让模型评估模型:构建双代理RAG评估系统的步骤解析
在当前大语言模型(LLM)应用开发的背景下,一个关键问题是如何评估模型输出的准确性。我们需要确定哪些评估指标能够有效衡量提示(prompt)的效果,以及在多大程度上需要对提示进行优化。
为解决这一问题,我们将介绍一个基于双代理的RAG(检索增强生成)评估系统。该系统使用生成代理和反馈代理,基于预定义的测试集对输出进行评估。或者更简单的说,我们使用一个模型来评估另外一个模型的输出。
在本文中将详细介绍如何构建这样一个RAG评估系统,并展示基于四种提示工程技术的不同结果,包括ReAct、思维链(Chain of Thought)、自一致性(Self-Consistency)和角色提示(Role Prompting)。
以下是该项目的整体架构图:

数据收集与摄入
此部分在 ingestion.py 中实现
数据收集过程使用了三篇文章作为源数据。在加载和分割数据后,我们对文本进行嵌入,并将嵌入向量存储在FAISS中。FAISS(Facebook AI Similarity Search)是由Meta开发的开源库,用于高效进行密集向量的相似性搜索和聚类。
以下是实现代码:
urls= [ "https://medium.com/@fareedkhandev/prompt-engineering-complete-guide-2968776f0431", "https://medium.com/@researchgraph/prompt-engineering-21112dbfc789", "https://blog.fabrichq.ai/what-is-prompt-engineering-a-detailed-guide-with-examples-4d3cbbd53792" ] loader=WebBaseLoader(urls) # 文本分割器 text_splitter=RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=20 ) documents=loader.load_and_split(text_splitter) # LLM embedder_llm=OpenAIModel().embed_model() # 对文档块进行嵌入 vectorstore=FAISS.from_documents(documents, embedder_llm) vectorstore.save_local("faiss_embed") print("===== 数据摄入完成 ===== ")
创建测试集
此部分在 create_test_set.py 中实现
测试集的构建使用了Giskard工具。Giskard是一个开源工具,专为测试和改进机器学习模型而设计。它使用户能够创建、运行和自动化测试,以评估模型的性能、公平性和稳健性。
实现代码如下:
fromlangchain_community.document_loadersimportWebBaseLoader fromlangchain.text_splitterimportRecursiveCharacterTextSplitter # 用于构建测试集 fromgiskard.ragimportKnowledgeBase, generate_testset # 数据框 importpandasaspd fromLLM.modelsimportOpenAIModel if__name__=='__main__': urls= [ "https://medium.com/@fareedkhandev/prompt-engineering-complete-guide-2968776f0431", "https://medium.com/@researchgraph/prompt-engineering-21112dbfc789", "https://blog.fabrichq.ai/what-is-prompt-engineering-a-detailed-guide-with-examples-4d3cbbd53792" ] loader=WebBaseLoader(urls) # 文本分割器 text_splitter=RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=20 ) documents=loader.load_and_split(text_splitter) df=pd.DataFrame([doc.page_contentfordocindocuments], columns=["text"]) print(df.head(10)) ## 将数据框添加到giskard KnowledgeBase knowledge_base=KnowledgeBase(df) # 生成测试集 test_set=generate_testset( knowledge_base, num_questions=10, agent_description="A chatbot answering question about prompt engineering" ) test_set.save("test-set.jsonl")
由于文本太多,生成的样例就不显示了
答案检索
此部分在 generation.py 中实现
本文的第一个流程是生成流程。我们从FAISS检索数据。实现代码如下:
generate_llm=OpenAIModel().generate_model() embedder_llm=OpenAIModel().embed_model() vectorstore=FAISS.load_local("faiss_embed", embedder_llm, allow_dangerous_deserialization=True) retrieval_qa_chat_prompt= (retrieval) prompt=ChatPromptTemplate.from_messages( [ ("system", retrieval_qa_chat_prompt), ("human", "{input}"), ] )combine_docs_chain=create_stuff_documents_chain(generate_llm, prompt) retrival_chain=create_retrieval_chain( retriever=vectorstore.as_retriever(), combine_docs_chain=combine_docs_chain )
评估
此部分在 evaluation.py 中实现
评估过程中向LLM提供三个输入:问题、AI答案(第一个LLM的输出)和实际答案(从测试集中检索)。实现代码如下:
defRAG_eval(question, AI_answer, Actual_answer, prompt): evaluation_prompt_template=PromptTemplate( input_variables=[ "question", "AI_answer", "Actual_answer" ], template=prompt ) generate_llm=OpenAIModel().generate_model() optimization_chain=evaluation_prompt_template|generate_llm|StrOutputParser() result_optimization=optimization_chain.invoke( {"question": question, "AI_answer": AI_answer, "Actual_answer": Actual_answer}) returnresult_optimization
