GPT-4论文阅读
GPT-4 Technical Report论文阅读
文章目录
- GPT-4 Technical Report论文阅读
- Abstract
- 训练的稳定性
- Training process
- Predictable scaling
- 训练的稳定性多么难能可贵
- Capabilities
- 考试成绩
- 传统的benchmark
- 语言方面的能力
- Visual inputs
- Steerability
- Limitations
- Risks & mitigations
- 哪些工作可能会被GPT-4取代?
- 未来研究方向
官方博客地址:https://openai.com/research/gpt-4
Abstract
本篇虽然是GPT-4的技术报告,但其中没有提到GPT-4的具体模型架构与训练过程,主要就是讲他的结果。
- GPT-4是一个多模态的模型,能够接受文本或者是图片的输入,最后输出纯文本
- GPT-4基本能够达到类人的表现,在事实性、可控性和安全性上有了很大的进步
- GPT-4在真实世界中与人还是存在差距,但是在很多具有专业性或者学术性的数据集或者任务上面上,GPT-4有时候能够达到甚至超过人类的水平
- GPT-4能够通过律师考试资格证考试,且能在所有参加考试的人中排名前10%(GPT-3.5在同样的考试中无法通过,且只能排到最后10%)
训练的稳定性
在此次GPT-4的训练过程中,训练表现出了前所未有的稳定性
- 训练稳定
- 硬件设施没有出错
- 训练不会中断,一次训练直接跑到底
- loss没有跑飞
- 更重要的是,可以准确预测模型训练的结果(通过在小规模计算成本下训练出来的模型可以准确地预估扩大计算成本之后模型的最终性能)
对于大模型来讲,如果每次跑完训练才知道结果(参数的好坏,改进是否有效),花销比较大,一般会在较小的模型或者较小的数据集上做消融实验,验证之后再去大模型上进行实验。对于语言模型来讲,由于语言的扩展较大,所以导致在小规模模型上做的实验可能有效,但是换到大模型上就达不到想要的结果了;并且大模型上特有的涌现能力在小模型上无法观测。
Training process
与之前的GPT模型类似,GPT-4也是通过预测文章中下一个词的方式(Language Modeling Loss)去训练的,训练所用到的数据是公开数据(网络数据和公司所购买的数据)
- 数据集非常大,包含了非常多的内容,比如数学问题的正确的解和不正确的解、弱推理、强推理、自相矛盾或者保持一致的陈述、各种意识形态和想法,以及更多的纯文本数据
- 因为在大量的数据集上训练过,而且有的时候是在不正确的答案上训练过,所以预训练模型(Base Model)有些时候的回答跟想要得到的回答相差很远。为了能跟人的意图尽可能保持一致,并且更加安全可控,所以使用RLHF(Reinforcement Learning with Human Feedback)的方法对模型进行了微调
模型的能力看起来像是从预训练的过程中得到的,后续RLHF所进行的微调并不能够提高在考试中的成绩(如果没有好好调参,甚至会降低考试的成绩)
- 模型所谓的涌现的能力靠堆数据、堆算力,然后用简单的Language Modeling Loss堆出来的
但是,RLHF用来对模型做控制,让模型更加清楚人类的意图,并且按照人类所能接受的方式做出回答
- 这个预训练模型甚至需要prompt engineering才知道需要回答问题
Predictable scaling
GPT-4的关键问题在于如何构建深度学习的infrastructure,然后准确地进行扩大
- 训练的主要原因是在大模型上是不可能做大规模的模型调参的,首先需要很多的算力,其次需要很长的训练时间。如果增加训练机器的数量,训练的稳定性也不能保证,多机器的并行训练很容易导致Loss跑飞
OpenAI研发出来了一套整体的infrastructure和优化方法,可以在多个尺度上的实验上达到稳定预测
- 为了验证,利用内部的代码库在GPT-4模型刚开始训练的时候,就已经可以准确地预测到GPT-4最终训练完成的Loss(预测结果是由另外一个Loss外推出去的,用了比原始所需计算资源小一万倍的计算资源上用同样的计算方法训练出来的模型)

