深度学习自编码器 - 收缩自编码器(CAE)篇
序言
在深度学习的浪潮中,收缩自编码器( Compressive Autoencoder, CAE \text{Compressive Autoencoder, CAE} Compressive Autoencoder, CAE)作为自编码器的一种高级形式,正逐步崭露头角。收缩自编码器在保留自编码器核心功能——即数据压缩与重构的基础上,引入了更为严格的压缩技术,以追求更低维且更具代表性的数据表示。这一特性使得收缩自编码器在数据降维、特征学习、降噪及高效信息处理等方面展现出独特的优势。本文将简要介绍收缩自编码器的概念、原理及其在实际应用中的潜力,以期为读者提供一个全面而深入的了解。
收缩自编码器(Compressive Autoencoder)
- 收缩自编码器( Rifai et al., 2011a,b \text{Rifai et al., 2011a,b} Rifai et al., 2011a,b) 在编码 h = f ( x ) \boldsymbol{h} = f(\boldsymbol{x}) h=f(x) 的基础上添加了显式的正则项,鼓励 f f f 的导数尽可能小:
Ω ( h ) = λ ∥ ∂ f ( x ) ∂ x ∥ F 2 \Omega(\boldsymbol{h})=\lambda\Vert\frac{\displaystyle\partial f(\boldsymbol{x})}{\partial \boldsymbol{x}}\Vert_F^2 Ω(h)=λ∥∂x∂f(x)∥F2 — 公式1 \quad\textbf{---\footnotesize{公式1}} —公式1 - 惩罚项 Ω ( h ) \Omega(\boldsymbol{h}) Ω(h) 为平方 Frobenius \text{Frobenius} Frobenius范数(元素平方之和),作用于与编码器的函数相关偏导数的 Jacobian \text{Jacobian} Jacobian矩阵。
- 去噪自编码器和收缩自编码器之间存在一定联系: Alain and Bengio (2013) \text{Alain and Bengio (2013)} Alain and Bengio (2013) 指出在小高斯噪声的限制下,当重构函数将 x \boldsymbol{x} x 映射到 r = g ( f ( x ) ) \boldsymbol{r} = g(f(\boldsymbol{x})) r=g(f(x)) 时,去噪重构误差与收缩惩罚项是等价的。换句话说, 去噪自编码器能抵抗小且有限的输入扰动,而收缩自编码器使特征提取函数能抵抗极小的输入扰动。
- 分类任务中,基于 Jacobian \text{Jacobian} Jacobian的收缩惩罚预训练特征函数 f ( x ) f(\boldsymbol{x}) f(x),将收缩惩罚应用在 f ( x ) f(\boldsymbol{x}) f(x) 而不是 g ( x ) ) g(\boldsymbol{x})) g(x)) 可以产生最好的分类精度。如
深度学习自编码器 - 去噪自编码器篇所讨论,应用于 f ( x ) f(\boldsymbol{x}) f(x)的收缩惩罚与得分匹配也有紧密的联系。 - 收缩 ( contractive \text{contractive} contractive) 源于 CAE \text{CAE} CAE弯曲空间的方式。具体来说,由于 CAE \text{CAE} CAE训练为抵抗输入扰动,鼓励将输入点邻域映射到输出点处更小的邻域。我们能认为这是将输入的邻域收缩到更小的输出邻域。
- 说得更清楚一点, CAE \text{CAE} CAE只在局部收缩——一个训练样本 x \boldsymbol{x} x 的所有扰动都映射到 f ( x ) f(\boldsymbol{x}) f(x) 的附近。
- 全局来看,两个不同的点 x \boldsymbol{x} x 和 x ′ \boldsymbol{x}^\prime x′ 会分别被映射到远离原点的两个点 f ( x ) f(\boldsymbol{x}) f(x) 和 f ( x ′ ) f(\boldsymbol{x}^\prime) f(x′)。
- f f f 扩展到数据流形的中间或远处是合理的(见
图例1中小例子的情况)。 - 当 Ω ( h ) \Omega(\boldsymbol{h}) Ω(h) 惩罚应用于 sigmoid \text{sigmoid} sigmoid单元时, 收缩 Jacobian \text{Jacobian} Jacobian的简单方式是令 sigmoid \text{sigmoid} sigmoid趋向饱和的 0 0 0 或 1 1 1。
- 这鼓励 CAE \text{CAE} CAE使用 sigmoid \text{sigmoid} sigmoid的极值编码输入点,或许可以解释为二进制编码。
- 它也保证了 CAE \text{CAE} CAE可以穿过大部分 sigmoid \text{sigmoid} sigmoid隐藏单元能张成的超立方体,进而扩散其编码值。
