Linux 开发工具(vim、gcc/g++、make/Makefile)+【小程序:进度条】-- 详解
目录
- 一、Linux软件包管理器 - yum(ubuntu用apt代替yum)
- 1、Linux下安装软件的方式
- 2、认识 yum
- 3、查找软件包
- 4、安装软件
- 5、如何实现本地机器和云服务器之间的文件互传
- 二、Linux编辑器 - vim
- 1、vim 的基本概念
- 2、vim 下各模式的切换
- 3、vim 命令模式各命令汇总
- 4、vim 底行模式各命令汇总
- 5、vim 中批量添加和删除注释
- 6、简单 vim 配置
- 三、Linux编译器 - gcc/g++
- 1、gcc/g++ 命令 & 程序编译
- (1)gcc/g++语法
- (2)预处理(进行宏替换)
- (3)编译(生成汇编)
- (4)汇编(生成机器可识别代码)
- (5)链接(生成可执行文件或库文件)
- 2、函数库
- 3、动态链接和静态链接
- (1)动态链接:链接动态库
- (2)静态链接:链接静态库
- 四、项目自动化构建工具 - make/Makefile
- 1、基本概念
- (1)背景
- (2)概念
- 2、基本使用
- (1)方式一:直接使用 gcc 命令
- (2)方式二:可以用 make 命令:
- 3、原理
- (1)图解代码
- (2)make 工作规则
- (i)依赖文件存在
- (ii)依赖文件不存在
- (iii)依赖文件列表为空(特殊)
- (3) .PHONY关键字
- (i)无 .PHONY关键字时:
- (ii)加上.PHONY关键字
- 4、常用makefile写法
- (1)内置符号法
- (2)变量替换法
- 五、小程序 —— 进度条
- 1、回车、换行和回车换行
- 2、行缓冲区概念
- 3、补充 : 刷新
- 4、小程序 —— 倒计时
- 5、进度条代码
一、Linux软件包管理器 - yum(ubuntu用apt代替yum)
本人是乌班图,因此借用他人图
1、Linux下安装软件的方式
在Linux下安装软件的方法大概有以下三种:
1)下载到程序的源代码,自行进行编译,得到可执行程序。
2)获取rpm安装包,通过rpm命令进行安装。(未解决软件的依赖关系)
3)通过yum进行安装软件。(常用)
2、认识 yum
yum是一个在Fedora、RedHat以及CentOS中的前端软件包管理器,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。

注意:一个服务器同一时刻只允许一个yum进行安装,不能在同一时刻同时安装多个软件。
因为yum是从服务器上下载RPM包,所以在下载时必须联网,可以通过ping指令判断当前云服务器是否联网。

3、查找软件包
[cl@VM-0-15-centos lesson5]$ yum list
使用yum list指令,可以罗列出可供下载的全部软件。

说明一下:
1)软件包名称:主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构。
2)"x86_64"后缀表示64位系统的安装包,"i686"后缀表示32位系统安装包,选择包时要和系统匹配。
3)"el7"表示操作系统发行版的版本,“el7"表示的是"centos7/redhat7”,“el6"表示"centos6/redhat6”。
4)最后一列表示的是“软件源”的名称,类似于“小米应用商店”,“华为应用商店”这样的概念。
这里我们以查找lrzsz为例。
lrzsz可以将Windows当中的文件上传到Linux当中,也可以将Linux当中的文件下载到Windows当中,实现云服务器和本地机器之间进行信息互传。
[cl@VM-0-15-centos lesson5]$ yum list | grep lrzsz
由于包的数量非常多,所以我们可以使用grep指令筛选出我们所关注的包,这里我们以lrzsz为例。

此时就只会显示与lrzsz相关的软件包。
4、安装软件
指令: sudo yum install 软件名
[cl@VM-0-15-centos yum.repos.d]$ sudo yum install lrzsz
yum会自动找到都有哪些软件包需要下载,这时候敲“y”确认安装,当出现“complete”字样时,说明安装完成。
注意事项:
1)安装软件时由于需要向系统目录中写入内容,一般需要sudo或者切换到root账户下才能完成。
2)yum安装软件只能一个装完了再装另一个,正在使用yum安装一个软件的过程中,如果再尝试用yum安装另外一个软件,yum会报错。
5、如何实现本地机器和云服务器之间的文件互传
既然已经安装了lrzsz,这里就顺便说一下lrzsz如何使用。
指令: rz -E
通过该指令可选择需要从本地机器上传到云服务器的文件。

指令: sz 文件名
该指令可将云服务器上的文件下载到本地机器的指定文件夹。

卸载软件
指令: sudo yum remove 软件名
[cl@VM-0-15-centos yum.repos.d]$ sudo yum remove lrzsz
yum会自动卸载该软件,这时候敲“y”确认卸载,当出现“complete”字样时,说明卸载完成。
二、Linux编辑器 - vim
为什么选择使用 vim 呢?
因为 vim 是所有 Linux 环境下自带的。
1、vim 的基本概念
vim在我们做开发的时候,主要解决我们编写代码的问题,本质上就是一个多模式的文本编辑器。
我们这里主要介绍vim最常用的三种模式:命令模式、插入模式、底行模式。
- 命令模式(Normal mode)。
在命令模式下,我们可以控制屏幕光标的移动,字符、字或行的删除,复制粘贴,剪贴等操作。 - 插入模式(Insert mode)。
只有在插入模式下才能进行文字输入,该模式是我们使用最频繁的编辑模式。 - 底行模式(Command mode)。
在底行模式下,我们可以将文件保存或退出,也可以进行查找字符串等操作。在底行模式下我们还可以直接输入vim help-modes查看当前vim的所有模式。
2、vim 下各模式的切换
指令: vim 文件名(记得先创建文件)
root@VM-4-17-ubuntu:~/112/lesson5# vim code.c
进入vim后默认为 命令模式(普通模式),要输入文字需切换到插入模式。

