多层感知机paddle
多层感知机——paddle部分
本文部分为paddle框架以及部分理论分析,torch框架对应代码可见多层感知机
import paddle
print("paddle version:",paddle.__version__)
paddle version: 2.6.1
多层感知机(MLP,也称为神经网络)与线性模型相比,具有以下几个显著的优势:
-
非线性建模能力:线性模型,如线性回归或逻辑回归,仅能够学习输入和输出之间的线性关系。然而,在现实世界中,许多问题和数据的关系是非线性的。多层感知机通过引入激活函数(如Sigmoid、ReLU等),能够在神经元之间创建非线性关系,从而能够捕捉和模拟更复杂的非线性模式。
-
强大的表征学习能力:多层感知机通过多层网络结构,能够学习到输入数据的层次化特征表示。每一层都可以被视为对输入数据进行的一种非线性变换,通过逐层传递,网络可以逐渐抽取出更高级、更抽象的特征,这有助于模型处理复杂的任务。
-
自动特征提取:在传统的机器学习模型中,特征工程是一个重要的步骤,需要人工设计和选择特征。然而,多层感知机具有自动学习和提取有用特征的能力。通过训练,网络可以自动发现数据中的重要特征,并据此进行预测和分类,从而减少了特征工程的依赖。
-
强大的泛化能力:由于多层感知机能够学习到数据的复杂非线性关系,并且具有自动特征提取的能力,因此它通常具有很好的泛化性能。这意味着训练好的模型能够较好地处理未见过的数据,这是机器学习模型的重要性能之一。
-
适应性强:多层感知机可以处理各种类型的数据,包括图像、文本、音频等。通过调整网络结构和参数,可以灵活地适应不同的学习任务和数据集。
-
持续优化和改进:多层感知机可以通过不同的优化算法(如梯度下降法)进行训练和调整,以不断改进模型的性能。此外,随着深度学习技术的不断发展,多层感知机的结构和训练方法也在不断优化和改进,使其在各种任务中取得更好的性能。
多层感知机(MLP)原理
多层感知机(Multilayer Perceptron, MLP)是一种前馈神经网络,由输入层、一个或多个隐藏层和输出层组成。每一层由若干个神经元构成,每个神经元执行线性变换和非线性激活。
网络结构
设:
- 输入向量为 x = [ x 1 , x 2 , … , x n ] T \mathbf{x} = [x_1, x_2, \ldots, x_n]^T x=[x1,x2,…,xn]T
- 权重矩阵为 W ( l ) \mathbf{W}^{(l)} W(l) 和偏置向量为 b ( l ) \mathbf{b}^{(l)} b(l)
- 激活函数为 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)
第 l l l 层的输出 h ( l ) \mathbf{h}^{(l)} h(l) 可以表示为:
h ( l ) = ϕ ( W ( l ) h ( l − 1 ) + b ( l ) ) \mathbf{h}^{(l)} = \phi(\mathbf{W}^{(l)} \mathbf{h}^{(l-1)} + \mathbf{b}^{(l)}) h(l)=ϕ(W(l)h(l−1)+b(l))
其中, h ( 0 ) = x \mathbf{h}^{(0)} = \mathbf{x} h(0)=x 表示输入层的输出。
每一层的计算过程包括线性变换和非线性变换:
- 线性变换:
a ( l ) = W ( l ) h ( l − 1 ) + b ( l ) \mathbf{a}^{(l)} = \mathbf{W}^{(l)} \mathbf{h}^{(l-1)} + \mathbf{b}^{(l)} a(l)=W(l)h(l−1)+b(l) - 非线性变换(激活函数):
h ( l ) = ϕ ( a ( l ) ) \mathbf{h}^{(l)} = \phi(\mathbf{a}^{(l)}) h(l)=ϕ(a(l))
前向传播
前向传播是指从输入层到输出层的计算过程。通过前向传播可以得到网络的输出 y ^ \hat{\mathbf{y}} y^。
对于一个三层的网络(输入层、一个隐藏层、输出层),前向传播的计算过程如下:
-
输入层到隐藏层:
a ( 1 ) = W ( 1 ) x + b ( 1 ) \mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)} a(1)=W(1)x+b(1)
h ( 1 ) = ϕ ( a ( 1 ) ) \mathbf{h}^{(1)} = \phi(\mathbf{a}^{(1)}) h(1)=ϕ(a(1)) -
隐藏层到输出层:
a ( 2 ) = W ( 2 ) h ( 1 ) + b ( 2 ) \mathbf{a}^{(2)} = \mathbf{W}^{(2)} \mathbf{h}^{(1)} + \mathbf{b}^{(2)} a(2)=W(2)h(1)+b(2)
y ^ = ϕ ( a ( 2 ) ) \hat{\mathbf{y}} = \phi(\mathbf{a}^{(2)}) y^=ϕ(a(2))
损失函数
损失函数 L ( y , y ^ ) L(\mathbf{y}, \hat{\mathbf{y}}) L(y,y^) 用于衡量预测值 y ^ \hat{\mathbf{y}} y^ 和目标值 y \mathbf{y} y 之间的差异。常用的损失函数有均方误差和交叉熵损失。
对于均方误差:
L ( y , y ^ ) = 1 2 ∥ y − y ^ ∥ 2 L(\mathbf{y}, \hat{\mathbf{y}}) = \frac{1}{2} \|\mathbf{y} - \hat{\mathbf{y}}\|^2 L(y,y^)=21∥y−y^∥2
反向传播
反向传播(Backpropagation)是通过计算损失函数相对于各层参数的梯度,从而更新网络参数以最小化损失函数的过程。
反向传播的关键步骤如下:
-
计算输出层的误差:
δ ( L ) = ∂ L ∂ a ( L ) = ( y ^ − y ) ⊙ ϕ ′ ( a ( L ) ) \delta^{(L)} = \frac{\partial L}{\partial \mathbf{a}^{(L)}} = (\hat{\mathbf{y}} - \mathbf{y}) \odot \phi'(\mathbf{a}^{(L)}) δ(L)=∂a(L)∂L=(y^−y)⊙ϕ′(a(L)) -
计算隐藏层的误差:
δ ( l ) = ( W ( l + 1 ) ) T δ ( l + 1 ) ⊙ ϕ ′ ( a ( l ) ) \delta^{(l)} = (\mathbf{W}^{(l+1)})^T \delta^{(l+1)} \odot \phi'(\mathbf{a}^{(l)}) δ(l)=(W(l+1))Tδ(l+1)⊙ϕ′(a(l))
其中, ⊙ \odot ⊙ 表示元素逐个相乘, ϕ ′ ( a ( l ) ) \phi'(\mathbf{a}^{(l)}) ϕ′(a(l)) 是激活函数的导数。 -
计算梯度:
∂ L ∂ W ( l ) = δ ( l ) ( h ( l − 1 ) ) T \frac{\partial L}{\partial \mathbf{W}^{(l)}} = \delta^{(l)} (\mathbf{h}^{(l-1)})^T ∂W(l)∂L=δ(l)(h(l−1))T
∂ L ∂ b ( l ) = δ ( l ) \frac{\partial L}{\partial \mathbf{b}^{(l)}} = \delta^{(l)} ∂b(l)∂L=δ(l) -
更新权重:
使用梯度下降法,学习率为 η \eta η:
W ( l ) ← W ( l ) − η ∂ L ∂ W ( l ) \mathbf{W}^{(l)} \leftarrow \mathbf{W}^{(l)} - \eta \frac{\partial L}{\partial \mathbf{W}^{(l)}} W(l)←W(l)−η∂W(l)∂L
b ( l ) ← b ( l ) − η ∂ L ∂ b ( l ) \mathbf{b}^{(l)} \leftarrow \mathbf{b}^{(l)} - \eta \frac{\partial L}{\partial \mathbf{b}^{(l)}} b(l)←b(l)−η∂b(l)∂L
通过反复进行以上步骤,网络的参数会逐渐调整,以最小化损失函数,从而提高模型的预测准确性。
激活函数
激活函数在神经网络中起着至关重要的作用,它们决定了神经网络的非线性特性和表达能力。注意,激活函数不会改变输入输出的形状,它只对每一个元素进行运算。以下是激活函数的主要作用和用途:
1. 引入非线性
神经网络的核心计算包括线性变换(矩阵乘法和加法)和非线性变换(激活函数)。如果没有激活函数,整个网络就只是线性变换的叠加,无论有多少层,最终也只是输入的线性变换,无法处理复杂的非线性问题。
通过引入非线性激活函数,神经网络能够逼近任意复杂的函数,从而具有更强的表达能力。
2. 提供特征转换
激活函数可以将线性变换的输出映射到不同的特征空间,从而使得神经网络能够捕捉输入数据的复杂特征。每一层的激活函数都对输入进行某种形式的特征转换,使得后续层能够更好地学习和提取特征。
3. 保持梯度流
在反向传播过程中,激活函数的选择会影响梯度的传播。如果激活函数的导数为0,梯度将无法传播,导致网络无法训练。适当的激活函数可以避免梯度消失和梯度爆炸问题,使得梯度能够顺利传播。
常用的激活函数
- Sigmoid 函数
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1- 优点:输出范围在 (0, 1) 之间,便于处理概率问题。
- 缺点:容易导致梯度消失问题,特别是在深层网络中。
import numpy as np
import matplotlib.pyplot as plt # 测试sigmoid函数
x_input = paddle.arange(-8.0, 8.0, 0.1, dtype='float32') # 输入
x_input.stop_gradient = False # 允许梯度计算
y_output = paddle.nn.functional.sigmoid(x_input) # 输出 # 绘制图像
plt.plot(x_input.numpy(), y_output.numpy())
plt.show()