- 我们可以认为点 x \boldsymbol{x} x 处的 Jacobian \text{Jacobian} Jacobian矩阵 J \boldsymbol{J} J 能将非线性编码器近似为线性算子。这允许我们更形式地使用 “收缩’’ 这个词。
- 在线性理论中,当 J x \boldsymbol{J}\boldsymbol{x} Jx 的范数对于所有单位 x \boldsymbol{x} x 都小于等于 1 1 1 时, J \boldsymbol{J} J 被称为收缩的。
- 换句话说,如果 J \boldsymbol{J} J 收缩了单位球,他就是收缩的。
- 我们可以认为 CAE \text{CAE} CAE为鼓励每个局部线性算子具有收缩性,而在每个训练数据点处将 Frobenius \text{Frobenius} Frobenius范数作为 f ( x ) f(\boldsymbol{x}) f(x) 的局部线性近似的惩罚。
- 如
深度学习自编码器 - 使用自编码器学习流形篇中描述,正则自编码器基于两种相反的推动力学习流形。- 在 CAE \text{CAE} CAE的情况下,这两种推动力是重构误差和收缩惩罚 Ω ( h ) \Omega(\boldsymbol{h}) Ω(h))。
- 单独的重构误差鼓励 CAE \text{CAE} CAE学习一个恒等函数。
- 单独的收缩惩罚将鼓励 CAE \text{CAE} CAE学习关于 x \boldsymbol{x} x 是恒定的特征。
- 这两种推动力的的折衷产生导数 ∂ f ( x ) ∂ x \displaystyle\frac{\partial f(\boldsymbol{x})}{\partial \boldsymbol{x}} ∂x∂f(x) 大多是微小的自编码器。
- 只有少数隐藏单元,对应于一小部分输入数据的方向,可能有显著的导数。
- CAE \text{CAE} CAE的目标是学习数据的流形结构。
- 使 J x \boldsymbol{J}\boldsymbol{x} Jx 很大的方向 x \boldsymbol{x} x,会快速改变 h \boldsymbol{h} h,因此很可能是近似流形切平面的方向。
- Rifai et al. (2011a,b) \text{Rifai et al. (2011a,b)} Rifai et al. (2011a,b) 的实验显示训练 CAE \text{CAE} CAE会导致 J \boldsymbol{J} J 中大部分奇异值(幅值)比 1 1 1 小,因此是收缩的。
- 然而,有些奇异值仍然比 1 1 1大,因为重构误差的惩罚鼓励 CAE \text{CAE} CAE对最大局部变化的方向进行编码。
- 对应于最大奇异值的方向被解释为收缩自编码器学到的切方向。
- 理想情况下,这些切方向应对应于数据的真实变化。
- 比如,一个应用于图像的 CAE \text{CAE} CAE应该能学到显示图像改变的切向量,如
深度学习自编码器 - 使用自编码器学习流形篇 - 图例1图中物体渐渐改变状态。 - 如
图例1所示,实验获得的奇异向量的可视化似乎真的对应于输入图象有意义的变换。
- 收缩自编码器正则化准则的一个实际问题是,尽管它在单一隐藏层的自编码器情况下是容易计算的,但在更深的自编码器情况下会变的难以计算。
- 根据 Rifai et al. (2011a) \text{Rifai et al. (2011a)} Rifai et al. (2011a) 的策略,分别训练一系列单层的自编码器,并且每个被训练为重构前一个自编码器的隐藏层。
- 这些自编码器的组合就组成了一个深度自编码器。
- 因为每个层分别训练成局部收缩,深度自编码器自然也是收缩的。
- 这个结果与联合训练深度模型完整架构(带有关于 Jacobian \text{Jacobian} Jacobian的惩罚项)获得的结果是不同的,但它抓住了许多理想的定性特征。
- 另一个实际问题是,如果我们不对解码器强加一些约束,收缩惩罚可能导致无用的结果。
- 例如 编码器将输入乘一个小常数 ϵ \epsilon ϵ, 解码器将编码除以一个小常数 ϵ \epsilon ϵ。
- 随着 ϵ \epsilon ϵ 趋向于 0 0 0, 编码器会使收缩惩罚项 Ω ( h ) \Omega(\boldsymbol{h}) Ω(h) 趋向于 0 0 0 而学不到任何关于分布的信息。
- 同时, 解码器保持完美的重构。
- Rifai et al. (2011a) \text{Rifai et al. (2011a)} Rifai et al. (2011a) 通过绑定 f f f 和 g g g 的权重来防止这种情况。
- f f f 和 g g g 都是由线性仿射变换后进行逐元素非线性变换的标准神经网络层组成,因此将 g g g 的权重矩阵设成 f f f 权重矩阵的转置是很直观的。
- 图例1:通过局部PCA和收缩自编码器估计的流形切向量的图示。
-
通过局部PCA和收缩自编码器估计的流形切向量的图示。

