Kafka原理剖析之「Topic创建」
一、前言
Kafka提供了高性能的读写,而这些读写操作均是操作在Topic上的,Topic的创建就尤为关键,其中涉及分区分配策略、状态流转等,而Topic的新建语句非常简单
bash kafka-topics.sh \
--bootstrap-server localhost:9092 \ // 需要写入endpoints
--create --topic topicA // 要创建的topic名称
--partitions 10 // 当前要创建的topic分区数
--replication-factor 2 // 副本因子,即每个TP创建多少个副本因此Topic的创建可能并不像表明上操作的那么简单,这节我们就阐述一下Topic新建的细节
以下论述基于Kafka 2.8.2版本
二、整体流程
Topic新建分2部分,分别是
- 用户调用对应的API,然后由Controller指定分区分配策略,并将其持久化至Zookeeper中
- Controller负责监听Zookeeper的回调函数拿到元数据变更后,触发状态机并真正执行副本分配
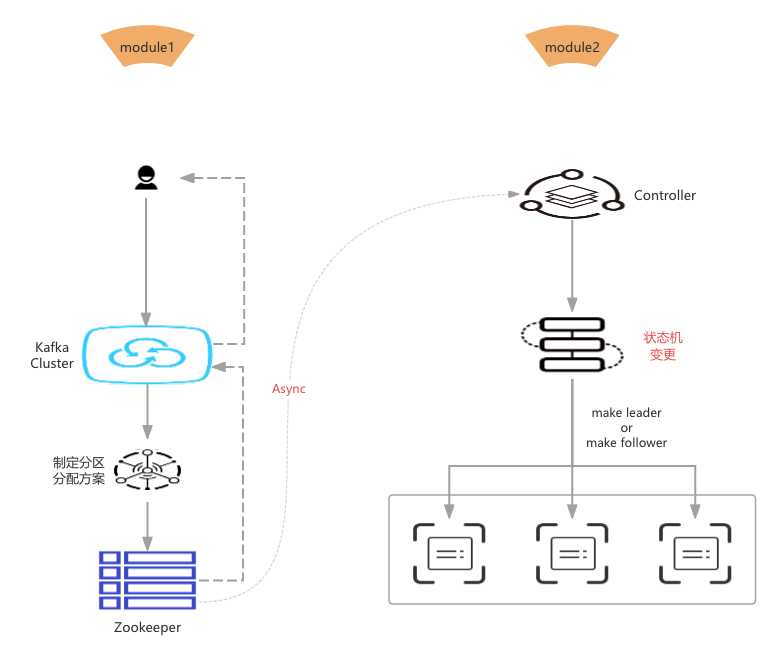
用户发起一个Topic新建的请求,Controller收到请求后,开始制定分区分配方案,继而将分配方案持久化到Zookeeper中,然后就向用户返回结果
而在Controller中专门监听Zookeeper节点变化的线程(当然这个线程与创建Topic的线程是异步的),当发现有变更后,将会异步触发状态机进行状态流转,后续会将对应的Broker设置为Leader或Follower
三、Topic分区分配方案
在模块一中,主要的流程是3部分:
- 用户向Controller发起新增Topic请求
- Controller收到请求后,开始制定该Topic的分区分配策略
- Controller将制定好的策略持久化至Zookeeper中
而上述描述中,流程1、3都是相对好理解的,我们着重要说的是流程2,即分区分配策略。Kafka分区制定方案核心逻辑放在 scala/kafka/admin/AdminUtils.scala 中,分为无机架、有机架两种,我们核心看一下无机架的策略
无机架策略中,又分为Leader Replica及Follow Replica两种
3.1、Leader Partition
而关于Leader及Follower的分配策略统一在方法kafka.admin.AdminUtils#assignReplicasToBrokersRackUnaware中,此方法只有20多行,我们简单来看一下
private def assignReplicasToBrokersRackUnaware(nPartitions: Int, // 目标topic的分区总数replicationFactor: Int, // topic副本因子brokerList: Seq[Int], // broker列表fixedStartIndex: Int, // 默认情况传-1startPartitionId: Int /* 默认情况传-1 */): Map[Int, Seq[Int]] = {val ret = mutable.Map[Int, Seq[Int]]()val brokerArray = brokerList.toArray// leader针对broker列表的开始index,默认会随机选取val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)// 默认为0,从0开始var currentPartitionId = math.max(0, startPartitionId)// 这个值主要是为分配Follower Partition而用var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)// 这里开始对partition进行循环遍历for (_ <- 0 until nPartitions) {// 这个判断逻辑,影响follower partitionif (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))nextReplicaShift += 1// 当前partition的第一个replica,也就是leader// 