如何精确统计Pytorch模型推理时间
文章目录
- 0 背景
- 1 精确统计方法
- 2 手动synchronize和Event适用场景
0 背景
在分析模型性能时需要精确地统计出模型的推理时间,但仅仅通过在模型推理前后打时间戳然后相减得到的时间其实是Host侧向Device侧下发指令的时间。如下图所示,Host侧下发指令与Device侧计算实际上是异步进行的。

1 精确统计方法
比较常用的精确统计方法有两种,一种是手动调用同步函数等待Device侧计算完成。另一种是通过Event方法在Device侧记录时间戳。

下面示例代码中分别给出了直接在模型推理前后打时间戳相减,使用同步函数以及Event方法统计模型推理时间(每种方法都重复50次,忽略前5次推理,取后45次的平均值)。
import timeimport torch
import torch.nn as nnclass CustomModel(nn.Module):def __init__(self):super().__init__()self.part0 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=512, kernel_size=3, stride=2, padding=1),nn.GELU(),nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=2, padding=1),nn.GELU())self.part1 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(1, 1)),nn.Flatten(),nn.Linear(in_features=1024, out_features=2048),nn.GELU(),nn.Linear(in_features=2048, out_features=512),nn.GELU(),nn.Linear(in_features=512, out_features=1))def forward(self, x):x = self.part0(x)x = self.part1(x)return xdef cal_time1(model, x):with torch.inference_mode():time_list = []for _ in range(50):ts = time.perf_counter()ret = model(x)td = time.perf_counter()time_list.append(td - ts)print(f"avg time: {sum(time_list[5:]) / len(time_list[5:]):.5f}")def cal_time2(model, x):device = x.devicewith torch.inference_mode():time_list = []for _ in range(50):torch.cuda.synchronize(device)ts = time.perf_counter()ret = model(x)torch.cuda.synchronize(device)td = time.perf_counter()time_list.append(td - ts)print(f"syn avg time: {sum(time_list[5:]) / len(time_list[5:]):.5f}")def cal_time3(model, x):with torch.inference_mode():start_event = torch.cuda.Event(enable_timing=True)end_event = torch.cuda.Event(enable_timing=True)time_list = []for _ in range(50):start_event.record()ret = model(x)end_event.record()end_event.synchronize()time_list.append(start_event.elapsed_time(end_event) / 1000)print(f"event avg time: {sum(time_list[5:]) / len(time_list[5:]):.5f}")def main():device = torch.device("cuda:0")model = CustomModel().eval().to(device)x = torch.randn(size=(32, 3, 224, 224), device=device)cal_time1(model, x)cal_time2(model, x)cal_time3(model, x)if __name__ == '__main__':main()终端输出:
avg time: 0.00023
syn avg time: 0.04709
event avg time: 0.04710
通过终端输出可以看到,如果直接在模型推理前后打时间戳相减得到的时间非常短(因为并没有等待Device侧计算完成)。而使用同步函数或者Event方法统计的时间明显要长很多。
2 手动synchronize和Event适用场景
通过上面的代码示例可以看到,通过同步函数统计的时间和Event方法统计的时间基本一致(差异1ms内)。那两者有什么区别呢?如果只是简单统计一个模型的推理时间确实看不出什么差异。但如果要统计一个完整AI应用通路(其中可能包含多个模型以及各种CPU计算)中不同模型的耗时,而又不想影响到整个通路的性能,那么建议使用Event方法。因为使用同步函数可能会让Host长期处于等待状态,等待过程中也无法干其他的事情,从而导致计算资源的浪费。可以看看下面这个示例,整个通路由Model1推理+一段纯CPU计算+Model2推理串行构成,假设想统计一下model1、model2推理分别用了多长时间:
import timeimport torch
import torch.nn as nn
import numpy as npclass CustomModel1(nn.Module):def __init__(self):super().__init__()self.part0 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=512, kernel_size=3, stride=2, padding=1),nn.GELU(),nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=2, padding=1),nn.GELU())def forward(self, x):x = self.part0(x)return xclass CustomModel2(nn.Module):def __init__(self):super().__init__()self.part1 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(1, 1)),nn.Flatten(),nn.Linear(in_features=1024, out_features=2048),nn.GELU(),nn.Linear(in_features=2048, out_features=512),nn.GELU(),nn.Linear(in_features=512, out_features=1))def forward(self, x):x = self.part1(x)return xdef do_pure_cpu_task():x = np.random.randn(1, 3, 512, 512)x = x.astype(np.float32)x = x * 1024 ** 0.5def cal_time2(model1, model2, x):device = x.devicewith torch.inference_mode():time_total_list = []time_model1_list = []time_model2_list = []for _ in range(50):torch.cuda.synchronize(device)ts1 = time.perf_counter()ret = model1(x)torch.cuda.synchronize(device)td1 = time.perf_counter()do_pure_cpu_task()torch.cuda.synchronize(device)ts2 = time.perf_counter()ret = model2(ret)torch.cuda.synchronize(device)td2 = time.perf_counter()time_model1_list.append(td1 - ts1)time_model2_list.append(td2 - ts2)time_total_list.append(td2 - ts1)avg_model1 = sum(time_model1_list[5:]) / len(time_model1_list[5:])avg_model2 = sum(time_model2_list[5:]) / len(time_model2_list[5:])avg_total = sum(time_total_list[5:]) / len(time_total_list[5:])print(f"syn avg model1 time: {avg_model1:.5f}, model2 time: {avg_model2:.5f}, total time: {avg_total:.5f}")def cal_time3(model1, model2, x):with torch.inference_mode():model1_start_event = torch.cuda.Event(enable_timing=True)model1_end_event = torch.cuda.Event(enable_timing=True)model2_start_event = torch.cuda.Event(enable_timing=True)model2_end_event = torch.cuda.Event(enable_timing=True)time_total_list = []time_model1_list = []time_model2_list = []for _ in range(50):model1_start_event.record()ret = model1(x)model1_end_event.record()do_pure_cpu_task()model2_start_event.record()ret = model2(ret)model2_end_event.record()model2_end_event.synchronize()time_model1_list.append(model1_start_event.elapsed_time(model1_end_event) / 1000)time_model2_list.append(model2_start_event.elapsed_time(model2_end_event) / 1000)time_total_list.append(model1_start_event.elapsed_time(model2_end_event) / 1000)avg_model1 = sum(time_model1_list[5:]) / len(time_model1_list[5:])avg_model2 = sum(time_model2_list[5:]) / len(time_model2_list[5:])avg_total = sum(time_total_list[5:]) / len(time_total_list[5:])print(f"event avg model1 time: {avg_model1:.5f}, model2 time: {avg_model2:.5f}, total time: {avg_total:.5f}")def main():device = torch.device("cuda:0")model1 = CustomModel1().eval().to(device)model2 = CustomModel2().eval().to(device)x = torch.randn(size=(32, 3, 224, 224), device=device)cal_time2(model1, model2, x)cal_time3(model1, model2, x)if __name__ == '__main__':main()终端输出:
syn avg model1 time: 0.04725, model2 time: 0.00125, total time: 0.05707
event avg model1 time: 0.04697, model2 time: 0.00099, total time: 0.04797
通过终端打印的结果可以看到无论是使用同步函数还是Event方法统计的model1、model2的推理时间基本是一致的。但对于整个通路而言使用同步函数时总时间明显变长了。下图大致解释了为什么使用同步函数时导致整个通路变长的原因,主要是在model1发送完指令后使用同步函数时会一直等待Device侧计算结束,期间啥也不能干。而使用Event方法时在model1发送完指令后不会阻塞Host,可以立马去进行后面的CPU计算任务。

