机器学习算法与实践_03概率论与贝叶斯算法笔记
1、概率论基础知识介绍
人工智能项目本质上是一个统计学项目,是通过对 样本 的分析,来评估/估计 总体 的情况,与数学知识相关联
-
高等数学 ——> 模型优化
-
概率论与数理统计 ——> 建模思想
-
线性代数 ——> 高性能计算
在机器学习中,许多算法都是基于概率模型进行构建的,这些模型使用概率来描述数据生成过程,从而能够对数据进行预测和分类,例如:
- 朴素贝叶斯分类器:基于贝叶斯定理,使用概率来预测数据点的类别
- 逻辑回归:虽然通常被视为线性分类器,但它本质上是一个概率模型,输出的是数据点属于某个类别的概率
- 隐马尔可夫模型(HMMs):使用概率来描述状态转换和观测序列
所以,我们需要先了解概率论相关基础知识,为下面理解贝叶斯算法原理打下基础
1.1 概率与频率
在实际操作中,直接计算或得知某个事件的精确概率可能是困难的或不可能的,而频率作为一个可观测、可计算的量,为我们提供了一种近似估计概率的方法
1.1.1 定义
-
概率(probability,又称或然率、置信度): 是数学中描述某个事件发生的可能性的量度,是一个理论上的度量,它通常是一个介于0和1之间的实数,其中0表示事件几乎不可能发生,1表示事件几乎肯定会发生
-
频率(frequency): 是实际观测或实验中某一事件发生的次数与总试验次数之比,它是一个经验度量,反映了在一系列试验中事件实际发生的次数
1.1.2 用频率估概率
-
大数定律:大数定律是概率论中的一个基本定理,它指出当试验次数足够多时,事件发生的频率将趋近于其真实概率,这意味着随着试验次数的增加,频率作为概率的估计会越来越准确
-
实际应用:在实际应用中,尤其是数据科学和机器学习领域,我们经常使用频率来估计概率,例如:在训练模型时,我们可能使用大量数据来估计某个特征值出现的概率
-
数据量与估计准确性:数据量越大,频率估计的准确性通常越高,这是因为大数定律保证了频率随试验次数增加而趋于稳定
1.1.3 工程实践中的处理
-
数据驱动的决策:在工程实践中,尤其是在数据量很大的情况下,我们经常直接使用频率作为概率的替代,这种方法在处理大量数据时尤其有效,因为大数定律确保了估计的稳定性和可靠性
-
模型训练:在机器学习模型训练中,我们通常使用大量数据来估计模型参数,这些参数的概率分布往往通过频率来估计
-
统计推断:统计推断中,频率也被用来估计总体参数,例如:样本均值的分布可以用来估计总体均值
1.1.4 注意事项
-
有限样本偏差:在样本量较小的情况下,频率可能不是概率的良好估计,因为小样本更易受到随机波动的影响
-
数据质量:数据的质量和代表性也会影响频率估计的准确性,数据集中的偏差或不准确可能导致估计结果不可靠
1.2 概率的基本特性
-
非负性: 概率的非负性是指任何事件发生的概率都不会是负数,即:

-
规范性: 概率的规范性(或归一性)是指在一个完整样本空间内所有可能事件的概率之和等于1。这适用于所有可能的事件集合,包括所有可能的单一事件和它们的组合。对于一个包含所有可能结果的样本空间,存在:

其中:
 表示样本空间中的第
表示样本空间中的第 个事件,
个事件, 是事件的总数
是事件的总数 -
单调性:如果事件
 (即:当事件 A 发生时,事件 B 也同样会发生),那么
(即:当事件 A 发生时,事件 B 也同样会发生),那么
-
可加性:对于两个互斥事件 A 和 B (即:它们不能同时发生),存在:

-
连续性:对于一系列事件
 ,如果这些事件是互斥的,并且覆盖了整个样本空间,那么对于任意事件
,如果这些事件是互斥的,并且覆盖了整个样本空间,那么对于任意事件 包含在这些事件中的概率可以通过极限来定义
包含在这些事件中的概率可以通过极限来定义
1.3 概率的计算方法
1.3.1 离散型变量
(1)特点: 有限个状态,状态之间无大小、程度等概念,状态之间是严格对立的
(2)示例:
- 鸢尾花有山鸢尾、杂色鸢尾、长鞘鸢尾等不同类型的品种
- 交通信号灯有红、绿、黄不同的颜色
- 人类有男、女不同的性别
- 骰子有1、2、3、4、5、6不同的点数
(3)编码: 连续型变量是指有限个状态,而状态大多数不是数值类型的数据,不易进行处理,所以需要对其进行编码(编码就是为了将非数值型数据转换为机器学习算法可以处理的数值型数据,方便进行处理)
离散型变量的常用编码方法分为Zero index编码和One hot编码这两种
-
①Zero Index编码: 也称为索引编码或标签编码,是一种将类别变量转换为从0开始的连续整数的方法,每个类别被赋予一个唯一的整数标签。
特点:
-
简单:实现简单,易于理解和操作。
-
连续性:编码是连续的,从0开始,但这种连续性并不代表类别之间的任何顺序或等级关系。
-
大小无内涵:编码的大小没有数学意义,例如,编码为1和编码为4的类别是平等的,它们之间没有内在的比较意义。
-
应用场景:
-
适用于那些类别之间没有顺序或等级关系的情况。
-
常用于机器学习模型中,如决策树、随机森林等。
-
②One Hot编码: 也称为一位有效编码,是一种将类别变量转换为二进制向量的方法,每个类别都分别由一个长度等于类别数的向量表示,并且在此向量中只有一个位置为1,其余位置均为0。
特点:
-
向量表示:每个类别由一个唯一的二进制向量表示,向量中的1表示该类别的存在。
-
平等性:所有类别在向量空间中是平等的,没有大小或顺序之分。
-
无序性:One Hot编码不包含任何类别之间的顺序或等级信息。
-
应用场景:
-
适用于需要明确区分类别,且类别之间没有顺序或等级关系的情况。
-
常用于自然语言处理、推荐系统、神经网络等场景。
-
③示例: 假设有一个数据集,包含三个类别:苹果、香蕉、樱桃,则使用这两种编码方式可以表示如下:
Zero Index编码:
-
苹果:0
-
香蕉:1
-
樱桃:2
-
One Hot编码:
-
苹果:[1, 0, 0]
-
香蕉:[0, 1, 0]
-
樱桃:[0, 0, 1]
(4)计算方法: 先转换为频率,然后数个数
- 示例:求iris数据集中,三种鸢尾花出现的概率
# 引入load_iris,获取鸢尾花数据集
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)# 查看所有y值(可以发现分别用0、1、2这三个编码代表了三种鸢尾花类型)
print(y)# 求概率(可以发现在这个数据集中,三种鸢尾花出现的概率都是1/3,非常均衡,属于一个理想的数据集)
P0 = (y == 0).mean()
P1 = (y == 1).mean()
P2 = (y == 2).mean()print(f"标签编码为0的鸢尾花出现的概率为:{P0}")
print(f"标签编码为1的鸢尾花出现的概率为:{P1}")
print(f"标签编码为2的鸢尾花出现的概率为:{P2}")1.3.2 连续型变量
(1)特点: 无限个数值,数值之间有大小、程度等差异,数值之间的内涵是一致的
(2)例如:
- 一个人的身高是一个连续变量,可以是 1.75 米、1.76 米、1.77 米等
- 一个人的体重也是一个连续变量,可以有无数个可能的值
- 气温是一个连续变量,可以是 23.5 度、23.6 度、23.7 度等
- 商品的价格是一个连续变量,可以有小数点后的值
- 一个人每天花费在上班通勤上的时间是一个连续变量,可以是 30.5 分钟、31 分钟、31.5 分钟等
(3)编码: 连续型变量通常不需要像离散型变量那样的编码,因为它们已经是数值型,可以直接用于大多数机器学习算法。然而,在某些情况下,对连续型变量进行特定的处理或转换可能是有益的,这些处理包括:
-
归一化(Normalization):将数据缩放到一个特定的范围,通常是 [0, 1],或者转换为具有零均值和单位方差的形式,这有助于加快学习算法的收敛速度,并提高模型的性能
-
标准化(Standardization):将数据转换为均值为 0,标准差为 1 的形式,这种方法对于假设数据分布为正态分布的算法(如线性回归、逻辑回归等)尤其重要
-
离散化(Discretization):将连续变量分割成若干个区间或桶,将其转换为离散型变量,这在某些分类任务中可能有用,尤其是当连续变量的每个区间对预测结果有明显区别时
-
特征工程:通过数学变换(如对数变换、平方根变换等)来改善模型的性能,或者创建新的特征,这些新特征可能更好地捕捉数据中的模式
-
异常值处理:识别并处理异常值,因为极端的数值可能会对模型的性能产生负面影响
-
降维:使用主成分分析(PCA)或其他方法来减少数据的维度,同时尽可能保留原始数据的信息
(4)计算方法: 通过对概率密度函数(PDF,Probability Density Function)的积分来求解
(概率密度函数是概率的导数,概率是概率密度函数的积分)
①计算步骤(理论数学):
-
先找到概率密度函数(在概率论和统计学中,有多种类型的概率密度函数,用于描述不同类型连续型随机变量的概率分布,高斯分布函数就是其中的一种)
-
再对概率密度函数求积分
高斯分布函数(也称为正态分布函数)是特定形式的一种概率密度函数,它描述了正态分布的变量的概率密度,其公式如下:(其中,μ是均值,可以用mean方法计算得出;σ是标准差,可以用std方法计算得出)