由于startIndex是随机生成的,因此firstReplicaIndex也是从broker list中随机取一个val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length// 存储了当前partition的所有replica的数组val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))for (j <- 0 until replicationFactor - 1)replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))ret.put(currentPartitionId, replicaBuffer)currentPartitionId += 1}ret
}由此可见,Topic Leader Replica的分配策略是相对简单的,我们再简单概括一下它的流程
- 从Broker List中随机选取一个Broker,作为 Partition 0 的 Leader
- 之后开始遍历Broker List,依次创建Partition 1、Partition 2、Partition 3....
- 如果遍历到了Broker List末尾,那么重定向到0,继续向后遍历
假定我们有5个Broker,编号从1000开始,分别是1000、1001、1002、1003、1004,假定partition 0随机选举的broker是1000,那么最终的分配策略将会是如下:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader Partition | 0 | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 |
而假定partition 0随机选举的broker是1002,那么最终的分配策略将会是如下:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader Partition | 3 | 4 | 0 | 1 | 2 |
| 8 | 9 | 5 | 6 | 7 |
这样做的目的是将Partition尽可能地打乱,将Partition Leader分配到不同的Broker上,避免数据热点
然而这个方案也并不是完美的,它只是会将当前创建的Topic Partition Leader打散,并没有考虑其他Topic Partition的分配情况,假定我们现在创建了5个Topic,均是单分区的,而正好它们都落在Broker 1000上,下一次我们创建新Topic的时,它的Partition 0依旧可能落在Broker 1000上,造成数据热点。不过因为是随机创建,因此当Topic足够多的情况时,还是能保证相对离散
3.2、Follower Partition
Leader Replica已经确定下来,接下来就是要制定Follower的分配方案,Follower的分配方案至少要满足以下2点要求
- Follower要随机打散在不同的Broker上,主要是做高可用保证,当Leader Broker不可用时,Follower要能顶上
- Follower的分配还不能太随机,因为如果真的全部随机分配的话,可能出现某个Broker比其他Broker的replica要多,而这个是可以避免的
Follower Replica的分配逻辑除了上述说的kafka.admin.AdminUtils#assignReplicasToBrokersRackUnaware方法外,很重要的一个方法是kafka.admin.AdminUtils#replicaIndex
private def replicaIndex(firstReplicaIndex: Int, // 第一个replica的index,也就是leader indexsecondReplicaShift: Int, // 随机shift,范围是[0, brokerList.length),每隔brokerList.length,将+1replicaIndex: Int, // 当前follower副本编号,从0开始nBrokers: Int): Int = { // broker数量val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)(firstReplicaIndex + shift) % nBrokers
