pt-query-digest_详细使用方法
pt-query-digest_详细使用方法
- 1. pt介绍
- 1.1. 说明
- 1.2. 安装
- 2 语法选项
- 2.1 所有参数
- 2.2 常见参数
- 2.3 事件和属性
- 2.4 分组
- 2.5 过滤
- 2.6 排序
- 2.7 输出选项
- 2.8 DSN(数据源)选项
- 3. 慢日志
- 3.1 事件属性
- 3.2 分析报告
- 3.2.1 第一部分:总体概况说明
- 3.2.2 第二部分:查询SQL概况说明
- 3.3.3 使用场景
- 4. 通用日志(了解)
- 4.1 属性
- 4.2 分析报告
- 4.3 使用场景
- 5.binlog(了解)
- 5.1 属性
- 5.2 使用场景
- 6 processlist
- 7 将数据保存到表
- 7.1 查询&审计转存到表
- 7.2 查询分析指标转存到表
1. pt介绍
1.1. 说明
pt-query-digest用于分析mysql慢查询的工具,可以分析binlog、General log、slowlog,甚至processlist
分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
1.2. 安装
yum -y install perl-Digest-MD5
yum -y install perl-DBI
yum -y install perl-DBD-MySQL
yum -y install perl-Time-HiRes
yum -y install perl-IO-Socket-SSL
yum -y install perl-TermReadKey
rpm -ivh percona-toolkit-3.5.1-2.el7.x86_64.rpm
2 语法选项
pt-query-digest [OPTIONS] [FILES] [DSN]
2.1 所有参数
pt-query-digest --help
| 变量 | 默认值 | 说明 |
|---|---|---|
| –ask-pass | FALSE | #连接到MySQL时提示输入密码 |
| –attribute-aliases | db/Schema | #属性列表别名等(默认db/schema) |
| –attribute-value-limit | 0 | #属性值的限制(默认为0) |
| –charset | (No value) | #默认字符集 |
| –config | /etc/percona-toolkit/percona-toolkit.conf,/etc/percona-toolkit/pt-query-digest.conf,/root/.percona-toolkit.conf,/root/.pt-query-digest.conf | #逗号分隔的配置文件列表;如果指定,则必须是命令行上的第一个选项 |
| –continue-on-error | TRUE | #即使有错误也继续解析 |
| –create-history-table | TRUE | #创建–history表(如果不存在)(默认为yes) |
| –create-review-table | TRUE | #创建–review表(如果不存在)(默认为yes) |
| –daemonize | FALSE | #Fork到后台并从shell分离 |
| –database | (No value) | #连接到该数据库 |
| –defaults-file | (No value) | #从给定文件读取mysql选项 |
| –embedded-attributes | (No value) | #两个Perl正则表达式模式,用于捕获查询中嵌入的伪属性 |
| –expected-range | 5,10 | #当数量多于或少于预期时解释项目(默认值为5,10) |
| –explain | (No value) | #使用此DSN对示例查询运行EXPLAIN并打印结果 |
| –filter | (No value) | #过滤事件 |
| –group-by | fingerprint | #要对事件的哪个属性进行分组(默认fingerprint) |
| –help | TRUE | #显示帮助并退出 |
| –history | (No value) | #在给定表中保存每个查询类的指标。 pt-query-digest将查询指标(查询时间,锁定时间等)保存到此表中,以便您查看查询类如何随时间变化 |
| –host | (No value) | #连接到主机 |
| –ignore-attributes | arg cmd insert_id ip,port Thread_id timestamp exptime flags key res val server_id offset end_log_pos Xid | #不要聚合这些属性 |
| –inherit-attributes | db,ts | #如果丢失,则从具有属性的最后一个事件继承这些属性(默认db,ts) |
| –interval | .1 | #轮询show processlist的频率,以秒为单位(默认为.1) |
| –iterations | 1 | #在收集和报告周期中迭代多少次(默认为1) |
| –limit | 95%:20 | #将输出限制为给定的百分比或计数(默认为95%:20) |
| –log | (No value) | #守护进程时将所有输出打印到此文件 |
| –max-hostname-length | 10 | #将报告中的主机名修剪到此长度。 0 =不修剪主机名(默认为10) |
| –max-line-length | 74 | #将行修剪到此长度。 0 =不修剪线条(默认74) |
| –order-by | Query_time:sum | #按此属性:聚合函数对事件进行排序(默认Query_time:sum) |
| –outliers | Query_time:1:10 | #按属性:百分比:计数报告异常值(默认查询时间:1:10) |
| –output | report | #如何格式化和打印查询分析结果(默认report) |
| –password | (No value) | #连接时使用的密码 |
| –pid | (No value) | #创建给定的PID文件 |
| –port | (No value) | #用于连接的端口号 |
| –preserve-embedded-numbers | FALSE | #查询时保留数据库/表名中的数字 |
| –processlist | (No value) | #使用–interval sleep轮询此DSN的进程列表以进行查询 |
| –progress | time,30 | #将进度报告打印到STDERR(默认时间30) |
| –read-timeout | 0 | #等待的超时时间,等待来自输入的事件; 0表示永远等待(默认值为0)。 可选后缀s =秒,m =分钟,h =小时,d =天; 如果没有后缀,则使用s。 |
| –report | TRUE | #打印每个–group-by属性的查询分析报告(默认为yes) |
| –report-all | FALSE | #报告所有查询,甚至包括已审核的查询 |
| –report-format | rusage,date,hostname,files,header,profile,query_report,prepared | #打印查询分析报告的这些部分 |
