MySQL篇(窗口函数/公用表达式(CTE))
目录
讲解一:窗口函数
一、简介
二、常见操作
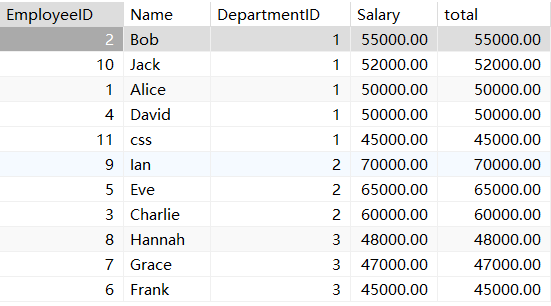
1. sum+group by常规的聚合函数操作
2. sum+窗口函数的聚合操作
三、基本语法
1. Function(arg1,..., argn)
1.1. 聚合函数
sum函数:求和
min函数 :最小值
1.2. 排序函数
1.3. 跨行函数
2. OVER [PARTITION BY <...>]
3. [ORDER BY <....>]
4. [window_expression]
四、练习题
1. 建库建表语句
2. 题目
3. 答案解析
计算每日销售额总和(分区按日期)
计算每个区域的总销售额
为每个产品计算其销售排名(按销售额降序)
计算每个区域每天的平均销售额
计算每个产品的销售累计总额
计算每个区域每个产品的销售总额
计算每个区域最近7天的平均销售额
为每个产品的销售记录添加序列号(按日期排序)
计算每个区域每天相对于前一天的销售额变化
计算每个产品的销售占比(按总销售额)
讲解二:公用表达式(CTE)
一、简介
二、语法
三、示例
四、递归 CTE
1. 简介
2. 递归成员限制
3. 示例
4. 使用递归 CTE 遍历分层数据
五、CTE 与 Derived Table
1. 在 5.6 版本中
2. 在 5.7 版本中
3. 在 8.0 版本中
讲解一:窗口函数
一、简介
窗口函数是一种SQL函数,非常适合于数据分析,其最大的特点就是:输入值是从
SELECT语句的结果集中的一行或者多行的"窗口"中获取的,也可以理解为窗口有大有
小(行数有多有少)。
通过OVER子句,窗口函数与其他的SQL函数有所区别,如果函数具有OVER子句,
则它是窗口函数。如果它缺少了OVER子句,则他就是个普通的聚合函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组
合的常规聚合会隐去正在聚合的各个行,最终输出称为一行。但是窗口函数聚合完之
后还可以访问当前行的其他数据,并且可以将这些行的某些属性添加到结果当中去。
下面可以通过两个图来区分普通的聚合函数和窗口函数
为了更加直观的反映窗口函数和普通聚合函数的区别,让我们通过代码的形式感受一
下 ,首先让我们先添加测试数据,并查看表。
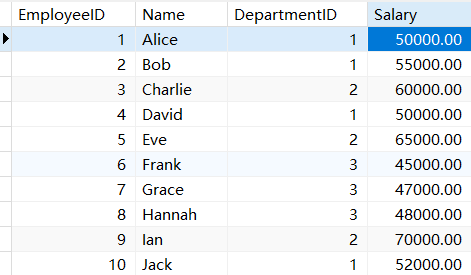
CREATE DATABASE IF NOT EXISTS EmployeeDB;
USE EmployeeDB;
CREATE TABLE Employees (EmployeeID INT AUTO_INCREMENT PRIMARY KEY,Name VARCHAR(100),DepartmentID INT,Salary DECIMAL(10, 2)
);INSERT INTO Employees (Name, DepartmentID, Salary) VALUES
('Alice', 1, 50000),
('Bob', 1, 55000),
('Charlie', 2, 60000),
('David', 1, 50000),
('Eve', 2, 65000),
('Frank', 3, 45000),
('Grace', 3, 47000),
('Hannah', 3, 48000),
('Ian', 2, 70000),
('Jack', 1, 52000);
二、常见操作
1. sum+group by常规的聚合函数操作
select DepartmentID, sum(salary) as total
from employees
group by DepartmentID;
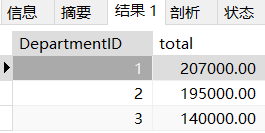
我们可以看的出来,常规聚合函数把id进行分组然后把每组的薪资综合计算出来放在
最后面。
2. sum+窗口函数的聚合操作
select *, sum(Salary) over (partition by DepartmentID) total
from employees
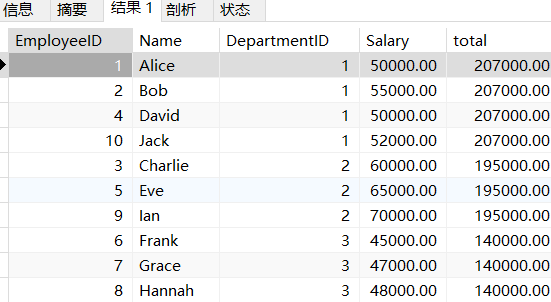
我们可以通过这两个例子看出来,聚合函数和窗口聚合函数的区别。就是窗口函数会
进行分组,但不会把行进行合并。对于每一组窗口函数返回出来的结果都会重复的放在最后面。
三、基本语法
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>]
[<window_expression>])
对于以上的窗口函数的语法[ ]中的语法是可以根据自己的需求进行选择(非必须写
入语法),并且此语法严格按照上面的顺序来规定。
Function(arg1,..., argn)是表示函数的分类,可以是下面分类中的任何一组。
- 聚合函数,例如sum,min,avg,count等函数(常用)
- 排序函数,例如rank row_number dense_rank()等函数(常用)
- 跨行函数,lag lead 函数
OVER [PARTITION BY <...>] 类似于group by 用于指定分组
- 每个分组你可以把它叫做窗口
- 不分组的情况可以写成partition by null 或者直接不写partition by,所有列为
一个大组
- 分组的情况下,partition by 后面可以跟多个列,例如partition by cid,cname
[ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