}其实这个方法只有2行,不过这2行代码相当晦涩,要理解它不太容易,而且在2.8.2版本中没有对其的注释,我特意翻看了当前社区的最新版本3.9.0-SNAPSHOT,依旧没有针对这个方法的注释。不过我们还是需要花点精力去理解它的
第一行
val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)
这行代码的作用是生成一个随机值shift,因此shift的范围是 0 <= shift < nBrokers,而随着replicaIndex的增加,shift也会相应增加,当然这样做的目的是为第二行代码做铺垫
当然shift的值,只会与secondReplicaShift、replicaIndex相关,与partition无关
第二行
(firstReplicaIndex + shift) % nBrokers
这样代码就保证了生成的follower index不会与Leader index重复,并且所有的follower index是向前递增的
总结一下分配的规则:
- 随机从Broker list中选择一个作为第一个follower的起始位置(由变量secondReplicaShift控制)
- 后续的follower均基于步骤1的起始位置,依次向后+1
- follower的位置确保不会与Leader冲突,如果冲突则向后顺延一位(由
(firstReplicaIndex + shift) % nBrokers进行控制) - 并非当前Topic的所有的partition均采用同一步调,一旦(
PartitionNum%BrokerNum == 0),secondReplicaShift将会+1,导致第一个follower的起始位置+1,这样就更加离散
我们看一个具体case:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader | 0 | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | |
| Follower 1 | 1 | 2 | 3 | 4 | 0 |
| 9 | 5 | 6 | 7 | 8 | |
| Follower 2 | 4 | 0 | 1 | 2 | 3 |
| 8 | 9 | 5 | 6 | 7 |
- Partition 1:Leader在1001上,而2个Follower分别在1000、1002上。很明显,Follower是从1000开始往后遍历寻找的,因此2个Follower的分布本来应该是1000、1001,但1001正好是Leader,因此往后顺移,最终Follower的分布也就是【1000、1002】
-
- 此处注意:为什么“Follower是从1000开始往后遍历”? 这个就与kafka.admin.AdminUtils#replicaIndex方法中的shift变量有关,而shift则是由随机变量secondReplicaShift而定的,因此“1000开始往后遍历”是本次随机运行后的一个结果,如果再跑一次程序,可能结果就不一致了
- Partition 3:再看分区3,Leader在1003上,Follower是从1002开始的,因此Follower的分布也就是【1002、1004】
- Partition 7:因为从partition 5开始,超过了broker的总数,因此变量secondReplicaShift++,导致Follower的起始index也+1,因此Follower的分布是【1003、1004】
为什么要费尽九牛二虎之力,做这么复杂的方案设定呢?直接将Leader Broker后面的N个Broker作为Follower不可以吗?其实自然是可以的,不过可能带来一些问题,比如如果Leader宕机后,这些Leader Partition都会飘到某1个或某几个Broker上,这样可能带来一些热点隐患,导致存活的Broker不能均摊这些流量
3.3、手动制定策略
当然上述是Kafka帮助我们自动制定分区分配方案,另外我们可以手动制定策略:
bash kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create --topic topicA \
--replica-assignment 1000,1000,1000,1000,1000按照上述的命令创建Topic,我们会新建一个名称为“topicA”的主题,它有5个分区,全部都创建在ID为1000的Broker上
