【LLM多模态】文生视频评测基准VBench
note
- VBench的16个维度
- 自动化评估指标代码实践(待完成)
- 16个维度的prompt举例
- 人类偏好标注:计算VBench评估结果与人类偏好之间的相关性、用于DPO微调
文章目录
- note
- 一、相关背景
- 二、VBench评测基准
- 概述:论文如何解决这个问题?
- (1)视频质量(Video Quality)
- (2)视频条件一致性(Video-Condition Consistency)
- 三、相关实验
- (1)在所有指标上评估(Per-Dimension Evaluation)
- (2)验证VBench的人类对齐效果
- (3)在不同类别上评估
- 四、论文总结
- 五、其他文生视频的benchmark
- Reference
一、相关背景
论文:VBench: Comprehensive Benchmark Suite for Video Generative Models
CVPR 2024
- 相关背景
论文:VBench: Comprehensive Benchmark Suite for Video Generative Models
CVPR 2024
实时排名:https://huggingface.co/spaces/Vchitect/VBench_Leaderboard

Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为VBench的综合基准测试套件,旨在解决视频生成模型评估中存在的挑战。具体来说,它试图解决以下问题:
- 现有评估指标与人类感知不一致:传统的视频生成质量评估指标,如Inception Score (IS)、Fréchet inception distance (FID)、Fréchet Video Distance (FVD) 和 CLIPSIM,与人类的判断并不完全一致。这意味着这些指标可能无法准确反映人类对生成视频质量的真实感受。
- 缺乏全面的评估系统:理想的评估系统不仅应该能够准确反映人类对生成视频的感知,还应该能够揭示每个模型的具体优势和劣势,为未来的视频生成模型的数据、训练和架构选择提供指导。然而,现有的评估方法并没有为视频生成模型提供这样的全面评估。
为了解决这些问题,VBench通过以下方式提供了解决方案:
- 综合评估维度:VBench将视频生成质量分解为16个具体、分层和解耦的维度,每个维度都有专门的提示(prompts)和评估方法。
- 与人类感知的对齐:通过收集人类偏好注释来验证VBench评估与人类感知的一致性。
- 提供有价值的洞察:VBench能够从多个角度为视频生成社区提供详细的反馈,帮助评估现有模型的优势和劣势,并指导未来模型的改进。
总的来说,VBench旨在提供一个与人类感知更加一致、能够全面评估视频生成模型性能的基准测试套件,以推动视频生成技术的发展。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与VBench相关的研究领域和具体工作:
- 视频生成模型:最近,扩散模型(diffusion models)在图像合成方面取得了显著进展,并推动了一系列视频生成的工作。许多这些工作是基于文本到视频(text-to-video, T2V)的模型。
- 视觉生成模型的评估:现有的视频生成模型通常使用Inception Score (IS)、Fréchet inception distance (FID)、Fréchet Video Distance (FVD) 和 CLIPSIM等指标进行评估。然而,这些指标缺乏多样性和特异性,限制了对视频生成能力的准确和细粒度评估。
- 文本到图像(T2I)模型的评估:对于文本到图像模型,已经提出了几个基准来评估各种能力,如组合性和编辑能力。然而,视频生成模型仍然缺乏全面的评估基准,以提供详细和与人类对齐的反馈。
- 视频质量评估(VQA)方法:这些方法主要是为真实视频设计的,因此忽略了由生成模型带来的独特挑战,例如合成视频中的伪影。
- 与VBench并行的研究:论文中提到了一些并行的研究工作,这些工作也在探索视频生成模型的评估方法,但VBench在创建评估维度、与人类感知的一致性验证以及多维度和多类别评估方面有所不同。
- 视频编辑和视频合成:还有一些研究工作集中在视频编辑和视频合成上,这些工作提供了不同的方法和技术,用于生成或编辑视频内容。
- 视频理解:一些研究专注于视频内容的理解,包括动作识别、场景识别和视频字幕生成等。
- 图像和视频的美学评估:有研究工作致力于评估图像和视频的美学质量,这与VBench中评估视频质量的维度相关。
- 图像和视频的生成模型:包括使用GANs、VAEs、VQ-VAEs和扩散模型等生成高质量图像和视频的研究。
这些相关研究为VBench提供了背景和上下文,同时也表明了视频生成和评估领域是一个活跃的研究领域,需要像VBench这样的工具来推动进一步的发展。
二、VBench评测基准
概述:论文如何解决这个问题?
A: 论文通过提出VBench这一综合基准测试套件来解决视频生成模型评估中的问题。具体解决方案如下:
- 多维度评估:VBench将视频生成质量分解为16个具体、分层和解耦的维度,每个维度都有针对性的评估方法和提示(prompts)。这种多维度的方法可以更细致地评估视频生成模型的性能,并揭示模型在各个具体方面的优势和劣势。
- 与人类感知对齐:为了确保评估结果与人类感知一致,VBench收集了人类偏好注释,并验证了其评估方法与人类感知的一致性。这有助于提高评估结果的可靠性,并为未来的模型改进提供指导。
- 提供有价值的洞察:VBench的多维度和多类别评估方法能够为视频生成社区提供详细的反馈,帮助研究人员和开发者了解现有模型在不同方面的表现,并指导未来的模型训练、数据选择和架构设计。
- 开放和扩展性:VBench计划开源,包括所有的提示、评估方法、生成视频和人类偏好注释。这鼓励更多的研究者和开发者参与到视频生成模型的评估中来,并为VBench贡献更多的视频生成模型和评估维度。
- 评估方法的精心设计:对于每个评估维度,VBench都设计了专门的评估方法或指定的评估流程,以实现自动、客观的评估。
- 跨类别评估:VBench还包括了针对不同内容类别的提示套件,允许在各个类别内分别评估模型的性能,从而揭示模型在特定内容类型上的能力和需要改进的地方。
- 图像与视频生成模型的比较:VBench还能够评估图像生成模型,并调查视频和图像生成模型之间的差异,为两种类型的模型提供比较和洞见。
通过这些综合的方法,VBench旨在为视频生成领域提供一个全面、细致、与人类感知一致的评估工具,以推动该领域的进一步发展。
具体的16个指标:
VBench论文中提出的16个评估维度分为两大类:视频质量(Video Quality)和视频条件一致性(Video-Condition Consistency)。具体维度如下:

(1)视频质量(Video Quality)
时间维度的质量(Temporal Quality):
- 主体一致性(Subject Consistency):评估视频中主体(如人物、车辆等)的外观是否在不同帧中保持一致。
- 背景一致性(Background Consistency):评估视频背景场景在时间上的一致性。
- 时间闪烁(Temporal Flickering):评估视频中局部和高频细节的不完美时间一致性。
- 运动平滑性(Motion Smoothness):评估视频中生成的运动是否平滑,并遵循现实世界物理定律。
- 动态度(Dynamic Degree):评估视频中生成的动态程度,即是否包含大量运动。
帧质量(Frame-Wise Quality):
- 美学质量(Aesthetic Quality):评估每个视频帧的艺术性和美观价值。
- 成像质量(Imaging Quality):评估生成帧中的失真(如过曝、噪声、模糊)。
(2)视频条件一致性(Video-Condition Consistency)
语义(Semantics):
- 对象类别(Object Class):评估特定类别对象在视频中的生成成功率。
- 多个对象(Multiple Objects):评估视频中不同类别对象的组合能力。
- 人类动作(Human Action):评估视频中人物执行文本提示中特定动作的准确性。
- 颜色(Color):评估合成对象颜色与文本提示的一致性。
- 空间关系(Spatial Relationship):评估视频中对象间的空间关系是否遵循用户指令。比如a物体是否在b物体的左方(如果prompt这么要求)。
- 场景(Scene):评估合成视频与文本提示中描述的场景的一致性。如指令要求是ocean时不能生成river。
整体一致性(Overall Consistency):
使用视频-文本一致性计算作为辅助指标,反映语义和风格的一致性。
风格(Style):
外观风格(Appearance Style):评估视频与用户指令要求的风格(如油画风格、黑白风格等)的一致性。
时间风格(Temporal Style):评估视频的时间风格(如不同的摄像机运动)与文本提示的一致性。
注意:Temporal Style更多强调运镜/外观等的动态/视觉风格;Temporal Quality强调在时间维度上的连贯性、一致性(重点不在是否遵循用户指令)
在上面的16个指标中,每个指标都设计对应100个左右的prompt,不同的类别也是(比如针对不同的视频类别有对应的prompt,如动物、建筑、食品、人类、生活方式、植物、风景和交通场景八个视频类别),保证全方面进行测试:

对主流模型在16个评估指标上进行评测:

三、相关实验
(1)在所有指标上评估(Per-Dimension Evaluation)
- Empirical Max
- Empirical Min
- WebVid-Avg
(2)验证VBench的人类对齐效果
VBench评测结果和人类对齐标注数据高度一致:

(3)在不同类别上评估
动物、建筑、食品、人类、生活方式、植物、风景和交通场景八个视频类别

Q: 论文做了哪些实验?
A: 根据论文内容,作者们进行了一系列实验来验证VBench基准测试套件的有效性、与人类感知的一致性,以及提供对视频生成模型的深入洞察。以下是他们进行的主要实验:
- 按维度评估:对每个评估维度,使用VBench评估方法套件计算得分,并展示结果。这包括与Empirical Max、Empirical Min和WebVid-Avg等参考基线的比较。
- 验证VBench与人类感知的一致性:通过大规模人类注释来验证VBench评估方法是否能忠实反映人类感知。这涉及到计算每个模型在每个维度上的获胜比例,并与人类偏好注释进行比较。
- 按类别评估:在八个不同的内容类别中评估文本到视频(T2V)模型的性能,通过生成基于类别的提示套件的视频并计算不同评估维度上的表现。
- 视频生成与图像生成的比较:对文本到视频(T2V)模型和文本到图像(T2I)模型的帧级生成能力进行比较分析,以评估T2V模型在继承T2I模型帧级生成能力方面的成功程度,并调查现有T2I和T2V模型之间的帧级生成能力差距。
- 多模型评估:采用LaVie、ModelScope、VideoCrafter和CogVideo等视频生成模型进行VBench评估,并计划将更多开源模型纳入评估。
- 人类偏好注释:执行人类偏好标注,以验证VBench评估与人类感知的一致性,并展示人类偏好注释在未来任务中的潜在用途,例如微调生成和评估模型以提高与人类感知的一致性。
- 实验结果的可视化:通过雷达图和其他可视化手段展示实验结果,以清晰地展示不同模型在各个评估维度上的性能。
- 提供洞察和讨论:基于VBench评估结果,讨论观察到的现象和洞察,例如不同能力维度之间的权衡、特定内容类别中T2V模型的潜力、复杂类别的挑战等。
四、论文总结
Q: 总结一下论文的主要内容
A: 这篇论文介绍了VBench,一个全面的视频生成模型基准测试套件。以下是论文的主要内容总结:
- 问题识别:视频生成技术迅速发展,但现有评估方法无法全面反映人类对生成视频质量的感知,且缺乏对模型优势和劣势的深入洞察。
- VBench套件介绍:提出了VBench,一个包含16个评估维度的分层和解耦的评估体系,每个维度都有专门的提示和评估方法。
- 评估维度:VBench的评估维度分为两大类——视频质量和视频条件一致性,进一步细分为多个子维度,如主题一致性、背景一致性、时间闪烁、运动平滑度等。
- 人类感知对齐:通过收集人类偏好注释来验证VBench评估与人类感知的一致性,并展示了评估结果与人类偏好的高度相关性。
- 洞察提供:VBench能够提供多角度的反馈,帮助评估现有模型的性能,并为未来模型的训练、数据选择和架构设计提供指导。
- 实验验证:对LaVie、ModelScope、VideoCrafter和CogVideo等视频生成模型进行了评估,并通过实验展示了VBench的有效性和与人类感知的一致性。
- 内容类别评估:VBench还包括了按内容类别组织的提示套件,允许在不同类别中评估模型的性能。
