Qlib使用
Qlib https://github.com/microsoft/qlib
将csv文件转化为Qlib的数据格式:https://qlib.readthedocs.io/en/latest/component/data.html#converting-csv-format-into-qlib-format
注意每支股票都要保存成单独一个文档,且文档名字与股票代号一致。
其中factor 也就是 https://crm.htsc.com.cn/doc/2020/10750101/d287ebf2-7f3f-4382-bf3f-cfabd4b90161.pdf中提到的复权。
youbube 教程 https://www.youtube.com/watch?v=z6a4mQTkMwg
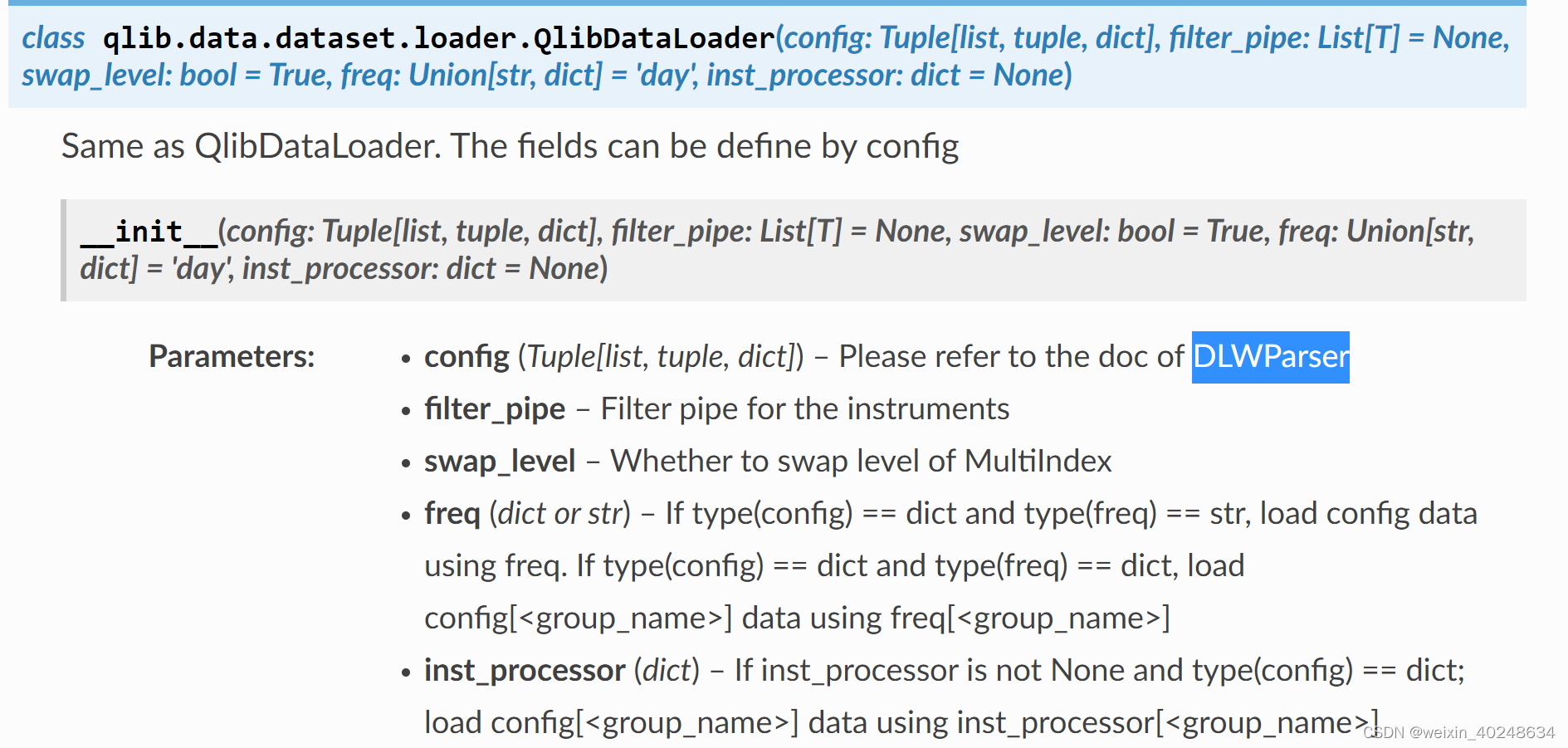
from qlib.data.dataset.loader import QlibDataLoaderMACD_EXP = '(EMA($close, 12) - EMA($close, 26))/$close - EMA((EMA($close, 12) - EMA($close, 26))/$close, 9)/$close'fields = [MACD_EXP,'$close'] # MACDnames = ['MACD','收盘价']labels = ['Ref($close, -2)/Ref($close, -1) - 1'] # labellabel_names = ['LABEL']data_loader_config = {"feature": (fields, names),"label": (labels, label_names)}data_loader = QlibDataLoader(config=data_loader_config)df = data_loader.load(instruments='all', start_time='2010-01-01', end_time='2017-12-31')print(df)
使用Qlib时候直接使用 Data Handler, 是上面 QlibDataLoader 的封装,所以Data Handler 也自然可以使用"label"的设置。
一个完整的例子:
from qlib.data.dataset import DatasetH
# 实例化Data Loader
market = 'sh000300' # 沪深300股票池代码,在instruments文件夹下有对应的sh000300.txt
close_ma = ['EMA($close, 10)', 'EMA($close, 30)'] # EMA($close, 10)表示计算close的10日指数加权均线
ma_names = ['EMA10', 'EMA30']
ret = ["Ref($close, -1)/$close-1"] # 下一日收益率, Ref($close, -1)表示下一日收盘价
ret_name = ['next_ret']
qdl_ma_gp = QlibDataLoader(config={'feature':(close_ma, ma_names), 'label': (ret, ret_name)}) # 实例化Data Handler
shared_processors = [DropnaProcessor()]
learn_processors = [CSZScoreNorm()]
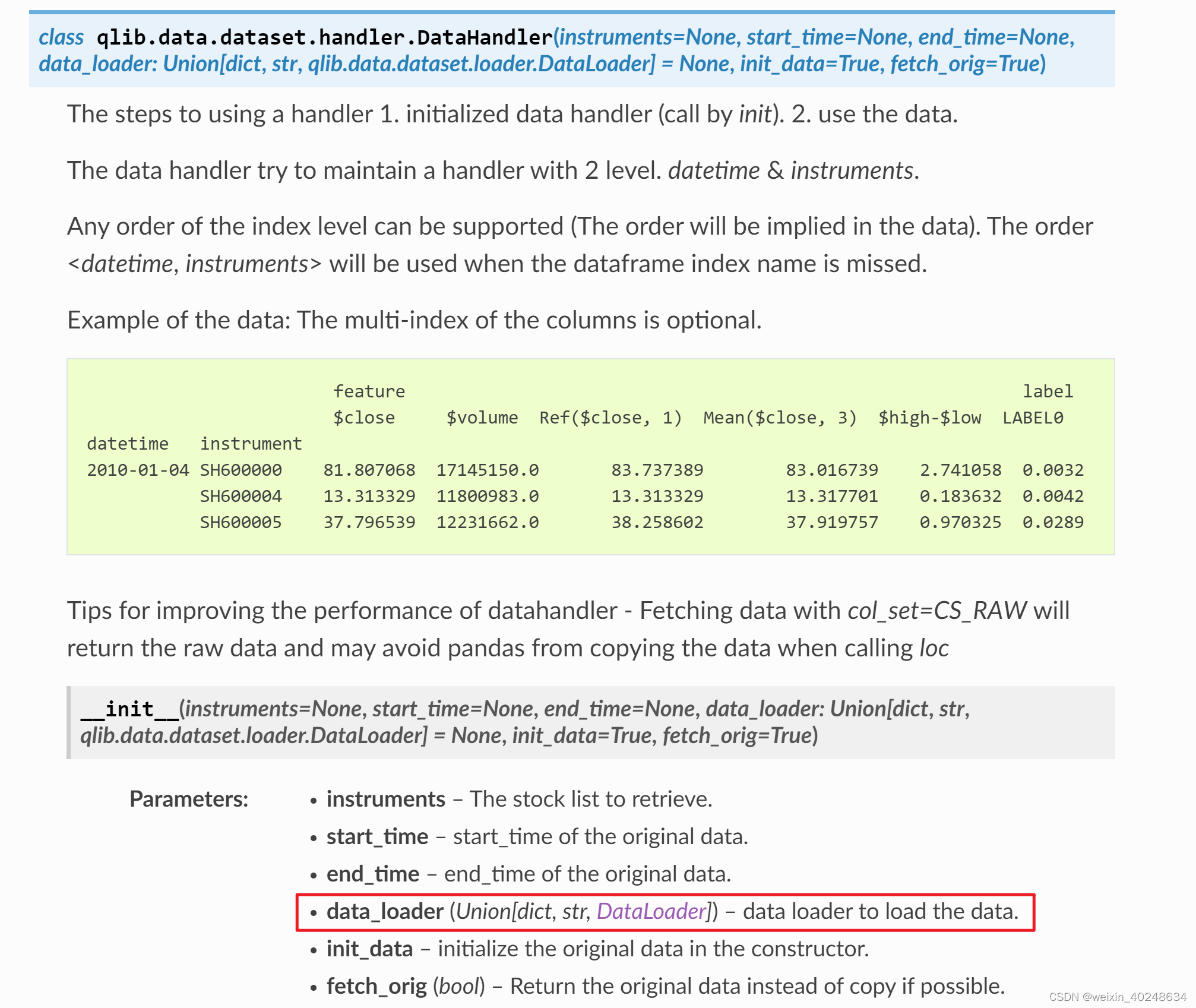