[<window_expression>] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
1. Function(arg1,..., argn)
通常和partition by分组使用。
当然也可以不分组使用,但也不分组使用通常没有意义。
- 聚合函数,例如sum,min,avg,count等函数(常用)
- 排序函数,例如rank row_number dense_rank()等函数(常用)
- 跨行函数,lag lead 函数
1.1. 聚合函数
我们还通过上文的测试数据进行演示。我们就演示2个函数,其他的聚合类函数都是
相同的用法。
sum函数:求和
select *,sum(Salary) over (partition by DepartmentID) total
from employees
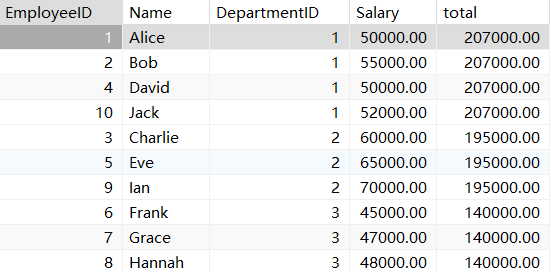
min函数 :最小值
select *,min(Salary) over (partition by DepartmentID) total
from employees;
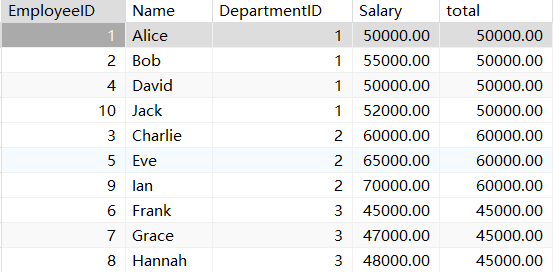
其他的聚合函数都是同样的用法。
1.2. 排序函数
rank row_number dense_rank()等函数,通常与order by函数一起使用。
row_number()函数:对分组之后按照某些规则从高到低或者从低到高进行排序
(order by),然后打上序号,不考虑并列的情况。
select *,row_number() over (partition by DepartmentID order by Salary desc ) total
from employees;
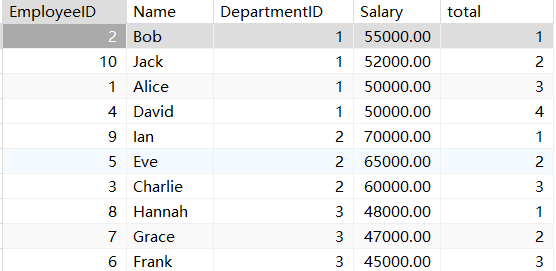
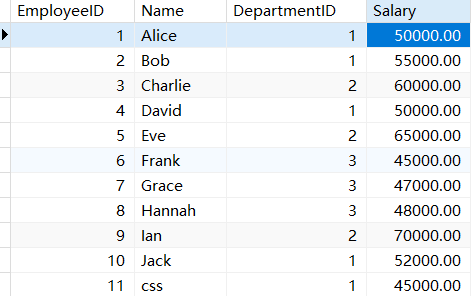
rank()函数:对分组之后按照某些规则从高到低或者从低到高进行排序(order by),然
后打上序号,考虑并列情况并且跳跃排名,对此我们需要增添一组数据。
INSERT INTO Employees (Name, DepartmentID, Salary) VALUES('css',1,45000);
select *,rank() over (partition by DepartmentID order by Salary desc ) total
from employees;
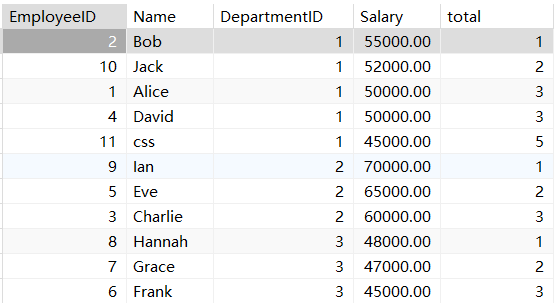
dense_rank()函数:
select *,dense_rank() over (partition by DepartmentID order by Salary desc ) total
from employees;
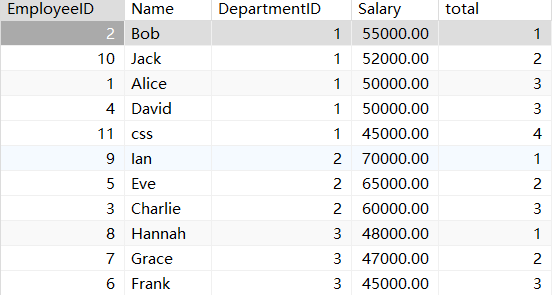
1.3. 跨行函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认
值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
select *,lag(Salary,1) over (partition by DepartmentID order by Salary desc ) total
from employees;
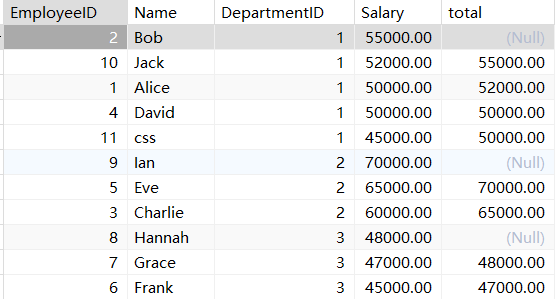
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认
值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
select *,lead(Salary,1) over (partition by DepartmentID order by Salary desc ) total
from employees;
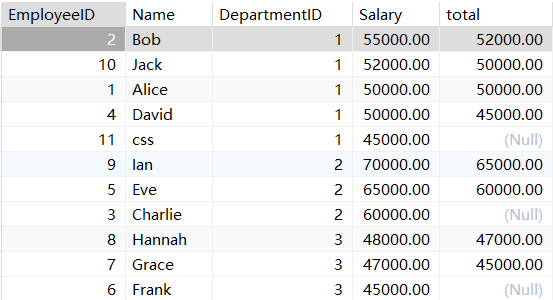
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值;
select *,first_value(Salary) over (partition by DepartmentID order by Salary desc ) total
from employees;
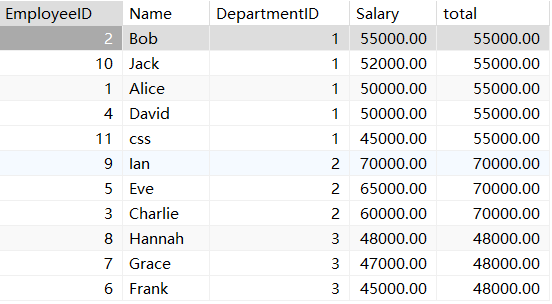
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值;
select *,last_value(Salary) over (partition by DepartmentID order by Salary desc ) total
from employees;
从这个数据我们有个疑问,为啥不是去分组内的最后一个值呢?
在这里我给大家解释一下,对于我们分的窗口(比如部门id=1)里面还有个小窗口
row函数
对于我们没有指定小窗口默认是当之前所有行到当前行,这样理解可以很抽象,我们
举个例子。对于部门id=1来说,我们从第一行来看(心里默念从之前所有行到当前
行)从之前所有行到当前行来看确实输出的值应该是55000.00,那么我们看第二行
(心里默念从之前所有行到当前行)那么确实输出的是52000.00。这样我们通过row
函数来改变一下小窗口的范围。更清晰的感受一下这个函数。
