深度学习经典模型之T5
T5(Text-to-Text Transfer Transformer) 是继BERT之后Google的又外力作,它是一个文本到文本迁移的基于Transformer的NLP模型,通过将 所有任务统一视为一个输入文本并输出到文本(Text-to-Text)中,即将任务嵌入在输入文本中,用文本的方式解决各种NLP的任务。T5是由google的Raffel等人于2019年提出了新的预训练模型,其参数量高达110亿,完爆BertLarge模型,且在多项NLP任务中达到SOTA性能,在NLP兴起了“迁移学习技术”热潮,带来了一系列方法、模型和实距的创新。
本文从 基本信息、模型架构、多个官方模型以及其T5主要贡献与应用场景对T5做一个简要的介绍.
附录是相关的概念
模型架构
T5(Text-to-Text Transfer Transformer) 是基于Transformer结构的序列到序列(Seq2Seq)模型,其主要特点是将多种NLP任务(如翻译、摘要、问答等)转化为一个统一的框架下进行训练。即在不同的具体任务上有不同的prefix指导模型,对预训练目标进行大范围探索,最后得到一个很强的baseline。而我们之后做这方面实验就能参考它的一套参数。
三种模型对比
为了解决Text-to-Text问题,作者分别使用了三种结构作为实验Encoder-Decoder、Language model和Prefix LM。Language model和Prefix LM比较适用于NLU类问题,但对于NLG,实验结果表明Encoder-Decoder效果更好。所以T5选择了Encoder-Decoder结构。如下图所示:

Encoder-Decoder: T5使用的就是Transformer标准的基本结构,分成 Encoder 和 Decoder 两部分,但有所区别:对于Encoder部分,是双向注意力,词与词之间互相可见,之后结果输给Decoder, Decoder部分当前时间步的词汇只能看到之前时间步的词汇。
Decoder-only: 在T5的自回归模型中当前时间步词汇只能看到之前时间步词汇。
GPT全系列及目前主流大模型均为 Decoder-only 结构。
Prefix LM: 通过巧妙的 Attention 设计实现双向注意力与单向注意力的结合,一部分如 Encoder 一样能看到全体信息,一部分如Decoder一样只能看到过去信息。
三种注意力机制对比
在同一种模型结构下,这三种架构依旧是通过注意力机制的 Mask 控制,下图表示不同注意掩码模式的矩阵。

上图中注意掩码模式的矩阵符号
- 自我注意力机制的输入和输出分别表示为x和y。
- 第i行和第j列的深色单元格表示允许自我注意机制在输出时间步i关注输入元素j。
- 浅色单元格表示不允许自我注意机制关注相应的i和j组合。
上图中左中右的三个图示说明说明
- 左图:一个完全可见的掩码允许自我注意力机制在每个输出时间步关注完整的输入。
- 中间:因果掩码防止第i个输出元素依赖“未来”的任何输入元素。
- 右图:带有前缀的因果掩码允许自我注意力机制对输入序列的一部分使用完全可见的掩蔽
- 不同架构的一个主要区别因素是模型中不同注意力机制使用的“掩码”。
- 同样运算复杂度的情况下,Encoder-decoder结构的参数量是其他结构的两倍左右。
实验路径
明确的基础结构之后,就开始考虑自监督的组织方式、掩码(方式、比例等)如何设计,下图是一个实验路径,最终探索最优结果:

High-level approaches
高层次方法对比(左图)
- Prefix LM: 即有条件文本生成,输入完整文本,输出从左到右预测
- BERT-style: 就是像 BERT 一样将一部分给破坏掉,然后还原出来
- Deshuffling: 就是将文本打乱,然后还原出来
Corrupted strategies
对文本一部分进行破坏时的策略(第二图)
- Mask: 如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
- Replace spans: 可以把它当作是把上面 Mask 法中相邻[M] 都合成了一个特殊符,每小段替换一个特殊符,提高计算效率;
- Drop: 没有替换操作,直接随机丢弃一些字符;
Corrupted Rate
(第三图)文本的 Mask 比例,论文中挑了 4 个值,10%,15%,25%,50%,最后明确BERT 的 15% 是最最优选择