| –report-histogram | Query_time | #绘制此属性值的分布图(默认Query_time) |
| –resume | (No value) | #如果指定,该工具会将最后一个文件偏移(如果有的话)写入给定的文件名 |
| –review | (No value) | #保存查询以供以后查看,并且不报告已查看的 |
| –run-time | (No value) | #每个迭代要运行多长时间。可选后缀s =秒,m =分钟,h =小时,d =天;如果没有后缀,则使用s。 |
| –run-time-mode | clock | #设置–run-time的值所用的值(默认clock) |
| –sample | (No value) | #过滤掉每个查询中除前N个事件外的所有事件 |
| –set-vars | #在此以逗号分隔的(变量=值对)列表中设置MySQL变量 | |
| –show-all | #显示这些属性的所有值 | |
| –since | (No value) | #解析仅查询比该值新的查询(自此日期以来解析查询) |
| –slave-password | (No value) | #设置用于连接到从的密码 |
| –slave-user | (No value) | #设置用于连接到从的用户 |
| –socket | (No value) | #用于连接的套接字文件 |
| –timeline | FALSE | #显示事件的时间表 |
| –type | slowlog | #要解析的输入的类型(默认慢日志) |
| –until | (No value) | #仅解析早于此值的查询(直到此日期为止解析查询) |
| –user | (No value) | #用于登录的用户(如果不是当前用户) |
| –variations | #报告这些属性值的变化数量 | |
| –version | FALSE | #显示版本并退出 |
| –version-check | TRUE | #检查最新版本的Percona Toolkit,MySQL和其他程序(默认为是) |
| –vertical-format | TRUE | #在报告的SQL查询中输出尾随的“ \ G”(默认为是) |
| –watch-server | (No value) | #此选项告诉pt-query-digest在解析tcpdump时要监视哪个服务器IP地址和端口(例如“ 10.0.0.1:3306”)(对于–type tcpdump);其他所有服务器均被忽略 |
2.2 常见参数
--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。
--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。
--filter 对输入的慢查询按指定条件进行匹配过滤后再进行分析
--limit 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
--host mysql服务器地址
--user mysql用户名
--password mysql用户密码
--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。
--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
--until 截止时间,配合—since可以分析一段时间内的慢查询。
--sample:过滤掉每个查询中除前N个事件外的所有事件
--type: slowlog,genlog,binlog指定分析的日志类型
2.3 事件和属性
当使用过滤/分组/排序的时候,需要了解其事件属性,可用于过滤/分组/排序。
-
event
pt-query-digest处理得到的单元叫事件,这些事件是属性集合,例如查询时间,锁时间等。 -
得到属性
$ pt-query-digest slow.log --filter 'print Dumper $event' --no-report --sample 1
产生很多带有“ attribute => value”对的输出
- slowlog
$VAR1 = {Lock_time => '0.000101',Query_time => '7.967977',Rows_examined => '1000000',Rows_sent => '1000000',Thread_id => '20',arg => 'select * from emp limit 1000000',bytes => 31,cmd => 'Query',db => 'dbsql',fingerprint => 'select * from emp limit ?',host => 'localhost',ip => '',pos_in_log => 8768,timestamp => '1679739655',ts => '2023-03-25T10:20:55',user => 'root'
};
- genlog
$VAR1 = {Query_time => '7.967977',Thread_id => '20',arg => 'select * from emp limit 1000000',bytes => 31,cmd => 'Query',db => 'dbsql',fingerprint => 'select * from emp limit ?',pos_in_log => 8768,ts => '2023-03-25T10:20:55'
};
- binlog
$VAR1 = {Query_time => '7.967977',Thread_id => '20',arg => 'select * from emp limit 1000000',bytes => 31,cmd => 'Query',db => 'dbsql',end_log_pos => '289',error_code => '0',fingerprint => 'select * from emp limit ?',offset => '108',pos_in_log => 8768,server_id => '111',timestamp => '1679739655',ts => '2023-03-25T10:20:55',
};
- 新建属性
例如编写–filter,可以创建从现有属性派生的新属性。 例如,要创建一个名为Row_ratio的属性以检查Rows_sent与Rows_examined的比率,请指定一个过滤器:
--filter '($event->{Row_ratio} = $event->{Rows_sent} / ($event->{Rows_examined})) && 1'
# Row ratio 1.00 0.00 1 0.50 1 0.71 0.50
2.4 分组
默认情况下按fingerprint分组,并按查询时间的降序排列(最慢的查询排在第一位)。
- FINGERPRINTS
简而言之就是将将相似的查询分组在一起,如:
SELECT name, password FROM user WHERE id='12823';
select name, password from user where id=5;
可以合并当成:
select name, password from user where id=?
- group-by