另外Kafka还支持机架(rack)优先的分区分配方案,即尽量将某个partition的replica均匀地打散至N个rack中,这样确保某个rack不可用后,不影响这个partition整体对外的服务能力。本文不再对这种case进行展开
四、状态机
在分区分配方案制定完毕后,Controller便将此方案进行编码,转换为二进制的byte[],进而持久化到ZooKeeper的路径为/topics/topicXXX(其中topicXXX就是topic名称)的path内,而后便向用户返回创建成功的提示;然而真正创建Topic的逻辑并没有结束,Controller会异步执行后续创建Topic的操作,源码中逻辑写的相对比较绕,不过不外乎做了以下两件事儿:
- 更新元数据并通知给所有Brokers
- 向各个Broker传播ISR,并对应执行Make Leader、Make Follower操作
而实现上述操作则是通过两个状态机:
PartitionStateMachine.scala分区状态机ReplicaStateMachine.scala副本状态机
Controll收到ZK异步通知的入口为 kafka.controller.KafkaController#processTopicChange
4.1、分区状态机
即一个partition的状态,对应的申明类为kafka.controller.PartitionState,共有4种状态:
- NewPartition 新建状态,其实只会在Controll中停留很短的时间,继而转换为OnlinePartition
- OnlinePartition 在线状态,只有处于在线状态的partition才能对外提供服务
- OfflinePartition 下线状态,比如Topic删除操作
- NonExistentPartition 初始化状态,如果新建Topic,partition默认则为此状态
转换关系如下
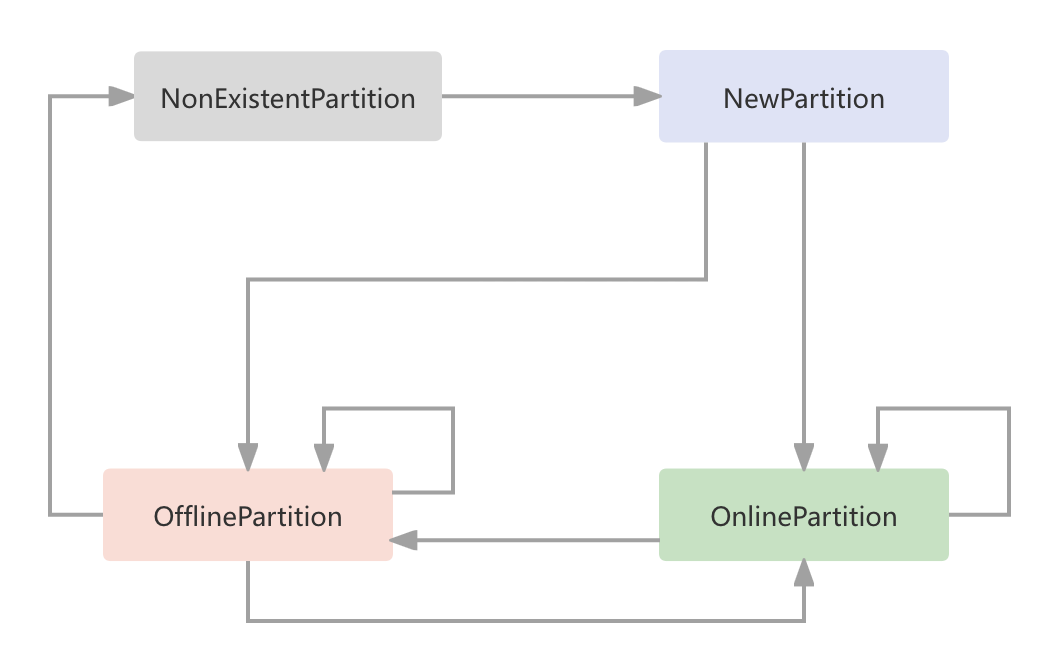
本文只讨论新建Topic时,状态转换的过程,因此只涉及
- NonExistentPartition -> NewPartition
- NewPartition -> OnlinePartition
4.2、副本状态机
所谓副本状态机,对应的申明类为kafka.controller.ReplicaState,共有7种状态:NewReplica、OnlineReplica、OfflineReplica、ReplicaDeletionStarted、ReplicaDeletionSuccessful、ReplicaDeletionIneligible、NonExistentReplica。在Topic新建的流程中,我们只会涉及其中的3种:NewReplica、OnlineReplica、NonExistentReplica,且副本状态机在新建流程中发挥的空间有限,不是本文的重点,读者对其有个大致概念即可
4.3、状态流转
首先要确认一点,Kafka的Controller是单线程的,所有的事件均是串行执行,以下所有的操作也均是串行执行
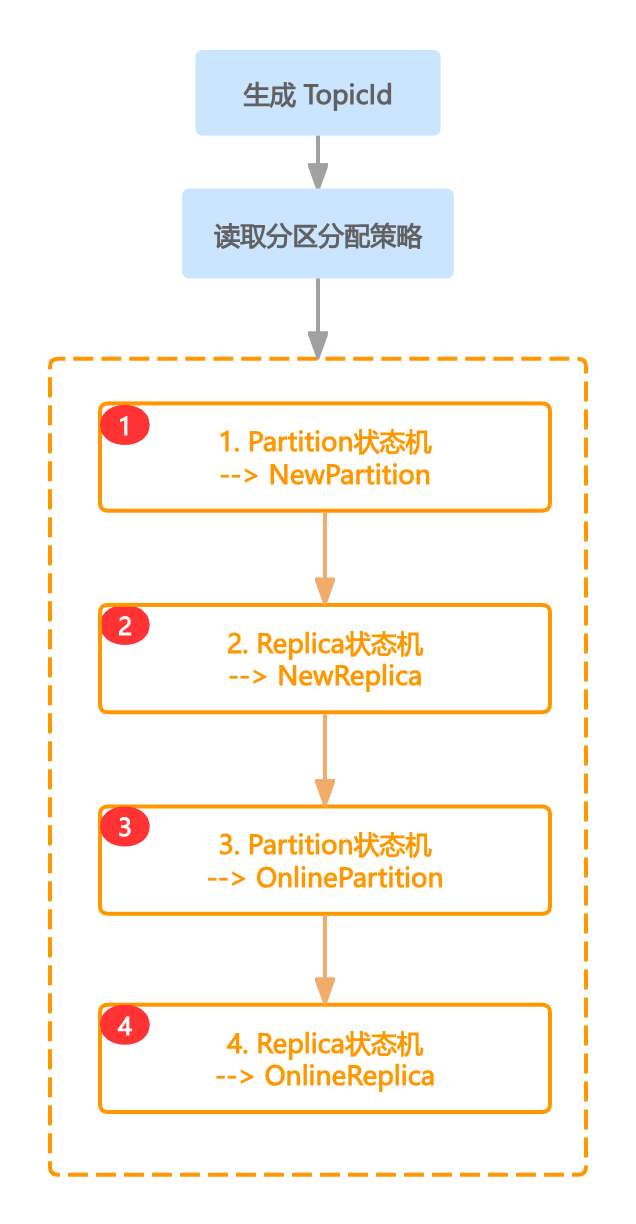
在真正执行状态流转前,需要执行2个前置步骤
- 生产Topic ID。为新建的Topic生产唯一的TopicID,具体实现方法位置在
kafka.zk.KafkaZkClient#setTopicIds内,其实就是简单调用org.apache.kafka.common.Uuid#randomUuid来生成一个随机串 - 读取分区分配策略。接着从zk(存储路径为
/brokers/topics/topicName)中读取这个Topic的分区分配策略,然后将分区分配策略放进缓存中,缓存的位置为kafka.controller.ControllerContext#partitionAssignments
上述两个步骤其实没啥好说的,只是为状态流转做一些前置铺垫。接下来就要进入主方法的逻辑中了,即kafka.controller.KafkaController#onNewPartitionCreation,可简单看一下此方法,主要执行4部分内容
-
- partition状态机将状态设置为NewPartition
- replica状态机降状态置为NewReplica
