Transformer模型详细步骤
Transformer模型是nlp任务中不能绕开的学习任务,我将从数据开始,每一步骤都列举出来,然后对应重点的代码进行讲解
-------------------------------------------------------------------------------------------------------------
Transformer模型是基于注意力机制的一种深度学习架构,最早由Vaswani等人在2017年提出,主要用于自然语言处理(NLP)任务。它不同于传统的循环神经网络(RNN)或卷积神经网络(CNN),因为它完全依赖于注意力机制,不需要通过时间步长来处理序列数据,从而可以更高效地并行处理数据。
大名鼎鼎的transform一经出现就席卷了各个方面,
transform原论文:
Attention Is All You Need
论文网址:https://arxiv.org/pdf/1706.03762
核心组件介绍
Transformer模型主要包括以下几个部分:
- 输入嵌入(Input Embeddings)
- 位置编码(Positional Encoding)
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feedforward Neural Network)
- 编码器(Encoder)和解码器(Decoder)结构
- 输出层(Output Layer)

以句子“我喜欢小狗”为例,详细展示Transformer模型中的每一步及其对应的矩阵变化。假设每个单词的嵌入维度为4,句子长度为4。
步骤 1:输入嵌入
假设通过一个词嵌入矩阵(Embedding Matrix)将每个词转化为一个4维的嵌入向量,嵌入后得到的矩阵X∈R^4×4,词嵌入矩阵是通过预训练得到的。例如,Word2Vec和GloVe等模型已经在大规模文本语料上训练好,提供了每个单词的嵌入向量。
Word2Vec 简介
Word2Vec 是一种将词汇表示为向量的技术,它通过神经网络模型将词映射到连续向量空间中,能够捕捉词与词之间的语义关系。Word2Vec 有两种主要的模型结构:
- CBOW(Continuous Bag of Words):基于上下文词来预测中心词。
- Skip-gram:基于中心词来预测上下文词。
Word2Vec 的原理
Word2Vec 的核心思想是基于词的上下文来学习词向量。在大规模语料库中,词汇共现的模式可以用来推测它们之间的语义相似性。词向量模型旨在使得语义相似的词在向量空间中彼此接近。
CBOW 模型
CBOW 通过上下文词预测中心词。例如,在“我喜欢小狗”这个句子中,假设要预测“喜欢”,则上下文词为“我”和“小狗”。
上下文词嵌入平均值:对于给定的上下文词,计算它们词嵌入向量的平均值:
预测中心词的概率分布:我们用上下文的平均向量通过 softmax 函数来预测中心词的概率分布:
通过计算每个词向量和上下文向量的内积来衡量词语匹配的可能性,最后通过 softmax 归一化成概率分布。
损失函数:CBOW 模型的目标是最大化所有中心词的预测概率,通常使用交叉熵损失:
Skip-gram 模型
Skip-gram 模型与 CBOW 模型相反,它使用中心词预测上下文词。例如,给定中心词“喜欢”,我们预测上下文词“我”和“小狗”。
公式:
Skip-gram 模型的计算步骤与 CBOW 类似,只是这里使用中心词来预测每个上下文词。
上下文词的预测:给定中心词,我计算上下文词的概率:
损失函数:Skip-gram 模型的目标是最大化上下文词的预测概率,损失函数为:
在实际应用中,由于词汇表 V的大小可能非常大,直接计算 softmax 的开销非常高。为了解决这个问题,Word2Vec 引入了 负采样 技术。
负采样的主要思想是,只对正样本(真实的上下文词)和一小部分负样本(随机选择的非上下文词)进行训练,而不是对整个词汇表计算 softmax。负采样的损失函数为:
Word2Vec 的训练
- 初始化词向量矩阵,通常是随机生成的。
- 通过优化损失函数(如交叉熵或负采样)来更新词向量。
- 最终训练完成后,模型会输出每个词在向量空间中的表示,语义相似的词在向量空间中距离较近。
示例:
假设条件:
- 词汇表大小 V=5(假设词汇表中只有 "我"、"喜欢"、"小狗"、"吃"、"饭" 五个词)。
- 词向量维度 d=4
- Skip-gram 模型,中心词为 "喜欢",上下文词为 "我" 和 "小狗"。
1. 初始化嵌入矩阵
首先,词嵌入矩阵是随机初始化的,用来表示词汇表中每个词的向量表示。假设嵌入矩阵:
2. Skip-gram 中心词和上下文词
在 Skip-gram 模型中,中心词 "喜欢" 的嵌入向量是通过查找嵌入矩阵
3. 预测上下文词
使用中心词的嵌入向量来预测上下文词。Skip-gram 的目标是让中心词和真实上下文词的相似度最大化,同时最小化中心词与负样本(随机选取的词)的相似度。预测上下文词的概率可以通过计算中心词嵌入和上下文词嵌入的点积:
对于 "我":
对于”狗“:
通过点积可以计算出中心词和上下文词之间的相似度分数。为了得到概率,我们通常通过 softmax 函数对这些相似度进行归一化。
4. Softmax 计算
为了预测 "我" 和 "小狗" 的概率,需要计算 softmax:
5. 负采样
为了简化计算,Skip-gram 模型引入了负采样。假设我们随机选择 "吃"作为负样本,计算它们与中心词 "喜欢" 的点积:
接下来,将正样本和负样本的结果输入到 sigmoid 函数中进行优化。










