Meta-Learning数学原理
文章目录
- 什么是元学习
- 元学习的目标
- 元学习的类型
- 数学推导
- 1. 传统机器学习的数学表述
- 2. 元学习的基本思想
- 3. MAML 算法推导
- 3.1 元任务设置
- 3.2 内层优化:任务级别学习
- 3.3 外层优化:元级别学习
- 3.4 元梯度计算
- 3.5 最终更新规则
- 4. 算法合并
- 5. 理解 MAML 的优化
- 图例
- MAML 的优势
- 其他元学习方法
- 总结
- 手写笔记
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发,目前开始人工智能领域相关知识的学习
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
之前介绍过元学习的内容:https://xzl-tech.blog.csdn.net/article/details/142025393
这篇文章讲一下Meta-Learning的数学原理。
什么是元学习
元学习(Meta-Learning),也称为“学习如何学习”,是一种机器学习方法,其目的是通过学习算法的经验和结构特性,提升算法在新任务上的学习效率。
换句话说,元学习试图学习一种更有效的学习方法,使得模型能够快速适应新的任务或环境。
传统的机器学习算法通常需要大量的数据来训练模型,并且当数据分布发生变化或者遇到一个新任务时,模型往往需要重新训练才能保持良好的性能。
而元学习则不同,它通过 从多个相关任务中学习,从而在面对新任务时更快速地进行学习。
元学习的核心思想是利用“学习的经验”来提高学习的速度和质量。
在元学习的框架中,有两个层次的学习过程:
- 元学习者(Meta-Learner): 负责从多个任务中提取经验和知识,用于更新学习策略或模型参数。
- 基础学习者(Base Learner): 在每个具体任务上执行实际的学习过程。
元学习的目标
元学习的目标是解决以下问题:
- 快速适应: 当模型面临新任务时,能够基于已有的经验快速适应,而无需大量的数据和计算资源。
- 跨任务泛化: 提高模型从多个任务中学习到的知识在新任务上的泛化能力。
- 提高数据效率: 减少模型在新任务上所需的数据量,尤其是在数据稀缺或高昂的情况下。
元学习的类型
元学习可以按照不同的方式分类,以下是三种主要类型:
- 基于模型的元学习(Model-Based Meta-Learning):
- 这种方法通过直接设计一种能够快速适应新任务的模型架构,通常是通过某种特殊的神经网络结构来实现的。例如,基于记忆的神经网络(如 LSTM 或 Memory-Augmented Neural Networks)被设计成能有效地记住过去的任务信息,并在新任务上进行快速调整。
- 例子: MANN(Memory-Augmented Neural Networks),SNAIL(Simple Neural Attentive Meta-Learner)。
- 基于优化的元学习(Optimization-Based Meta-Learning):
- 这种方法的核心是通过改进优化过程本身来实现快速学习。其代表算法是 MAML(Model-Agnostic Meta-Learning),它通过在所有任务上共享一个初始模型参数,使得初始模型在每个任务上进行少量梯度下降更新后能够快速适应新任务。
- 例子: MAML(Model-Agnostic Meta-Learning),Reptile。
- 基于记忆的元学习(Memory-Based Meta-Learning):
- 这类方法直接存储并检索训练过程中的经验数据。当遇到新任务时,通过查找与之相似的旧任务,并利用这些旧任务的数据和经验来快速学习。k-NN(k-近邻)方法是最基本的例子,而更复杂的方法可能使用深度记忆网络。
- 例子: Meta Networks,Prototypical Networks。
数学推导
1. 传统机器学习的数学表述
在传统的机器学习中,我们通常试图找到一个函数 f θ f_\theta fθ来最小化给定数据集 D D D的损失函数:
θ ∗ = arg min θ L ( f θ , D ) \theta^* = \arg\min_{\theta} L(f_\theta, D) θ∗=argminθL(fθ,D)
其中:
- θ \theta θ是模型的参数。
- L ( f θ , D ) L(f_\theta, D) L(fθ,D)是损失函数,例如交叉熵损失。
- 通过梯度下降等优化方法,我们不断更新参数 θ \theta θ以最小化损失。
2. 元学习的基本思想
元学习的目标是找到一种元算法 F ϕ F_\phi Fϕ,使得它可以快速学习新任务。这里的关键是学习一种 学习算法。换句话说,元学习希望找到一组元参数 ϕ \phi ϕ,从而在给定一个新任务 T i T_i Ti时,使用少量数据和梯度更新就可以迅速找到特定任务的参数 θ i \theta_i θi。
3. MAML 算法推导
MAML 的目标是学习一个初始模型参数 θ \theta θ,使得它可以通过少量的梯度更新快速适应新任务。
3.1 元任务设置
假设有一组任务 { T 1 , T 2 , … , T N } \{T_1, T_2, \dots, T_N\} {T1,T2,…,TN},每个任务 T i T_i Ti有自己的训练数据 D i train D_i^{\text{train}} Ditrain和测试数据 D i test D_i^{\text{test}} Ditest。
3.2 内层优化:任务级别学习
对于每个任务 T i T_i Ti,我们首先使用任务的训练数据 D i train D_i^{\text{train}} Ditrain和当前的模型参数 θ \theta θ进行一次或多次梯度更新,得到任务特定的参数 θ i ′ \theta_i' θi′:
θ i ′ = θ − α ∇ θ L T i ( f θ , D i train ) \theta_i' = \theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}}) θi′=θ−α∇θLTi(fθ,Ditrain)
其中:
- α \alpha α是学习率。
- L T i ( f θ , D i train ) L_{T_i}(f_\theta, D_i^{\text{train}}) LTi(fθ,Ditrain)是任务 T i T_i Ti的损失函数,例如对于分类任务可以是交叉熵损失。
3.3 外层优化:元级别学习
在每个任务的测试数据上评估更新后的模型参数 θ i ′ \theta_i' θi′,计算其损失,并在所有任务上最小化测试损失的总和:
min θ ∑ i = 1 N L T i ( f θ i ′ , D i test ) \min_{\theta} \sum_{i=1}^N L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) minθ∑i=1NLTi(fθi′,Ditest)
将 θ i ′ \theta_i' θi′展开,这个目标实际上是关于初始参数 θ \theta θ的优化问题:
min θ ∑ i = 1 N L T i ( f θ − α ∇ θ L T i ( f θ , D i train ) , D i test ) \min_{\theta} \sum_{i=1}^N L_{T_i}(f_{\theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}})}, D_i^{\text{test}}) minθ∑i=1NLTi(fθ−α∇θLTi(fθ,Ditrain),Ditest)
3.4 元梯度计算
为了优化这个目标,我们需要对 θ \theta θ求梯度。这里涉及二阶梯度,因为 θ i ′ \theta_i' θi′是通过内层优化得到的:
θ ← θ − β ∑ i = 1 N ∇ θ L T i ( f θ i ′ , D i test ) \theta \leftarrow \theta - \beta \sum_{i=1}^N \nabla_\theta L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) θ←θ−β∑i=1N∇θLTi(fθi′,Ditest)