- partition状态机将状态设置为OnlinePartition
- replica状态机降状态置为OnlineReplica
// kafka.controller.KafkaController#onNewPartitionCreation
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {info(s"New partition creation callback for ${newPartitions.mkString(",")}")partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)partitionStateMachine.handleStateChanges(newPartitions.toSeq, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}4.3.1、Partition状态机NewPartition
partition状态机将状态设置为NewPartition。这一步就是维护kafka.controller.ControllerContext#partitionStates内存变量,将对应partition的状态设置为NewPartition,其他什么都不做
4.3.2、Replica状态机NewReplica
replica状态机降状态置为NewReplica。这一步是维护kafka.controller.ControllerContext#replicaStates内存变量,将replica状态设置为NewReplica
4.3.3、Partition状态机OnlinePartition
这一步也是整个状态机流转中的核心部分,共分为以下5大步:
- 初始化Leader、ISR等信息,并将这些信息暂存至zk中
-
- 创建topic-partition在zk中的路径,path为/brokers/topics/topicName/partitions
- 为每个partition创建路径,path为/brokers/topics/topicName/partitions/xxx,例如
-
-
- /brokers/topics/topicName/partitions/0
- /brokers/topics/topicName/partitions/1
- /brokers/topics/topicName/partitions/2
-
-
- 将Leader及ISR的信息持久化下来,path为/brokers/topics/topicName/partitions/0/state
- 而后将Leader、ISR等已经持久化到zk的信息放入缓存
kafka.controller.ControllerContext#partitionLeadershipInfo中 - 因为Leader、ISR这些元数据发生了变化,因此将这些信息记录下来,放在内存结构
kafka.controller.AbstractControllerBrokerRequestBatch#leaderAndIsrRequestMap中,表明这些信息是需要同步给对应的Broker的 - 维护
kafka.controller.ControllerContext#partitionStates内存变量,将状态设置为OnlinePartition - 调用接口ApiKeys.LEADER_AND_ISR,向对应的Broker发送数据,当Broker接收到这个请求后,便会执行MakeLeader/MakeFollower相关操作
4.3.4、Replica状态机OnlineReplica
replica状态机降状态置为OnlineReplica。维护kafka.controller.ControllerContext#replicaStates内存变量,将状态设置为OnlineReplica
至此,一个 Kafka Topic 才算是真正被创建出来
相关文章:
Kafka原理剖析之「Topic创建」
一、前言 Kafka提供了高性能的读写,而这些读写操作均是操作在Topic上的,Topic的创建就尤为关键,其中涉及分区分配策略、状态流转等,而Topic的新建语句非常简单 bash kafka-topics.sh \ --bootstrap-server localhost:9092 \ // …...