Corrupted Span length
(第四图) Replace spans 对多长的 span 进行破坏,选定了4个探索值: 2,3,5,10 这四个值,最后发现span平均长为3结果最好。

模型配置
模型参数
为了适应不同使用场景,T5有五个不同size。Small、Base、Large、3B 和 11B, 模型参数量分别为 6000 万、2.2 亿、7.7 亿、30 亿和 110 亿。

执行效果

最优总结
综上所述,作者发现,一个最优的预训练T5模型应该是这样的:
目标函数:Span-corruption,span的平均长度为3,corruption的概率为15%
更长的训练步数:采用C4数据集继续训练1M步(bs=2^11),总计约训练了1 万亿个token
模型大小
- base版本:24层,隐层768维,12个注意力头,参数量为220M
- small版本:12层,隐层 512维,8个注意力头,参数量约为60M
- Large版本:48层,隐层1024维,16个注意力头,参数量约为770M
- 3B和11B版本:48层,隐层1024维,分别为32/128个注意力头,参数量达到了 2.8B和11B
- 多任务预训练:在非监督预训练时,混合有监督任务可以涨点。
- 微调:在每个任务上微调
- Beam Search:Beam size为4,长度惩罚为0.6

此段中文来自 zhuanlan.zhihu.com/p/580554368 ,但结论归属于T5论文作者,见上上图)
T5主要贡献
Text-to-Text Transfer
F5最大的创新在于给整个NLP预训练模型领域提供了一个通用框架,把所有任务都转化成一种文本。即将每个NLP任务,包括NLU和NLG,统一成了"text-to-text"的问题。如下图在翻译、问答、分类等四个不同任务上,添加不同的prefix在输入上,即可通过生成模型得到输出结果。
允许在不同的任务集合中使用相同的模型、损失函数、超参数等。

C4(Colossal Clean Crawled Corpus)
作者从Common Crawl里清出了750GB的训练数据,并取名为"Colossal Clean Crawled Corpus (超大型干净爬取数据)",简称 C4。
Common Crawl是一种公开可用的web存档,它通过从已删除的HTML文件删除标记和其他非文本内容来提供“web提取文本”, 该存档大约每月会新产生约20TB的抓取文本数据。但数据主要由诸如菜单、错误消息或重复文本之类的胡言乱语或锅炉板文本组成,且有大量删减的文本或冒犯性语言、占位符文本、源代码等等。
应用场景
在过去的几年中,随着深度学习技术的发展,NLP领域取得了突破性进展。在众多的NLP模型中,T5模型作为一种强大的语言生成模型,在自然摘要、机器翻译、智能问答和文本分类等任务中表现出色,成为了该领域的研究热点之一。
附-文本中涉及的相关深度学习的基本概念
SOTA(State of the art) 是指在某一领域做的Performance里最好的modal, 一般是指在一些benchmark的数据集上跑分非常高的那些模型。
迁移学习 通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。
涌现 模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
思维链(Chain-of-Thought,CoT) 是指通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
NLU和NLG:是指NLP(自然语言处理)的两个主要核心任务。NLU是所有支持机器理解文本内容的方法模型或任务的总称,即能够进行常见的文本分类、序列标注、信息抽取等任务。NLG(自然语言生成) 将非语言格式的数据转换成人类可以理解的语言格式。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

相关文章:
深度学习经典模型之T5
T5(Text-to-Text Transfer Transformer) 是继BERT之后Google的又外力作,它是一个文本到文本迁移的基于Transformer的NLP模型,通过将 所有任务统一视为一个输入文本并输出到文本(Text-to-Text)中,即将任务嵌入在输入文本中,用文本的…...

10.第二阶段x86游戏实战2-反编译自己的程序加深堆栈的理解
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 工具下载: 链接:https://pan.baidu.com/s/1rEEJnt85npn7N38Ai0_F2Q?pwd6tw3 提…...

ARM总复习
1.计算机的组成 输入设备 输出设备 存储设备 运算器 控制器、总线 2.指令和指令集 2.1 机器指令 机器指令又叫机器码,在运算器内部存在各种运算电路,当处理器从内存中获取一条机器指令,就可以按照指令让运算器内部的指定的运算电路进行运…...

