选择Alluxio来解决AI模型训练场景数据访问的五大理由

在AI模型训练尤其是大模型领域,存储系统的性能和稳定性直接决定了模型训练、推理、部署任务的效率和成本。随着全球AI行业的爆发带来的数据规模的快速增长,如何高效管理和利用这些数据成为AI模型训练中的一大挑战。
AI模型训练场景面临的五大难题
1. 数据读写性能不足
在AI模型训练与推理过程中,数据的高效读写是确保计算效率的关键。然而,随着数据集的急剧增长,存储系统往往无法满足对高速数据传输的需求,导致读写性能不足,尤其是在需要频繁读取和写入的场景中,影响整体训练进度。
2. 规模与可扩展性问题
随着AI模型的复杂度和数据规模的不断增加,存储系统需要具备高度的扩展能力。多模态模型和大模型任务通常涉及多类型数据存储,如何在跨多种存储平台和系统间灵活扩展并保持高效的访问成为主要挑战。
3. 稳定性问题
在大规模模型训练中,数据的连续高负荷读写对存储系统的稳定性提出了严峻挑战。系统中断或性能波动会严重影响AI训练的连贯性,进而延长开发周期。因此,保证存储系统在高压力下的持续稳定性至关重要。
4. 易用性问题
AI模型开发者不仅需要高效的数据访问,还期望存储系统具备简便的操作接口和支持多种数据访问API的能力。复杂的操作和难以配置的系统会降低开发效率,增加运维负担。
5. 成本问题
在AI模型训练场景中,如何在保证高效数据访问的同时控制存储和运维成本是长期面临的挑战。存储资源和计算资源的过度使用,尤其是GPU的低利用率,都会显著增加总体成本,降低ROI。
Alluxio Enterprise AI的最新3.3版本,通过一系列的产品升级、创新和优化,专为解决AI模型训练场景存储难题提供了有力的支持。以下是Alluxio Enterprise AI的五大核心亮点以及它们如何应对AI模型训练场景中的关键挑战。
Alluxio Enterprise AI 五大核心亮点
1. 卓越的性能
Alluxio Enterprise AI大幅提升了读吞吐和IOPS性能。在大模型训练中,GPU服务器能够在10秒内加载完100GB的Checkpoint,实现单客户端10GB/s的加载吞吐。此外,Alluxio通过优化Checkpoint写入过程,将数据先写入本地再异步上传到慢速持久层,显著减少了GPU的闲置时间,从而提高了资源利用率。
在Alluxio 3.3中,模型训练方面:利用专为 AI 工作负载定制的高性能低延迟的分布式缓存,在数据湖之上可实现高达 20 倍的 I/O 性能。Alluxio 可在训练工作流程的各个阶段提高读取数据集到写入模型的 IO 性能,从而消除 GPU 因I/O缓慢造成的性能瓶颈。模型服务方面:与直接从对象存储提供模型服务相比,通过Alluxio从离线训练集群向离线和在线推理节点提供模型上线的速度最高可达对象存储的 10 倍以上。Alluxio完全分布式的缓存架构可轻松扩展到为数千个推理节点提供服务,让你无需担心模型更新的高延迟。
2. 可充分支持大规模和实现可扩展性
Alluxio Enterprise AI使用的是新的DORA架构,从根本上使得Alluxio更易于支持大规模场景的使用。DORA,即去中心化对象存储库架构(Decentralized Object Repository Architecture),是 Alluxio 产品的新一代架构。DORA 作为分布式缓存系统,具有低延迟、高吞吐量、节省成本等特点,旨在为 AI 工作负载提供高性能数据访问层。DORA 利用分散式存储和元数据管理来提供更高的性能和可用性,以及可插入的数据安全和治理,从而实现更高的可扩展性和对大规模数据访问的高效管理。从数据规模上看,Alluxio Enterprise AI的最新版本可以支持百亿规模的数据量,因此充分支持模型训练中的大规模和可扩展性的需求。
3. 即插即用,无需进行硬件改造和数据迁移
Alluxio向上兼容Tensorflow, Pytorch、Ray等AI计算框架,以及Spark, Presto, Hive等大数据引擎,向下适配市场上主流的存储和云厂商(例如S3, Dell EMC ECS, MinIO,以及云厂商AWS, Azure, GCP, 火山引擎等)。因此,无需更换或者增加硬件供应商,可以继续在现有的硬件和系统架构上增加Alluxio,即插即用,不会增加硬件或者系统的支出。
使用 Kubernetes 在 GPU 集群上快速部署 Alluxio,并将Alluxio与存储集群连接。无需迁移数据,即可以开启高性能的训练作业,并最大限度地缩短机器学习平台在不同云和本地集群上的生产时间。
值得一提的是,Alluxio Enterprise AI引入了全新的Python API,使得基于FSSpec的Python应用程序(如Ray)可以无缝连接各种后端存储系统,无需部署Alluxio FUSE即可直接使用Alluxio的高性能缓存服务,提升数据访问的IO性能。此外,新的zero-copy S3接口不仅降低了内存开销和处理延时,还显著提升了数据访问性能,增强了系统的灵活性与兼容性。
4. 稳定性和易用性进一步提升
Alluxio 在系统升级和稳定性管理方面做出了重要改进,通过集群的滚动升级能力,实现了无停机时间的平滑升级。Alluxio Operator不仅提供了一键部署的便捷性,还具备多种运维功能,如CSI故障转移机制,自动恢复错误的FUSE pod,确保应用层任务的持续运行。在缓存管理方面,Alluxio发布了功能丰富的缓存生命周期管理工具集,使缓存空间管理更加高效,降低了整体缓存成本。
5. 针对AI模型训练场景工作负载的优化,且能实现自动化的扩展与成本优化
Alluxio Enterprise AI专门针对AI模型训练场景中的多样化工作负载进行了优化,支持多租户架构和隔离,确保在高负载情况下,各任务依然能够获得稳定的存储性能。同时,针对性地优化了对小文件和随机I/O操作的处理,使其能够更好地适应复杂的AI工作负载。
Alluxio Enterprise AI的自动化扩展功能使得系统可以根据需求灵活扩展,同时引入了新的成本优化策略,通过智能的数据分层和资源调度,用户能够在保持高性能的同时,显著降低存储成本,满足AI环境中对高性价比的需求。
使用Alluxio之后,通常可以通过利用本地或者云上的SSD/NVMe盘的闲置资源进行数据缓存,GPU使用率在现有客户中都得到了大幅的提升,可以从30%~50%提升到90%+。
相关文章:
选择Alluxio来解决AI模型训练场景数据访问的五大理由
在AI模型训练尤其是大模型领域,存储系统的性能和稳定性直接决定了模型训练、推理、部署任务的效率和成本。随着全球AI行业的爆发带来的数据规模的快速增长,如何高效管理和利用这些数据成为AI模型训练中的一大挑战。 AI模型训练场景面临的五大难题 1. 数…...