Java 高级学习路线概要~
前言:恭喜你已经掌握了 Java 的基础知识!现在,让我们踏上 Java 高级学习之旅,探索更强大的编程技巧和技术。学习前记得不要忘了巩固和加强基础的学习哦,高级学习也是建立在基础的学习之上。 1. 集合框架进阶 Map 接口…...

浏览器插件快速开启/关闭IDM接管下载
假设你已经为浏览器安装了IDM扩展,那么按下图的点击顺序,可以快速开启或关闭IDM的下载接管,而不必在IDM软件的设置->选项中,临时作调整。...

初识c++:入门基础
打字不易,留个赞再走吧~~ 目录 一.第一个c程序二.命名空间 namespace三.C输⼊&输出四.缺省参数 C兼容C语⾔绝⼤多数的语法,所以C语⾔实现的hello world依旧可以运⾏,C中需要把定义⽂件 代码后缀改为.cpp 一.第一个c程序 做好准备我们来写…...

Java Exception 异常相关总结
1.简介 在Java中,当代码运行有问题时会抛出异常,主要分为两类: 1.可以通过try...catch来捕获解决的,不影响后续执行的RuntimeException。 2.不可以通过代码解决的Exception。 为了提高代码的健壮性,我们会选择去捕…...
HighCharts图表自动化简介
什么是分析数据? 在任何应用程序中捕获并以图形或图表形式显示的分析数据是任何产品或系统的关键部分,因为它提供了对实时数据的洞察。 验证此类分析数据非常重要,因为不准确的数据可能会在报告中产生问题,并可能影响应用程序/系统的其他相关领域。 什么是HighChart? …...
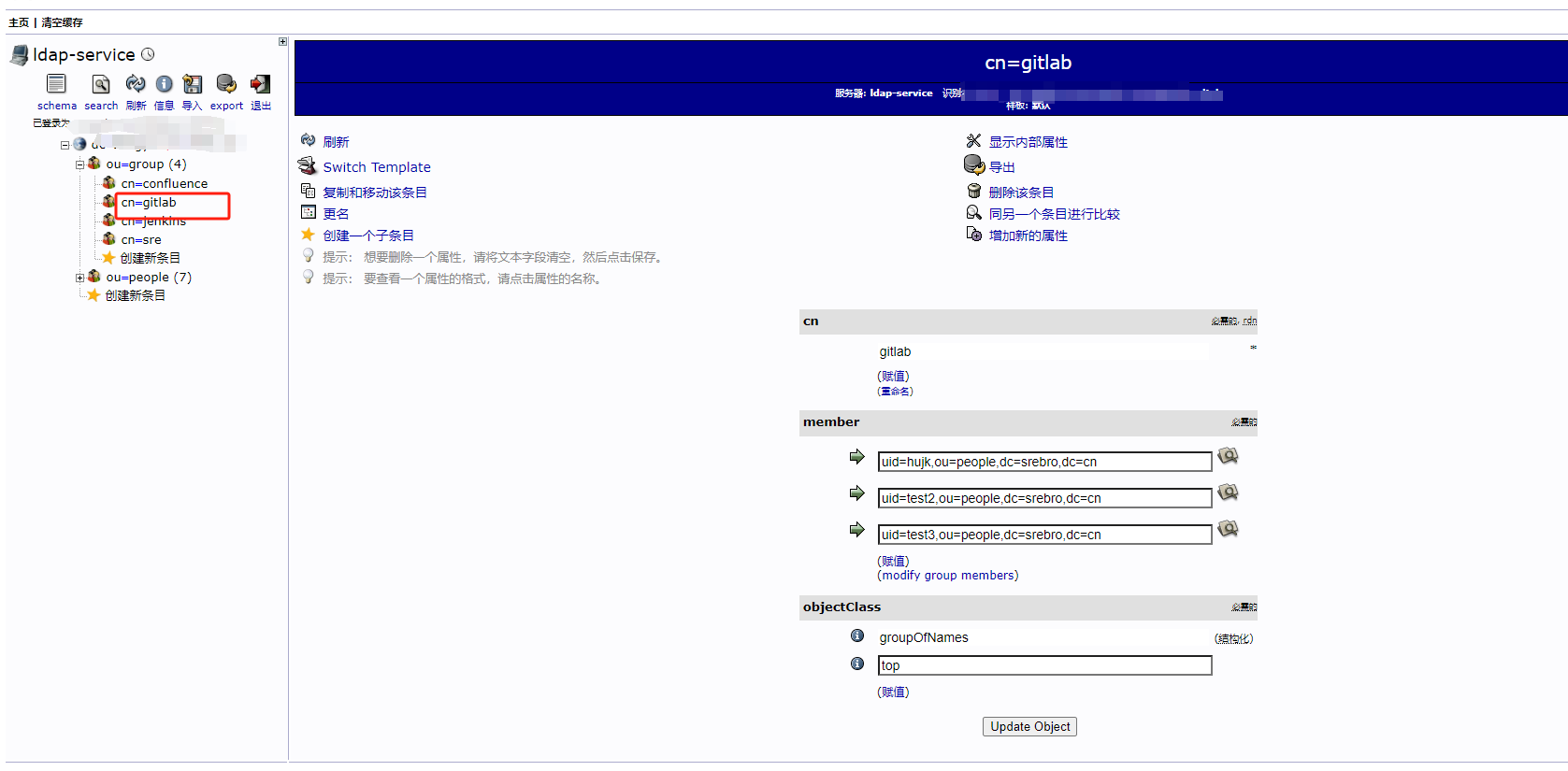
使用LDAP登录GitLab
使用LDAP登录GitLab gitlab.rb 配置如下 gitlab_rails[ldap_enabled] true #gitlab_rails[prevent_ldap_sign_in] false###! **remember to close this block with EOS below** gitlab_rails[ldap_servers] YAML.load <<-EOSmain:label: LDAPhost: 172.16.10.180port:…...