使用ENVI之大气校正(下)
再根据遥感影像的拍摄时间将Flight ate与Flight Time GMT (H:M:SS)填写,如要查询按如下方法 这里按照表中的内容修改 根据影像范围的经纬度与拍摄时间更改Atmospheric Model,更改完成后点击Multispectral Settings...在跳出的界面中选择GUI再点击Default…...
2024.9.18)
C++(学习)2024.9.18
目录 C基础介绍 C特点 面向对象的三大特征 面向对象与面向过程的区别 C拓展的非面向对象的功能 引用 引用的性质 引用的参数 指针和引用的区别 赋值 键盘输入 string字符串类 遍历方式 字符串与数字转换 函数 内联函数 函数重载overload 哑元函数 面向对象基…...

认知小文2《成功之路:习惯、学习与实践》
内容摘要: 在这个充满机遇的时代,成功不再是偶然,而是可以通过培养良好习惯、持续学习和实践来实现的目标。 一、肌肉记忆:技能的基石 成功往往需要像运动员一样,通过日复一日的练习来形成肌肉记忆。无论是健身…...

【数据仓库】数据仓库层次化设计
一、基本概念 **1. RDS(RAW DATA STORES,原始数据存储)** RDS作为原始数据存储层,用于存储来自各种源头的未经处理的数据。这些数据可能来自企业内部的业务系统、外部数据源或各种传感器等。RDS确保原始数据的完整性和可访问性&…...
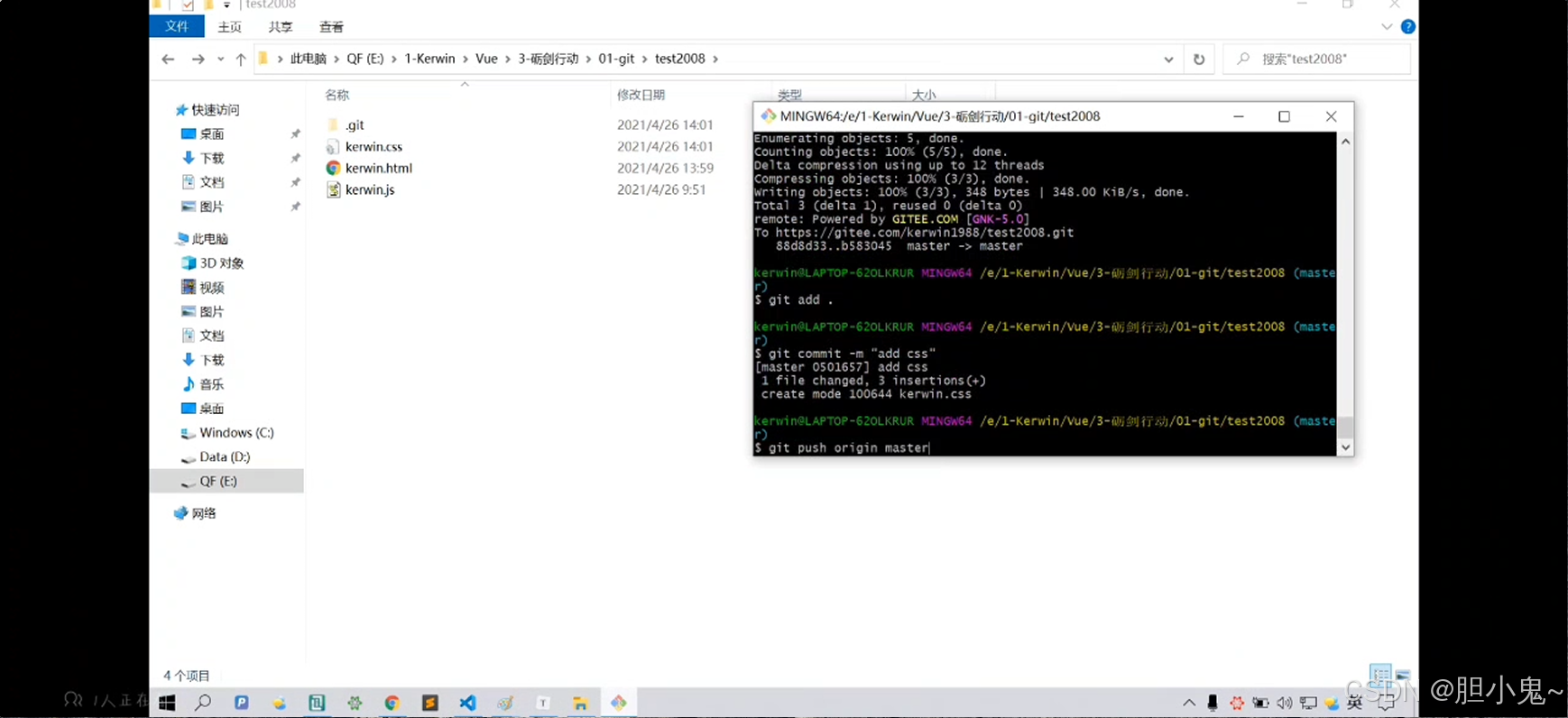
【DAY20240918】03教你轻松配置 Git 远程仓库并高效推送代码!
文章目录 前言 git diff一、远程仓库?1、在 Gitee 上新建仓库:2、Git 全局设置:3、添加远程仓库:4、推送本地代码到远程仓库:5、输入用户名和密码:6、后续推送: 二、全情回顾三、参考 前言 git …...