其中 β \beta β是元学习的学习率。
- 这个更新包含了二阶导数项: ∇ θ θ i ′ = ∇ θ ( θ − α ∇ θ L T i ( f θ , D i train ) ) \nabla_\theta \theta_i' = \nabla_\theta \left(\theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}})\right) ∇θθi′=∇θ(θ−α∇θLTi(fθ,Ditrain))。
3.5 最终更新规则
最终的元学习更新规则可以写为:
θ ← θ − β ∑ i = 1 N ∇ θ L T i ( f θ − α ∇ θ L T i ( f θ , D i train ) , D i test ) \theta \leftarrow \theta - \beta \sum_{i=1}^N \nabla_\theta L_{T_i}\left(f_{\theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}})}, D_i^{\text{test}}\right) θ←θ−β∑i=1N∇θLTi(fθ−α∇θLTi(fθ,Ditrain),Ditest)
4. 算法合并
将内层优化 θ i ′ \theta_i' θi′代入外层优化的公式中,外层优化的梯度 ∇ θ L T i ( f θ i ′ , D i test ) \nabla_\theta L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) ∇θLTi(fθi′,Ditest)需要应用链式法则:
∇ θ L T i ( f θ i ′ , D i test ) = ∇ θ L T i ( f θ − α ∇ θ L T i ( f θ , D i train ) , D i test ) \nabla_\theta L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) = \nabla_\theta L_{T_i}\left(f_{\theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}})}, D_i^{\text{test}}\right) ∇θLTi(fθi′,Ditest)=∇θLTi(fθ−α∇θLTi(fθ,Ditrain),Ditest)
通过链式法则,展开这个公式:
∇ θ L T i ( f θ i ′ , D i test ) = ∇ θ i ′ L T i ( f θ i ′ , D i test ) ⋅ ∇ θ θ i ′ \nabla_\theta L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) = \nabla_{\theta_i'} L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) \cdot \nabla_\theta \theta_i' ∇θLTi(fθi′,Ditest)=∇θi′LTi(fθi′,Ditest)⋅∇θθi′
其中 ∇ θ θ i ′ \nabla_\theta \theta_i' ∇θθi′的形式为:
∇ θ θ i ′ = I − α ∇ θ 2 L T i ( f θ , D i train ) \nabla_\theta \theta_i' = I - \alpha \nabla^2_\theta L_{T_i}(f_\theta, D_i^{\text{train}}) ∇θθi′=I−α∇θ2LTi(fθ,Ditrain)
I I I是单位矩阵, ∇ θ 2 L T i ( f θ , D i train ) \nabla^2_\theta L_{T_i}(f_\theta, D_i^{\text{train}}) ∇θ2LTi(fθ,Ditrain)是损失函数关于 θ \theta θ的二阶导数(Hessian 矩阵)。