模式切换指令:
【命令模式】切换至【插入模式】
1)输入「i」:在当前光标处进入插入模式。
2)输入「a」:在当前光标的后一位置进入插入模式。
3)输入「o」:在当前光标处新起一行进入插入模式。
【命令模式】切换至【底行模式】
1)输入「Shift+;」即可,实际上就是输入「:」。
【插入模式】或【底行模式】切换至【命令模式】
1)插入模式或是底行模式切换至命令模式都是直接按一下「Esc」键即可。
3、vim 命令模式各命令汇总
【移动光标】
vim 可以直接用键盘上的方向键来控制光标上下左右移动,但正规的 vim 是用小写英文字母 h、j、k、l 来分别控制光标向左、下、
1)按「k」:光标上移。
2)按「j」:光标下移。
3)按「h」:光标左移。
4)按「l」:光标右移。

5)按「shift+4 / $」:移动到光标所在行的行尾。
6)按「shift+6 / ^」:移动到光标所在行的行首。
7)按「g+g」:移动到文本开始。
8)按「Shift+g / G」:移动到文本末尾。
9)按「n+Shift+g / G」:移动到第n行行首。
10)按「n+l」:光标移到该行的第 n 个位置,如:5l、56l。
11)按「n+Enter / n+j」:当前光标向下移动n行。
12)按「n+k」:当前光标向下移动n行。
13)按「w」:光标跳到下个字的开头(以单词为单位)。
14)按「e」:光标跳到下个字的字尾(以单词为单位)。
15)按「b」:光标回到上个字的开头(以单词为单位)。
【删除】
1)按「x」:删除光标所在位置的字符。
2)按「n+x」:删除光标所在位置开始往后的n个字符。
3)按「shift+x / X」:删除光标所在位置的前一个字符。
4)按「n+X」:删除光标所在位置的前n个字符。
5)按「d+d」:删除光标所在行。
6)按「n+d+d」:删除光标所在行开始往下的n行。
【复制粘贴】
1)按「y+y」:复制光标所在行到缓冲区。
2)按「n+y+y」:复制光标所在行开始往下的n行到缓冲区。
3)按「y+w」:将光标所在位置开始到字尾的字符复制到缓冲区。
4)按「n+y+w」:将光标所在位置开始往后的n个字复制到缓冲区。
5)按「p」:将已复制的内容在光标的下一行粘贴上。
6)按「n+p」:将已复制的内容在光标的下一行粘贴n次。
7)按「y+y+p」:复制粘贴。
8)按「d+d+p」:复制粘贴。
【剪切】
1)按「d+d」:剪切光标所在行。
2)按「n+d+d」:剪切光标所在行开始往下的n行。
3)按「p」:将已剪切的内容在光标的下一行粘贴上。
4)按「n+p」:将已剪切的内容在光标的下一行粘贴n次。
【撤销】
1)按「u」:如果您误执行一个命令,可以马上按下 u,回到上一个操作。按多次 “u” 可以执行多次恢复。
2)按「Ctrl+r」:撤销 u 操作,也就是撤销的恢复(反撤销)。
【大小写切换】
1)按「~」:完成光标所在位置字符的大小写切换,往后遇到的所有小写字母将被转成大写,所有大写字母将被转成小写。
2)按「n~」:完成光标所在位置开始往后的n个字符的大小写切换。
【替换】
1)按「r」:替换光标所在位置的字符。
2)按「R」:替换光标所到位置的字符,直到按下「Esc」键为止(整体文本替换)。
【更改】
1)按「c+w」:将光标所在位置开始到字尾的字符删除,并进入插入模式。
2)按「c+n+w」:将光标所在位置开始往后的n个字删除,并进入插入模式。
【翻页】
1)按「Ctrl+b」:上翻一页。
2)按「Ctrl+f」:下翻一页。
3)按「Ctrl+u」:上翻半页。
4)按「Ctrl+d」:下翻半页。
4、vim 底行模式各命令汇总
在使用底行模式之前,记住先按「Esc」键确定你已经处于命令模式,再按「:」即可进入底行模式。
【行号设置】
1)「set nu」:显示行号。
2)「set nonu」:取消行号。
【跳到文件中的某一行】
1)「n」:n表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字 15 后再回车,就会跳到文章的第 15 行。
【查找字符】
1)「/关键字」:先按 / 键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按 n 会往后寻找到您要的关键字为止。(常用)
2)「?关键字」:先按 ? 键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按 n 会往前寻找到您要的关键字为止。
【批量化替换字符】
1)「%s/printf/cout/g」:把文中所有 printf 替换成 cout(g --global 表示全局的意思)。
【查看函数手册】
1)「!man」: [选项] [函数名](按 q 退出手册)。
【保存退出】
1)「w」:保存文件。
2)「q」:退出vim,如果无法离开vim,可在「q」后面跟一个「!」表示强制退出。
3)「w+q」:保存退出。
【分屏指令】
1)「vs 文件名」:实现多文件的编辑。
2)「Ctrl+w+w」:光标在多屏幕下进行切换。
【执行指令】
1)「!+指令」:在不退出vim的情况下,可以在指令前面加上「!」就可以执行Linux的指令,例如查看目录、编译当前代码等。
5、vim 中批量添加和删除注释
方法一:块选择模式
1)批量添加注释:
- 进入 vim 编辑器,按 「ctrl+v 」进入块选择模式(visual block),然后按「j / k」上下移动光标或者「Shift+g / G」移动到末尾等操作选择要添加注释的行。
- 再按 「shift+i / I 」(大写字母),进入 Insert 插入模式,输入你要插入的注释符(比如 //)。
- 最后按 ESC 键,你所选择的行就被注释上了。
2)批量删除注释:
- 同样按 ctrl+v 进入块选择模式,选中要删除的行首的注释符号,注意 // 要选中两个。
选好之后按 d 键即可删除注释,ESC 保存退出。
方法二:替换命令
在底行模式下,可以采用替换命令进行注释:
1)添加注释:
- 「起始行号, 结束行号 s/^/注释符/g」:(表示在 xx 到 xx 行加入注释符,^ 表示行首的意思),然后按下回车键,注释成功。
2)删除注释:
- 「起始行号, 结束行号 s/^注释符//g」:(表示取消 xx 到 xx 行行首的注释符),然后按下回车键,取消注释成功。
比如:

注:如果注释符是 / 则按键里的/用#代替
6、简单 vim 配置
- 在目录/etc/下面,有个名为vimrc的文件,这是系统中公共的配置文件,对所有用户都有效。
- 在每个用户的主目录/home/xxx下,都可以自己建立私有的配置文件,命名为“.vimrc”,这是该用户私有的配置文件,仅对该用户有效。例如,root 用户的 /root 目录下,通常已经存在一个 .vimrc 文件,如果不存在,就创建一下。
例如,普通用户在自己的主目录下建立了“.vimrc”文件后,在文件当中输入set nu指令并保存,下一次打开vim的时候就会自动显示行号。
vim的配置比较复杂,某些vim配置还需要使用插件,建议不要自己一个个去配置。比较简单的方法是直接执行以下指令(想在哪个用户下让vim配置生效,就在哪个用户下执行该指令,不推荐直接在root下执行):
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
然后按照提示输入root密码:


如上图,此指令只适用centos 7,因此借图一用

配置完成后,像什么自动补全、行号显示以及自动缩进什么的就都有了。
三、Linux编译器 - gcc/g++
1、gcc/g++ 命令 & 程序编译
C/C++ 程序要运行,一般要经历以下步骤:
预处理(进行宏替换)–> 编译(生成汇编)–> 汇编(生成机器可识别代码)–> 链接(生成可执行文件或库文件)


Linux 下通过 gcc 命令完成 C 程序编译的过程,通过 g++ 命令完成 C++ 程序编译的过程:
(1)gcc/g++语法
语法: gcc 命令格式:gcc [选项] 要编译的文件 [选项] [目标文件](g++ 与之类似)
常用选项:
1)-E 只进行预处理,这个不生成文件,你需要把他重定向到一个输出文件里面(否则将把预处理后的结果打印到屏幕上)。
2)-S 编译到汇编语言,不进行汇编和链接,即只进行预处理和编译。
3)-c 编译到目标代码
4)-o 将处理结果输出到指定文件,该选项后需紧跟输出文件名。
5)-static 此选项对生成的文件采用静态链接。
6)-g 生成调试信息(若不携带该选项则默认生成release版本)。
7)-shared 此选项将尽量使用动态库,生成文件较小。
8)-w 不生成任何警告信息。
9)Wall 生成所有警告信息。
10)-O0/-O1/-O2/-O3 编译器优化选项的四个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高。
(2)预处理(进行宏替换)
预处理阶段会做的事:头文件展开、宏替换、条件编译、去掉注释等等。
预处理指令是以 # 号开头的代码行。
命令格式:gcc –E hello.c –o hello.i
- 选项 -E,该选项的作用是让 gcc 在预处理结束后停止编译过程。
- 选项 -o,是指目标文件,.i 文件为已经过预处理的 C 原始程序。
(3)编译(生成汇编)
编译阶段会做的事:语法检查(代码的规范性、是否有语法错误等),函数实例化,生成 .s 汇编文件。
命令格式:gcc –S hello.i –o hello.s
用户可以使用 -S 选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
(4)汇编(生成机器可识别代码)
汇编阶段会做的事:把编译阶段生成的 .s 汇编文件转成 .o 目标文件(二进制机器码)。
命令格式:gcc –c hello.s –o hello.o
用户可使用选项 -c 即可看到汇编代码已转化为 .o 的二进制目标代码。
(5)链接(生成可执行文件或库文件)
在成功编译之后,就进入了链接阶段。
命令格式:gcc hello.o –o hello
2、函数库
在 C 程序中,并没有定义 printf 的函数实现,且在预编译中包含的 stdio.h 中也只有该函数的声明,而没有定义函数的实现,那么是在哪里实现 printf 函数的呢?
系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径 /usr/lib 下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数 printf 了,而这也就是链接的作用。
函数库一般分为静态库和动态库两种。
静态库(.a):指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。
动态库(.so): 与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。
- 前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件:gcc hello.o –o hello
- gcc 默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。
3、动态链接和静态链接
生成可执行程序的方式有两种:
(1)动态链接:链接动态库
- 优点:不需要把相关库中的代码拷贝到可执行程序中,编译效率高,程序运行起来后,需要用到哪个库,再把哪个库加载到内存中,边运行边加载。
- 缺点:万一有库丢失了,将直接导致程序无法正常运行。
(2)静态链接:链接静态库
- 优点:不依赖于任何的动态库,自己就可以独立运行。
- 缺点:占磁盘空间,占内存,把相关库中的代码完完全全拷贝到了可执行程序中。
Linux 下生成的可执行程序,默认是动态链接的,如何查看呢?
- 使用 ldd [filename] 命令可以查看可执行文件的库依赖关系。
- 使用 file [filename] 命令可以查看可执行文件的信息和类型。

