面试真题-TCP的三次握手
TCP的基础知识
TCP头部

面试题:TCP的头部是多大?
TCP(传输控制协议)的头部通常是固定的20个字节长,但是根据TCP选项(Options)的不同,这个长度可以扩展。TCP头部包含了许多关键的字段,如源端口号(Source Port)、目的端口号(Destination Port)、序列号(Sequence Number)、确认号(Acknowledgment Number)、数据偏移量(Data Offset,也称为头部长度)、保留位(Reserved)、控制位(Control Bits,包括URG、ACK、PSH、RST、SYN、FIN)、窗口大小(Window Size)、校验和(Checksum)、紧急指针(Urgent Pointer)以及选项(Options)和填充(Padding)。
标准的TCP头部是20个字节,但是如果TCP头部中包含选项(Options),那么TCP头部的长度就会增加。选项字段是可选的,长度可变,以32位(即4字节)为单位增加。每个选项的开始是1字节的kind字段,用来指示选项的类型,后面跟着的是长度(Length)字段,指明整个选项(包括kind和length字段)的字节数。选项字段的存在允许TCP头部扩展到最大60字节(包含基本的20字节),这是因为数据偏移量(Data Offset)字段是4位的,可以表示的最大值是15,乘以4(因为TCP头部是以32位字为单位的)就是60字节。
因此,TCP头部的长度至少是20字节,最多可以达到60字节,具体取决于是否包含选项以及选项的长度。
序列号:在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。
确认应答号:指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。
控制位:
- ACK:该位为
1时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的SYN包之外该位必须设置为1。 - RST:该位为
1时,表示 TCP 连接中出现异常必须强制断开连接。 - SYN:该位为
1时,表示希望建立连接,并在其「序列号」的字段进行序列号初始值的设定。 - FIN:该位为
1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位为 1 的 TCP 段。
网络模型(左边是TCP/IP,右边是OSI)

什么是 TCP ?
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。

-
面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
-
可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
-
字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。
什么是 TCP 连接?
我们来看看 RFC 793 是如何定义「连接」的:
Connections: The reliability and flow control mechanisms described above require that TCPs initialize and maintain certain status information for each data stream. The combination of this information, including sockets, sequence numbers, and window sizes, is called a connection.
简单来说就是,用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括 Socket、序列号和窗口大小称为连接。

所以我们可以知道,建立一个 TCP 连接是需要客户端与服务端达成上述三个信息的共识。
- Socket:由 IP 地址和端口号组成
- 序列号:用来解决乱序问题等
- 窗口大小:用来做流量控制
如何唯一确定一个 TCP 连接呢?
TCP 四元组可以唯一的确定一个连接,四元组包括如下:
- 源地址
- 源端口
- 目的地址
- 目的端口

源地址和目的地址的字段(32 位)是在 IP 头部中,作用是通过 IP 协议发送报文给对方主机。
源端口和目的端口的字段(16 位)是在 TCP 头部中,作用是告诉 TCP 协议应该把报文发给哪个进程。
有一个 IP 的服务端监听了一个端口,它的 TCP 的最大连接数是多少?
服务端通常固定在某个本地端口上监听,等待客户端的连接请求。
因此,客户端 IP 和端口是可变的,其理论值计算公式如下:
![]()
对 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数,约为 2 的 48 次方。
当然,服务端最大并发 TCP 连接数远不能达到理论上限,会受以下因素影响:
- 文件描述符限制,每个 TCP 连接都是一个文件,如果文件描述符被占满了,会发生 Too many open files。Linux 对可打开的文件描述符的数量分别作了三个方面的限制:
- 系统级:当前系统可打开的最大数量,通过
cat /proc/sys/fs/file-max查看; - 用户级:指定用户可打开的最大数量,通过
cat /etc/security/limits.conf查看; - 进程级:单个进程可打开的最大数量,通过
cat /proc/sys/fs/nr_open查看;
- 系统级:当前系统可打开的最大数量,通过
- 内存限制,每个 TCP 连接都要占用一定内存,操作系统的内存是有限的,如果内存资源被占满后,会发生 OOM。
UDP 和 TCP 有什么区别呢?分别的应用场景是?
UDP 不提供复杂的控制机制,利用 IP 提供面向「无连接」的通信服务。
UDP 协议真的非常简,头部只有 8 个字节(64 位),UDP 的头部格式如下:

- 目标和源端口:主要是告诉 UDP 协议应该把报文发给哪个进程。
- 包长度:该字段保存了 UDP 首部的长度跟数据的长度之和。
- 校验和:校验和是为了提供可靠的 UDP 首部和数据而设计,防止收到在网络传输中受损的 UDP 包。
TCP 和 UDP 区别:
1. 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
2. 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
3. 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议.
4. 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5. 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
20个字节,如果使用了「选项」字段则会变长的。 - UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
6. 传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠。
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7. 分片不同
- TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
- UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP文件传输;- HTTP / HTTPS;
由于 UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,因此经常用于:
- 包总量较少的通信,如
DNS、SNMP等; - 视频、音频等多媒体通信;
- 广播通信;
为什么 UDP 头部没有「首部长度」字段,而 TCP 头部有「首部长度」字段呢?
原因是 TCP 有可变长的「选项」字段,而 UDP 头部长度则是不会变化的,无需多一个字段去记录 UDP 的首部长度。
在TCP头部中,实际上并没有直接标记为“首部长度”的字段,但有一个非常接近的字段叫做“数据偏移量”(Data Offset)或“头部长度”(Header Length)。这个字段占4位(即半个字节),用于指示TCP头部(包括选项)的长度,以32位字(即4字节)为单位。
由于TCP头部是以32位(4字节)为单位的,因此数据偏移量的值实际上是指TCP头部长度(包括选项)除以4的结果。数据偏移量的最小值是5,表示TCP头部长度为最基本的20字节(5 * 4 = 20)。如果TCP头部包含了选项,那么数据偏移量的值会增加,以反映额外的头部长度。
需要注意的是,虽然这个字段在TCP协议中被称为“数据偏移量”,但它实际上更准确地表示了TCP头部的长度。这个命名可能与TCP协议设计时的某些考虑有关,但在现代网络编程和TCP协议分析的上下文中,它通常被理解为表示TCP头部的长度。
因此,当你看到TCP头部的“数据偏移量”字段时,你应该知道它实际上是在告诉你TCP头部的长度(以32位字为单位)。如果你需要将这个值转换为字节,你需要将数据偏移量的值乘以4。
为什么 UDP 头部有「包长度」字段,而 TCP 头部则没有「包长度」字段呢?
先说说 TCP 是如何计算负载数据长度:

其中 IP 总长度 和 IP 首部长度,在 IP 首部格式是已知的。TCP 首部长度,则是在 TCP 首部格式已知的,所以就可以求得 TCP 数据的长度。
大家这时就奇怪了问:“UDP 也是基于 IP 层的呀,那 UDP 的数据长度也可以通过这个公式计算呀? 为何还要有「包长度」呢?”
这么一问,确实感觉 UDP 的「包长度」是冗余的。
我查阅了很多资料,我觉得有两个比较靠谱的说法:
- 第一种说法:因为为了网络设备硬件设计和处理方便,首部长度需要是
4字节的整数倍。如果去掉 UDP 的「包长度」字段,那 UDP 首部长度就不是4字节的整数倍了,所以我觉得这可能是为了补全 UDP 首部长度是4字节的整数倍,才补充了「包长度」字段。 - 第二种说法:如今的 UDP 协议是基于 IP 协议发展的,而当年可能并非如此,依赖的可能是别的不提供自身报文长度或首部长度的网络层协议,因此 UDP 报文首部需要有长度字段以供计算。
TCP 和 UDP 可以使用同一个端口吗?
答案:可以的。
在数据链路层中,通过 MAC 地址来寻找局域网中的主机。在网际层中,通过 IP 地址来寻找网络中互连的主机或路由器。在传输层中,需要通过端口进行寻址,来识别同一计算机中同时通信的不同应用程序。
所以,传输层的「端口号」的作用,是为了区分同一个主机上不同应用程序的数据包。
传输层有两个传输协议分别是 TCP 和 UDP,在内核中是两个完全独立的软件模块。
当主机收到数据包后,可以在 IP 包头的「协议号」字段知道该数据包是 TCP/UDP,所以可以根据这个信息确定送给哪个模块(TCP/UDP)处理,送给 TCP/UDP 模块的报文根据「端口号」确定送给哪个应用程序处理。
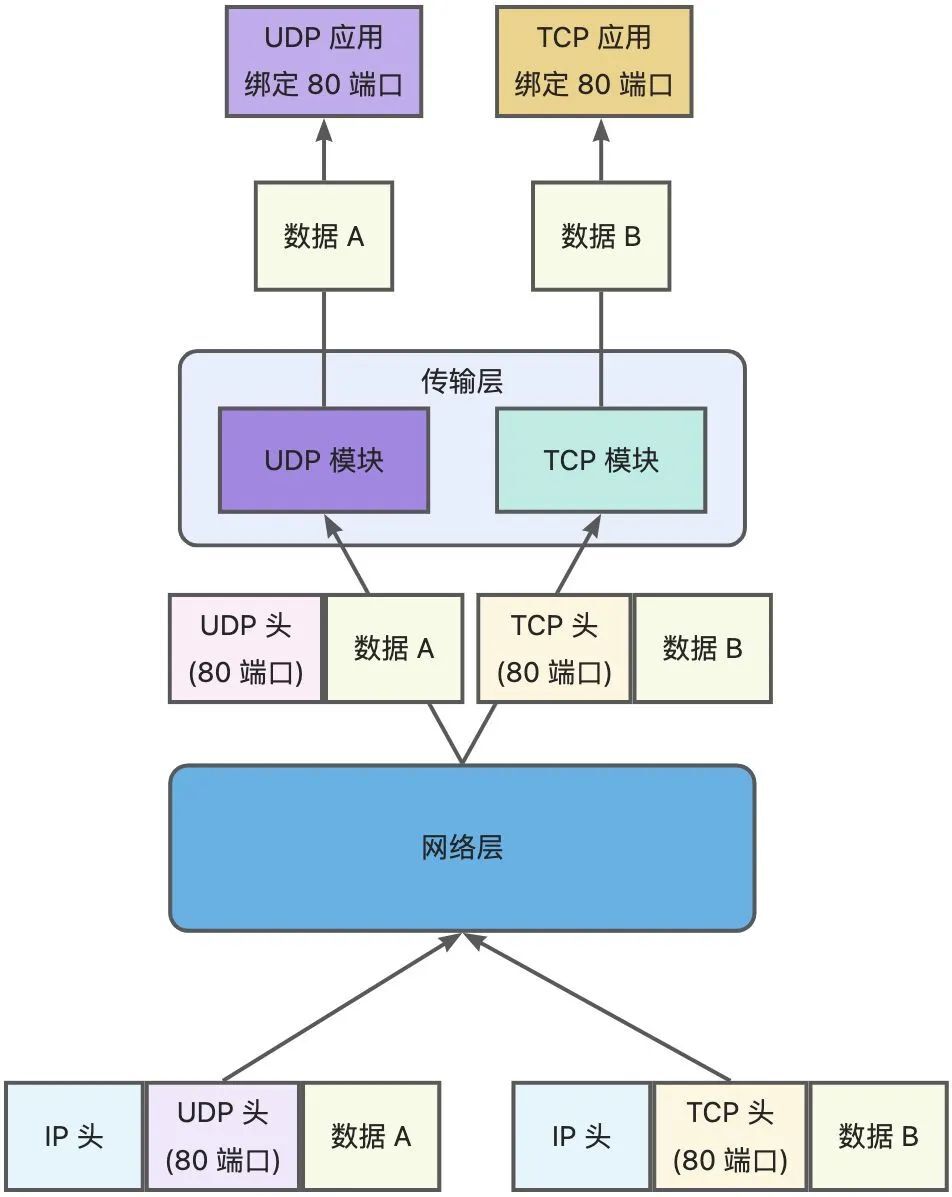
因此,TCP/UDP 各自的端口号也相互独立,如 TCP 有一个 80 号端口,UDP 也可以有一个 80 号端口,二者并不冲突。
关于端口的知识点,还是挺多可以讲的,比如还可以牵扯到这几个问题:
- 多个 TCP 服务进程可以同时绑定同一个端口吗?
- 重启 TCP 服务进程时,为什么会出现“Address in use”的报错信息?又该怎么避免?
- 客户端的端口可以重复使用吗?
- 客户端 TCP 连接 TIME_WAIT 状态过多,会导致端口资源耗尽而无法建立新的连接吗?
TCP 连接建立
TCP 三次握手过程是怎样的?
TCP 是面向连接的协议,所以使用 TCP 前必须先建立连接,而建立连接是通过三次握手来进行的。三次握手的过程如下图:
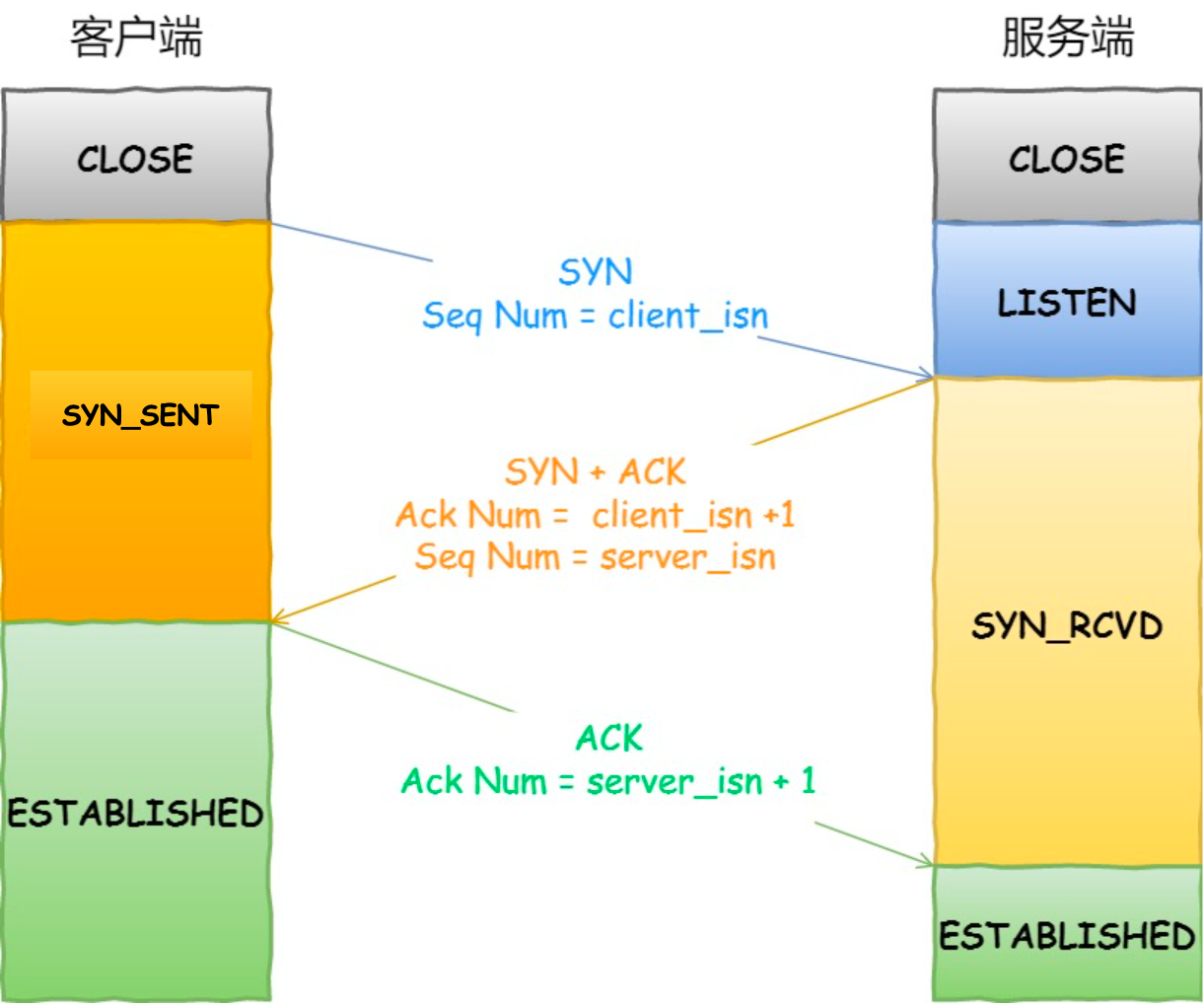
- 一开始,客户端和服务端都处于
CLOSE状态。先是服务端主动监听某个端口,处于LISTEN状态