infer_processors = [ZScoreNorm(fit_start_time='20190101', fit_end_time='20211231')]dh_pr_test = DataHandlerLP(instruments='sh000300', start_time='20190101', end_time='20211231',process_type=DataHandlerLP.PTYPE_I, learn_processors=learn_processors,shared_processors=shared_processors,infer_processors=infer_processors,data_loader=qdl_ma_gp)ds = DatasetH(dh_pr_test, segments={"train": ('20190101', '20201231'), "test": ('20210101', '20211231')})
from qlib.data.dataset import DatasetH
from qlib.data.dataset.handler import DataHandlerLP

自定义 https://blog.csdn.net/qq_37373209/article/details/125224210
所以 最后其实是可以直接用 DatasetH 来设置的
Alpha360:
其data_loader 是指定了feature的,不可改变; 但是label 是可以从kwargs里边导入的。所以想要用自己的alpha 因子得从data_loader 开始写起,而不能直接使用这个类
class Alpha360(DataHandlerLP):def __init__(self,instruments="csi500",start_time=None,end_time=None,freq="day",infer_processors=_DEFAULT_INFER_PROCESSORS,learn_processors=_DEFAULT_LEARN_PROCESSORS,fit_start_time=None,fit_end_time=None,filter_pipe=None,inst_processor=None,**kwargs):infer_processors = check_transform_proc(infer_processors, fit_start_time, fit_end_time)learn_processors = check_transform_proc(learn_processors, fit_start_time, fit_end_time)data_loader = {"class": "QlibDataLoader","kwargs": {"config": {"feature": self.get_feature_config(), ## 这里是特征"label": kwargs.pop("label", self.get_label_config()), # 这里为标签},"filter_pipe": filter_pipe,"freq": freq,"inst_processor": inst_processor,},}super().__init__(instruments=instruments,start_time=start_time,end_time=end_time,data_loader=data_loader,learn_processors=learn_processors,infer_processors=infer_processors,**kwargs)def get_feature_config(): # 可以拿来直接使用# NOTE:# Alpha360 tries to provide a dataset with original price data# the original price data includes the prices and volume in the last 60 days.