从IPC摄像机读取视频帧解码并转化为YUV数据到转化为Bitmap
前言 本文主要介绍根据IPC的RTSP视频流地址,连接摄像机,并持续读取相机视频流,进一步进行播放实时画面,或者处理视频帧,将每一帧数据转化为安卓相机同格式数据,并保存为bitmap。 示例 val rtspClientListener = object: RtspClient.RtspClientListener {override fun …...

LeetCode 面试经典 150 题回顾
目录 一、数组 / 字符串 1.合并两个有序数组 (简单) 2.移除元素 (简单) 3.删除有序数组中的重复项 (简单) 4.删除有序数组中的重复项 II(中等) 5.多数元素(简单&am…...

【网络安全的神秘世界】渗透测试基础
🌝博客主页:泥菩萨 💖专栏:Linux探索之旅 | 网络安全的神秘世界 | 专接本 | 每天学会一个渗透测试工具 渗透测试基础 基于功能去进行漏洞挖掘 1、编辑器漏洞 1.1 编辑器漏洞介绍 一般企业搭建网站可能采用了通用模板ÿ…...

【重学 MySQL】二十九、函数的理解
【重学 MySQL】二十九、函数的理解 什么是函数不同 DBMS 函数的差异函数名称和参数功能实现数据类型支持性能和优化兼容性和可移植性 MySQL 的内置函数及分类单行函数多行函数(聚合函数)使用注意事项 什么是函数 函数(Function)在…...

MySQL5.7主从复制搭建-gtid方式
环境准备 1、主机名和和IP地址如下 10.0.0.51 db01.ljbb.com 10.0.0.52 db02.ljbb.com 10.0.0.53 db03.ljbb.com2、配置文件 db01 [mysqld] usermysql basedir/app/mysql datadir/data/mysql/data socket/tmp/mysql.sock server_id51 port3306 secure-file-priv/tmp autoco…...

golang学习笔记22——golang微服务中数据竞争问题及解决方案
推荐学习文档 golang应用级os框架,欢迎stargolang应用级os框架使用案例,欢迎star案例:基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总想学习更多golang知识,这里有免费的golang学习笔…...

yolo训练出现Could not load library libcudnn_cnn_train.so.8问题及解决方法
问题场景: 训练yolov5或者yolov8时候会报错: Could not load library libcudnn_cnn_train.so.8. Error: /usr/local/cuda-12.1/lib64/libcudnn_cnn_train.so.8: uined symbol: _ZN5cudnn3cnn34layerNormFwd_execute_internal_implERKNS_7backend11Vari…...