- 图像与视频生成模型比较:使用VBench评估了图像生成模型,并与视频生成模型进行了比较,探讨了两者之间的差异。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
- 扩展评估维度:虽然VBench已经包含了16个评估维度,但随着视频生成技术的发展,可能会出现新的挑战和特性,需要添加新的评估维度来覆盖。
- 增加更多模型:目前开源的视频到视频(T2V)模型数量有限,未来可以包括更多的模型进行评估,以提供更全面的比较和分析。
- 评估其他视频生成任务:除了文本到视频(T2V)任务,还有视频编辑、图像到视频转换、个性化视频生成等其他视频生成任务,VBench可以扩展以评估这些任务。
- 提高评估方法的自动化和精确度:尽管VBench提供了一套评估方法,但自动化评估的精确度和可靠性仍可以进一步提高,以更好地反映人类感知。
- 考虑伦理和社会影响:在未来的迭代中,考虑包括安全性和平等性维度,以确保视频生成模型的评估不仅技术上有效,也符合伦理和社会标准。
- 数据集的多样性和质量:研究不同数据集的多样性和质量如何影响视频生成模型的性能,并探索如何通过数据集的选择和清洗来提高模型的泛化能力。
- 模型的可解释性和透明度:提高视频生成模型的可解释性,让研究人员和用户更好地理解模型的决策过程和潜在的偏差。
- 用户研究和反馈:进行用户研究,收集用户对生成视频的反馈,以进一步指导评估标准的制定和模型的改进。
- 跨模态评估:探索如何将视频生成模型的评估与其他模态(如音频、文本)结合,以评估多模态生成系统的综合性能。
- 实时性能评估:研究如何评估视频生成模型在实时或近实时条件下的性能,这对于实际应用非常重要。
- 模型鲁棒性评估:评估视频生成模型在面对各种异常输入或对抗性攻击时的鲁棒性。
- 模型效率和可扩展性:除了质量评估之外,还可以考虑模型的计算效率和可扩展性,这对于资源有限的环境或大规模应用尤为重要。
五、其他文生视频的benchmark
常见的文生视频评测集benchmark包括:
- AIGCBench:这是一个全面且可扩展的基准测试,专为评估视频生成任务而设计,特别关注图像到视频(Image-to-Video, I2V)的生成。AIGCBench包括多个维度的评估指标,涵盖控制视频对齐、运动效果、时间一致性和视频质量等方面。它还包括一个多样化的真实世界视频-文本和图像-文本数据集,以及通过专有生成管道产生的新数据集。
- VBench:VBench是一个全面的视频生成模型基准测试套件,它将“视频生成质量”分解为多个定义明确的维度,以便于进行细致和客观的评估。VBench包括16个维度,如主体身份不一致性、运动平滑度、时间闪烁和空间关系等。它还提供了与人类感知一致的人类偏好注释数据集,以验证基准测试与人类感知的一致性。
- FETV:FETV是一个用于细粒度评估开放领域文本到视频生成的基准测试。它通过多方面分类文本来评估T2V模型,揭示了不同类别提示下模型的优缺点。FETV还扩展为一个测试平台,用于评估自动T2V指标的可靠性。
Reference
[1] VBench: Comprehensive Benchmark Suite for Video Generative Models
[2] VBench:视频生成模型评测体系 | CVPR 2024
相关文章:
【LLM多模态】文生视频评测基准VBench
note VBench的16个维度自动化评估指标代码实践(待完成)16个维度的prompt举例人类偏好标注:计算VBench评估结果与人类偏好之间的相关性、用于DPO微调 文章目录 note一、相关背景二、VBench评测基准概述:论文如何解决这个问题&…...

