self-play RL学习笔记

让AI用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得AI记住多使用这个成功的事件,再开始下一次的尝试。——llya Sutskever
这两天炸裂朋友圈的OpenAI草莓大模型o1和此前代码能力大幅升级的Claude 3.5,业内都猜测经过了自博弈强化学习(self-play RL)。
1、什么是self-play RL?
self-play RL的核心概念其实并不复杂。可以想象一场自我博弈的游戏,AI自己和自己“对打”,通过反复尝试、调整策略,逐步学习如何在特定环境中取得更好的结果。这种机制让AI能够像人类一样,不断进行探索与反思,以寻找更优解。
例如,AlphaGo正是依靠self-play RL,在无数场自我对弈中学会了如何打败人类顶尖棋手。通过这种不断的尝试、失败和进步,AI可以自主地提高自己的能力。
为了更好理解self-play RL,可以类比一下运动员的训练过程。一个马拉松运动员虽然掌握了基本的跑步技巧,但如果想要取得更好的成绩,必须通过反复训练来找到最适合自己的节奏、姿势、饮食等关键细节。在每次训练中,他会根据前一次的经验,做出调整,不断改进,直到达到最佳状态。
self-play RL的工作原理类似:AI不断在自己设计的场景中进行“训练”,每次调整策略,优化路径,最终取得最佳的决策能力。
2、self-play RL和LLM的关系
LLM,例如GPT系列,依靠海量的数据进行预训练,学习现有的知识和模式。但是,预训练的核心问题在于,AI只能“利用”这些已有的知识,缺乏“探索”新知识的能力。这也是现有LLM逐渐遇到瓶颈的原因之一。
self-play RL与LLM的结合,则为AI带来了突破性的新机会。它为模型提供了一种自主探索的能力,让它不再局限于预训练的框架内,能够通过模拟场景中的探索,自我生成新的数据,从而提升逻辑推理能力。这使得GPT-4以上更聪明的LLM有可能利用self-play RL,在一些任务上变得更加智能。
3、LLM和强化学习应该怎么相互补充?
LLM可以提供对环境的理解和解释能力,而强化学习可以在此基础上做出决策。例如,在自动驾驶汽车中,LLM可以解释交通标志和道路情况,而强化学习可以决定如何驾驶。同时,强化学习生成的决策可以通过LLM转换成自然语言,使得决策过程更加透明和易于理解。
在强化学习的训练过程中,LLM可以帮助智能体更好地与人类或其他智能体进行交流,从而提高学习效率。
4、self-play RL,它与传统的强化学习区别是什么?
经典三大范式(监督学习、非监督学习、强化学习)中只有强化学习的假设是让AI进行自主探索、连续决策,这个学习方式最接近人类的学习方式,也符合我们想象中的AI agent应该具备的自主行动能力。LLM在"利用"现有知识上做到了现阶段的极致,而在"探索"新知识方面还有很大潜力,RL的引入就是为了让LLM能通过探索进一步提升推理能力。

self-play RL是一种特殊类型的强化学习,它与传统的强化学习的主要区别在于学习过程中的互动方式。在传统的强化学习中,智能体(agent)通常与一个静态的环境互动,环境提供状态和奖励,智能体通过与环境的交互学习最优策略。而self-play RL中,智能体通常与自己或其他智能体进行博弈,例如在围棋、国际象棋或多人游戏中,智能体通过与自己的不同版本或策略进行对抗来学习,从而提高策略的性能。
在自博弈强化学习中,智能体通过模拟对抗来探索和改进策略,这种方法可以更有效地发现策略中的弱点和潜在的改进空间。自博弈强化学习的一个典型例子是AlphaGo,它通过与自身的不同版本进行大量的围棋对局来学习,最终超越了人类顶尖棋手。
5、self-play RL的机制
self-play RL的核心机制可以分为三个关键步骤:
- 环境:AI所处的环境非常重要,比如下棋时的棋盘,或与用户对话的场景。AI通过与环境互动,收集关于其行为是否成功的反馈。
- 智能体:AI是一个智能体,它可以做出决策和行动。它通过观察环境的反馈,调整自己的行为,以实现更高的目标。
- 奖励机制:AI在完成任务时,会根据其表现收到“奖励”。这个奖励系统帮助AI判断自己做得是否好。比如,AI下棋时,接近胜利会得到正面的反馈,这种机制引导其选择更优的策略。

