Kettle的安装及简单使用
Kettle的安装及简单使用一、kettle概述二、kettle安装部署和使用Windows下安装案例1:MySQL to MySQL案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据案例3:将hive表的数据输出到hdfs案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中三、创建资源库1、数据库资源库2、文件资源库四、 Linux下安装使用1、单机2、 集群模式案例:读取hive中的emp表,根据id进行排序,并将结果输出到hdfs上五、调优
一、kettle概述
1、什么是kettle
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
2、Kettle工程存储方式
(1)以XML形式存储
(2)以资源库方式存储(数据库资源库和文件资源库)
3、Kettle的两种设计

4、Kettle的组成

5、kettle特点

二、kettle安装部署和使用
Windows下安装
(1)概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
(2)安装步骤
1、安装jdk 2、下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可 3、双击Spoon.bat,启动图形化界面工具,就可以直接使用了
案例1:MySQL to MySQL
把stu1的数据按id同步到stu2,stu2有相同id则更新数据
1、在mysql中创建testkettle数据库,并创建两张表
create database testkettle; use testkettle; create table stu1(id int,name varchar(20),age int); create table stu2(id int,name varchar(20));
2、往两张表中插入一些数据
insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23); insert into stu2 values(1001,'wukong');
3、把pdi-ce-8.2.0.0-342.zip文件拷贝到win环境中指定文件目录,解压后双击Spoon.bat,启动图形化界面工具,就可以使用了

主界面:
在kettle中新建转换--->输入--->表输入-->表输入双击

在data-integration\lib文件下添加mysql驱动

在数据库连接栏目点击新建,填入mysql相关配置,并测试连接

建立连接后,选择刚刚建好的连接,填入SQL,并预览数据:

以上说明stu1的数据输入ok的,现在我们需要把输入stu1的数据同步到stu2输出的数据

注意:拖出来的线条必须是深灰色才关联成功,若是浅灰色表示关联失败

转换之前,需要做保存

执行成功之后,可以在mysql查看,stu2的数据
mysql> select * from stu2; +------+----------+ | id | name | +------+----------+ | 1001 | zhangsan | | 1002 | lisi | | 1003 | wangwu | +------+----------+ 3 rows in set (0.00 sec)
案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据
1、新建一个作业