group-by:对event的哪个属性进行分组(默认fingerprint)。可以根据查询的任何属性(如user或db)将查询分组为类,默认情况下,这些属性将显示哪些用户和哪些数据库获得的Query_time最多。每个值在–order-by中的相同位置必须具有对应的值。为方便起见,将值添加到–group-by将自动将值添加到–order-by。如根据db和user分组:
--group-by=db,user# Report grouped by db
...
# Report grouped by user
...
- 可选值有:
fingerprint:指纹,将查询抽象为规范形式,然后用于将event分组到一个类中。
tables:按表的形式返回报告信息。
distill:超级指纹,将查询分解为对它们执行操作的建议。
2.5 过滤
- filter:过滤器规则,舍弃此Perl代码未返回true的事件。属性的名称可以看文章前面的 “ attribute => value”。
只返回指定类型的查询,如返回select的查询:
--filter '$event->{arg} =~ m/^select/i'
--filter '$event->{fingerprint} =~ m/^select/i'
只返回指定用户的查询,如返回hulk用户的查询:
--filter '$event->{user} =~ m/^hulk/i'
--filter '($event->{user} || "") =~ m/^hulk/i'
只返回指定IP的查询,如返回192.168.16.111的查询:
--filter '($event->{host} || $event->{ip} || "") =~ m/^192.168.16.111/i'
只返回指定DB的查询,如返回dbsql DB的查询:
--filter '($event->{db} || "") =~ m/^dbsql/i'
返回指定DB和类型的查询,如返回dbsql DB中的select查询:
--filter '(($event->{db} || "") =~ m/^dbsql/i) && (($event->{fingerprint} || "") =~ m/^select/i)'
2.6 排序
order-by:通过指定属性对事件进行排序,默认值:Query_time:sum,也用于–group-by属性。
对于genlog)默认的属性为Query_time:cnt。
#按总的执行时间排序
order-by=Query_time:sum
#按总的执行次数排序
order-by=Query_time:cnt
2.7 输出选项
- output
默认的–output是查询分析报告。 - no-report
–no-report选项控制是否打印此报告。 - review
使用–review或–history时,解析所有查询但不显示报告。
将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用–review时,如果存在相同的语句分析,就不会记录到数据表中。 - history
使用–review或–history时,解析所有查询但不显示报告。
将分析结果保存到表中,分析结果比较详细,下次再使用–history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。默认表是query_history,指定数据库(D)和表(t)的DSN选项以覆盖默认值。 除非指定了–no-create-history-table,否则将自动创建数据库和表。
--history='h=192.168.163.132,u=root,p=root'
2.8 DSN(数据源)选项
用于创建DSN, 例如想将得到的数据存储到表中,则配置DSN。各个选项说明如下:
A:默认字符集
D:连接到MySQL时要使用的默认数据库。
F:从给定文件中读取默认选项。
h:连接到主机的地址。
p:连接使用的密码,如果密码包含逗号,则必须使用反斜杠将其转义。
P:用于连接的端口号。
S:连接的套接字文件。
t:指定--review或--history表名。
u:连接的用户。
3. 慢日志
slow log:–type=slowlog
3.1 事件属性
$VAR1 = {Lock_time => '0.000101',Query_time => '7.967977',Rows_examined => '1000000',Rows_sent => '1000000',Thread_id => '20',arg => 'select * from emp limit 1000000',bytes => 31,cmd => 'Query',db => 'dbsql',fingerprint => 'select * from emp limit ?',host => '192.168.16.111',ip => '192.168.16.111',pos_in_log => 8768,timestamp => '1679739655',ts => '2023-03-25T10:20:55',user => 'root'
};
3.2 分析报告
3.2.1 第一部分:总体概况说明
-- 分析消耗的用户CPU时间,系统CPU时间,物理内存占用大小,虚拟内存占用大小
# 150ms user time, 20ms system time, 27.02M rss, 221.53M vsz
-- 分析的当前日期
# Current date: Sun Mar 26 09:49:20 2023
-- 分析的主机名
# Hostname: sdns
-- 分析的文件名
# Files: /data/mysql/my3306/logs/slow.log
-- 分析的整体情况:语句总数量,唯一语句数量,QPS和并发数
# Overall: 40 total, 14 unique, 0.00 QPS, 0.01x concurrency
-- 分析日志的时间范围
# Time range: 2023-03-24T13:55:43 to 2023-03-26T13:47:01
--属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
-- 执行时间
# Exec time 918s 322us 734s 23s 26s 112s 32ms
-- 锁时间
# Lock time 385ms 0 199ms 10ms 38ms 32ms 268us
-- 发送到客户端的行数
# Rows sent 18.88M 0 7.63M 483.42k 1.86M 1.24M 3.89
-- 扫描行数
# Rows examine 27.62M 0 7.63M 707.19k 2.75M 1.65M 3.89
-- 查询的字节数
# Query size 1.34k 15 123 34.20 80.10 22.23 24.84
/*如果在此地方想新增一些属性,可以用--filter来进行设置 比如:--filter '($event->{Row_ratio} = $event->{Rows_sent}/($event->{Rows_examined}))' ,会新增Row ratio属性*/-- 概况统计
# Profile
-- 排名,查询指纹,总响应时间及百分比,执行次数,执行平均响应时间,响应时间Variance-to-mean的比率,查询对象
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============== ===== ======== ===== ============
