【机器学习】--- 决策树与随机森林

文章目录
- 决策树与随机森林的改进:全面解析与深度优化
- 目录
- 1. 决策树的基本原理
- 2. 决策树的缺陷及改进方法
- 2.1 剪枝技术
- 2.2 树的深度控制
- 2.3 特征选择的优化
- 3. 随机森林的基本原理
- 4. 随机森林的缺陷及改进方法
- 4.1 特征重要性改进
- 4.2 树的集成方法优化
- 4.3 随机森林的并行化处理
- 4.4 使用极端随机树(Extra Trees)
- 5. 代码示例:如何在实践中使用这些改进
- 5.1 决策树的剪枝与优化
- 5.2 随机森林的改进与并行化实现
- 6. 总结
决策树与随机森林的改进:全面解析与深度优化
决策树和随机森林是机器学习中的经典算法,因其易于理解和使用广泛而备受关注。尽管如此,随着数据集规模和复杂性增加,这些算法的性能可能会遇到瓶颈。因此,研究决策树与随机森林的改进成为了机器学习领域的一个热点话题。本博客将详细探讨决策树与随机森林的基本原理、其存在的问题以及如何通过多种改进方法提升其性能。
目录
1. 决策树的基本原理
决策树是一种贪心算法,通过递归地分裂数据集构建树形结构。其主要目标是通过最大化信息增益或最小化基尼系数等指标,在每一步找到最佳的特征进行分割。
决策树的构建步骤包括:
- 选择最佳的特征和阈值
- 递归地将数据集划分为子集
- 构建叶节点,存储预测的类别或值
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据集
data = load_iris()
X, y = data.data, data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树分类器
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)# 评估模型
accuracy = tree.score(X_test, y_test)
print(f"决策树准确率: {accuracy:.4f}")
在上面的代码中,我们使用了 sklearn 的 DecisionTreeClassifier 来训练决策树,并对其进行简单的性能评估。
2. 决策树的缺陷及改进方法
尽管决策树在许多情况下表现良好,但它存在一些问题,如过拟合、对噪声数据敏感以及对训练集的极端依赖。这些问题可以通过以下几种方式改进:
2.1 剪枝技术
决策树容易陷入过拟合的困境,尤其是在构建过于复杂的树结构时。剪枝是一种常见的解决方案,分为预剪枝和后剪枝:
- 预剪枝:在构建树的过程中设定限制条件,如最大深度、最小样本数等,提前终止树的生长。
- 后剪枝:在树构建完成后,通过回溯移除冗余节点,从而简化树结构。
# 设置决策树的最大深度为3
pruned_tree = DecisionTreeClassifier(max_depth=3)
pruned_tree.fit(X_train, y_train)# 评估模型
pruned_accuracy = pruned_tree.score(X_test, y_test)
print(f"剪枝后的决策树准确率: {pruned_accuracy:.4f}")
2.2 树的深度控制
树的深度过大会导致过拟合,而过小则会导致欠拟合。因此,设置合适的最大深度是一个非常重要的参数调优步骤。
# 使用网格搜索进行最大深度调参
from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth': [3, 5, 10, 20, None]}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)print(f"最佳深度: {grid_search.best_params_}")
2.3 特征选择的优化
传统的决策树使用信息增益或基尼系数来选择特征,但在某些数据集上,这些标准可能并不理想。可以考虑引入新的特征选择标准,比如均方误差(MSE)或基于正则化的方法。
# 基于均方误差的决策树回归模型
from sklearn.tree import DecisionTreeRegressorregressor = DecisionTreeRegressor(criterion='mse')
regressor.fit(X_train, y_train)
3. 随机森林的基本原理
随机森林是一种集成学习方法,通过生成多个决策树并结合它们的预测结果来提高模型的稳定性和准确性。它通过引入随机性(随机特征选择和数据子采样)来减少过拟合的风险。
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器
forest = RandomForestClassifier(n_estimators=100)
forest.fit(X_train, y_train)# 评估随机森林模型
forest_accuracy = forest.score(X_test, y_test)
print(f"随机森林准确率: {forest_accuracy:.4f}")
4. 随机森林的缺陷及改进方法
尽管随机森林具有许多优点,但它也有一些缺点,如计算开销较大、特征重要性计算偏差等。以下是一些改进方法。