2、按图示拉取组件

3、双击Start编辑Start
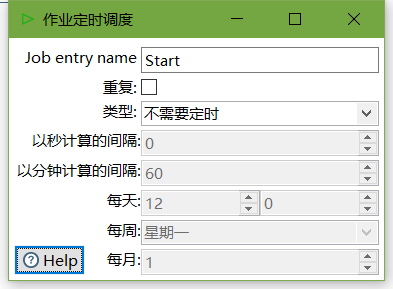
4、双击转换,选择案例1保存的文件

5、在mysql的stu1中插入一条数据,并将stu2中id=1001的name改为wukong
mysql> insert into stu1 values(1004,'stu1',22); Query OK, 1 row affected (0.01 sec) mysql> update stu2 set name = 'wukong' where id = 1001; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0
6、双击SQL脚本编辑
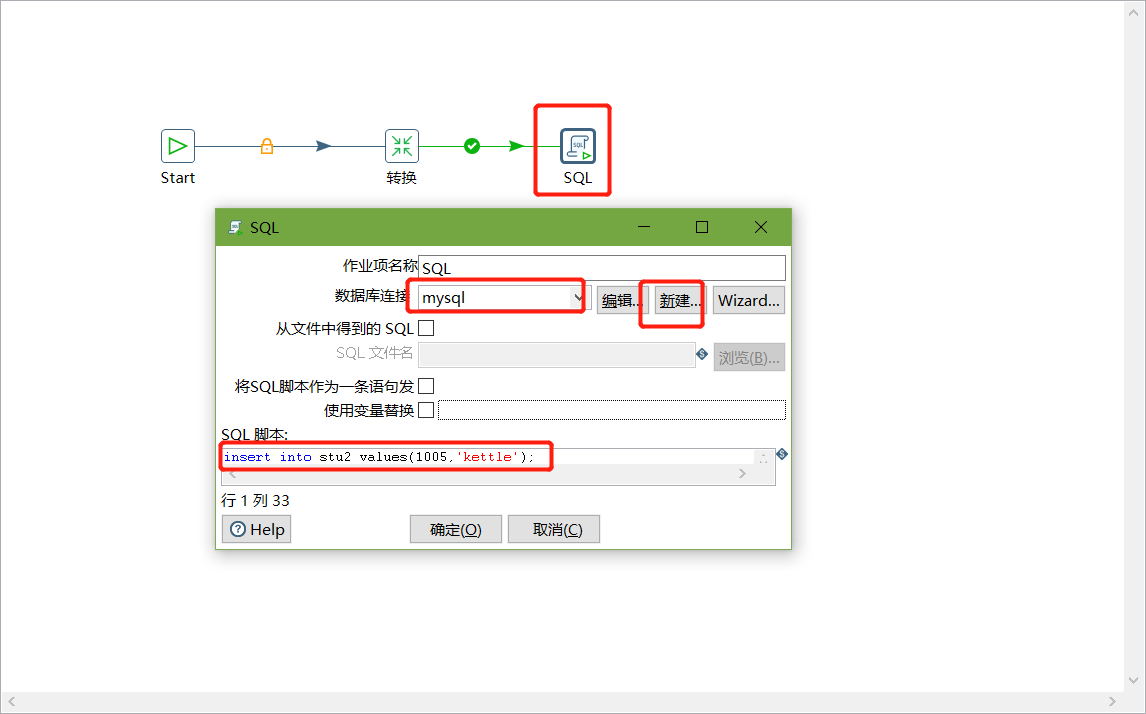
7、加上Dummy,如图所示:

8、保存并执行

9、在mysql数据库查看stu2表的数据
mysql> select * from stu2; +------+----------+ | id | name | +------+----------+ | 1001 | zhangsan | | 1002 | lisi | | 1003 | wangwu | | 1004 | stu1 | | 1005 | kettle | +------+----------+ 5 rows in set (0.00 sec)
案例3:将hive表的数据输出到hdfs
1、因为涉及到hive和hbase(后续案例)的读写,需要修改相关配置文件
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下

2、启动hadoop集群、hiveserver2服务
3、进入hive shell,创建kettle数据库,并创建dept、emp表
create database kettle; use kettle; CREATE TABLE dept(deptno int,dname string,loc string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; CREATE TABLE emp(empno int,ename string,job string,mgr int,hiredate string,sal double,comm int,deptno int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
4、插入数据
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON'); insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
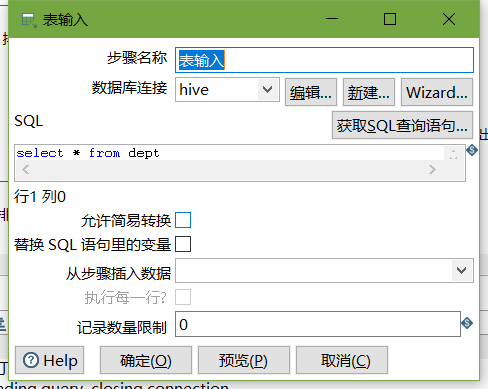
5、按下图建立流程图