- 图中绿色的点是GPT-4最终的Loss的结果
- 纵坐标可以理解成Loss的大小,单位是Bits per word
- 横坐标表示所使用的算力(这里将数据集的大小、模型的大小全部混在一起,表示总体训练一个模型所需要的算力),越往左,模型的训练代价越小
- OpenAI通过将不同训练代价下的Loss点进行拟合,从而准确得到GPT-4最终的Loss
- 在同等的资源下,可以以更快的速度尝试更多的方法,最后得到更优的模型
下图也是类似,只是任务不同,但是得到的都是可预测的结果

但是还有一部分数据集是不能完全根据小模型预测的,如inverse scaling prize竞赛,专门给大模型找茬,用来测试是否存在一些任务是小模型做的好,大模型反而做不好的,而且最好能够找到那些任务(随着计算成本的增加,任务的结果越来越差,除了GPT-4)

- hindsight neglect:过去做一件事情的时候,使用很理性地判断做出一个决断,这个决断按道理来讲是正确的,但是运气不好导致最终的结果不是很好,那么如果回到过去,是继续选择当初选择的理性做法还是愿意赌一把选择一个更冒险的方式
- 按道理来讲,每次做选择都应该按照最理性的方式做选择,但是大模型在这种情况下出现了一个很有意思的现象:随着模型越来越大,反而越来越不理性,会根据最后的结果来判断到底应不应该做出决定
- GPT-4的准确度达到了100%,从侧面说明了可能GPT-4已经拥有了一定的推理能力,不会受到最后结果的影响
训练的稳定性多么难能可贵
斯坦福MLSYS 在MetaAi怎样用三个月的时间做了一个跟GPT-3同等大小的语言模型(OPT-175Billion)
- 地址:https://www.bilibili.com/video/BV1XT411v7c9?t=1283.6
- 模型虽然性能一般,但是整个过程干货比较多

- OPT-175Billion在整个一个多月的训练过程中,因为各种各样的原因(机器崩掉,网络中断、Loss跑飞等),中间一共中断了五十多次,图中的每一段不同颜色就代表跑的一段
- 训练一个大的模型的工程复杂度是难以想象的,所以GPT-4的成功除了大量算力的投入,还需要很多的工程上的努力
Capabilities
考试成绩
在日常对话中,GPT-3.5和GPT-4的区别是非常小的,但是这个区别随着任务难度的增加慢慢会体现出来
- GPT-4更加可靠,更加具有创造力,而且能够处理更加细微的人类的指示
为了弄清楚这两个模型之间的区别,OpenAI设计了一系列的benchmark,包含很多之前专门为人类设计的模拟考试,使用了最近公开的一些数据,比如奥赛题目、AP(美国高中的一些大学先修课中的问题、购买的执照考试的版权数据)。在这些考试上没有做过特殊的训练
- 可能有一些问题是之前在模型预训练的过程中被模型见过的,这里OpenAI为了澄清,他们跑了两个版本:一个版本是模型直接考试然后汇报分数;另一个版本虽然采用同样的模型,但是把在预训练数据集中出现的问题拿掉,只在那些模型可能没见过的问题上再做一次测试,最后取这两次的分钟较低的那一次来作为GPT-4的分数。希望这么做能更加具有说服力。
- 这里的问题去重并没有说明具体的方法
- GPT-4能在众多的考试中都取得较好的结果,说明其参加考试的能力还是不错的

- 柱状图是按照GPT-3.5的性能从低到高进行排列的
- GPT-3.5在最右侧的AP Environmental Science中表现是最好的
- 淡绿色(no vision)表示没有使用图片
- 图中可以看出GPT-4在有了图片加持之后,在有些考试上还能获得更大的进步
- 在AP Caculus BC、AMC12、Codeforces Rating、AMC10上表现较差,GPT系列在数学上的表现比较差
- 此外,虽然GPT-4能够修改文案,修改语法、润色文章,但是在高中英语文学课上以及高中英语语言本身的考试上得分都比较差。GPT系列的模型虽然能够生成大段大段的文字,但是它所写出来的东西很多时候就是翻来覆去地说话,都是一些空话大话,非常冠冕堂皇,并没有真正的思考,从而形成深刻的洞见
具体的考试结果如下图所示