4.1 特征重要性改进
随机森林中的特征重要性通常基于每个特征在决策树中的分裂贡献。但这种方法容易偏向高基数特征。可以通过正则化方法或基于模型输出的特征重要性计算进行改进。
# 提取特征重要性
importances = forest.feature_importances_
for i, importance in enumerate(importances):print(f"特征 {i}: 重要性 {importance:.4f}")
4.2 树的集成方法优化
除了随机森林,还可以采用更复杂的集成方法,如极端梯度提升(XGBoost)或LightGBM,它们通过优化决策树的构建过程,提高了模型的性能。
from xgboost import XGBClassifier# 使用XGBoost训练模型
xgb = XGBClassifier(n_estimators=100)
xgb.fit(X_train, y_train)# 评估XGBoost模型
xgb_accuracy = xgb.score(X_test, y_test)
print(f"XGBoost准确率: {xgb_accuracy:.4f}")
4.3 随机森林的并行化处理
随机森林的另一个问题是其计算量较大。通过并行化处理,可以加速模型的训练过程。n_jobs 参数可以控制并行化的线程数。
# 并行化的随机森林
parallel_forest = RandomForestClassifier(n_estimators=100, n_jobs=-1)
parallel_forest.fit(X_train, y_train)
4.4 使用极端随机树(Extra Trees)
极端随机树(Extra Trees)是一种与随机森林类似的集成方法,不同之处在于它在选择分割点时使用完全随机的方式,从而进一步提高模型的泛化能力。
from sklearn.ensemble import ExtraTreesClassifier# 创建极端随机树分类器
extra_trees = ExtraTreesClassifier(n_estimators=100)
extra_trees.fit(X_train, y_train)# 评估极端随机树模型
extra_trees_accuracy = extra_trees.score(X_test, y_test)
print(f"极端随机树准确率: {extra_trees_accuracy:.4f}")
5. 代码示例:如何在实践中使用这些改进
5.1 决策树的剪枝与优化
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine# 加载数据集
data = load_wine()
X, y = data.data, data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建带剪枝的决策树
tree = DecisionTreeClassifier(max_depth=5, min_samples_split=10, min_samples_leaf=5)
tree.fit(X_train, y_train)# 评估模型
accuracy = tree.score(X_test, y_test)
print(f"剪枝后的决策树准确率: {accuracy:.4f}")
5.2 随机森林的改进与并行化实现
from sklearn.ensemble import RandomForestClassifier# 创建并行化的随机森林分类器
parallel_forest = RandomForestClassifier(n_estimators=200, max_depth=10, n_jobs=-1, random_state=42)
parallel_forest.fit(X_train, y_train)# 评估并行化随机森林模型
accuracy = parallel_forest.score(X_test, y_test)
print(f"并行化随机森林准确率: {accuracy:.4f}")
6. 总结
决策树和随机森林作为经典的机器学习算法,已经在众多领域得到了广泛应用。然而,它们的性能在面对复杂的数据时可能会出现瓶颈。通过剪枝、树深度控制、优化特征选择等方法,我们可以提高决策树的泛化能力。同时,通过特征重要性改进、极端随机树的引入和并行化处理,可以在提升随机森林性能的同时减少计算资源的消耗。
相关文章:
【机器学习】--- 决策树与随机森林
文章目录 决策树与随机森林的改进:全面解析与深度优化目录1. 决策树的基本原理2. 决策树的缺陷及改进方法2.1 剪枝技术2.2 树的深度控制2.3 特征选择的优化 3. 随机森林的基本原理4. 随机森林的缺陷及改进方法4.1 特征重要性改进4.2 树的集成方法优化4.3 随机森林的…...
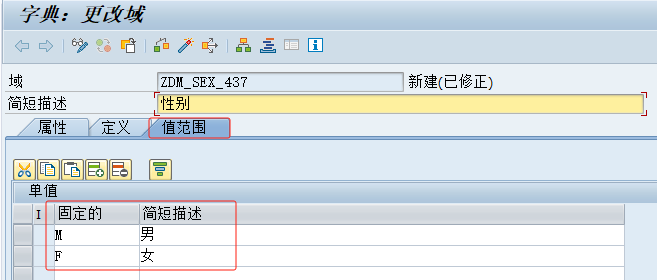
[SAP ABAP] 创建域
我们可以使用事务码SE11创建域 输入要创建的域的名称,然后点击创建 输入简短描述,选择数据类型和输入字符数 激活并保存域,创建的域才能够生效 补充扩展练习 创建一个有关"性别"基本信息的域...

