NLP开端:Tokenizer-文本向量化
Tokenizer
问题背景
An was a algorithm engineer
如上所示,在自然语言处理任务中,通常输入处理的数据是原始文本。但是算法模型自能处理数值类型,因此需要找到一种方法,将原始的文本数据转换为数值类型的数据。这就是分词器所解决的问题,分词器的目标是找到文本最有意义的、最小的表示方法
分词器(Tokenizer)是 NLP 管道的核心组件之一。它们有一个目的:将文本转换为模型可以处理的数据。模型只能处理数字,因此分词器(Tokenizer)需要将我们的文本输入转换为数字数据。
Tokenizer处理流程
-
Input text data:
An was a algorithm engineer -
String Tokenizer: 切分以上文本数据;
-
Output:
Anwasaalgorithmengineer
以上过程称为Tokenization
分词方法分类
-
Word-based:
-
按单词划分(tokenize on word)
-
按标点符号划分(tokenize on punctuation)
-
按空格划分(tokenize on white spaces)。
-
Character-based
-
Subword tokenization
-
Byte-level BPE, 用于 GPT-2
-
WordPiece, 用于 BERT
-
SentencePiece or Unigram, 用于多个多语言模型
基于词的(Word-based)
最简单直接的分词器是基于词的(word-based)分词方法。它简单易用,只需几条规则,并且通常会产生不错的结果。例如,将以下内容进行tokenize:
I'm an algorithm engineer, and my skills are awesome.
有多种拆分文本的方法。
仅基于单词空格的方法(Tokenize on whit spaces)
可以通过应用Python的split()函数,使用空格将文本标记为单词:
ttokenized_text = "I'm an algorithm engineer, and my skills are awesome.".split()
print("Tokenize on whit spaces:",tokenized_text)- output
Tokenize on whit spaces: `I'm ` `an` `algorithm` `engineer,` `and` `my` `skills` `are` `awesome.`
按标点符号划分(tokenize on punctuation)
还有一些单词分词器的变体,它们具有额外的标点符号规则。 例如:
-
Tokenize on punctuation:
I'misanalgorithmengineer,andmyskillsareawesome.使用这种分词器,我们最终可以得到一些非常大的“词汇表”,其中词汇表由我们在语料库中拥有的独立标记的总数定义。 -
Tokenize on word:
I'misanalgorithmengineer,andmyskillsareawesome.
以上的分词方法虽然有一些微小的差别,但是区别都不大,属于传统经典的分词方法。但是不同的分词方法会有不同的分词结果。
word-base tokenizer方法分析
每个单词都分配了一个 ID,从 0 开始一直到词汇表vocabularies的大小。该模型使用这些 ID 来识别每个单词。
如果用基于单词的分词器(tokenizer)完全覆盖一种语言,需要为语言中的每个单词都有一个标识符,这将生成大量的tokens。例如:
-
英语中有超过 500,000 个单词,因此要构建从每个单词到输入 ID 的映射,需要跟踪这么多 ID。
-
此外,诸如英文单词中的多种形态:
像“dog”与“dogs”、"look"衍生出的"looks", "looking", "looked、old, older, oldest 之间的关系到 smart, smarter, smartest…,这样的词,虽然表示方式不同,但其有一定的相互关系。 -
但是word-base tokenizer方法会将这些形态相似的词组识别为不相关。
-
最后,对于unknown token需要自定义一个token来表示不在词汇表中的单词,被称为“未知”标记(token)。通常表示为“[UNK]”或”“。如果分词器产生了很多这样的token,表明它无法检索到一个词的合理表示,并且在这个过程中丢失信息。制作词汇表时的目标是将未知token标记的尽可能少。
因此 word-base tokenizer方法的缺点是:
-
对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理(未知符号标记为 [UNK])。
-
词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)。
-
很多语言难以用空格进行分词,例如英语单词的多形态,“look"衍生出的"looks”, “looking”, “looked”,其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过 old, older, oldest 之间的关系学到 smart, smarter, smartest 之间的关系。
-
这一方面增加了训练冗余
-
另一方面也造成了大词汇量问题。
减少未知标记数量的一种方法是使用更深一层的分词器(tokenizer),即基于字符的(character-based)分词器(tokenizer)。
基于字符(Character-based)
基于字符的分词器(tokenizer)将文本拆分为字符和特殊符号,而不是单词。例如:将文本I'm an algorithm engineer, and my skills are awesome.内容进行tokenize:
-
Add special sapce symbol"/":
Im/an/algorithm/engineer,/and/my/skills/are/awesome. -
Ignore some symbols:
Imanalgorithmengineerandmyskillsareawesome. -
Ignore some symbols:
I'manalgorithmengineer,andmyskillsareawesome.
因此Character_based方法同时能解决能解决 OOV 问题,也避免了大词汇量问题,即:
-
词汇量要小得多。
-
词汇外(未知)标记(token)要少得多,因为每个单词都可以从字符构建。
这种方法缺点很明显:粒度太细,训练花费的成本太高。由于现在表示是基于字符而不是单词,因此有人会说:“从直觉上讲,它的意义不大:每个字符本身并没有多大意义,而单词就是这种情况。” 然而,这又因语言而异;例如,在中文中,每个字符比拉丁语言中的字符包含更多的信息。
另一件要考虑的事情是,模型会处理大量的tokens:虽然使用基于单词的分词器(tokenizer),单词只会是单个标记,但当转换为字符时,它很容易变成 10 个或更多的tokens。
为了两全其美,可以使用结合word-based和character-based两种方法的第三种技术:子词标记化(subword tokenization)。
子词标记化(subword tokenization)
子词分词算法的原则是不应将常用词拆分为更小的子词,而应将稀有词分解为有意义的子词。目的是通过一个有限的词表来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低
例如
-
“annoyingly”可能被认为是一个罕见的词,可以分解为
annoyingly。这两者都可能作为独立的子词出现得更频繁,同时“annoyingly”的含义由“annoying”和“ly”的复合含义保持。 -
“unfortunately” =
un+for+tun+ate+ly。
由此可见,subword有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。
再比如:子词标记化算法如何标记序列Let’s do tokenization!:Let's do token ization !
这些子词最终提供了很多语义含义:例如,在上面的示例中,“tokenization”被拆分为“token”和“ization”,这两个具有语义意义同时节省空间的词符(token)(只需要两个标记(token)代表一个长词)。这使我们能够对较小的词汇表进行相对较好的覆盖,并且几乎没有未知的标记
这种方法在土耳其语等粘着型语言(agglutinative languages)中特别有用,您可以通过将子词串在一起来形成(几乎)任意长的复杂词。
-