想要生成的可执行程序是静态链接的,该如何做呢?
gcc -o t_static t.s -static

四、项目自动化构建工具 - make/Makefile
1、基本概念
(1)背景
- 对于一个多文件的项目,在 VS 集成开发环境中,可以自动帮我们维护好多文件,我们只需要一键就可以完成对所有文件的编译,生成可执行程序。
- 而在 Linux,项目的所有文件,都需要我们自己来维护,成本太高,所以要用到 make 和 Makefile 帮我们自动化维护。
(2)概念
- 会不会写 Makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,Makefile 定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
- Makefile 带来的好处 —— “自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make 是一个命令工具,是一个解释 Makefile 中指令的命令工具,一般来说,大多数的 IDE 都有这个命令,比如:Delphi 的 make,Visual C++ 的 nmake,Linux 下 GNU 的 make。可见,Makefile 都成为了一种在工程方面的编译方法。
- make 是一条命令,Makefile 是一个文件(文件中保存的是目标文件和原始文件间的依赖关系和依赖方法),两个搭配使用,完成项目自动化构建。
2、基本使用
现在编写了一个 test.c 文件,需要编译文件生成可执行程序:
(1)方式一:直接使用 gcc 命令
gcc test.c -o test
(2)方式二:可以用 make 命令:
操作如下:
1. 先创建一个简单的C代码如下:

2. 建一个简单makefile文件,如下

3. 完成编译工作

可以看到,只需要一个make命令就能完成编译工作并形成可执行程序。。这就不需要每次编译源文件的时候都输入gcc xxx.c -o xxx这样一长串指令,效率提高了很多!
4. 完成清理工作

make会根据makefile的内容,完成编译/清理操作。
编译工作仅仅用make一条命令,而清理仅用make clean,是如何实现的?
3、原理
(1)图解代码

- 依赖文件列表
- 可以同时存在多个源文件,以空格为分隔符,如:test.c test1.c …
- 还可以为空,比如下面的清理操作,clean:,这是一种特殊的依赖关系!
- 依赖关系
目标文件的形成依赖于后面文件列表,这就构成了依赖关系。如上述的 proc:proc.c
,clean: 。(特殊)
- 依赖方法
目标文件形成的所依赖的方法,也就是光有依赖关系还不够,还得需要对应的方法才能实现。。如上述的gcc以及rm操作就是依赖方法。
此时上述的过程可以这样理解,使用make命令时,会在当前目录下寻找makefile文件,读取里面的内容,并根据依赖关系去找到对应的依赖方法并执行生成对应的目标文件!
(2)make 工作规则
① makefile文件,会被make从上到下开始扫描,默认执行第一对依赖关系和依赖方法,其他的不管,形成的是第一个目标文件!,如下这种情况
(i)依赖文件存在
演示如下:
当前目录下的文件:
makefile文件内容:
make一下看结果:
会发现此时执行顺序是从下往上的,不是说仅仅使用make命令时,从上往下读,只会执行第一对依赖关系吗?
是的没错,还是从上往下读,执行第一对依赖关系,但是因为第一对依赖关系中的依赖文件proc.o并不存在于当前目录,那么此时make会在当前文件中找目标文件为proc.o的依赖关系,发现依赖文件proc.s也并不存在,以此类推,最后推导发现依赖文件procc存在,就执行对应的依赖方法,在从下往上。如果推导至最后发现还是没有文件,那么此时的make就会直接退出,并报错!!