# 1 0x62C7F17FEBCDF619 733.6364 79.9% 1 733.6364 0.00 CALL insert_emp
# 2 0x1F571989BCCA84ED 91.1762 9.9% 14 6.5126 10.14 SELECT emp
# 3 0x7AD1AD546607A77C 57.0595 6.2% 1 57.0595 0.00 SELECT emp
# MISC 0xMISC 36.4823 4.0% 24 1.5201 0.0 <11 ITEMS> #剩余查询的显示
3.2.2 第二部分:查询SQL概况说明
-- 查询的顺序号(和第一部分的Rank对应),QPS,并发,查询指纹,
# Query 1: 0.08 QPS, 0.16x concurrency, ID 0x5C3D88030F0258F752A830BD792DF4BA at byte 739
# This item is included in the report because it matches --limit.
-- 响应比率
# Scores: V/M = 0.00
-- 分析查询的时间范围
# Time range: 2020-03-01T15:53:12 to 2020-03-01T15:54:16
-- 属性,百分比,总数,最小,最大,95%,标准,中等
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
-- 次数
# Count 55 5
-- 执行时间
# Exec time 38 10s 2s 2s 2s 2s 0 2s
-- 锁时间
# Lock time 38 7ms 209us 6ms 1ms 6ms 2ms 273us
-- 发送到客户端的行数
# Rows sent 43 20 4 4 4 4 0 4
-- 扫描行数
# Rows examine 43 20 4 4 4 4 0 4
-- 查询的字节数
# Query size 63 325 65 65 65 65 0 65
-- 发送和扫描行数比值,用第一部分提到的--filter来进行设置
# Row ratio 55 5 1 1 1 1 0 1
# String:
-- 数据库
# Databases test
-- 主机
# Hosts test2
-- 查询用户
# Users root
-- 查询执行时间分布的直方图:1微妙、10微妙、100微妙、10毫秒、100毫秒,1秒,10秒以上查询的分布情况
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
-- 表信息
# Tables
# SHOW TABLE STATUS FROM `test` LIKE 'host'\G
# SHOW CREATE TABLE `test`.`host`\G
-- 执行计划信息
# EXPLAIN /*!50100 PARTITIONS*/
-- 查询SQL
select id,hostname,agent_version,sleep(0.5) from host where id <5\G #如果是非select查询:insert,delete,update,则会转换成select进行explain
3.3.3 使用场景
①:分析所有的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog
②:分析指定数据库的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --filter '($event->{db} || "") =~ m/^dbsql/i'
③:分析指定用户的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --filter '($event->{user} || "") =~ m/^pmm/i'
④:分析指定IP的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --filter '($event->{host} || $event->{ip} || "") =~ m/^192.168.16.*/i'
⑤:分析指定时间范围的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --since='2023-03-26 00:00:00' --until='2023-03-27 23:59:59'
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --since='1583048987' --until='1583049175'
⑥:分析最近时间的慢查询(最近10h,单位可以为s、和m):
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --since='10h'
⑦:分析指定查询类型的慢查询:
pt-query-digest /data/mysql/my3306/logs/slow.log --type=slowlog --filter '$event->{arg} =~ m/^update/i'
⑧:指定时间、排除指定IP、指定慢查类型(select)写入到表中:
pt-query-digest --user=root --password=root --port=3306 --review h=192.168.16.111,D=slow_query_log,t=global_query_review --history h=192.168.16.111,D=slow_query_log,t=global_query_review_history --limit=0% --filter='($event->{Bytes} = length($event->{arg}) and $event->{hostname}="dbsql") and ($event->{host} || $event->{ip}) !~ m/^localhost$|^192.168.16.1$/i and $event->{arg} =~ m/^select/i' --since='2023-03-23 12:00:00' --until='2023-03-30 13:00:00' /data/mysql/my3306/logs/slow.log --no-report
4. 通用日志(了解)
general log:–type=genlog
4.1 属性
$VAR1 = {Query_time => 0,Thread_id => '138',arg => 'SHOW FULL PROCESSLIST',bytes => 21,cmd => 'Query',db => 'mysql',fingerprint => 'show full processlist',pos_in_log => 191402,ts => '2023-03-28T12:21:53.692656Z'
};
general log order-by默认从Query_time:sum改成了Query_time:cnt。general log没有执行时间。
4.2 分析报告
第一部分:总体概况说明,同上面的slow log。
第二部分:查询SQL概况说明。
