AIGC专栏15——CogVideoX-Fun详解 支持图文生视频 拓展CogVideoX到256~1024任意分辨率生成
AIGC专栏15——CogVideoX-Fun详解 支持图&文生视频 拓展CogVideoX到256~1024任意分辨率生成
- 学习前言
- 项目特点
- 生成效果
- 相关地址汇总
- 源码下载地址
- CogVideoX-Fun详解
- 技术储备
- Diffusion Transformer (DiT)
- Stable Diffusion 3
- EasyAnimate-I2V
- 算法细节
- 算法组成
- InPaint模型
- 基于Token长度的模型训练
- Resize 3D Embedding
- 项目使用
- 项目启动
- 文生视频
- 图生视频
- 视频生视频
学习前言
这段时间正在训练EasyAnimateV4.5,发现总有一些问题解决不了,开始怀疑是自己的训练框架有问题。
恰逢清华开源了CogVideoX,这是个很优秀的文生视频模型,可惜没有图生视频,还固定了分辨率,于是试着将CogVideo修改到我们的框架中,发现其实效果还不错。

项目特点
- 支持 图 和 文 生视频;
- 支持 首尾图 生成视频
- 最大支持720p 49帧视频生成;
- 无限长视频生成;
- 数据处理到训练完整pipeline代码开源。
生成效果
CogVideoX-Fun的生成效果如下,分别支持图生视频和文生视频。与EasyAnimate类似,通过图生视频的能力,我们还可以进行视频续写,生成无限长视频。






相关地址汇总
源码下载地址
https://github.com/aigc-apps/CogVideoX-Fun
感谢大家的关注。
CogVideoX-Fun详解
技术储备
Diffusion Transformer (DiT)
DiT基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
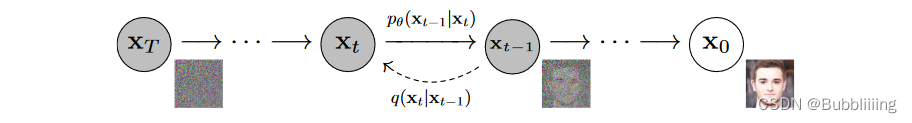
DiT相比于DDPM,使用了更快的采样器,也使用了更大的分辨率,与Stable Diffusion一样使用了隐空间的扩散,但可能更偏研究性质一些,没有使用非常大的数据集进行预训练,只使用了imagenet进行预训练。
与Stable Diffusion不同的是,DiT的网络结构完全由Transformer组成,没有Unet中大量的上下采样,结构更为简单清晰。
Stable Diffusion 3
在2024年3月,Stability AI发布了Stable Diffusion 3,Stable Diffusion 3一个模型系列,参数量从 800M 到 8B 不等。相比于过去的Stable Diffusion,Stable Diffusion 3的生图质量更高,且更符合人类偏好。
Stable Diffusion 3做了多改进,比如文本信息注入的方式,DiT模型在最初引入文本时,通常使用Cross Attention的方法结合文本信息,如Pixart-α、hunyuan DiT等。Stable Diffusion 3通过Self-Attention引入文本信息。相比于Cross Attention,使用Self-Attention引入文本信息不仅节省了Cross Attention的参数量,还节省了Cross Attention的计算量。
Stable Diffusion 3还引入了RMS-Norm。,在每一个attention运算之前,对Q和K进行了RMS-Norm归一化,用于增强模型训练的稳定性。
同时使用了更大的VQGAN,VQGAN压缩得到的特征维度从原来的4维提升到16维等。

