链表的快速排序(C/C++实现)
一、前言
大家在做需要排名的项目的时候,需要把各种数据从高到低排序。如果用的快速排序的话,处理数组是十分简单的。因为数组的存储空间的连续的,可以通过下标就可以简单的实现。但如果是链表的话,内存地址是随机分配的,不能像数组那样通过下标就直接实现。所以在这里给大家介绍一个简单实现的快速排序。
二、快速排序简单介绍
快速排序的是交换排序其中的一种,主要是采用分治的思想,每次迭代在当前区间中选取一个数作为哨兵,通过一系列的交换操作将当前区间分为左区间和右区间【使得左区间的值全部小于等于哨兵,右区间的值全部大于等于哨兵】。然后再对左区间、右区间执行这种划分区间的策略操作,当区间的长度为1时停止。等到所有分治的区间长度都为1时,此时的原数组就已经是一个排好序的数组了。代码如下:
void quickSort(int q[], int l, int r)
{// 当前区间的长度小于等于1时停止循环if (l >= r) return;// 创建哨兵 midint mid = q[l];// 创建i,j指针进行移动int i = l, j = r;// 进行区间数字交换,使得左侧区间全小于等于mid,右侧区间全大于等于midwhile (i < j){// j指针从右向左移动,至到遇到第一个小于哨兵的值while (q[j] >= mid && i < j) j--;// 将该值移动到左区间中q[i] = q[j];// i指针从左向右移动,至到遇到第大个小于哨兵的值while (q[i] <= mid && i < j) i++;// 将该值移动到右区间中q[j] = q[i];}// 交换结束后此时i,j指针指向的同一个位置,即哨兵应该放的位置// 而左区间已经是全部小于等于哨兵的值,右区间已经是全部大于等于哨兵的值了。q[i] = mid;// 对划分出来的左右区间的再一次进行快排quickSort(q, l, i - 1);quickSort(q, i + 1, r);
}
但这只适用于连续存储空间。对于链表来说,不太适用。所以接下来我将介绍一个比较简单的代码来实现链表的快速排序。
三、代码实现:
(该链表是包含有头结点的,即第一个结点不放数据):
// 自定义的结构体,用来存储链表的内容
typedef struct node
{int data = -1; // 数据域struct node* next = NULL; // 指针域,指向后一个元素struct node* pre = NULL; // 指针域,指向前一个元素
}NODE;//别名
// 函数声明
// 判断l是否走到了r的右边,如果在返回true,如果不在则返回false 【要求l和r在同一个链表上,且定义时l是r左侧的节点】
bool isRight(const NODE* l, const NODE* r);
// 判断l是否还在r的左边,如果在返回true,如果不在则返回false【要求l和r在同一个链表上,且定义时l是r左侧的节点】
bool isLeft(const NODE* l, const NODE* r);
// 在链表中挖出这个节点,即断开这个节点和链表的关系
NODE* dug(NODE* node);
// 在node所属的链表中,在node节点前插入target节点【此时target节点是一个孤立的节点,并没有链接链表】
void insertBefore(NODE* node, NODE* target);
// 在node所属的链表中,在node节点后插入target节点【此时target节点是一个孤立的节点,并没有链接链表】
void insertAfter(NODE* node, NODE* target);
// 进行快速排序
void quickSort(NODE* l, NODE* r)
{// 如果当前区间的元素已经只剩一个或者不剩了,那么结束递归if (isRight(l, r)) {return;}// 记录当前区间的外的前一个节点和当前区间外的后一个节点,防止进行交换后这个区间的第一个节点和最后一个节点的顺序找不到了// 由于头节点的存在,可以保证该区间外一定存在前一个节点NODE* preL = l->pre;// 但是不一定该区间外是否还有后一个节点NODE* nextR;bool tailDug = false; //标记是否给该区间外创建了后一个节点// 如果该区间外没有后一个节点了if (r->next == NULL) {// 则创建一个新的节点用来记录区间的最后一个节点nextR = (NODE*)malloc(sizeof(NODE));r->next = nextR;nextR->pre = r;nextR->next = NULL;tailDug = true;} // 如果该区间外后面还有一个节点,则直接使用这个节点来帮助记录区间的末尾节点else{nextR = r->next;}// 选择哨兵节点【区间的第一个节点】NODE* mid = dug(l);// 更新左、右指针的位置NODE* i = preL->next, * j = nextR->pre;// 进行快排的交换移动// 当左指针还在右指针的左侧时,进行交换判断while (isLeft(i, j)){// 右指针左移,至到遇到第一个小于哨兵的节点或者i,j指针相遇了,那么就停下while (j->data >= mid->data && isLeft(i, j)) { j = j->pre; }NODE* temp = NULL;// 如果此时i,j指针还未相遇,则右指针当前指向的节点是小于哨兵的节点,需要移动到左区间中。