POS共识机制简介
权益证明(Proof of Stake, PoS)共识机制基础 1. 引言 权益证明(Proof of Stake, PoS)是一种用于区块链网络的共识机制,旨在解决工作量证明(Proof of Work, PoW)机制中存在的能源消耗高、中心化…...

Spring为什么要用三级缓存解决循环依赖?
Spring为什么要用三级缓存解决循环依赖? 1. Spring是如何创建一个bean对象2. Spring三级缓存2.1 一级缓存:单例池,经历过完整bean生命,单例Bean对象2.2 二级缓存:提前暴露的Bean2.3 三级缓存:打破循环 3. S…...

【Redis入门到精通三】Redis核心数据类型(List,Set)详解
目录 Redis数据类型 编辑 1.List类型 (1)常见命令 (2)内部编码 2.Set类型 (1)常见命令 (2)内部编码 Redis数据类型 查阅Redis官方文档可知,Redis提供给用户的核…...

本科生如何学习机器学习
一、入门阶段 1. 数学与统计学基础 高等数学:学习微积分、极限、级数等基本概念。线性代数:掌握矩阵运算、特征值和特征向量、线性方程组等。概率论与统计学:理解概率分布、假设检验、贝叶斯定理等统计知识。 2. 编程语言学习 Python&…...