- 在生物竞赛中,GPT-4的表现很好几乎是第一名
- 但是在 Codeforces Rating写代码测试中,GPT-4的表现并不如人意,甚至在某些情况下表现更差
传统的benchmark
GPT-4在传统的benchmark上的性能测试结果如下图所示,几乎刷新了之前的state-of-the-art

语言方面的能力
- GPT-4在多语言上已经做得很好了,不仅是英语语系中的各种语言,对中文的支持也是不错的(能够识别拼音的输入,简体/繁体的转换也能够处理)
- OpenAI为了进行测试,将MMLU全部进行了翻译(将14000多个多选题用微软的翻译全部翻译成不同的语言),通过测试发现,在26个语言中,其中24个语言中的测试结果GPT-4都要优于GPT-3.5和其他的一些大模型(Google的Chinchilla、PaLM),而且甚至在那些没有什么训练语料库的语言(Latvian、Welsh、Swahili)上表现也很好

Visual inputs
GPT-4是一个多模态的模型,可以接受图片作为输入
- GPT-4可以允许用户任意自定义视觉或者语言任务
- 不管用户输入的是文本、图片或者是图片和文本混合的形式,GPT-4都能生成文本(自然语言、代码)
- GPT-4在其他任务上的表现也很不错,尤其是test-time techniques
- 这是一个用VGA线给手机充电的图片,很多时候GPT-4都能给出解释,而且是一步一步的解释为什么搞笑

- 图中是一个截图,并不是机器能够直接阅读的,需要内部自己做一个OCR才能让模型知道图片中到底是什么内容(截图中是一道法语描述的物理题)GPT-4用英语进行了一步一步的解释,最后得出答案

- 将一篇论文直接输入进GPT-4,让它输出对论文的总结。GPT-4能够很好地总结所输入的论文

Steerability
定义语言模型的行为,让语言模型按照用户所想要的方式进行答复
- 相比于ChatGPT,ChatGPT的人格是固定的,每次都是同样的语调语气,回复的风格也是一致的;最新的GPT-4开发了一个新功能,除了发给它的prompt(描述用户需求的文字),前面添加了System Message
- System Message可以定义AI使用什么样的语气语调进行对话
作为一个苏格拉底式的辅导员,回复永远都应该是保持苏格拉底的风格,即永远不告诉学生真正的答案,而是询问一些启发式的问题,通过暗示来进行辅导让学生自己意识到问题的解决方式,从而培养学生自己解决问题的能力。在这个过程中,将难度较大的问题进行拆分,在学生能够听懂的水平上进行因材施教。

Limitations
- 在能力和局限性方面,GPT-4和之前的GPT系列模型差不多,还是不能完全可靠,有的时候还是会瞎编乱造,扭曲事实,并且推理的时候也可能会出错。因此在使用这些大模型的时候还是需要更加小心谨慎,尤其是在一些高风险的领域(法律、金融、新闻、政治)中
- 虽然这些问题依然存在,但是GPT-4跟之前其他的模型以及外面的模型相比,在安全性上已经大幅提高了
- 在OpenAI内部专门用来进行对抗性测试的Evaluation Benchmark上,GPT-4比之前的GPT-3.5的得分要高出40%以上,提升显著

图中纵坐标表示准确度,横坐标表示OpenAI内部所使用的benchmark所涉及的领域
-
GPT-4本身还会有各种各样的偏见,目前已经取得了一些进步,但是还有很多需要做的
-
GPT-4一般是缺少2021年9月份之后的知识,因为预训练数据就是截止到2021年9月份
- 但是ChatGPT有很多个版本,可能后续微调或者RLHF的时候,可能包含更新之后的数据,所以有时候也能正确回答2021年之后的一些问题
-
GPT-4在很多的领域里都表现出强大的能力,取得很高的分数,但是有时候会犯一些非常简单的推理错误,看上去有点不可思议
- 如果用户故意输入一些虚假的陈述,GPT-4还非常容易上当受骗
-
在一些特别困难的问题上,GPT-4跟人差不多,都会出现安全隐患,可能会写出不正确的代码。但是GPT-4哪怕有的时候预测错误了,也会非常自信
- 通过研究发现,这是因为经过预训练之后,GPT-4的model calibration做的非常完美(calibration可以理解为模型有多大的自信认为自己的预测是对的)