最终的公式:
将这些部分合并在一起,得到 MAML 的最终更新公式为:
θ ← θ − β ∑ i = 1 N ∇ θ i ′ L T i ( f θ − α ∇ θ L T i ( f θ , D i train ) , D i test ) ⋅ ( I − α ∇ θ 2 L T i ( f θ , D i train ) ) \theta \leftarrow \theta - \beta \sum_{i=1}^N \nabla_{\theta_i'} L_{T_i}\left(f_{\theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}})}, D_i^{\text{test}}\right) \cdot \left(I - \alpha \nabla^2_\theta L_{T_i}(f_\theta, D_i^{\text{train}})\right) θ←θ−βi=1∑N∇θi′LTi(fθ−α∇θLTi(fθ,Ditrain),Ditest)⋅(I−α∇θ2LTi(fθ,Ditrain))
解释:
- 内层优化:第一部分 θ i ′ = θ − α ∇ θ L T i ( f θ , D i train ) \theta_i' = \theta - \alpha \nabla_\theta L_{T_i}(f_\theta, D_i^{\text{train}}) θi′=θ−α∇θLTi(fθ,Ditrain)表示在每个任务上用梯度下降更新 θ \theta θ,得到特定于任务的参数 θ i ′ \theta_i' θi′。
- 外层优化:外层优化考虑测试集上的损失,并通过链式法则计算对 θ \theta θ的梯度。这部分的关键是包含了内层更新的二阶导数 ∇ θ θ i ′ \nabla_\theta \theta_i' ∇θθi′。
- 合并公式:最终的更新公式同时结合了内层和外层优化的过程,充分考虑了内层更新对外层优化的影响。
简化(在某些情况下):
在实际应用中,计算二阶导数(Hessian 矩阵)非常昂贵。因此,有时会使用近似方法来简化计算,例如“一次近似 MAML (First-Order MAML, FOMAML)”,忽略二阶项,仅使用一阶导数进行更新。简化后的更新公式为:
θ ← θ − β ∑ i = 1 N ∇ θ i ′ L T i ( f θ i ′ , D i test ) \theta \leftarrow \theta - \beta \sum_{i=1}^N \nabla_{\theta_i'} L_{T_i}(f_{\theta_i'}, D_i^{\text{test}}) θ←θ−βi=1∑N∇θi′LTi(fθi′,Ditest)
这个简化版本去除了 ∇ θ θ i ′ \nabla_\theta \theta_i' ∇θθi′中的二阶导数计算。
5. 理解 MAML 的优化
通过上面的推导,MAML 的优化分为两个阶段:
- 内层优化:在每个任务上利用任务的训练数据对模型进行一次或多次更新,以获得任务特定的模型参数。
- 外层优化:在所有任务的测试数据上评估内层优化后的模型,并利用这个评估结果更新模型的初始参数。
图例
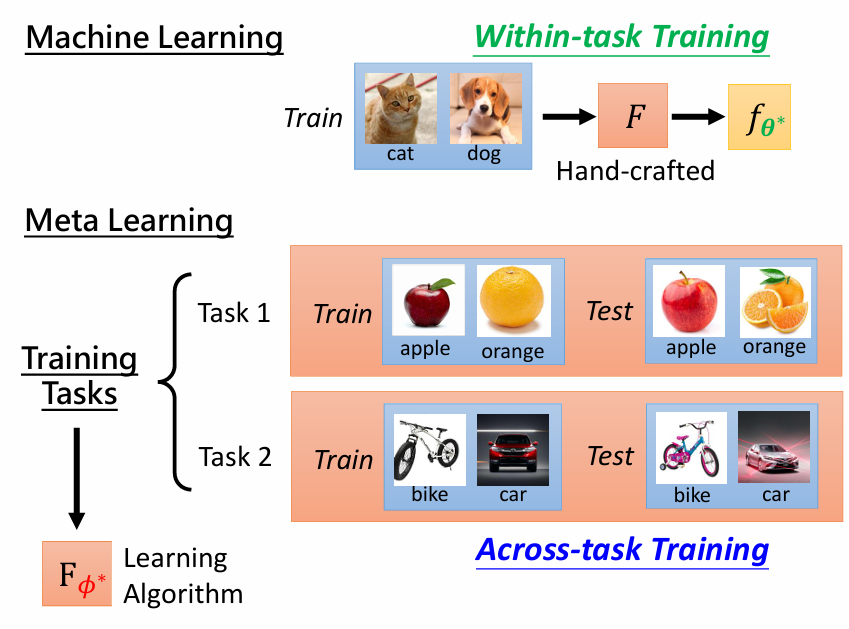
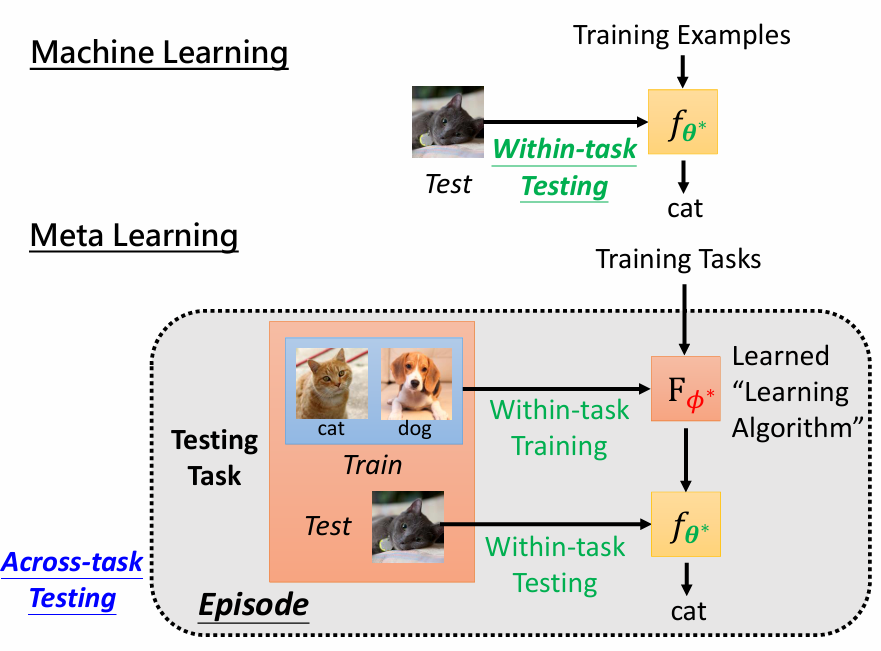
MAML 的优势
MAML 的一个关键优势在于,它学习了一个初始参数 θ \theta θ,使得它可以通过少量梯度更新快速适应新任务。这使得它非常适合少样本学习场景,如几次样本分类。
其他元学习方法
除了 MAML,文件中还提到其他元学习方法,如基于优化器的元学习、网络架构搜索(NAS)等。这些方法都在不同程度上优化了元学习的过程,使得模型能够在少量数据的情况下快速学习。
总结
元学习的数学推导核心在于通过多个任务的训练,学习到一个通用的学习算法(或模型初始化),使得模型可以快速适应新任务。MAML 是元学习的一个经典方法,通过在元任务上进行二阶优化,使模型获得更好的泛化能力。
手写笔记
最后放几张今天的手写笔记,主要是方便查阅。



