MVCC机制解析:提升数据库并发性能的关键
MVCC机制解析:提升数据库并发性能的关键
MVCC(Multi-Version Concurrency Control) 多版本并发控制 。
MVCC只在事务隔离级别为读已提交(Read Committed)和可重复读(Repeated Read)下生效。
MVCC是做什么用的
MVCC是为了处理 可重复读 和 读已提交 事务隔离级别下,在同一事务里,多次执行同一SQL查询语句,不会因为其他事务的横插一脚,对数据进行修改后,导致最终得到的结果不一致。如下图所示,事务B的两次查询得到的结果不一样。

MVCC是怎么实现的
在 串行读 这一事务隔离级别里面,为了保证较高的事务隔离性,采用了将所有的操作加锁互斥,将事务的执行变为顺序执行,相当于单线程的方式,以达到其高隔离性。
而mysql在 可重复读 和 已提交读 事务隔离级别下,他的隔离性是借助MVCC机制来保证的,MVCC机制呢,也不是通过加锁互斥来保证隔离性的,是通过 Undo日志版本链 和 Read View机制 实现的。避免了频繁的加锁互斥阻塞。
Undo日志版本链
Undo日志是什么?
undo日志是回滚日志,在mysql对某一数据进行修改更新时,会将其更新前的数据保存的undo回滚日志里,等当事务执行失败时,用来进行数据回滚的。
而什么是undo日志版本链呢?
就是一行数据被多个事务依次修改后,这条数据就会有很多条undo日志,这些undo日志就会通过一个 roll_pointer 字段进行串联起来,会形成这条数据的历史记录版本链,这个就是undo日志版本链。
roll_pointer 字段哪里来的呢?
在mysql数据库里,数据表都会有两个隐藏的字段属性, trx_id事务id 和 roll_pointer回滚指针 ,其中 trx_id 是用来记录操作数据的,而 roll_pointer 则是用来记录指向上一次修改的日志地址。
注意:begin/start transaction这个开始/启动事务命令,并不是一个事务的起点, 而是在执行到第一条更新update、删除delete、插入insert语句时,事务才真正的启动,才会有真正的事务id。
后生成的trx_id要比先生成的trx_id大。
只有InnoDB数据引擎才支持事务。
下图中,每一条数据都是一个undo回滚日志,通过roll_pointer串联起来后,就是undo日志版本链了。

如果第二次修改操作将name改为了
王五,又因为某些原因需要进行数据回滚,就要拿到roll_pointer里记录的上一次,也就是第一次修改操作的undo回滚日志地址,将name回滚为赵六。
Read View机制
在可重复读隔离级别下,一个事务在开始时,执行任何的查询SQL脚本,都会生成一个属于当前事务自己的 Read View一致性视图 ,这个视图在这个事务结束之间,都是保持不变的(除非在本事务里面自己执行了更新操作)。
如果事务隔离级别是读已提交,则
Read View一致性视图是在每次执行查询SQL脚本时,都会重新生成,与可重复读隔离级别的在同一事务里保持不变不同。
这个视图是什么呢?
这个视图是由执行查询SQL脚本这一时刻,所有还未提交的事务id构建而成的数组,和此时存在最大的一个事务id共同构建而成。
示意图一

示意图二

结合上面两图分析可知,
事务A 第一次执行查询语句时刻,所生成的ReadView的构成为 {[1002,1003,1004], 1004} ,其中[1002,1003,1004]为未提交的事务id(min_id=1002,min_id最小事务id是从未提交事务id里获取的),1004为当前最大的事务id(max_id=1004)。
事务A 第二次、三次执行查询语句时刻,其ReadView的依旧为 {[1002,1003,1004], 1004} 。
事务B 第一次执行查询语句时刻,所生成的ReadView的构成为 {[1002,1004], 1004} ,其中[1002,1004]为未提交的事务id(min_id=1002),1004为当前最大的事务id(max_id=1004)。
事务B 第二次执行查询语句时刻,所生成的ReadView的依旧为 {[1002,1004], 1004} 。
根据事务A和事务B的ReadView可以得出一个相同的工具图(用来判断某事务的某一次数据更新,是否对select是可见的)
事务里的select语句查询结果都是需要从undo日志版本链最新数据开始,逐条与本事务的ReadView进行比对,判断应该获取到哪一日志版本的数据为select语句的查询结果。
示意图三