用matplotlib绘制高斯函数的图像:
# 引入numpy,为高斯分布函数提供π、e的值
import numpy as np
# 引入matplotlib的pyplot函数,为绘图做准备
from matplotlib import pyplot as plt
# 如果是用pycharm等后端工具绘图,需要指定图形用户界面工具包
# import matplotlib
# matplotlib.use('TkAgg') # 设置绘图后端为 TkAgg# 从-5到5,等差数列,生成100个x均分点
x = np.linspace(start=-5, stop=5, num=100)
# 创建高斯分布函数,设定返回结果为高斯分布函数的方程式
def normal(x, mu=0, sigma=1):# np.pi即为圆周率π,np.exp即为数学常数ereturn 1 / (((2 * np.pi) ** 0.5) * sigma) * np.exp(-((x - mu) ** 2) / (2 * (sigma ** 2)))
# 用plot方法折线图,label是图线的标签
plt.plot(x, normal(x, mu=0, sigma=1), label="$\mu=0,\sigma =1$")
plt.plot(x, normal(x, mu=1, sigma=1), label="$\mu=1,\sigma =1$")
plt.plot(x, normal(x, mu=0, sigma=2), label="$\mu=0,\sigma =2$")
# 用grid方法显示图像网格
plt.grid()
# 用legend方法显示图线的标签
plt.legend()
# 用show方法显示图表
plt.show()绘制出来的图像如下图所示:(在任何一点的概率都是0,但中间的概率明显应该比两边的概率大,所以理论数学的计算是不可行的)
 ②计算步骤(工程数学):
②计算步骤(工程数学):
-
直接把连续型变量的分布看作是高斯分布
-
直接拿概率密度函数的值代替概率
-
示例:根据一天中每个小时的温度,来计算22摄氏度出现的概率
# 引入numpy,创建高斯分布函数,并返回函数的值
import numpy as np
def gauss(x, mu, sigma):return 1/(np.sqrt(2*np.pi)*sigma) * np.exp(-(x - mu)**2 / (2*sigma**2))# 采样一天中24小时的温度数据
temperature = np.array([10, 9, 8, 7, 6, 5, 6, 7, 9, 12, 15, 18, 20, 22, 23, 22, 21, 19, 17, 15, 13, 11, 10, 9])
# 求均值
mu = temperature.mean()
# 求标准差
sigma = temperature.std()
# 求温度为22的概率
P_22 = gauss(x=22, mu=mu, sigma=sigma)
print(f'温度为22的概率为:{P_22}')2、条件概率与贝叶斯算法基本介绍

2.1 定义
条件概率以贝叶斯定理为理论基础,指的是某事件已发生的前提下,另一事件发生的概率
例如: 假设我在做一道单选题,有A、B、C、D四个选项,但我不知道这道题的答案,只能猜一个选项
一般情况下,我能猜对答案的概率是1/4
此时,如果我已经排除了A、D两个选项,那么会存在以下情况:
-
A、D两项确实是错误答案,应该被排除,则在我已经排除A、D两项的前提下,我从B、C里面再去猜答案,猜对的概率是1/2
-
A、D两项其实有正确答案,不该被排除,则在我已经排除A、D两项的前提下,我从B、C里面再去猜答案,猜对的概率是0
2.2 公式推导
根据贝叶斯定理,B事件发生的前提下,A事件发生的概率为:

同理可得,A事件发生的前提下,B事件发生的概率为:

根据等式的乘法性质,可得:
![]()
![]()
因此:
![]()
进一步可推导出:

其中:
- P(A∣B) 是后验概率(Posterior Probability),指的是在事件 B 发生的前提下,事件 A 发生的概率。
- P(B∣A) 是似然概率(Likelihood),指的是在事件 A 发生的前提下,事件 B 发生的概率。
- P(A) 是先验概率(Prior Probability),指的是在没有考虑任何额外证据或信息之前,某个事件发生的概率
- P(B) 是边缘概率(Marginal Probability),指的是在考虑所有可能情况下,某个事件发生的总概率
在上述公式中,将A、B分别替换为机器学习模型中的标签y、特征X,可得:在特征X出现的前提下,标签y出现的概率为

由于条件概率模型通常是处理分类问题的,在分类问题中,同一组特征X,一般只会对应同一个标签y(如:y0、y1、y2...),所以上面公式可进一步推导出:



...