# To make it easier to learn models from this dataset, all the prices and volume# are normalized by the latest price and volume data ( dividing by $close, $volume)# So the latest normalized $close will be 1 (with name CLOSE0), the latest normalized $volume will be 1 (with name VOLUME0)# If further normalization are executed (e.g. centralization), CLOSE0 and VOLUME0 will be 0.fields = []names = []for i in range(59, 0, -1):fields += ["Ref($close, %d)/$close" % i]names += ["CLOSE%d" % i]fields += ["$close/$close"]names += ["CLOSE0"]for i in range(59, 0, -1):fields += ["Ref($open, %d)/$close" % i]names += ["OPEN%d" % i]fields += ["$open/$close"]names += ["OPEN0"]for i in range(59, 0, -1):fields += ["Ref($high, %d)/$close" % i]names += ["HIGH%d" % i]fields += ["$high/$close"]names += ["HIGH0"]for i in range(59, 0, -1):fields += ["Ref($low, %d)/$close" % i]names += ["LOW%d" % i]fields += ["$low/$close"]names += ["LOW0"]for i in range(59, 0, -1):fields += ["Ref($vwap, %d)/$close" % i]names += ["VWAP%d" % i]fields += ["$vwap/$close"]names += ["VWAP0"]for i in range(59, 0, -1):fields += ["Ref($volume, %d)/($volume+1e-12)" % i]names += ["VOLUME%d" % i]fields += ["$volume/($volume+1e-12)"]names += ["VOLUME0"]return fields, names
使用Alpha360的代码为:
from qlib.data.dataset import DatasetH
from qlib.data.dataset.handler import DataHandlerLPstart_time = datetime.datetime.strptime(args.train_start_date, '%Y-%m-%d')
end_time = datetime.datetime.strptime(args.test_end_date, '%Y-%m-%d')