- Tanh 函数
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x- 优点:输出范围在 (-1, 1) 之间,相对于 Sigmoid 函数,梯度消失问题较少。
- 缺点:仍然可能出现梯度消失问题。
# 测试Tanh函数
x_input = paddle.arange(-8.0, 8.0, 0.1, dtype='float32') # 输入
x_input.stop_gradient = False # 允许梯度计算
y_output = paddle.nn.functional.tanh(x_input) # 输出 # 绘制图像
plt.plot(x_input.numpy(), y_output.numpy())
plt.show()

- ReLU 函数
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)- 优点:计算简单,高效,能够缓解梯度消失问题。
- 缺点:在训练过程中,部分神经元可能会“死亡”(即长时间输出为0),导致梯度无法更新。
# 测试ReLU函数
x_input = paddle.arange(-8.0, 8.0, 0.1, dtype='float32') # 输入
x_input.stop_gradient = False # 允许梯度计算
y_output = paddle.nn.functional.relu(x_input) # 输出 # 绘制图像
plt.plot(x_input.numpy(), y_output.numpy())
plt.show()

- Leaky ReLU 函数
Leaky ReLU ( x ) = { x if x ≥ 0 α x if x < 0 \text{Leaky ReLU}(x) = \begin{cases} x & \text{if } x \geq 0 \\ \alpha x & \text{if } x < 0 \end{cases} Leaky ReLU(x)={xαxif x≥0if x<0- 优点:解决 ReLU 函数的神经元“死亡”问题。
- 缺点:引入了一个需要调节的参数 α \alpha α。
# 测试Leaky ReLU函数
x_input = paddle.arange(-8.0, 8.0, 0.1, dtype='float32') # 输入
x_input.stop_gradient = False # 允许梯度计算
y_output = paddle.nn.functional.leaky_relu(x_input, negative_slope=0.01) # 输出 # 绘制图像
plt.plot(x_input.numpy(), y_output.numpy())
plt.show()

