优先级队列(堆)
目录
优先级队列
堆的概念
堆的创建
堆的向下调整
堆的插入
完整代码
优先级队列
队列是一种先进先出的数据结构,有些时候操作的数据可能带有优先级,出队列时就需要优先级高的数据先出队列。
在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数 据结构就是优先级队列(Priority Queue)。
堆的概念
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:Ki = K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。

注意:
- 已知孩子节点为i,则双亲节点为 (i-1)/2;
- 已知双亲节点为i,左孩子:2*i+1;右孩子:2*i+2。
堆的创建
堆的向下调整
这里以大根堆为例来讲解堆的向下调整。
题目:对于集合{ 27,15,19,18,28,34,65,49,25,37 }中的数据,如果将其创建成大根堆呢?
首先我们要定义基本变量,来供使用。因为是对于集合中的数据进行创建大根堆,所以我们可以使用数组来进行。
public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){this.elem = new int[10];}
}对于如何把数组中的数据放到实现堆的数组里,我们可以通过for循环来进行放置。
注意:这里是有两个数组。
public void intelem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];usedSize++;}}接着我们就要开始创建堆了
public void createHeap(){for (int parent = (this.usedSize-1-1)/2; parent >= 0 ; parent--) {shifDown(parent, this.usedSize);//每棵树结束时候都给个10,如果接着调整的节点比10//大了,说明这棵树一定调整完了}}主要的重心在于如何写出shifDown这个方法。
思路:
- 由上面我们能知道 child = parent*2+1。为了确保child的数组不越界,我们要确定循环条件。
- 因为是创建大根堆,所以要找到左右子树的最大值同根节点进行比较、交换。
- 关于break,这里因为当 前一个节点已经结束了,下面的节点也是结束的状态。
/**** @param parent 每棵子树调整的起始位置* @param usedSize 判断 每棵子树 什么时候 调整结束*/private void shifDown(int parent, int usedSize) {int child = 2*parent+1;while(child < usedSize){//找到左右子树的最大值if(child+1 < usedSize && elem[child] < elem[child+1]){child++;}if(elem[child] > elem[parent]){swap(elem,child,parent);parent = child;child = 2*parent+1;}else{break;}}}private void swap(int[] elem, int i ,int j){int tmp = elem[i];elem[i] = elem[j];elem[j] = tmp;}通过Test测试类和调试,我们能看到大根堆创建成功了。
public class Test {public static void main(String[] args) {int[] array = {27,15,19,18,28,34,65,49,25,37};TestHeap testHeap = new TestHeap();//把array的值赋值给testHeaptestHeap.intelem(array);testHeap.createHeap();
}
创建的堆下图,大根堆。

堆的插入
堆的插入总共需要两个步骤:
- 先将元素放入到底层空间中(注意:空间不够时需要扩容)
- 将最后新插入的节点向上调整,直到满足堆的性质
其实这和上面的创建大根堆有些类似,但这里用到的是向上调整。
//插入public void push(int val){if(isFull()){elem = Arrays.copyOf(elem,2*elem.length);}elem[usedSize] = val;sitUp(usedSize);usedSize++;}public boolean isFull(){return elem.length == usedSize;}
}
这里的关键在于向上调整部分代码的编写。
private void sitUp(int child) {int parent = (child-1)/2;while(parent >= 0){if (elem[parent] < elem[child]){swap(elem,child,parent);child = parent;parent = (child-1)/2;}else{break;}}}向上调整我们可以先确定孩子节点,最后一棵树的节点位置可以通过 useSize来确定,进而能确定双亲节点。
完整代码
TestHeap类
import java.util.Arrays;public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){this.elem = new int[10];}public void intelem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];usedSize++;}}public void createHeap(){for (int parent = (this.usedSize-1-1)/2; parent >= 0 ; parent--) {shifDown(parent, this.usedSize);//没棵树结束时候都给个10,如果接着调整的节点比10大了。说明这棵树一定调整完了}}//alt+p+enter 直接生成/**** @param parent 每棵子树调整的起始位置* @param usedSize 判断 每棵子树 什么时候 调整结束*/private void shifDown(int parent, int usedSize) {int child = 2*parent+1;while(child < usedSize){//找到左右子树的最大值if(child+1 < usedSize && elem[child] < elem[child+1]){child++;}if(elem[child] > elem[parent]){swap(elem,child,parent);parent = child;child = 2*parent+1;}else{break;}}}//插入public void push(int val){if(isFull()){elem = Arrays.copyOf(elem,2*elem.length);}elem[usedSize] = val;sitUp(usedSize);usedSize++;}private void swap(int[] elem, int i ,int j){int tmp = elem[i];elem[i] = elem[j];elem[j] = tmp;}private void sitUp(int child) {int parent = (child-1)/2;while(parent >= 0){if (elem[parent] < elem[child]){swap(elem,child,parent);child = parent;parent = (child-1)/2;}else{break;}}}public boolean isFull(){return elem.length == usedSize;}
}Test类
public class Test {public static void main(String[] args) {int[] array = {27,15,19,18,28,34,65,49,25,37};TestHeap testHeap = new TestHeap();//把array的值赋值给testHeaptestHeap.intelem(array);testHeap.createHeap();/*for (int i = 0; i < array.length; i++) {testHeap.push(array[i]);}testHeap.push(80);*/}
}相关文章:
优先级队列(堆)
目录 优先级队列 堆的概念 堆的创建 堆的向下调整 堆的插入 完整代码 优先级队列 队列是一种先进先出的数据结构,有些时候操作的数据可能带有优先级,出队列时就需要优先级高的数据先出队列。 在这种情况下,数据结构应该提供两个最基本…...