- 客户端会随机初始化序号(
client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把SYN标志位置为1,表示SYN报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于SYN-SENT状态。

- 服务端收到客户端的
SYN报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入client_isn + 1, 接着把SYN和ACK标志位置为1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于SYN-RCVD状态。

-
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部
ACK标志位置为1,其次「确认应答号」字段填入server_isn + 1,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于ESTABLISHED状态。 -
服务端收到客户端的应答报文后,也进入
ESTABLISHED状态。
从上面的过程可以发现第三次握手是可以携带数据的,前两次握手是不可以携带数据的,这也是面试常问的题。
一旦完成三次握手,双方都处于 ESTABLISHED 状态,此时连接就已建立完成,客户端和服务端就可以相互发送数据了。
如何在 Linux 系统中查看 TCP 状态?
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。

为什么是三次握手?不是两次、四次?
相信大家比较常回答的是:“因为三次握手才能保证双方具有接收和发送的能力。”
这回答是没问题,但这回答是片面的,并没有说出主要的原因。
在前面我们知道了什么是 TCP 连接:
- 用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括 Socket、序列号和窗口大小称为连接。
所以,重要的是为什么三次握手才可以初始化 Socket、序列号和窗口大小并建立 TCP 连接。
接下来,以三个方面分析三次握手的原因:
- 三次握手才可以阻止重复历史连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
原因一:避免历史连接
我们来看看 RFC 793 指出的 TCP 连接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
简单来说,三次握手的首要原因是为了防止旧的重复连接初始化造成混乱。
我们考虑一个场景,客户端先发送了 SYN(seq = 90)报文,然后客户端宕机了,而且这个 SYN 报文还被网络阻塞了,服务端并没有收到,接着客户端重启后,又重新向服务端建立连接,发送了 SYN(seq = 100)报文(注意!不是重传 SYN,重传的 SYN 的序列号是一样的)。
看看三次握手是如何阻止历史连接的:

客户端连续发送多次 SYN(都是同一个四元组)建立连接的报文,在网络拥堵情况下:
- 一个「旧 SYN 报文」比「最新的 SYN」 报文早到达了服务端,那么此时服务端就会回一个
SYN + ACK报文给客户端,此报文中的确认号是 91(90+1)。 - 客户端收到后,发现自己期望收到的确认号应该是 100 + 1,而不是 90 + 1,于是就会回 RST 报文。
- 服务端收到 RST 报文后,就会释放连接。
- 后续最新的 SYN 抵达了服务端后,客户端与服务端就可以正常的完成三次握手了。
上述中的「旧 SYN 报文」称为历史连接,TCP 使用三次握手建立连接的最主要原因就是防止「历史连接」初始化了连接。
TIP
有很多人问,如果服务端在收到 RST 报文之前,先收到了「新 SYN 报文」,也就是服务端收到客户端报文的顺序是:「旧 SYN 报文」->「新 SYN 报文」,此时会发生什么?
当服务端第一次收到 SYN 报文,也就是收到 「旧 SYN 报文」时,就会回复 SYN + ACK 报文给客户端,此报文中的确认号是 91(90+1)。
然后这时再收到「新 SYN 报文」时,就会回Challenge Ack报文给客户端,这个 ack 报文并不是确认收到「新 SYN 报文」的,而是上一次的 ack 确认号,也就是91(90+1)。所以客户端收到此 ACK 报文时,发现自己期望收到的确认号应该是 101,而不是 91,于是就会回 RST 报文。
如果是两次握手连接,就无法阻止历史连接,那为什么 TCP 两次握手为什么无法阻止历史连接呢?
我先直接说结论,主要是因为在两次握手的情况下,服务端没有中间状态给客户端来阻止历史连接,导致服务端可能建立一个历史连接,造成资源浪费。
你想想,在两次握手的情况下,服务端在收到 SYN 报文后,就进入 ESTABLISHED 状态,意味着这时可以给对方发送数据,但是客户端此时还没有进入 ESTABLISHED 状态,假设这次是历史连接,客户端判断到此次连接为历史连接,那么就会回 RST 报文来断开连接,而服务端在第一次握手的时候就进入 ESTABLISHED 状态,所以它可以发送数据的,但是它并不知道这个是历史连接,它只有在收到 RST 报文后,才会断开连接。

可以看到,如果采用两次握手建立 TCP 连接的场景下,服务端在向客户端发送数据前,并没有阻止掉历史连接,导致服务端建立了一个历史连接,又白白发送了数据,妥妥地浪费了服务端的资源。
因此,要解决这种现象,最好就是在服务端发送数据前,也就是建立连接之前,要阻止掉历史连接,这样就不会造成资源浪费,而要实现这个功能,就需要三次握手。
所以,TCP 使用三次握手建立连接的最主要原因是防止「历史连接」初始化了连接。
TIP
有人问:客户端发送三次握手(ack 报文)后就可以发送数据了,而被动方此时还是 syn_received 状态,如果 ack 丢了,那客户端发的数据是不是也白白浪费了?
不是的,即使服务端还是在 syn_received 状态,收到了客户端发送的数据,还是可以建立连接的,并且还可以正常收到这个数据包。这是因为数据报文中是有 ack 标识位,也有确认号,这个确认号就是确认收到了第二次握手。如下图:

所以,服务端收到这个数据报文,是可以正常建立连接的,然后就可以正常接收这个数据包了。
原因二:同步双方初始序列号
TCP 协议的通信双方, 都必须维护一个「序列号」, 序列号是可靠传输的一个关键因素,它的作用:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的(通过 ACK 报文中的序列号知道);
可见,序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 SYN 报文的时候,需要服务端回一个 ACK 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步。

四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。
而两次握手只保证了一方的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
原因三:避免资源浪费
如果只有「两次握手」,当客户端发生的 SYN 报文在网络中阻塞,客户端没有接收到 ACK 报文,就会重新发送 SYN ,由于没有第三次握手,服务端不清楚客户端是否收到了自己回复的 ACK 报文,所以服务端每收到一个 SYN 就只能先主动建立一个连接,这会造成什么情况呢?
如果客户端发送的 SYN 报文在网络中阻塞了,重复发送多次 SYN 报文,那么服务端在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。