- Softmax 函数
Softmax ( x i ) = e x i ∑ j e x j \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} Softmax(xi)=∑jexjexi- 优点:常用于分类问题的输出层,将输入映射为概率分布。
- 缺点:计算开销较大,容易出现数值不稳定问题。
# 测试Softmax函数
x_input = paddle.randn((1, 10), dtype=paddle.float32) # 输入
x_input.stop_gradient = False # 允许梯度计算
y_output = paddle.nn.functional.softmax(x_input) # 输出
x_input, y_output
(Tensor(shape=[1, 10], dtype=float32, place=Place(gpu:0), stop_gradient=False,[[ 0.77194822, 0.51511782, -0.10991125, 1.85037136, 1.80251789,1.33102489, -1.37035322, 1.50795293, -1.83983290, -0.36562130]]),Tensor(shape=[1, 10], dtype=float32, place=Place(gpu:0), stop_gradient=False,[[0.08144495, 0.06299762, 0.03371922, 0.23945138, 0.22826263, 0.14245182,0.00956036, 0.17002270, 0.00597836, 0.02611103]]))
激活函数的选择
- 隐藏层:通常选择 ReLU 或其变种(如 Leaky ReLU、Parametric ReLU)作为隐藏层的激活函数,因为它们能有效缓解梯度消失问题。
- 输出层:根据具体任务选择合适的激活函数。
- 分类问题:使用 softmax 函数将输出映射为概率分布。
- 回归问题:使用线性函数或没有激活函数。
- 二分类问题:使用 sigmoid 函数。
手动实现多层感知机
接下来,我们将手动设计一个多层感知机模型,并实现前向传播和反向传播算法。我们利用面向对象编程的方法,结合深度学习库进行设计。
# 手动实现一个三层感知机模型,并实现前向传播和反向传播算法
import paddle.nn as nn
import paddle.nn.functional as F class Perceptron(nn.Layer): def __init__(self, input_size, output_size, hidden_size=10): super(Perceptron, self).__init__() # 初始化权重和偏置 self.W1 = self.create_parameter(shape=[input_size, hidden_size], default_initializer=nn.initializer.Normal()) self.b1 = self.create_parameter(shape=[hidden_size], default_initializer=nn.initializer.Normal()) self.W2 = self.create_parameter(shape=[hidden_size, output_size], default_initializer=nn.initializer.Normal()) self.b2 = self.create_parameter(shape=[output_size], default_initializer=nn.initializer.Normal()) def forward(self, x): # 前向传播 x = paddle.matmul(x, self.W1) + self.b1 x = F.relu(x) # 激活函数 x = paddle.matmul(x, self.W2) + self.b2 return x
接下来让我们测试一下该模型的输入输出
# 检查是否有可用的GPU设备,并选择设备
device = 'gpu' if paddle.is_compiled_with_cuda() else 'cpu'
paddle.set_device(device) # 创建随机的输入数据
x_input = paddle.randn([1, 10]) # 实例化模型
model = Perceptron(input_size=10, output_size=1) # 前向传播
y_output = model(x_input) # 打印输入、输出及其形状
print(x_input, y_output, x_input.shape, y_output.shape)
Tensor(shape=[1, 10], dtype=float32, place=Place(gpu:0), stop_gradient=True,[[-0.39587662, -1.33803356, -0.19662718, -0.33600944, -1.95559239,-0.94301635, -0.60298145, 0.75455868, -0.01416266, -3.05695415]]) Tensor(shape=[1, 1], dtype=float32, place=Place(gpu:0), stop_gradient=False,[[8.06220722]]) [1, 10] [1, 1]
接下来,我们导入一个California housing数据,用于训练测试多层感知机
from sklearn.model_selection import train_test_split
from sklearn import datasets
# 加载California housing数据集
California = datasets.fetch_california_housing()
X = paddle.Tensor(California.data, dtype=paddle.float32)
y = paddle.Tensor(California.target, dtype=paddle.float32)
from sklearn.model_selection import train_test_split
from paddle.io import Dataset, DataLoader class CustomDataset(Dataset): def __init__(self, features, labels): self.features = features self.labels = labels def __len__(self): return len(self.labels) def __getitem__(self, idx): return self.features[idx], self.labels[idx] def create_data_loaders(features, labels, batch_size=32, test_size=0.2, random_state=42): # 划分数据集 X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=test_size, random_state=random_state) # 创建Dataset对象 train_dataset = CustomDataset(X_train, y_train) test_dataset = CustomDataset(X_test, y_test) # 创建DataLoader对象 train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True) return train_loader, test_loader train_loader, test_loader = create_data_loaders(X, y, batch_size=64)
# 实例化模型
model = Perceptron(input_size=8, output_size=1) # 定义损失函数
criterion = paddle.nn.MSELoss() # 定义优化器
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.001) num_epochs = 100 # 定义训练轮数 for epoch in range(num_epochs): for batch_id, (inputs, labels) in enumerate(train_loader()): # 前向传播 inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) labels = paddle.reshape(labels, shape=[-1, 1]) # 调整标签形状以匹配输出 loss = criterion(outputs, labels) # 计算损失 # 反向传播和优化 loss.backward() # 反向传播 optimizer.step() # 更新权重 optimizer.clear_grad() # 梯度清零,PaddlePaddle中在optimizer.step()之后需要清零梯度 if (epoch + 1) % 10 == 0: # 每10轮输出一次损失 print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.numpy():.4f}') # 进行测试
model.eval() # 设置模型为评估模式
for batch_id, (inputs, labels) in enumerate(test_loader()): inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) labels = paddle.reshape(labels, shape=[-1, 1]) # 调整标签形状以匹配输出 loss = criterion(outputs, labels) # 计算损失 # 输出损失 print(f'Test Loss: {loss.numpy():.4f}') break # 假设我们只展示第一批测试数据的损失
Epoch [100/100], Loss: 0.6896
Test Loss: 0.5361
从上述过程中可以看到损失在不断减小,这证明模型在不断优化。然而观察X数据不难发现,X各维度之间的数值范围差异较大,这可能会导致模型在训练过程中收敛速度过慢。因此,我们可以对数据进行预处理,将数据缩放到一个较小的范围内。