相关文章:
Meta-Learning数学原理
文章目录 什么是元学习元学习的目标元学习的类型数学推导1. 传统机器学习的数学表述2. 元学习的基本思想3. MAML 算法推导3.1 元任务设置3.2 内层优化:任务级别学习3.3 外层优化:元级别学习3.4 元梯度计算3.5 最终更新规则 4. 算法合并5. 理解 MAML 的优…...

【图像匹配】基于SURF算法的图像匹配,matlab实现
博主简介:matlab图像代码项目合作(扣扣:3249726188) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 本次案例是基于基于SURF算法的图像匹配,用matlab实现。 一、案例背景和算法介绍 前…...

RocketMQ实战与集群架构详解
目录 一、MQ简介 MQ的作用主要有以下三个方面 二、RocketMQ产品特点 1、RocketMQ介绍 2、RocketMQ特点 三、RocketMQ实战 1、快速搭建RocketMQ服务 2、快速实现消息收发 1. 命令行快速实现消息收发 2. 搭建Maven客户端项目 3、搭建RocketMQ可视化管理服务 4、升级分…...

docker容器中的内存占用高的问题分析
文章目录 问题描述原因分析分析1分析2验证猜想 结论和经验 问题描述 运维新增对某服务的监控后发现:内存不断上涨的现象。进一步确认,是因为有多个导出日志操作导致的内存上涨问题。 进一步的测试得出的结果是:容器刚启动是占用内存约为50M…...

纯血鸿蒙NEXT常用的几个官方网站
一、官方文档 https://gitee.com/openharmony/docs/blob/master/zh-cn/application-dev/Readme-CN.md刚入门查看最多的就是UI开发模块,首先要熟悉组件使用 二、官方API参考 https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/development-i…...

A股上市公司企业创新能力、质量、效率-原始数据+dofile+结果(2006-2023年)
上市公司的创新能力体现在其不断研发新技术、新产品和服务的能力上,这是企业保持竞争优势的关键;质量则是指公司所提供的产品或服务达到高标准的程度,高质量是赢得客户信任和市场份额的基础;效率则涵盖了生产运营中的资源利用程度…...

Selenium:开源自动化测试框架的Java实战解析
背景 在软件开发领域,随着Web应用程序的日益复杂和快速迭代的需求,传统的手动测试方法已经无法满足高效、全面的测试需求。自动化测试作为一种高效、稳定的测试手段,逐渐成为软件开发流程中不可或缺的一环。Selenium,作为一款开源…...

搜索功能技术方案
1. 背景与需求分析 门户平台需要实现对服务信息的高效查询,包括通过关键字搜索服务以及基于地理位置进行服务搜索。面对未来可能的数据增长和性能需求,选择使用 Elasticsearch 来替代 MySQL 的全文检索功能。这一选择的背景与需求可以总结为以下几点&am…...

硬件体系架构的学习
硬件体系架构的学习 RISC全称Reduced Instruction Set Compute,精简指令集计算机; CISC全称Complex Instruction Set Computers,复杂指令集计算机。 SOC片上系统概念 System on Chip,简称Soc,也即片上系统。从狭义…...