海康威视摄像机和录像机的监控与回放
文章目录 海康威视摄像机和录像机的监控与回放1、海康威视监控设备简介1.1、摄像机二次开发1.1.1:协议选择 1.2:web集成1.2:标准协议对接1.2.1:ffmpeg软件转流1.2.2:开源监控软件shinobi1.2.2.1 安装使用1.2.2.2 shino…...
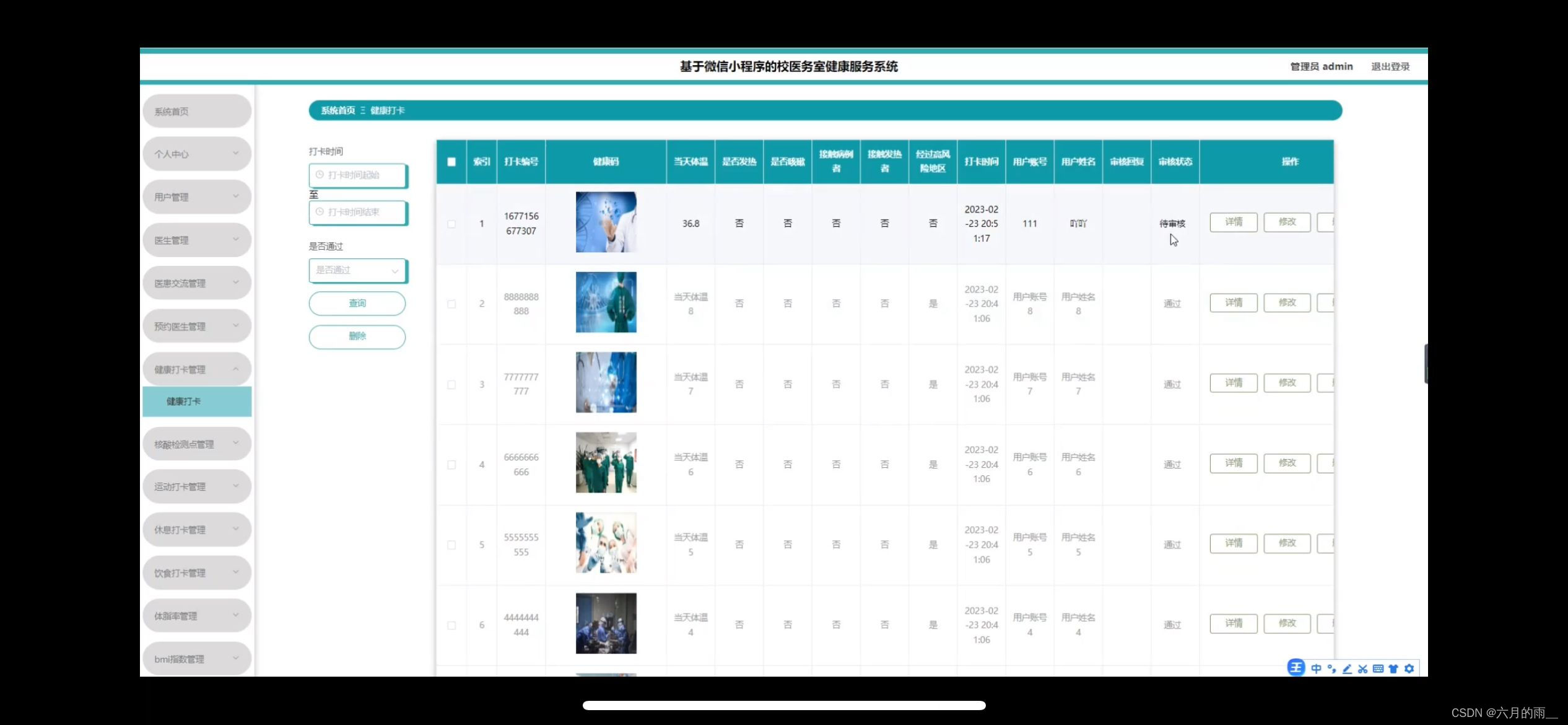
校医务室健康服务系统小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,医生管理,医患交流管理,预约医生管理,健康打卡管理,运动打卡管理,饮食打卡管理 微信端账号功能包括:系统首…...

MySQL 中的 UTF-8 与 UTF8MB4:差异解析
在 MySQL 数据库中,字符集的选择对于数据的存储和处理至关重要。其中,UTF-8 和 UTF8MB4 是两个常见的字符集选项。那么,它们之间到底有什么区别呢? 一、字符集简介 UTF-8 UTF-8(8-bit Unicode Transformation Format&…...

nvm无法下载npm的问题
1、问题 执行 nvm install 14.21.3 命令,node可以正常下载成功,npm下载失败 2、nvm配置信息 …/nvm/settings.txt root: D:\soft\nvm path: D:\soft\nodejs node_mirror: npmmirror.com/mirrors/node/ npm_mirror: registry.npmmirror.com/mirrors/…...