相关文章:
如何精确统计Pytorch模型推理时间
文章目录 0 背景1 精确统计方法2 手动synchronize和Event适用场景 0 背景 在分析模型性能时需要精确地统计出模型的推理时间,但仅仅通过在模型推理前后打时间戳然后相减得到的时间其实是Host侧向Device侧下发指令的时间。如下图所示,Host侧下发指令与De…...

Mybatis-plus-Generator 3.5.5 自定义模板支持 (DTO/VO 等) 配置
随着项目节奏越来越快,为了减少把时间浪费在新建DTO 、VO 等地方,直接直接基于Mybatis-plus 这颗大树稍微扩展一下,在原来生成PO、 DAO、Service、ServiceImpl、Controller 基础新增。为了解决这个问题,网上找了一堆资料ÿ…...

C#环境下MAC地址获取方法解析
在C#中,获取MAC地址并不是直接支持的,因为出于安全和隐私的考虑,操作系统通常会限制对这类硬件信息的直接访问。不过,仍然可以通过一些方法间接地获取到本地网络接口(比如以太网接口)的MAC地址。 以下是几…...
Kubernetes 从0到1容器编排之旅)
(k8s)Kubernetes 从0到1容器编排之旅
一、引言 在当今数字化的浪潮中,Kubernetes 如同一艘强大的航船,引领着容器化应用的部署与管理。它以其卓越的灵活性、可扩展性和可靠性,成为众多企业和开发者的首选。然而,要真正发挥 Kubernetes 的强大威力,仅仅掌握…...