self-play RL的机制依靠不断的循环,智能体通过多次“自博弈”,优化自己的行动策略。这种自我驱动的学习方式,使得AI能够比单纯依赖预训练的模型在复杂场景中更具适应性和灵活性。
6、只有“聪明”的LLM才能进行self-play RL
一个非常关键的问题是,self-play RL并不是任何AI都可以执行的任务。正如你不能指望一个初学者在没有基础知识的情况下通过自己探索掌握高难度的技能,AI也是一样。只有GPT-4或以上这种聪明的大模型,具备足够的逻辑能力和推理基础,才能利用self-play RL进行有效的自我提升。
这一点类似于,你只有在拥有一定基础能力的情况下,才能通过自学和实践取得突破。因此,self-play RL在当前只有那些已经非常强大的LLM中才可能发挥作用,特别是当模型已经通过预训练掌握了足够的基础知识时,它才能在更复杂的任务中实现自主探索和提升。
7、范式转移与非共识
self-play RL通过让AI自己和自己进行博弈和反馈循环,能够显著提升AI的推理能力和任务完成能力。在大模型(如GPT-4)发展的道路上,它是一个关键的范式转移,标志着AI从单纯的知识“利用”向自主“探索”的方向前进,self-play RL开启了新赛道。
大部分人还没意识到,在纯靠语言模型预训练的Scaling Law这个经典物理规律遇到瓶颈后,多家硅谷明星公司已经把它们的资源重心押宝在一条新路径上:self-play RL。只不过,这个范式转移还未形成共识......
Reference
LLM新范式:OpenAIo1,self-playRL和AGI下半场
LLM的范式转移:RL带来新的ScalingLaw
相关文章:
self-play RL学习笔记
让AI用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得AI记住多使用这个成功的事件,再开始下一次的尝试。——llya Sutskever 这两天炸裂朋友圈的OpenAI草莓大模型o1和此前代码能力大幅升级的Claude 3.5&…...

【机器学习】OpenCV入门与基础知识
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 OpenCV入门与基础知识简介安装与环境配置WindowsLinuxmacOS 核心数据结构MatSca…...

JUC学习笔记(二)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 四、共享模型之内存4.1 Java 内存模型4.2 可见性退不出的循环解决方法可见性 vs 原子性模式之 Balking1.定义2.实现 4.3 有序性原理之指令级并行1. 名词2.鱼罐头的故…...

炫酷HTML蜘蛛侠登录页面
全篇使用HTML、CSS、JavaScript,建议有过基础的进行阅读。 一、预览图 二、HTML代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-w…...

算法里面的离散化
一、离散化(discretization)在算法和数据结构中指的是将连续的输入数据映射到离散的值或者范围,从而使得处理和计算变得更高效。通常用于处理大范围或者无限可能的输入,以便将其转化为有限的、可以有效处理的范围。 离散化的定义…...

Https AK--(ssl 安全感满满)
免责声明:本文仅做分享! 目录 https探测 openssl Openssl连接服务器获取基本信息 连接命令: 指定算法连接: 测试弱协议连接是否可以连接: 得到的内容包括: sslscan 在线查询证书 https AK type 中间人AK sslsplit 工具…...

ERROR: Failed building wheel for cython_bbox | pip install cython_bbox 失败【解决方案】
🥇 版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连 🎉 声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️ 文章目录 win11 系统 pip3 install cython_bbox 失败报错如下解决方法:1 下载…...