②make makefile 在执行gcc命令时候,如果发生了语法错误,就会停止推导过程,如下述两种情况:
(ii)依赖文件不存在
注意:这种情况下的不存在不是文件为空,而是没有创建此文件
演示如下:
当前目录下的文件:
makefile中的内容:
code.c文件并不在该目录下,来看结果:
可见,当依赖文件不存在时,make就不工作了。



(iii)依赖文件列表为空(特殊)
演示如下:
将上述的clean操作放在proc.c前面
make的结果:
从上往下读取,但是碰到依赖文件为空时,会直接执行对应的依赖方法,不会再向下推导了。也就是make将这种情况也视为依赖文件存在的情况。。那么此时如果要执行生成其他的目标文件,那就需要带上对应目标文件的名称!
所以,我们一般习惯上把形成可执行程序的目标文件放在第一位,文件的清理工作放在其他的位置,这也是开头演示时为什么使用make clean命令的原因!因为文件的清理工作放在其他的位置,不能直接make



小总结: make会自动根据文件的依赖性,进行自动推导,帮助我们执行所有相关的依赖方法!!
(3) .PHONY关键字
.PHONY:xxx(目标文件)
作用:让xxx(目标文件)对应的依赖方法,总是要被执行的!!!!
(i)无 .PHONY关键字时:
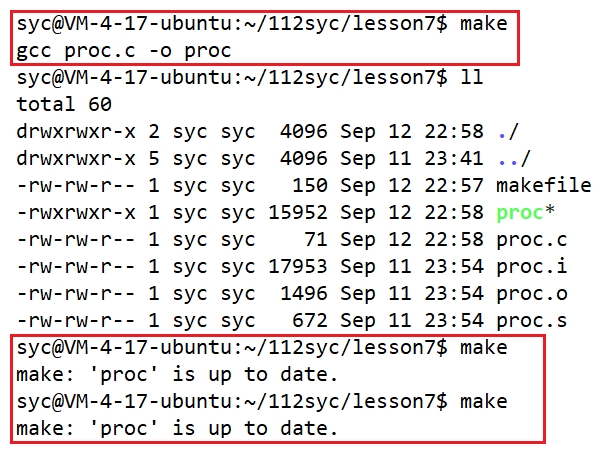
可以看到,只能make一下,当你连续make多次,是无法实现的! 因为makefile对最新生成的可执行程序,默认不会在重新生成,这样可以提高编译的效率!!除非你更新可执行程序所依赖的源文件时,即更新proc.c的内容才可以重新make!
但是可以加上.PHONY关键字就能打破这种限制!
(ii)加上.PHONY关键字
加上.PHONY关键字就能打破这种限制

但是实际上对于生成可执行程序的,一般不用这个关键字去修饰,这样编译效率不高(对于一个大工程而言),默认情况都是用于修饰clean这样的项目清理文件。。让清理工作总是被执行!
问题:加上.PHONY关键字是怎么打破这种限制,让文件不需要更新也可以继续make?
我们需要先了解,对于源文件和可执行程序,都是文件,文件=内容+属性(文件的时间+文件的大小…)
首先,用 [stat + 文件] 命令,查到文件对应的时间问题。

其中Access即当cat 文件的时候就会刷新,但是如果是每次访问一次就刷新的话,系统就一直需要io交互,因此改变了测率,积累一定次数刷新
用 chmod 修改文件的属性

可以发现属性时间改变了
然后 vim proc.c 修改文件的内容

我们发现Modify和Change的时间一起改变了,这是因为当对内容做修改时候,可能会引发属性的联动,内容变了,文件的大小可能会变,因此属性也就被修改了。
解释完上述内容,我们来看主线任务,proc.c时间在proc前,可以make

此时已经make过后,如果继续make,则无法编译。
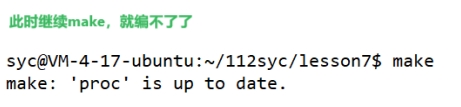
因此当源文件时间比可执行文件时间新时候,才可以继续编译。
对于上述proc is up to date情况,解决方法一:touch,更新proc.c这个源文件时间,使他在proc之后。


当proc.c时间被更新后,也就可以继续编译成proc了
解决方法二:便是我们主线任务的.PHONY
.PHONY的作用就是忽略掉时间对比,既然如此,proc.c与proc也没有谁先谁后之分,因此可以一直编译,即总是被编译

4、常用makefile写法
原理中的makefile写法依赖方法太多,我们正常的makefile是这样写的。

简化如下:

gcc -c 即默认形成同名的.o文件
对于上面的依赖方法的写法还是有点麻烦,还是要写gcc xxx.c -o xxx。(小文件还行)来看以下两种写法。
(1)内置符号法
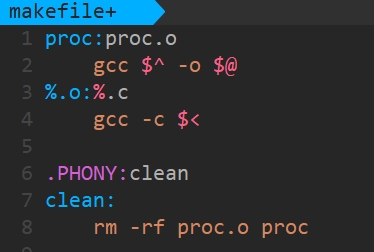
% 是makefile语法中的通配符。
%.c :当前目录下所有的.c文件,展开到依赖列表中。
类似于:
proc1.c proc2.c proc3.c
$< :右侧的依赖文件,一个一个的交给gcc -c选项,形成同名的.o文件
类似于:
gcc -c proc1.cgcc -c proc2.cgcc -c proc3.c
$^ :所有的依赖文件列表。
$@ :目标文件
执行结果与原先写法相同
注意: 对于清理文件不能用内置符号。
(2)变量替换法
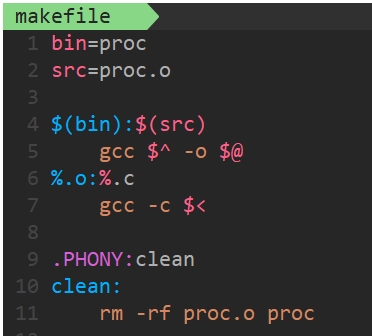
src后面可以跟多个文件。
这与宏替换类似,以后要是想改文件名,即在上面直接改就好。
使用make指令,默认一次只能生成一个可执行程序。如果如下这么做就可以一次执行多个。
all 依赖 bin1 和 bin2,要形成 all,就要形成 bin1 和 bin2,当 bin1 和 bin2 都形成后,all并没有依赖方法,因此makefile就到这结束了。