即两次握手会造成消息滞留情况下,服务端重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
TIP
很多人问,两次握手不是也可以根据上下文信息丢弃 syn 历史报文吗?
我这里两次握手是假设「由于没有第三次握手,服务端不清楚客户端是否收到了自己发送的建立连接的 ACK 确认报文,所以每收到一个 SYN 就只能先主动建立一个连接」这个场景。
当然你要实现成类似三次握手那样,根据上下文丢弃 syn 历史报文也是可以的,两次握手没有具体的实现,怎么假设都行。
小结
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
不使用「两次握手」和「四次握手」的原因:
- 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
第一次握手丢失了,会发生什么?
当客户端想和服务端建立 TCP 连接的时候,首先第一个发的就是 SYN 报文,然后进入到 SYN_SENT 状态。
在这之后,如果客户端迟迟收不到服务端的 SYN-ACK 报文(第二次握手),就会触发「超时重传」机制,重传 SYN 报文,而且重传的 SYN 报文的序列号都是一样的。
不同版本的操作系统可能超时时间不同,有的 1 秒的,也有 3 秒的,这个超时时间是写死在内核里的,如果想要更改则需要重新编译内核,比较麻烦。
当客户端在 1 秒后没收到服务端的 SYN-ACK 报文后,客户端就会重发 SYN 报文,那到底重发几次呢?
在 Linux 里,客户端的 SYN 报文最大重传次数由 tcp_syn_retries内核参数控制,这个参数是可以自定义的,默认值一般是 5。
# cat /proc/sys/net/ipv4/tcp_syn_retries
5
通常,第一次超时重传是在 1 秒后,第二次超时重传是在 2 秒,第三次超时重传是在 4 秒后,第四次超时重传是在 8 秒后,第五次是在超时重传 16 秒后。没错,每次超时的时间是上一次的 2 倍。
当第五次超时重传后,会继续等待 32 秒,如果服务端仍然没有回应 ACK,客户端就不再发送 SYN 包,然后断开 TCP 连接。
所以,总耗时是 1+2+4+8+16+32=63 秒,大约 1 分钟左右。
举个例子,假设 tcp_syn_retries 参数值为 3,那么当客户端的 SYN 报文一直在网络中丢失时,会发生下图的过程:
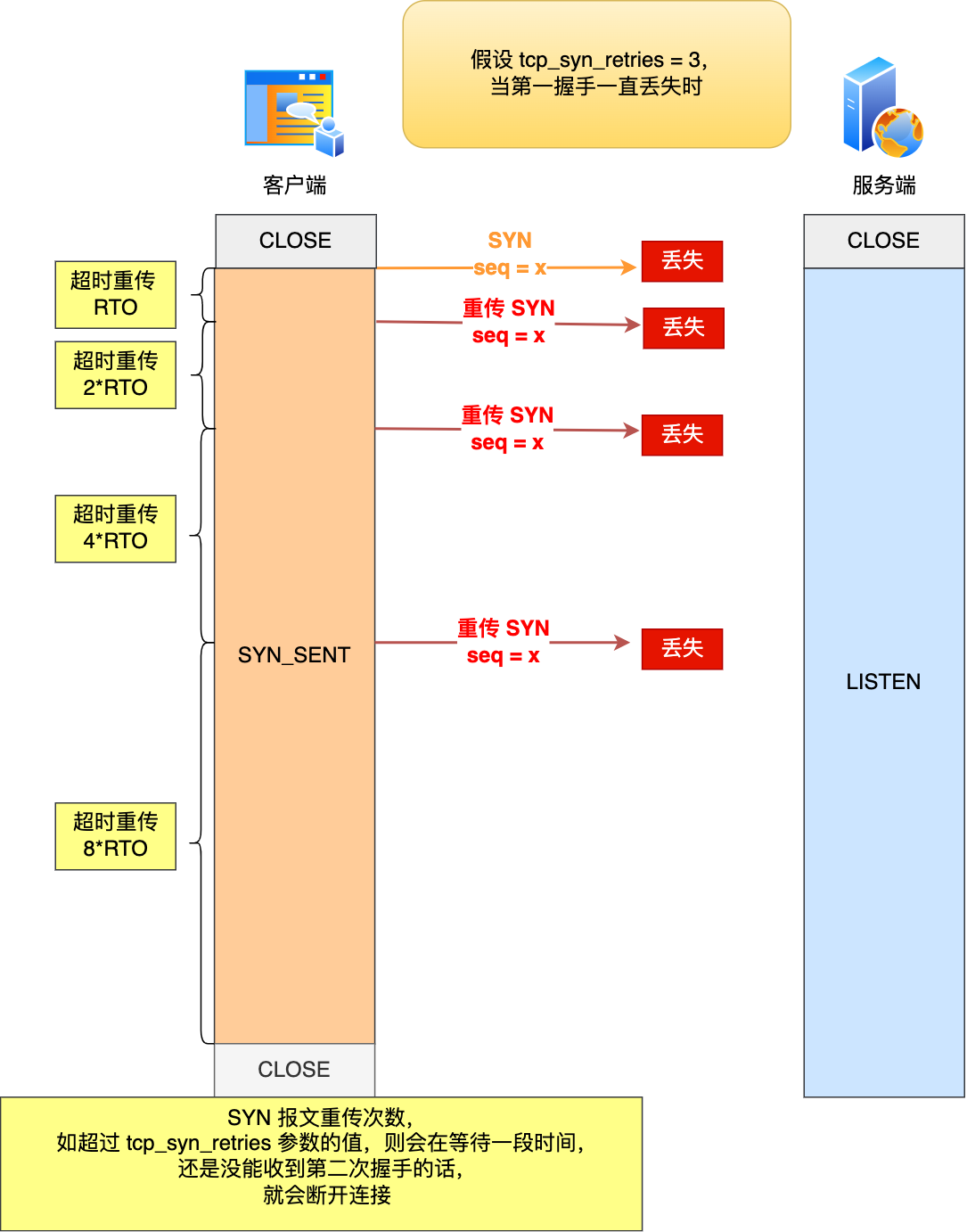
具体过程:
- 当客户端超时重传 3 次 SYN 报文后,由于 tcp_syn_retries 为 3,已达到最大重传次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到服务端的第二次握手(SYN-ACK 报文),那么客户端就会断开连接。
第二次握手丢失了,会发生什么?
当服务端收到客户端的第一次握手后,就会回 SYN-ACK 报文给客户端,这个就是第二次握手,此时服务端会进入 SYN_RCVD 状态。
第二次握手的 SYN-ACK 报文其实有两个目的 :
- 第二次握手里的 ACK, 是对第一次握手的确认报文;
- 第二次握手里的 SYN,是服务端发起建立 TCP 连接的报文;
所以,如果第二次握手丢了,就会发生比较有意思的事情,具体会怎么样呢?
因为第二次握手报文里是包含对客户端的第一次握手的 ACK 确认报文,所以,如果客户端迟迟没有收到第二次握手,那么客户端就觉得可能自己的 SYN 报文(第一次握手)丢失了,于是客户端就会触发超时重传机制,重传 SYN 报文。