-
说明:
- 流形的位置由来自 CIFAR-10 \text{CIFAR-10} CIFAR-10数据集中狗的输入图像定义。
- 切向量通过输入到代码映射的 Jacobian \text{Jacobian} Jacobian矩阵 ∂ h ∂ x \frac{\partial \boldsymbol{h}}{\partial \boldsymbol{x}} ∂x∂h 的前导奇异向量估计。
- 虽然局部 PCA \text{PCA} PCA和 CAE \text{CAE} CAE都可以捕获局部切方向,但 CAE \text{CAE} CAE能够从有限训练数据形成更准确的估计,因为它利用了不同位置的参数共享(共享激活的隐藏单元子集)。
- CAE \text{CAE} CAE切方向通常对应于物体的移动或改变部分(例如头或腿)。
- 经 Rifai et al. (2011c) \text{Rifai et al. (2011c)} Rifai et al. (2011c) 许可转载此图。
-
总结
收缩自编码器通过其高效的压缩机制,实现了对输入数据更为紧凑和精确的特征提取。相比传统自编码器,收缩自编码器在保持数据质量的同时,进一步降低了数据维度,减少了存储和传输的开销,提高了计算效率。此外,其强大的降噪和特征学习能力,使得收缩自编码器在数据预处理、特征工程及异常检测等领域具有广泛的应用前景。随着深度学习技术的不断发展,收缩自编码器将持续进化,为更多复杂数据的处理与分析提供有力支持。
往期内容回顾
深度学习自编码器 - 去噪自编码器篇
深度学习自编码器 - 使用自编码器学习流形篇
相关文章:
深度学习自编码器 - 收缩自编码器(CAE)篇
序言 在深度学习的浪潮中,收缩自编码器( Compressive Autoencoder, CAE \text{Compressive Autoencoder, CAE} Compressive Autoencoder, CAE)作为自编码器的一种高级形式,正逐步崭露头角。收缩自编码器在保留自编码器核心功能—…...