EasyAnimate-I2V

在EasyAnimate中,需要重建的部分和重建的参考图分别通过VAE进行编码,上图黑色的部分代表需要重建的部分,白色的部分代表首图,然后和随机初始化的latent进行concat,假设我们期待生成一个384x672x144的视频,此时的初始latent就是4x36x48x84,需要重建的部分和重建的参考图编码后也是4x36x48x84,三个向量concat到一起后便是12x36x48x84,传入DiT模型中进行噪声预测。
这样模型就可以知道视频的哪些部分需要重建,通过inpaint的方式实现图生视频。
算法细节
算法组成
我们使用了CogVideoX作为基础模型,并在此基础上重新训练。
在CogVideoX-FUN中,我们基于CogVideoX在大约1.2m的数据上进行了训练,支持图片与视频预测,支持像素值从512x512x49、768x768x49、1024x1024x49与不同纵横比的视频生成。另外,我们支持图像到视频的生成与视频到视频的重建。
- 引入InPaint模型,实现图生视频功能,可以通过首尾图指定视频生成。
- 基于Token长度的模型训练。达成不同大小多分辨率在同一模型中的实现。
InPaint模型

我们以CogVideoX作为基础结构,参考EasyAnimate进行图生视频的模型训练。
在进行视频生成的时候,将参考视频使用VAE进行encode,上图黑色的部分代表需要重建的部分,白色的部分代表首图,与噪声Latents一起堆叠后输入到Transformer中进行视频生成。
我们对被Mask的区域进行3D Resize,直接Resize到需要重建的视频的画布大小。
然后将Latent、Encode后的参考视频、被Mask的区域,concat后输入到DiT中进行噪声预测。获得最终的视频。
基于Token长度的模型训练
我们收集了大约高质量的1.2m数据进行CogVideoX-Fun的训练。
在进行训练时,我们根据不同Token长度,对视频进行缩放后进行训练。整个训练过程分为三个阶段,每个阶段的13312(对应512x512x49的视频),29952(对应768x768x49的视频),53248(对应1024x1024x49的视频)。
以CogVideoX-Fun-2B为例子,其中:
- 13312阶段,Batch size为128,训练步数为7k
- 29952阶段,Batch size为256,训练步数为6.5k。
- 53248阶段,Batch size为128,训练步数为5k。
训练时我们采用高低分辨率结合训练,因此模型支持从512到1280任意分辨率的视频生成,以13312 token长度为例:
- 在512x512分辨率下,视频帧数为49;
- 在768x768分辨率下,视频帧数为21;
- 在1024x1024分辨率下,视频帧数为9;
这些分辨率与对应长度混合训练,模型可以完成不同大小分辨率的视频生成。
Resize 3D Embedding
在适配CogVideoX-2B到CogVideoX-Fun框架的途中,发现源码是以截断的方式去得到3D Embedding的,这样的方式只能适配单一分辨率,当分辨率发生变化时,Embedding也应当发生变化。

参考Pixart-Sigma,我们采用positional embeddings Interpolation对3D embedding进行Resize,positional embeddings Interpolation相比于直接生成cos sin的embedding更易收敛。
项目使用
项目启动
推荐在docker中使用CogVideoX-Fun:
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun# clone code
git clone https://github.com/aigc-apps/CogVideoX-Fun.git# enter CogVideoX-Fun's dir
cd CogVideoX-Fun# download weights
mkdir models/Diffusion_Transformer
mkdir models/Personalized_Modelwget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/Diffusion_Transformer/CogVideoX-Fun-2b-InP.tar.gz -O models/Diffusion_Transformer/CogVideoX-Fun-2b-InP.tar.gzcd models/Diffusion_Transformer/
tar -xvf CogVideoX-Fun-2b-InP.tar.gz
cd ../../python app.py
到这里已经可以打开gradio网站了。
文生视频
首先进入gradio网站。选择对应的预训练模型,如"models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512"。然后在下方填写提示词。

然后调整视频高宽和生成帧数,最后进行生成;
图生视频

图生视频与文生视频有两个不同点:
- 1、需要指定参考图;
- 2、指定与参考图类似的高宽;
CogVideoX-Fun的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的首图调整高宽。

视频生视频
视频生视频与文生视频有两个不同点:
- 1、需要指定参考视频;
- 2、指定与参考视频类似的高宽;
CogVideoX-Fun的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的视频调整高宽。

