report_to: Optional[List[str]] = field(default="none", metadata={"help": "The list of integrations to report the results and logs to."})def main():parser = HfArgumentParser((ModelArguments, DataArguments, RetrieverTrainingArguments))model_args, data_args, training_args = parser.parse_args_into_dataclasses()model_args: ModelArgumentsdata_args: DataArgumentstraining_args: TrainingArgumentsif (os.path.exists(training_args.output_dir)and os.listdir(training_args.output_dir)and training_args.do_trainand not training_args.overwrite_output_dir):raise ValueError(f"Output directory ({training_args.output_dir}) already exists and is not empty. ""Use --overwrite_output_dir to overcome.")logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,)logger.warning("Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",training_args.local_rank,training_args.device,training_args.n_gpu,bool(training_args.local_rank != -1),training_args.fp16,)logger.info("Training/evaluation parameters %s", training_args)logger.info("Model parameters %s", model_args)logger.info("Data parameters %s", data_args)set_seed(training_args.seed)tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,cache_dir=model_args.cache_dir,use_fast=False,)if training_args.use_bnb_config:from transformers import BitsAndBytesConfiglogger.info('Use quantization bnb config')quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16,)else:quantization_config = Noneif training_args.do_train:model = AutoModelForEmbedding.from_pretrained(model_name_or_path=model_args.model_name_or_path,pooling_method=training_args.pooling_method,use_lora=training_args.use_lora,quantization_config=quantization_config,)loss_fn = AutoLoss(loss_name=training_args.loss_fn,loss_kwargs={'use_inbatch_negative': training_args.use_inbatch_negative,'temperature': training_args.temperature,},)model = model.set_train_type("pairwise",loss_fn=loss_fn,)train_dataset = RetrievalTrainDataset(args=data_args,tokenizer=tokenizer,positive_key=data_args.positive_key,negative_key=data_args.negative_key,)logger.info(f"Total training examples: {len(train_dataset)}")trainer = RetrievalTrainer(model=model,args=training_args,train_dataset=train_dataset,data_collator=TripletCollator(tokenizer,query_max_length=data_args.query_max_length,document_max_length=data_args.document_max_length,positive_key=data_args.positive_key,negative_key=data_args.negative_key,),)Path(training_args.output_dir).mkdir(parents=True, exist_ok=True)trainer.train()# trainer.save_model(training_args.output_dir)model.save_pretrained(training_args.output_dir)if trainer.is_world_process_zero():tokenizer.save_pretrained(training_args.output_dir)if training_args.do_encode:model = AutoModelForEmbedding.from_pretrained(model_name_or_path=model_args.model_name_or_path,pooling_method=training_args.pooling_method,use_lora=training_args.use_lora,quantization_config=quantization_config,lora_path=model_args.lora_path,)max_length = data_args.query_max_length if data_args.is_query else data_args.document_max_lengthlogger.info(f'Encoding will be saved in {training_args.output_dir}')encode_dataset = EncodeDataset(args=data_args, tokenizer=tokenizer, max_length=max_length, text_key='text')logger.info(f"Number of train samples: {len(encode_dataset)}, max_length: {max_length}")encode_loader = DataLoader(encode_dataset,batch_size=training_args.per_device_eval_batch_size,collate_fn=EncodeCollator(tokenizer, max_length=max_length, padding='max_length'),shuffle=False,drop_last=False,num_workers=training_args.dataloader_num_workers,)embeddings = model.encode(encode_loader, show_progress_bar=True, convert_to_numpy=True)lookup_indices = list(range(len(encode_dataset)))with open(os.path.join(training_args.output_dir, data_args.encoding_save_file), 'wb') as f:pickle.dump((embeddings, lookup_indices), f)if __name__ == "__main__":main()- 最终调用文件
shell run.sh
MODEL_NAME="moka-ai/m3e-base"TRAIN_DATA="/root/kag101/src/open-retrievals/t2/t2_ranking.jsonl"
OUTPUT_DIR="/root/kag101/src/open-retrievals/t2/ft_out"# loss_fn: infonce, simcsedeepspeed -m --include localhost:0 embed.py \--deepspeed ds_zero2_no_offload.json \--output_dir $OUTPUT_DIR \--overwrite_output_dir \--model_name_or_path $MODEL_NAME \--do_train \--data_name_or_path $TRAIN_DATA \--positive_key positive \--negative_key negative \--pooling_method mean \--loss_fn infonce \--use_lora False \--query_instruction "" \--document_instruction "" \--learning_rate 3e-5 \--fp16 \--num_train_epochs 5 \--per_device_train_batch_size 32 \--dataloader_drop_last True \--query_max_length 64 \--document_max_length 256 \--train_group_size 4 \--logging_steps 100 \--temperature 0.02 \--save_total_limit 1 \--use_inbatch_negative false