-
表输入
-
表输入2

-
排序记录

-
记录集连接

-
字段选择


-
文本文件输出

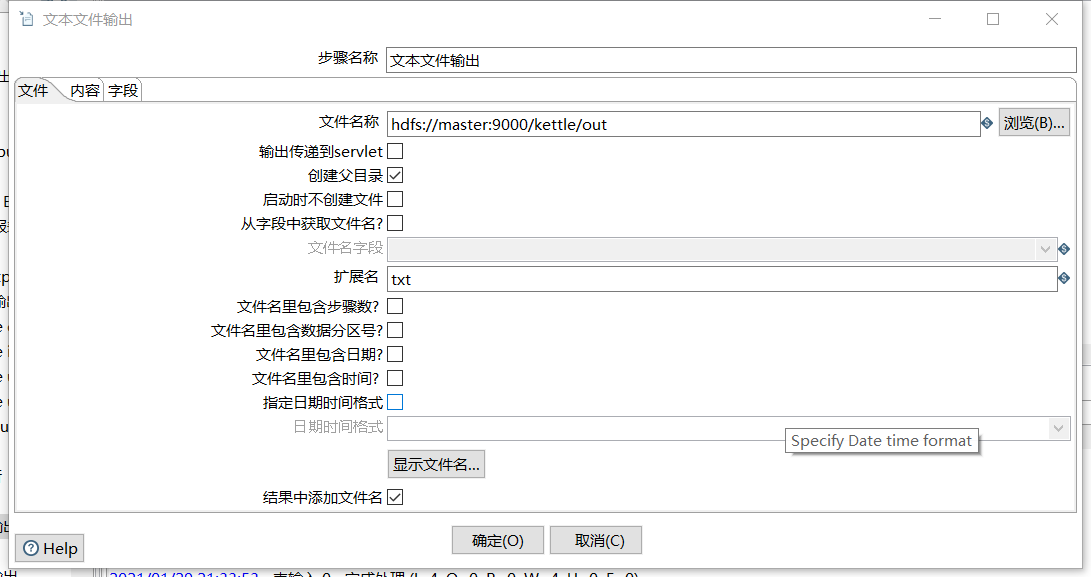
6、保存并运行查看hdfs
-
运行

-
查看HDFS文件

案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中
1、在HBase中创建一张people表
hbase(main):004:0> create 'people','info'
2、按下图建立流程图