【2024】前端学习笔记5-表单标签使用
表单是网页提供的一种交互式操作手段,主要用于采集用户输入的信息。 学习笔记 1.表单框架:form标签1.1.action属性:目标指向1.2.method属性:提交方式1.3.id属性:唯一标识1.4.placeholder属性:提示文字2.input标签2.1.text类型:基本文本输入2.2.password类型:密码输入2.…...
)
数据结构--二叉树(C语言实现,超详细!!!)
文章目录 二叉树的概念代码实现二叉树的定义创建一棵树并初始化组装二叉树前序遍历中序遍历后序遍历计算树的结点个数求二叉树第K层的结点个数求二叉树高度查找X所在的结点查找指定节点在不在完整代码 二叉树的概念 二叉树(Binary Tree)是数据结构中一种…...

【将字符串变为空的编辑距离】
题目描述 求由s串变成t串的编辑距离 在s串的开头/末尾添加一个字符,花费p 在s串的开头/末尾添加一个s串的子串,花费q 每次作都是基于当前的s串 s串初始为空 分析 等价于将一个字符串变为空串的过程 第一层按照长度遍历(如果按照下标i,j遍…...

卡特兰数的推理
卡特兰数(Catalan number),又称卡塔兰数、明安图数,是组合数学中一种常出现于各种计数问题中的数列。它以比利时数学家欧仁查理卡特兰的名字命名,但值得注意的是,这一数列的首次发现可以追溯到1730年&#…...

高精度治具加工的重要性和优势
在现代工业制造中,高精度治具加工扮演着举足轻重的角色。它不仅关乎产品制造的精度与质量,还直接影响到生产效率和成本控制。因此,时利和将深入探讨高精度治具加工的重要性和优势,对于提升工业制造水平具有重要意义。 高精度治具加…...