4. 测试
微调前性能 c-mteb t2-ranking score

微调后性能

采用infoNCE损失函数,没有加in-batch negative,而关注的是困难负样本,经过微调map从0.654提升至0.692,mrr从0.754提升至0.805
对比一下非deepspeed而是直接torchrun的微调
- map略低,mrr略高。猜测是因为deepspeed中设置的一些auto会和直接跑并不完全一样

相关文章:
动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习
动手学习RAG: 向量模型动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习动手学习RAG:迟交互模型colbert微调实践 bge-m3 1. 环境准备 pip install transformers pip install open-retrievals注意安装时是pip install open-retrievals,但调用时只…...

Nacos rce-0day漏洞复现(nacos 2.3.2)
Nacos rce-0day漏洞复现(nacos 2.3.2) NACOS是 一个开源的服务发现、配置管理和服务治理平台,属于阿里巴巴的一款开源产品。影像版本:nacos2.3.2或2.4.0版本指纹:fofa:app“NACOS” 从 Github 官方介绍文档可以看出国…...

yjs04——matplotlib的使用(多个坐标图)
1.多个坐标图与一个图的折线对比 1.引入包;字体(同) import matplotlib.pyplot as plt import random plt.rcParams[font.family] [SimHei] plt.rcParams[axes.unicode_minus] False 2.创建幕布 2.1建立图层幕布 一个图:plt.fig…...

MOS管和三极管有什么区别?
MOS管是基于金属-氧化物-半导体结构的场效应晶体管,它的控制电压作用于氧化物层,通过调节栅极电势来控制源漏电流。MOS管是FET中的一种,现主要用增强型MOS管,分为PMOS和NMOS。 MOS管的三个极分别是G(栅极),D(漏极)&…...
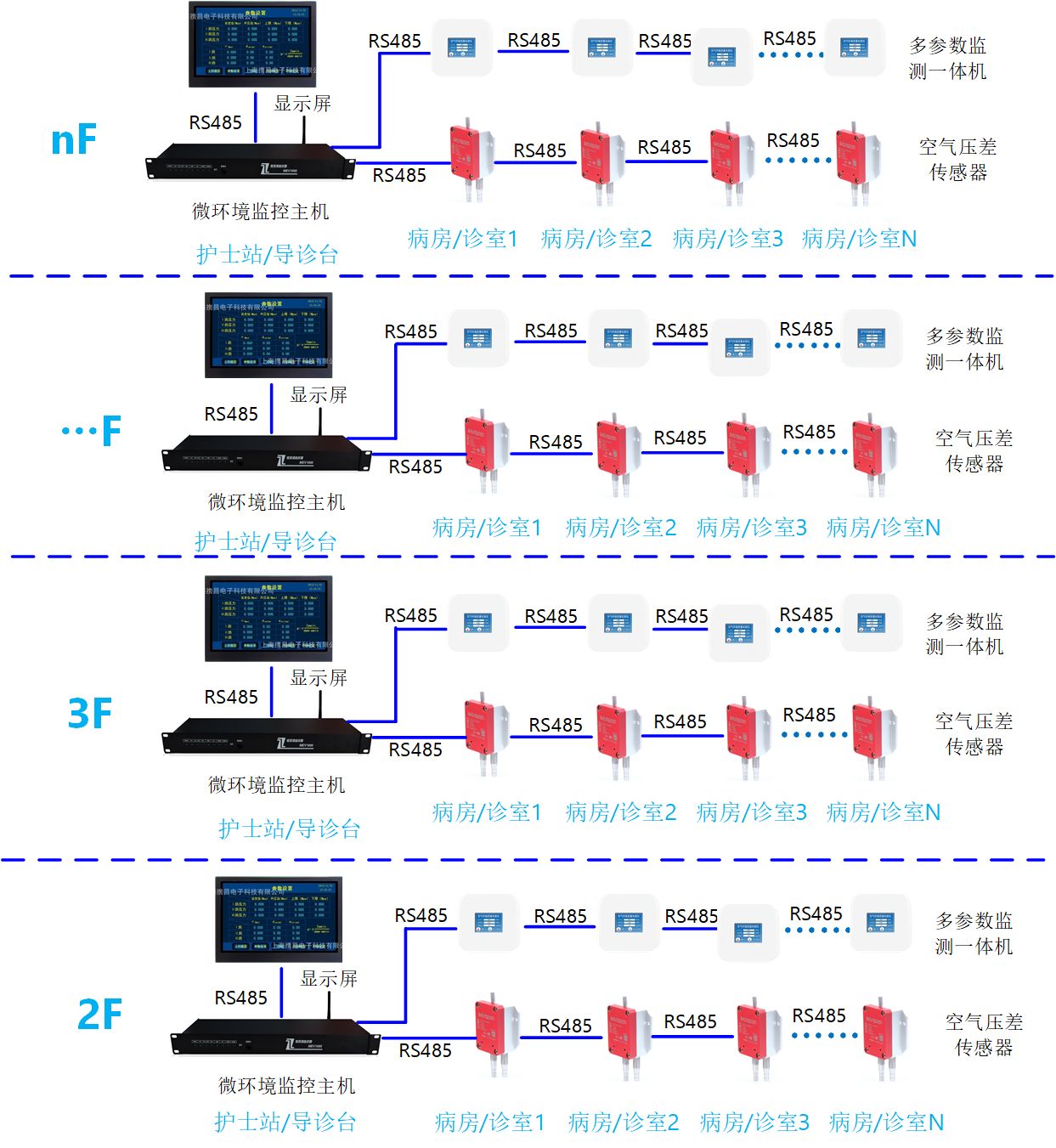
医院多参数空气质量监控和压差监测系统简介@卓振思众
在现代医院管理中,确保患者和医疗人员的健康与安全是首要任务。为实现这一目标,医院需要依赖高科技设施来维持最佳的环境条件。特别是,多参数空气质量监测系统和压差监测系统在这一方面发挥了不可替代的作用。【卓振思众】多参数空气质量监测…...