通过覆写 url_for 将 flask 应用部署到子目录下
0. 缘起 最近用 flask 写了一个 web 应用,需要部署到服务器上。而服务器主域名已经被使用了,只能给主域名加个子目录进行部署,比如主域名 example.org ,我需要在 example.org/flask 下部署。这时 flask 应用里的内部连接们就出现…...

攻防世界---->埃尔隆德32
做题笔记。 下载 查壳。 32ida 打开。 发现就一个判断。 跟进看看。 // 首次a20 int __cdecl sub_8048414(_BYTE *a1, int a2) {int result; // eaxswitch ( a2 ){case 0:if ( *a1 105 )goto LABEL_19;result 0;break;case 1:if ( *a1 101 ) // e…...

redis短信登录模型
基于Session实现登录 ,...
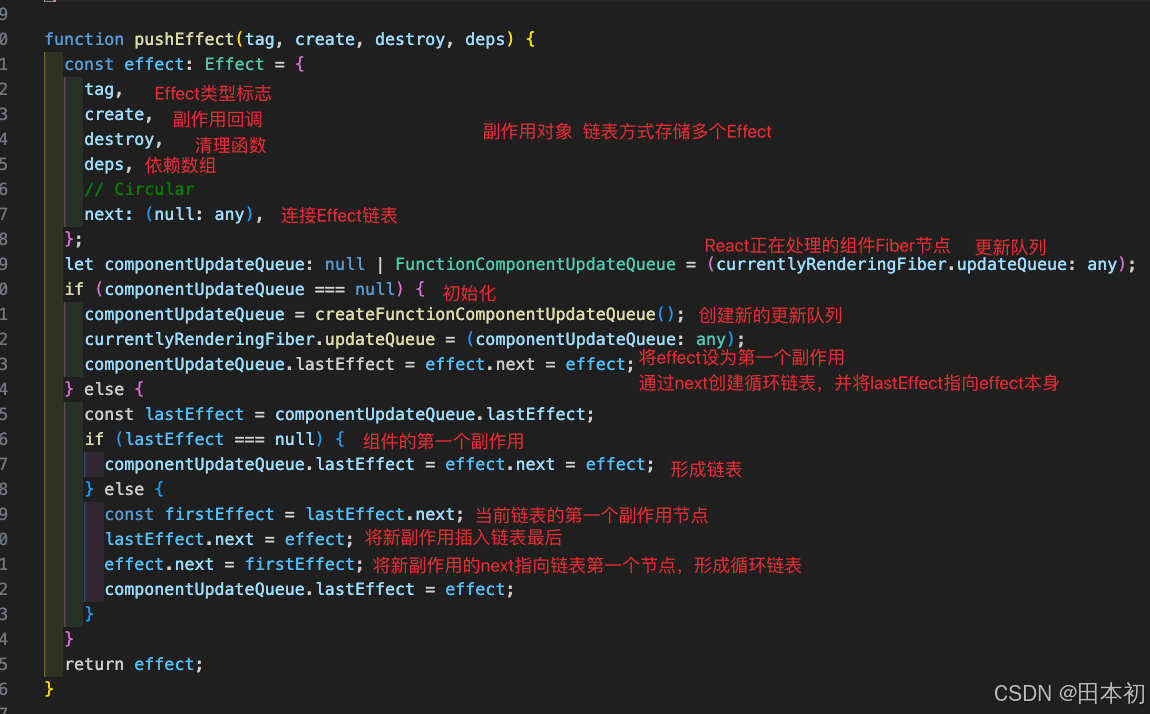
【React】React18.2.0核心源码解读
前言 本文使用 React18.2.0 的源码,如果想回退到某一版本执行git checkout tags/v18.2.0即可。如果打开源码发现js文件报ts类型错误请看本人另一篇文章:VsCode查看React源码全是类型报错如何解决。 阅读源码的过程: 下载源码 观察 package…...

深度学习-目标检测(四)-Faster R-CNN
目录 一.模型框架 二:步骤详细 1.conv layers 2.RPN 3.anchors 4.cls layer分类 5.reg layer回归 6.Proprosal 7.Rol pooling 8.Classification 三.训练 1.训练RPN网络 2.全连接层部分训练: 都看到这里了,点个赞把!&a…...

MATLAB中的无线通信系统设计有哪些最佳实践
在无线通信系统设计领域,MATLAB提供了一套强大的工具箱,使得系统设计、仿真、测试和分析变得更加高效和精确。本文将探讨MATLAB在无线通信系统设计中的最佳实践,包括信号处理、调制与解调、信道建模、误码率分析以及无线通信标准的实现。 1.…...

Java的发展史与前景
🌈个人主页:Yui_ 🌈Linux专栏:Linux 🌈C语言笔记专栏:C语言笔记 🌈数据结构专栏:数据结构 🌈C专栏:C 文章目录 0. Java语言的发展史1.概述1.1 什么是Java1.2 …...

2024年上海小学生古诗文大会倒计时30多天:做几道今年的官方模拟题
2024年上海市小学生古诗文大会自由报名活动的初赛日期于10月19日开始,距离今天只有34天了。 小学生古诗文大会考什么?怎么考呢?今天好真题就带着大家来做一做官方发布的2024年小学生古诗文大会的模拟题,根据往年的经验࿰…...