在处理分类问题时,条件概率模型不是非要算出一个具体的概率值,而是通过概率密度函数来比较大小,将概率最大的,视为特征样本的标签
既然是比大小,那么上面的公式应当还能化简,即:由于上面的式子都有除以P(X),所以与其比较除以P(X)之后的大小,不如直接比较不除以P(X)时的大小
例如:因为9>6>3,所以当9、6、3分别除以2之后,这个大小关系依然一致(9/2 > 6/2 > 3/2)
因此,上面的公式可进一步化简得:
![]()
![]()
![]()
...
![]()
由于X代表的是一组特征,包含X1,X2,X3,X4,...,Xn,所以可进一步推导得出:
![]()
![]()
![]()
...
![]()
因为X1、X2、X3、X4、...、Xn是独立特征,所以可以最终推导得出:
![]()
![]()
![]()
...
![]()
2.3 贝叶斯算法
贝叶斯算法是基于贝叶斯定理的一类算法,它提供了一种计算条件概率的方法,即:在已知其他事件发生的情况下,某事件发生的概率
朴素贝叶斯(Naive Bayes)和高斯贝叶斯(Gaussian Naive Bayes)都属于贝叶斯算法,但它们在处理数据和假设数据分布方面有所不同:
(1)朴素贝叶斯(Naive Bayes)
- 是一种基于贝叶斯定理的简单概率分类器,它假设所有特征之间相互独立
- 适用于文本分类、垃圾邮件检测等任务
- 可以用于多种类型的数据分布,如多项式分布、伯努利分布等
(2)高斯贝叶斯(Gaussian Naive Bayes)
- 是朴素贝叶斯的一个特例,它假设数据特征遵循高斯(正态)分布
- 通常用于连续数据的特征,因为高斯分布是连续的
- 在特征值近似正态分布时效果最好
3、高斯贝叶斯算法实践
以鸢尾花的分类任务为例,下面介绍通过高斯贝叶斯算法来进行预测
# 引入load_iris,获取鸢尾花数据集
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)# 引入train_test_split,将数据集切分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 在python中,sklearn.naive_bayes是 sklearn 库中的一个模块,它实现了多种朴素贝叶斯分类器
# 在sklearn.naive_bayes中,GaussianNB就是用于实现高斯贝叶斯算法的分类器,所以我们需要先对其进行引入
from sklearn.naive_bayes import GaussianNB# GaussianNB是一个类,所以应该用面向对象的思想对其进行使用(即:实例化对象)
gnb = GaussianNB()# 训练模型时,需要将训练集(X_train和y_train)作为参数传入fit方法中
gnb.fit(X=X_train, y=y_train)
# 预测模型时,需要将测试集(X_test)作为参数传入predict方法中
y_pred = gnb.predict(X=X_test)#将y_test与y_pred进行对比,看有多少个数是相等的,就可以得到预测的准确率
acc = (y_pred == y_test).mean()
print(f"预测的准确率为:{acc}")4、自定义高斯贝叶斯分类器
在本文第三章节的高斯贝叶斯算法实践中,用的都是sklearn库中的标准模块和函数,为了理解其中的实现原理(贝叶斯公式和高斯函数都有运用),本章节将模仿sklearn,自定义一个高斯贝叶斯分类器
# 引入numpy,为高斯分布函数提供π、e的值,以及提供一些其他的科学计算方法
import numpy as np# 定义一个MyGaussianNB类,实现高斯贝叶斯算法的fit和predict方法
class MyGaussianNB(object):"""自定义高斯贝叶斯分类算法"""def __init__(self):"""初始化方法"""passdef _gauss(self, x, mu, sigma):"""定义一个内部方法,返回高斯分布函数值"""return 1 / (((2 * np.pi) ** 0.5) * sigma) * np.exp(-((x - mu) ** 2) / (2 * (sigma ** 2)))def fit(self, X_train, y_train):"""训练过程(高斯贝叶斯算法不是懒惰学习的方式,有训练过程)训练逻辑:Step1:将训练集中所有的y标签去重,得到总共有多少个y标签(比如鸢尾花标准数据集中有3个y标签)Step2:将训练集中的X样本按照这3个标签做切分,划分出每一类标签对应的所有X样本Step3:对于每一类标签的所有X样本,求出每一列特征的均值和标准差标签值为0对应的所有X样本,第1列特征的均值和标准差、第2列特征的均值和标准差、第3列特征的均值和标准差、第4列特征的均值和标准差标签值为1对应的所有X样本,第1列特征的均值和标准差、第2列特征的均值和标准差、第3列特征的均值和标准差、第4列特征的均值和标准差标签值为2对应的所有X样本,第1列特征的均值和标准差、第2列特征的均值和标准差、第3列特征的均值和标准差、第4列特征的均值和标准差最终得到的结果示例:# [[{'mean': 5.02051282051282, 'std': 0.3596148132908301}, {'mean': 3.4025641025641025, 'std': 0.37654786836856813}, {'mean': 1.4615384615384615, 'std': 