【AI大模型】ChatGPT模型原理介绍(下)

目录
🍔 GPT-3介绍
1.1 GPT-3模型架构
1.2 GPT-3训练核心思想
1.3 GPT-3数据集
1.4 GPT-3模型的特点
1.5 GPT-3模型总结
🍔 ChatGPT介绍
2.1 ChatGPT原理
2.2 什么是强化学习
2.3 ChatGPT强化学习步骤
2.4 监督调优模型
2.5 训练奖励模型
2.6 使用 PPO 模型微调 SFT 模型
2.7 ChatGPT特点
🍔 小结
学习目标
🍀 了解ChatGPT的本质
🍀 了解GPT系列模型的原理和区别
🍔 GPT-3介绍
2020年5月, OpenAI发布了GPT-3, 同时发表了论文“Language Models are Few-Shot Learner”《小样本学习者的语言模型》.
通过论文题目可以看出:GPT-3 不再去追求那种极致的不需要任何样本就可以表现很好的模型,而是考虑像人类的学习方式那样,仅仅使用极少数样本就可以掌握某一个任务,但是这里的 few-shot 不是像之前的方式那样,使用少量样本在下游任务上去做微调,因为在 GPT-3 那样的参数规模下,即使是参数微调的成本也是高到无法估计。
GPT-3 作为其先前语言模型 (LM) GPT-2 的继承者. 它被认为比GPT-2更好、更大. 事实上, 与他语言模型相比, OpenAI GPT-3 的完整版拥有大约 1750 亿个可训练参数, 是迄今为止训练的最大模型, 这份 72 页的研究论文 非常详细地描述了该模型的特性、功能、性能和局限性.
下图为不同模型之间训练参数的对比:

1.1 GPT-3模型架构
实际上GPT-3 不是一个单一的模型, 而是一个模型系列. 系列中的每个模型都有不同数量的可训练参数. 下表显示了每个模型、体系结构及其对应的参数:

在模型结构上,GPT-3 延续使用 GPT 模型结构,但是引入了 Sparse Transformer 中的 sparse attention 模块(稀疏注意力)。
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²) sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,... 的 token,其他所有 token 的注意力都设为 0,如下图所示:

使用 sparse attention 的好处主要有以下两点:
-
减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
-
具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
其中最大版本 GPT-3 175B 或“GPT-3”具有175个B参数、96层的多头Transformer、Head size为96、词向量维度为12288、文本长度大小为2048.
1.2 GPT-3训练核心思想
GPT-3模型训练的思想与GPT-2的方法相似, 去除了fine-tune过程, 只包括预训练过程, 不同只在于采用了参数更多的模型、更丰富的数据集和更长的训练的过程.
但是GPT-3 模型在进行下游任务评估和预测时采用了三种方法, 他们分别是: Few-shot、One-shot、Zero-shot.
其中 Few-shot、One-shot也被称之为情境学习(in-context learning,也可称之为提示学习). 情境学习理解: 在被给定的几个任务示例或一个任务说明的情况下, 模型应该能通过简单预测以补全任务中其他的实例. 即情境学习要求预训练模型要对任务本身进行理解.
In-context learnin核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
下面以从“英语到法语的翻译任务”为例, 分别对比传统的微调策略和GPT-3三种情景学习方式.
-
下图是传统的微调策略:

-
传统的微调策略存在问题:
-
微调需要对每一个任务有一个任务相关的数据集以及和任务相关的微调.
-
需要一个相关任务大的数据集, 而且需要对其进行标注
-
当一个样本没有出现在数据分布的时候, 泛化性不见得比小模型要好
-
下图显示了 GPT-3 三种情景学习方法:

-
zero-shot learning
-
定义: 给出任务的描述, 然后提供测试数据对其进行预测, 直接让预训练好的模型去进行任务测试.
-
示例: 向模型输入“这个任务要求将中文翻译为英文. 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”
-
-
one-shot learning
-
定义: 在预训练和真正翻译的样本之间, 插入一个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给一个例子, 告诉模型英语翻译为法语, 应该这么翻译.
-
示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
-
-
few-shot learning
-
定义: 在预训练和真正翻译的样本之间, 插入多个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给多个例子, 告诉模型应该如何工作.
-
示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 再见->goodbye, 购买->purchase, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
-
-
总之: in-context learning,虽然它与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:
-
【本质区别】fine-tuning 基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新;
-
in-context learning 依赖的数据量(10~100)远远小于 fine-tuning 一般的数据量;
-
最终通过大量下游任务实验验证,Few-shot 效果最佳,One-shot 效果次之,Zero-shot 效果最差:
1.3 GPT-3数据集
一般来说, 模型的参数越多, 训练模型所需的数据就越多. GPT-3共训练了5个不同的语料大约 45 TB 的文本数据, 分别是低质量的Common Crawl(需要数据清洗), 高质量的WebText2, Books1, Books2和Wikipedia, GPT-3根据数据集的不同的质量赋予了不同的权值, 权值越高的在训练的时候越容易抽样到, 如下表所示.
| 数据集 | 数量(TOKENS) | 训练数据占比 |
|---|---|---|
| Common Crawl(filterd) | 4100亿 | 60% |
| Web Text2 | 190亿 | 22% |
| BOOK1 | 120亿 | 8% |
| BOOK2 | 550亿 | 8% |
| Wikipedia | 30亿 | 2% |
不同数据的介绍:
-
Common Crawl语料库包含在 8 年的网络爬行中收集的 PB 级数据. 语料库包含原始网页数据、元数据提取和带有光过滤的文本提取.
-
WebText2是来自具有 3+ upvotes 的帖子的所有出站 Reddit 链接的网页文本.
-
Books1和Books2是两个基于互联网的图书语料库.
-
英文维基百科页面 也是训练语料库的一部分.
1.4 GPT-3模型的特点
与 GPT-2 的区别
效果上,超出 GPT-2 非常多,能生成人类难以区分的新闻文章;
主推 few-shot,相比于 GPT-2 的 zero-shot,具有很强的创新性;
模型结构略微变化,采用 sparse attention 模块;
海量训练语料 45TB(清洗后 570GB),相比于 GPT-2 的 40GB;
海量模型参数,最大模型为 1750 亿,GPT-2 最大为 15 亿参数;
优点:
-
整体上, GPT-3在zero-shot或one-shot设置下能取得尚可的成绩, 在few-shot设置下有可能超越基于fine-tune的SOTA模型.
-
去除了fune-tuning任务.
缺点:
-
由于40TB海量数据的存在, 很难保证GPT-3生成的文章不包含一些非常敏感的内容
-
对于部分任务比如: “填空类型”等, 效果具有局限性
-
当生成文本长度较长时,GPT-3 还是会出现各种问题,比如重复生成一段话,前后矛盾,逻辑衔接不好等等;
-
成本太大
1.5 GPT-3模型总结
GPT系列从1到3, 通通采用的是transformer架构, 可以说模型结构并没有创新性的设计. GPT-3的本质还是通过海量的参数学习海量的数据, 然后依赖transformer强大的拟合能力使得模型能够收敛. 得益于庞大的数据集, GPT-3可以完成一些令人感到惊喜的任务, 但是GPT-3也不是万能的, 对于一些明显不在这个分布或者和这个分布有冲突的任务来说, GPT-3还是无能为力的.
🍔 ChatGPT介绍
ChatGPT是一种基于GPT-3的聊天机器人模型. 它旨在使用 GPT-3 的语言生成能力来与用户进行自然语言对话. 例如, 用户可以向 ChatGPT 发送消息, 然后 ChatGPT 会根据消息生成一条回复.
GPT-3 是一个更大的自然语言处理模型, 而 ChatGPT 则是使用 GPT-3 来构建的聊天机器人. 它们之间的关系是 ChatGPT 依赖于 GPT-3 的语言生成能力来进行对话.
目前基于ChatGPT的论文并没有公布, 因此接下来我们基于openai官网的介绍对其原理进行解析
2.1 ChatGPT原理
在介绍ChatGPT原理之前, 请大家先思考一个问题: “模型越大、参数越多, 模型的效果就越好么啊?”. 这个答案是否定的, 因为模型越大可能导致结果越专一, 但是这个结果有可能并不是我们期望的. 这也称为大型语言模型能力不一致问题. 在机器学习中, 有个重要的概念: “过拟合”, 所谓的过拟合, 就是模型在训练集上表现得很好, 但是在测试集表现得较差, 也就是说模型在最终的表现上并不能达到我们的预期, 这就是模型能力不一致问题.
原始的 GPT-3 就是非一致模型, 类似GPT-3 的大型语言模型都是基于来自互联网的大量文本数据进行训练, 能够生成类似人类的文本, 但它们可能并不总是产生符合人类期望的输出.
ChatGPT 为了解决模型的不一致问题, 使用了人类反馈来指导学习过程, 对其进行了进一步训练. 所使用的具体技术就是强化学习(RLHF) .
2.2 什么是强化学习
强化学习(Reinforcement Learning, RL), 又称再励学习、评价学习或增强学习, 是机器学习方法的一种, 用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题.
强化学习的关键信息:
-
一种机器学习方法
-
关注智能体与环境之间的交互
-
目标是追求最大回报
强化学习的架构
-
下图是强化学习的基本流程整体架构, 其中大脑指代智能体agent, 地球指代环境environment, 从当前的状态St出发, 在做出一个行为At 之后, 对环境产生了一些影响, 它首先给agent反馈了一个奖励信号Rt然后给agent反馈一个新的环境状态, 此处用Ot 表示, 进而融汇进入一个新的状态, agent再做出新的行为, 形成一个循环.