【说明它满足的上面while的 j->data >= mid->data】if (isLeft(i, j)) {// j指针前移一位,因为上面的判断已经知道当前这个节点应该放在左区间了,故下一次判断时j指针不需要判断这个节点了,直接从前一个节点开始判断即可。j = j->pre;// 将刚才j指针找到的节点移动到i节点前面,【因为i节点的左侧都应该是小于等于哨兵值的节点】temp = j->next;dug(temp);insertBefore(i, temp);}// 左指针右移,至到遇到第一个大于哨兵的节点或者i,j指针相遇了,那么就停下while (i->data <= mid->data && isLeft(i, j)) { i = i->next; }// 如果此时i,j指针还未相遇,则左指针当前指向的节点是大于哨兵的节点,需要移动到右区间中。【说明它满足的上面while的 i->data <= mid->data 】if (isLeft(i, j)) {// i指针后移一位,因为上面的判断已经知道当前这个节点应该放在右区间了,故下一次判断时i指针不需要判断这个节点了,直接从后一个节点开始判断即可。i = i->next;// 将刚才i指针找到的节点移动到j节点后面,【因为j节点的右侧都应该是大于等于哨兵值的节点】temp = i->pre;dug(temp);insertAfter(j, temp);}}// 此时的i,j指针已经相遇了,故下面使用到i的地方都可以替换为j// 最后一次填坑,此时只剩哨兵这个节点的位置需要重新放进来了。// 如果当前节点小于哨兵,则代表当前相遇位置的节点【i,j】是左区间的最后一个节点,那么哨兵应该放在该节点的右侧if (i->data < mid->data) {insertAfter(i, mid);//当前相遇的节点【i,j】代表左区间的最后一个元素,故放在该节点后面即代表放在了左区间和右区间的正中间} // 否则代表当前相遇位置的节点【i,j】是右区间的第一个节点,那么哨兵应该放在该节点的左侧else {insertBefore(i, mid);//当前相遇的节点【i,j】代表右区间的第一个元素,故放在该节点前面即代表放在了左区间和右区间的正中间}// 更新这个区间的区间内的第一个节点和最后一个节点l = preL->next;r = nextR->pre;// 如果区间外的后一个节点实际上是不存在的,那么删除这个被我们临时创建出来的节点if (tailDug) {dug(nextR);}// 进行左右区间的快排quickSort(l, mid->pre), quickSort(mid->next, r);
}
// 函数实现
bool isRight(const NODE* l, const NODE* r)
{return l == NULL || r == NULL || l == r || l == r->next;
}
bool isLeft(const NODE* l, const NODE* r)
{return !isRight(l, r);//如果不在右边,则代表在左边
}
NODE* dug(NODE* node)
{// 如果当前节点在链表中是最后一个节点if (node->next == NULL){// 则将前一个节点指向NULL即可NODE* l = node->pre;l->next = NULL;return node;}// 如果当前节点不是最后一个节点else{// 将当前节点在链表中的前一个节点与当前节点在链表中的后一个节点联系起来NODE* l = node->pre;NODE* r = node->next;l->next = r;r->pre = l;// 断开当前节点与链表的联系node->pre = NULL;node->next = NULL;return node;}
}
void insertBefore(NODE* node, NODE* target)
{// 获取链表中node的前一个节点NODE* l = node->pre;// 将target节点插入到 l 节点和 node 节点之间l->next = target;node->pre = target;target->pre = l;target->next = node;
}
void insertAfter(NODE* node, NODE* target)
{// 获取链表中node的后一个节点NODE* r = node->next;// 将target节点插入到 node 节点和 r 节点之间r->pre = target;node->next = target;target->pre = node;target->next = r;
}
四、分析讲解
假设需要排序的链表数据为:2 3 6 1 9。那么链表的结构如下:

4.1 第一个递归过程
4.1.1 数据预处理
4.1.1.1 需要处理的链表结点【区间数据】

4.1.1.2 本次递归的结点介绍【未获取哨兵结点之前】

提示:由于需要处理的区间结点的最后一个结点9 后面不再有结点,故需要 创建一个新的结点nextR 插入在9这个结点后面,这样就可以精准的找到我们这个区间的最后一个数据结点的位置【由于nextR这个结点是不会进行位置交换的,故nextR的前一个结点一定是当前区间的最后一个数据结点】。
4.1.1.3 获取哨兵结点

提示:哨兵结点mid是一般取的是区间的第一个结点,即2这个结点。而本文的快速排序会将哨兵结点从链表中挖出去,这样可以方便后续的处理。故现在区间结点只有四个数据了,即3 6 1 9。
4.1.1.4 本次递归所有结点介绍

结点介绍:
mid:哨兵结点,用于确定其他每个结点的位置,来使得其他结点进行移动。
l:区间的第一个结点,一般只在初始化其他结点的时候用到。
r:区间的最后一个结点,一般只在初始化其他结点的时候用到。
preL:区间第一个结点的前一个结点,由于位置不会发生改变,故用来找区间的第一个结点。
nextR:区间最后一个结点的后一个结点,由于位置不会发生改变,故用来找区间的最后一个结点。
i:从区间的第一个结点向区间的最后一个结点进行移动,用于每一次循环移动数据的结点判断。
j:从区间的最后一个结点向区间的第一个结点进行移动,用于每一次循环移动数据的结点判断。
4.1.2 循环移动数据
4.1.2.1 第一次循环结果
目的:第一次循环,判断j所在的结点是否需要移动位置。
过程:
第一步: j当前所在的结点是9,由于9大于哨兵结点2,故当前结点不需要移动,j结点向左移动,此时j结点成为了1结点。
第二步: j当前所在的结点是1,由于1小于于哨兵结点2,故当前结点需要移动。将当前j所在的结点【1结点】移动到i所在的结点【3结点】前面。让j的位置仍然保持距离区间最后一个结点的距离不变,那么此时j所指向的结点即为6结点。【因为从区间结尾开始处理的话,此时只有9结点正常通过判断确定了位置,但是6结点还未通过判断确定位置,那么j就应该指向区间最后一个未确认位置的结点】

4.1.2.2 第二次循环结果
目的:第二次循环,判断i所在的结点是否需要移动位置。
过程:
第一步: i当前所在的结点是3,由于3大于哨兵结点2,故当前结点需要移动。将当前i所在的结点【3结点】移动到j所在的结点【6结点】后面。让i的位置仍然保持距离区间第一个结点的距离不变,那么此时i所指向的结点即为6结点。【因为从区间开始开始处理的话,此时只有1结点正常通过判断确定了位置,但是6结点还未通过判断确定位置,那么i就应该指向区间第一个未确认位置的结点】

4.1.2.3 第三次循环结果
目的:由于i、j指针已经相遇,那么目前只需要确定哨兵结点的位置,本轮循环就结束了。
过程:由于快排算法的性质决定了,i指针左侧的结点都小于哨兵结点的值,j指针右侧结点的值都大于哨兵结点的值。故我们比较一下当前i结点(或者j结点,因为每次循环到了最后一步的时候,i和j结点都会相遇)的值和哨兵结点的值的大小。由于i结点6大于哨兵结点2,那么哨兵结点2就需要插入到链表中i结点6的左侧。此时本轮位置移动已经完成,哨兵结点2的左侧结点均为小于哨兵结点值的结点,哨兵结点2的右侧结点均为大于哨兵结点值的结点。