然后,因为第二次握手中包含服务端的 SYN 报文,所以当客户端收到后,需要给服务端发送 ACK 确认报文(第三次握手),服务端才会认为该 SYN 报文被客户端收到了。
那么,如果第二次握手丢失了,服务端就收不到第三次握手,于是服务端这边会触发超时重传机制,重传 SYN-ACK 报文。
在 Linux 下,SYN-ACK 报文的最大重传次数由 tcp_synack_retries内核参数决定,默认值是 5。
# cat /proc/sys/net/ipv4/tcp_synack_retries
5
因此,当第二次握手丢失了,客户端和服务端都会重传:
- 客户端会重传 SYN 报文,也就是第一次握手,最大重传次数由
tcp_syn_retries内核参数决定; - 服务端会重传 SYN-ACK 报文,也就是第二次握手,最大重传次数由
tcp_synack_retries内核参数决定。
举个例子,假设 tcp_syn_retries 参数值为 1,tcp_synack_retries 参数值为 2,那么当第二次握手一直丢失时,发生的过程如下图:
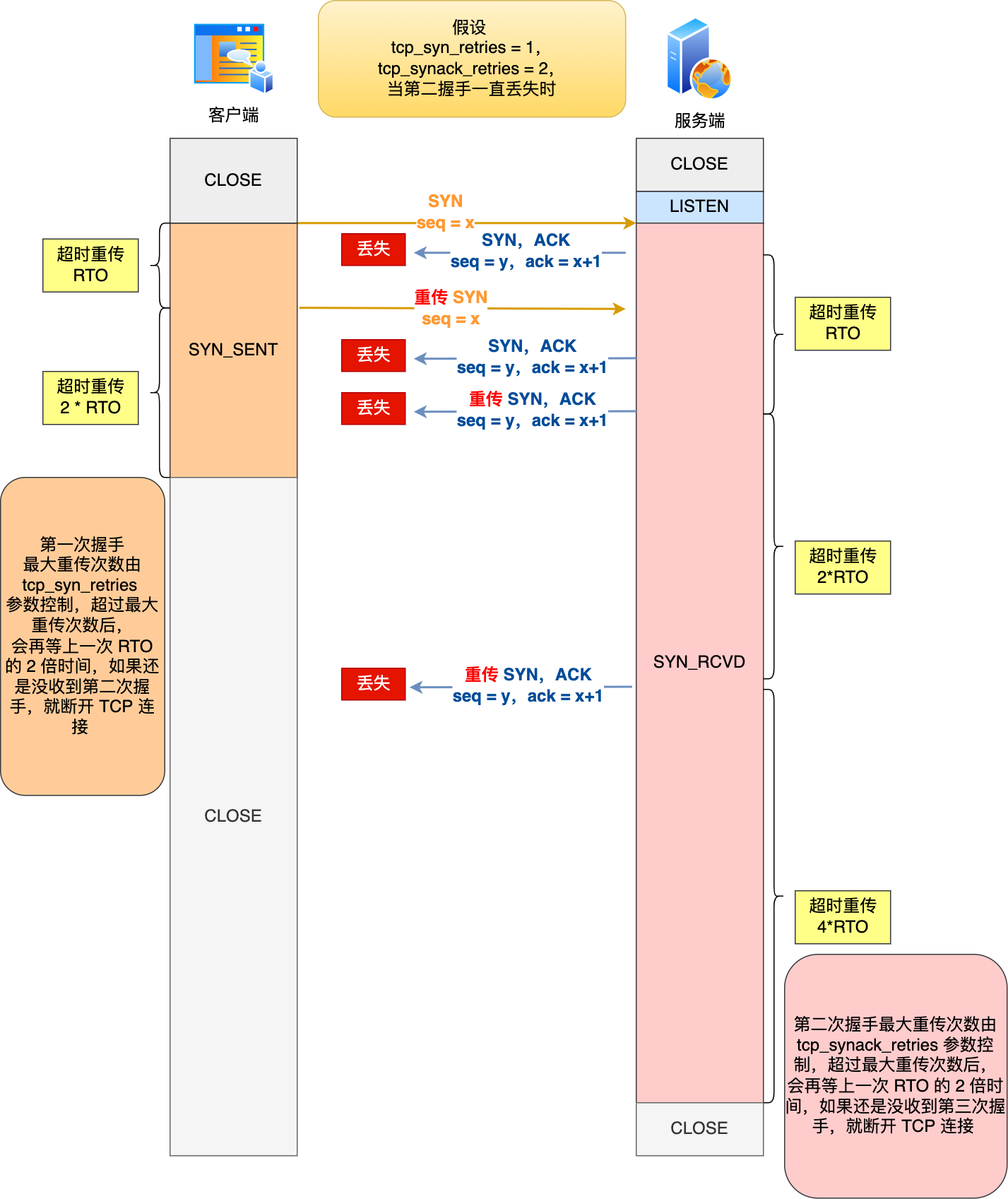
具体过程:
- 当客户端超时重传 1 次 SYN 报文后,由于 tcp_syn_retries 为 1,已达到最大重传次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到服务端的第二次握手(SYN-ACK 报文),那么客户端就会断开连接。
- 当服务端超时重传 2 次 SYN-ACK 报文后,由于 tcp_synack_retries 为 2,已达到最大重传次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到客户端的第三次握手(ACK 报文),那么服务端就会断开连接。
第三次握手丢失了,会发生什么?
客户端收到服务端的 SYN-ACK 报文后,就会给服务端回一个 ACK 报文,也就是第三次握手,此时客户端状态进入到 ESTABLISH 状态。
因为这个第三次握手的 ACK 是对第二次握手的 SYN 的确认报文,所以当第三次握手丢失了,如果服务端那一方迟迟收不到这个确认报文,就会触发超时重传机制,重传 SYN-ACK 报文,直到收到第三次握手,或者达到最大重传次数。
注意,ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。
举个例子,假设 tcp_synack_retries 参数值为 2,那么当第三次握手一直丢失时,发生的过程如下图:
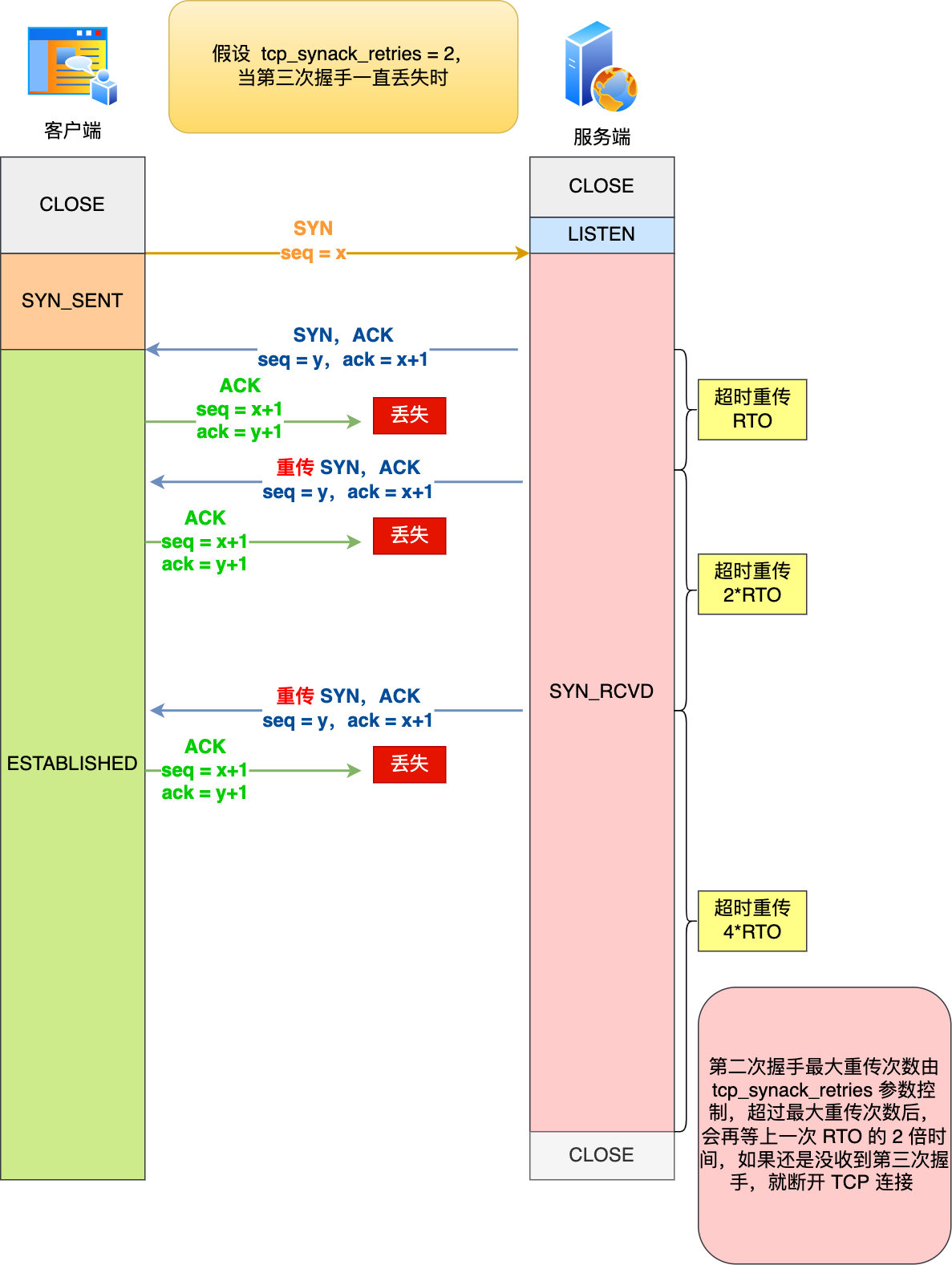
具体过程:
- 当服务端超时重传 2 次 SYN-ACK 报文后,由于 tcp_synack_retries 为 2,已达到最大重传次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到客户端的第三次握手(ACK 报文),那么服务端就会断开连接。
什么是 SYN 攻击?如何避免 SYN 攻击?
我们都知道 TCP 连接建立是需要三次握手,假设攻击者短时间伪造不同 IP 地址的 SYN 报文,服务端每接收到一个 SYN 报文,就进入SYN_RCVD 状态,但服务端发送出去的 ACK + SYN 报文,无法得到未知 IP 主机的 ACK 应答,久而久之就会占满服务端的半连接队列,使得服务端不能为正常用户服务。