帧率和丢帧分析理论
一、丢帧问题概述 应用丢帧通常指的是在应用程序的界面绘制过程中,由于某些原因导致界面绘制的帧率下降,从而造成界面卡顿、动画不流畅等问题。以60Hz刷新率为例子,想要达到每秒60帧(即60fps)的流畅体验,每…...

solidwork找不到曲面
如果找不到曲面 则右键找到选项卡,选择曲面...

mac安装JetBtains全家桶新版本时报错:Cannot start the IDE
mac安装JetBtains全家桶新版本时报错:Cannot start the IDE 前言报错信息解决方法 前言 作者使用的是Mac电脑,最近想要更新JetBrains相关工具的软件版本,但是在安装时突然报错,导致安装失败,现在将报错信息以及解决方…...

MVCC机制解析:提升数据库并发性能的关键
MVCC机制解析:提升数据库并发性能的关键 MVCC(Multi-Version Concurrency Control) 多版本并发控制 。 MVCC只在事务隔离级别为读已提交(Read Committed)和可重复读(Repeated Read)下生效。 MVCC是做什么用的 MVCC是为了处理 可重复读 和…...

如何使用Postman搞定带有token认证的接口实战!
现在许多项目都使用jwt来实现用户登录和数据权限,校验过用户的用户名和密码后,会向用户响应一段经过加密的token,在这段token中可能储存了数据权限等,在后期的访问中,需要携带这段token,后台解析这段token才…...

Linux Vim编辑器常用命令
目录 一、命令模式快捷键 二、编辑/输入模式快捷键 三、编辑模式切换到命令模式 四、搜索命令 注:本章内容全部基于Centos7进行操作,查阅本章节内容前请确保您当前所在的Linux系统版本,且具有足够的权限执行操作。 一、命令模式快捷键 二…...
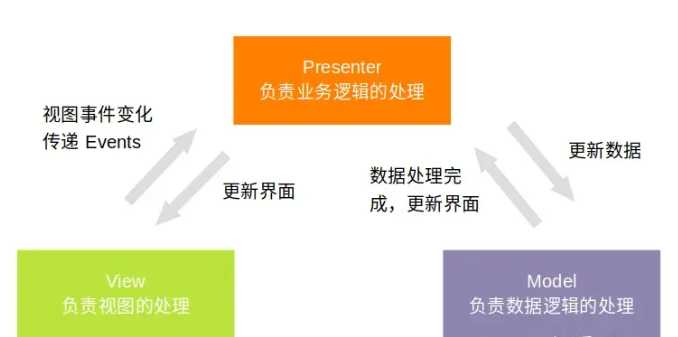
【Android】浅析MVC与MVP
【Android】浅析MVC与MVP 什么是架构? 架构(Architecture)在软件开发中指的是软件系统的整体设计和结构,它描述了系统的高层组织方式,包括系统中各个组件之间的关系、依赖、交互方式,以及这些组件如何协同…...

spark 面试题
spark 面试题 1、spark 任务如何解决第三方依赖 比如机器学习的包,需要在本地安装?--py-files 添加 py、zip、egg 文件不需要在各个节点安装 2、spark 数据倾斜怎么解决 spark 中数据倾斜指的是 shuffle 过程中出现的数据倾斜,主要是由于…...