[项目实战]EOS多节点部署
文章总览:YuanDaiMa2048博客文章总览 EOS多节点部署 (一)环境设计(二)节点配置(三)区块信息同步(四)启动节点并验证同步EOS单节点的环境如何配置 (一…...
 vs setTimeout() 在 JavaScript 中的区别)
setImmediate() vs setTimeout() 在 JavaScript 中的区别
setImmediate() vs setTimeout() 在 JavaScript 中的区别 在 JavaScript 中,setImmediate() 和 setTimeout() 都用于调度任务,但它们的工作方式不同。 JavaScript 的异步特性 JavaScript 以其非阻塞、异步行为而闻名,尤其是在 Node.js 环境…...

【Java文件操作】文件系统操作文件内容操作
文件系统操作 常见API 在Java中,File类是用于文件和目录路径名的抽象表示。以下是一些常见的方法: 构造方法: File(String pathname):根据给定的路径创建一个File对象。File(String parent, String child):根据父路径…...

关于若依flowable的安装
有个项目要使用工作流功能,在网上看了flowable的各种资料,最后选择用若依RuoYi-Vue-Flowable这个项目来迁移整合。 一、下载项目代码: 官方项目地址:https://gitee.com/shenzhanwang/Ruoyi-flowable/ 二、新建数据库ÿ…...
)
猜数字困难版(1-10000)
小游戏,通过提示每次猜高或猜低以及每次猜中的位数,10次内猜中1-10000的一个数。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthde…...

ASPICE术语表
术语来源描述活动Automotive SPICE V4.0由利益相关方或参与方执行的任务用参数Automotive SPICE V4.0应用参数是包含了在系统或软件层级可被更改的数据的软件变量,他们影响系统或软件的行为和属性。应用参数的概念有两种表达方式:规范(分别包括变量名称、值域范围、…...