-
文本文件输入

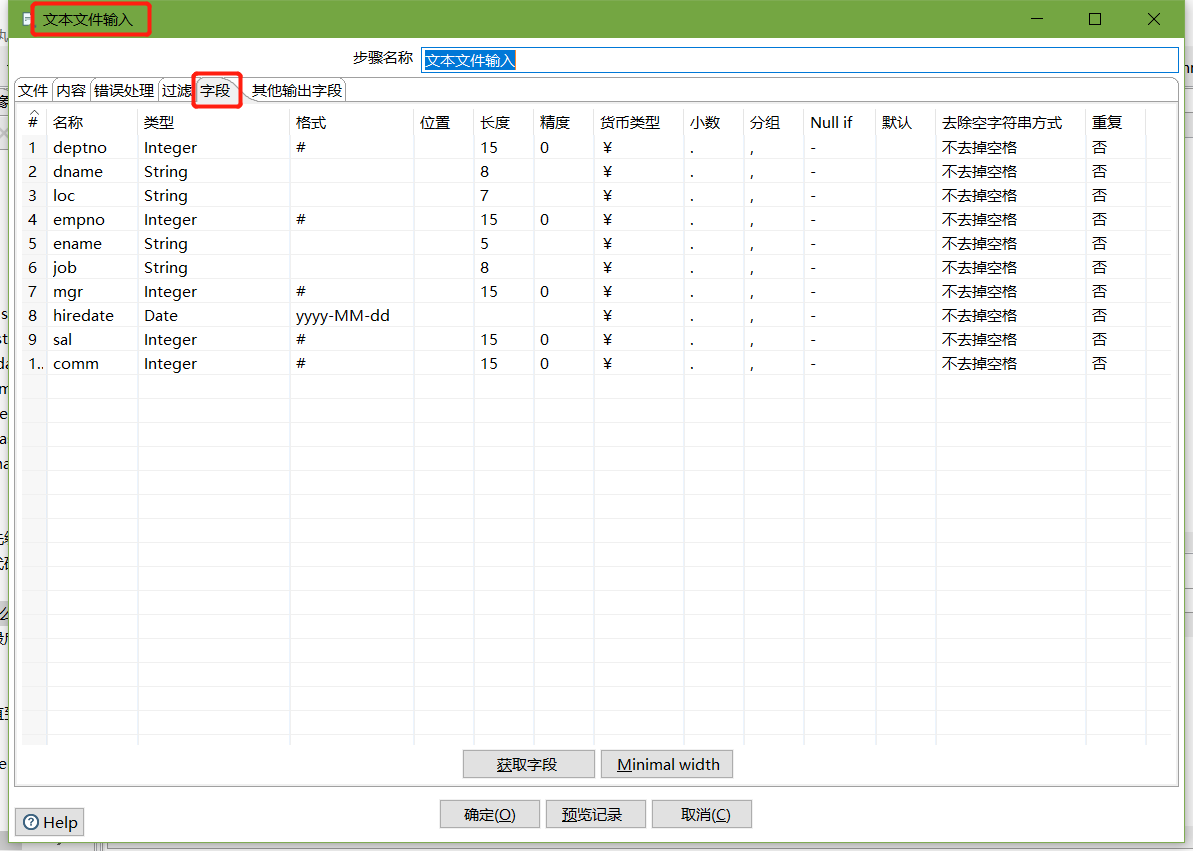
-
设置过滤记录

-
设置HBase output
编辑hadoop连接,并配置zookeeper地址


-
执行转换

-
查看hbase people表的数据
scan 'people'
注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"
三、创建资源库
1、数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,方便跨平台使用
-
在MySQL中创建kettle数据库
mysql> create database kettle; Query OK, 1 row affected (0.01 sec)
-
点击右上角connect,选择Other Resporitory

-
选择Database Repository

-
建立新连接


-
填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成

-
连接资源库
默认账号密码为admin

-
将之前做过的转换导入资源库
-
选择从xml文件导入

-
点击保存,选择存储位置及文件名

-
查看MySQL中kettle库中的R_TRANSFORMATION表,观察转换是否保存

-
2、文件资源库
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样
创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨
平台使用比较麻烦
-
选择connect
-
点击add后点击Other Repositories
-
选择File Repository
-
填写信息

四、 Linux下安装使用
1、单机
-
jdk安装
-
安装包上传到服务器,并解压
注意:
-
把mysql驱动拷贝到lib目录下
-
将windows本地用户家目录下的隐藏目录C:\Users\自己用户名\.kettle 目录,
整个上传到linux的用户的家目录下,root用户的家目录为/root/
-
-
运行数据库资源库中的转换:
cd /usr/local/soft/data-integration ./pan.sh -rep=my_repo -user=admin -pass=admin -trans=trans1
参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)(如果是以ktr文件运行时,需要指定ktr文件的路径)

-
运行资源库里的作业:
记得把作业里的转换变成资源库中的资源
记得把作业也变成资源库中的资源
cd /usr/local/soft/data-integration mkdir logs ./kitchen.sh -rep=my_repo -user=admin -pass=admin -job=job1 -logfile=./logs/log.txt
参数说明: -rep - 资源库名 -user - 资源库用户名 -pass – 资源库密码 -job – job名 -dir – job路径(当直接运行kjb文件的时候需要指定) -logfile – 日志目录

2、 集群模式
-
准备三台服务器
master作为Kettle主服务器,服务器端口号为8080,
node1和node2作为两个子服务器,端口号分别为8081和8082。
-
安装部署jdk
-
hadoop完全分布式环境搭建
-
上传并解压kettle的安装包至
/usr/local/soft/目录下 -
进到/usr/local/soft/data-integration/pwd目录,修改配置文件
-
修改主服务器配置文件carte-config-master-8080.xml
<slaveserver><name>master</name><hostname>master</hostname><port>8080</port><master>Y</master><username>cluster</username><password>cluster</password> </slaveserver>
-
修改从服务器配置文件carte-config-8081.xml
<masters><slaveserver><name>master</name><hostname>master</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver> </masters> <report_to_masters>Y</report_to_masters> <slaveserver><name>slave1</name><hostname>node1</hostname><port>8081</port><username>cluster</username><password>cluster</password><master>N</master> </slaveserver>
-
修改从配置文件carte-config-8082.xml
<masters><slaveserver><name>master</name><hostname>master</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver> </masters> <report_to_masters>Y</report_to_masters> <slaveserver><name>slave2</name><hostname>node2</hostname><port>8082</port><username>cluster</username><password>cluster</password><master>N</master> </slaveserver>
-
-
分发整个kettle的安装目录,通过scp命令
-
分发/root/.kettle目录到node1、node2
-
启动相关进程,在master,node1,node2上分别执行
[root@master]# ./carte.sh master 8080 [root@node1]# ./carte.sh node1 8081 [root@node2]# ./carte.sh node2 8082
-
访问web页面
http://master:8080
案例:读取hive中的emp表,根据id进行排序,并将结果输出到hdfs上
注意:因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下