设单词xi 是输入的单词,其嵌入向量为 e(xi)

- "我" -> 0
- "喜欢" -> 1
- "小狗" -> 2
词向量矩阵的学习过程如下:
- 初始化:开始时,嵌入矩阵的每个单词向量可以是随机初始化的。
- 前向传播:通过嵌入矩阵将单词转换为向量,并传递到模型的下一层。
- 损失计算:模型的输出与目标标签计算损失。
- 反向传播:通过计算损失函数的梯度来更新嵌入矩阵。
- 优化:使用优化算法(如SGD、Adam)来更新嵌入矩阵,直到模型收敛。
生成方式:
词向量矩阵初始时随机生成,但在训练过程中会根据反向传播更新。其目的是让相似意义的单词在向量空间中靠得更近。具体来说:
假设矩阵如下所示:
"我" -> [0.2, 0.4, 0.1, 0.3]
"喜欢" -> [0.6, 0.8, 0.5, 0.9]
"小狗" -> [0.7, 0.2, 0.9, 0.1]

步骤 2:位置编码(Positional Encoding)
由于Transformer没有时间步长的概念,因此需要加入位置信息来帮助模型理解序列顺序。位置编码使用一些数学公式,比如正弦和余弦函数,将位置信息加入到嵌入向量中。位置编码矩阵是固定的,不需要训练。它根据输入序列的位置和维度生成。计算公式为:

其中 pos 是位置,i 是维度索引,d 是嵌入的总维度。
- 每个位置 pospospos 对应的向量由正弦和余弦函数的组合构成。位置越靠前的单词,它的编码数值变化越剧烈,越往后的单词,数值变化就会越缓慢。这种设计让不同位置的编码在各个维度上有所区分。
- 正弦和余弦函数的周期性特性也使得模型可以容易地捕捉到不同单词之间的位置差异。
假设句子是“我喜欢小狗”,词嵌入矩阵初始化为:
根据位置编码公式,计算第 0、1、2 个位置的编码

然后我们将词向量和位置编码向量相加,得到最终输入 Transformer 的向量:

位置编码与词向量的关系
-
词向量:是通过嵌入矩阵(通常是随机初始化后经过训练得到的)来表示单词的语义。词向量中没有位置信息。
-
位置编码:是为了让模型知道每个词在句子中的位置。它不会改变词向量的语义,而是将位置信息叠加到词向量中。位置编码矩阵是固定的,不需要训练。
#对应代码
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(1), :]
步骤 3:多头自注意力机制(Multi-Head Self-Attention)
这是Transformer的核心部分,自注意力机制计算的是句子中每个单词和其他单词的相关性。首先将输入嵌入分别映射到三个不同的空间:查询(Query)、键(Key)和值(Value)。然后计算每对单词之间的注意力权重,最终通过这些权重加权求和得到每个单词的新表示。