select *,last_value(Salary) over (partition by DepartmentID order by Salary descrows between unbounded preceding and unbounded following ) total
from employees;解释一下设置小窗口的含义:rows between unbounded preceding and
unbounded following
之前所有的行到之后所有的行,那么让我们输出一下。
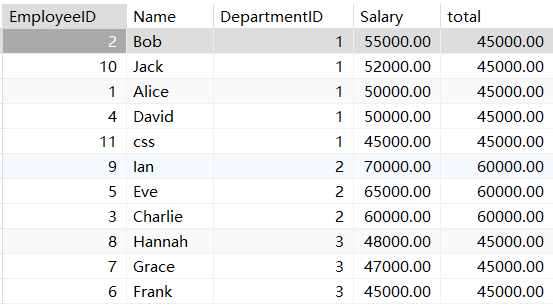
我们可以很清晰的看出来,输出的是每一组里面最后一个的薪资。
2. OVER [PARTITION BY <...>]
over是窗口函数的标志,partition by 用来指定分组,把partition by 后面跟的字段
相同的放在一起
3. [ORDER BY <....>]
用于指定每个分组内的数据排序规则 支持ASC、DESC, 跟group by 中的order by
是一样的用法
4. [window_expression]
用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
窗口子句操作的数据范围:
- 起始行:N preceding/unbounded preceding
- 当前行:currentrow
- 终止行:N following/unbounded following
举例:
- rows between unbounded preceding and current row
从之前所有的行到当前行
- rows between 2 preceding and current row
从前面两行到当前行
- rows between current row and unbounded following
从当前行到之后所有的行
- rows between current row and 1following
从当前行到后面一行
注意:
排序子句后面缺少窗口子句,窗口规范默认是
rows between unbounded preceding and current row
排序子句和窗口子句都缺失,窗口规范默认是
rows between unbounded preceding and unbounded following
总体流程:
- 通过partition by和 order by 子句确定大窗口(定义出上界unbounded preceding和下界unbounded following)
- 通过row 子句针对每一行数据确定小窗口(滑动窗口)
- 对每行的小窗口内的数据执行函数并生成新的列
四、练习题
1. 建库建表语句
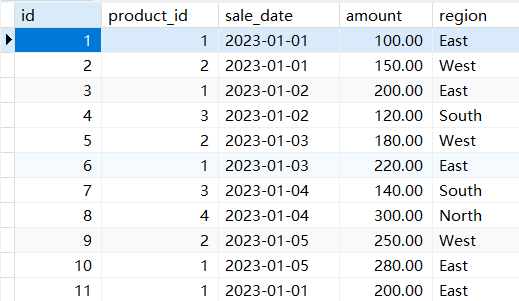
CREATE DATABASE IF NOT EXISTS sales_db;
USE sales_db;CREATE TABLE IF NOT EXISTS sales (id INT AUTO_INCREMENT PRIMARY KEY,product_id INT comment '商品id',sale_date DATE comment '销售日期',amount DECIMAL(10, 2)comment '销售额',region VARCHAR(50) comment '地区'
)comment '销售';-- 插入一些示例数据
INSERT INTO sales (product_id, sale_date, amount, region) VALUES
(1, '2023-01-01', 100.00, 'East'),
(2, '2023-01-01', 150.00, 'West'),
(1, '2023-01-02', 200.00, 'East'),
(3, '2023-01-02', 120.00, 'South'),
(2, '2023-01-03', 180.00, 'West'),
(1, '2023-01-03', 220.00, 'East'),
(3, '2023-01-04', 140.00, 'South'),
(4, '2023-01-04', 300.00, 'North'),
(2, '2023-01-05', 250.00, 'West'),
(1, '2023-01-05', 280.00, 'East');
insert into sales(product_id, sale_date, amount, region) values
(1,'2023-01-01',200.00,'East');
2. 题目
- 计算每日销售额总和(分区按日期)
- 计算每个区域的总销售额
- 为每个产品计算其销售排名(按销售额降序)
- 计算每个区域每天的平均销售额
- 计算每个产品的销售累计总额
- 计算每个区域每个产品的销售总额
- 计算每个区域最近7天的平均销售额
- 为每个产品的销售记录添加序列号(按日期排序)
- 计算每个区域每天相对于前一天的销售额变化
- 计算每个产品的销售占比(销售额/总销售额)
自己可以先把这些最基础的窗口函数做完之后,再看下面的解析
3. 答案解析
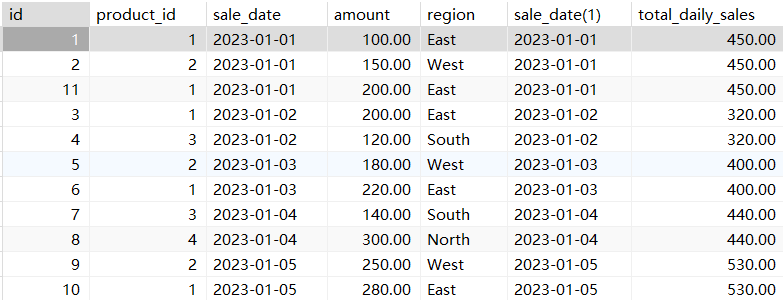
计算每日销售额总和(分区按日期)
# 计算每日销售额总和(分区按日期)
SELECT *,sale_date, SUM(amount) OVER (PARTITION BY sale_date order by sale_date) AS total_daily_sales
FROM sales;
计算每个区域的总销售额