subword的基本切分原则是:
-
高频词依旧切分成完整的整词
-
低频词被切分成有意义的子词,例如 dogs => [dog, ##s]
-
基于subword的切分可以实现:
-
词表规模适中,解码效率较高
-
不存在UNK,信息不丢失
-
能学习到词缀之间的关系
基于subword的切分包括三种分词模型:
-
BPE及Byte-level BPE, 用于 GPT-2
-
WordPiece
-
SentencePiece or Unigram, 用于多个多语言模型Unigram
字节对编码(BPE, Byte Pair Encoding)
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,是一种数据压缩算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前是最广泛采用的subword分词器。
BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
BPE 在分词中的算法过程:
-
算法过程准备语料库,确定期望的 subword 词表大小等参数
-
通常在每个单词末尾添加后缀
</w>,统计每个单词出现的频率,例如,low的频率为 5,那么我们将其改写为l o w </ w>:5注:停止符
</w>的意义在于标明 subword 是词后缀。举例来说:st 不加</w>可以出现在词首,如st ar;加了</w>表明该子词位于词尾,如we st</w>,二者意义截然不同 -
将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的 subword 的粒度是字符
-
挑出频次最高的符号对,比如说
t和h组成的th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有t和h都变为th。注:新字符依然可以参与后续的 merge,有点类似哈夫曼树,BPE 实际上就是一种贪心算法 。
-
重复遍历
2和3操作,直到词表中单词数达到设定量 或下一个最高频数为 1,如果已经达到设定量,其余的词汇直接丢弃注:看似我们要维护两张表,一个词表,一个字符表,实际上只有一张,词表只是为了我们方便理解。
-
训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
-
编码方法:将文本切分成字符,再应用训练阶段获得的合并规则
-
经典模型:GPT, GPT-2, RoBERTa, BART, LLaMA, ChatGLM等
例如
-
获取语料库,这样一段话为例:“ FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models. ”
-
拆分,加后缀,统计词频:
| WORD | FREQUENCY | WORD | FREQUENCY |
|---|---|---|---|
d e e p </w> | 3 | b u i l d </w> | 1 |
l e a r n i n g </w> | 3 | t r a i n </w> | ` |
t h e </w> | 2 | a n d </w> | 1 |
m o d e l s </w> | 2 | d e p l o y </w> | 1 |
F l o y d h u b </w> | 1 | ||
B u i l d </w> | |||
i s </w> | 1 | m o d e l s </w> | 1 |
f a s t e s t </w> | 1 | i n </w> | 1 |
w a y </w> | 1 | c l o u d </w> | 1 |
t o </w> | 1 | T r a i n </w> | 1 |
- 建立词表,统计字符频率,并排序:
| NUMBER | TOKEN | FREQUENCY | NUMBER | TOKEN | FREQUENCY |
|---|---|---|---|---|---|
| 1 | </w> | 24 | 15 | g | 3 |
| 2 | e | 16 | 16 | m | 3 |
| 3 | d | 12 | 17 | . | 3 |
| 4 | l | 11 | 18 | b | 2 |
| 5 | n | 10 | 19 | h | 2 |
| 6 | i | 9 | 20 | F | 1 |
| 7 | a | 8 | 21 | H | 1 |
| 8 | o | 22 | f | 1 | |
| 9 | s | 23 | w | 1 | |
| 10 | t | 24 | , | 1 | |
| 11 | r | 25 | B | 1 | |
| 12 | u | 26 | c | 1 | |
| 13 | p | 27 | T | 1 | |
| 14 | y | ||||
- 以第一次迭代为例,将字符频率最高的
d和e替换为de,后面依次迭代:
| NUMBER | TOKEN | FREQUENCY | NUMBER | TOKEN | FREQUENCY |
|---|---|---|---|---|---|
| 1 | </w> | 24 | 16 | g | 3 |
| 2 | e | 16-7=9 | 17 | m | 3 |
| 3 | d | 12-7=5 | 18 | . | 3 |
| 4 | l | 11 | 19 | b | 2 |
| 5 | n | 10 | 20 | h | 2 |
| 6 | i | 9 | 21 | F | 1 |
| 7 | a | 8 | 22 | H | 1 |
| 8 | o | 23 | f | 1 | |
9 | de | 7 | 24 | w | 1 |
| 10 | s | 25 | , | 1 | |
| 11 | t | 26 | B | 1 | |
| 12 | r | 27 | c | 1 | |
| 13 | u | 28 | T | 1 | |
| 14 | p | ||||
| 15 | y | ||||
- 更新词汇表
| WORD | FREQUENCY | WORD | FREQUENCY |
|---|---|---|---|
de e p </w> | 3 | b u i l d </w> | 1 |
l e a r n i n g </w> | 3 | t r a i n </w> | ` |
t h e </w> | 2 | a n d </w> | 1 |
m o de l s </w> | 2 | de p l o y </w> | 1 |
F l o y d h u b </w> | 1 | ||
B u i l d </w> | |||
i s </w> | 1 | m o de l s </w> | 1 |
f a s t e s t </w> | 1 | i n </w> | 1 |
w a y </w> | 1 | c l o u d </w> | 1 |
t o </w> | 1 | T r a i n </w> | 1 |
继续迭代直到达到预设的 subwords 词表大小或下一个最高频的字节对出现频率为 1。
如果将词表大小设置为 10,最终的结果为:
d e
r n
rn i
rni n
rnin g</w>
o de
ode l
m odel
l o
l e
这样就得到了更加合适的词表,这个词表可能会出现一些不是单词的组合,但是其本身有意义的一种形式
BPE 的优点
上面例子中的语料库很小,知识为了方便理解 BPE 的过程,但实际中语料库往往非常非常大,无法给每个词(token)都放在词表中。BPE 的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的 token 数量)。
随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
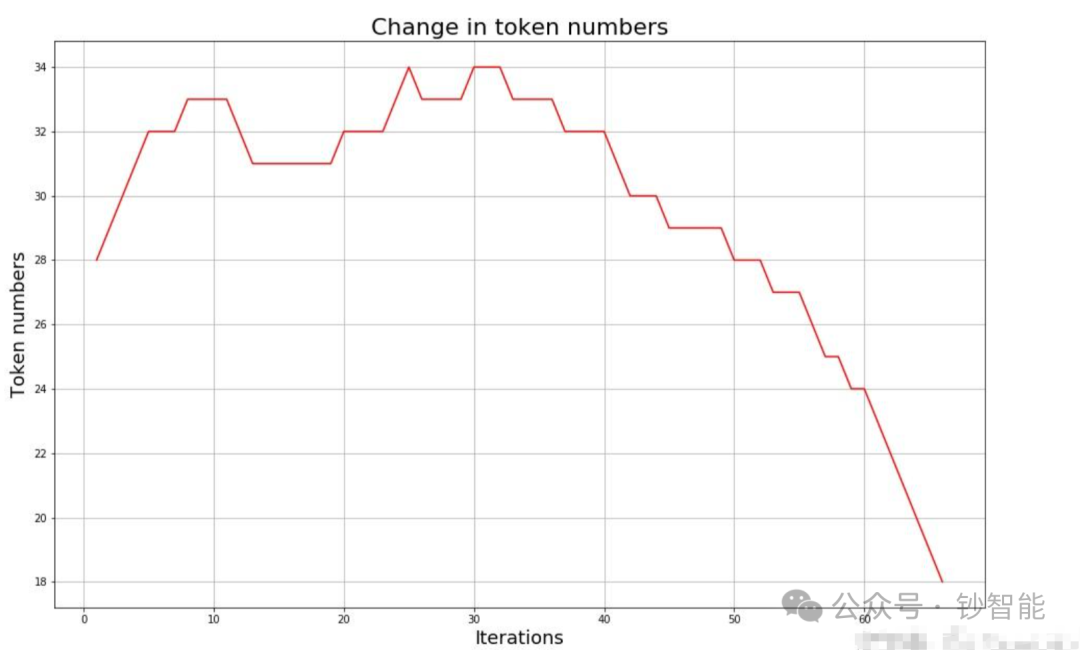
BPE 的缺点
-
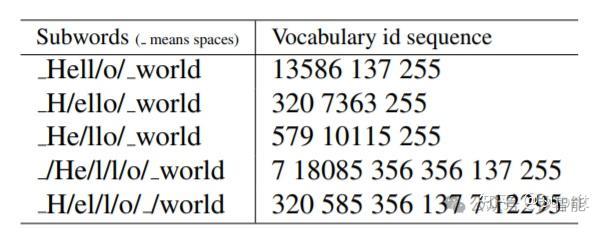
对于同一个句子, 可能会有不同的 Subword 序列。
-
例如 Hello world,如图所示,。不同的 Subword 序列会产生完全不同的 id 序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的 id 序列可能翻译出不同的句子,这显然是错误的。
-
-
在训练任务中,如果能对不同的 Subword 进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而 BPE 的贪心算法无法对随机分布进行学习。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