Rust Web开发框架对比:Warp与Actix-web
文章目录 Rust Web开发框架对比:Warp与Actix-web引言框架概述Warp框架简介Actix-web框架简介 设计理念Warp的设计理念Actix-web的设计理念 性能比较可扩展性和生态插件和中间件支持社区和文档 使用示例使用Warp构建简单的HTTP服务使用Actix-web构建简单的HTTP服务 学…...

F12抓包12:Performance(性能)前端性能分析
课程大纲 使用场景: ① 前端界面加载性能测试。 ② 导出性能报告给前端开发。 复习:后端(接口)性能分析 ① 所有请求耗时时间轴:“网络”(Network) - 概览。 ② 单个请求耗时:“网络”(Network…...

数据结构(Day13)
一、学习内容 内存空间划分 1、一个进程启动后,计算机会给该进程分配4G的虚拟内存 2、其中0G-3G是用户空间【程序员写代码操作部分】【应用层】 3、3G-4G是内核空间【与底层驱动有关】 4、所有进程共享3G-4G的内核空间,每个进程独立拥有0G-3G的用户空间 …...

链表的快速排序(C/C++实现)
一、前言 大家在做需要排名的项目的时候,需要把各种数据从高到低排序。如果用的快速排序的话,处理数组是十分简单的。因为数组的存储空间的连续的,可以通过下标就可以简单的实现。但如果是链表的话,内存地址是随机分配的…...
)
css总结(记录一下...)
文字 语法说明word-wrapword-wrap:normal| break-word normal:使用浏览器默认的换行 break-word:允许在单词内换行 text-overflow clip:修剪文本 ellipsis:显示省略符号来代表被修剪的文本 text-shadow可向文本应用的阴影。能够规定水平阴影、垂直阴影、模糊距离,以…...

SpringBoot 处理 @KafkaListener 消息
消息监听容器 1、KafkaMessageListenerContainer 由spring提供用于监听以及拉取消息,并将这些消息按指定格式转换后交给由KafkaListener注解的方法处理,相当于一个消费者; 看看其整体代码结构: 可以发现其入口方法为doStart(),…...

Spring Boot-API版本控制问题
在现代软件开发中,API(应用程序接口)版本控制是一项至关重要的技术。随着应用的不断迭代,API 的改动不可避免,如何在引入新版本的同时保证向后兼容,避免对现有用户的影响,是每个开发者需要考虑的…...

Git 提取和拉取的区别在哪
1. 提取(Fetch) 操作说明:Fetch 操作会从远程仓库下载最新的提交、分支信息等,但不会将这些更改合并到你当前的分支中。它只是将远程仓库的更新信息存储在本地,并不会自动修改你当前的工作区。 使用场景: …...

【数据结构与算法 | 每日一题 | 力扣篇】力扣2390, 2848
1. 力扣2390:从字符串中删除星号 1.1 题目: 给你一个包含若干星号 * 的字符串 s 。 在一步操作中,你可以: 选中 s 中的一个星号。移除星号 左侧 最近的那个 非星号 字符,并移除该星号自身。 返回移除 所有 星号之…...
破解信息架构实施的密码:常见挑战与最佳解决方案全指南
信息架构的成功实施是企业数字化转型的关键步骤,但在实际操作中,企业往往会遇到各种复杂的挑战。这些挑战包括 技术整合的难度、数据管理的复杂性、合规性要求的变化 以及 资源限制 等。《信息架构:商业智能&分析与元数据管理参考模型》为…...
 A~D)
CodeChef Starters 151 (Div.2) A~D
codechef是真敢给分,上把刚注册,这把就div2了,再加上一周没打过还是有点不适应的,好在最后还是能够顺利上分 今天的封面是P3R的设置菜单 我抠出来做我自己的游戏主页了( A - Convert string 题意 在01串里面可以翻转…...

Redis学习——数据不一致怎么办?更新缓存失败了又怎么办?
文章目录 引言正文读写缓存的数据一致性只读缓存的数据一致性删除和修改数据不一致问题操作执行失败导致数据不一致解决办法 多线程访问导致数据不一致问题总结 总结参考信息 引言 最近面试快手的时候被问到了缓存不一致怎么解决?一开始还是很懵的,因为…...
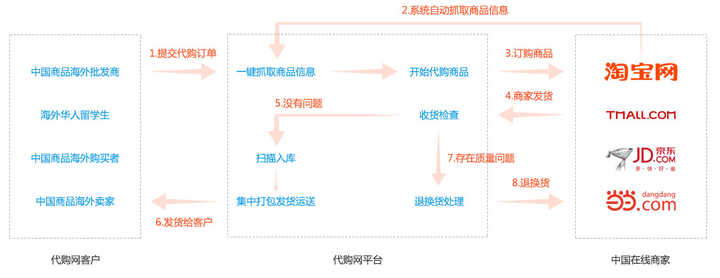
跨境电商代购新纪元:一键解锁全球好物,系统流程全揭秘
添加图片注释,不超过 140 字(可选) 在全球化日益加深的今天,跨境电商代购成为了连接消费者与世界各地优质商品的桥梁。本文将在CSDN平台上,深入剖析跨境电商代购系统的功能流程,带您一窥其背后的技术奥秘与…...