# 计算每个区域的总销售额
SELECT region, SUM(amount) OVER (PARTITION BY region) AS total_regional_sales
FROM sales;
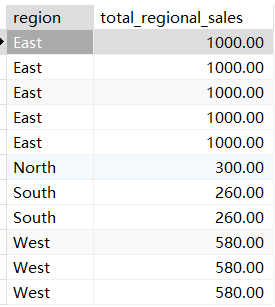
为每个产品计算其销售排名(按销售额降序)
# 为每个产品计算其销售排名(按销售额降序)
select product_id,rank() over (order by sum(amount) desc )as '销售排名' from sales group by product_id ;
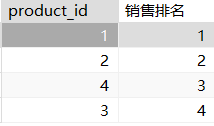
计算每个区域每天的平均销售额
# 计算每个区域每天的平均销售额
select *,avg(amount)over (partition by region,sale_date rows between unbounded preceding and unbounded following) from sales;
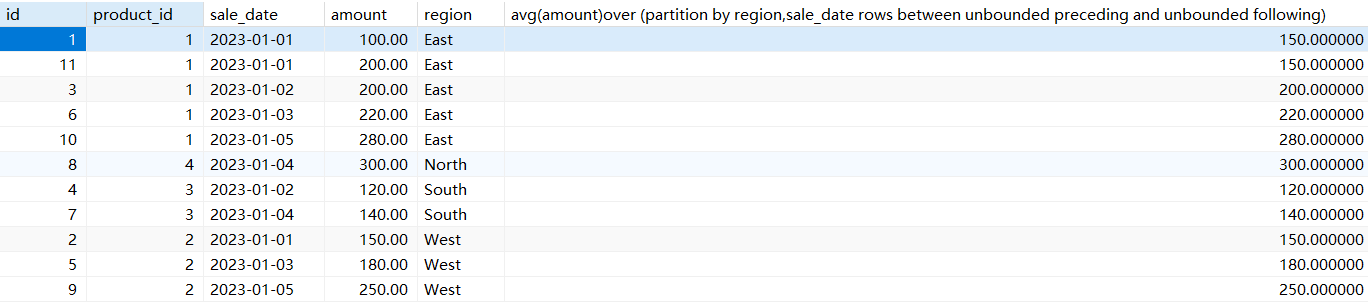
计算每个产品的销售累计总额
# 计算每个产品的销售累计总额
select *,sum(amount)over (partition by product_id) from sales;
计算每个区域每个产品的销售总额
# 计算每个区域每个产品的销售总额
select *,sum(amount)over (partition by product_id,region)from sales;
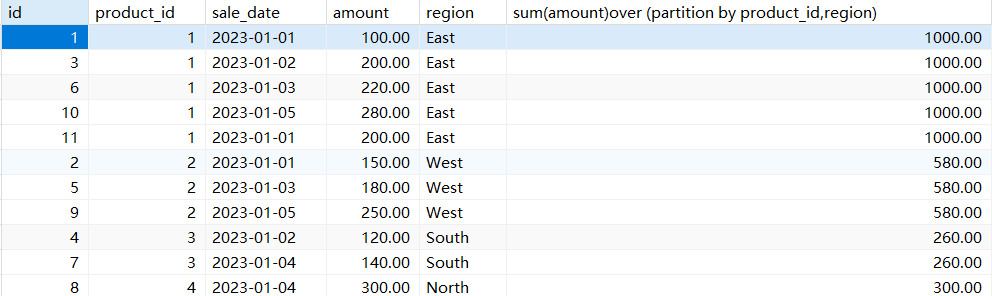
计算每个区域最近7天的平均销售额
# 计算每个区域最近7天的平均销售额
with t1 as ( select *,dense_rank() over(partition by region order by sale_date)as ttime from sales )
select *,avg(amount)over(partition by region) from t1 where ttime<7;
;
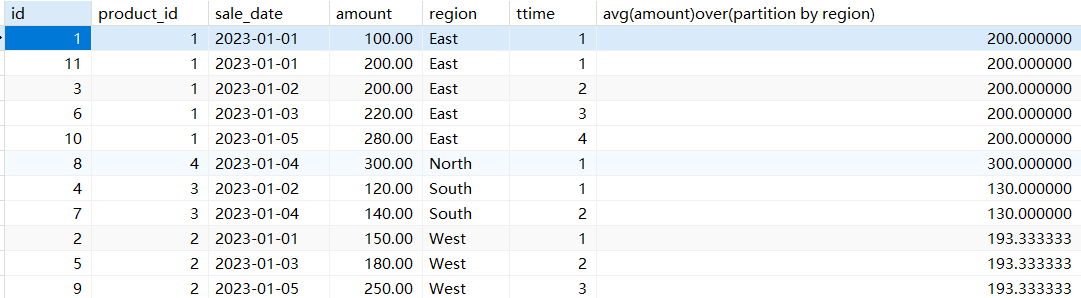
为每个产品的销售记录添加序列号(按日期排序)
# 为每个产品的销售记录添加序列号(按日期排序)
select *,dense_rank() over (partition by product_id order by sale_date)from sales;
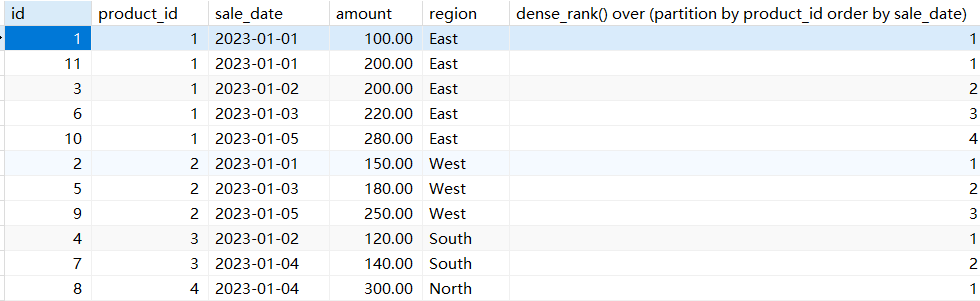
计算每个区域每天相对于前一天的销售额变化
# 计算每个区域每天相对于前一天的销售额变化
SELECTa.sale_date,a.region,a.amount,a.amount - LAG(a.amount) OVER (PARTITION BY a.region ORDER BY a.sale_date) AS daily_change
FROM sales a;
计算每个产品的销售占比(按总销售额)
# 计算每个产品的销售占比(按总销售额)
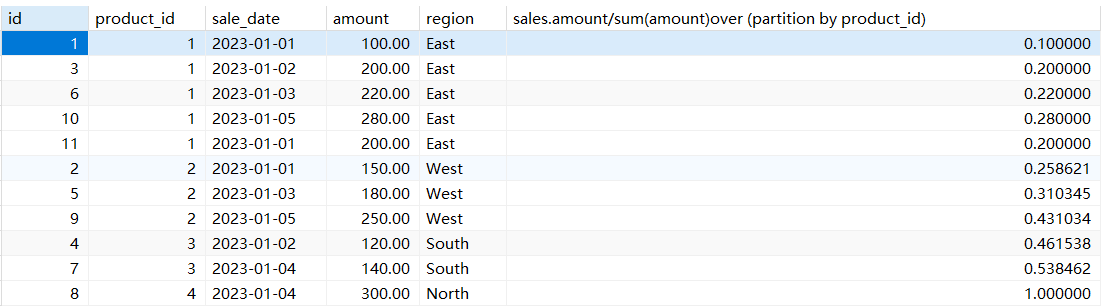
select *,sales.amount/sum(amount)over (partition by product_id)from sales;
讲解二:公用表达式(CTE)
一、简介
官网:MySQL :: MySQL 8.0 Reference Manual :: 15.2.20 WITH (Common Table Expressions)
MySQL 从 8.0 开始支持 WITH 语法,即:Common Table Expressions - CTE,公用表表达式。
CTE 是一个命名的临时结果集合,仅在单个 SQL 语句(select、insert、update 或 delete)的执行范
围内存在。
与派生表类似的是:CTE 不作为对象存储,仅在查询执行期间持续。
与派生表不同的是:CTE 可以是自引用(递归CTE),也可以在同一查询中多次引用。
此外,与派生表相比,CTE 提供了更好的可读性和性能。
二、语法
CTE 的结构包括:名称、可选列列表和定义 CTE 的查询。
定义 CTE 后,可以像 select、insert、update、delete 或 create view 语句中的视图一样使用它。
with cte_name (column_list) as (query)
select * from cte_name;查询中的列数必须与 column_list 中的列数相同。
如果省略 column_list,CTE 将使用定义 CTE 的查询的列列表。
三、示例
初始化数据:
-- create table
create table department
(id bigint auto_increment comment '主键ID'primary key,dept_name varchar(32) not null comment '部门名称',parent_id bigint default 0 not null comment '父级id'
);-- insert values
insert into `department` values (null, '总部', 0);
insert into `department` values (null, '研发部', 1);
insert into `department` values (null, '测试部', 1);