逻辑与位运算的双面舞者:、、|、||深度解析
深入解析&、&&、|、||:逻辑与位运算的奥秘之旅 在编程的世界里,&、&&、|、||这四种运算符扮演着至关重要的角色。它们不仅仅是简单的符号,更是连接程序逻辑、实现复杂功能的桥梁。本文旨在深入探讨这四者的区别与联…...

中断门+陷阱门
中断门: 中断描述符在IDT表里面 kd> dq idtr 80b95400 83e48e000008bfc0 83e48e000008c150 80b95410 0000850000580000 83e4ee000008c5c0 80b95420 83e4ee000008c748 83e48e000008c8a8 80b95430 83e48e000008ca1c 83e48e000008d018 80b95440 000085000050…...

RTMP直播播放器的几种选择
如何选择RTMP播放器? 在选择RTMP播放器时,需要综合考虑多个因素,以确保选择的播放器能够满足实际需求并提供良好的用户体验。以下是一些选择RTMP播放器的建议: 1. 功能需求 低延迟:对于直播场景,低延迟是…...

初识爬虫1
学习路线:爬虫基础知识-requests模块-数据提取-selenium-反爬与反反爬-MongoDB数据库-scrapy-appium。 对应视频链接(百度网盘):正在整理中 爬虫基础知识: 1.爬虫的概念 总结:模拟浏览器,发送请求,获取…...
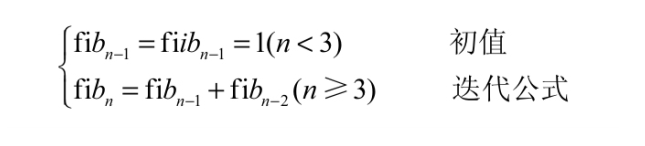
【趣学Python算法100例】兔子产子
问题描述 有一对兔子,从出生后的第3个月起每个月都生一对兔子。小兔子长到第3个月后每个月又生一对兔子,假设所有的兔子都不死,问30个月内每个月的兔子总对数为多少? 题目解析 兔子产子问题是一个有趣的古典数学问题,…...

HTTP 四、HttpClient的使用
一、简单介绍 1、简介 HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著…...

C语言:结构体变量
1. 结构体变量的引用方法 例如,若有数据定义: struct Student{char name[10];int age;struct Date birthday; }s1,s2,stu[10]; 则下面对结构体变量的引用都是正确的: s1.age20; scanf("%d",&s1.age); gets(stu[0].name); s…...

bibtex是什么
BibTeX 是一个用于处理和格式化参考文献的工具,常与 LaTeX 一起使用。它提供了一种方便的方式来管理和生成参考文献列表,特别适用于学术写作和科研论文中。以下是对 BibTeX 的详细介绍: 基本概念 BibTeX 是 LaTeX 的一个附加工具࿰…...

【大模型专栏—进阶篇】智能对话全总结
大模型专栏介绍 😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文为大模型专栏子篇,大模型专栏将持续更新,主要讲解大模型从入门到实战打怪升级。如有兴趣,欢迎您的阅读。 Ǵ…...

MVC应用单元测试以及请求参数的验证
SpringMVC支持对Controller单元测试 RunWith(SpringJUnit4ClassRunner.class) ContextConfiguration(locations {"classpath:mvc-dispatcher-servlet.xml", }) WebAppConfiguration public class ControllerJUnitBase{Resourceprivate RequestMappingHandlerMappin…...

算法:TopK问题
题目 有10亿个数字,需要找出其中的前k大个数字。 为了方便讲解,这里令k为5。 思路分析(以找前k大个数字为例) 很容易想到,进行排序,然后取前k个数字即可。 但是,难点在于,10亿个数…...

.json文件的C#解析,基于Newtonsoft.Json插件
目录 1. 前言 2. 正文 2.1 问题 2.2 解决办法 2.2.1 思路 2.2.2 代码实现 2.2.3 测试结果 3. 备注 1. 前言 天气晚来秋,这几天天气变凉了,各位同学注意好多穿衣服。回归正题 由于需要,需要将json的配置里面的调理解析出来,做成接口,以便于开发。 2. 正文 2.1 …...