import numpy as np class Preprocessor: def __init__(self): self.min_values = None self.scale_factors = None def normalize(self, data): """ 对输入数据进行归一化处理。 data: numpy数组或类似结构,其中每一列是一个特征。 """ # 确保输入是numpy数组 data = np.asarray(data) # 检查是否已经拟合过数据,如果没有,则先拟合 if self.min_values is None or self.scale_factors is None: self.fit(data) # 对数据进行归一化处理 normalized_data = (data - self.min_values) * self.scale_factors return normalized_data def denormalize(self, normalized_data): """ 对归一化后的数据进行反归一化处理。 normalized_data: 已经归一化处理的数据。 """ # 确保输入是numpy数组 normalized_data = np.asarray(normalized_data) # 反归一化数据 original_data = normalized_data / self.scale_factors + self.min_values return original_data def fit(self, data): """ 计算每个特征的最小值和比例因子,用于后续的归一化和反归一化。 data: numpy数组或类似结构,其中每一列是一个特征。 """ # 确保输入是numpy数组 data = np.asarray(data) # 计算每个特征(列)的最小值 self.min_values = np.min(data, axis=0) # 计算每个特征(列)的比例因子 ranges = np.max(data, axis=0) - self.min_values # 避免除以零错误,如果范围是零,则设置为1 self.scale_factors = np.where(ranges == 0, 1, 1.0 / ranges)
data_all = np.concatenate((X.numpy(), y.reshape((-1, 1)).numpy()), axis=1)
# 这样,我们在data_all中,前8列是特征量,最后一列是目标变量
preprocessor = Preprocessor()
# 归一化
data_all_normalized = preprocessor.normalize(data_all)
train_loader, test_loader = create_data_loaders(data_all_normalized[:, :8], data_all_normalized[:, 8:], batch_size=256) # 划分数据集
再次进行训练
# 实例化模型
model = Perceptron(input_size=8, output_size=1) # 定义损失函数
criterion = paddle.nn.MSELoss() # 定义优化器
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.001) num_epochs = 100 # 定义训练轮数 for epoch in range(num_epochs): for batch_id, (inputs, labels) in enumerate(train_loader()): # 前向传播 inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) labels = paddle.reshape(labels, shape=[-1, 1]) # 调整标签形状以匹配输出 loss = criterion(outputs, labels) # 计算损失 # 反向传播和优化 loss.backward() # 反向传播 optimizer.step() # 更新权重 optimizer.clear_grad() # 梯度清零,PaddlePaddle中在optimizer.step()之后需要清零梯度 if (epoch + 1) % 10 == 0: # 每10轮输出一次损失 print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.numpy():.4f}')
Epoch [100/100], Loss: 0.0142
# 在测试集上反归一化后计算损失值
model.eval() # 设置模型为评估模式 for inputs, labels in test_loader(): inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) # 反归一化前的拼接操作 combined_outputs = paddle.concat([inputs, outputs], axis=1) combined_labels = paddle.concat([inputs, labels], axis=1) # 将Paddle Tensor转换为NumPy数组以进行反归一化 combined_outputs_np = combined_outputs.numpy() combined_labels_np = combined_labels.numpy() # 反归一化 denorm_outputs = preprocessor.denormalize(combined_outputs_np) denorm_labels = preprocessor.denormalize(combined_labels_np) # 截取反归一化后的预测值和真实值(假设我们感兴趣的是从第9列开始的数据) denorm_outputs = denorm_outputs[:, 8:] denorm_labels = denorm_labels[:, 8:] # 将NumPy数组转回Paddle Tensor outputs_tensor = paddle.to_tensor(denorm_outputs, dtype='float32') labels_tensor = paddle.to_tensor(denorm_labels, dtype='float32') # 计算损失 loss = criterion(outputs_tensor, labels_tensor) # 输出损失 print(f'Test Loss: {loss.numpy():.4f}') break # 假设我们只展示第一批测试数据的损失
Test Loss: 0.6538
可见,当进行数据归一化操作后,在测试集上计算损失值时,我们能够得到一个差不多的结果。
多层感知机的简洁实现
接下来,我们将使用深度学习库来实现一个多层感知机(MLP)。
class MLP(nn.Layer): def __init__(self, input_size, output_size): super(MLP, self).__init__() self.fc1 = nn.Linear(in_features=input_size, out_features=64) # 第一个全连接层 self.relu = nn.ReLU() # 激活函数 self.fc2 = nn.Linear(in_features=64, out_features=32) # 第二个全连接层 self.fc3 = nn.Linear(in_features=32, out_features=output_size) # 输出层 def forward(self, x): out = self.fc1(x) out = self.relu(out) out = self.fc2(out) out = self.relu(out) out = self.fc3(out) return out
# 进行训练
model = MLP(input_size=8, output_size=1).to(device) # 实例化模型# 定义损失函数
criterion = paddle.nn.MSELoss() # 定义优化器
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.001) num_epochs = 100 # 定义训练轮数 for epoch in range(num_epochs): for batch_id, (inputs, labels) in enumerate(train_loader()): # 前向传播 inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) labels = paddle.reshape(labels, shape=[-1, 1]) # 调整标签形状以匹配输出 loss = criterion(outputs, labels) # 计算损失 # 反向传播和优化 loss.backward() # 反向传播 optimizer.step() # 更新权重 optimizer.clear_grad() # 梯度清零,PaddlePaddle中在optimizer.step()之后需要清零梯度 if (epoch + 1) % 10 == 0: # 每10轮输出一次损失 print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.numpy():.4f}') # 进行测试
# 在测试集上反归一化后计算损失值
model.eval() # 设置模型为评估模式 for inputs, labels in test_loader(): inputs = inputs.astype('float32')labels = labels.astype('float32')outputs = model(inputs) # 反归一化前的拼接操作 combined_outputs = paddle.concat([inputs, outputs], axis=1) combined_labels = paddle.concat([inputs, labels], axis=1) # 将Paddle Tensor转换为NumPy数组以进行反归一化 combined_outputs_np = combined_outputs.numpy() combined_labels_np = combined_labels.numpy() # 反归一化 denorm_outputs = preprocessor.denormalize(combined_outputs_np) denorm_labels = preprocessor.denormalize(combined_labels_np) # 截取反归一化后的预测值和真实值(假设我们感兴趣的是从第9列开始的数据) denorm_outputs = denorm_outputs[:, 8:] denorm_labels = denorm_labels[:, 8:] # 将NumPy数组转回Paddle Tensor outputs_tensor = paddle.to_tensor(denorm_outputs, dtype='float32') labels_tensor = paddle.to_tensor(denorm_labels, dtype='float32') # 计算损失 loss = criterion(outputs_tensor, labels_tensor) # 输出损失 print(f'Test Loss: {loss.numpy():.4f}') break # 假设我们只展示第一批测试数据的损失
Epoch [100/100], Loss: 0.0111
Test Loss: 0.3320
可以看到,该模型在测试集上具有较好的精度。
如何查看模型中各个层的参数?