Dubbo与SpringCloud的区别和优缺点
经常会有同学问我,Dubbo和SpringCloud的选择。甚至也经常会有面试官就这个问题刨根问底。 说实话,其实我不太喜欢回答这个问题,本质上来讲,Dubbo的SpringCloud可以算是完全不同赛道的两种东西,就好像问大家西瓜和土豆我…...

★ C++进阶篇 ★ 多态
Ciallo~(∠・ω< )⌒☆ ~ 今天,我将继续和大家一起学习C进阶篇第二章----多态 ~ ❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️ 澄岚主页:椎名澄嵐-CSDN博客 C基础篇专栏:★ C基础篇 ★_椎名澄嵐的博客-CSDN博客 …...

pg入门3—详解tablespaces2
pg默认的tablespace的location为空,那么如果表设置了默认的tablespace,数据实际上是存哪个目录的呢? 在 PostgreSQL 中,如果你创建了一个表并且没有显式指定表空间(tablespace),或者表空间的 location 为…...

python 爬虫 selenium 笔记
todo 阅读并熟悉 Xpath, 这个与 Selenium 密切相关、 selenium selenium 加入无图模式,速度快很多。 from selenium import webdriver from selenium.webdriver.chrome.options import Options# selenium 无图模式,速度快很多。 option Options() o…...

git分支管理的一些常用规范
一、分支命名规范 1.通常项目经理或者需求方会给需求开发做计划,约定一些编码,例如FN-01。此时这个需求指派给你,这个时候你可以在现有代码仓库的maser分支或者其他约定的开发分支checkout到本地,命名这个需求的开发分支为feat/F…...

GPT-4论文阅读
GPT-4 Technical Report论文阅读 文章目录 GPT-4 Technical Report论文阅读 Abstract训练的稳定性Training processPredictable scaling训练的稳定性多么难能可贵 Capabilities考试成绩传统的benchmark语言方面的能力Visual inputsSteerability LimitationsRisks & mitigat…...

this 指向
this 指向谁? 多数情况下,this 指向调用它所在方法的那个对象。 说得更通俗点,谁调的函数,this 就归谁。当调用方法没有明确对象时,this 就指向全局对象。在浏览器中,指向 window;在 Node 中,指向 Global。(严格模式下,指向 undefined) this 的指向是在调用时决定的…...

【贪心算法】贪心算法一
贪心算法一 1.柠檬水找零2.将数组和减半的最少操作次数3.最大数4.摆动序列 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃😃 1.柠檬水找零 题目…...

windnd.hook_dropfiles中的create_buffer值太小无法拖放长文件名
今天在使用我之前的Python识别拖放的PDF文件再转成文本文件-CSDN博客发现,文件藏在路径太深入的地方,不能打开,因为拖放文件只能读取260个字节的文件名(b’路径),再查看windnd.hook_dropfiles函数ÿ…...

Gitlab runner的使用示例(二):Maven + Docker 自动化构建与部署
Gitlab runner的使用示例(二):Maven Docker 自动化构建与部署 在本篇文章中,我们将详细解析一个典型的 GitLab CI/CD 配置文件(gitlab-ci.yml),该文件主要用于通过 Maven 构建 Java 应用&…...
Linux Guest IPC 二)
QNX Hypervisor(十)Linux Guest IPC 二
上文还遗留了一个问题,就是在测试ipc的时候挂死了。相关原理我写在了另外一篇文章。 内存管理 所以导致挂死的问题就是因为没有进行地址映射,mmu无法转换。从kernel代码看,只有ram区域才会进行映射。我们的qvmconf文件也确实没有配置0xb8000000,只配置了pass。 pass loc …...
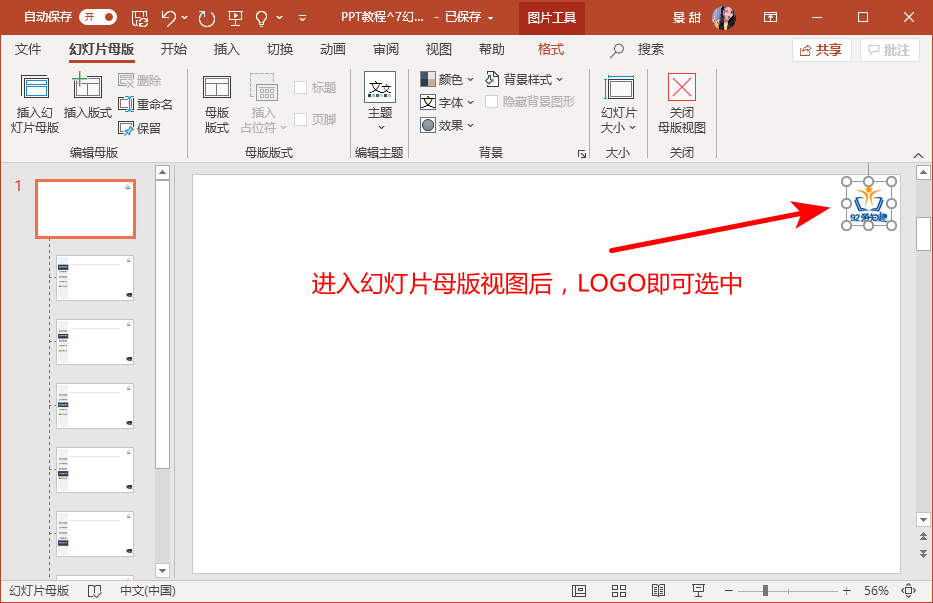
怎样把PPT上顽固的图标删了
例如: 解决: 首先打开下载好的PPT模板,然后在视图选项卡里面找到幻灯片母版。 进入幻灯片母版后,找到第一页母版页就会看到LOGO了,这时使用鼠标就可以选中删除啦。...