# Query 1: 0 QPS, 0x concurrency, ID 0x0BBD8F114BF69E6F45609ADE347419D3 at byte 1075144
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: 2023-03-28T09:38:40.431645Z to 2020-02-29T17:03:19.210317Z
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
-- 次数
# Count 96 16463
-- 执行时间
# Exec time 0 0 0 0 0 0 0 0
-- 查询字节数
# Query size 90 337.62k 21 21 21 21 0 21
# String:
# Databases mysql
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+
SHOW FULL PROCESSLIST\G
4.3 使用场景
①:分析所有general log:
pt-query-digest /data/mysql/my3306/data/sdns.log --type=genlog
②:分析指定数据库的general log:
pt-query-digest /data/mysql/my3306/data/sdns.log --type=genlog --filter '($event->{db} || "") =~ m/^dbsql/i'
③:分析指定用户的general log:
pt-query-digest /data/mysql/my3306/data/sdns.log --type=genlog --filter '($event->{user} || "") =~ m/^pmm/i'
④:分析指定IP的general log:只能查询有连接信息的一行
pt-query-digest /data/mysql/my3306/data/sdns.log --type=genlog --filter '($event->{host} || $event->{ip} || "") =~ m/^192.168.16.111/i'
⑤:分析指定查询类型的general log:
pt-query-digest /data/mysql/my3306/data/sdns.log --type=genlog --filter '$event->{arg} =~ m/^update/i'
5.binlog(了解)
binlog:–type=binlog
预备:在分析binlog之前,需要先把binlog转换成文本:
mysqlbinlog --no-defaults -vv --base64-output=DECODE-ROWS mysql-bin.000022 > mysql-bin.000022.txt
5.1 属性
$VAR1 = {Query_time => '0',Thread_id => '176',arg => '...',bytes => 40,cmd => 'Query',db => 'xyz',end_log_pos => '695',error_code => '0',fingerprint => '...',offset => '583',pos_in_log => 1942,server_id => '1',timestamp => '1583133657',ts => '202303 15:20:57'
};
5.2 使用场景
① 分析所有binlog:
pt-query-digest mysql-bin.000022.txt --type=binlog
②:分析指定数据库的bin log:
pt-query-digest mysql-bin.000022.txt --type=binlog --filter '($event->{db} || "") =~ m/^dbsql/i'
③:分析指定时间范围的binlog
pt-query-digest mysql-bin.000022.txt --type=binlog --since='2023-03-26 15:49:47' --until='2023-03-27 23:59:55'
④:分析最近时间的binlog
pt-query-digest mysql-bin.000022.txt --type=binlog --since='60m'
⑤:分析指定类型的binlog
pt-query-digest mysql-bin.000022.txt --type=binlog --filter '$event->{arg} =~ m/^update/i'
6 processlist
①:抓取show processlist的慢查,转存到指定文件:
间隔1s执行show full processlist 拉取processlist中订阅到的慢查询转存到指定的文件。
pt-query-digest --processlist h=192.168.16.111,u=root,p=123456 --interval=1 --output=slowlog > /tmp/process.log
说明:比较适用于一些云数据库没有看慢查文件的权限。
②:分析show processlist的慢查:配合–run-time使用,可以限制执行时间,到时间(–iterations=1)之后退出并且打印分析。
间隔1s执行show full processlist,永远运行,每30秒生成一次报告
pt-query-digest --processlist h=192.168.16.111,u=root,p=123456 --interval=1 --run-time-mode=clock --run-time=30s --iterations=0
说明:比较适用于一些问题排查方面的工作。
7 将数据保存到表
7.1 查询&审计转存到表
pt-query-digest --review u=root,p=123456,h=192.168.16.111,P=3306,D=xyz,t=query_review --create-review-table test2-slow.log
说明:把慢查询记录到数据库xyz的query_review表中:
表列说明:
| 字段 | 说明 |
|---|---|
| checksum | 查询指纹的64位校验和 |
| fingerprint | 查询的抽象版本;它的主键 |
| sample | 查询样本的文本 |
| first_seen | 此类查询的最早时间戳 |
| last_seen | 此类查询的最近时间戳 |
| reviewed_by | 如果设置,此后将跳过查询 |
| reviewed_on | 没有赋予任何特殊含义 |
| comments | 没有赋予任何特殊含义 |
注意:如果表中的记录reviewed_by被设了值,则下次运行pt-query-digest --review不会显示该query。
7.2 查询分析指标转存到表
pt-query-digest --history u=root,p=123456,h=192.168.16.111,P=3306,D=xyz,t=query_review_history --create-review-table /data/mysql/my3306/data/sdns.log
说明:把慢查询记录的分析指标转存到数据库xyz的query_review_history表中:
注意:通过report打印出来的信息转存到表中。针对1,2生成的表可以进行关联,来找出那些没有被审计的SQL。通过这2个参数,可以做成一个MySQL的慢查询审计平台。
相关文章:

pt-query-digest_详细使用方法
pt-query-digest_详细使用方法1. pt介绍1.1. 说明1.2. 安装2 语法选项2.1 所有参数2.2 常见参数2.3 事件和属性2.4 分组2.5 过滤2.6 排序2.7 输出选项2.8 DSN(数据源)选项3. 慢日志3.1 事件属性3.2 分析报告3.2.1 第一部分:总体概况说明3.2.2 第二部分:查…...

基于MATLAB编程的萤火虫FA优化BP神经网络的回归分析
目录 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络激活函数及公式 SVM应用实例,基于fa-svm分类预测 代码 结果分析 展望 BP神经网络的原理 BP神经网络的定义 人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过…...
)
leetcode 消失的数字(面试题)
题目 数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在O(n)时间内完成吗? 注意:本题相对书上原题稍作改动 示例 1: 输入:[3,0,1] 输出:2 示例 2: 输入&…...

Spring入门篇6 --- AOP
目录1.核心概念AOP(Aspect Oriented Programming)面向切面编程:一种编程范式,指导开发者如何组织程序结构作用:在不惊动原始设计的基础上为其进行功能增强。连接点(JoinPoint):程序执行过程中的任意位置切入点(PointCut)ÿ…...
linux 配置java环境
1、上传jdk包到/usr/local/java目录下 2、解压jdk的tar包 tar -zxvf jdk-8u291-linux-x64.tar.gz 3、添加配置(环境变量) 注意:JAVA_HOME值为实际jdk路径 打开配置文件 vi /etc/profile 最下面添加: #set java environment JAVA_HOME/usr/…...