补充:
每次我们在make时,都会有gcc……这条指令显示出来,如果不想显示,可以这样改

在依赖方法前加上@符号即可。
五、小程序 —— 进度条
gcc/g++,vim,make/makefile — 综合点的案例 – linux第一个偏系统的一个样例程序 进度条
1、回车、换行和回车换行
回车:用 \r 表示。回到当前行的最开始,如果此时写入数据,会依次往后覆盖掉当前行的数据。
换行:用\n表示,表示光标移动到下一行正下方。
回车换行:光标移动到下一行的最开始。
注意:
- 键盘上的 Enter 键表示:回车并换行。
2、行缓冲区概念
(1)这段代码在 Linux 中运行,会产生什么结果呢?
#include <stdio.h>
#include <unistd.h> //sleep() int main()
{printf("hello world!\n"); //有'\n'sleep(3);return 0;
}
运行结果:先打印出 hello world,然后休眠 5s,结束程序。
(2)这段代码在 Linux 中运行,会产生什么结果呢?
#include <stdio.h>
#include <unistd.h> //sleep()
int main()
{printf("hello world"); //没有'\n'sleep(5);return 0;
}
运行结果:先休眠了 5s,当 5s 结束后,才打印出 hello world,结束程序。
当 sleep(5); 执行的时候,printf(“hello world”); 已经执行完了,但却没有先打印字符串,这是为什么呢?
printf(“hello world”);已经执行完了,但并不代表字符串就得显示出来。
那在执行 sleep(5); 期间,字符串在哪里呢?
缓冲区(本质就是一段内存空间,可以暂存临时数据,在合适的时候刷新出去)。
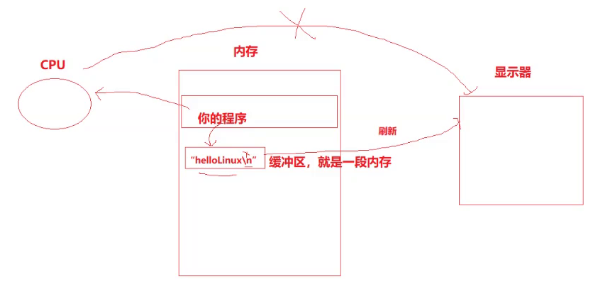
3、补充 : 刷新
刷新是什么?
把数据真正的写入磁盘、文件、显示器、网络等设备或文件中。
刷新策略:
- 直接刷新,不缓冲。
- 缓冲区写满,再刷新(称为全缓冲)。
- 碰到 ‘\n’ 就刷新,称为行刷新。(注:行刷新一般对应的设备是显示器)
- 强制刷新。
任何一个 C 程序,启动的时候,都会默认打开三个流(文件):
- 标准输入 stdin、标准输出 stdout、错误 stderr(类型是 FILE* 文件指针类型)
- 如果想要让数据在显示器上显示出来,需要向输出流 stdout 中写入数据。
回到前面的问题,为什么在执行 sleep 的时候,没有显示字符串呢?
因为我们想要把字符串显示到显示器上,显示器默认是行刷新,遇到 ‘\n’ 才刷新,而我们前面写的代码中,并没有 ‘\n’,所以 printf 执行完了没有刷新。
为了在 printf 执行完的时候,让字符串立马显示出来,需要进行强制刷新,把字符串尽快的写入显示器中。
强制刷新需要用到一个函数:
#include <stdio.h>
int fflush(FILE *stream); //把当前缓冲区的数据写入到流中
因为是让字符串在显示器上显示,所以我们需要传文件指针 File* stdout,代码如下:
#include<stdio.h>
#include<unistd.h> //sleep()
int main()
{printf("hello world"); //没有'\n',字符串写入到了缓冲区中,但不会被立即刷新出来fflush(stdout); //强制刷新,把当前缓冲区中的数据写入到输出流文件中sleep(5);return 0;
}
运行结果:先打印出 hello world,然后休眠 5s,结束程序。
4、小程序 —— 倒计时
普通版:换行打印


每隔一秒换行打印

升级版:在一行中打印内容

运行结果:(借用一下)

代码中加一个printf(“\r\n”); 就会重启一行表示结束运行。
问题1:
上述代码存在在一个错误,当你想从10开始打印时候,打印结果会是10,90,80…
因为显示器没有类型的概念,显示器只认识一个一个的字符,printf要把整数1234,转化成“1”,“2”,“3”,“4”。
因此我们打印10的时候会打印成“1”+“0”,然后\r回到最开始后,只会覆盖一个数字,“0”不会被覆盖。

改成左对齐就好。
5、进度条代码
简易版:

演示如下:

接下来引入usleep,可以用man usleep 来使睡眠周期以微秒为单位增加
再加上一些美化:

演示如下:

再优化一下:

演示如下:

相关文章:
Linux 开发工具(vim、gcc/g++、make/Makefile)+【小程序:进度条】-- 详解
目录 一、Linux软件包管理器 - yum(ubuntu用apt代替yum)1、Linux下安装软件的方式2、认识 yum3、查找软件包4、安装软件5、如何实现本地机器和云服务器之间的文件互传 二、Linux编辑器 - vim1、vim 的基本概念2、vim 下各模式的切换3、vim 命令模式各命令…...
后续学习规划 ----含我个人的学习路线,经历及感受
目前的基础 开发相关(最重要) 1.Java SE 从入门到起飞 2.Java Web开发 3.苍穹外卖 以上三个是和开发相关的基础。 我是按照书写的顺序学习的,有需要的朋友可以参考。 计算机相关 其他的话,都是比较久远的了。隔得时间一年半…...
Skytower
一、安装配置靶机 下载地址: SkyTower: 1 ~ VulnHub 下载之后解压发现是VirtualBox格式的 我们下载一个VirtualBox,这是官网 Downloads – Oracle VirtualBox 安装到默认路径就 打开后点击注册 选择解压后的vbox文件 然后点击左上角管理 点击导出虚拟电脑&…...

成型的程序
加一个提示信息 加上python 常用的包 整个程序打包完 250M 安装 960MB matplot numpy pandas scapy pysearial 常用的包 (pyvisa)… … 啥都有 Python 解释器组件构建 要比 lua 容易的多 (C/Rust 的组件库)...

卡尔曼滤波中Q和R与噪声的关系
卡尔曼滤波 一种用于估计系统状态的递归滤波器,通过融合传感器测量和系统模型,提供系统状态的最优估计。 Q和R是什么 在卡尔曼滤波中,Q和R分别表示过程噪声和测量噪声的协方差矩阵。 Q Q Q矩阵(过程噪声协方差矩阵)…...

sicp每日一题[2.10]
Exercise 2.10 Ben Bitdiddle, an expert systems programmer, looks over Alyssa’s shoulder and comments that it is not clear what it means to divide by an interval that spans zero. Modify Alyssa’s code to check for this condition and to signal an error if i…...

MCN跨国企业如何从0到1搭建ITSM运维体系
1. IT运维体系概述 1.1 定义与目标 IT运维体系,即信息技术运维管理体系,是指企业为了保障IT基础设施和业务系统的稳定、高效、安全运行,所建立的一系列管理流程、规范、工具和组织的总称。其核心目标是通过对IT资源的集中管理和服务&#x…...

【C++入门学习】7. 类型
基本类型 修饰符类型 基本类型 类型关键字布尔型bool字符型char整型int浮点型float双浮点型double无类型void宽字符型wchar_t 字符型char只占八位,存储ascii码的,而宽字符型是为了存储多国语言的代码unicode。 // 宽字符型的定义 typedef short int …...

视频服务器:GB28181网络视频协议
一、前言 某项目中需要集成视频管理平台,实现分布在各省公司的摄像及接入,对视频进行统一管理。本项目中视频管理平台采用GB/T28181实现的监控设备接入管理平台,支持在开放互联网和局域网对监控设备进行远程接入、远程管理、远程调阅、录像回…...

vue3 一次二次封装element-plus组件引发的思考
前言 在开发 Vue 项目中我们一般使用第三方 UI 组件库进行开发,如 Element-Plus、Element-ui、Ant-design等, 但是这些组件库提供的组件并不一定都能满足我们的日常开发需求,有时候我们需要实现的效果是直接使用组件库无法实现的,那么这时我们就可以通过对组件库的组件进行…...

[Web安全 网络安全]-文件读取与下载漏洞
文章目录: 一:任意文件读取漏洞 1.定义 2.危害 3.产生原因 4.发现漏洞 5.利用漏洞 6.防范措施 7.读取漏洞举例 二:任意文件下载漏洞 1.定义 2.漏洞利用 3.漏洞挖掘 4.漏洞验证 5.漏洞防御修复 pikachu靶场:是一个…...

2024.9.12(k8s环境搭建2)
一、接9.11 19、部署calico的pod 4. 查看容器和节点状态 异常处理: 出现Init:0/3,查看node节点 /var/log/messages是否有除网络异常之外的报错信息 三台机器执行:(更新版本) yum list kernel yum update kernel reb…...

Redis 字典的哈希函数和 rehash 操作详解
Redis 字典的哈希函数和 rehash 操作详解 在 Redis 中,字典(Hash Table)是一种重要的数据结构,用于存储键值对。下面解释 Redis 字典的哈希函数和 rehash 操作。 一、哈希函数 作用 Redis 的字典使用哈希函数将键转换为一个整数索引,这个索引用于确定键值对在哈希表中的…...
汉王手写签批控件如何在谷歌、火狐、Edge等浏览器使用
背景 近日,有网友咨询汉王手写签批控件是否可以通过allWebPlugin中间件技术加载到谷歌、火狐、Edge等浏览器?为此,笔者详细了解了一下汉王手写签批控件,它是一个标准的ActiveX控件,曾经主要在IE浏览器使用,…...

Halo 开发者指南——项目运行、构建
准备工作 环境要求 OpenJDK 17 LTSNode.js 20 LTSpnpm 9IntelliJ IDEAGitDocker(可选) 名词解释 工作目录 指 Halo 所依赖的工作目录,在 Halo 运行的时候会在系统当前用户目录下产生一个 halo-next 的文件夹,绝对路径为 ~/ha…...