4.1.2.4 下一次循环的区间划分
目的:本轮位置移动已经完成了,已经确定了结点2的位置,但其他结点的位置还未确定,还需要继续进行分冶结点2两侧的区间进行快排位置移动。
过程:最开始指向区间头、尾的结点的l和r,在进行了无数次交换了,我们可以发现它们已经不在区间的第一个结点和最后一个结点了。但由于preL和nextR结点始终没有移动过位置,preL的下一个结点一直指向的是区间的第一个结点【目前指向的结点1,即快排结束后区间的第一个结点】,nextR的上一个结点一直指向的是区间的最一个结点【目前指向的结点9,即快排结束后区间的最后一个结点】。故我们可以确定需要继续进行快排的两个区间为:preL->next, mid->pre、mid->next, nextR->pre。【即(preL的下一个结点,哨兵结点的上一个结点)、(哨兵结点的下一个结点,nextR的上一个结点)】。而哨兵结点已经确定好在整个链表的位置了,故不需要参与后续的其他区间迭代的位置移动了。而由于此时nextR结点是创建的新结点,在原因链表中不需要,在最后我们将该结点从链表中删掉即可。
故下一轮的递归区间为:

五、可运行的完整代码:
#include<stdio.h>
#include<stdlib.h>// 自定义的结构体,用来存储链表的内容
typedef struct node
{int data = -1; // 数据域struct node* next = NULL; // 指针域,指向后一个元素struct node* pre = NULL; // 指针域,指向前一个元素
}NODE;//别名// 找到链表的最后一个节点
NODE* findTail(NODE* head)
{while (head->next != NULL) { //当没有下一个元素的时候,就代表当前元素是链表的最后一个元素head = head->next;}return head;
}// 给链表新增节点
void add(NODE* head, int data)
{NODE* tail = findTail(head); //获取链表的最后一个节点// 创建新节点NODE* p = (NODE*)malloc(sizeof(NODE));// p 为新增的结点p->data = data; // 把值赋给p中的data域p->next = NULL; // 初始化操作,p是最后一个节点,故没有下一个节点了,因此next指针域需要指向NULL// 将新创建的结点与当前链表创建关联p->pre = tail; //新节点左指针域应该指向链表中的最后一个节点tail->next = p; //链表中最后一个节点的右指针域应该指向这个新节点。【至此新节点成功加入到链表中】
}// 判断l是否走到了r的右边,如果在返回true,如果不在则返回false 【要求l和r在同一个链表上,且定义时l是r左侧的节点】
bool isRight(const NODE* l, const NODE* r)
{return l == NULL || r == NULL || l == r || l == r->next;
}// 判断l是否还在r的左边,如果在返回true,如果不在则返回false【要求l和r在同一个链表上,且定义时l是r左侧的节点】
bool isLeft(const NODE* l, const NODE* r)
{return !isRight(l, r);//如果不在右边,则代表在左边
}// 在链表中挖出这个节点,即断开这个节点和链表的关系
NODE* dug(NODE* node)
{// 如果当前节点在链表中是最后一个节点if (node->next == NULL) {// 则将前一个节点指向NULL即可NODE* l = node->pre;l->next = NULL;return node;}// 如果当前节点不是最后一个节点else {// 将当前节点在链表中的前一个节点与当前节点在链表中的后一个节点联系起来NODE* l = node->pre;NODE* r = node->next;l->next = r;r->pre = l;// 断开当前节点与链表的联系node->pre = NULL;node->next = NULL;return node;}
}// 在node所属的链表中,在node节点前插入target节点【此时target节点是一个孤立的节点,并没有链接链表】
void insertBefore(NODE* node, NODE* target)
{// 获取链表中node的前一个节点NODE* l = node->pre;// 将target节点插入到 l 节点和 node 节点之间l->next = target;node->pre = target;target->pre = l;target->next = node;
}// 在node所属的链表中,在node节点后插入target节点【此时target节点是一个孤立的节点,并没有链接链表】
void insertAfter(NODE* node, NODE* target)
{// 获取链表中node的后一个节点NODE* r = node->next;// 将target节点插入到 node 节点和 r 节点之间r->pre = target;node->next = target;target->pre = node;target->next = r;
}// 进行快速排序
void quickSort(NODE* l, NODE* r)