缩放因子 :这是一个常数,确保内积的尺度合适。它不会被训练,也不是随机生成的。
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0self.d_k = d_model // num_headsself.num_heads = num_heads# 需要训练的矩阵:W_Q, W_K, W_Vself.W_Q = nn.Linear(d_model, d_model)self.W_K = nn.Linear(d_model, d_model)self.W_V = nn.Linear(d_model, d_model)self.W_O = nn.Linear(d_model, d_model) # 最终的输出权重矩阵def forward(self, X):batch_size, seq_len, d_model = X.shape# 线性变换得到 Q, K, VQ = self.W_Q(X) # (batch_size, seq_len, d_model)K = self.W_K(X)V = self.W_V(X)# 将 Q, K, V 分成多个头Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)# 计算缩放点积注意力attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / np.sqrt(self.d_k)attention_weights = torch.nn.functional.softmax(attention_scores, dim=-1)attention_output = torch.matmul(attention_weights, V)# 将多个头的输出合并attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.W_O(attention_output) # 通过线性层输出
步骤 4:前馈神经网络(Feedforward Neural Network)
每个注意力层后面接一个前馈神经网络,通常由两个线性变换和一个ReLU激活函数组成。
前馈神经网络由两个全连接层构成,各自有权重和偏置矩阵:
![]()
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super(FeedForward, self).__init__()self.linear1 = nn.Linear(d_model, d_ff)self.relu = nn.ReLU()self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):return self.linear2(self.relu(self.linear1(x)))
步骤 5:编码器(Encoder)和解码器(Decoder)
Transformer的编码器由多个层堆叠而成,每一层都包含一个多头自注意力机制和前馈神经网络。解码器除了这些模块外,还包含一个额外的注意力层,用于接收编码器的输出。
步骤 6:输出层(Output Layer)
最终的输出通常会通过一个线性层映射到所需的输出维度,比如词汇表大小(用于机器翻译)或分类任务中的类别数。
相关文章:

Transformer模型详细步骤
Transformer模型是nlp任务中不能绕开的学习任务,我将从数据开始,每一步骤都列举出来,然后对应重点的代码进行讲解 ------------------------------------------------------------------------------------------------------------- Trans…...
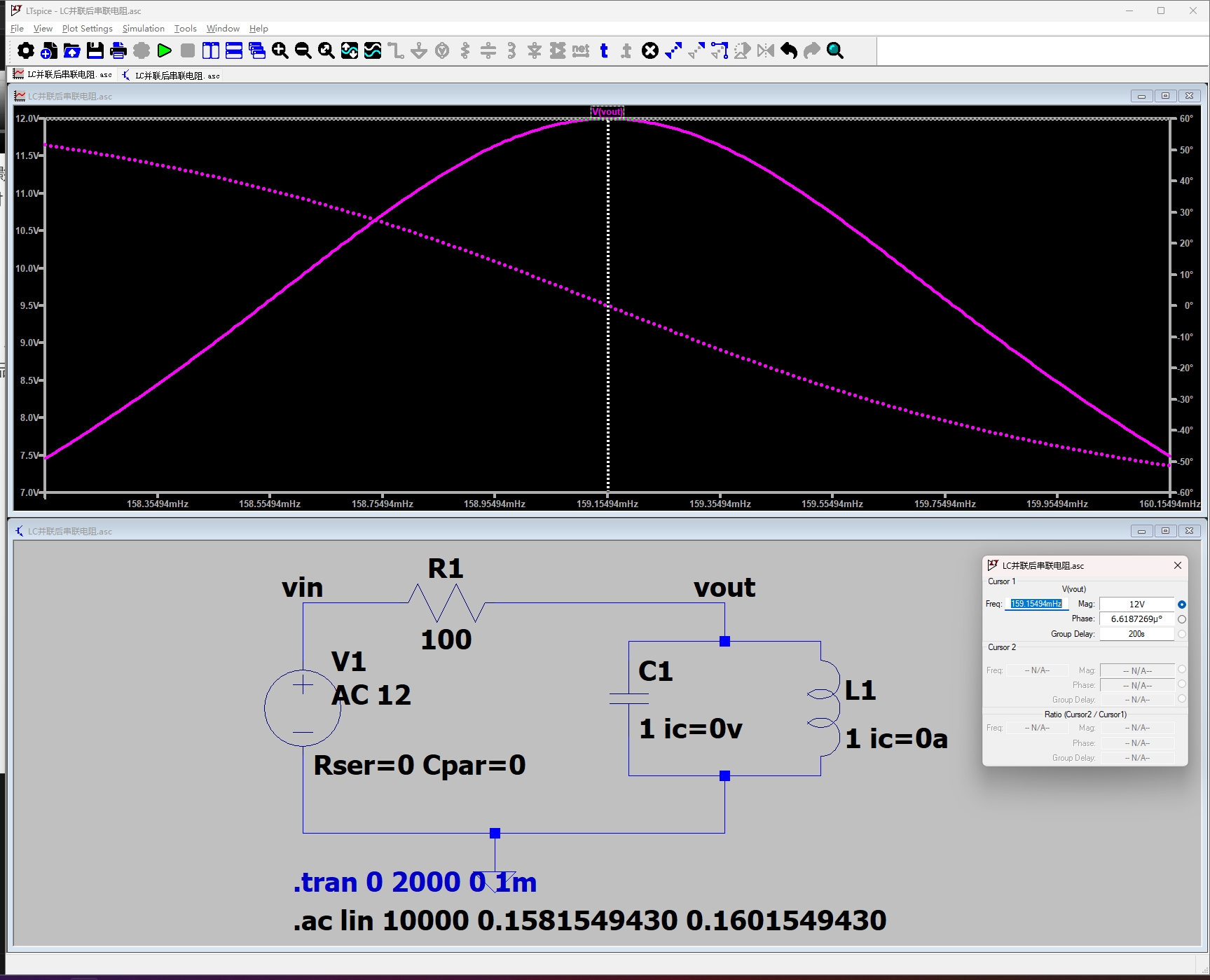
LC并联电路在正弦稳态下的传递函数推导(LC并联谐振选频电路)
LC并联电路在正弦稳态下的传递函数推导(LC并联谐振选频电路) 本文通过 1.解微分方程、2.阻抗模型两种方法推导 LC 并联选频电路在正弦稳态条件下的传递函数,并通过仿真验证不同频率时 vo(t) 与 vi(t) 的幅值相角的关系。 电路介绍 已知条件…...

【前后端】大文件切片上传
Ruoyi框架上传文件_若依微服务框架 文件上传-CSDN博客 原理介绍 大文件上传时,如果直接上传整个文件,可能会因为文件过大导致上传失败、服务器超时或内存溢出等问题。因此,通常采用文件切片(Chunking)的方式来解决这些…...

图像处理 -- ISP功能之局部对比度增强 LCE
局部对比度增强(LCE) 局部对比度增强(Local Contrast Enhancement, LCE)是一种图像处理技术,旨在通过调整图像的局部区域对比度,增强图像细节和视觉效果。LCE 的实现方式多种多样,以下是几种常…...

C++速通LeetCode简单第5题-回文链表
解法1,堆栈O(n)简单法: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListN…...

【Java 优选算法】双指针(下)
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 有效三角形的个数 题目链接 解法 解法1:暴力枚举--->O(n^3) 解法2:利用单调性,使用双指针来解决---->O(n^2) 优化:对整个数组进行排序先固定最大数在最大数的左…...

动态规划:07.路径问题_珠宝的最大价值_C++
题目链接:LCR 166. 珠宝的最高价值 - 力扣(LeetCode)https://leetcode.cn/problems/li-wu-de-zui-da-jie-zhi-lcof/description/ 一、题目解析 题目: 解析: 有过做前几道题的经验,我们会发现这道题其实就…...

COMDEL电源CX2500S RF13.56MHZ RF GENERATOR手侧
COMDEL电源CX2500S RF13.56MHZ RF GENERATOR手侧...