【与C++的邂逅】--- C++的IO流
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: 与C的邂逅 本篇博客我们来了解C中io流的相关知识。 🏠 C语言输入输出 C语言中我们用到的最频繁的输入输出方式就是scanf ()与printf()。 sc…...

【C++ Primer Plus习题】16.8
大家好,这里是国中之林! ❥前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。有兴趣的可以点点进去看看← 问题: 解答: main.cpp #include <iostream> #include <set> #includ…...

基于stm32的四旋翼无人机控制系统设计系统设计与实现
文章目录 前言资料获取设计介绍功能介绍设计程序 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师,一名热衷于单片机技术探索与分享的博主、专注于 精通51/STM32/MSP430/AVR等单片机设计 主要对象是咱们电子相关专业…...

【原理图PCB专题】案例:原理图设计检查为什么要检查全局网络?
本案例发生在新人的PCB设计文件中,当然就算硬件老人们,其实只要不注意也很容易出现这种全局网络乱用的问题。 如下所示是给新人的接口参考图纸,要求使用嘉立创绘制16个相同的接口做一个工装板。同时还要增加单片机实现切换控制功能。可以看到座子的24个管脚中使用到了3.3V、…...

Java 之 IO流
一、IO流概述 在计算机编程中,IO流(Input/Output Stream)是处理设备间数据传输的关键技术。简单来说,IO流就是以流的方式进行输入输出,数据被当作无结构的字节序或字符序列来处理。在Java等编程语言中,IO流…...

计算机毕业设计 健身房管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

uniapp uview扩展u-picker支持日历期间 年期间 月期间 时分期间组件
uniapp uview扩展u-picker支持日历期间 年期间 月期间 时分期间组件 日历期间、年期间、月期间及时分期间组件在不同的应用场景中发挥着重要的作用。这些组件通常用于表单、应用程序或网站中,以方便用户输入和选择特定的日期和时间范围。以下是这些组件的主要作用&a…...

GAMES101(10~11节,几何)
Geometry implicit隐式几何表示: 函数f(x,y,z): 根据函数fn描述几何,遍历所有空间内 的点,如果带入xyz到函数f(x,y,z)结果0那就绘制这个点 如果xyz求值结果>0表示在几何外,0在表面,<0在几何内 构造几何csg(…...

家电制造的隐形守护者:矫平机确保材料完美无瑕
在家电制造业中,产品的美观和耐用性是消费者选择的关键因素。然而,在生产过程中,材料的翘曲问题往往成为影响产品质量的隐形杀手。幸运的是,矫平机的出现,为家电制造商提供了一个有效的解决方案,确保每一件…...

软件设计师考纲及笔记
1. 计算机系统知识(分值占比:10%,重要程度:★★★★☆) 1.1 计算机系统基础 计算机组成: 中央处理器(CPU):计算机的核心部件,执行指令并处理数据。内存&…...
基于SpringCloud的微服务框架
1. 服务架构演变 1.1 单体架构 开发部署方便,维护扩展难。 1.2 垂直分割 将应用拆分成多个垂直部分,每一部分负责一组相关功能。 1.3 SOA(Service-Oriented Architecture) 面向服务的架构,引入了服务的概念。通过…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...
)
独家首发|DeepSeek官方未公开的IP检查API接口文档(含沙箱环境调用密钥获取路径)
更多请点击: https://kaifayun.com 第一章:DeepSeek知识产权检查 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder、DeepSeek-MoE)由深度求索(DeepSeek)公司自主研发,其权重、训练代码、推…...

别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次
别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次在Unity游戏开发中,性能优化是一个永恒的话题。尤其是使用URP(Universal Render Pipeline)进行开发时,相机的合理配…...

MPC Video Renderer技术解析:DirectShow硬件加速渲染器的实现原理与深度剖析
MPC Video Renderer技术解析:DirectShow硬件加速渲染器的实现原理与深度剖析 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer MPC Video Renderer是一款基于GPL v3协…...