{// 如果当前区间的元素已经只剩一个或者不剩了,那么结束递归if (isRight(l, r)) {return;}// 记录当前区间的外的前一个节点和当前区间外的后一个节点,防止进行交换后这个区间的第一个节点和最后一个节点的顺序找不到了// 由于头节点的存在,可以保证该区间外一定存在前一个节点NODE* preL = l->pre;// 但是不一定该区间外是否还有后一个节点NODE* nextR;bool tailDug = false; //标记是否给该区间外创建了后一个节点// 如果该区间外没有后一个节点了if (r->next == NULL) {// 则创建一个新的节点用来记录区间的最后一个节点nextR = (NODE*)malloc(sizeof(NODE));r->next = nextR;nextR->pre = r;nextR->next = NULL;tailDug = true;} // 如果该区间外后面还有一个节点,则直接使用这个节点来帮助记录区间的末尾节点else{nextR = r->next;}// 选择哨兵节点【区间的第一个节点】NODE* mid = dug(l);// 更新左、右指针的位置NODE* i = preL->next, * j = nextR->pre;// 进行快排的交换移动// 当左指针还在右指针的左侧时,进行交换判断while (isLeft(i, j)){// 右指针左移,至到遇到第一个小于哨兵的节点或者i,j指针相遇了,那么就停下while (j->data >= mid->data && isLeft(i, j)) { j = j->pre; }NODE* temp = NULL;// 如果此时i,j指针还未相遇,则右指针当前指向的节点是小于哨兵的节点,需要移动到左区间中。【说明它满足的上面while的 j->data >= mid->data】if (isLeft(i, j)) {// j指针前移一位,因为上面的判断已经知道当前这个节点应该放在左区间了,故下一次判断时j指针不需要判断这个节点了,直接从前一个节点开始判断即可。j = j->pre;// 将刚才j指针找到的节点移动到i节点前面,【因为i节点的左侧都应该是小于等于哨兵值的节点】temp = j->next;dug(temp);insertBefore(i, temp);}// 左指针右移,至到遇到第一个大于哨兵的节点或者i,j指针相遇了,那么就停下while (i->data <= mid->data && isLeft(i, j)) { i = i->next; }// 如果此时i,j指针还未相遇,则左指针当前指向的节点是大于哨兵的节点,需要移动到右区间中。【说明它满足的上面while的 i->data <= mid->data 】if (isLeft(i, j)) {// i指针后移一位,因为上面的判断已经知道当前这个节点应该放在右区间了,故下一次判断时i指针不需要判断这个节点了,直接从后一个节点开始判断即可。i = i->next;// 将刚才i指针找到的节点移动到j节点后面,【因为j节点的右侧都应该是大于等于哨兵值的节点】temp = i->pre;dug(temp);insertAfter(j, temp);}}// 此时的i,j指针已经相遇了,故下面使用到i的地方都可以替换为j// 最后一次填坑,此时只剩哨兵这个节点的位置需要重新放进来了。// 如果当前节点小于哨兵,则代表当前相遇位置的节点【i,j】是左区间的最后一个节点,那么哨兵应该放在该节点的右侧if (i->data < mid->data) {insertAfter(i, mid);//当前相遇的节点【i,j】代表左区间的最后一个元素,故放在该节点后面即代表放在了左区间和右区间的正中间} // 否则代表当前相遇位置的节点【i,j】是右区间的第一个节点,那么哨兵应该放在该节点的左侧else {insertBefore(i, mid);//当前相遇的节点【i,j】代表右区间的第一个元素,故放在该节点前面即代表放在了左区间和右区间的正中间}// 更新这个区间的区间内的第一个节点和最后一个节点l = preL->next;r = nextR->pre;// 如果区间外的后一个节点实际上是不存在的,那么删除这个被我们临时创建出来的节点if (tailDug) {dug(nextR);}// 进行左右区间的快排quickSort(l, mid->pre), quickSort(mid->next, r);
}int main()
{NODE* head = (NODE*)malloc(sizeof(NODE));//定义头结点int n;//链表的长度printf("请输入链表的长度: ");scanf("%d", &n);printf("请输入链表中的数字: ");for (int i = 0; i < n; i++){int x;//每一个结点的值scanf("%d", &x);add(head, x);//向链表追加结点}//进行冒泡排序quickSort(head->next, findTail(head));NODE* p = head->next;//因为第一个结点没有存放数据,所以从第二个结点开始输出while (p != NULL){printf("%d\t", p->data);p = p->next;}return 0;
}
**
温馨提示:第一个结点不是用来放数据的,是用来辅助完成排序的。
题目测试地址:C语言网-快速排序题目测试
**
相关文章
快速排序(C/C++实现)—— 简单易懂系列
单链表的冒泡排序(C/C++实现)
相关文章:
链表的快速排序(C/C++实现)
一、前言 大家在做需要排名的项目的时候,需要把各种数据从高到低排序。如果用的快速排序的话,处理数组是十分简单的。因为数组的存储空间的连续的,可以通过下标就可以简单的实现。但如果是链表的话,内存地址是随机分配的…...
)
css总结(记录一下...)
文字 语法说明word-wrapword-wrap:normal| break-word normal:使用浏览器默认的换行 break-word:允许在单词内换行 text-overflow clip:修剪文本 ellipsis:显示省略符号来代表被修剪的文本 text-shadow可向文本应用的阴影。能够规定水平阴影、垂直阴影、模糊距离,以…...