- 从图中能够看出,模型经过了完美的矫正,即模型对自己的预测越有信心,他的预测就越可能是正确的(可以因为预训练的语料库比较大,已经掌握了客观事实的规律,因此模型对自己产生的结果比较自信)
- 但是经过后处理(Instructed Tuning或者是RLHF)之后,calibration的效果就没有了,模型的校准就没有处理前好了(可能是经过RLHF之后,模型更接近于人,具备一定的主观性,因此校准性能就下降了)
Risks & mitigations
- Red Teaming
- 通过找各个领域的专家询问模型该问和不该问的问题,希望让模型知道哪些应该回答,哪些不该回答,通过人力的过程搜集数据,从而提升GPT-4的能力,能够拒绝不合理的要求
- GPT-4还利用自己来提升安全性的要求,在后续的RLHF的训练过程中,又新加了一个专门做安全的reward signal
- 这个reward signal是从自己已经预训练好的GPT-4模型开始,通过分类器分类当前prompt到底是不是sensitive,是不是存在危险,可能不应该进行回答
- 通过reward signal让RLHF更加智能,让模型更加贴合人的意图,而且更加安全
- 这种减少risk的方式能够显著提升GPT-4的安全性能,和GPT-3.5相比,对于那些不该回答的问题,GPT-4能比GPT-3.5少回答82%的问题
哪些工作可能会被GPT-4取代?
论文:GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
- 大概有80%的美国劳动力会因为大语言模型的到来而受到影响,大概是平时工作中10%的任务(剩余90%的任务仍然需要人来完成),19%的工人会发现有50%的工作有可能会被影响(AI至少能够完成50%以上的工作任务)
- 受影响比较少的工作,如果有做科研(基础科学研究)的能力或者思维比较缜密,能够快速做出合理的决定,这些技能点大语言模型暂时还不具备
- 受影响比较多的工作,和大语言模型冲突的技能点:写代码、写文章。凡是和这两个技能点相关的工作可能会收到较大的影响
即使有些工作不会被GPT-4取代,如服务员、泥瓦匠,但是也会被其他的AI机器人取代。所以这篇文章讲的不会受影响的工作也是相对的(所以没列出来)。
未来研究方向
现在机器学习还有很多的问题悬而未决,而且现在大语言模型遇到的问题其实跟30年前机器学习领域遇到的问题还是一样的,现在依然不知道大语言模型到底是怎样工作、怎么泛化的:
- 如何从单语言到多语言?
- 为什么会具有涌现的能力?
- 如何提高模型做推理的能力(尤其是做因果推理)?
- 需要更多的方式阻止语言模型生成有害的文字或者带来比较坏的社会影响
- 目前模型仅仅局限于文本,更多的问题都是在文本之外的,还有更多的模态等待探索
相关文章:
GPT-4论文阅读
GPT-4 Technical Report论文阅读 文章目录 GPT-4 Technical Report论文阅读 Abstract训练的稳定性Training processPredictable scaling训练的稳定性多么难能可贵 Capabilities考试成绩传统的benchmark语言方面的能力Visual inputsSteerability LimitationsRisks & mitigat…...

this 指向
this 指向谁? 多数情况下,this 指向调用它所在方法的那个对象。 说得更通俗点,谁调的函数,this 就归谁。当调用方法没有明确对象时,this 就指向全局对象。在浏览器中,指向 window;在 Node 中,指向 Global。(严格模式下,指向 undefined) this 的指向是在调用时决定的…...

【贪心算法】贪心算法一
贪心算法一 1.柠檬水找零2.将数组和减半的最少操作次数3.最大数4.摆动序列 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃😃 1.柠檬水找零 题目…...

windnd.hook_dropfiles中的create_buffer值太小无法拖放长文件名
今天在使用我之前的Python识别拖放的PDF文件再转成文本文件-CSDN博客发现,文件藏在路径太深入的地方,不能打开,因为拖放文件只能读取260个字节的文件名(b’路径),再查看windnd.hook_dropfiles函数ÿ…...