Knife4j:打造优雅的SpringBoot API文档
1. 为什么需要API文档? 在现代软件开发中,API文档的重要性不言而喻。一份清晰、准确、易于理解的API文档不仅能够提高开发效率,还能降低前后端沟通成本。今天,我们要介绍的Knife4j正是这样一款强大的API文档生成工具,它专为Spring Boot项目量身打造,让API文档的生成…...
数学建模笔记—— 多目标规划
数学建模笔记—— 多目标规划 多目标规划1. 模型原理1.1 多目标规划的一般形式1.2 多目标规划的解1.3 多目标规划的求解 2. 典型例题3. matlab代码实现 多目标规划 多目标规划是数学规划的一个分支。研究多于一个的目标函数在给定区域上的最优化。又称多目标最优化。通常记为 …...

【鸿蒙HarmonyOS NEXT】页面之间相互传递参数
【鸿蒙HarmonyOS NEXT】页面之间相互传递参数 一、环境说明二、页面之间相互传参 一、环境说明 DevEco Studio 版本: API版本:以12为主 二、页面之间相互传参 说明: 页面间的导航可以通过页面路由router模块来实现。页面路由模块根据页…...

SonicWall SSL VPN曝出高危漏洞,可能导致防火墙崩溃
近日,有黑客利用 SonicWall SonicOS 防火墙设备中的一个关键安全漏洞入侵受害者的网络。 这个不当访问控制漏洞被追踪为 CVE-2024-40766,影响到第 5 代、第 6 代和第 7 代防火墙。SonicWall于8月22日对其进行了修补,并警告称其只影响防火墙的…...
采购订单信息)
关于SAP标准委外(带料外协)采购订单信息
业务背景: 业务部门提出需要将售料外协方式变更为带料外协,带料外协实际业务存在一个委外订单存在多次发料,且每次发票需要进行齐套发料,不同批次的发料涉及物料替代。在半成品收货时需要进行对发料的组件进行扣料。 需求分析&a…...

SpringBoot整合WebSocket实现消息推送或聊天功能示例
最近在做一个功能,就是需要实时给用户推送消息,所以就需要用到 websocket springboot 接入 websocket 非常简单,只需要下面几个配置即可 pom 文件 <!-- spring-boot-web启动器 --><dependency><groupId>org.springframewo…...

使用 QEMU 模拟器运行 FreeRTOS 实时操作系统
文章目录 QEMU 官网QEMU 文档QEMU 简介QEMU 安装QEMU 命令启动虚拟机串口控制台监控命令行 FreeRTOS安装编译工具FreeRTOS 源码RISC-V-Qemu-virt_GCC 示例编译 RISC-V-Qemu-virt_GCC启动虚拟机运行 FreeRTOS QEMU 官网 https://www.qemu.org/ QEMU 文档 https://www.qemu.or…...

Oracle EBS中AR模块的财务流程概览
应收账款 (AR) 模块是Oracle E-Business Suite (EBS) 中另一个重要的财务管理模块,主要用于管理企业销售过程中的账款回收。下面是AR模块中的一些关键财务流程及其详细说明: 1. 销售订单管理 创建销售订单:当客户下单时,销售人员…...

Minitab 的直方图结果分析解释
Minitab 的直方图结果分析解释 步骤 1:评估关键特征 检查分布的尖峰和散布。评估样本数量对直方图外观的影响。 标识尖峰(即,条的最高聚类): 尖峰表示样本中最常见的值。评估样本的散布以了解数据的变异程度。例如…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验?
如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验? 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv 想要在智能电视上享受专业的媒体管理体验吗?…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

Arm Neoverse CMN-700多芯片架构与一致性哈希解析
1. Arm Neoverse CMN-700多芯片架构解析在现代高性能计算领域,多芯片系统架构已成为突破单芯片性能瓶颈的关键技术路径。Arm Neoverse CMN-700作为第二代一致性网状网络控制器,其设计哲学体现在三个维度:首先是通过模块化设计实现计算单元的可…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

MCP-Commander:让AI助手操作本地文件与命令行的智能接口
1. 项目概述:一个连接思维与执行的智能接口最近在折腾AI工作流的时候,发现了一个挺有意思的项目,叫nmindz/mcp-commander。乍一看这个名字,可能有点摸不着头脑,但如果你正在尝试让大型语言模型(LLM…...

【Clickhouse从入门到精通】第03篇:ClickHouse适用场景深度剖析
上一篇【第02篇】ClickHouse横空出世——天下武功唯快不破 下一篇【第04篇】ClickHouse生态全景与生产实践者巡礼 摘要 技术选型是数据架构设计的核心命题。再优秀的工具,若用错了场景,也会事倍功半。ClickHouse 以"极速分析查询"著称&#x…...