IDEA 常用配置和开发插件
件市场中搜索并安装“Git Integration”插件。 一、前言 在本篇文章中我会为大家总结一些我自己常用的配置和开发插件,此外也给大家提供一个建议,可以根据自己的项目需求和个人偏好选择适合的插件。另外,IDEA 也在不断更新,可能会…...

还在为企微联系人烦恼?一招解决!企业微信2024年效率升级全攻略
现在信息多得让人眼花,微信里头那些企业微信的联系人是不是让你头疼? 看着满屏的绿色头像,心里想:“我就想和朋友聊聊天,怎么就这么难?”别急,今天教你个办法,轻松搞定这些小烦恼&am…...

【docker npm】npm 私库
1.部署环境 window 11 x64Docker Desktop 4.34.1 (166053) Docker Engine v27.2.0 1.1.Docker 镜像源 1.1.1.Docker Engine 配置 {"builder": {"features": {"buildkit": true},"gc": {"defaultKeepStorage": "32…...

完整gpt应用(自用)
qrc.py 把gpt_qrc.qrc转化成gpt_qrc.py pyrcc5 -o icons_rc.py icons.qrc <RCC><qresource prefix"img"><file>img/53.png</file><file>img/ai.png</file><file>img/关闭.png</file><file>img/最小化.png&l…...

【信息论基础第二讲】离散信源的数学模型及其信息测度包括信源的分类、信源的数学模型、离散信源的信息测度、二元信源的条件熵联合熵
一、信源的分类 二、信源的数学模型 1、信源的概念 在通信系统中,收信者在未收到信息以前,对信源发出什么消息是不确定的、随机的、因此我们可以用随机变量、随机序列或者随机过程来描述信源的输出。严格地说,用概率空间来描述信源输出。 …...

在 Spring Boot 项目中连接 IBM AS/400 数据库——详细案例教程
文章目录 1. 添加 jt400 依赖2. 下载 jt400 驱动包依赖下载手动下载下载地址:手动下载 JAR 的步骤: 3. 配置 application.properties 或 application.yml(1)application.properties(2)application.yml 4. 数…...

VUE + NODE 历史版本安装
以node 12.20.0为例子,想下载哪个版本,后面写哪个版本 https://registry.npmmirror.com/binary.html?pathnode/v12.20.0/ 安装国内镜像7.1.0 cnpm npm install -g cnpm7.1.0 -g --registryhttps://registry.npmmirror.com 安装vue脚手架4.5.15 cnpm …...

git reset 几点疑问
疑问:使用 git reset --hard <commit-hash-from-branch-B> 将工作区状态reset为其他branch的某点。 如果当前工作区的分支(比如 branch A)上使用 git reset --hard 将其状态重置为另一个分支(比如 branch B)的某…...
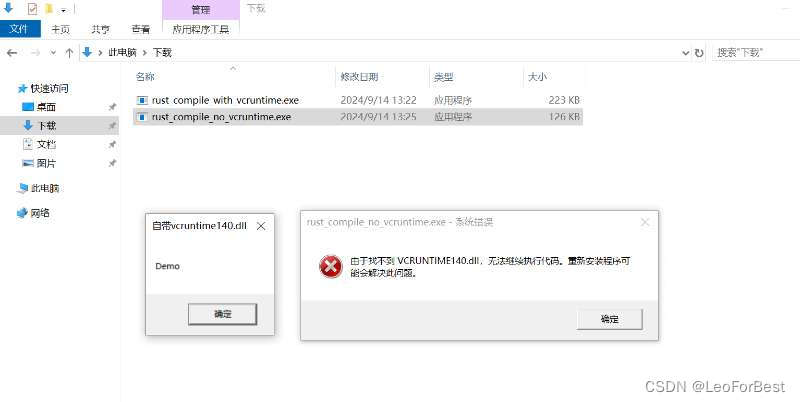
Rust Windows下编译 静态链接VCRuntime140.dll
Rust 编译出来的exe默认动态链接VC运行库,分发电脑上需要安装有Microsoft Visual C Redistributable for Visual Studio 2015运行库。 编译时能静态链接进去,就省去客户端未安装运行库的问题。方法如下: 只需在当前根目录下新建.cargo\config.toml&#…...