理解强化学习基本要素
-
这里我们以一个简单小游戏flappy bird为代表为大家讲解强化学习的基本要素:

-
Agent(智能体): 强化学习训练的主体就是Agent, 统称为“智能体”. 这里小鸟就是Agent.
-
Environment(环境): 整个游戏的大背景就是环境;超级玛丽中Agent、地面、柱子组成了整个环境.
-
State(状态): 当前 Environment和Agent所处的状态, 因为小鸟一直在移动, 分数数目也在不停变化, Agent的位置也在不停变化, 所以整个State处于变化中.
-
Policy(策略): Policy的意思就是根据观测到的状态来进行决策, 来控制Agent运动. 即基于当前的State, Agent可以采取哪些Action, 比如向上或者向下. 在数学上Policy一般定义为函数π(深度学习中Policy可以定义为一个模型), 这个policy函数π是个概率密度函数:

-
Reward(奖励): Agent在当前State下, 采取了某个特定的Action后, 会获得环境的一定反馈(或奖励)就是Reward. 比如: 小鸟顺利通过柱子获得奖励R=+1,如果赢了这场游戏奖励R=+10000, 我们应该把打赢游戏的奖励定义的大一些, 这样才能激励学到的policy打赢游戏而不是一味的加分, 如果小鸟碰到柱子, 小鸟就会死, 游戏结束, 这时奖励就设R=-10000, 如果这一步什么也没发生, 奖励就是R=0, 强化学习的目标就是使获得的奖励总和尽量要高.
如何让AI实现自动打游戏?
-
第一步: 通过强化学习(机器学习方法)学出Policy函数, 该步骤目的是用Policy函数来控制Agent.
-
第二步: 获取当前状态为s1, 并将s1带入Policy函数来计算概率, 从概率结果中抽样得到a1, 同时环境生成下一状态s2, 并且给Agent一个奖励r1.
-
第三步: 将新的状态s2带入Policy函数来计算概率, 抽取结果得到新的动作a2、状态s3、奖励r2.
-
第四步: 循环2-3步骤, 直到打赢游戏或者game over, 这样我们就会得到一个游戏的trajectory(轨迹), 这个轨迹是每一步的状态, 动作, 奖励.
2.3 ChatGPT强化学习步骤
从人类反馈中进行强化学习, 该方法总体上包括三个步骤:
-
步骤1: 有监督的调优, 预训练的语言模型在少量已标注的数据上进行调优, 以学习从给定的 prompt 列表生成输出的有监督的策略(即 SFT 模型);
-
步骤2: 模拟人类偏好: 标注者们对相对大量的 SFT 模型输出进行投票, 这就创建了一个由比较数据组成的新数据集. 在此数据集上训练新模型, 被称为训练奖励模型(Reward Model, RM);
-
步骤3: 近端策略优化(PPO): RM 模型用于进一步调优和改进 SFT 模型, PPO 输出结果的是策略模式.
-
步骤 1 只进行一次, 而步骤 2 和步骤 3 可以持续重复进行: 在当前最佳策略模型上收集更多的比较数据, 用于训练新的 RM 模型, 然后训练新的策略. 接下来, 将对每一步的细节进行详述.
2.4 监督调优模型