Mac 上终端使用 MySql 记录
文章目录 下载安装终端进入 MySql常用操作查看数据库选择一个数据库查看当前选择的数据库Navcat 打开提示报错参考文章 下载安装 先下载社区版的 MySql 安装的过程需要设置 root 的密码,这个是要进入数据库所设定的,所以要记住 终端进入 MySql 首先输…...
461. 汉明距离
一:题目: 两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 示例 1: 输入:x 1, y 4 输出:2 解释: 1 (0 0…...

开发指南061-nexus权限管理
平台后台服务的核心是组件,管理组件的软件有: Apache的Archiva、JFrog的Artifactory、Sonatype的Nexus。 本平台选择nexus。nexus的权限模型是用户-角色-权限体系:通过组合权限定义角色,通过给用户赋角色来赋权限。有关nexus的权…...

Photoshop图层批量导出神器:快速高效导出PSD图层为独立文件的最佳解决方案
Photoshop图层批量导出神器:快速高效导出PSD图层为独立文件的最佳解决方案 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ado…...
)
用STM32F103和电位器给你的无刷电机做个“油门”:手把手实现ADC调速(附完整代码)
用STM32F103和电位器打造无刷电机调速系统:从硬件连接到代码实战 旋转电位器旋钮就能精准控制无刷电机转速,这种直观的交互方式在机器人、无人机和工业控制领域有着广泛应用。本文将带您从零开始,基于STM32F103微控制器构建完整的电位器调速…...

构建多模型备选策略以提升AI应用服务稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型备选策略以提升AI应用服务稳定性 在将大模型能力集成到生产应用时,服务可用性是核心考量之一。依赖单一模型…...

别再手动改路由了!用Ant Design Vue的Menu组件动态生成“顶一左多”级导航菜单
基于Ant Design Vue的声明式导航菜单架构设计 在复杂后台管理系统开发中,导航菜单的动态生成与权限控制一直是架构设计的难点。传统方案往往需要在多个组件中硬编码菜单结构,导致维护成本高、权限同步困难。本文将介绍如何利用Ant Design Vue的Menu组件与…...

吃透护网面试!HVV 行动全套面试题目及答案,网安新人入门进阶必备
本文全面整理网络安全面试题,涵盖HVV、OWASP Top 10漏洞原理与修复方法。详细讲解内网渗透技术、权限维持方法、Windows/Linux系统提权技巧,以及渗透测试流程和应急响应策略。还包含红蓝对抗概念、漏洞挖掘经验、常见中间件漏洞和安全基础知识࿰…...

GESP学习,如何判断孩子是否适合跳级
判断孩子是否适合跳级,核心是综合评估其学术能力、心理成熟度、社交适应力及政策合规性。以下是基于教育规律与官方政策的系统性判断标准: 一、学术能力:是否真正“学有余力” 1、成绩特别优异: 在当前年级中,各…...

纯文本CRM:用Markdown与Git构建极简客户关系管理系统
1. 项目概述与核心价值最近在开源社区里,我注意到一个名为anthroos/plaintext-crm的项目,它提出了一种非常规的客户关系管理(CRM)思路。简单来说,这个项目主张用纯文本文件(如 Markdown、TXT)来…...
工作流使用攻略 操作指南(2026最新版))
Coze(扣子)工作流使用攻略 操作指南(2026最新版)
Coze工作流(Workflow)是实现复杂AI任务的核心工具,它通过可视化拖拽节点的方式,将大模型、插件、代码、数据库等组件组合成自动化流程。适合处理多步骤、结构化任务(如内容生成、数据分析、图像处理、客服流程等&#…...

SMILES编码实战:从原子到环状结构的精准表达
1. SMILES编码入门:化学结构的字母游戏 第一次接触SMILES字符串时,我盯着"C1CCCCC1"这样的字符组合愣了半天——这串看似随机的字母数字组合,竟然能完整描述环己烷的分子结构。SMILES(Simplified Molecular Input Line…...

AP431比较器应用设计与动态响应优化
1. AP431作为比较器的设计背景与特性解析在模拟电路设计中,电压基准源和比较器是两个最基础的构建模块。AP431作为行业标准431系列的一员,最初的设计定位是精密电压基准源,用于替代传统齐纳二极管。其核心价值在于内部集成了一个高精度2.5V带…...