BPE 的适用范围
BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。
而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种:
-
理论上分词效果更好,更好的区别语义。
-
分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
BPE实现
import re, collectionsdef get_vocab(filename):vocab = collections.defaultdict(int)with open(filename, 'r', encoding='utf-8') as fhand:for line in fhand:words = line.strip().split()for word in words:vocab[' '.join(list(word)) + ' </w>'] += 1return vocabdef get_stats(vocab):pairs = collections.defaultdict(int)for word, freq in vocab.items():symbols = word.split()for i in range(len(symbols)-1):pairs[symbols[i],symbols[i+1]] += freqreturn pairsdef merge_vocab(pair, v_in):v_out = {}bigram = re.escape(' '.join(pair))p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')for word in v_in:w_out = p.sub(''.join(pair), word)v_out[w_out] = v_in[word]return v_outdef get_tokens(vocab):tokens = collections.defaultdict(int)for word, freq in vocab.items():word_tokens = word.split()for token in word_tokens:tokens[token] += freqreturn tokensif __name__=="__main__":vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}print('==========')print('Tokens Before BPE')tokens = get_tokens(vocab)print('Tokens: {}'.format(tokens))print('Number of tokens: {}'.format(len(tokens)))print('==========')num_merges = 5for i in range(num_merges):pairs = get_stats(vocab)if not pairs:breakbest = max(pairs, key=pairs.get)vocab = merge_vocab(best, vocab)print('Iter: {}'.format(i))print('Best pair: {}'.format(best))tokens = get_tokens(vocab)print('Tokens: {}'.format(tokens))print('Number of tokens: {}'.format(len(token)))
Byte-level BPE
BPE的一个问题是,如果遇到了unicode,基本字符集可能会很大。Byte-level BPE是以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256。 例如,像GPT-2的词汇表大小为50257 = 256 + <EOS> + 50000 mergers,<EOS>是句子结尾的特殊标记。
2019年提出的Byte-level BPE (BBPE)算法是上面BPE算法的进一步升级。具体参见:Neural Machine Translation with Byte-Level Subwords。 核心思想是用byte来构建最基础的词表而不是字符。首先将文本按照UTF-8进行编码,每个字符在UTF-8的表示中占据1-4个byte。 在byte序列上再使用BPE算法,进行byte level的相邻合并。编码形式如下图所示:

通过这种方式可以更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的BPE更节省词表空间(同等词表大小效果更好),每个token也能获得更充分的训练。
但是在解码阶段,一个byte序列可能解码后不是一个合法的字符序列,这里需要采用动态规划的算法进行解码,使其能解码出尽可能多的合法字符。具体算法如下: 算法如下:对于给定的字节序列,从中恢复的最大字符数表示为。则 具有最优的子结构,可以通过动态规划求解有最优的子结构:
其中 如果, 则 对应于有效字符,否则为,。当 递归计算时,还记录每个位置 的选择,以便我们可以通过回溯来恢复解决方案。UTF-8 编码的设计确保了此恢复过程的唯一性:对于使用多个字节编码的字符 UTF-8,其尾随字节不会成为有效的 UTF-8 编码字符。那么Eq 1 中的最佳选择是唯一的,最终解决方案也是如此。
WordPiece
WordPiece分词与BPE非常类似,只是在训练阶段合并pair的策略不是pair的频率而是互信息。
这里的动机是一个pair的频率很高,但是其中pair的一部分的频率更高,这时候不一定需要进行该pair的合并。 而如果一个pair的频率很高,并且这个pair的两个部分都是只出现在这个pair中,就说明这个pair很值得合并。
-
训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
-
编码方法:将文本切分成词,对每个词在词表中进行最大前向匹配
-
经典模型:BERT及其系列DistilBERT,MobileBERT等
Unigram
Unigram分词与BPE和WordPiece不同,是基于一个大词表逐步裁剪成一个小词表。 通过Unigram语言模型计算删除不同subword造成的损失来衡量subword的重要性,保留重要性较高的子词。
-
训练方法:从包含字符和全部子词的大词表出发,逐步裁剪出一个小词表,并且每个词都有自己的分数。
-
编码方法:将文本切分成词,对每个词基于Viterbi算法求解出最佳解码路径。
-
经典模型:AlBERT, T5, mBART, Big Bird, XLNet
SentencePiece
SentencePiece是Google出的一个分词工具:
-
内置BPE,Unigram,char和word的分词方法
-
无需预分词,以unicode方式直接编码整个句子,空格会被特殊编码为▁
-
相比传统实现进行优化,分词速度速度更快
transformers中使用Tokenizer类
Loading and saving
加载和保存分词器(tokenizer)就像使用模型一样简单。两种方法: from_pretrained() 和 save_pretrained() ,将加载或保存分词器(tokenizer)使用的算法(有点像model的architecture)以及它的词汇(有点像model的weights)。
加载使用与 BERT 相同的检查点训练的 BERT 分词器(tokenizer)与加载模型的方式相似,使用 BertTokenizer 类:
from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("bert-base-cased")
如同 AutoModel,AutoTokenizer 类将根据检查点名称在库中获取正确的分词器(tokenizer)类,并且可以直接与任何检查点一起使用:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
使用分词器(tokenizer):
tokenizer("Using a Transformer network is simple")
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
保存分词器(tokenizer)与保存模型相同:
tokenizer.save_pretrained("directory_on_my_computer")
我们在Chapter 3中将更多地谈论token_type_ids,稍后我们将解释 attention_mask 键。首先,让我们看看 input_ids 如何生成。为此,我们需要查看分词器(tokenizer)的中间方法。
Encoding
将文本翻译成数字被称为编码(encoding).编码分两步完成:标记化,然后转换为输入 ID。
-
第一步是将文本拆分为单词(或单词的一部分、标点符号等),称为
token。有多个规则可以执行该过程,如BPE、WordPiece、SentencePiece or Unigram,这就是为什么我们需要使用模型名称来实例化分词器(tokenizer),以确保我们使用模型预训练时使用的相同规则。 -
第二步是将这些
token转换为数字,就可以用它们构建一个张量并输入给模型。为此,分词器(tokenizer)有一个**词汇表(vocabulary)**,这是在实例化from_pretrained()时下载的。同样,需要使用模型预训练时使用的相同vocabulary。
Tokenization
标记化过程由分词器(tokenizer)的tokenize() 方法实现:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)print(tokens)
此方法的输出是一个字符串列表或标记(token):
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
这个分词器(tokenizer)是一个subword tokenizer:它对词进行拆分,直到获得可以用其词汇表表示的token。transformer 就是这种情况,它分为两个标记:transform 和 ##er。
从tokens到输入 ID
输入 ID 的转换由分词器(tokenizer)的convert_tokens_to_ids()方法实现:
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
Output:
[7993, 170, 11303, 1200, 2443, 1110, 3014]
这些输出一旦转换为适当的框架张量,就可以用作模型的输入。
Decode
解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。 如果仍然有子字符串没被替换但所有 token 都已迭代完毕,则将剩余的子词替换为特殊 token,如 <unk>解码(Decoding):从词汇索引中,想要得到一个字符串。这可以通过 decode() 方法实现,如下:
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
'Using a Transformer network is simple'
请注意, decode 方法不仅将索引转换回标记(token),还将属于相同单词的标记(token)组合在一起以生成可读的句子。当我们使用预测新文本的模型(根据提示生成的文本,或序列到序列问题(如翻译或摘要))时,这种行为将非常有用。
到现在为止,您应该了解分词器(tokenizer)可以处理的原子操作:标记化、转换为 ID 以及将 ID 转换回字符串。
参考
-
https://zhuanlan.zhihu.com/p/448147465
-
https://huggingface.co/learn/nlp-course/en/chapter2/4#tokenization
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
NLP开端:Tokenizer-文本向量化
Tokenizer 问题背景 An was a algorithm engineer 如上所示,在自然语言处理任务中,通常输入处理的数据是原始文本。但是算法模型自能处理数值类型,因此需要找到一种方法,将原始的文本数据转换为数值类型的数据。这就是分词器所…...