Gitlab runner的使用示例(二):Maven + Docker 自动化构建与部署
Gitlab runner的使用示例(二):Maven Docker 自动化构建与部署 在本篇文章中,我们将详细解析一个典型的 GitLab CI/CD 配置文件(gitlab-ci.yml),该文件主要用于通过 Maven 构建 Java 应用&…...
Linux Guest IPC 二)
QNX Hypervisor(十)Linux Guest IPC 二
上文还遗留了一个问题,就是在测试ipc的时候挂死了。相关原理我写在了另外一篇文章。 内存管理 所以导致挂死的问题就是因为没有进行地址映射,mmu无法转换。从kernel代码看,只有ram区域才会进行映射。我们的qvmconf文件也确实没有配置0xb8000000,只配置了pass。 pass loc …...
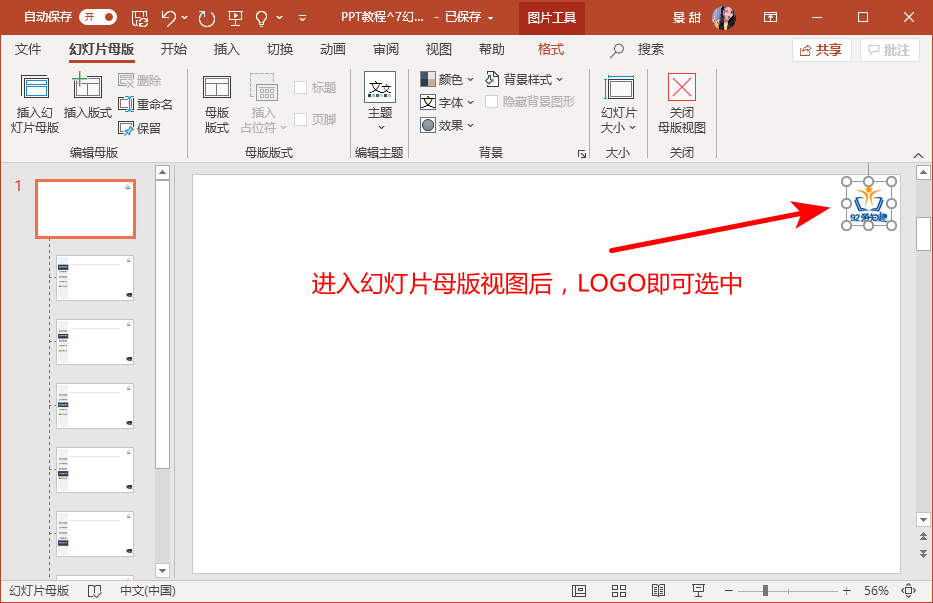
怎样把PPT上顽固的图标删了
例如: 解决: 首先打开下载好的PPT模板,然后在视图选项卡里面找到幻灯片母版。 进入幻灯片母版后,找到第一页母版页就会看到LOGO了,这时使用鼠标就可以选中删除啦。...

【论文阅读】Slim Fly: A Cost Effective Low-Diameter Network Topology 一种经济高效的小直径网络拓扑
文章目录 Slim Fly: A Cost Effective Low-Diameter Network Topology文章总结1. 摘要2. indroduction3. 主要工作 主要思想references Slim Fly: A Cost Effective Low-Diameter Network Topology Slim Fly:一种经济高效的小直径网络拓扑 SC’14 Maciej Besta 苏…...

Prometheus使用Pushgateway推送数据
Pushgateway简介 Prometheus 的 Pushgateway 是一个简单的 HTTP 服务器,它允许数据被推送到该服务器,而不是通过拉取的方式获取。它的存在是为了让临时和批处理作业能够将其指标暴露给 Prometheus。由于这类作业可能存在的时长不足以被主动抓取…...

【Oracle】调优与oracle最大连接数配置
博主介绍: 大家好,我是想成为Super的Yuperman,互联网宇宙厂经验,17年医疗健康行业的码拉松奔跑者,曾担任技术专家、架构师、研发总监负责和主导多个应用架构。 技术范围: 目前专注java体系,DDD&…...