相关文章:
AIGC专栏15——CogVideoX-Fun详解 支持图文生视频 拓展CogVideoX到256~1024任意分辨率生成
AIGC专栏15——CogVideoX-Fun详解 支持图&文生视频 拓展CogVideoX到256~1024任意分辨率生成 学习前言项目特点生成效果相关地址汇总源码下载地址 CogVideoX-Fun详解技术储备Diffusion Transformer (DiT)Stable Diffusion 3EasyAnimate-I2V 算法细节算法组成InPa…...
BFS 解决多源最短路问题
文章目录 多源BFS542. 01 矩阵题目解析算法原理代码实现 1020. 飞地的数量题目解析算法原理 1765. 地图中的最高点题目解析算法原理代码实现 1162. 地图分析题目解析算法原理代码实现 多源BFS 单源最短路: 一个起点、一个终点 多源最短路: 可以多个起点…...

论文笔记:交替单模态适应的多模态表征学习
整理了CVPR2024 Multimodal Representation Learning by Alternating Unimodal Adaptation)论文的阅读笔记 背景MLA框架实验Q1 与之前的方法相比,MLA能否克服模态懒惰并提高多模态学习性能?Q2 MLA在面临模式缺失的挑战时表现如何?Q3 所有模块是否可以有…...

鸿蒙OS 线程间通信
鸿蒙OS 线程间通信概述 在开发过程中,开发者经常需要在当前线程中处理下载任务等较为耗时的操作,但是又不希望当前的线程受到阻塞。此时,就可以使用 EventHandler 机制。EventHandler 是 HarmonyOS 用于处理线程间通信的一种机制,…...

执行 npm报错 Cannot find module ‘../lib/cli.js‘
报错 /usr/local/node/node-v18.20.4-linux-x64/bin/npm node:internal/modules/cjs/loader:1143 throw err; ^ Error: Cannot find module ../lib/cli.js Require stack: - /usr/local/node/node-v18.20.4-linux-x64/bin/npm at Module._resolveFilename (node:inter…...

基于SpringBoot+Vue+MySQL的国产动漫网站
系统展示 用户前台界面 管理员后台界面 系统背景 随着国内动漫产业的蓬勃发展和互联网技术的快速进步,动漫爱好者们对高质量、个性化的国产动漫内容需求日益增长。然而,市场上现有的动漫平台大多以国外动漫为主,对国产动漫的推广和展示存在不…...

AUTOSAR汽车电子嵌入式编程精讲300篇-基于CAN总线的气动控制
目录 前言 知识储备 什么是气动控制: 气动控制基础知识 一、气动元件 二、气路设计 三、气动控制系统 气动控制系统构成图 气动控制系统基本组成功能图 几种常见的气动执行元件实物图 常用气动压力控制阀实物图 常用气动流动控制阀实物图 电磁控制换向发实物图 部…...

Ubuntu 20.04 内核升级后网络丢失问题的解决过程
在 Ubuntu 系统中,内核升级是一个常见的操作,旨在提升系统性能、安全性和兼容性。然而,有时这一操作可能会带来一些意外的副作用,比如导致网络功能的丧失。 本人本来是想更新 Nvidia 显卡的驱动,使用 ubuntu-drivers …...

论文解读《LaMP: When Large Language Models Meet Personalization》
引言:因为导师喊我围绕 “大语言模型的个性化、风格化生成” 展开研究,所以我就找相关论文,最后通过 ACL 官网找到这篇,感觉还不错,就开始解读吧! “说是解读,其实大部分都是翻译哈哈哈&#x…...
Excel VLOOKUP函数怎么用?vlookup函数的使用方法及案例
大家好,这里是效率办公指南! 🔎 在Excel的世界里,VLOOKUP函数无疑是查询和数据分析中的明星。无论是从庞大的数据表中提取特定信息,还是进行数据的快速匹配,VLOOKUP都能大显身手。今天,我们将深…...