GPU加速生物信息分析的尝试
GPU工具分类 实话实说,暂时只有英伟达的GPU才能实现比较方便的基因组分析集成化解决方案,其他卡还需要努力呀,或者需要商业公司或学术团体的努力开发呀!FPGA等这种专用卡的解决方案也是有的,比如某测序仪厂家…...

【零散技术】详解Odoo17邮件发送(一)
序言:时间是我们最宝贵的财富,珍惜手上的每个时分 Odoo的邮件功能十分强大,在非常多的场景中可以看见其应用,例如原生的用户邀请,报价单发送,询价单发送等等.... 那么抛开原生自带的功能,我们如何巧妙的通过代码进行自…...

函数题 6-5 求自定类型元素的最大值【PAT】
文章目录 题目函数接口定义裁判测试程序样例输入样例输出样例 题解解题思路完整代码AC代码 编程练习题目集目录 题目 要求实现一个函数,求N个集合元素S[]中的最大值,其中集合元素的类型为自定义的ElementType。 函数接口定义 ElementType Max( Element…...

Python---爬虫
文章目录 目录 前言 一.Http请求/响应模块 requests模块 二.文本筛选模块 re模块 XPath模块 XPath 路径表达式 XPath 语法元素 三. 爬虫模板 爬虫案例 前言 Python爬虫是一种通过自动化程序爬取互联网上的信息的技术。爬虫可以自动访问网页并提取所需的数据,比…...

设计模式之组合设计模式
一、组合设计模式概念 组合模式 (Component) 是一种结构型设计模式,将对象组合成树形结构以表示“部分-整体”的层次结构。 组合模式使得用户对单个对象和组合对象的使用具有唯一性。 适用场景 想要表示对象的部分-整体层次结构。想要客户端忽略组合对象与单个对象的…...

Java汽车销售管理
技术架构: springboot mybatis Mysql5.7 vue2 npm node 有需要该项目的小伙伴可以添加我Q:598748873,备注:CSDN 功能描述: 针对汽车销售提供客户信息、车辆信息、订单信息、销售人员管理、财务报表等功能&…...

js TypeError: Cannot read property ‘initialize’ of undefined
js TypeError: Cannot read property ‘initialize’ of undefined 在JavaScript开发旅程中,遇到TypeError: Cannot read property ‘initialize’ of undefined这样的错误提示,无疑是令人沮丧的。这个错误通常意味着你试图访问一个未定义对象的initiali…...

【Motion Forecasting】【摘要阅读】BANet: Motion Forecasting with Boundary Aware Network
BANet: Motion Forecasting with Boundary Aware Network 这项工作发布于2022年,作者团队来自于OPPO。这项工作一直被放在arxiv上,并没有被正式发表,所提出的方法BANet在2022年达到了Argoverse 2 test dataset上的SOTA水准。 Method BANet…...

Cpp快速入门语法(下)(2)
文章目录 前言一、函数重载概念与使用C为何支持函数重载? 二、引用概念语法特性权限(常引用)使用场景与指针的区别 三、内联函数四、auto关键字(C11)五、基于范围的for循环(C11)六、指针空值nullptr(C11)总结 前言 承前启后,正文开始! 一、函…...

【GO开发】MacOS上搭建GO的基础环境-Hello World
文章目录 一、引言二、安装Go语言三、配置环境变量(可跳过)四、Hello World五、总结 一、引言 Go语言(Golang)因其简洁、高效、并发性强等特点,受到了越来越多开发者的喜爱。本文将带你一步步在Mac操作系统上搭建Go语…...

探索轻量级语言模型 GPT-4O-mini 的无限可能
随着人工智能技术的日益发展,语言模型正逐渐成为人们日常生活和工作中不可或缺的一部分。其中,GPT-4O-mini 作为一个轻量级大模型,以其强大的功能和易用性吸引了众多关注。本文将带您了解 GPT-4O-mini 的出色表现、应用场景以及如何免费使用这…...

CSS 笔记 1
1. CSS 优先级, 内部大于外部。 2. 几个属性: flex-grow: 1; 让 当前元素 在剩余空间中, 占据尽可能多的高度,确保它能在中间居中。 max-height: 300px; 限制最大高度 300 像素, flex-grow: 1; 导致占的太满了&#x…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...