STM32 通过 SPI 驱动 W25Q128
目录 一、STM32 SPI 框图1、通讯引脚2、时钟控制3、数据控制逻辑4、整体控制逻辑5、主模式收发流程及事件说明如下: 二、程序编写1、SPI 初始化2、W25Q128 驱动代码2.1 读写厂商 ID 和设备 ID2.2 读数据2.3 写使能/写禁止2.4 读/写状态寄存器2.5 擦除扇区2.6 擦除整…...

C#进阶-基于雪花算法的订单号设计与实现
在现代电商系统和分布式系统中,高效地生成全局唯一的订单号是一个关键需求。订单号不仅需要唯一性,还需要具备一定的趋势递增性,以满足数据库索引和排序的需求。本文将介绍如何在C#中使用雪花算法(Snowflake)设计和实现…...

低版本SqlSugar的where条件中使用可空类型报语法错误
SQLServer数据表中有两列可空列,均为数值类型,同时在数据库中录入测试数据,Age和Height列均部分有值。 使用SqlSugar的DbFirst功能生成数据库表类,其中Age、Height属性均为可空类型。 开始使用的SqlSugar版本较低&…...

跨游戏引擎的H5渲染解决方案(腾讯)
本文是腾讯的一篇H5 跨引擎解决方案的精炼。 介绍 本文通过实现基于精简版的HTML5(HyperText Mark Language 5)来屏蔽不同引擎,平台底层的差异。 好处: 采用H5的开发方式,可以将开发和运营分离,运营部门自…...

docker构建java镜像,运行镜像出现日志 no main manifest attribute, in /xxx.jar
背景 本文主要是一个随笔,记录一下出现"no main manifest attribute"的解决办法 问题原因 主要是近期在构建一个镜像,在镜像构建成功后,运行一直提示"no main manifest attribute",当时还在想,是不是Dockerfile写错了,后来仔细检查了一下,发现是…...

react + antDesignPro 企业微信扫码登录
效果 实现步骤 1、项目中document.ejs文件引入企微js链接 注意:技术栈是使用的react antDesignPro,不同的技术栈有不同的入口文件(如vue在html文件引入) <script src"https://wwcdn.weixin.qq.com/node/wework/wwopen/j…...

Go-知识-定时器
Go-知识-定时器 1. 介绍2. Timer使用场景2.1 设定超时时间2.2 延迟执行某个方法 3. Timer 对外接口3.1 创建定时器3.2 停止定时器3.3 重置定时器3.4 After3.5 AfterFunc 4. Timer 的实现原理4.1 Timer数据结构4.1.1 Timer4.1.2 runtimeTimer 4.2 Timer 实现原理4.2.1 创建Timer…...

【alluxio编译报错】Some files do not have the expected license header
Some files do not have the expected license header 快捷导航 在开始解决问题之前,大家可以通过下面的导航快速找到相关资源啦!💡👇 快捷导航链接地址备注相关文档-ambaribigtop自定义组件集成https://blog.csdn.net/TTBIGDA…...

基于SpringBoot+Vue的商城积分系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 精品专栏:Java精选实战项目源码、Python精…...

docker-compose up 报错:KeyError: ‘ContainerConfig‘
使用命令查看所有容器: docker ps -a 找到有异常的容器删除 docker rm {容器id} 后续发现还是会出现这种情况,尝试使用更高版本的docker-compose后解决...

股票行情接口,量化金融交易在未来会被广泛应用吗
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

[SDX35+WCN6856]SDX35 开启class/gpio子系统配置操作说明
SDX35 SDX35介绍 SDX35设备是一种多模调制解调器芯片,支持 4G/5G sub-6 技术。它是一个4nm芯片专为实现卓越的性能和能效而设计。它包括一个 1.9 GHz Cortex-A7 应用处理器。 SDX35主要特性 ■ 3GPP Rel. 17 with 5G Reduced Capability (RedCap) support. Backward compati…...

react:React Hook函数
使用规则 只能在组件中或者其他自定义的Hook函数中调用 只能在组件的顶层调用,不能嵌套在if、for、 其他函数中 基础Hook 函数 useState useState是一个hook函数,它允许我们向组件中添加一个状态变量,从而控制影响组件的渲染结果 示例1…...

算法学习2
学习目录 一.插入排序 一.插入排序 从数组的第一个元素开始,当前元素与其前一个元素进行比较; 大于(或小于时)将其进行交换,即当前元素替换到前一位; 再将该元素与替换后位置的前一个元素进行交换…...

vue循环渲染动态展示内容案例(“更多”按钮功能)
当我们在网页浏览时,常常会有以下情况:要展示的内容太多,但展示空间有限,比如我们要在页面的一部分空间中展示较多的内容放不下,通常会有两种解决方式:分页,“更多”按钮。 今天我们的案例用于…...

好用的工具网址
代码类: 1,json解析:JSON在线解析及格式化验证 - JSON.cn 2.传参转化编码 在线url网址编码、解码器-BeJSON.com 日常: 1.莆田医院查询:滚蛋吧!莆田系...

【Temporal】方法规范
在workflow或者childWorkflow的方法代码中,不能使用golang的一些库方法,比如sleep,go协程等,必须使用其对应的封装方法,比如对应关系如下: time.Sleep -> workflow.Sleepgo xx -> workflow.Go(xx) 这…...

Python实现图形学曲线和曲面的Bezier曲线算法
目录 使用Python实现图形学曲线和曲面的Bezier曲线算法引言Bezier曲线的数学原理1. Bezier曲线定义2. Bezier曲线的递归形式 Python实现Bezier曲线算法1. 代码实现 代码详解使用示例Bezier曲线的特点Bezier曲面的扩展Bezier曲面类实现 总结 使用Python实现图形学曲线和曲面的Be…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

结肠“瑞士卷”制片法
在肠道病理研究中,如何完整保留小鼠结肠的全层结构、同时避免人为损伤,一直是实验操作的难点。本文分享一套改良版“瑞士卷”制片技术,无需剖开肠管、无需机械顶压,即可获得高质量的全结肠切片,特别适合炎症、隐窝异常…...