【论文阅读】Slim Fly: A Cost Effective Low-Diameter Network Topology 一种经济高效的小直径网络拓扑
文章目录 Slim Fly: A Cost Effective Low-Diameter Network Topology文章总结1. 摘要2. indroduction3. 主要工作 主要思想references Slim Fly: A Cost Effective Low-Diameter Network Topology Slim Fly:一种经济高效的小直径网络拓扑 SC’14 Maciej Besta 苏…...

Prometheus使用Pushgateway推送数据
Pushgateway简介 Prometheus 的 Pushgateway 是一个简单的 HTTP 服务器,它允许数据被推送到该服务器,而不是通过拉取的方式获取。它的存在是为了让临时和批处理作业能够将其指标暴露给 Prometheus。由于这类作业可能存在的时长不足以被主动抓取…...

【Oracle】调优与oracle最大连接数配置
博主介绍: 大家好,我是想成为Super的Yuperman,互联网宇宙厂经验,17年医疗健康行业的码拉松奔跑者,曾担任技术专家、架构师、研发总监负责和主导多个应用架构。 技术范围: 目前专注java体系,DDD&…...

Unity教程(十六)敌人攻击状态的实现
Unity开发2D类银河恶魔城游戏学习笔记 Unity教程(零)Unity和VS的使用相关内容 Unity教程(一)开始学习状态机 Unity教程(二)角色移动的实现 Unity教程(三)角色跳跃的实现 Unity教程&…...

图像超分辨率(ISR)
图像超分辨率(Image Super-Resolution, ISR)是一种图像处理技术,旨在通过软件算法从低分辨率的图像中重建出高分辨率的图像。这种技术对于改善图像质量、增加细节清晰度等方面非常重要,特别是在图像放大、卫星成像、医学成像和视频…...

园区网基础组网保姆级(mstp,vrrp,irf,eth-trunk,route-policy,ospf,bgp,rbm,nat,mlag等等)
本文实验使用模拟器:H3C HCL 5.10.2版本 一、园区核心/接入架构1.1.三层架构1.2.二层架构二、园区核心 To 接入实践2.1.MSTP+VRRP派系2.1.1.MSTP+VRRP配置2.1.2.MSTP+VRRP验证2.2.IRF+Eth-Trunk派系2.2.1.IRF+Eth-Trunk配置2.3.两种派系的对比2.4.VXLAN结构三、园区核心/出口架…...

大数据技术原理与应用
第一章、大数据概述 1、大数据时代的特征,并结合生活实例谈谈带来的影响。 (一)特征 1、Volume 规模性:数据量大。 2、Velocity高速性:处理速度快。数据的生成和响应快 摩尔定律:每两年,数…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...