insert into `department` values (null, '产品部', 1);
insert into `department` values (null, 'Java组', 2);
insert into `department` values (null, 'Python组', 2);
insert into `department` values (null, '前端组', 2);
insert into `department` values (null, '供应链测试组', 3);
insert into `department` values (null, '商城测试组', 3);
insert into `department` values (null, '供应链产品组', 4);
insert into `department` values (null, '商城产品组', 4);
insert into `department` values (null, 'Java1组', 5);
insert into `department` values (null, 'Java2组', 5);(1)最基本的CTE语法
mysql> with cte1 as (select * from `department` where id in (1, 2)),-> cte2 as (select * from `department` where id in (2, 3))-> select *-> from cte1-> join cte2-> where cte1.id = cte2.id;
+----+-----------+-----------+----+-----------+-----------+
| id | dept_name | parent_id | id | dept_name | parent_id |
+----+-----------+-----------+----+-----------+-----------+
| 2 | 研发部 | 1 | 2 | 研发部 | 1 |
+----+-----------+-----------+----+-----------+-----------+
1 row in set (0.00 sec)(2)一个 CTE 引用另一个 CTE
mysql> with cte1 as (select * from `department` where id = 1),-> cte2 as (select * from cte1)-> select *-> from cte2;
+----+-----------+-----------+
| id | dept_name | parent_id |
+----+-----------+-----------+
| 1 | 总部 | 0 |
+----+-----------+-----------+
1 row in set (0.00 sec)四、递归 CTE
1. 简介
递归 CTE 是一个具有引用 CTE 名称本身的子查询的 CTE。递归 CTE 的语法为:
with recursive cte_name as (initial_query -- anchor member
union all
recursive_query -- recursive member that references to the cte name
)
select * from cte_name;递归 CTE 由三个主要部分组成:
- 形成 CTE 结构的基本结果集的初始查询(initial_query),初始查询部分被称为锚成员。
- 递归查询部分是引用 CTE 名称的查询,因此称为递归成员。递归成员由一个 union all 或 union distinct 运算符与锚成员相连。
- 终止条件是当递归成员没有返回任何行时,确保递归停止。
递归 CTE 的执行顺序如下:
- 首先,将成员分为两个:锚点和递归成员。
- 接下来,执行锚成员形成基本结果集(R0),并使用该基本结果集进行下一次迭代。
- 然后,将 Ri 结果集作为输入执行递归成员,并将 Ri + 1 作为输出。
- 之后,重复第三步,直到递归成员返回一个空结果集,换句话说,满足终止条件。
- 最后,使用 union all 运算符将结果集从 R0 到 Rn 组合。
2. 递归成员限制
递归成功不能包含以下结构:
- 聚合函数,如 max、min、sum、avg、count 等。
- group by 子句
- order by 子句
- limit 子句
- distinct
上述约束不适用于锚点成员。 另外,只有在使用 union 运算符时,要禁止 distinct 才适用。
如果使用 union distinct 运算符,则允许使用 distinct。
另外,递归成员只能在其子句中引用 CTE 名称,而不是引用任何子查询。
3. 示例
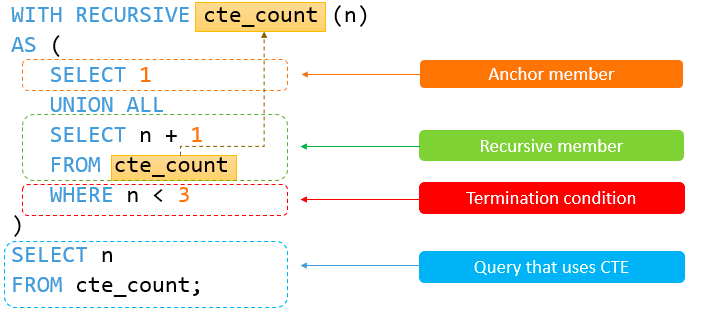
with recursive cte_count (n)as (select 1union allselect n + 1from cte_countwhere n < 3)
select n from cte_count; 在此示例中,以下查询:
select 1是作为基本结果集返回 1 的锚成员。
以下查询:
select n + 1
from cte_count
where n < 3是递归成员,因为它引用了 cte_count 的 CTE 名称。递归成员中的表达式 < 3 是终止条件。
当 n 等于 3,递归成员将返回一个空集合,将停止递归。
下图显示了上述 CTE 的元素:

递归 CTE 返回以下输出:
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
+------+递归 CTE 的执行步骤如下:
- 首先,分离锚和递归成员。
- 接下来,锚定成员形成初始行 select 1,因此第一次迭代在 n = 1 时产生 1 + 1 = 2。
- 然后,第二次迭代对第一次迭代的输出 2 进行操作,并且在 n = 2 时产生 2 + 1 = 3。
- 之后,在第三次操作 n = 3 之前,满足终止条件 n <3 ,因此查询停止。
- 最后,使用 union all 运算符组合所有结果集 1,2 和 3。
4. 使用递归 CTE 遍历分层数据
查部门 id = 2 的所有下级部门和本级:
mysql> with recursive cte_tab as (select id, dept_name, parent_id, 1 as level-> from department-> where id = 2-> union all-> select d.id, d.dept_name, d.parent_id, level + 1-> from cte_tab c-> inner join department d on c.id = d.parent_id-> )-> select *-> from cte_tab;
+------+-----------+-----------+-------+
| id | dept_name | parent_id | level |
+------+-----------+-----------+-------+
| 2 | 研发部 | 1 | 1 |
| 5 | Java组 | 2 | 2 |
| 6 | Python组 | 2 | 2 |
| 7 | 前端组 | 2 | 2 |
| 12 | Java1组 | 5 | 3 |
| 13 | Java2组 | 5 | 3 |
+------+-----------+-----------+-------+
6 rows in set (0.00 sec)五、CTE 与 Derived Table
针对 from 子句里面的 subquery,MySQL 在不同版本中,是做过一系列的优化,接下来我们就来看看。
1. 在 5.6 版本中
MySQL 会对每一个 Derived Table 进行物化,生成一个临时表保存 Derived Table 的结果,然后利用临时表来完
成父查询的操作,具体如下:
mysql> explain-> select * from (select * from department where id <= 1000) t1 join (select * from department where id >= 990) t2 on t1.id = t2.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1 | 100.00 | Using where |
| 1 | SIMPLE | department | NULL | eq_ref | PRIMARY | PRIMARY | 8 | pointer_mall.department.id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)2. 在 5.7 版本中
MySQL 引入了 Derived Merge 新特性,允许符合条件的 Derived Table 中的子表与父查询的表进行合并,具体如下:
mysql> explain-> select * from (select * from department where id <= 1000) t1 join (select * from department where id >= 990) t2 on t1.id = t2.id;
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1900 | 100.00 | NULL |
| 1 | PRIMARY | <derived3> | NULL | ref | <auto_key0> | <auto_key0> | 8 | t1.id | 2563 | 100.00 | NULL |
| 3 | DERIVED | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 4870486 | 100.00 | Using where |
| 2 | DERIVED | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1900 | 100.00 | Using where |
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
4 rows in set, 1 warning (0.00 sec)3. 在 8.0 版本中
我们可以使用 CTE 实现,其执行计划也是和 Derived Table 一样
mysql> explain-> with t1 as (select * from department where id <= 1000),-> t2 as (select * from department where id >= 990)-> select * from t1 join t2 on t1.id = t2.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1 | 100.00 | Using where |
| 1 | SIMPLE | department | NULL | eq_ref | PRIMARY | PRIMARY | 8 | pointer_mall.department.id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)从测试结果来看,CTE 似乎是 Derived Table 的一个替代品?
其实不是的,虽然 CTE 内部优化流程与 Derived Table 类似,但是两者还是区别的,具体如下:
- 一个 CTE 可以引用另一个 CTE
- CTE 可以自引用
- CTE 在语句级别生成临时表,多次调用只需要执行一次,提高性能
从上面介绍可以知道,CTE 一方面可以非常方便进行 SQL 开发,另一方面也可以提升 SQL 执行效率。
相关文章:
MySQL篇(窗口函数/公用表达式(CTE))
目录 讲解一:窗口函数 一、简介 二、常见操作 1. sumgroup by常规的聚合函数操作 2. sum窗口函数的聚合操作 三、基本语法 1. Function(arg1,..., argn) 1.1. 聚合函数 sum函数:求和 min函数 :最小值 1.2. 排序函数 1.3. 跨行函数…...