0.14253273958653637}, {'mean': 0.24102564102564095, 'std': 0.10553392629362397}], # [{'mean': 5.886486486486486, 'std': 0.513684182165048}, {'mean': 2.7621621621621624, 'std': 0.32244953625825373}, {'mean': 4.216216216216216, 'std': 0.4795907678447316}, {'mean': 1.324324324324324, 'std': 0.2018902637511686}], # [{'mean': 6.638636363636365, 'std': 0.6238501820042829}, {'mean': 2.9886363636363638, 'std': 0.328367801745452}, {'mean': 5.5659090909090905, 'std': 0.5426966262094999}, {'mean': 2.0318181818181817, 'std': 0.2538545819171491}]] """self.X_train = X_trainself.y_train = y_train#找出训练集 y_train 中有多少个不重复的类别标签,并将其存储在 self.classes 中self.classes = np.unique(y_train) # 定义一个空列表,存放每个标签对应的四列X特征数据中,每一列X特征数据的均值和标准差self.parameters = []# 对 self.classes 中的类别进行遍历,并将索引和对应的元素值分别赋给变量 i 和 y_nowfor i, y_now in enumerate(self.classes):# X_train[y_train == y_now],是将训练集中的 y 标签分别于当前循环中的标签做对比,找到有哪些组X是对应此标签的X_classes = X_train[y_train == y_now]# 往self.parameters中添加一个空列表,用于存放当前标签对应的所有训练集X样本中每一列特征的均值和标准差数据self.parameters.append([])# X_classes.T是将X_classes进行转置,方便求其每一列的均值和标准差# 假设X_classes=[[5.2 3.5 1.5 0.2]# [5.7 3.8 1.7 0.3]# [4.7 3.2 1.3 0.2]# [5. 3.5 1.6 0.6]# [5.4 3.7 1.5 0.2]# [4.8 3.1 1.6 0.2]# [5.3 3.7 1.5 0.2]# [4.3 3. 1.1 0.1]# [5.4 3.4 1.7 0.2]# [5.7 4.4 1.5 0.4]# [4.6 3.1 1.5 0.2]# [4.6 3.4 1.4 0.3]# [4.8 3. 1.4 0.1]# [5.1 3.8 1.6 0.2]# [4.8 3.4 1.6 0.2]# [4.5 2.3 1.3 0.3]# [4.9 3. 1.4 0.2]# [4.4 3.2 1.3 0.2]]# 则X_classes.T=[[5.2 5.7 4.7 5. 5.4 4.8 5.3 4.3 5.4 5.7 4.6 4.6 4.8 5.1 4.8 4.5 4.9 4.4]# [3.5 3.8 3.2 3.5 3.7 3.1 3.7 3. 3.4 4.4 3.1 3.4 3. 3.8 3.4 2.3 3. 3.2]# [1.5 1.7 1.3 1.6 1.5 1.6 1.5 1.1 1.7 1.5 1.5 1.4 1.4 1.6 1.6 1.3 1.4 1.3]# [0.2 0.3 0.2 0.6 0.2 0.2 0.2 0.1 0.2 0.4 0.2 0.3 0.1 0.2 0.2 0.3 0.2 0.2]]# 转置之后,遍历获取的就是每一个特征列的数据,需要分别求其均值和标准差,并添加到self.parameters中for col in X_classes.T:parameters = {"mean": col.mean(), "std": col.std()}self.parameters[i].append(parameters)def predict(self, X_test):"""推理过程(此处是重点)"""# 大致流程:# Step1:将测试数据集中的每一个特征值都与分别于训练数据集中每一列特征值的均值和标准差一一对应,求得当前测试数据对于每一类标签的概率密度函数值# Step2:取概率密度函数最大的值对应的标签值,作为当前测试数据预测出来的标签# 具体实现:# 1、定义一个列表,用于接收每个测试集预测出来的标签值results = []# 2、循环遍历测试集中的每一个样本,分别求其对应的标签值,并存放值results中for x_test in X_test:# 定义一个空列表,用于存放每个P(y_train_i|x_test_j)的概率结果posteriors = []# 对 self.classes 中的类别进行遍历,并将索引和对应的元素值分别赋给变量 i 和 y_nowfor i, y_now in enumerate(self.classes):# 计算先验概率P(y_train_i)prior = (self.y_train == y_now).mean()# 重置似然概率likelihood = 