链接整合
此部分在 main.py 中实现
主文件遍历测试数据,使用问题作为第一个LLM的输入。然后将第一个LLM的输出用作第二个LLM的输入。实现代码如下:
foritemindata: question= {"input": item['question']} # 生成回答 result=retrival_chain.invoke(input=question) AI_answer=result['answer'] # 获取实际答案 Actual_answer=item['reference_answer'] # 将所有内容提供给第二个LLM Evaluation=RAG_eval( question=question, AI_answer=AI_answer, Actual_answer=Actual_answer, prompt=evaluation_self_consistency_prompting ) print(f"AI_answer:{AI_answer}") print(Evaluation)
实验结果
评估组件采用了四种不同的提示工程技术:
- 思维链(Chain of Thought)
- ReAct
- 角色提示(Role Prompting)
- 自一致性(Self-Consistency)
以下是基于这四种不同提示技术的评估代理对测试集第一个问题的输出示例:
问题: What is the purpose of incorporating knowledge in prompt engineering?
实际答案: Incorporating knowledge or information in prompt engineering enhances the model’s prediction accuracy. By providing relevant knowledge or information related to the task at hand, the model can leverage this additional context to make more accurate predictions. This technique enables the model to tap into external resources or pre-existing knowledge to improve its understanding and generate more informed responses
**AI答案:**Incorporating knowledge in prompt engineering enhances the quality of responses by guiding AI models to provide not just answers, but also relevant context and insights. This leads to more informative and meaningful interactions, improving user experience and understanding.
使用思维链输出的**评估结果:**The student’s answer correctly identifies that incorporating knowledge enhances the quality of responses and improves user experience. However, it lacks emphasis on the model’s prediction accuracy and the importance of leveraging external resources or pre-existing knowledge, which are key components of the actual answer. This omission affects the completeness and correctness of the response.
使用ReAct输出的评估结果**:**The student’s answer correctly identifies that incorporating knowledge enhances the quality of responses and improves user experience. However, it lacks emphasis on the specific aspect of prediction accuracy and the importance of leveraging external resources or pre-existing knowledge, which are key components of the actual answer. This omission affects the completeness of the response, leading to a lower evaluation percentage.
使用角色提示输出的评估结果**:**The student’s response accurately captures the essence of incorporating knowledge in prompt engineering by emphasizing the enhancement of response quality and user experience. However, it lacks specific mention of prediction accuracy and the model’s ability to leverage external resources, which are key aspects of the actual response.
使用自一致性输出的评估结果**:**The student’s answer captures the essence of enhancing the quality of responses through knowledge incorporation, but it lacks specific mention of prediction accuracy and the model’s ability to leverage external resources. The initial evaluation was slightly optimistic, but upon reevaluation, it became clear that the answer did not fully align with the actual answer’s emphasis on prediction accuracy and context utilization
实验结果分析
下图展示了四种提示工程技术的准确性比较。每种技术由图中的一条独立线条表示,X轴上的10个数据点对应测试数据的索引值,Y轴表示准确性值。