-
创建转换,编辑步骤,填好相关配置
直接使用trans1
-
创建子服务器,填写相关配置,跟集群上的配置相同


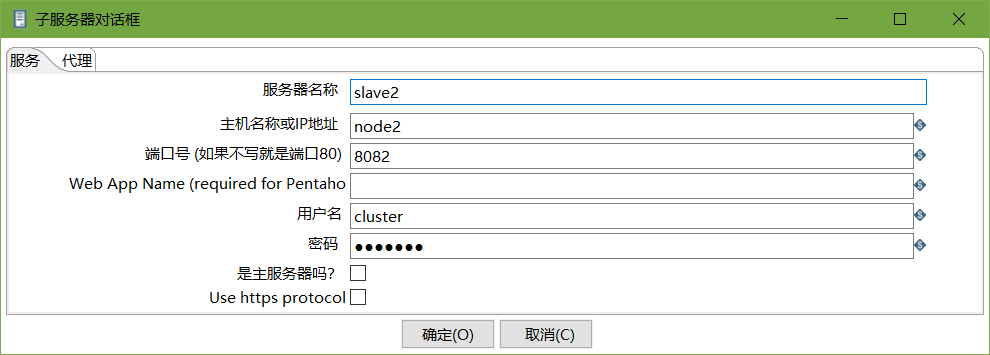
-
创建集群schema,选中上一步的几个服务器

-
对于要在集群上执行的步骤,右键选择集群,选中上一步创建的集群schema
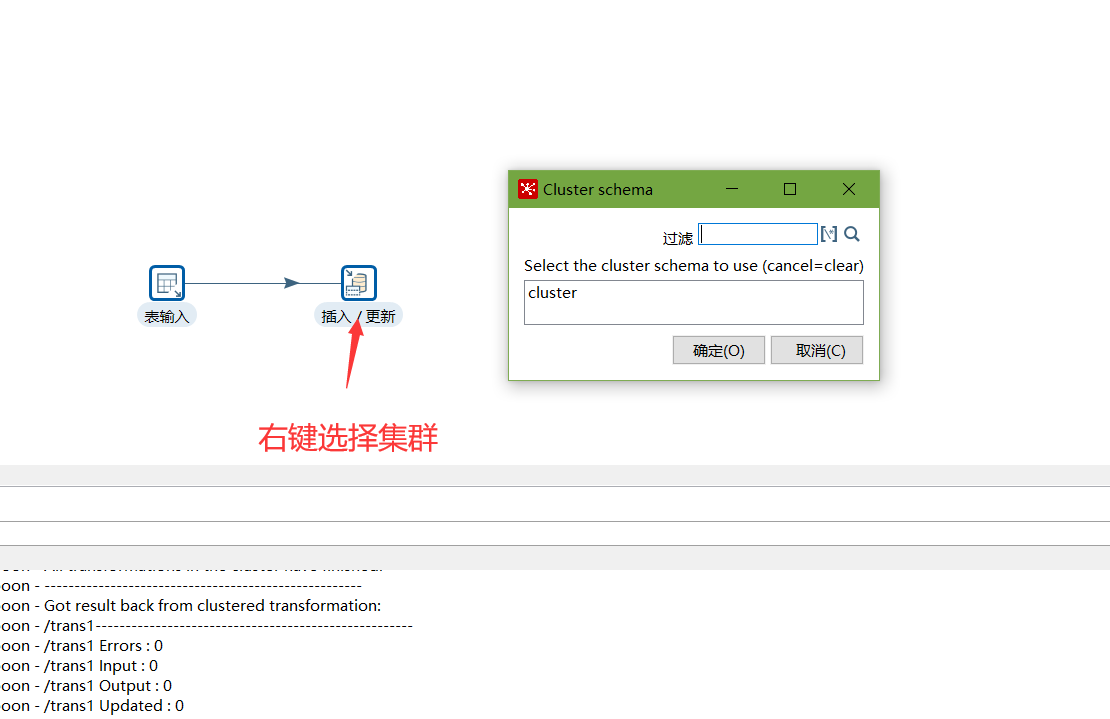
-
创建Run Configuration,选择集群模式