专为汽车功能应用打造的 MLX90376GGO、MLX90377GGO、MLX90377GDC-ADB-280 Triaxis®磁位置传感器 IC
一、MLX90376 Triaxis堆叠式高性能位置传感器芯片(模拟/PWM/SENT/SPC) MLX90376GGO-ABA-600 MLX90376GGO-ABA-630 MLX90376GGO-ABA-680 MLX90376是一款磁性绝对位置传感器芯片,适用于要求具备抗杂散磁场干扰性能的360旋转汽车应用。它提供…...

34.贪心算法1
0.贪心算法 1.柠檬水找零(easy) . - 力扣(LeetCode) 题目解析 算法原理 代码 class Solution {public boolean lemonadeChange(int[] bills) {int five 0, ten 0;for (int x : bills) {if (x 5) // 5 元:直接收下…...

DataX实战:从MongoDB到MySQL的数据迁移--修改源码并测试打包
在现代数据驱动的业务环境中,数据迁移和集成是常见的需求。DataX,作为阿里云开源的数据集成工具,提供了强大的数据同步能力,支持多种数据源和目标端。本文将介绍如何使用DataX将数据从MongoDB迁移到MySQL。 环境准备 安装MongoDB…...

Axure设计之表格列冻结(动态面板+中继器)
在Web端产品设计中,复杂的表格展示是常见需求,尤其当表格包含大量列时,如何在有限的屏幕空间内优雅地展示所有信息成为了一个挑战。用户通常需要滚动查看隐藏列,但关键信息列(如ID、操作按钮等)在滚动时保持…...

WPF DataGrid 动态修改某一个单元格的样式
WPF DataGrid 动态修改某一个单元格的样式 <DataGrid Name"main_datagrid_display" Width"1267" Height"193" Grid.Column"1"ItemsSource"{Binding DataGridModels}"><DataGrid.Columns><!--ElementStyle 设…...

如何安装部署kafka
安装和部署Apache Kafka需要以下几个步骤,包括下载 Kafka、配置 ZooKeeper(或者使用 Kafka 自带的 Kafka Raft 模式替代 ZooKeeper),以及启动 Kafka 服务。以下是一个但基于 Linux 的典型安装流程,可以根据需要改装到其…...

Centos7-rpm包管理器方式安装MySQL 5.7.25
前言 本文用于学习通过Mysql压缩包在centos7中安装和配置的过程以及过程中碰到的Bug解决。 Mysql安装包下载和上传 MySQL :: Download MySQL Community Server (Archived Versions)https://downloads.mysql.com/archives/community/访问Mysql官方下载站,选择对应的…...

Project Online 协作版部署方案
目录 前言 第一部分:为什么选择Project Online? 一、核心优势 二、适用场景 第二部分:部署前的准备工作 一、需求分析 二、账户和权限管理 三、培训与支持 第三部分:Project Online 的核心功能 一、项目创建与管理 二、资源管理 三、团队协作 四、风险管理 五…...

小米 13 Ultra机型工程固件 资源预览与刷写说明 步骤解析
小米 13 Ultra机型---机型代码为ishtar 。工程固件可以辅助修复格机或者全檫除分区后的基带修复。可以用于修复TEE损坏。以及一些分区的底层修复。此款固件也可以为更换UFS后的底包。 通过博文了解 1💝💝💝-----此机型工程固件的资源刷写注意事项 2💝💝💝-----此…...

Goweb预防XSS攻击
XSS攻击示例 假设您有一个简单的Web应用程序,其中包含一个用户输入表单,用户可以在其中输入他们的名字,然后这个名字会被显示在页面上。攻击者可以在表单中输入恶意的JavaScript代码,如,如果应用程序没有对这个输入进…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...

“--glow”并不存在?!深度逆向Midjourney 6.1源码级辉光模拟协议,曝光官方刻意隐藏的4个隐式辉光增强开关
更多请点击: https://kaifayun.com 第一章:辉光效果的视觉本质与Midjourney 6.1协议悖论 辉光(Glow)并非物理光源的直接投射,而是人眼视网膜对高对比度边缘与饱和色域交界处产生的神经光学响应——一种由局部亮度梯度…...