STM32 MCU学习资源
STM32 MCU学习资源 文档下载需要注册登录账号 ST公司官方文档 STM32 MCU开发者资源 STM32F446 相关PDF文档 ST中文论坛 中文译文资料 ST MCU中文官网 其他学习资源 野火STM32库开发实战指南 零基础快速上手STM32开发(手把手保姆级教程) 直接使…...

Python知识点:Python内存管理与优化
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! Python内存管理与优化指南 Python是一种动态类型的解释型语言,它提…...

SpringBoot Kafka发送消息与接收消息实例
前言 Kafka的基本工作原理 我们将消息的发布(publish)称作 producer(生产者),将消息的订阅(subscribe)表述为 consumer(消费者),将中间的存储阵列称作 broker(代理),这…...

【资料分析】刷题日记2
第一套 √ 2013-2016一共有13,14,15,16四年,亦即16 - 13 1 4年 √ 是多少倍 ③vs④:都是只给出了年均增速,③求的是其中一年的,无法确定;④求的是这个时段总共的,可…...

Aigtek功率放大器怎么选择型号
功率放大器在各个领域中都扮演着重要的角色,用于增强信号的幅度,以满足特定的需求。在选择功率放大器型号时,需要综合考虑多个因素,如应用领域、功率要求、频率范围、输入输出特性等。下面安泰电子官网将从这些方面详细介绍功率放…...

【RabbitMQ】重试机制、TTL
重试机制 在消息从Broker到消费者的传递过程中,可能会遇到各种问题,如网络故障、服务不可用、资源不足等,这些问题都可能导致消息处理失败。为了解决这些问题,RabbitMQ提供了重试机制,允许消息在处理失败之后重新发送…...

Linux用户及用户组操作命令笔记
1.用户概念及作用 用户:指的是Linux操作系统中用于管理系统或者服务的人 Linux下一切皆文件,所以用户管理的是相应的文件 基本上分为两种: 基本管理:文件的创建、删除、复制、查找、打包压缩等;文件的权限增加、减…...

threejs加载高度图渲染点云,不支持tiff
问题点 使用的point来渲染高度图点云,大数据图片无效渲染点多(可以通过八叉树过滤掉无效点增加效率,这个太复杂),但是胜在简单能用 效果图 code 代码可运行,无需npm <!DOCTYPE html> <html la…...

MySQL面试题——第二篇
1. MySQL的优化手段有哪些? MySQL的常见的优化手段有以下五种 1. 查询优化 避免select * ,只查询需要的字段。小表驱动大表,即小的数据集驱动大的数据集,比如当B表的数据集小于A表时,用in优化exist。两表执行顺序是先查B表&#x…...
Unity Transform 组件
在 Unity 中,Transform 是一个非常重要的组件,它定义了物体的位置、旋转和缩放,几乎每个 GameObject 都包含一个 Transform 组件。Transform 组件的主要属性如下: 1. position 表示物体在世界空间中的位置。可以通过 transf…...

LeeCode 3. 无重复字符的最长子串
经典方法滑动窗口:(两个指针) 针对这个题我们首先假定两个指针 left 和 right 分别指在数组最左端. 然后两个变量记录长度length和maxlength. 并且因为不能有重复的字符,我们使用HashSet结构来当收集结果的表. 随着右指针不断往右移,左指针和右指针之间的就为截取的字符,而这…...

使用canal.deployer-1.1.7和canal.adapter-1.1.7实现mysql数据同步
1、下载地址 --查看是否开启bin_log日志,value on表示开启 SHOW VARIABLES LIKE log_bin; -- 查看bin_log日志文件 SHOW BINARY LOGS; --查看bin_log写入状态 SHOW MASTER STATUS; --查看bin_log存储格式 row SHOW VARIABLES LIKE binlog_format; --查看数据库服…...

VMware Workstation Pro 17下载及安装教程
下载 好消息!从VMware Workstation Pro 17开始,个人可以免费使用了,再也不需要找破解激活码啥的了。 但是坏处却不小:其下载变得异常复杂。首先需要注册账号,外网非常慢很可能注册不上;其次根本找不到下载…...
集采良药:从“天价神药”到低价良药,伊马替尼的真实世界研究!
在医疗科技日新月异的今天,有一种药物以其卓越的疗效和深远的影响力,成为了众多患者心中的“精准武器”——伊马替尼。这款药物不仅在慢性髓细胞白血病(CML)的治疗上屡创佳绩,更是胃肠道间质瘤(GIST&#x…...