-
直接运行,选择集群模式运行
五、调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。

参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。
相关文章:
Kettle的安装及简单使用
Kettle的安装及简单使用一、kettle概述二、kettle安装部署和使用Windows下安装案例1:MySQL to MySQL案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据案例3:将hive表的数据输出到hdfs案例4:读取hdfs文件并将…...

Golang | Leetcode Golang题解之第420题强密码检验器
题目: 题解: func strongPasswordChecker(password string) int {hasLower, hasUpper, hasDigit : 0, 0, 0for _, ch : range password {if unicode.IsLower(ch) {hasLower 1} else if unicode.IsUpper(ch) {hasUpper 1} else if unicode.IsDigit(ch)…...

面试金典题3
URL化。编写一种方法,将字符串中的空格全部替换为%20。假定该字符串尾部有足够的空间存放新增字符,并且知道字符串的“真实”长度。 示例 1: 输入:"Mr John Smith ", 13 输出:"Mr%20John%20Smith&…...

FFmpeg开发笔记(五十六)使用Media3的Exoplayer播放网络视频
Android早期的MediaPlayer控件对于网络视频的兼容性很差,所以后来单独推出了Exoplayer库增强支持网络视频,在《Android Studio开发实战:从零基础到App上线(第3版)》一书第14章的“14.3.3 新型播放器ExoPlayer”就详细介绍了Exoplayer库的详细…...

Python使用总结之py-docx将word文件中的图片保存,并将内容返回
Python使用总结之py-docx将word文件中的图片保存,并将内容返回 使用py-docx读取word文档的内容,其中包含标题、文本和图片等信息。该方法将标题和内容返回,并将文件中的图片保存到指定的文件夹中。 实现步骤 加载文件内容读取文件的段落对文…...

Radware 报告 Web DDoS 攻击活动
新一代 HTTPS 洪水攻击的频率和强度急剧增加,攻击者引入的复杂程度也在迅速提高。2024 年上半年,Web 分布式拒绝服务 (DDoS) 攻击的频率和强度显著增加。其中很大一部分活动可以归因于受政治紧张局势驱使的黑客活动分子。 众所周知,当今的黑…...

OpenCV运动分析和目标跟踪(2)累积操作函数accumulateSquare()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将源图像的平方加到累积器图像中。 该函数将输入图像 src 或其选定区域提升到2的幂次方,然后加到累积器 dst 中: dst ( …...

PCIe进阶之TL:Common Packet Header Fields TLPs with Data Payloads Rules
1 Transaction Layer Protocol - Packet Definition TLP有四种事务类型:Memory、I/O、Configuration 和 Messages,两种地址格式:32bit 和 64bit。 构成 TLP 时,所有标记为 Reserved 的字段(有时缩写为 R)都必须全为0。接收者Rx必须忽略此字段中的值,PCIe Switch 必须对…...

Linux之实战命令01:xargs应用实例(三十五)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...