青柠视频云——如何开启HTTPS服务?
前言 由于青柠视频云的语音对讲会使用到HTTPS服务,这里我们说一下如何申请证书以及如何在实战中部署并且配置使用。 一、证书申请 1、进入控制台 我们拿阿里云的免费个人证书为例,首先登录阿里云,在控制台找到数字证书管理服务,进…...

2016年国赛高教杯数学建模A题系泊系统的设计解题全过程文档及程序
2016年国赛高教杯数学建模 A题 系泊系统的设计 近浅海观测网的传输节点由浮标系统、系泊系统和水声通讯系统组成(如图1所示)。某型传输节点的浮标系统可简化为底面直径2m、高2m的圆柱体,浮标的质量为1000kg。系泊系统由钢管、钢桶、重物球、…...

vue-使用refs取值,打印出来是个数组??
背景: 经常使用$refs去获取组件实例,一般都是拿到实例对象,这次去取值的时候发现,拿到的竟然是个数组。 原因: 这是vue的特性,自动把v-for里面的ref展开成数组的形式,哪怕你的ref名字是唯一的!…...

微服务_入门1
文章目录 一、 认识微服务二、 微服务演变2.1、 单体架构2.2、 分布式架构2.3、 微服务2.4、 微服务方案对比 三、 注册中心3.1、 Eureka3.2、 Nacos3.2.1、服务分级存储模型3.2.2、权重配置3.2.3、环境隔离 一、 认识微服务 二、 微服务演变 随着互联网行业的发展,…...

【学习资料】袋中共36个球,红白黑格12个,问能一次抽到3个红4个白5个黑的概率是多少?
1、公式计算 1.1 题目1 袋中共 36 36 36个球, 红 \fcolorbox{red}{#FADADE}{\color{red}{红}} 红 白 \fcolorbox{white}{#808080}{\color{white}{白}} 白 黑 \fcolorbox{#808080}{#0D0D0D}{\color{#808080}{黑}} 黑各 12 12 12个,问能一次抽到 3…...

@PathVariable,@RequestParam,@RequestBody注解,springboot与前端请求之间的数据类型转换
前端数据与springboot java数据类型转换 springboot&mybatis中数组和字符串数据类型的转换-CSDN博客中曾经提到,在Spring Boot中,通过URL传参、payload中的key-value形式或json形式,将前端数据以字符串格式发送到后端,后端We…...

在Python中优雅地打开和操作RDS
在Python中优雅地打开和操作RDS 随着数据存储需求的不断增长,关系数据库服务(Relational Database Service, RDS)成为了许多企业首选的数据存储方式。那么,在Python中如何轻松地与RDS进行交互呢?以下是一份详尽的指南…...

.whl文件下载及pip安装
以安装torch_sparse库为例 一、找到自己需要的版本,点击下载。 去GitHub的pyg-team主页中找到pytorch-geometric包。网址如下: pyg-team/pytorch_geometricgithub.com/pyg-team/pytorch_geometric 然后点击如图中Additional Libraries位置的here&am…...

望繁信科技受邀出席ACS2023,为汽车行业数智化护航添翼
2023年5月25-26日,ACS2023第七届中国汽车数字科技峰会在上海成功举行。此次峰会汇聚了众多汽车领域的顶级专家、产业链代表及企业高管,共同探讨当今汽车产业的转型与未来发展趋势。 作为唯一受邀的流程挖掘厂商代表,望繁信科技携最新行业优势…...

基于 C语言的 Modbus RTU CRC 校验程序
一、CRC校验原理 Modbus RTU是一种常用于工业设备通信的协议,它基于串行通信,如RS-232或RS-485。在Modbus RTU中,CRC(循环冗余校验)是一种常用的错误检测机制,用于确保数据在传输过程中的完整性和准确性。 …...

基于微信小程序的剧本杀游玩一体化平台
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 基于微信小程序JavaSpringBootVueMySQL的剧…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

开发者在构建多模态AI应用时如何借助TaoToken简化模型集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在构建多模态AI应用时如何借助TaoToken简化模型集成 构建一个集成了文本、图像等多模态能力的AI应用,开发者常常…...

为Claude Code配置Taotoken解决账号封禁与Token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决账号封禁与Token不足难题 对于依赖Claude Code进行日常编程辅助的开发者而言,直接使用官…...