数据结构与算法——Java实现 6.递归
要学会试着安静下来 —— 24.9.17 一、递归的定义 计算机科学中,递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集 说明: ① 自己调用自己,如果说每个函数对应着一种解决方案,自己调用自己意味着解决方案是…...

.Net Core 生成管理员权限的应用程序
创建一个ASP.NET Core Web API项目 给解决方案设置一个名称 选择一个目标框架,这里选择的是 .NET 8.0框架 在Porperties文件夹中添加一个app.manifest文件 设置app.manifest文件属性,生成操作设置为嵌入的资源 双击解决方案名称,编辑WebAppli…...

DAY15:链表实现学生信息管理系统
要求功能: 创建学生信息表 头插法输入学生信息 尾插法输入学生信息输出任意位置范围内的学生信息 头删法删除学生信息尾删法删除学生信息按位置添加学生信息按位置删除学生信息 按位置修改学生信息按位置查找学生信息释放空间 今天有点累,懒得写注释了&a…...

JAVA语法基础 day05-面向对象
一、面向对象基本概念 /* 面向对象编程的步骤: 1.先设计对象的模板,也就是一个类class 生成一个新类的语句是:public class 类名,就跟python中class 类名一样 2.通过new关键字生成具体的对象,每new一次代表创建了的一个新的对象*…...

关于RabbitMQ重复消费的解决方案
一、产生原因 RabbitMQ在多种情况下可能会出现消息的重复消费。这些情况主要包括以下几个方面: 1. 网络问题 网络波动或中断:在消息处理过程中,由于网络波动或中断,消费者向RabbitMQ返回的确认消息(ack)…...

【SSM-Day2】第一个SpringBoot项目
运行本篇中的代码:idea专业版或者idea社区版本(2021.1~2022.1.4)->这个版本主要是匹配插件spring boot Helper的免费版(衰) 【SSM-Day2】第一个SpringBoot项目 框架->Spring家族框架快速上手Spring BootSpring Boot的作用通过idea创建S…...

【PyTorch】张量操作与线性回归
张量的操作 Tensor Operation 拼接与切分 1.1 torch.cat() torch.cat(tensors, dim0, outNone)功能:将张量按维度dim进行拼接 tensors:张量序列dim:要拼接的维度 1.2 torch.stacok() torch.stack(tensors, dim0, outNone)功能…...
情感类智能体——你的微信女神
智能体名称:你的微信女神 链接:文心智能体平台AgentBuilder | 想象即现实 (baidu.com)https://agents.baidu.com/agent/preview/RulbsUjIGj4wsinydlBH7AR3NQKFungt 简介 “你的微信女神”是一个直率的智能体,她用犀利而真实的言辞帮助用户…...

基于SpringBoot+Vue+MySQL的养老院管理系统
系统展示 管理员界面 家属界面 系统背景 随着全球人口老龄化的加速,养老院管理面临着前所未有的挑战。传统管理方式存在信息不透明、效率低下、资源分配不均等问题,难以满足日益增长的养老服务需求。因此,开发一套智能化、高效的养老院管理系…...

大数据Flink(一百二十二):阿里云Flink MySQL连接器介绍
文章目录 阿里云Flink MySQL连接器介绍 一、特色功能 二、语法结构 三、WITH参数 阿里云Flink MySQL连接器介绍 阿里云提供了MySQL连接器,其作为源表时,扮演的就是flink cdc的角色。 一、特色功能 MySQ…...

FutureTask源码分析
Thread类的run方法返回值类型是void,因此我们无法直接通过Thread类获取线程执行结果。如果要获取线程执行结果就需要使用FutureTask。用法如下: class CallableImpl implements Callable{Overridepublic Object call() throws Exception {//do somethin…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Taotoken的TokenPlan套餐如何实现更经济的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的TokenPlan套餐如何实现更经济的模型调用 1. 理解TokenPlan的计费模式 在模型应用开发过程中,成本的可预测性…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...