工作原理:
-
第一步是收集数据, 以训练有监督的策略模型.
-
数据收集: 选择一个提示列表, 标注人员按要求写下预期的输出. 对于 ChatGPT, 使用了两种不同的 prompt 来源: 一些是直接使用标注人员或研究人员准备的, 另一些是从 OpenAI 的 API 请求(即从 GPT-3 用户那里)获取的. 虽然整个过程缓慢且昂贵, 但最终得到的结果是一个相对较小、高质量的数据集, 可用于调优预训练的语言模型.
-
模型选择: ChatGPT 的开发人员选择了 GPT-3.5 系列中的预训练模型, 而不是对原始 GPT-3 模型进行调优. 使用的基线模型是最新版的 text-davinci-003(通过对程序代码调优的 GPT-3 模型)
由于此步骤的数据量有限, 该过程获得的 SFT 模型可能会输出仍然并非用户关注的文本, 并且通常会出现不一致问题. 这里的问题是监督学习步骤具有高可扩展性成本.
为了克服这个问题, 使用的策略是让人工标注者对 SFT 模型的不同输出进行排序以创建 RM 模型, 而不是让人工标注者创建一个更大的精选数据集.
2.5 训练奖励模型
这一步的目标是直接从数据中学习目标函数. 该函数的目的是为 SFT 模型输出进行打分, 这代表这些输出对于人类来说可取程度有多大. 这强有力地反映了选定的人类标注者的具体偏好以及他们同意遵循的共同准则. 最后, 这个过程将从数据中得到模仿人类偏好的系统.

工作原理:
-
选择 prompt 列表, SFT 模型为每个 prompt 生成多个输出(4 到 9 之间的任意值)
-
标注者将输出从最佳到最差排序. 结果是一个新的标签数据集, 该数据集的大小大约是用于 SFT 模型的精确数据集的 10 倍;
-
此新数据用于训练 RM 模型 . 该模型将 SFT 模型输出作为输入, 并按优先顺序对它们进行排序.
-
模型选择: RM模型是GPT-3的蒸馏版本(参数量为6亿), 目的是通过该训练模型得到一个预测值(得分), 模型损失函数为下图表示:

-
公式参数解析: x代表prompt原始输入, yw代表SFT模型输出的得分较高的结果, yl代表SFT模型输出得分较低的结果, rθ代表RM模型即GPT-3模型, σ代表sigmoid函数, K代表SFT 模型为每个 prompt 生成多个输出, 这里K个任选2个来模型训练.
2.6 使用 PPO 模型微调 SFT 模型
这一步里强化学习被应用于通过优化 RM 模型来调优 SFT 模型. 所使用的特定算法称为近端策略优化(PPO, Proximal Policy Optimization), 而调优模型称为近段策略优化模型.

工作原理: (明确任务: 模型是通过RL来更新)
-
第一步: 获取数据
-
第二步: 将数据输入PPO模型 (这里直接也可以理解为ChatGPT模型), 得到一个输出结果
-
第三步: 将第二步得到的结果输入到RM奖励模型中, 然后得到一个奖励分数. 如果奖励分数比较低, 代表ChatGPT模型输出结果不对, 此时需要利用PPO算法更新ChatGPT模型参数
-
第四步: 循环上述步骤, 不断更新ChatGPT、RM模型.
2.7 ChatGPT特点
优点:
-
回答理性又全面, ChatGPT更能做到多角度全方位回答
-
降低学习成本, 可以快速获取问题答案
缺点:
-
ChatGPT 服务不稳定
-
容易一本正经的"胡说八道"
🍔 小结
-
本章节主要讲述了ChatGPT的发展历程,重点对比了N-gram语言模型和神经网络语言模型的区别,以及GPT系列模型的对比.
相关文章:
【AI大模型】ChatGPT模型原理介绍(下)
目录 🍔 GPT-3介绍 1.1 GPT-3模型架构 1.2 GPT-3训练核心思想 1.3 GPT-3数据集 1.4 GPT-3模型的特点 1.5 GPT-3模型总结 🍔 ChatGPT介绍 2.1 ChatGPT原理 2.2 什么是强化学习 2.3 ChatGPT强化学习步骤 2.4 监督调优模型 2.5 训练奖励模型 2.…...