新版IDEA提示@Autowired不建议字段注入
随着项目的复杂度的增加,我们通常会在一个业务类中注入其他过多的业务类。从而使当前的业务层扩充成一个大而全的功能模块。那么就容易出现一下问题 字段注入会让依赖关系变得不那么明显,因为你无法通过构造函数看到所有的依赖项。使用构造函数时&#…...

adb的安装和使用 以及安装Frida 16.0.10+雷电模拟器
.NET兼职社区 .NET兼职社区 .NET兼职社区 1.下载adb Windows版本:https://dl.google.com/android/repository/platform-tools-latest-windows.zip 2.配置adb环境变量 按键windowsr打开运行,输入sysdm.cpl,回车。 高级》环境变量》系统变量》…...

解决移动端1px 边框优化的8个方法
前言 您是否注意到 1px 边框在移动设备上有时会显得比预期的要粗?这种不一致源于移动屏幕的像素密度不同。 在 Web 开发中,我们使用 CSS 来设置页面样式。但是,CSS 中的 1px 并不总是转换为设备上的物理 1px。这种差异就是我们的“1px 边框…...

频带宽度固定,如何突破数据速率的瓶颈?
目录 目录 引言 信道 频带宽度 信噪比 信噪比的重要性 影响信噪比的因素 码元 码元的特点: 码元与比特的关系: 码元的作用: 码元的类型: Question 类比解释: 技术解释: 引言 在现代通信系统中…...

Linux网络编程 --- 高级IO
前言 IO Input&&Output read && write 1、在应用层read && write的时候,本质把数据从用户层写给OS --- 本质就是拷贝函数 2、IO 等待 拷贝。 等的是:要进行拷贝,必须先判断读写事件成立。读写事件缓冲区空间满…...

Python中给定一个数组a = [2,3,9,1,0],找出其中最大的一个数,并打印出来 求解?
Python有内置的max函数可以取最大值: max([2,3,9,1,0])也可以使用sorted先排序,再索引取出最大值: sorted([2,3,9,1,0])[-1]如果不用内置函数,自己排序算法来找出最大值,也有很多选择。 比如冒泡排序、循环排序、交…...
系统优化工具 | PC Cleaner v9.7.0.3 绿色版
PC Cleaner是一款功能强大的电脑清理和优化工具,旨在通过清理系统垃圾文件、解除恶意软件和优化系统性能来提高计算机的运行效率。该软件提供了多种功能,可以帮助用户维护和提升计算机的整体表现。 PC Cleaner 支持 Windows 7 及以上操作系统࿰…...

JavaSE、JavaEE 与 JavaWeb 的详解与区别
一、JavaSE(Java Standard Edition)——标准版 1. 什么是JavaSE JavaSE,全称Java Standard Edition,译为Java标准版,是Java平台的基础,也是开发者最常使用的Java版本。JavaSE包含了编程中最基础的核心库,如Java的基本语法、面向对象编程、集合框架、多线程、网络编程、…...
)
ElevenLabs语音合成效果翻倍的秘密(行业未公开的声学参数调优矩阵)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音合成效果翻倍的核心洞察 关键瓶颈在于语音上下文建模粒度 ElevenLabs 的高质量语音合成并非单纯依赖更大模型参数量,而是通过细粒度的语义-韵律联合编码实现自然度跃升。…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

通用框架操作系统:统一异构应用框架的运行时与治理平台
1. 项目概述:一个面向未来的通用框架操作系统最近在开源社区里,一个名为TELLEBO/universal-framework-os的项目引起了我的注意。乍一看这个标题,可能会觉得有点“大词”堆砌的感觉——“通用”、“框架”、“操作系统”,每一个词单…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

基于Helm Chart的JupyterHub生产级部署与运维实战指南
1. 项目概述:为什么我们需要一个可扩展的JupyterHub部署方案?如果你在团队里负责过数据科学或机器学习平台的搭建,大概率会为Jupyter Notebook的部署和管理头疼过。单个Jupyter Notebook服务给一两个人用还行,一旦团队规模扩大到十…...