SpringBoot 处理 @KafkaListener 消息
消息监听容器 1、KafkaMessageListenerContainer 由spring提供用于监听以及拉取消息,并将这些消息按指定格式转换后交给由KafkaListener注解的方法处理,相当于一个消费者; 看看其整体代码结构: 可以发现其入口方法为doStart(),…...

Spring Boot-API版本控制问题
在现代软件开发中,API(应用程序接口)版本控制是一项至关重要的技术。随着应用的不断迭代,API 的改动不可避免,如何在引入新版本的同时保证向后兼容,避免对现有用户的影响,是每个开发者需要考虑的…...

Git 提取和拉取的区别在哪
1. 提取(Fetch) 操作说明:Fetch 操作会从远程仓库下载最新的提交、分支信息等,但不会将这些更改合并到你当前的分支中。它只是将远程仓库的更新信息存储在本地,并不会自动修改你当前的工作区。 使用场景: …...

【数据结构与算法 | 每日一题 | 力扣篇】力扣2390, 2848
1. 力扣2390:从字符串中删除星号 1.1 题目: 给你一个包含若干星号 * 的字符串 s 。 在一步操作中,你可以: 选中 s 中的一个星号。移除星号 左侧 最近的那个 非星号 字符,并移除该星号自身。 返回移除 所有 星号之…...
破解信息架构实施的密码:常见挑战与最佳解决方案全指南
信息架构的成功实施是企业数字化转型的关键步骤,但在实际操作中,企业往往会遇到各种复杂的挑战。这些挑战包括 技术整合的难度、数据管理的复杂性、合规性要求的变化 以及 资源限制 等。《信息架构:商业智能&分析与元数据管理参考模型》为…...
 A~D)
CodeChef Starters 151 (Div.2) A~D
codechef是真敢给分,上把刚注册,这把就div2了,再加上一周没打过还是有点不适应的,好在最后还是能够顺利上分 今天的封面是P3R的设置菜单 我抠出来做我自己的游戏主页了( A - Convert string 题意 在01串里面可以翻转…...