# 输出模型参数
# 假设model是一个已经定义好的PaddlePaddle模型
for name, layer in model.named_sublayers(): for param in layer.parameters(): # 在PaddlePaddle中,参数名通常是通过 layer.name + 参数名 来获取的 # 例如:线性层的权重可能被命名为 "linear_0.w_0" full_param_name = f"{name}.{param.name}" print(full_param_name, param.shape, param.numpy())
fc1.linear_3.w_0 [8, 64] [[ 3.13081950e-01 2.06018716e-01 -2.03244463e-01 6.62552845e-031.20794969e-02 -1.63710177e-01 -7.88584426e-02 -1.71072856e-01-2.38272175e-01 -1.40343830e-01 -3.40595514e-01 -1.27847895e-01-8.12689662e-02 -1.93796322e-01 -1.73967615e-01 -6.09782934e-02-2.30334118e-01 5.17311767e-02 1.49296045e-01 1.77590698e-012.87044793e-01 3.24724615e-01 -9.37301572e-03 2.07839161e-022.03638270e-01 -2.86146969e-01 1.73401520e-01 2.73310632e-01-1.29703968e-03 -2.08033428e-01 -2.79000718e-02 2.02144414e-018.92829448e-02 2.35799953e-01 -1.24874398e-01 -2.52885759e-01-1.20067850e-01 1.37583837e-01 3.11312914e-01 2.81481184e-02-5.56637207e-03 3.96346040e-02 -9.06345099e-02 3.16798061e-011.95969284e-01 1.22597426e-01 -2.12079436e-01 -1.10605480e-022.52932459e-01 2.94231102e-02 -7.79357785e-03 -1.04727827e-011.52468294e-01 -3.32752287e-01 -3.68948251e-01 -4.53656614e-029.80597511e-02 -2.06019282e-01 6.06062263e-02 3.22720438e-01-1.39198959e-01 1.09098367e-01 1.65877655e-01 3.83714810e-02][ 1.97691053e-01 2.68247962e-01 1.02182925e-01 -2.21673980e-016.71685040e-02 2.14003429e-01 7.95149729e-02 -1.43927904e-021.95485000e-02 -2.51339942e-01 7.93670043e-02 1.12638079e-01-5.38468882e-02 -3.06898467e-02 1.51379794e-01 6.22531846e-022.14708835e-01 9.80924591e-02 1.66708350e-01 -3.12378965e-02-2.03294098e-01 1.10657394e-01 -2.52982259e-01 3.22187413e-03-8.82982910e-02 -1.55200779e-01 -2.23677039e-01 -1.12245090e-01-6.63331011e-04 -9.65051353e-02 7.15597644e-02 3.07830255e-025.82662830e-03 -2.87823766e-01 2.92417437e-01 3.21345702e-021.66399077e-01 4.70230281e-02 -7.07463454e-03 -6.04915805e-029.32222903e-02 -5.92378080e-02 -1.09557621e-01 3.09029445e-02-2.38836870e-01 1.38097152e-01 3.25661036e-03 -3.17538623e-031.48152769e-01 1.04433727e-02 -1.72422007e-02 2.42527097e-019.16873887e-02 -6.48293570e-02 -1.68860570e-01 -6.40835911e-026.08525500e-02 -1.49053276e-01 -2.48240486e-01 5.74986730e-033.12685445e-02 -6.31402507e-02 -2.81727612e-01 6.12065531e-02][-4.09857005e-01 3.11477602e-01 2.69458681e-01 4.48913306e-011.18098319e-01 2.47394755e-01 -1.15581743e-01 -2.04905525e-018.42827260e-01 -1.63813263e-01 1.00870140e-01 -1.04029886e-01-2.64002960e-02 -5.50883487e-02 -1.95006967e-01 -2.73619950e-01-3.00938524e-02 1.68695450e-01 5.22577986e-02 2.13823944e-014.51764077e-01 3.49374563e-01 -5.65181017e-01 -3.87557358e-011.29004359e-01 -1.20676987e-01 5.81966043e-01 3.37479147e-032.79788673e-02 -2.01127931e-01 2.44547185e-02 -1.75951913e-01-1.52701110e-01 2.95786243e-02 5.36481179e-02 2.97037140e-024.32989985e-01 -2.68881559e-01 4.25330549e-02 1.45621091e-015.48326433e-01 -3.74135941e-01 2.69327462e-01 1.13747448e-013.42393726e-01 -7.92791024e-02 2.18861148e-01 1.63596347e-011.47850409e-01 -4.30780828e-01 -4.81581949e-02 -2.52826780e-014.90360469e-01 -2.41113584e-02 7.71145597e-02 -1.40949534e-02-3.01896352e-02 -1.34475499e-01 -1.92220926e-01 -2.49957636e-01-2.03098997e-01 -1.53841227e-01 1.32989585e-01 4.62006480e-02][ 2.65925497e-01 4.05812204e-01 2.53788888e-01 4.99203712e-01-2.75020540e-01 3.65542322e-02 -3.27302329e-02 -2.58379102e-017.17044175e-01 -2.85323590e-01 -4.86054897e-01 -1.47260606e-01-9.64693353e-02 -4.43619825e-02 -6.87486455e-02 3.30955803e-011.83765545e-01 -1.89430609e-01 2.36887589e-01 3.58756721e-015.59944008e-03 -3.37457284e-02 2.50176519e-01 -4.56583709e-013.08023691e-01 -7.37715885e-02 -1.83679652e-03 9.28729996e-02-7.18701780e-01 2.79626548e-01 -2.19838172e-01 -6.79115504e-022.52646714e-01 2.41785645e-02 -6.17026567e-01 1.08945765e-01-1.62117127e-02 2.05493614e-01 -2.45605379e-01 2.65016913e-01-2.44144589e-01 4.52748537e-01 -2.06575722e-01 4.17236686e-01-1.04198933e-01 -2.66322345e-01 -5.73289171e-02 8.69868994e-02-3.20162088e-01 6.04037166e-01 -1.37159184e-01 2.63334125e-01-9.83569175e-02 -3.48932803e-01 -8.56782496e-02 2.06245899e-016.13508761e-01 2.07591414e-01 1.90393880e-01 -5.00104487e-01-1.53477311e-01 1.80223972e-01 -1.44515052e-01 -3.93530965e-01][-2.08107382e-02 -1.04099689e-02 1.54960945e-01 -1.76455304e-01-2.76900291e-01 2.41604139e-04 -6.17245845e-02 -1.93189204e-01-1.34109721e-01 -9.80562791e-02 -5.07896505e-02 8.53389949e-023.32316190e-01 1.53314933e-01 2.63355583e-01 8.86959657e-021.02258776e-03 2.05812305e-02 3.04718852e-01 1.02881730e-01-1.97050065e-01 -3.14103186e-01 -2.95645714e-01 -4.10347618e-022.84989476e-01 1.41007662e-01 -5.29043414e-02 3.68966639e-014.19721343e-02 -2.27591306e-01 -7.85444304e-02 -3.95845734e-02-2.98132330e-01 5.92459619e-01 -1.16872571e-01 6.15054853e-02-3.56268175e-02 -2.33406723e-02 -8.01426917e-02 -6.06930912e-01-1.41250402e-01 -3.51036370e-01 -2.24154398e-01 1.02946751e-01-1.62987053e+00 3.95317942e-01 1.55391753e-01 -1.58332791e-021.95650697e-01 7.13705143e-04 3.25329900e-01 1.07448131e-013.67635749e-02 -1.15112327e-01 8.02160278e-02 7.15531111e-025.10841250e-01 -1.32755637e-02 5.78131527e-02 2.79938608e-011.96959719e-01 -1.49558550e-02 3.00721645e-01 1.92038730e-01][-1.41917720e-01 -8.23766112e-01 3.62229139e-01 -4.03780222e-01-2.69680589e-01 5.43978333e-01 1.13129258e-01 -2.34977201e-013.57693760e-03 -2.98992321e-02 3.95094931e-01 1.11738533e-017.97432438e-02 -3.33442068e+00 2.30269492e-01 -7.64713943e-01-3.62472677e+00 7.77017295e-01 -2.42613745e+00 -1.50677538e+00-1.81879580e+00 9.88062397e-02 6.39276326e-01 4.79470283e-01-4.57693189e-01 1.07487750e+00 -1.29751253e+00 -8.10215354e-011.42558360e+00 -4.01732302e+00 4.02323753e-01 3.82710427e-01-3.57001638e+00 1.59708217e-01 1.28399014e+00 4.95734781e-01-5.63715808e-02 -3.56859064e+00 9.86382723e-01 -9.85695496e-02-7.60960162e-01 -9.98046935e-01 2.64710575e-01 1.63424224e-01-5.36435902e-01 6.28703833e-01 -1.64718166e-01 2.44663283e-011.47745657e+00 -4.11281919e+00 -7.97118247e-02 -1.20846283e+005.36247194e-01 1.03536451e+00 6.48276210e-01 3.26947302e-01-6.36863649e-01 2.36443996e-01 -1.75268464e-02 9.11053002e-011.20773637e+00 -2.47064066e+00 1.39027083e+00 3.95809710e-01][-1.61872298e-01 -4.73983921e-02 6.85898662e-02 1.39827654e-01-2.81924009e-01 1.64999783e-01 5.07304221e-02 -7.57065322e-031.31751299e-02 -9.22666211e-03 -2.24459730e-03 -1.60971448e-013.60914260e-01 -5.30816376e-01 -7.19735026e-01 -2.70165414e-01-6.34882301e-02 2.39850268e-01 -2.85788506e-01 -1.95005029e-01-3.71909924e-02 1.26119405e-01 2.35527605e-01 -4.28029150e-01-1.86404482e-01 3.03764254e-01 1.68191209e-01 1.67935163e-01-4.90795523e-01 1.00804202e-01 2.96638042e-01 1.71004266e-01-7.12542892e-01 -1.22327924e-01 -6.40762523e-02 1.65183812e-01-9.62912291e-03 -5.62684417e-01 1.75650641e-01 -4.40592200e-01-5.94980717e-02 -7.43935108e-02 -1.40420739e-02 1.86078727e-015.90516478e-02 1.40652969e-01 2.07288951e-01 -3.56071979e-01-4.49561607e-03 -1.98708162e-01 -6.95218593e-02 1.41653836e-01-1.28223494e-01 2.45206684e-01 5.62587902e-02 2.33916819e-01-2.45445043e-01 -1.57471791e-01 8.02162364e-02 -2.01123461e-012.75151104e-01 -7.36439764e-01 3.20188314e-01 -2.09429801e-01][-3.28922004e-01 3.21036875e-02 2.22631067e-01 3.42117250e-01-1.12229772e-01 -2.66779274e-01 2.27642640e-01 2.20010914e-021.13763986e-02 -1.42701551e-01 2.68349409e-01 -2.52015948e-01-3.80049646e-02 3.47857952e-01 -1.01911351e-01 -9.48912576e-023.98219973e-02 1.73353031e-02 -9.56577733e-02 5.20637492e-047.12814406e-02 -2.12296322e-01 2.00989246e-01 2.12521911e-01-2.45683312e-01 2.90980250e-01 -2.29072943e-01 -1.06725402e-011.87950462e-01 1.07663557e-01 1.29231781e-01 1.85621411e-012.34211445e-01 2.91730464e-01 -1.43423870e-01 -5.12544155e-011.94987655e-01 1.47930682e-01 3.78352068e-02 1.07470788e-01-9.71678831e-03 1.87591657e-01 -2.50399202e-01 -2.78749466e-01-3.17813486e-01 -1.39596477e-01 -5.97474456e-01 2.33624965e-011.88751385e-01 -2.05612496e-01 -4.54004332e-02 -1.34112224e-01-4.78985086e-02 2.64923960e-01 2.43170783e-01 -3.36947381e-01-2.53851831e-01 -1.67460501e-01 -4.19287942e-02 2.38913167e-027.84337968e-02 1.86697602e-01 2.65319109e-01 2.39701837e-01]]
fc1.linear_3.b_0 [64] [ 0.00306091 -0.02558158 0.00454489 0.03016263 0. -0.02868694-0.03931118 -0.00534521 -0.01530213 0. -0.03536369 0.0.02151108 0.0478561 -0.00703085 0.15141265 -0.00562203 -0.11636003-0.00471907 0.13182724 0.11320475 -0.07400184 -0.03130092 -0.037886560.20136295 -0.0085999 0.07928443 0.00637756 -0.01485943 0.07640248-0.01773066 -0.07182821 0.06375627 -0.04906173 -0.02948626 0.086062750.03898708 0.0261287 -0.11079289 -0.03349609 0.01131025 0.042847540. 0.08617433 -0.06705883 -0.00527788 0.00102845 -0.078828770.00541376 0.14916475 -0.04195836 0.03309786 -0.07463162 0.01432823-0.03576329 -0.0278319 0.128363 0. 0.16126738 -0.05268143-0.0318003 0.00874252 -0.12467249 0.00437972]
fc2.linear_4.w_0 [64, 32] [[ 0.12076211 0.29710326 0.18435588 ... 0.02129124 -0.14632721-0.0602207 ][-0.15748596 -0.13409673 0.16428283 ... 0.23962677 0.04871811-0.07986252][-0.22211064 0.08062842 0.23870611 ... 0.23241106 0.20715353-0.02460032]...[-0.06257392 -0.54390067 0.41931018 ... -0.00761214 0.137970670.13061428][-0.13696408 0.04951911 0.17234398 ... 0.02103687 0.090170390.2544022 ][ 0.00619695 0.10919159 0.02408725 ... -0.08012126 -0.119147960.09203152]]
fc2.linear_4.b_0 [32] [ 0. 0.11219498 0.03213965 0.08007792 0.01139668 0.03578897-0.00302749 0.02309586 0.06290476 0.01535221 0. -0.04957908-0.01963384 0.02519283 -0.00790157 0.03342469 0.03499044 -0.06439646-0.01683257 0.01111472 0.0128254 -0.01295854 -0.01288085 0.0.02362463 -0.01070113 -0.04373857 -0.08965649 0.02834409 0.016859730.03126996 0.03094241]
fc3.linear_5.w_0 [32, 1] [[-0.055028 ][-1.2238208 ][ 0.33306003][ 1.0926676 ][ 0.33545637][-0.42914596][-0.23753783][-0.7103648 ][ 0.92299587][ 0.7484889 ][-0.03405289][-0.94157344][-0.3386857 ][-0.24807313][ 0.0398786 ][ 0.37158772][ 0.2504425 ][-0.6008288 ][-0.5686133 ][ 0.28256068][-0.31580347][-0.4092537 ][-0.32789922][ 0.31644353][-0.6614081 ][-0.6777225 ][-0.42700088][-0.7607351 ][ 0.07619953][ 0.44976866][ 0.26336157][ 0.14496523]]
fc3.linear_5.b_0 [1] [0.03343805]
相关文章:
多层感知机paddle
多层感知机——paddle部分 本文部分为paddle框架以及部分理论分析,torch框架对应代码可见多层感知机 import paddle print("paddle version:",paddle.__version__)paddle version: 2.6.1多层感知机(MLP,也称为神经网络࿰…...