00898 互联网软件应用与开发自考复习题
资料来自互联网软件应用与开发大纲 南京航空航天大学 高纲4295和JSP 应用与开发技术(第 3 版) 马建红、李学相 清华大学出版社2019年 第一章 一、选择题 通过Internet发送请求消息和响应消息使用()网络协议。 FTP B. TCP/IP C. HTTP D. DNS Web应…...
)
linux 进程间通信之pthread(条件变量共享和互斥锁共享)
0,互斥锁共享 初始化和销毁mutex互斥锁 int pthread_mutexattr_init(pthread_mutexattr_t *attr); int pthread_mutexattr_destroy(pthread_mutexattr_t *attr); 进程共享属性有两种值: 1、PTHREAD_PROCESS_PRIVATE,这个是默认值(1),同一个进程中的多个线程访问同一个…...

数据结构-2.7.单链表的查找与长度计算
注:本文只探讨"带头结点"的情况(查找思路类似循环找到第i-1 个结点的代码) 一.按位查找: 1.代码演示: 版本一: #include<stdio.h> #include<stdlib.h> //定义单链表结点类型 typedef struct LNo…...
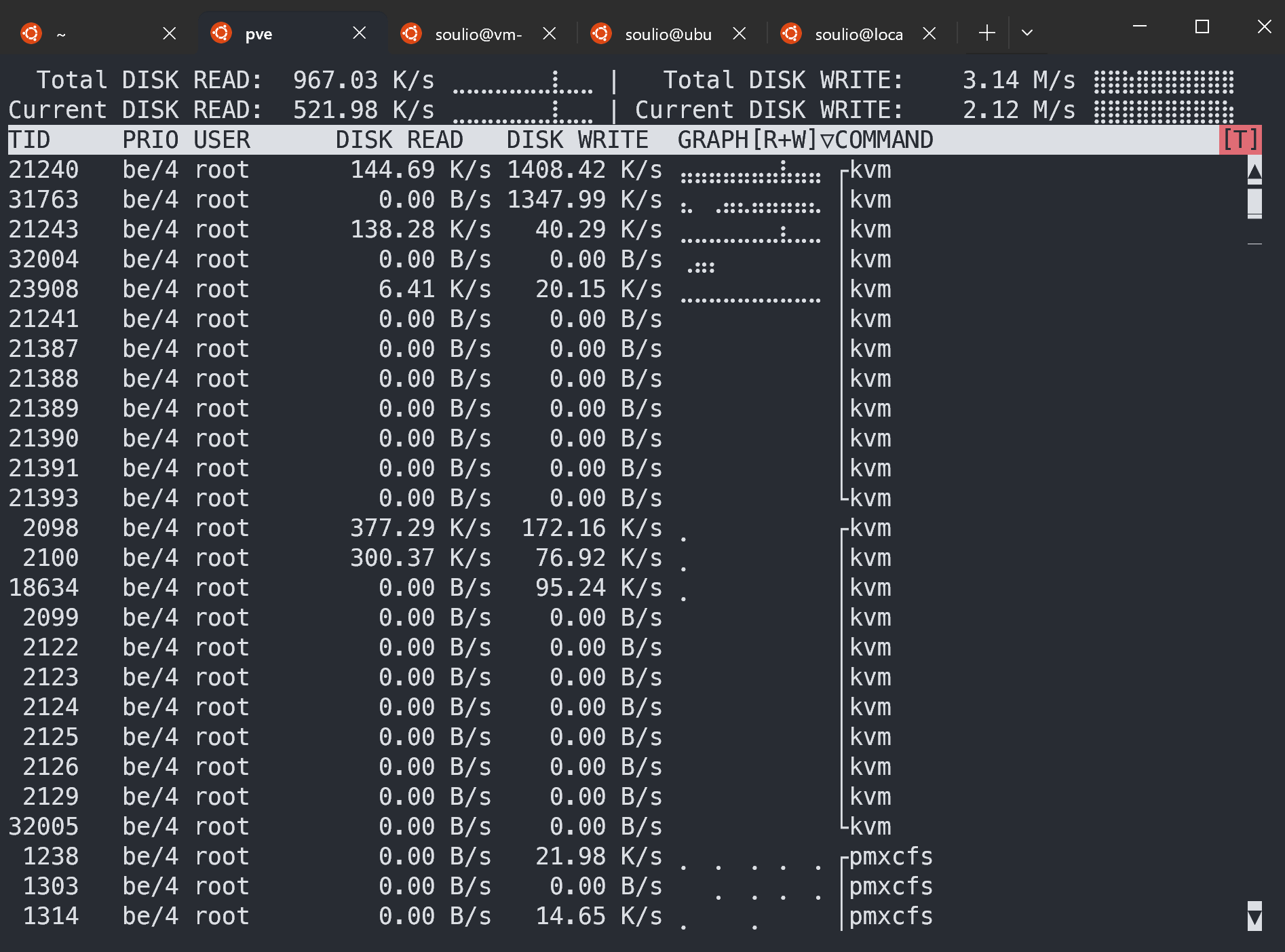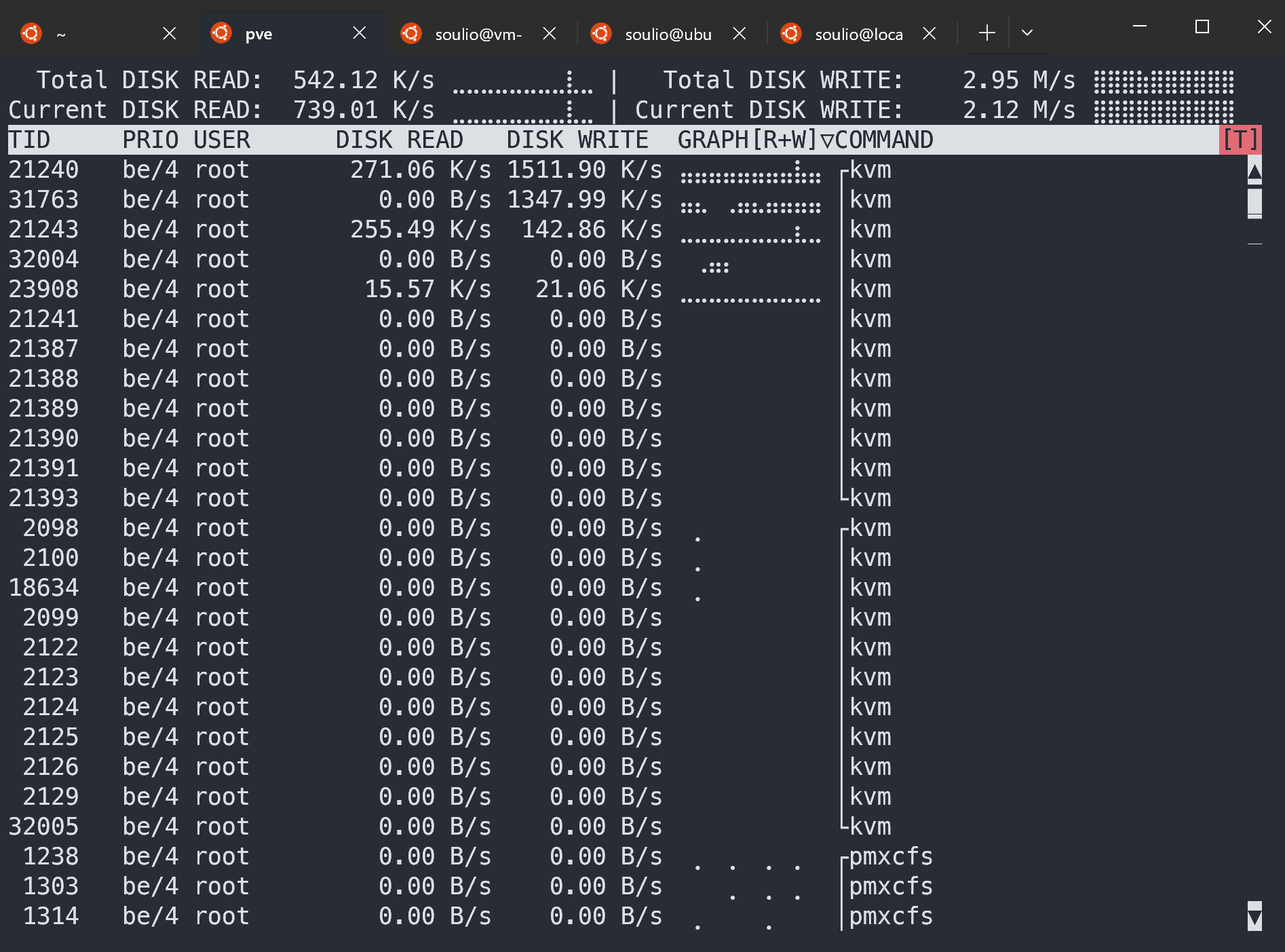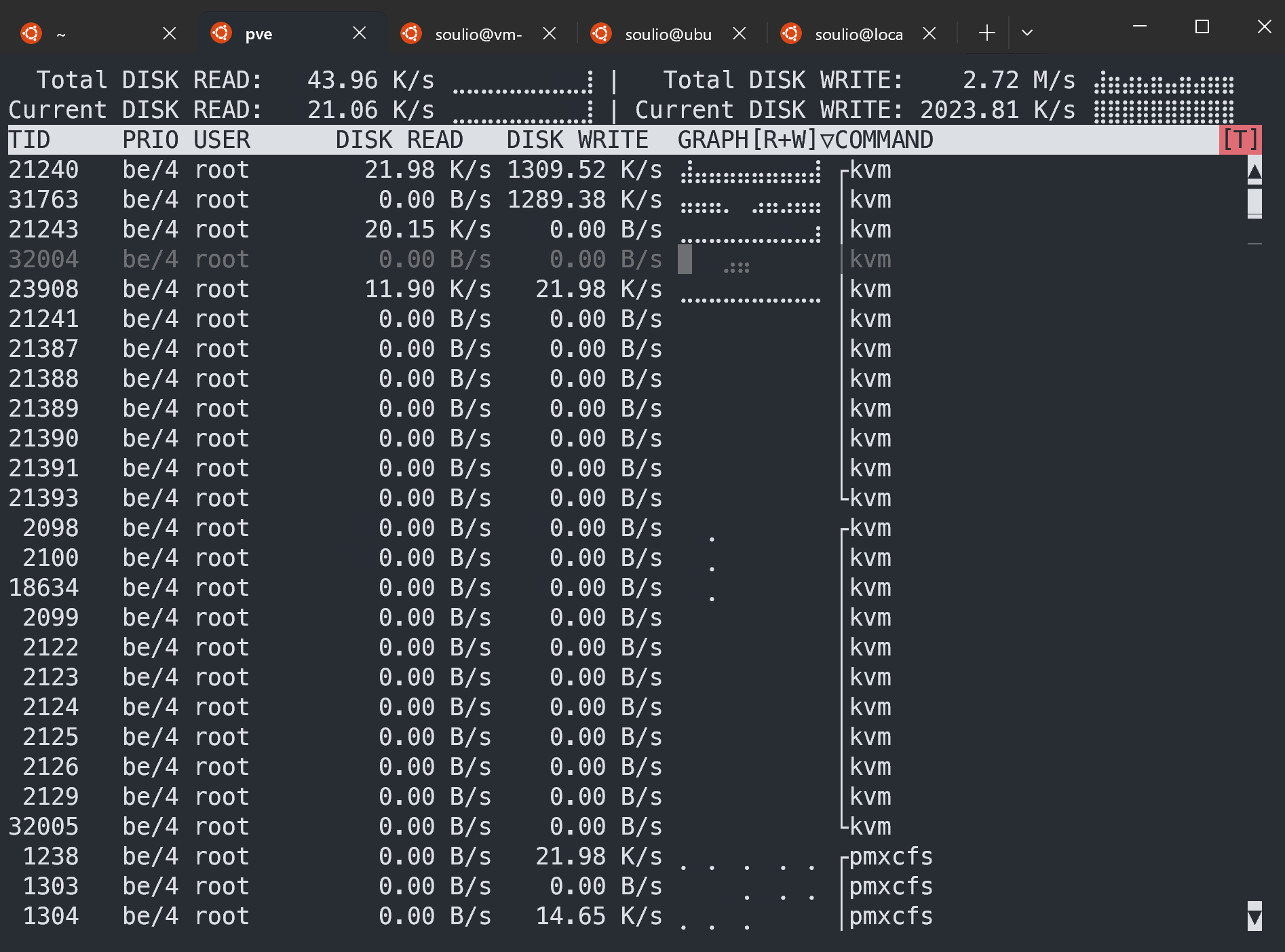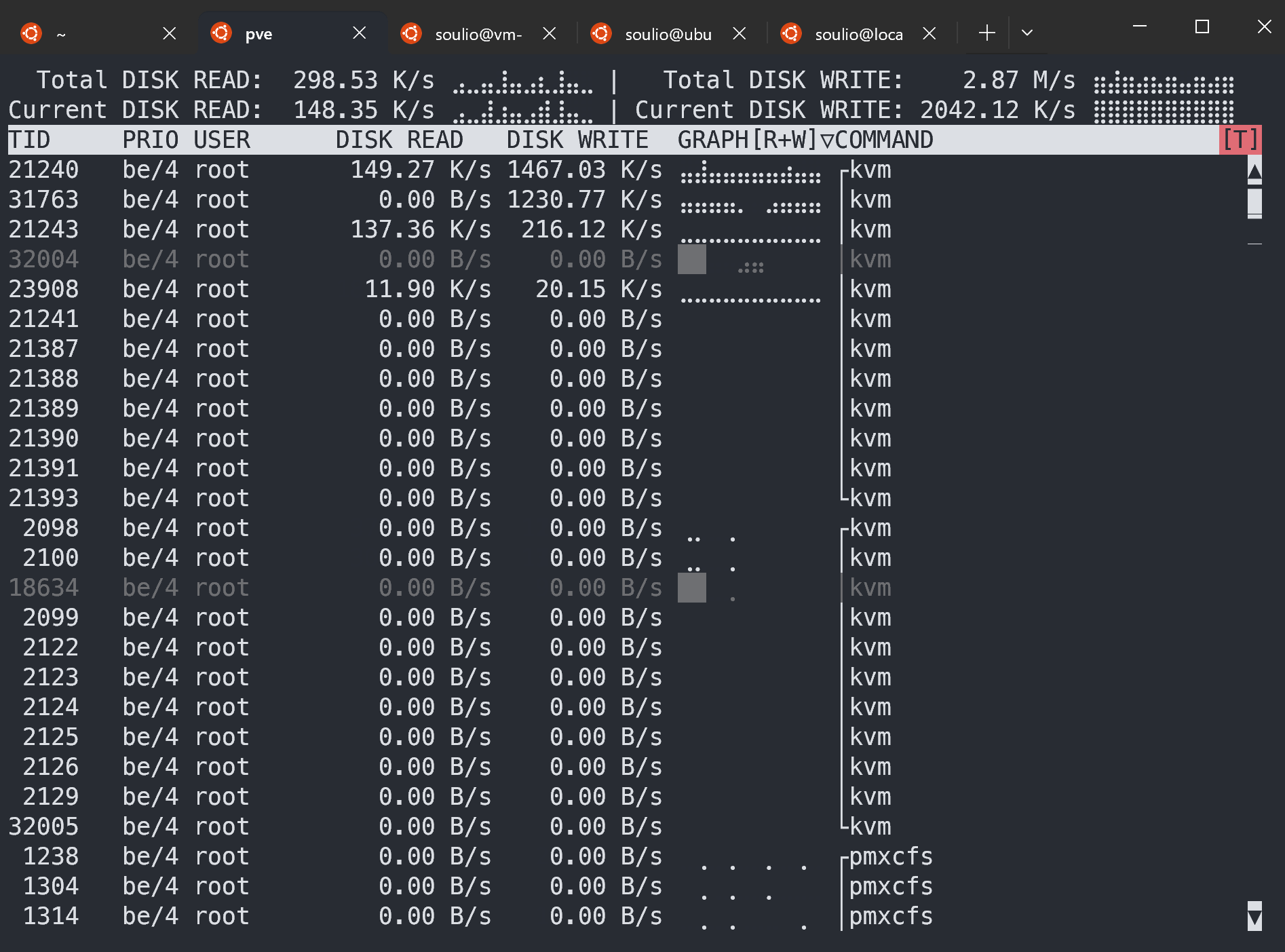
iotop 命令:磁盘IO监控和诊断
一、命令简介 iotop命令用于监视磁盘I/O,实时显示每个进程或线程的读写速率等信息。非常适合用于诊断系统中的I/O瓶颈。 安装 iotop 在大多数Linux发行版中,iotop可能不是预装的。可以使用包管理器来安装它。 例如,在…...

解锁编程新境界:GitHub Copilot 让效率翻倍
Number.1:工具介绍 功能特点: 智能代码生成与补全:通过学习大量代码库和开发者的编码风格,能根据上下文自动推断可能的代码补全选项,甚至可以自动完成函数定义、循环结构等复杂代码片段。例如,当编写一个算…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...