Redis学习——数据不一致怎么办?更新缓存失败了又怎么办?
文章目录 引言正文读写缓存的数据一致性只读缓存的数据一致性删除和修改数据不一致问题操作执行失败导致数据不一致解决办法 多线程访问导致数据不一致问题总结 总结参考信息 引言 最近面试快手的时候被问到了缓存不一致怎么解决?一开始还是很懵的,因为…...
跨境电商代购新纪元:一键解锁全球好物,系统流程全揭秘
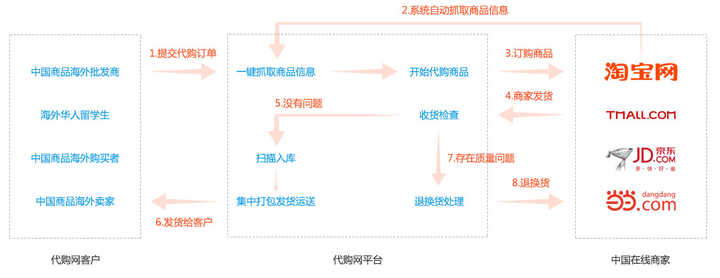
添加图片注释,不超过 140 字(可选) 在全球化日益加深的今天,跨境电商代购成为了连接消费者与世界各地优质商品的桥梁。本文将在CSDN平台上,深入剖析跨境电商代购系统的功能流程,带您一窥其背后的技术奥秘与…...

Mac 上终端使用 MySql 记录
文章目录 下载安装终端进入 MySql常用操作查看数据库选择一个数据库查看当前选择的数据库Navcat 打开提示报错参考文章 下载安装 先下载社区版的 MySql 安装的过程需要设置 root 的密码,这个是要进入数据库所设定的,所以要记住 终端进入 MySql 首先输…...
461. 汉明距离
一:题目: 两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 示例 1: 输入:x 1, y 4 输出:2 解释: 1 (0 0…...

开发指南061-nexus权限管理
平台后台服务的核心是组件,管理组件的软件有: Apache的Archiva、JFrog的Artifactory、Sonatype的Nexus。 本平台选择nexus。nexus的权限模型是用户-角色-权限体系:通过组合权限定义角色,通过给用户赋角色来赋权限。有关nexus的权…...

Qt 弹出菜单右键菜单 QMenu 设置不同颜色的子项
概述 在Qt中,可以使用样式表(StyleSheet)来自定义 QMenu 的外观,包括其子项(如菜单项QAction)的颜色。但是,这通常可以设置 QMenu 的整体样式,而不能单独设置某个子项的颜色。不过&…...

Git换行符自动转换参数core.autocrlf的用法
core.autocrlf 是 Git 中用于控制换行符自动转换的配置选项。它有以下几个可能的值: 1. true 作用:在 checkin 时将 CRLF 转换为 LF,在 checkout 时将 LF 转换为 CRLF。适用场景:适用于 Windows 用户,希望在本地文件…...

C语言的结构体类型
在我们使用C语言进行编写代码时,常常会使用已经给定的类型来创建变量,比如int型,char型,double型等,而当我们想创建一些较为复杂的东西时,单单用一个类型变量是没办法做到的,比如我们想创建一个…...

illustrator 收集字体插件VBscript
这是早些年从俄罗斯网站上看到的一个收集字体插件,语言是用VBscript写的,能用,但个别字体不能收集完成,现在Adobe也在illustrator中加入了收集字体打包功能,所以这个也很少用啦。 使用方法: 下好插件,或把下面的代码存入到本地侯后缀名改为.vbs,然后把.ai文件往.vbs文…...

【LLM多模态】文生视频评测基准VBench
note VBench的16个维度自动化评估指标代码实践(待完成)16个维度的prompt举例人类偏好标注:计算VBench评估结果与人类偏好之间的相关性、用于DPO微调 文章目录 note一、相关背景二、VBench评测基准概述:论文如何解决这个问题&…...

通过覆写 url_for 将 flask 应用部署到子目录下
0. 缘起 最近用 flask 写了一个 web 应用,需要部署到服务器上。而服务器主域名已经被使用了,只能给主域名加个子目录进行部署,比如主域名 example.org ,我需要在 example.org/flask 下部署。这时 flask 应用里的内部连接们就出现…...