在评估过程中,准确性达到85%及以上的响应视为真正准确(True),低于85%则视为不准确(False)。下面的条形图展示了基于每种提示工程技术的评估结果中True和False的计数。
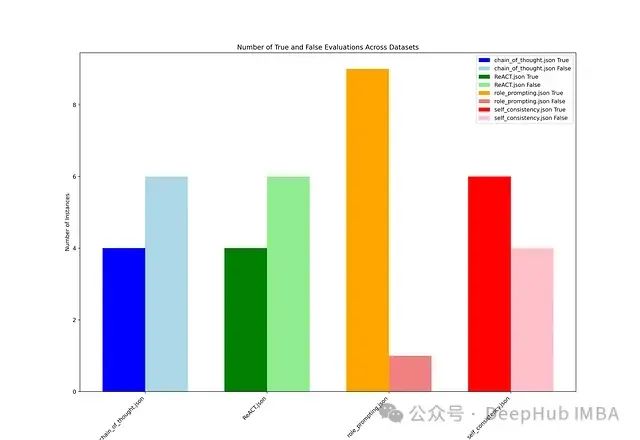
实验结果显示,ReAct和思维链(Chain of Thought)的性能几乎相似,而自一致性(Self-Consistency)则表现出完全相反的行为。角色提示(Role Prompting)在所有方法中表现最不稳定。
一些发现
- 评估代理的所有响应虽然在内容上相近,都提到了类似的缺失元素,但反馈之间的差异主要体现在具体措辞和强调点上,这些细微差别可能会对最终的评分过程产生影响。
- 角色提示和自一致性技术倾向于强调结果的积极方面,而ReAct和思维链则更多地使用特定措辞来突出回答中的缺失部分。
总结
本文展示了如何构建一个基于双代理的RAG(检索增强生成)评估系统,该系统使用两个大语言模型(LLM):一个用于生成响应,另一个用于提供反馈。通过采用四种不同的提示工程技术——思维链、ReAct、角色提示和自一致性,我们能够全面评估AI生成响应的准确性和质量。
实验结果表明:
- ReAct和思维链技术在性能上表现相似,这可能是因为它们都强调了结构化思考过程。
- 自一致性技术经常产生与其他方法相反的结果,这突显了在评估过程中考虑多个角度的重要性。
- 角色提示技术被证明是最不可靠的,这可能是由于其在不同上下文中的不一致性。
本文代码:
https://avoid.overfit.cn/post/f64e1de74d8a423a859086dfed4d5a47
作者:Homayoun S.
相关文章:
让模型评估模型:构建双代理RAG评估系统的步骤解析
在当前大语言模型(LLM)应用开发的背景下,一个关键问题是如何评估模型输出的准确性。我们需要确定哪些评估指标能够有效衡量提示(prompt)的效果,以及在多大程度上需要对提示进行优化。 为解决这一问题,我们将介绍一个基于双代理的RAG(检索增强生成)评估系统。该系统使用生成代理…...

RabbitMQ 高级特性——发送方确认
文章目录 前言发送方确认confirm 确认模式return 退回模式 常见面试题 前言 前面我们学习了 RabbitMQ 中交换机、队列和消息的持久化,这样能够保证存储在 RabbitMQ Broker 中的交换机和队列中的消息实现持久化,就算 RabbitMQ 服务发生了重启或者是宕机&…...

马踏棋盘c++
马踏棋盘c 题目回溯问题模型特征模型 代码 题目 马踏棋盘算法,即骑士周游问题。将马放在国际象棋的 88 棋盘的某个方格中,马按走棋规则(马走日字)进行移动。每个方格只进入一次,走遍棋盘上全部 64 个方格。 回溯问题模型 特征 解组织成树…...

OpenSSH从7.4升级到9.8的过程 亲测--图文详解
一、下载软件 下载openssh 下载地址: Downloads | Library 下载openssl Index of /pub/OpenBSD/OpenSSH/ zlib Home Site 安装的 openssl-3.3.1.tar.gz ,安装3.3.2有问题 安装有问题, 二、安装依赖 yum install -y perl-CPAN perl-ExtUtils-CB…...