Python数据分析与可视化实战指南
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。 一、环境准…...

react18基础教程系列-- 框架基础理论知识mvc/jsx/createRoot
react的设计模式 React 是 mvc 体系,vue 是 mvvm 体系 mvc: model(数据)-view(视图)-controller(控制器) 我们需要按照专业的语法去构建 app 页面,react 使用的是 jsx 语法构建数据层,需要动态处理的的数据都要数据层支持控制层: 当我们需要…...
)
牛客周赛 Round 60 折返跑(组合数学)
题目链接:题目 大意: 在 1 1 1到 n n n之间往返跑m趟,推 m − 1 m-1 m−1次杆子,每次都向中间推,不能推零次,问有多少种推法(mod 1e97)。 思路: 一个高中学过的组合数…...

深入浅出Java匿名内部类:用法详解与实例演示
匿名内部类(Anonymous Inner Class)在Java中是一种非常有用的特性,它允许你在一个类的定义中直接创建并实例化一个内部类,而不需要为这个内部类指定一个名字。匿名内部类通常用于以下几种情况: 实现接口:当…...

数据库MySQL、Mariadb、PostgreSQL、MangoDB、Memcached和Redis详细介绍
以下是一些常见的后端开发数据库选型: 关系型数据库(RDBMS):关系型数据库是最常见的数据库类型,使用表格和关系模型来存储和管理数据。常见的关系型数据库包括MySQL、PostgreSQL和Oracle等。这些数据库适合处理结构化数…...

【ArcGIS Pro实操第七期】栅格数据合并、裁剪及统计:以全球不透水面积为例
【ArcGIS Pro实操第七期】批量裁剪:以全球不透水面积为例 准备:数据下载ArcGIS Pro批量裁剪数据集1 数据拼接2 数据裁剪3 数据统计:各栅格取值3.1 栅格计算器-精确提取-栅格数据特定值3.2 数据统计 4 不透水面积变化分析 参考 准备࿱…...

【Linux】Image、zImage与uImage的区别
1、Image 1.1 什么是 Image Image 是一种未压缩的 Linux 内核镜像文件,包含了内核的所有代码、数据和必要的元信息。它是 Linux 内核在编译过程中生成的一个原始的二进制文件,未经过任何压缩或额外的封装处理。由于未压缩,Image 文件相对较…...
:自定义cuda扩展)
算子加速(3):自定义cuda扩展
需要自定义某个层,或有时候用c++实现你的操作(c++扩展)可能会更好: 例如:需要实现一个新型的激活函数例如: bevfusion用cuda实现bevpool加速自定义扩展的步骤 (1) 首先用纯pytorch和python 实现我们所需的功能,看看效果再决定要不要进一步优化(2) 明确优化方向,用C++ (或CU…...

信息安全数学基础(14)欧拉函数
前言 在信息安全数学基础中,欧拉函数(Eulers Totient Function)是一个非常重要的概念,它与模运算、剩余类、简化剩余系以及密码学中的许多应用紧密相关。欧拉函数用符号 φ(n) 表示,其中 n 是一个正整数。 一、定义 欧…...

7-17 汉诺塔的非递归实现
输入样例: 3输出样例: a -> c a -> b c -> b a -> c b -> a b -> c a -> c 分析: 不会汉罗塔的uu们,先看看图解: 非递归代码: #include<iostream> #include<stack> using namespace std; s…...

word文档无损原样转pdf在windows平台使用python调用win32com使用pip安装pywin32
前提: windows环境下,并且安装了office套装,比如word,如果需要调用excel.也需要安装。在另外的文章会介绍。这种是直接调用word的。所以还原度会比较高。 需求: word文档转pdf,要求使用命令行形式,最终发布为api接口…...