比对规则
如果比较的undo日志的 trx_id小于min_id ,则表示这个版本事务是已经提交的,代表本次select这一事务可以查到这个数据。
如果比较的undo日志的 trx_id大于max_id ,则表示这个版本事务是在本次select这一事务后面新启动的,这种数据肯定是不可被查询到的。
如果比较的undo日志的 trx_id大于等于min_id ,且 trx_id小于等于max_id ,则再判断 trx_id是否是在未提交事务id数组里。
- 在未提交事务id数组里,则表示这个版本数据是由未提交的事务所生成的,这种数据不可被查询到(除非这个未提交的事务就是自己)。
- 不在未提交事务id数组里,则表示这个版本数据是由已经提交的事务所生成的,这种数据可以被查询到。
案例一
那么事务A第一条select语句查询脚本执行时,获取到的name是什么呢?
先说结果,查询到的name为赵六。
事务A执行第一条select语句时,他的SQL执行顺序,和SQL查询脚本执行时拿到的日志版本链及判断示意图如下。


上面在示意图二里也说了,事务A的第一次执行查询语句时刻时,其ReadView为 {[1002,1003,1004], 1004} 。
比较步骤如下
第一次: 事务A从undo日志版本链拿到最后一次更新记录(第二次修改记录),得到trx_id为1003,然后对照着上面的 判断工具图 进行比较,大于min_id,小于max_id,所以1003事务id属于是 第二部分 ,且1003这一事务id处于还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1003,1004]),所以这个事务进行的更新数据,是不可被查询到的。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第二次: 事务A从undo日志版本链拿到第二条日志记录(第一次插入记录),得到trx_id为1001,然后同样对照着上面的 判断工具图 进行比较,发现小于min_id的1002,所以1001事务id属于是 第一部分 ,是已经提交了事务的,他更新的数据就属于可以被查询到,于是此时查询到的结果name为张三。
案例二
那么事务A第二条select语句查询脚本执行时,获取到的name是什么呢?
先说结果,查询到的name依旧为赵六。
事务A执行第二条select语句时,他的SQL执行顺序,和SQL查询脚本执行时拿到的日志版本链及判断示意图如下。