Redisson实现分布式锁(看门狗机制)
目录 可重入锁: 锁重试和看门狗机制: 主从一致性: 首先引入依赖,配置好信息 3.使用Redisson的分布式锁 可重入锁: 可重入锁实现是通过redsi中的hash实现的,key依旧是业务名称加id,然后第一个…...

记录一次显卡驱动安装
1. 驱动安装 1.1. 查看适合的版本 apt-get update ubuntu-drivers devices输出结果: 1.2. 安装合适的驱动版本 根据上面输出的内容 apt-get install nvidia-driver-545完成后重启 reboot查看新的驱动 nvidia-smi2. 安装/升级cuda 在nvidia-smi中显示的CUDA…...

nginx的作用是什么
Nginx是一个轻量级、高性能的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,它的作用广泛且重要。以下是Nginx的主要作用: 1. 作为Web服务器 高效处理静态文件:Nginx对静态文件(如HTML、图片…...

【全网最全】2024年华为杯研赛B题成品论文获取入口(后续会更新)
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片,那是获取资料的入口! 点击链接加入【2024华为杯研赛资料汇总】:https://qm.qq.com/q/hMgWngXvcQhttps://qm.qq.com/q/hMgWngXvcQ你是否在寻找数学建模比赛的突破点&a…...

计算机网络(八) —— Udp协议
目录 一,再谈端口号 1.1 端口号 1.2 netsta命令 二,UDP协议 2.1 关于UDP 2.2 Udp协议格式 2.3 Udp协议特点 2.4 Udp的缓冲区 一,再谈端口号 http协议本质是“请求 - 响应”形式的协议,但是应用层需要先将数据交给传输层&…...

【Linux篇】TCP/IP协议(笔记)
目录 一、TCP/IP协议族体系结构 1. 数据链路层 (1)介绍 (2)常用协议 ① ARP协议(Address Resolve Protocol,地址解析协议) ② RARP协议(Reverse Address Resolve Protocol&…...

std::pair和std::tuple
提示:文章 文章目录 前言一、背景二、 2.1 2.2 总结 前言 前期疑问: 本文目标: 一、背景 最近 std::pair和std::tuple 二、用法 1.1 创建 看代码规范,提到:通过std::pair 和std::tuple ,函数可以同…...
)
Access denied for user ‘root‘@‘114.254.154.110‘ (using password: YES)
navicat 连接远程服务器报错 1045 - Access denied for user root114.254.154.110 (using password: YES)报错解释: 这个错误表示客户端从IP地址114.254.154.110尝试以用户’root’身份连接到MySQL服务器时,被拒绝访问。原因可能是密码错误、用户’roo…...

深度学习03-神经网络01-什么是神经网络?
神经网络的基本概念 人工神经网络(Artificial Neural Network,ANN): 是一种模仿生物神经网络的计算模型。由多个神经元(或称为节点)组成,这些节点通过不同的连接来传递信息。 每个神经元可以接…...

Redisson 分布式锁的使用详解
一、分布式锁的概述 1.1 分布式锁的背景 在单机系统中,Java 提供了 synchronized 和 Lock 等锁机制来确保并发情况下的线程安全。然而,在分布式系统中,多个服务实例运行在不同的物理或虚拟机上,无法直接使用这些本地的锁机制来控…...

计算机网络:物理层 --- 基本概念、编码与调制
目录 一. 物理层的基本概念 二. 数据通信系统的模型 三. 编码 3.1 基本概念 3.2 不归零制编码 3.3 归零制编码 3.4 曼切斯特编码 3.5 差分曼切斯特编码 编辑 四. 调制 4.1 调幅 4.2 调频 4.3 调相 4.4 混合调制 今天我们讲的是物理…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...

OpenTK 3.3.3实现3D旋转立方体:C# OpenGL入门实战
1. 为什么一个旋转立方体是3D图形编程真正的“Hello World” 很多人第一次接触OpenGL或现代图形API时,总想直接上手做粒子系统、PBR渲染或者实时阴影——结果卡在顶点缓冲对象(VBO)绑定失败、着色器编译报错、甚至窗口根本没显示出来。我带过…...