分布式事务基础入门
分布式事务基础入门 什么是分布式事务 什么是分布式事务? 首先理解什么是本地事务? 平常我们在程序中通过spring去控制事务是利用数据库本身的事务特性来实现的,因此叫数据库事务,由于应用主要靠关系数据库来控制事务࿰…...

白盒测试究竟怎么做
大家好,我是洋子 在进行日常测试的时候,我们大部分时间花在手动的功能测试上,功能测试又可称为手工测试,官方一点的学名叫黑盒测试,当然作为测试工程师,我们一般俗称点点点 黑盒测试是一种软件测试方法&am…...
EEG微状态的功能意义
导读大脑的瞬时全局功能状态反映在其电场结构上。聚类分析方法一致地提取了四种头表面脑电场结构,这些结构能够最佳地解释自发EEG记录中随时间变化的差异。这四种结构被称为EEG微状态A、B、C和D类,分别与言语/语音、视觉、主观感受-自主加工和注意力重定…...

Python3 - Flask+swift实现单点登录
基于 Flask 和 Redis 实现单设备登录的服务端代码和客户端swift、oc代码: Python flask 实现服务端 from flask import Flask, jsonify, request from redis import Redisapp Flask(__name__) redis_db Redis()# 用户登录接口,验证用户名和密码&#…...

HTML URL
文章目录HTML URLURL - 统一资源定位器常见的 URL SchemeURL 字符编码URL 编码实例HTML URL URL 是一个网页地址。 URL可以由字母组成,如"csdn.net",或互联网协议(IP)地址: 192.168.100.1。大多数人进入网站…...

带你了解ICCV、ECCV、CVPR三大国际会议
文章目录 前言 一、ICCV、ECCV、CVPR是什么? 1.ICCV 2.ECCV 3.CVPR 二、三大会链接及论文下载链接 前言 作为刚入门CV的新人,有必要记住计算机视觉方面的三大顶级会议:ICCV,CVPR,ECCV,统称为ICE。 与其它学术领域不同,计算机科学使用会议而不是期刊作为发表研究成果的主…...
常用的一些代码
今天菜鸟涨工资了,到手估计有8000左右了,有点开心,本来想上一篇就把这篇写了的,但是发现还是分开写比较好! 文章目录自适应js禁止放大播放声音store的使用websocket封装echarts实现渐变swiper常用的陌生方法࿰…...
和np.array.shape()属性)
Python-df.pop()和np.array.shape()属性
1.df.pop() 删除某一列 可以使用这个来删除某一列(不能是多列),只有一个参数,就是列名,可以是str类型,函数返回的是被删除的列,df直接是删除后的df,不需要我们处理。 我们建模时&a…...

多线程并发编程笔记03(小滴课堂)---线程安全性
原子性操作: 这样一段代码。 我们输出一下: 我们发现它的结果和我们想的不太一样。 正常应该输出1000. 这是因为没有保证原子性。 所以我们来加上原子性: 这样就保证了我们的原子性。 接下来我们来细说说这个关键字: 我发现我…...
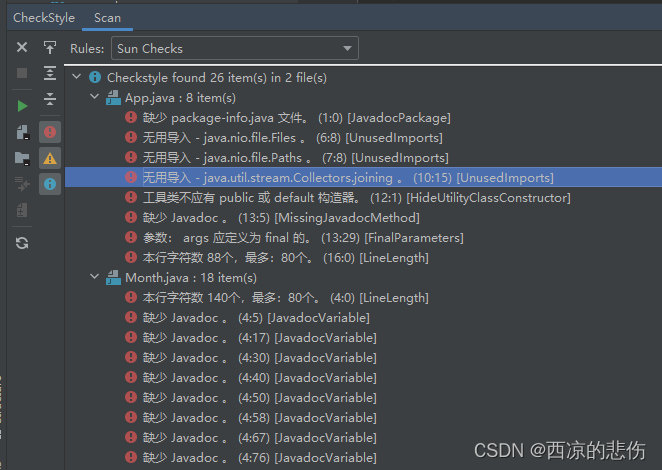
提升代码质量,使用插件对 java 代码进行扫描检查分析
目录前言一、使用maven-checkstyle-plugin插件1. maven-checkstyle-plugin 介绍2.引入依赖3.使用二、使用 idea 插件1.安装2.使用前言 很多时候我们的代码写的不规范,比如没缩进、参数间没空格、导入的包没用到没删除、方法很长没有进行拆分、 直接对方法参数进行了…...

如何用秒验提升用户体验和转换率?
手机号验证是移动应用开发中常见的需求,它可以用于用户注册、登录、身份认证等场景。目前,市场上主要的手机号验证方式是短信验证码,但这种方式存在一些问题,例如: 延迟:短信验证码需要等待运营商发送和用…...

【新】(2023Q2模拟题JAVA)华为OD机试 - 机器人活动区域
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:机器人活动区域 题目 现有一…...