上面在示意图二里也说了,事务A的第二次和第三次执行查询语句时刻时,其ReadView依旧为 {[1002,1003,1004], 1004} 。
比较步骤如下
第一次: 事务A从undo日志版本链拿到最后一次更新记录(第四次修改记录),得到trx_id为1003,然后对照着上面的 判断工具图 进行比较,大于min_id,小于max_id,所以1003事务id属于是 第二部分 ,继续判断得知,1003这一事务id处于还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1003,1004])(即便此时事务1003已经提交了,但是只要在事务A第一次执行查询语句时,这个事务没有提交,那他在事务A里就一直被标记的是未提交,否则就会出现 不可重复读 问题),所以这个事务进行的更新数据,是不可被查询到的。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第二次: 事务A从undo日志版本链拿到第二条日志记录(第三次修改记录),得到trx_id为1002,然后同样对照着上面的 判断工具图 进行比较,发现等于min_id的1002,所以1002事务id属于是 第二部分 ,继续判断得知,1002这一事务id处于还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1003,1004]),所以这个事务进行的更新数据,是不可被查询到的。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第三次: 事务A从undo日志版本链拿到最后一次更新记录(第二次修改记录),得到trx_id为1003,然后对照着上面的 判断工具图 进行比较,大于min_id,小于max_id,所以1003事务id属于是 第二部分 ,且1003这一事务id处于还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1003,1004]),所以这个事务进行的更新数据,是不可被查询到的。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第四次: 事务A从undo日志版本链拿到第二条日志记录(第一次插入记录),得到trx_id为1001,然后同样对照着上面的 判断工具图 进行比较,发现小于min_id的1002,所以1001事务id属于是 第一部分 ,是已经提交了事务的,他更新的数据就属于可以被查询到,于是此时查询到的结果name为张三。
案例三
那么事务B第一条select语句查询脚本执行时,获取到的name是什么呢?
先说结果,查询到的name为李四。
为什么事务B的一条查询语句和事务A的第二条查询语句是同时执行的,但是结果不一样呢?可以详细看看下面对事务的比较步骤。
事务B 第一次执行查询语句时刻,其所生成的ReadView的构成为 {[1002,1004], 1004} ,其中[1002,1004]为未提交的事务id(min_id=1002),1004为当前最大的事务id(max_id=1004)。
事务B执行第一条select语句时,他的SQL执行顺序,和SQL查询脚本执行时拿到的日志版本链及判断示意图同案例二里的一样。
比较步骤如下
第一次: 事务B从undo日志版本链拿到最后一次更新记录(第四次修改记录),得到trx_id为1003,然后对照着上面的 案例二的判断工具图 进行比较,大于min_id,小于max_id,所以1003事务id属于是 第二部分 ,继续判断得知,1003这一事务id 不处于 还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1004]),所以表示这个事务已经提交了,这个事务所更新的数据版本可以被查询到,查询结果就是name为李四。
案例四
事务A第三条select语句查询脚本执行时,获取到的name是什么呢?
先说结果,查询到的name还是赵六。
事务A执行第三条select语句时,他的SQL执行顺序,和SQL查询脚本执行时拿到的日志版本链及判断示意图如下。
上面在示意图二里也说了,事务A的第二次和第三次执行查询语句时刻时,其ReadView依旧为 {[1002,1003,1004], 1004} 。
比较步骤如下
第一次: 事务A从undo日志版本链拿到最后一次更新记录(第五次修改记录),得到trx_id为1004,然后对照着上面的 判断工具图 进行比较,大于min_id,小于 等于 max_id,所以1004事务id属于是 第二部分 ,且1004这一事务id 不处于 还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1003,1004]),所以这个事务进行的更新数据,是不可被查询到的。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第二次: 比较过程和示例二里的第一次比较操作过程一样。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第三次: 比较过程和示例二里的第二次比较操作过程一样。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第四次: 比较过程和示例二里的第三次比较操作过程一样。
于是根据roll_pinter回滚指针(上一版本数据的地址)找到上一个版本数据。
第五次: 比较过程和示例二里的第四次比较操作过程一样。得到查询结果name为张三。
案例五
那么事务B第二条select语句查询脚本执行时,获取到的name是什么呢?
先说结果,查询到的name为李四。
事务B 第二次执行查询语句时刻,其所生成的ReadView的依旧为 {[1002,1004], 1004} 。和其第一次执行查询语句时刻一样。
事务B执行第三条select语句时,他的SQL执行顺序图,和SQL查询脚本执行时拿到的日志版本链和上面案例三的一样。
虽然ReadView和案例三的不同,为 {[1002,1004], 1004} ,但是其形成的判断图还是一样的。
比较步骤如下
第一次: 事务B从undo日志版本链拿到最后一次更新记录(第五次修改记录),得到trx_id为1004,然后对照着上面的 判断工具图 进行比较,大于min_id,小于 等于 max_id,所以1004事务id属于是 第二部分 ,且1004这一事务id 不处于 还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1004])(即便此时事务1004已经提交了,但是只要在事务B第一次执行查询语句时,这个事务没有提交,那他在事务B里就一直被标记的是未提交,否则就会出现 不可重复读 问题),所以这个事务进行的更新数据,是不可被查询到的。(和上面案例二的第一次比较一样)
第二次:事务B从undo日志版本链拿到第二条日志记录(第四次修改记录),得到trx_id为1003,然后对照着上面的 案例二的判断工具图 进行比较,大于min_id,小于max_id,所以1003事务id属于是 第二部分 ,继续判断得知,1003这一事务id 不处于 还未提交的事务id构建而成的数组里(未提交的事务id数组[1002,1004]),所以表示这个事务已经提交了,这个事务所更新的数据版本可以被查询到,查询结果就是name为李四。
读已提交隔离级别又是怎么比较的
读已提交 (已提交读)事务隔离级别的undo日志版本链和 可重复读 是一样的,Read View的生成规则就不同了, 读已提交的 Read View一致性视图 是在每次执行查询SQL脚本时,都会重新生成 ,与可重复读隔离级别的在同一事务里保持不变的定义不同。
这也就导致每次执行查询脚本时,都会重新构建 还未提交的事务id数组 ,所以只要其他事务在本事务执行这一条查询脚本之前,更新数据并提交了,那他的更新数据就可以被本事务的这一次查询操作查询到。
其他的比对规则还是和 可重复读 事务隔离级别一样,仅仅是ReadView在每次查询时需要重新生成。
可以理解为 读已提交 事务隔离,只会读到最后一次提交了更新操作事务的数据。
相关文章:
MVCC机制解析:提升数据库并发性能的关键
MVCC机制解析:提升数据库并发性能的关键 MVCC(Multi-Version Concurrency Control) 多版本并发控制 。 MVCC只在事务隔离级别为读已提交(Read Committed)和可重复读(Repeated Read)下生效。 MVCC是做什么用的 MVCC是为了处理 可重复读 和…...