从“天宫课堂”到人工智能:中国少儿编程的未来在哪里?
近日,中国载人航天“天宫课堂”第三次开讲,激发了全国数百万青少年对科技的热情。从航天技术到人工智能,科技的快速发展正不断改变我们的生活,也让越来越多的家长意识到,未来属于那些掌握编程和创新思维的孩子。与其让…...

ARM base instruction -- blr
BLR Branch with Link to Register calls a subroutine at an address in a register, setting register X30 to PC4. 带寄存器链接的分支在寄存器中的某个地址调用一个子程序,将寄存器 X30 (lr) 设置为 PC4。 BLR <Xn> BLR 跳转到reg内容地址,…...
)
TVA 在宠物混合监护场景中的创新应用(5)
重磅预告:本专栏将独家连载新书《智能体视觉技术与应用》(系列丛书)部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。…...

STM32F407霸天虎实战:用硬件I2C点亮OLED,顺便聊聊软件模拟I2C的坑
STM32F407硬件I2C驱动OLED全攻略:从原理到避坑指南 在嵌入式开发中,显示模块的选择往往决定了用户体验的上限。0.96寸OLED凭借其高对比度、低功耗和轻薄特性,成为众多项目的首选。但如何为它选择合适的通信方式?本文将带你深入STM…...

Windows 10系统优化深度指南:使用Win10BloatRemover打造高效工作环境
Windows 10系统优化深度指南:使用Win10BloatRemover打造高效工作环境 【免费下载链接】Win10BloatRemover Configurable CLI tool to easily and aggressively debloat and tweak Windows 10 by removing preinstalled UWP apps, services and more. Originally bas…...

Cursor AI插件开发指南:构建企业级智能编码助手
1. 项目概述:一个为开发者而生的智能编码伴侣如果你是一名开发者,每天在IDE里敲代码的时间超过8小时,那你一定对“上下文切换”和“信息查找”这两件事深恶痛绝。想象一下,你正在写一个复杂的API接口,突然需要回忆上周…...

贪吃蛇游戏开发实战:从基础架构到错误监控与性能优化
1. 项目概述:一个“会说话”的贪吃蛇游戏最近在GitHub上看到一个挺有意思的项目,叫“BugSplat-Git/snake-game”。初看标题,你可能觉得这不就是个经典的贪吃蛇游戏吗?从诺基亚时代玩到现在的玩意儿,还能有什么新花样&a…...

AI VTuber技术栈全解析:从Live2D到GPT-SoVITS的实战搭建指南
1. 项目概述:为什么我们需要一份AI VTuber的“Awesome”清单? 如果你最近在GitHub、B站或者一些技术社区里逛过,大概率会看到一个词反复出现: AI VTuber 。它不再是科幻电影里的概念,而是正在快速渗透到直播、内容创…...

Web无障碍性自动化检查:CLI工具集成与工程实践指南
1. 项目概述:一个为开发者赋能的Web无障碍性CLI工具 如果你是一名前端开发者、测试工程师,或者正在构建一个需要服务广泛用户群体的Web应用,那么“无障碍性”(Accessibility, 常缩写为 a11y)这个词对你来说…...

PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解
PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解 在处理数据库时,日期和时间操作几乎是每个开发者都会遇到的挑战。PostgreSQL作为功能强大的开源关系型数据库,提供了丰富的日期时间处理函数,能够…...

xpull:轻量级声明式文件同步工具的设计原理与K8s实战
1. 项目概述:一个轻量级、高可用的文件同步利器在分布式系统、微服务架构乃至日常的自动化运维中,文件同步是一个看似基础却至关重要的环节。无论是将日志文件从边缘服务器拉取到中心进行分析,还是将配置文件从版本库分发到成百上千个实例&am…...

前台测试想转后台优化?这4个条件缺一不可,否则别折腾
很多做前台测试的兄弟都问过同一个问题:我能不能转后台?今天这篇文章,一次性把后台工程师的准入清单说清楚。一、基础条件:5条缺一不可年龄20-50岁太小的缺经验,太大的学新东西慢,这个区间刚刚好。有网优基…...