系统分析与设计
一、结构化方法 生命周期:结构化分析、结构化设计、结构化编程 原则:程序 算法 数据结构 1、结构化分析:数据流图和数据字典 2、结构化设计: 1)模块结构:信息隐藏与抽象、模块化、低耦合高内聚 2&…...

vite 使用飞行器仪表示例
这里写自定义目录标题 环境vue代码效果图 环境 jquery npm install -S jqueryjQuery-Flight-Indicators 将img、css、js拷贝到vite工程目录中 打开 jquery.flightindicators.js,在文件开头加上import jQuery from "jquery"; vue代码 <template>&…...
【隐私计算】Cheetah安全多方计算协议-阿里安全双子座实验室
2PC-NN安全推理与实际应用之间仍存在较大性能差距,因此只适用于小数据集或简单模型。Cheetah仔细设计DNN,基于格的同态加密、VOLE类型的不经意传输和秘密共享,提出了一个2PC-NN推理系统Cheetah,比CCS20的CrypTFlow2开销小的多&…...
Python 实现Excel XLS和XLSX格式相互转换
在日常工作中,我们经常需要处理和转换不同格式的Excel文件,以适应不同的需求和软件兼容性。Excel文件的两种常见格式是XLS(Excel 97-2003)和XLSX(Excel 2007及以上版本)。本文将详细介绍如何使用Python在XL…...

黑马智数Day1
src文件夹 src 目录指的是源代码目录,存放项目应用的源代码,包含项目的逻辑和功能实现,实际上线之后在浏览器中跑的代码就是它们 apis - 业务接口 assets - 静态资源 (图片) components - 组件 公共组件 constants…...

网络协议全景:Linux环境下的TCP/IP、UDP
目录 1.UDP协议解析1.1.定义1.2.UDP报头1.3.特点1.4.缓冲区 2.TCP协议解析2.1.定义2.2.报头解析2.2.1.首部长度(4位)2.2.2.窗口大小2.2.3.确认应答机制2.2.4.6个标志位 2.3.超时重传机制2.4.三次握手四次挥手2.4.1.全/半连接队列2.4.2.listen2.4.3.TIME_…...

制造企业MES系统委外工单管理探析
一、委外工单管理的重要性 在制造企业的生产过程中,委外工单管理是一项重要且复杂的任务。委外加工是指企业将某些生产任务外包给外部供应商完成,以降低成本、提高效率或满足特定需求。然而,委外加工过程中往往存在诸多不确定性,…...

【C语言-数据结构】顺序表的基本操作
顺序表的基本操作 【建议:如果对结构体还不太理解的话可以先看 C语言-结构体 这篇文章】 插入操作 ListInsert(&L,i,e):插入操作,在表 L 中的第 i 个位置上插入指定元素 e 代码实现 #include <stdio.h> #include <stdbool.…...

使用Renesas R7FA8D1BH (Cortex®-M85)实现多功能UI
目录 概述 1 系统框架介绍 1.1 模块功能介绍 1.2 UI页面功能 2 软件框架结构实现 2.1 软件框架图 2.1.1 应用层API 2.1.2 硬件驱动层 2.1.3 MCU底层驱动 2.2 软件流程图 4 软件功能实现 4.1 状态机功能核心代码 4.2 页面功能函数 4.3 源代码文件 5 功能测试 5.1…...