如何使用Postman搞定带有token认证的接口实战!
现在许多项目都使用jwt来实现用户登录和数据权限,校验过用户的用户名和密码后,会向用户响应一段经过加密的token,在这段token中可能储存了数据权限等,在后期的访问中,需要携带这段token,后台解析这段token才…...

Linux Vim编辑器常用命令
目录 一、命令模式快捷键 二、编辑/输入模式快捷键 三、编辑模式切换到命令模式 四、搜索命令 注:本章内容全部基于Centos7进行操作,查阅本章节内容前请确保您当前所在的Linux系统版本,且具有足够的权限执行操作。 一、命令模式快捷键 二…...
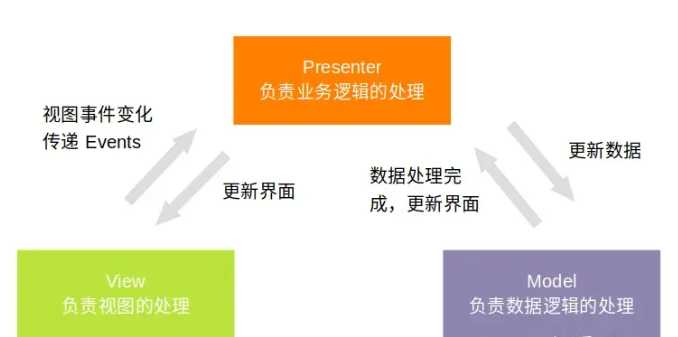
【Android】浅析MVC与MVP
【Android】浅析MVC与MVP 什么是架构? 架构(Architecture)在软件开发中指的是软件系统的整体设计和结构,它描述了系统的高层组织方式,包括系统中各个组件之间的关系、依赖、交互方式,以及这些组件如何协同…...

spark 面试题
spark 面试题 1、spark 任务如何解决第三方依赖 比如机器学习的包,需要在本地安装?--py-files 添加 py、zip、egg 文件不需要在各个节点安装 2、spark 数据倾斜怎么解决 spark 中数据倾斜指的是 shuffle 过程中出现的数据倾斜,主要是由于…...

青柠视频云——如何开启HTTPS服务?
前言 由于青柠视频云的语音对讲会使用到HTTPS服务,这里我们说一下如何申请证书以及如何在实战中部署并且配置使用。 一、证书申请 1、进入控制台 我们拿阿里云的免费个人证书为例,首先登录阿里云,在控制台找到数字证书管理服务,进…...

2016年国赛高教杯数学建模A题系泊系统的设计解题全过程文档及程序
2016年国赛高教杯数学建模 A题 系泊系统的设计 近浅海观测网的传输节点由浮标系统、系泊系统和水声通讯系统组成(如图1所示)。某型传输节点的浮标系统可简化为底面直径2m、高2m的圆柱体,浮标的质量为1000kg。系泊系统由钢管、钢桶、重物球、…...

vue-使用refs取值,打印出来是个数组??
背景: 经常使用$refs去获取组件实例,一般都是拿到实例对象,这次去取值的时候发现,拿到的竟然是个数组。 原因: 这是vue的特性,自动把v-for里面的ref展开成数组的形式,哪怕你的ref名字是唯一的!…...