linux-网络管理-网络服务管理 17 / 100
Linux 网络管理:网络服务管理 一、概述 在 Linux 系统中,网络服务管理是系统管理中的重要组成部分。网络服务通常涉及到多种协议、服务和工具,用于确保服务器与客户端、局域网与广域网、以及不同系统之间的通信畅通。Linux 提供了强大的工具…...

Docker上安装mysql
获取 MySQL 镜像 获取镜像。使用以下命令来拉取镜像: 1docker pull mysql:latest 这里拉取的是最新版本的 MySQL 镜像。你也可以指定特定版本,例如: 1docker pull mysql:8.0 运行 MySQL 容器 运行 MySQL 容器时,你需要指定一些…...

【秋招笔试-支持在线评测】8.28华为秋招(已改编)-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 华为专栏传送🚪 -> 🧷华为春秋招笔试 目前今年秋招的笔…...

基于python上门维修预约服务数据分析系统
目录 技术栈和环境说明解决的思路具体实现截图python语言框架介绍技术路线性能/安全/负载方面可行性分析论证python-flask核心代码部分展示python-django核心代码部分展示操作可行性详细视频演示源码获取 技术栈和环境说明 结合用户的使用需求,本系统采用运用较为广…...
:React Hooks)
React基础教程(10):React Hooks
9.1 使用hooks理由 高阶组件为了复用,导致代码层级复杂。生命周期的复杂。写成函数组件,无状态组件,因为需要状态,又写成了class,成本高9.2 useState(保存组件状态) const [state, setState] = useState(initialState);案例:点击按钮修改name...

JVM 调优篇9 调优案例6- cpu使用过载解决办法【超赞】
一 cpu过载说明 1.1 背景说明 如果线程死锁,那么线程一直在占用CPU,这样就会导致CPU一直处于一个比较高的占用率。 1.2 代码 模拟一个死锁的代码 public class JstackDeadLockDemo {/*** 必须有两个可以被加锁的对象才能产生死锁,只有一个不会产生死锁问题*/private f…...

Spring8-事务
目录 JdbcTemplate 声明式事务 事务 概述 特性(ACID) 编程式事务 声明式事务 基于注解的声明式事务 Transactional注解标识的位置 事务属性:只读 事务属性:超时 事务属性:隔离级别 事务属性:传…...

在Python中,类是用于定义对象的蓝图或模板,而对象则是根据类创建的具体实例
当然,我可以为您演示类与对象的基本概念和它们之间的关系。在Python中,类是用于定义对象的蓝图或模板,而对象则是根据类创建的具体实例。 下面是一个简单的Python程序,它定义了一个Car类,该类具有一些属性和方法&…...
)
【小波去噪】【matlab】基于小波分析的一维信号滤波(对照组:中值滤波、均值滤波、高斯滤波)
链接1-傅里叶变换 链接2-傅立叶分析和小波分析间的关系 链接3-小波变换(wavelet transform)的通俗解释 链接4-小波基的选择 1.示例代码 function main_wavelet clc clear close all warning off %% 1.信号生成 time_length 10;%总时长,秒 …...