携手科大讯飞丨云衔科技为企业提供全栈AI技术解决方案
作为智能时代的核心驱动力,人工智能不仅重塑了传统行业的面貌,更开辟了全新的经济增长点。科大讯飞以其深厚的技术底蕴和创新能力,持续引领着人工智能领域的发展潮流。云衔科技作为科大讯飞开放平台的AI技术产品线合作伙伴代理商,…...
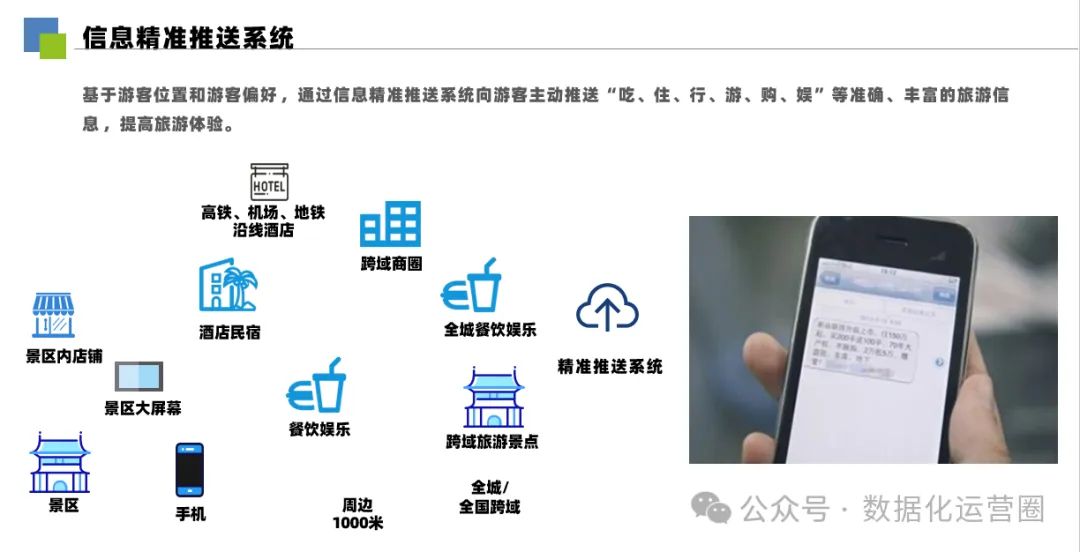
57页PPT | 智慧文旅整体建设解决方案
主要介绍了智慧文旅的建设背景、需求分析、解决方案、应用系统功能需求、客户价值、企业价值、建设理念、建设思路、总体架构、安全管理体系、融媒体综合服务平台、大数据分析平台、智慧文旅云平台、智慧管理、智慧营销、智慧服务等方面的内容。 背景及需求分析 方案架构及理念…...

线性代数之QR分解和SVD分解
文章目录 1.QR分解Schmidt正交化Householder变换QR分解的应用 2. 求矩阵特征值、特征向量的基本方法3.SVD分解SVD分解的应用 参考文献 1.QR分解 矩阵的正交分解又称为QR分解,是将矩阵分解为一个正交矩阵Q和一个上三角矩阵R的乘积的形式。 任意实数方阵A,…...

在虚拟机安装mysql数据库
一、安装步骤(下载包-传输软件包-安装包-启用仓库-使用yum安装服务器) 1、要在mysql官网下载yum仓库包 2、下载好rpm包后,将其通过xftp传输到root目录下 3、使用sudo yum install yum的仓库名(sudo yum install mysql-community-…...

详解QT插件机制
Qt插件机制允许将功能模块化为独立的插件,从而在运行时动态加载和卸载这些模块。这种机制对于扩展应用程序、插件架构和动态功能添加非常有用 插件机制 插件的基本概念 插件: 在Qt中,插件是实现特定接口的动态库(DLL或so文件),这些接口由Qt插件框架定义。插件可以被应用程序…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

Noto字体终极指南:告别“豆腐块“,让全球文字清晰显示
Noto字体终极指南:告别"豆腐块",让全球文字清晰显示 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在数字世界中,你是否经常看到那些令人困…...