train_end_time = datetime.datetime.strptime(args.train_end_date, '%Y-%m-%d')hanlder = {'class': 'Alpha360', 'module_path': 'qlib.contrib.data.handler', 'kwargs': {'start_time': start_time, 'end_time': end_time, 'fit_start_time': start_time, 'fit_end_time': train_end_time, 'instruments': args.data_set,'infer_processors': [{'class': 'RobustZScoreNorm', 'kwargs': {'fields_group': 'feature', 'clip_outlier': True}}, {'class': 'Fillna', 'kwargs': {'fields_group': 'feature'}}],'learn_processors': [{'class': 'DropnaLabel'}, {'class': 'CSRankNorm', 'kwargs': {'fields_group': 'label'}}],'label': ['Ref($close, -1) / $close - 1']}}
segments = { 'train': (args.train_start_date, args.train_end_date), 'valid': (args.valid_start_date, args.valid_end_date), 'test': (args.test_start_date, args.test_end_date)}
dataset = DatasetH(hanlder,segments)df_train, df_valid, df_test = dataset.prepare( ["train", "valid", "test"], col_set=["feature", "label"], data_key=DataHandlerLP.DK_L,)
>> x = np.arange(10) # x例子
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>> np.roll(x, 2) # axis为None,则会先进行扁平化,然后再向水平滚动2个位置
array([8, 9, 0, 1, 2, 3, 4, 5, 6, 7])https://blog.csdn.net/qq_37373209/article/details/125224210
相关文章:
Qlib使用
Qlib https://github.com/microsoft/qlib 将csv文件转化为Qlib的数据格式:https://qlib.readthedocs.io/en/latest/component/data.html#converting-csv-format-into-qlib-format 注意每支股票都要保存成单独一个文档,且文档名字与股票代号一致。 其中f…...
TL-WDR7660 httpProcDataSrv任意代码执行漏洞复现分析
01 漏洞简述 2023年1月31日,CNVD公开了一个由国内安全研究员提交的TL-WDR7660 httpProcDataSrv任意代码执行漏洞,编号为CNVD-2023-05404,同时公开了漏洞利用详情,poc代码链接为https://github.com/fishykz/TP-POC。从poc代码详情…...
基于DDS的SOA测试方案实现
随着以太网技术在车载网络中的应用,各种基于以太网的中间件也相继被应用在车内,如果对车载网络有过相关了解的小伙伴,对于作为中间件之一的DDS(数据分发服务Data Distribution Service)可能并不陌生;若没有…...

LibTorch中Windows系统环境配置及CUDA不可用问题解决
前言:本文对在Windows系统上进行LibTorch开发环境配置及相关问题解决做一个较为详细的记录,以便后续查询使用。 使用环境版本: Windows 11 Visual Studio 2022 CUDA 12.0 LibTorch 1.13.1_cu11.7 目录一、LibTorch简介二、LibTorch下载安装三…...