先跟大家说一下,什么是 TCP 半连接和全连接队列。
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accept 队列;
我们先来看下 Linux 内核的 SYN 队列(半连接队列)与 Accpet 队列(全连接队列)是如何工作的?

正常流程:
- 当服务端接收到客户端的 SYN 报文时,会创建一个半连接的对象,然后将其加入到内核的「 SYN 队列」;
- 接着发送 SYN + ACK 给客户端,等待客户端回应 ACK 报文;
- 服务端接收到 ACK 报文后,从「 SYN 队列」取出一个半连接对象,然后创建一个新的连接对象放入到「 Accept 队列」;
- 应用通过调用
accpet()socket 接口,从「 Accept 队列」取出连接对象。
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,默认情况都会丢弃报文。
SYN 攻击方式最直接的表现就会把 TCP 半连接队列打满,这样当 TCP 半连接队列满了,后续再在收到 SYN 报文就会丢弃,导致客户端无法和服务端建立连接。
避免 SYN 攻击方式,可以有以下四种方法:
- 调大 netdev_max_backlog;
- 增大 TCP 半连接队列;
- 开启 tcp_syncookies;
- 减少 SYN+ACK 重传次数
方式一:调大 netdev_max_backlog
当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数,默认值是 1000,我们要适当调大该参数的值,比如设置为 10000:
net.core.netdev_max_backlog = 10000
方式二:增大 TCP 半连接队列
增大 TCP 半连接队列,要同时增大下面这三个参数:
- 增大 net.ipv4.tcp_max_syn_backlog
- 增大 listen() 函数中的 backlog
- 增大 net.core.somaxconn
具体为什么是三个参数决定 TCP 半连接队列的大小,可以看这篇:可以看这篇:TCP 半连接队列和全连接队列满了会发生什么?又该如何应对?(opens new window)
方式三:开启 net.ipv4.tcp_syncookies
开启 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,相当于绕过了 SYN 半连接来建立连接。

具体过程:
- 当 「 SYN 队列」满之后,后续服务端收到 SYN 包,不会丢弃,而是根据算法,计算出一个
cookie值; - 将 cookie 值放到第二次握手报文的「序列号」里,然后服务端回第二次握手给客户端;
- 服务端接收到客户端的应答报文时,服务端会检查这个 ACK 包的合法性。如果合法,将该连接对象放入到「 Accept 队列」。
- 最后应用程序通过调用
accpet()接口,从「 Accept 队列」取出的连接。
可以看到,当开启了 tcp_syncookies 了,即使受到 SYN 攻击而导致 SYN 队列满时,也能保证正常的连接成功建立。
net.ipv4.tcp_syncookies 参数主要有以下三个值:
- 0 值,表示关闭该功能;
- 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
- 2 值,表示无条件开启功能;
那么在应对 SYN 攻击时,只需要设置为 1 即可。
$ echo 1 > /proc/sys/net/ipv4/tcp_syncookies
方式四:减少 SYN+ACK 重传次数
当服务端受到 SYN 攻击时,就会有大量处于 SYN_REVC 状态的 TCP 连接,处于这个状态的 TCP 会重传 SYN+ACK ,当重传超过次数达到上限后,就会断开连接。
那么针对 SYN 攻击的场景,我们可以减少 SYN-ACK 的重传次数,以加快处于 SYN_REVC 状态的 TCP 连接断开。
SYN-ACK 报文的最大重传次数由 tcp_synack_retries内核参数决定(默认值是 5 次),比如将 tcp_synack_retries 减少到 2 次:
$ echo 2 > /proc/sys/net/ipv4/tcp_synack_retries声明:本文来自丁奇老师的部分内容加工而成,因为不在csdn,所以无法转载
只是为了自己学习方便以及和大家分享使用,不会用于商业用途。丁老师应该也不会这么小气。
相关文章:
面试真题-TCP的三次握手
TCP的基础知识 TCP头部 面试题:TCP的头部是多大? TCP(传输控制协议)的头部通常是固定的20个字节长,但是根据TCP选项(Options)的不同,这个长度可以扩展。TCP头部包含了许多关键的字…...
LabVIEW多语言支持优化
遇到的LabVIEW多语言支持问题,特别是德文显示乱码以及系统区域设置导致的异常,可能是由编码问题或区域设置不匹配引起的。以下是一些可能的原因及解决方案: 问题原因: 编码问题:LabVIEW内部使用UTF-8编码,但…...