1# self.parameters=[[{'mean': 5.02051282051282, 'std': 0.3596148132908301}, {'mean': 3.4025641025641025, 'std': 0.37654786836856813}, {'mean': 1.4615384615384615, 'std': 0.14253273958653637}, {'mean': 0.24102564102564095, 'std': 0.10553392629362397}], # [{'mean': 5.886486486486486, 'std': 0.513684182165048}, {'mean': 2.7621621621621624, 'std': 0.32244953625825373}, {'mean': 4.216216216216216, 'std': 0.4795907678447316}, {'mean': 1.324324324324324, 'std': 0.2018902637511686}], # [{'mean': 6.638636363636365, 'std': 0.6238501820042829}, {'mean': 2.9886363636363638, 'std': 0.328367801745452}, {'mean': 5.5659090909090905, 'std': 0.5426966262094999}, {'mean': 2.0318181818181817, 'std': 0.2538545819171491}]]# 以i=0为例:# i=0 ==> self.parameters[i]=[{'mean': 5.02051282051282, 'std': 0.3596148132908301}, {'mean': 3.4025641025641025, 'std': 0.37654786836856813}, {'mean': 1.4615384615384615, 'std': 0.14253273958653637}, {'mean': 0.24102564102564095, 'std': 0.10553392629362397}]# ==> j=0,param={'mean': 5.02051282051282, 'std': 0.3596148132908301},x_test[j]="测试集中第1列特征x的数据"# j=1,param={'mean': 3.4025641025641025, 'std': 0.37654786836856813},x_test[j]="测试集中第2列特征x的数据"# j=2,param={'mean': 1.4615384615384615, 'std': 0.14253273958653637},x_test[j]="测试集中第3列特征x的数据"# j=3,param={'mean': 0.24102564102564095, 'std': 0.10553392629362397},x_test[j]="测试集中第4列特征x的数据"for j, param in enumerate(self.parameters[i]):# 计算似然概率:P(x_test_1|y_train_i) · P(x_test_2|y_train_i) · P(x_test_3|y_train_i) · P(x_test_4|y_train_i)likelihood *= self._gauss(x_test[j], param["mean"], param["std"])# 计算后验概率,P(x_test_1|y_train_i) · P(x_test_2|y_train_i) · P(x_test_3|y_train_i) · P(x_test_4|y_train_i) · P(y_train_i)posterior = likelihood * prior# 将计算得到的概率都添加到posteriors列表中posteriors.append(posterior)# np.argmax是 NumPy 库中的一个函数,用于返回数组中最大值的索引# 由于每个概率的索引正好对应一个y标签,所以,可通过最大概率值的索引,从self.classes中获取到索引对应的标签值,作为预测值(y_pred),并添加到results结果集中results.append(self.classes[np.argmax(posteriors)])# 返回每个样本对应的标签值,方便后续与实际值之间做分析return results使用自定义的高斯贝叶斯分类器处理【鸢尾花(iris)识别】任务:
# 引入load_iris,获取鸢尾花数据集
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)# 引入train_test_split,将数据集切分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 调用自定义的高斯贝叶斯分类器,分别传入训练集和测试集
mygnb = MyGaussianNB()
mygnb.fit(X_train=X_train, y_train=y_train)
y_pred = mygnb.predict(X_test=X_test)# 比较测试集的标签值和预测出来的标签值,计算预测的准确率
acc = (y_pred == y_test).mean()
print(f"预测的准确率为:{acc}")相关文章:

机器学习算法与实践_03概率论与贝叶斯算法笔记
1、概率论基础知识介绍 人工智能项目本质上是一个统计学项目,是通过对 样本 的分析,来评估/估计 总体 的情况,与数学知识相关联 高等数学 ——> 模型优化 概率论与数理统计 ——> 建模思想 线性代数 ——> 高性能计算 在机器学…...

如何使用Privoxy将SOCKS5代理转换为HTTP代理?
在这篇博客中,我将介绍如何使用Privoxy将SOCKS5代理转换为HTTP代理。我们将从下载和安装Privoxy开始,接着配置Privoxy,最后配置Windows以便浏览器使用该代理。 1. 下载并安装Privoxy 首先,您需要下载并安装Privoxy。您可以从Pri…...

AJAX(一)HTTP协议(请求响应报文),AJAX发送请求,请求问题处理
文章目录 一、AJAX二、HTTP协议1. 请求报文2. 响应报文 三、AJAX案例准备1. 安装node2. Express搭建服务器3. 安装nodemon实现自动重启 四、AJAX发送请求1. GET请求2. POST请求(1) 配置请求体(2) 配置请求头 3. 响应JSON数据的两种方式(1) 手动,JSON.parse()(2) 设置…...
:Git LFS 使用详解)
Git进阶(十五):Git LFS 使用详解
文章目录 一、介绍二、Git LFS 使用步骤三、场景示例四、拓展阅读 一、介绍 Git LFS (Large File Storage) 是一个 Git 扩展,它使 Git 更适合处理大型文件,如音频、视频、图像或任何其他二进制大文件。Git LFS 替换仓库中的大文件为文本指针文件&#x…...
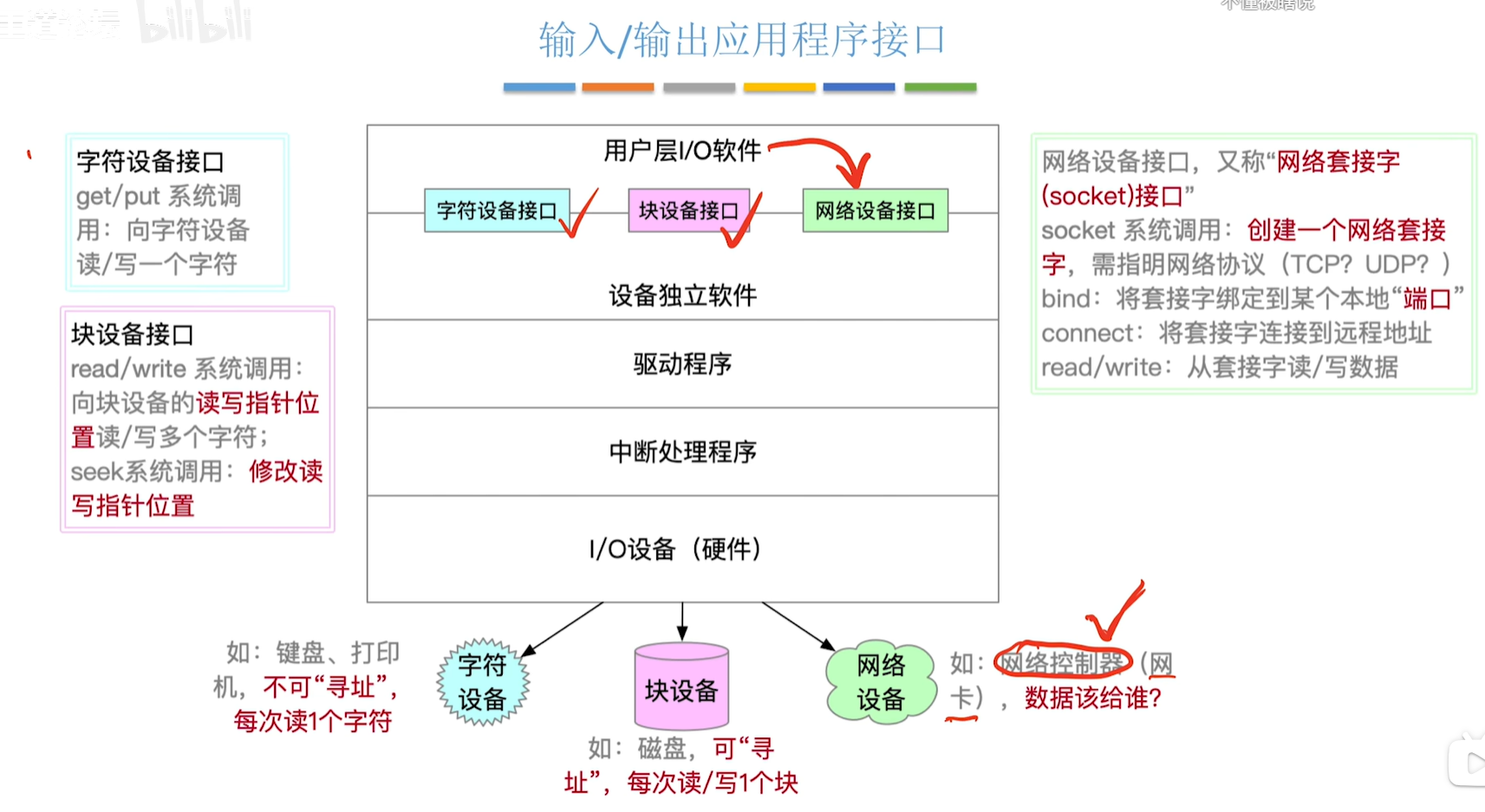
操作系统 | 学习笔记 | | 王道 | 5.1 I/O管理概述
5.1 I/O管理概述 5.1.1 I/O设备 注:块设备可以寻址,但是字符设备是不可寻址的 I/O设备是将数据输入到计算机中,或者可以接收计算机输出数据的外部设备,属于计算机中的硬件部件; 设备的分类 按使用特性分类ÿ…...

关于es的一个多集群、多索引切换的实现
首先是封装了一个类里定义了关于集群名称和集群节点;以及关于索引的名称和集群的名称做一个关联;将多个集群封装存储得到类中 /*** es集群类*/ Data public class EsClusterConfig implements Serializable {/*** 集群名称*/private String name;/*** 集…...

Linux系统编程(基础指令)上
1.Linux常见目录介绍 Linux目录为树形结构 /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录。所有的东西都是从这里开始。当你在终端里输入“/home”,你其实是在告诉电脑,先从/(根目录&…...