四、(JS)JS中常见的加载事件
一、文档加载监听 (1)抛出疑惑,什么是文档加载监听?为什么要有这个东西? 老样子,我们先讲一个场景,带着大家熟悉为什么会有文档加载监听,是来解决什么问题来着的。 我们先看下这段…...

终极指南:Nativefier 构建代理环境变量优先级与冲突解决方案
终极指南:Nativefier 构建代理环境变量优先级与冲突解决方案 【免费下载链接】nativefier Make any web page a desktop application 项目地址: https://gitcode.com/gh_mirrors/na/nativefier Nativefier 是一款强大的工具,能够将任何网页转换为…...

VirtualAPK插件监控告警终极指南:钉钉/企业微信通知配置
VirtualAPK插件监控告警终极指南:钉钉/企业微信通知配置 【免费下载链接】VirtualAPK A powerful and lightweight plugin framework for Android 项目地址: https://gitcode.com/gh_mirrors/vi/VirtualAPK VirtualAPK作为Android平台强大的插件化框架&#…...
)
IDEA鲜亮配色方案实战:Java/Mapper.xml/yml文件高亮配置指南(附下载)
IDEA鲜亮配色方案实战:Java/Mapper.xml/yml文件高亮配置指南(附下载) 长时间面对单调的代码编辑器界面容易导致视觉疲劳,而一套精心设计的配色方案不仅能提升编码愉悦度,还能通过色彩区分显著提高代码阅读效率。本文将…...

星光护航 家校同行 多方联合点亮4·2世界孤独症日公益之光
2026年4月2日第19个世界孤独症关注日来临之际,联合国官宣年度主题Autism and Humanity — Every Life Has Value(孤独症与人类 — 每一个生命都弥足珍贵),中国同步确定“提质全生涯服务供给,聚焦孤独症家庭支持与成年服…...

终极指南:优化uid-generator内存管理的7个实用技巧,显著降低GC压力
终极指南:优化uid-generator内存管理的7个实用技巧,显著降低GC压力 【免费下载链接】uid-generator UniqueID generator 项目地址: https://gitcode.com/gh_mirrors/ui/uid-generator 在高并发系统中,uid-generator作为一款高效的唯一…...

DreamZero技术解析:当视频扩散模型成为机器人“物理大脑“
原文摘要翻译最先进的视觉-语言-动作(VLA)模型在语义泛化方面表现出色,但在新环境中难以泛化到未见过的物理动作。我们提出了 DreamZero,一种基于预训练视频扩散主干网络构建的世界动作模型(WAM)。与 VLA 不…...

计算机三级嵌入式30天高效备考攻略——从零基础到通关秘籍
1. 零基础如何30天攻克计算机三级嵌入式? 第一次接触计算机三级嵌入式考试的同学,往往会被"嵌入式"三个字吓到。其实这个考试更像是"嵌入式系统知识入门认证",完全不需要硬件开发经验。我当年也是零基础备考,…...

Spring中的循环依赖是怎么个事?
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

数据库基础知识----数据库大观
这里写目录标题绪论发展历程数据模型三层模式两层映像基本概念关系数据库简介(基本术语)关系模型组成数据结构数据操纵数据完整性规则关系代数五个基本操作并差笛卡尔积投影(π)选择四个组合操作交连接除法关系数据库语言----SQL简…...

Flowable建模器汉化实战:如何用SecurityUtils绕过官方认证实现本地化部署
Flowable建模器深度汉化与本地化部署实战指南 当企业级工作流系统需要深度定制时,Flowable建模器的原生界面往往成为用户体验的瓶颈。本文将揭示一套完整的解决方案,从界面元素汉化到认证体系重构,最终实现开箱即用的中文建模环境。 1. 汉化…...