【C++】——list
文章目录 list介绍和使用list注意事项 list模拟实现list和vector的不同 list介绍和使用 在C中,list是一个带头双向链表 list注意事项 迭代器失效 删除元素:当使用迭代器删除一个元素时,指向该元素的迭代器会失效,但是不会影响其他…...

07_Python数据类型_集合
Python的基础数据类型 数值类型:整数、浮点数、复数、布尔字符串容器类型:列表、元祖、字典、集合 集合 集合(set)是Python中一个非常强大的数据类型,它存储的是一组无序且不重复的元素,集合中的元素必须…...

结合人工智能,大数据,物联网等主流技术实现业务流程的闭环整合的名厨亮灶开源了
明厨亮灶视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。AI技术可以24小时…...

vue环境搭建相关介绍
一、路由管理器说明 1.route:译为路由,可以理解为单个路由或者某一个路由。 2.routes:路由集合,可以理解为多个route的集合。 3.router:路由器,可以理解为路由集合的管理者。例如,当我们在页面…...
——MyBatis的关联映射和缓存机制)
MyBatis系统学习(四)——MyBatis的关联映射和缓存机制
MyBatis 是一个优秀的持久层框架,它通过 XML 或注解将 Java 对象与 SQL 语句相映射,简化了 JDBC 代码,增强了 SQL 的灵活性。在复杂业务场景中,数据库表之间经常存在一对一、一对多、多对多的关联关系,MyBatis 提供了相…...

Go语言的性能优化:从分析到实践
Go语言的性能优化:从分析到实践 性能优化的重要性 在软件开发中,性能优化是一个永恒的话题。一个高性能的应用程序可以: 提高用户体验,减少响应时间降低服务器成本,提高资源利用率增强系统的可扩展性提升应用程序的竞争…...
)
Edge/Chrome用户必看:3种免费工具批量清理失效书签(2023实测)
Edge/Chrome用户必备:2023年高效清理失效书签的3种解决方案 每次打开浏览器,看到密密麻麻的书签栏却找不到真正可用的链接?这可能是大多数互联网用户的日常困扰。根据2023年用户调研数据显示,平均每位浏览器用户拥有超过200个书签…...
2026-04-03 全国各地响应最快的 BT Tracker 服务器(联通版)
数据来源:https://bt.me88.top 序号Tracker 服务器地域网络响应(毫秒)1http://211.75.210.221:6969/announce江苏镇江联通222http://60.249.37.20:80/announce广东肇庆联通273udp://132.226.6.145:6969/announce宁夏银川联通724http://93.158.213.92:1337/announce…...

解密Prompt系列69. 从上下文管理到Runtime操作系统
AM)”,将 Runtime 视为“状态(State)”,构建一套属于智能体的“操作系统”。 最近,ByteDance 的 Context-Folding、MIT 的 RLM、以及热门项目 Ralph 的出现,共同指向了一个极其明确的趋势&…...
)
保姆级教程:用AutoDL租4090显卡,在PyCharm里远程复现具身智能论文PAI0(附完整避坑清单)
零基础实战:AutoDLPyCharm复现PAI0具身智能论文全流程指南 第一次接触云端GPU服务器和远程开发?别担心,这篇教程会手把手带你用AutoDL租用4090显卡,并通过PyCharm实现无缝远程开发,完整复现具身智能领域的前沿论文PAI0…...

AI大模型系统学习路线:零基础入门人工智能,附AI大模型学习与面试资源!【非常详细】
人工智能(AI)正在重塑全球产业格局,从自动驾驶到医疗诊断,从金融风控到内容创作,AI技术已成为21世纪的核心竞争力。对于零基础学习者而言,构建系统化的学习路径至关重要。1. 明确学习动机职业转型 …...

【Hot 100 刷题计划】 LeetCode 438. 找到字符串中所有字母异位词 | C++ 滑动窗口题解
LeetCode 438. 找到字符串中所有字母异位词 | C 固定滑动窗口极致优化题解 📌 题目描述 题目级别:中等 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。异位词ÿ…...
)
OpenClaw 实用指南-节假日系统巡检全自动化(下)
前言 在上一篇文章中,我们已详细讲解了节假日系统巡检全自动化的前三个核心部分,分别是:Part1:AI节假日智能判断、Part2:目标服务器稳定连接、Part3:借助“小龙虾”工具批量部署软件,并利用部署…...

手把手教程:快速设置远程开机,看完就会
今天就给大家带来一份完整、可直接照着操作的远程开机教程,即可实现无需公网 IP、一键远程唤醒,随时随地让设备为你待命。设备支持检查确认主板支持WAKE-ON-LAN(网络唤醒)功能,局域网内需具备两台设备:目标…...

【架构师通关】理发店排队 + 车库停车,大白话秒懂“进程状态模型”与“PV操作
兄弟们,操作系统的进程管理一直是软考里最让人头疼的“硬骨头” 🦴。什么“阻塞”、“挂起”、“信号量”、“PV操作”,听着就像天书 📚。 但今天,飞哥绝不跟你拽学术名词!咱们就通过“去理发店剪个头” &a…...