【STM32 Blue Pill编程】-定时器PWM模式
定时器PWM模式 文章目录 定时器PWM模式1、定时器PWM模式介绍2、硬件准备及接线3、模块配置4、代码实现在文中,我们将介绍如何使用 STM32 Blue Pill 定时器的PWM模式以及如何配置它们以生成具有不同占空比和频率的信号。 我们将使用 LED调光器示例来演示如何使用 STM32Cube IDE…...
数字英文验证码识别 API 对接说明
数字英文验证码识别 API 对接说明 本文将介绍一种 数字英文验证码识别 API 对接说明,它是基于深度学习技术,可用于识别变长英文数字验证码。输入验证码图像的内容,输出验证码结果。 接下来介绍下 数字英文验证码识别 API 的对接说明。 注册…...

稳了,搭建Docker国内源图文教程
大家好,之前分享了我的开源作品 Cloudflare Workers Proxy,它的作用是代理被屏蔽的地址,理论上支持代理任何被屏蔽的域名,使用方式也很简单,只需要设置环境变量 PROXY_HOSTNAME 为被屏蔽的域名,最后通过你的…...

零工市场小程序:推动零工市场建设
人力资源和社会保障部在2024年4月发布了标题为《地方推进零工市场建设经验做法》的文章。 零工市场小程序的功能 信息登记与发布 精准匹配、推送 在线沟通 权益保障 零工市场小程序作为一个找零工的渠道,在往后随着技术的发展和政策的支持下,功能必然…...

回归预测 | Matlab实现SSA-HKELM麻雀算法优化混合核极限学习机多变量回归预测
回归预测 | Matlab实现SSA-HKELM麻雀算法优化混合核极限学习机多变量回归预测 目录 回归预测 | Matlab实现SSA-HKELM麻雀算法优化混合核极限学习机多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现SSA-HKELM麻雀算法优化混合核极限学习机多变量…...

VCNet论文阅读笔记
VCNet论文阅读笔记 0、基本信息 信息细节英文题目VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments翻译VCNet和功能目标正则化用于学习连续处理的因果效应单位芝加哥大学年份2021论文链接[2103.07861] VCNet和功能定向正…...

Python 装饰器使用详解
文章目录 0. 引言1. 什么是装饰器?2. 装饰器的基本语法3. 装饰器的工作原理4. 常见装饰器应用场景4.1. 日志记录4.2. 权限校验4.3. 缓存 5. 多重装饰器的执行顺序6. 装饰器的高级用法6.1. 带参数的装饰器6.2. 使用 functools.wraps6.3. 类装饰器 7. 图示说明7.1. 单…...

Vue使用qrcodejs2-fix生成网页二维码
安装qrcodejs2-fix npm install qrcodejs2-fix核心代码 在指定父view中生成一个二维码通过id找到父布局 //通过id找到父布局let codeView document.getElementById("qrcode")new QRCode(codeView, {text: "测试",width: 128,height: 128,colorDark: #00…...

兼容多个AI应用接口,支持用户自定义切换AI接口
项目背景 2023年ChatGPT横空出世,给IT行业造成了巨大的反响。我第一次发现这个ChatGPT有着如此神奇的功能(智能对话,知识问答,代码生成,逻辑推理等),我感到非常吃惊!经过一番学习和…...

[docker]入门
本文章主要讲述的是,docker基本实现原理,docker概念的解释,docker的使用场景以及docker打包与部署的应用。 文章中docker所运行的系统:CentOS Linux release 7.9.2009 (Core) 目录 docker是什么,什么时候需要去使用 …...

《让手机秒变超级电脑!ToDesk云电脑、易腾云、青椒云移动端评测》
前言 科技发展到如今2024年,可以说每一年都在发生翻天覆地的变化。而云上这个词时常都被大家提起,从个人设备连接到云端在如今在也不是梦了。而云电脑这个市场近年来迅速发展,无需购买和维护额外的硬件就可以体验到电脑端顶配的性能和体验&am…...

Nginx处理带有分号“;“的路径
一、背景 安全渗透测试发现springboot 未授权访问的actuator和Swagger-ui 信息泄露的漏洞,需要规避。解决方案中较简单的就是通过Nginx将相关的接口转发到403页面。 在配置的过程当中,遇到了带有…;的路径:http://{ip:port}/{path}/…;/actu…...

Spring Boot框架下的心理教育辅导系统开发
1绪 论 1.1研究背景 随着计算机和网络技术的不断发展,计算机网络已经逐渐深入人们的生活,网络已经能够覆盖我们生活的每一个角落,给用户的网上交流和学习提供了巨大的方便。 当今社会处在一个高速发展的信息时代,计算机网络的发展…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...