攻防世界---->埃尔隆德32
做题笔记。 下载 查壳。 32ida 打开。 发现就一个判断。 跟进看看。 // 首次a20 int __cdecl sub_8048414(_BYTE *a1, int a2) {int result; // eaxswitch ( a2 ){case 0:if ( *a1 105 )goto LABEL_19;result 0;break;case 1:if ( *a1 101 ) // e…...

【C语言之 CJson】从零到一:构建与解析JSON的实战指南
1. 为什么C语言需要处理JSON数据 在物联网设备和嵌入式系统开发中,JSON已经成为事实上的数据交换标准。我去年参与的一个智能家居项目就深有体会:设备配置、状态上报、控制指令全都采用JSON格式传输。用C语言处理这些数据时,手动拼接字符串不…...

用PyQt5给树莓派人脸门禁做个图形界面:从Qt Designer设计到移植上板的完整流程
树莓派人脸门禁系统GUI开发实战:从Qt设计到嵌入式部署的全链路解析 当硬件项目需要与用户交互时,一个直观的图形界面往往能大幅提升使用体验。本文将带您完整实现一个基于树莓派的人脸识别门禁系统GUI应用,涵盖从桌面端设计到嵌入式部署的全…...

WeChatMsg:5分钟轻松掌握微信聊天记录的终极管理方案
WeChatMsg:5分钟轻松掌握微信聊天记录的终极管理方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChat…...

从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南
从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南 在电子电路设计中,三极管作为基础却关键的元件,其选型直接影响着电路的可靠性和性能。特别是当我们需要驱动LED、继电器或电机等负载时,NPN与PNP三极管的…...
)
手把手教你用Zynq-7100 FPGA实现100Mbps OOK信号定时同步(含完整Verilog代码)
基于Zynq-7100的OOK信号定时同步实战:从算法到FPGA实现全解析 在无线通信系统中,定时同步是数字接收机设计中最关键的环节之一。当我们需要在Xilinx Zynq-7100 FPGA平台上实现100Mbps OOK信号的接收处理时,面临的最大挑战是如何在仅有50MHz外…...

本事同根生,相煎何太急
简 介: 【轮腿组比赛难度调整建议】针对智能车竞赛轮腿穿越组室外赛道的视觉识别难题,参赛选手提出以下建议:1.科目三元素应避开塑胶跑道线干扰区域;2.当前轮腿组任务量(机械、控制、导航、视觉等)已远超往…...

国货视光标杆|欧普康视企业实力与DreamVision SL巩膜镜产品详解
一、企业简介欧普康视科技股份有限公司成立于2000年,由留美工程博士陶悦群创立,是国内深耕眼视光医疗器械领域的高新技术企业。企业专注于眼视光产品的自主研发、智能化生产与合规销售,同时配套全周期专业化眼健康服务,业务覆盖屈…...

Godot引擎集成CEF实现Web混合渲染:gdcef项目架构与实战指南
1. 项目概述与核心价值最近在折腾一个老项目的现代化改造,需要把传统的桌面应用嵌入到Web视图中,实现混合渲染。在技术选型时,我绕不开一个名字:CEF,也就是Chromium Embedded Framework。它几乎是桌面应用内嵌浏览器控…...

Claude任务大师浏览器扩展:AI自动化工作流与Chrome插件开发实战
1. 项目概述与核心价值最近在折腾AI自动化工作流,发现一个痛点:虽然像Claude这样的AI助手能力很强,但每次想让它帮我处理网页内容,都得手动复制粘贴,效率实在太低。直到我发现了GitHub上一个名为“claude-task-master-…...

国产替代浪潮下,琳科森:深耕半导体封装胶膜,做 “小而精” 的硬核材料企业
在半导体产业链中,封装制程用功能性胶膜是保障芯片良率与可靠性的关键基础材料。长期以来,高端 UV 减粘膜、晶圆划片膜等产品高度依赖进口,国内企业面临技术壁垒高、洁净制造门槛大、配方体系复杂等挑战。江苏琳科森材料科技有限公司…...