Unity教程(十六)敌人攻击状态的实现
Unity开发2D类银河恶魔城游戏学习笔记 Unity教程(零)Unity和VS的使用相关内容 Unity教程(一)开始学习状态机 Unity教程(二)角色移动的实现 Unity教程(三)角色跳跃的实现 Unity教程&…...

图像超分辨率(ISR)
图像超分辨率(Image Super-Resolution, ISR)是一种图像处理技术,旨在通过软件算法从低分辨率的图像中重建出高分辨率的图像。这种技术对于改善图像质量、增加细节清晰度等方面非常重要,特别是在图像放大、卫星成像、医学成像和视频…...

园区网基础组网保姆级(mstp,vrrp,irf,eth-trunk,route-policy,ospf,bgp,rbm,nat,mlag等等)
本文实验使用模拟器:H3C HCL 5.10.2版本 一、园区核心/接入架构1.1.三层架构1.2.二层架构二、园区核心 To 接入实践2.1.MSTP+VRRP派系2.1.1.MSTP+VRRP配置2.1.2.MSTP+VRRP验证2.2.IRF+Eth-Trunk派系2.2.1.IRF+Eth-Trunk配置2.3.两种派系的对比2.4.VXLAN结构三、园区核心/出口架…...

大数据技术原理与应用
第一章、大数据概述 1、大数据时代的特征,并结合生活实例谈谈带来的影响。 (一)特征 1、Volume 规模性:数据量大。 2、Velocity高速性:处理速度快。数据的生成和响应快 摩尔定律:每两年,数…...

《黑神话悟空》开发框架与战斗系统解析
本文主要围绕《黑神话悟空》的开发框架与战斗系统解析展开 主要内容 《黑神话悟空》采用的技术栈 《黑神话悟空》战斗系统的实现方式 四种攻击模式 连招系统的创建 如何实现高扩展性的战斗系统 包括角色属性系统、技能配置文件和逻辑节点的抽象等关键技术点 版权声明 本…...

网络资源模板--Android Studio 通讯录App
目录 一、项目演示 二、项目测试环境 三、项目详情 四、完整的项目源码 一、项目演示 网络资源模板--基于Android studio 通讯录 二、项目测试环境 三、项目详情 首页 MainActivity 类是一个 Android 地址簿应用的核心部分,负责管理联系人列表的显示、搜索和添…...

Spring 出现 No qualifying bean of type ‘com.xxx‘ available 解决方法
目录 1. 问题所示2. 原理分析3. 解决方法4. 彩蛋4.1 bug彩蛋4.2 完整Demo4.3 补充Springboot1. 问题所示 出现如下问题: 19:58:23.476 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean o…...

C# 批量更改文件后缀名称
解决问题思路 解决固定文件夹下更改文件后缀名,采用轮询的方式, 流程如下: 获取当前文件名(带后缀的文件名)截取文件名称,去掉后缀另存为带更改后的后缀文件 注意:采用第三方插件࿰…...

KIC算法介绍及pyrosetta示例代码
Kinetic Loop Closure (KIC) 是 Rosetta 中一种重要的环区(loop region)建模算法,主要用于解决蛋白质中的柔性区域(特别是环区)的重构问题。环区是蛋白质中非常灵活的部分,通常结构不确定。KIC 算法采用基于运动学的解决方案,通过设置特定的几何约束,能够在给定的两端锚…...

【论文串烧】多媒体推荐中的模态平衡学习 | 音视频语音识别中丢失导致的模态偏差对丢失视频帧鲁棒性的影响
文章目录 一、多媒体推荐中的模态平衡学习1.1 研究背景1.2 解决问题1.3 实施方案1.4 文章摘要1.5 文章重点1.6 文章图示图 1:不同模型变体在 AmazonClothing 数据集上的初步研究图 2:CKD模型架构的说明图 3:在 Amazon-Clothing 数据集上训练过…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

Noto字体终极指南:告别“豆腐块“,让全球文字清晰显示
Noto字体终极指南:告别"豆腐块",让全球文字清晰显示 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在数字世界中,你是否经常看到那些令人困…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...