身份证阅读器API模式 VUE Dorado7
VUE 新框架 // 身份证扫描 readIdCard(type) {// 1.连接axios.get(http://localhost:19196/openDevice).then(res > {if (res.data.resultFlag 0) {// 2.读卡axios.get(http://localhost:19196/readCard).then((res) > {if (res.data.resultFlag 0) {// this.$message…...

北京通州自闭症学校推荐:打造和谐学习氛围,助力孩子成长
在北京通州,寻找一所能够全面关注自闭症儿童成长、提供高效康复服务的学校,星贝育园无疑是众多家庭的首选。作为全国知名的广泛性发育障碍全托寄宿制儿童康复训练机构,星贝育园以其专业的康复方法、强大的师资力量和贴心的服务,为…...

openstack之cinder介绍
概念 cinder 为虚拟机提供管理块存储服务。支持的文件系统:lvm、iscsi、nfs、san、RBD 组件构成及功能介绍 cinder api:在控制节点运行,管理服务的接口,被命令行、其他组件调用; cinder scheduler:类似n…...

第k个排列 - 华为OD统一考试(E卷)
2024华为OD机试(E卷D卷C卷)最新题库【超值优惠】Java/Python/C合集 题目描述 给定参数n,从1到n会有n个整数:1,2,3,.,n,这n个数字共有 n!种排列。按大小顺序升序列出所有排列情况,并-一标记,当n3时,所有排列…...

清理C盘缓存,电脑缓存清理怎么一键删除,操作简单的教程
清理C盘缓存是维护电脑性能、释放磁盘空间的重要步骤。以下是一个详细且操作简单的教程,旨在帮助用户通过一键或几步操作完成C盘缓存的清理。 1.使用Windows系统自带工具 磁盘清理 1.打开磁盘清理工具: -按下“WinE”打开文件资源管理器…...

网络安全-ssrf
目录 一、环境 二、漏洞讲解 三、靶场讲解 四、可利用协议 4.1 dict协议 4.2 file协议 4.3 gopher协议 五、看一道ctf题吧(长亭的比赛) 5.1环境 5.2开始测试 编辑 一、环境 pikachu,这里我直接docker拉取的,我只写原…...

c++刷题
17.电话号码的组合 来源于题解思路: 继承 CC14 KiKi设计类继承 #include <iostream> #include <memory> using namespace std; class Shape{ private:int x;int y; };class Rectangle:public Shape { public:Rectangle(int length,int width):Shape…...

艾丽卡的区块链英语小课堂
系列文章目录 复习昨日 文章目录 系列文章目录前言1.opaque2.deduplicates3.references4,intermix5.serializing6.streamline7.robust8.flexibility9.exotic10.nevertheless11. realize12.flavor13.subtract14.attach15.award 前言 欢迎来到艾丽卡的区块链英语小课堂&#x…...

计算机毕业设计 公寓出租系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

eclipse使用 笔记02
创建一个项目: 【File-->New-->Dynamic Web Project】 进入页面: Project name为项目命名 Target runtime:选择自己所对应的版本 finish创建成功: 创建成功后的删除操作: 创建前端界面: 【注意&a…...

基于C++实现(MFC)职工工作量统计系统
题目:职工工作量统计系统设计 1、问题描述 职工包括姓名、职工号、性别、年龄、所在部门、联系方式等信息。 工作量包括职工号、完成的产品数量等信息。 该设计系统能够对职工的工作量进行统计,并排出名次。注意,一个职工的工作量是可以多次…...

大家好,我叫Redis~
大家好,我是Redis!下面请通过我的故事来认识我吧。 1. 初次登场:为什么需要我 在“双十一”期间,商店被顾客挤得水泄不通,所有人都急着问:“这款商品还有库存吗?” 可怜的服务员(My…...

【鸿蒙】HarmonyOS NEXT星河入门到实战6-组件化开发-样式结构重用常见组件
目录 1、Swiper轮播组件 1.1 Swiper基本用法 1.2 Swiper的常见属性 1.3 Swiper的样式自定义 1.3.1 基本语法 1.3.2 案例小米有品 2、样式&结构重用 2.1 Extend:扩展组件(样式、事件) 2.2 Styles:抽取通用属性、事件 2.3 Builder:自定义构建函数(结构、样式、事…...

网络安全学习(五)Burpsuite
经过测试,发现BP需要指定的JAVA才能安装。 需要的软件已经放在我的阿里云盘。 (一)需要下载Java SE 17.0.12(LTS) Java Downloads | Oracle 1.2023版Burp Suite 完美的运行脚本的环境是Java17 2.Java8不支持 看一下是否安装成功,…...

多版本node管理工具nvm
什么是nvm? 在项目开发过程中,使用到vue框架技术,需要安装node下载项目依赖,但经常会遇到node版本不匹配而导致无法正常下载,重新安装node却又很麻烦。为解决以上问题,nvm:一款node的版本管理工…...

如何扫描试卷去除笔迹?4种方法还原整洁试卷
如何扫描试卷去除笔迹?扫描试卷去除笔迹,作为现代学习管理与评估的革新手段,不仅显著提升了试卷的整洁美观度,更在环保和资源再利用层面发挥了积极作用。它使得试卷的保存、分享与复习变得更加便捷高效,减少了纸质资源…...

介绍⼀下泛型擦除
1.是什么 泛型擦除(Type Erasure)是Java泛型实现中的一个重要概念。Java的泛型是通过类型擦除来实现的,这意味着在运行时,泛型信息(即类型参数的具体类型)是不可用的。编译器在编译时会对泛型代码进行擦除处…...

从底层原理上理解ClickHouse 中的 Distributed 引擎
ClickHouse 的 Distributed 引擎 是实现大规模分布式查询和高可用性的关键技术之一,它允许集群中的多个节点协同工作,提供横向扩展能力和负载均衡机制。在底层,Distributed 引擎通过一系列的机制和策略,确保数据的分布、查询的并行…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...