【java】常见限流算法原理及应用
目录 前言 限流的作用 4种常见限流算法 固定窗口限流 基本原理 简单实现 优点和缺点 滑动窗口限流 基本原理 简单实现 优点和缺点 漏桶限流 基本原理 简单实现 优点和缺点 令牌桶限流 基本原理 简单实现 优点和缺点 算法比较与选择 前言 在现代分布式系统…...
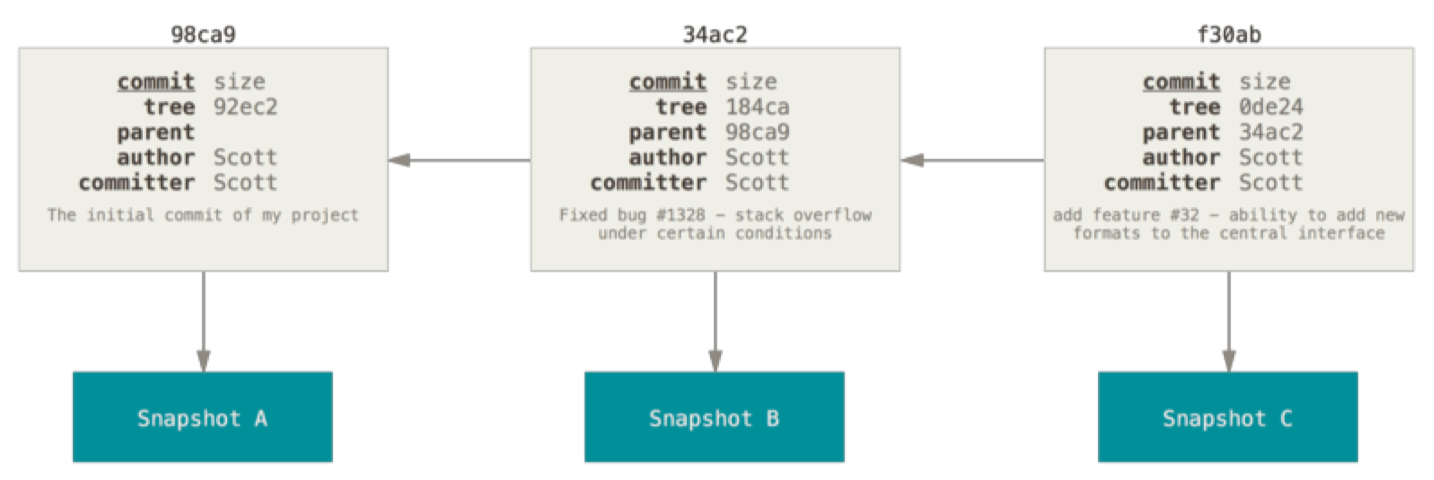
Git 原理(提交对象)(结合图与案例)
Git 原理(提交对象) 这一块主要讲述下 Git 的原理。 在进行提交操作时,Git 会保存一个提交对象(commit object): 该提交对象会包含一个指向暂存内容快照的指针; 该提交对象还包含了作者的姓…...

STM32如何修改外部晶振频率和主频
对于STM32F10x系列的单片机,除了STM32F10x_CL单片机,其它的单片机一般外部晶振HSE的时钟频率都默认是8MHz。如果我们使用的外部晶振为12Mhz,那么可以把上图绿色标记改为:12000000 72MHz的主频8MHz的外部晶振HSE*倍频系数9。当然如果像上面把外…...

【JAVA入门】Day48 - 线程池
【JAVA入门】Day48 - 线程池 文章目录 【JAVA入门】Day48 - 线程池一、线程池的主要核心原理二、自定义线程池三、线程池的大小 我们之前写的代码都是,用到线程的时候再创建,用完之后线程也就消失了,实际上这是不对的,它会浪费计算…...

图像亮度均衡算法
图像亮度均衡算法 图像亮度均衡算法的作用是提升图像的对比度和细节,使得图像的亮度分布更加均匀,从而改善视觉效果。通过调整亮度值,可以更好地揭示图像中的细节,尤其在低光或高光条件下的图像处理。 常见的图像亮度均衡算法包括…...

C++中的new与delete
目录 1.简介 2.底层 1.简介 new是升级版的malloc,它会先开空间再去调用构造函数。 delete是升级版的free,它会先调用析构函数再free掉空间。 class A { public:A(int a10, int b10){a a1;b b1;}private:int a;int b; };int main() {//new会先开空间…...

在HTML中添加视频
在HTML中添加视频,你可以使用<video>标签。这个标签允许你在网页上嵌入视频内容,并支持多种视频格式,如MP4、WebM和Ogg等。不过,由于浏览器对视频格式的支持程度不同,因此通常建议提供多种格式的视频文件&#x…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...