408算法题leetcode--第七天
283. 移动零 283. 移动零思路:代码中注释阐述时间:O(n);空间:O(1) class Solution { public:void moveZeroes(vector<int>& nums) {// 简单思路:用一个辅助数组,将非0元素复制到里面// 双指针&…...

政务安全体系构建中的挑战
在数字化政务安全体系的构建过程中,面临着几个关键的挑战: ▋挑战一:安全防护滞后现代网络攻击技术不断演进,攻击手段日益多样化,如高级持续性威胁(APT)和勒索软件等新型攻击方式频繁出现。这些…...

基于EchoMimic加速版,可编辑标志点控制实现逼真音频驱动的肖像动画
EchoMimic 是蚂蚁集团终端技术部门开发的一项技术,旨在通过音频驱动生成逼真的肖像动画。对于那些初次接触这项技术的用户,本教程将带你逐步了解如何设置开发环境、获取项目代码、安装依赖,并最终成功运行示例生成自己的肖像动画。 文章目录 项目代码安装依赖业务拓展参数调…...

【STM32 HAL库】IIC通信与CubeMX配置
【STM32 HAL库】IIC通信与CubeMX配置 前言理论IIC总线时序图IIC写数据IIC读数据 轮询模式CubeMX配置应用示例AHT20初始化初始化函数读取说明读取函数 中断模式CubeMX配置状态机图fsm.caht20.c DMA模式CubeMX配置代码 前言 本文为笔者学习 IIC 通信的总结,基于keysk…...