微服务_入门1
文章目录 一、 认识微服务二、 微服务演变2.1、 单体架构2.2、 分布式架构2.3、 微服务2.4、 微服务方案对比 三、 注册中心3.1、 Eureka3.2、 Nacos3.2.1、服务分级存储模型3.2.2、权重配置3.2.3、环境隔离 一、 认识微服务 二、 微服务演变 随着互联网行业的发展,…...

【学习资料】袋中共36个球,红白黑格12个,问能一次抽到3个红4个白5个黑的概率是多少?
1、公式计算 1.1 题目1 袋中共 36 36 36个球, 红 \fcolorbox{red}{#FADADE}{\color{red}{红}} 红 白 \fcolorbox{white}{#808080}{\color{white}{白}} 白 黑 \fcolorbox{#808080}{#0D0D0D}{\color{#808080}{黑}} 黑各 12 12 12个,问能一次抽到 3…...

@PathVariable,@RequestParam,@RequestBody注解,springboot与前端请求之间的数据类型转换
前端数据与springboot java数据类型转换 springboot&mybatis中数组和字符串数据类型的转换-CSDN博客中曾经提到,在Spring Boot中,通过URL传参、payload中的key-value形式或json形式,将前端数据以字符串格式发送到后端,后端We…...

在Python中优雅地打开和操作RDS
在Python中优雅地打开和操作RDS 随着数据存储需求的不断增长,关系数据库服务(Relational Database Service, RDS)成为了许多企业首选的数据存储方式。那么,在Python中如何轻松地与RDS进行交互呢?以下是一份详尽的指南…...

.whl文件下载及pip安装
以安装torch_sparse库为例 一、找到自己需要的版本,点击下载。 去GitHub的pyg-team主页中找到pytorch-geometric包。网址如下: pyg-team/pytorch_geometricgithub.com/pyg-team/pytorch_geometric 然后点击如图中Additional Libraries位置的here&am…...

望繁信科技受邀出席ACS2023,为汽车行业数智化护航添翼
2023年5月25-26日,ACS2023第七届中国汽车数字科技峰会在上海成功举行。此次峰会汇聚了众多汽车领域的顶级专家、产业链代表及企业高管,共同探讨当今汽车产业的转型与未来发展趋势。 作为唯一受邀的流程挖掘厂商代表,望繁信科技携最新行业优势…...

基于 C语言的 Modbus RTU CRC 校验程序
一、CRC校验原理 Modbus RTU是一种常用于工业设备通信的协议,它基于串行通信,如RS-232或RS-485。在Modbus RTU中,CRC(循环冗余校验)是一种常用的错误检测机制,用于确保数据在传输过程中的完整性和准确性。 …...

基于微信小程序的剧本杀游玩一体化平台
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 基于微信小程序JavaSpringBootVueMySQL的剧…...

AMD或Intel上编译出来的程序,可以跑在海光上吗?
在上一篇博文《海光处理器与AMD Zen1的指令差异-CSDN博客》中发现,海光相比AMD,缺失了一些指令集。 那么在AMD或Intel上编译出来的程序,可以跑在海光上吗? 这个问题的关键,在于编译器默认使用哪些指令来编译程序。以Ce…...
ChatGPT 4o 使用指南 (9月更新)
首先基础知识还是要介绍得~ 一、模型知识: GPT-4o:最新的版本模型,支持视觉等多模态,OpenAI 文档中已经更新了 GPT-4o 的介绍:128k 上下文,训练截止 2023 年 10 月(作为对比,GPT-4…...

微信getUserProfile不弹出授权框
当我们在微信小程序开发工具中想要使用getUserProfile来获取个人信息的时候,会发现不弹出授权框,这是什么原因呢? 早在2022年的小程序官方公告中就已经明确给出了小程序用户头像昵称获取规则调整公告 因此如果还想继续使用getUserProfile的弹…...

iostat 命令:系统状态监控
一、命令简介 iostat 命令用于报告系统中 CPU、磁盘、tty 设备和 CPU 利用率统计信息。 需安装 sysstat 软件包,该软件包提供了一组工具,包括 iostat、sar、mpstat 等,用于系统性能监控和报告。 二、命令参数 iostat…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...