海康威视相机在QTcreate上的使用教程
文章目录 前言:基础夯实:效果展示:图片展示:视频展示: 参考的资料:遇到问题:问题1:int64 does not问题2:LNK2019配置思路(这个很重要)配置关键图片:配置具体过…...
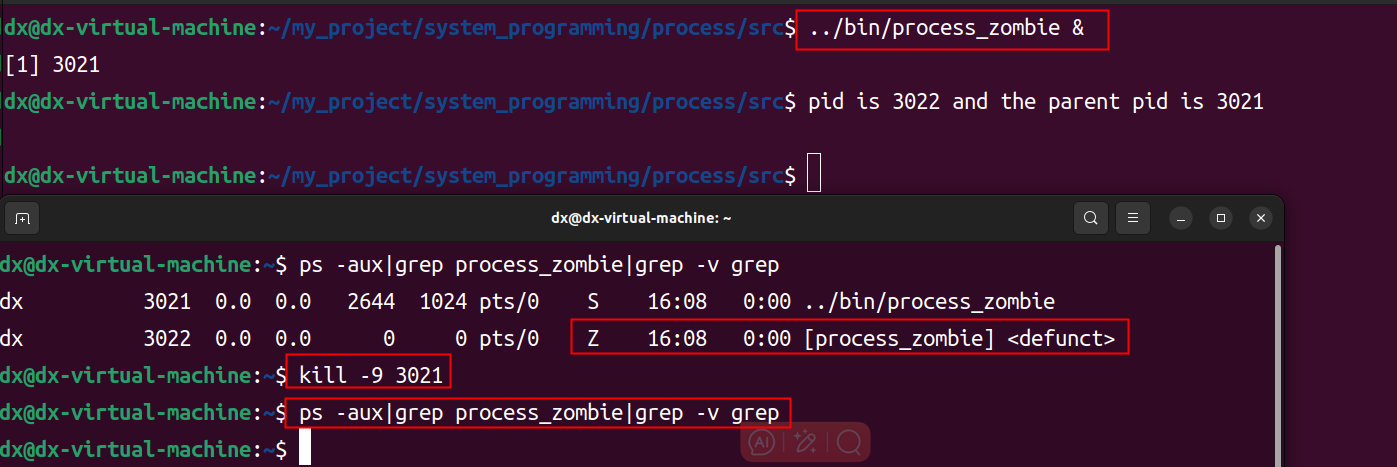
进程状态、进程创建和进程分类
文章目录 进程进程常见的状态进程调度进程状态变化关系 进程标识示例--进程标识的使用以及简介 进程创建fork函数vfork函数示例--使用fork函数创建子进程,并了解进程之间的关系 创建进程时发生的变化虚拟内存空间的变化示例--验证fork函数创建进程时的操作 对文件IO…...

java后端请求调用三方接口
java后端请求调用三方接口 /*** param serverURL http接口地址(例:http://www.iwsu.top:8016/dataSyn/bay/statsCar)* param parm 参数(可以是json,也可以是json数组)*/ public void doRestfulPostBody(St…...
)
C#使用TCP-S7协议读写西门子PLC(三)
接上篇 C#使用TCP-S7协议读写西门子PLC(二)-CSDN博客 这里我们进行封装读写西门子PLC的S7协议命令以及连接西门子PLC并两次握手 新建部分类文件SiemensS7ProtocolUtil.ReadWrite.cs 主要方法: 连接西门子PLC并发送两次握手。两次握手成功后,才真正连…...

铝型材及其常用紧固件、连接件介绍
铝型材介绍(包括紧固件和连接件以及走线) 铝型材 铝型材一般是6063铝合金挤压成型,分为欧标和国标两个标准。(左边国标,右边欧标,欧标槽宽一点) 由于槽型不一样,相关的螺栓和螺母也…...
-安装开发所需工具)
【裸机装机系列】7.kali(ubuntu)-安装开发所需工具
如果你是后端或是人工智能AI岗,可以安装以下推荐的软件: 1> sublime sublime官网 下载deb文件 安装命令 sudo dpkg -i sublime-text_build-4143_amd64.deb2> vscode 安装前置软件 sudo apt install curl gpg software-properties-common apt-t…...