CentOS 7官方源停服,配置本机光盘yum源
1、挂载系统光盘 mkdir /mnt/iso mount -o loop /tools/CentOS-7-x86_64-DVD-1810.iso /mnt/iso cd /mnt/iso/Packages/ rpm -ivh /mnt/iso/Packages/yum-utils-1.1.31-50.el7.noarch.rpm(图形界面安装,默契已安装) 如安装yum-utils依赖错误&#x…...

2024年汉字小达人区级自由报名备考冲刺:2024官方模拟题练一练(续)
2024年第十一届汉字小达人的区级活动的时间9月25-30日正式开赛,满打满算还有9天时间。 今天继续回答一些问题关于汉字小达人的常见问题,再做几道2024年官方模拟题,帮助大家直观地了解汉字小达人的比赛题型和那你程度。 本专题在比赛前持续更…...

实战Redis与MySQL双写一致性的缓存模式
Redis和MySQL都是常用的数据存储系统,它们各自有自己的优缺点。在实际应用中,我们可能需要将它们结合起来使用,比如将Redis作为缓存,MySQL作为持久化存储。 在这种情况下,我们需要保证Redis和MySQL的数据一致性&…...
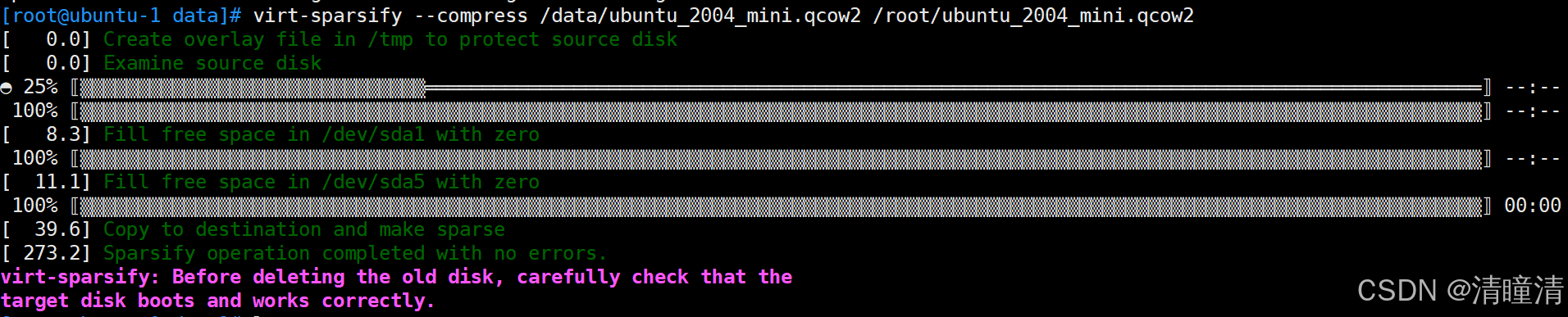
KVM环境下制作ubuntu qcow2格式镜像
如果是Ubuntu KVM环境是VMware虚拟机,需要CPU开启虚拟化 1、配置镜像源 wget -O /etc/apt/sources.list https://www.qingtongqing.cc/ubuntu/sources.list2、安装kvm qemu-img libvirt kvm虚拟化所需环境组件 apt -y install qemu-kvm virt-manager libvirt-da…...

基于SpringBoot+Vue的高校竞赛管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 【2025最新】基于JavaSpringBootVueMySQL的…...

PHP发邮件教程:配置SMTP服务器发送邮件?
PHP发邮件的几种方式?如何使用PHP通过SMTP协议发信? PHP作为一种广泛使用的服务器端脚本语言,提供了多种方式来发送邮件。AokSend将详细介绍如何通过配置SMTP服务器来实现PHP发邮件教程的核心内容。 PHP发邮件教程:设置参数 这…...

SpringBootWeb增删改查入门案例
前言 为了快速入门一个SpringBootWeb项目,这里就将基础的增删改查的案例进行总结,作为对SpringBootMybatis的基础用法的一个巩固。 准备工作 需求说明 对员工表进行增删改查操作环境搭建 准备数据表 -- 员工管理(带约束) create table emp (id int …...

pytorch实现RNN网络
目录 1.导包 2. 加载本地文本数据 3.构建循环神经网络层 4.初始化隐藏状态state 5.创建随机的数据,检测一下代码是否能正常运行 6. 构建一个完整的循环神经网络 7.模型训练 8.个人知识点理解 1.导包 import torch from torch import nn from torch.nn imp…...

智能工厂的软件设计 “程序program”表达式,即 接口模型的代理模式表达式
Q1、前面将“智能工厂的软件设计”中绝无仅有的“程序”视为 专注于 给定的某个单一面(语言面/逻辑面/数学面)中的 问题,专注于分析问题和解决问题的程序活动的组织,每一面都是一个“组织者”就像一个“独角兽”,并提出…...

leetcode 难度【简单模式】标签【数据库】题型整理大全
文章目录 175. 组合两个表181. 超过经理收入的员工182. 查找重复的电子邮箱COUNT(*)COUNT(*) 与 COUNT(column) 的区别 where和vaing之间的区别用法 183.从不订购的客户196.删除重复的电子邮箱197.上升的温度511.游戏玩法分析I512.游戏玩法分析II577.员工奖金584.寻找用户推荐人…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...

原来专业的赛事专用匹克球厂家有这么多门道?
引言在匹克球运动蓬勃发展的当下,专业赛事专用匹克球的选择至关重要。很多人可能不知道,看似普通的赛事专用匹克球背后,其实隐藏着诸多门道。接下来,我们就一起深入探究专业赛事专用匹克球厂家的秘密。核心技术与材料的门道专业赛…...

西安旅行社哪个靠谱
西安,这座承载着十三朝古都历史的城市,每年吸引着数千万游客。但面对市面上琳琅满目的旅行社,如何避开“购物团”“低价陷阱”“服务缩水”等坑?作为扎根西安8年的本地人,我结合陕西悠游天下国际旅行社有限公司&#x…...