iPhone 上丢失了重要的联系人?如何恢复已删除的 iPhone 联系人
丢失 iPhone 上的联系人可能会带来灾难。无论是一份很棒的新工作机会、潜在的恋爱对象,还是您一直想打电话的老朋友,如果您打开“联系人”应用时看到空白,这绝不是好事。不过,一切并非全无,仍然可以通过备份或专业软件…...

【有啥问啥】弱监督学习新突破:格灵深瞳多标签聚类辨别(Multi-Label Clustering and Discrimination, MLCD)方法
弱监督学习新突破:格灵深瞳多标签聚类辨别(Multi-Label Clustering and Discrimination, MLCD)方法 引言 在视觉大模型领域,如何有效利用海量无标签图像数据是一个亟待解决的问题。传统的深度学习模型依赖大量人工标注数据&…...

[强化你的LangChain工具创建技能:从基础到进阶]
强化你的LangChain工具创建技能:从基础到进阶 在现代AI开发中,为语言模型和智能代理提供工具是提升其功能的关键一步。本指南将带你深入了解如何在LangChain中创建工具,从简单的函数到复杂的可配置工具。 引言 在构建智能代理时࿰…...

4.提升客户服务体验:ChatGPT在客服中的应用(4/10)
本文大纲旨在指导撰写一篇全面探讨ChatGPT如何通过优化客户服务流程、提供实际应用案例和用户反馈,以提升客户服务体验的深入博客文章。 引言 在当今竞争激烈的商业环境中,客户服务已成为企业成功的关键因素。优质的客户服务不仅能够增强客户满意度和忠…...
Gradio导入AIGC大模型创建web端智能体聊天机器人,python(2)
Gradio导入AIGC大模型创建web端智能体聊天机器人,python(2) 选用这个大模型: https://huggingface.co/HuggingFaceTB/SmolLM-1.7B-Instructhttps://huggingface.co/HuggingFaceTB/SmolLM-1.7B-Instruct原因是该模型相对比较小&am…...

PEM 格式
文章目录 1.简介2.格式和内容3.常见用途4.标准化5.示例参考文献 1.简介 .pem 文件扩展名代表“Privacy Enhanced Mail”,但它被用于比电子邮件更广泛的上下文中,主要关联于加密、SSL/TLS 和证书管理。PEM 格式是一种用于存储和发送加密信息的标准&#…...

Android前台服务如何在后台启动activity?
本来最近在开发一个app保活另外一个app的功能,方案介绍如下: 应用A 启动一个前台服务保活自己应用A 用grpc连接应用B(服务端)是否存活如果发现B不存活,则在服务中拉起B 这次没有做好调研,直接开始了开发工作,等grpc都…...

c#visionpro开发 方法统计
toolblock开发 vpp第二种简单加载方式 public Cognex.VisionPro.ToolBlock.CogToolBlock ToolBlock1;//初始化后实例化一个方法 //窗口运行程序内部 ToolBlock1 (CogToolBlock)CogSerializer.LoadObjectFromFile(“tjjc.vpp”); MessageBox.Show(“算法加载成功”);//复制一个…...

dedecms——四种webshell姿势
姿势一:通过文件管理器上传WebShell 步骤一:访问目标靶场其思路为 dedecms 后台可以直接上传任意文件,可以通过文件管理器上传php文件获取webshell 步骤二:登陆到后台点击【核心】--》 【文件式管理器】--》 【文件上传】将准备好…...

GO GIN 推荐的库
在使用 Go 和 Gin 框架进行 Web 开发时,有许多第三方库可以增强功能和提高开发效率。以下是一些常用的、与 Gin 搭配使用的库: 1. 数据处理与验证 go-playground/validator 用于结构体字段的验证,Gin 默认已经集成了它。它提供了丰富的验证…...

YOLOv9改进策略【卷积层】| GnConv:一种通过门控卷积和递归设计来实现高效、可扩展、平移等变的高阶空间交互操作
一、本文介绍 本文记录的是利用GnConv优化YOLOv9的目标检测方法研究。YOLOv9在进行目标检测时,需要对不同层次的特征进行融合。GnConv可以考虑更高阶的空间交互,能够更好地捕捉特征之间的复杂关系,从而增强特征融合的效果,提高模…...

如何在Linux下升级R版本和RStudio
一、升级R版本 在Linux上,R的安装通常通过包管理器完成。不同的Linux发行版(如Ubuntu、Debian、Fedora等)可能略有不同。下面以Ubuntu为例,介绍如何升级R版本。如果你使用其他发行版,步骤可能类似。 二.更新步骤 2.…...

npm安装时候报错certificate has expired
打开了一个很久没用的电脑,npm和node都装好了,安装包的时候一直报错 request to https://registry.npm.taobao.org/create-react-app failed, reason: certificate has expired而且先报错rollbackFailedOptional 然而npm没什么问题,是ssl过…...

CSP-J_S第一轮复习资料1·计算机硬件
下一章...

oracle 表的外键
表的外键 3.5.1表之间的三种关系 在数据库设计中,工作中经常会分析商业逻辑中的表的设计。在设计表的关系之前,需要先了解关系型数据库特点。关系数据库有如下特点: 关系型数据库采用了关系模型来组织数据的数据库。 关系型数据库的最大特点…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...