[C语言]第九节 函数一基础知识到高级技巧的全景探索
目录 9.1 函数的概念 9.2 库函数 9.2.1 标准库与库函数 示例:常见库函数 9.2.2 标准库与头文件的关系 参考资料和学习工具 如何使用库函数 编辑 9.3 ⾃定义函数 9.3.1 函数的语法形式 9.3.2函数的举例 9.4 实参与形参 9.4.1 什么是实参? 9…...

1.1 计算机网络基本概述
欢迎大家订阅【计算机网络】学习专栏,开启你的计算机网络学习之旅! 文章目录 前言一、网络的基本概念二、集线器、交换机和路由器三、互连网与互联网四、网络的类型五、互连网的组成1. 边缘部分2. 核心部分 六、网络协议 前言 计算机网络是现代信息社会…...

ctfileGet:城通网盘高速直链提取完整指南
ctfileGet:城通网盘高速直链提取完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一款专门用于获取城通网盘一次性直连地址的开源工具,通过智能解析技术帮助用…...

python pygame实现贪食蛇
文章目录步骤2、创建snake.py,然后运行即可操作方式解读很简单的一个例子,开启小游戏制作大门。步骤 1、安装依赖 pip install pygame2、创建snake.py,然后运行即可 代码: import pygame import time import random# --- 1. 初…...

Nunchaku-flux-1-dev多场景落地:图文创作、副业接单、PPT配图、表情包生成一文覆盖
Nunchaku-flux-1-dev多场景落地:图文创作、副业接单、PPT配图、表情包生成一文覆盖 1. 引言:你的本地AI画师,不止于想象 想象一下,你正在为一个公众号文章找配图,翻遍了图库网站,要么风格不搭,…...

Apollo配置中心实战:从零到一的Docker化部署与核心配置详解
1. 为什么选择Apollo配置中心 在微服务架构中,配置管理一直是个让人头疼的问题。记得我第一次尝试用传统properties文件管理配置时,光是同步不同环境的配置就浪费了大半天时间。后来接触到Apollo,才发现原来配置管理可以这么优雅。 Apollo作为…...

3大核心策略!Langchain-Chatchat RAG语义匹配效率提升实战指南
3大核心策略!Langchain-Chatchat RAG语义匹配效率提升实战指南 【免费下载链接】Langchain-Chatchat Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM, Qwen 与 Llama 等语言模型的 RAG 与 Agent 应用 | Langchain-Chatch…...

Open Interpreter实时代码预览:沙箱模式部署详细说明
Open Interpreter实时代码预览:沙箱模式部署详细说明 1. 项目概述 Open Interpreter 是一个让人眼前一亮的开源工具,它能让你用平常说话的方式告诉AI要做什么,然后AI就会在你的电脑上直接写代码、运行代码,甚至帮你修改代码。想…...

避坑指南:用Pixhawk 4飞控连接Nooploop TOFSense激光雷达,这些线序错误千万别犯
Pixhawk 4与TOFSense激光雷达安全接线全攻略:从接口定义到防烧毁实战 当你第一次拿到TOFSense激光雷达模块时,那种迫不及待想把它接入飞控的心情我完全理解——毕竟谁不想让自己的无人机立刻获得精准的测距能力呢?但作为一个曾经因为接错线而…...

Python 日志神器 Loguru 超详细使用教程
前言 在 Python 开发中,日志记录是排查问题、监控程序运行的核心工具,但原生 logging 库配置繁琐、语法复杂,新手很难快速上手。Loguru 是一款极简、强大、开箱即用的第三方日志库,无需复杂配置,一行代码就能实现专业级…...

10点滑动平均滤波器:嵌入式零依赖高效实现
1. 项目概述MovingAverageFilter 是一个轻量级、零依赖的嵌入式数字滤波器实现,专为资源受限的微控制器环境设计。其核心功能是执行固定长度(10点)的滑动平均(Moving Average)运算,并在每次新采样输入后立即…...

5分钟掌握Scala.js构建工具链:从开发到生产的完整指南
5分钟掌握Scala.js构建工具链:从开发到生产的完整指南 【免费下载链接】scala-js Scala.js, the Scala to JavaScript compiler 项目地址: https://gitcode.com/gh_mirrors/sc/scala-js Scala.js是一个功能强大的Scala到JavaScript编译器,它允许开…...