2023软件测试面试真题宝典大汇总,没收藏的都后悔了
下边是我根据工作这几年来的面试经验,加上之前收集的资料,整理出来350道软件测试工程师 常考的面试题。字节跳动、阿里、腾讯、百度、快手、美团等大厂常考的面试题,在文章里面都有提到。 虽然这篇文章很长,但是绝对值得你点击一…...
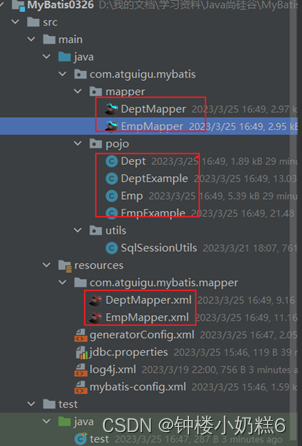
十、MyBatis的逆向工程
一、MyBatis的逆向工程 正向工程:先创建java实体类,由框架负责根据实体类生成数据库表。Hibernate是支持正向工程逆向工程:先创建数据库表,由框架负责根据数据库表,反向生成如下资源: Java实体类 Mapper接口 Mapper映射文件 1.创…...

网站是怎么屏蔽脏话的呢:简单学会SpringBoot项目敏感词、违规词过滤方案
一个社区最重要的就是交流氛围与审查违规,而这两者都少不了对于敏感词进行过滤的自动维护措施。基于这样的措施,我们才能基本保证用户在使用社区的过程中,不至于被敏感违规词汇包围,才能够正常的进行发布帖子和评论,享…...

Robodyssey机器人教育:从STEM理念到项目实践,点燃孩子科技兴趣
1. 项目概述与核心理念十年前,我在一次行业展会上第一次看到一群孩子围着一个摊位,他们不是在玩现成的玩具,而是聚精会神地调试着自己手里那些由电线、电路板和塑料零件组成的“小怪物”。那个摊位就是Robodyssey。当时我就在想,把…...
)
专利技术复杂性地级市面板(2001-2025)
核心速览数据编号:2323时间跨度:2001–2025空间尺度:中国全部地级市数据格式:Excel 年度面板测算依据:Research Policy 2026 顶刊范式(Frigon)测算方法(可直接写论文)以I…...

Qt 批量读取Excel数据:从性能瓶颈到优化实践
1. 为什么Qt读取Excel会卡成PPT? 第一次用Qt操作Excel表格时,我兴冲冲写了个循环读取单元格的代码。结果打开包含5000行数据的文件后,进度条像蜗牛爬坡,鼠标指针转成彩色圆圈,程序直接卡成PPT幻灯片模式——这场景估计…...

Ask your GIT:AI驱动的代码仓库智能助手,一键解析与安装
1. 项目概述:一个为开发者“减负”的智能代码助手在GitHub、GitLab或者Bitbucket上发现一个看起来很有潜力的开源项目,是每个开发者的日常。但随之而来的,往往是长达十几甚至几十分钟的“阅读理解”时间:你得先通读冗长的README&a…...

ComfyUI-Impact-Pack深度解析:从AI图像模糊到专业级细节增强的完整解决方案
ComfyUI-Impact-Pack深度解析:从AI图像模糊到专业级细节增强的完整解决方案 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. …...

计算机视觉工程师的周度技术雷达:从论文到产线的工程化筛选方法
1. 这不是一份“论文清单”,而是一份计算机视觉从业者的周度技术雷达 如果你每天刷arXiv、看CVPR会议摘要、追GitHub trending,却总在“读完就忘”和“知道很重要但不知从何下手”之间反复横跳——那你不是一个人。我做CV方向的工程落地和算法选型已经十…...

QQ音乐加密文件解密终极指南:qmcdump工具完整教程
QQ音乐加密文件解密终极指南:qmcdump工具完整教程 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

如何快速构建Python量化分析系统:5步掌握通达信数据接口
如何快速构建Python量化分析系统:5步掌握通达信数据接口 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个基于Python的高效通达信数据接口封装,专为量化投资和数…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

车规级国际物联卡是什么?车载物联网硬件选型与行业标准解析
随着跨境整车出口、改装车辆、工程机械外销、车载定位终端普及,车载联网通信要求持续升级。普通民用SIM卡无法适配车辆颠簸、温差跨度大、高速移动、跨境切换网络的复杂工况,车规级国际物联卡逐步成为车载智能化硬件的标配通信载体。很多出海设备厂商容易…...