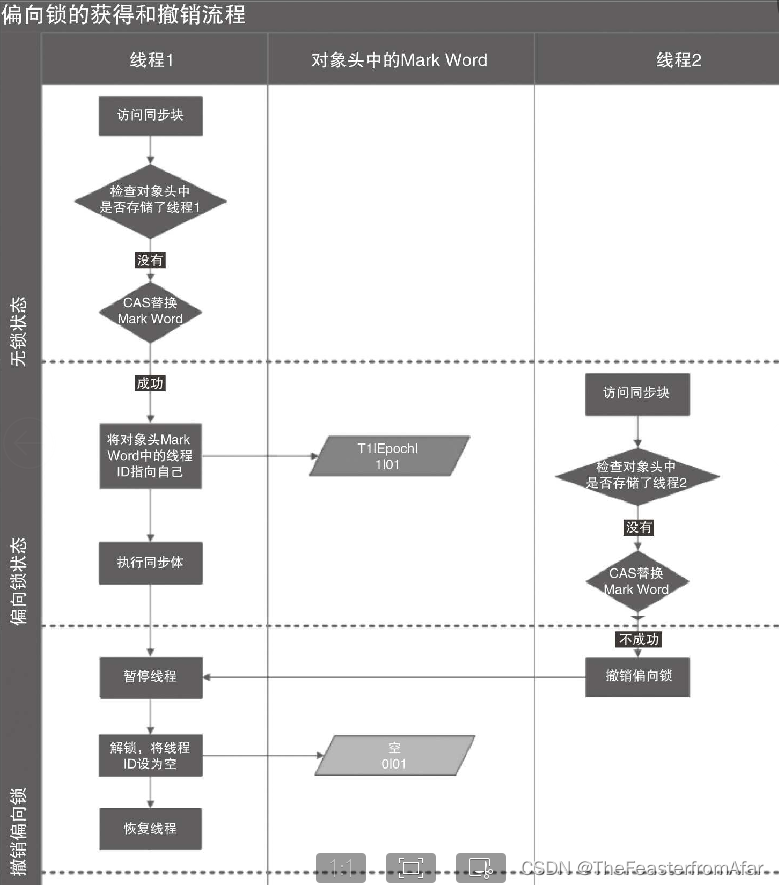
Java并发编程实战二
线程间的通讯方式 1.volitate(缓存一致性协议),synchronize,lock(都保证可见性) 2.wait.notify,await(),signal(前两个是Object,后两个属于lock) 3.管道输入、输出流 (示例代码:PipeInOut.java)(目前几乎没人使用) 管道输入/输…...
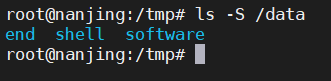
Linux中最基本的命令ls的用法有哪些?
Linux是一种流行的操作系统,被广泛应用于服务器和个人电脑。Linux命令行界面是使用Linux操作系统的关键。其中一个最基本的命令是"ls"命令,该命令用于列出指定目录中的所有文件和子目录。在这篇文章中,我们将探讨ls命令及其各种用途…...

第 100002(十万零二)个素数是多少?
题目描述 素数就是不能再进行等分的整数。比如7,11。而 9 不是素数,因为它可以平分为 3 等份。一般认为最小的素数是2,接着是 3,5,... 请问,第 100002(十万零二)个素数是多少? 请注意࿱…...

Lua迭代器
Lua迭代器 迭代器(iterator)是一种对象,它能够用来遍历标准模板库容器中的部分或全部元素,每个迭代器对象代表容器中的确定的地址。 在 Lua 中迭代器是一种支持指针类型的结构,它可以遍历集合的每一个元素。 泛型 f…...

同步与互斥之信号量
目录 1、信号量用于线程的互斥 验证 2、信号量用于线程的同步 验证 3、无名信号量用于进程间互斥 代码一 代码二 验证 4、有名信号量 用于进程间同步和互斥 验证 信号量广泛用于进程或线程间的同步和互斥,信号量本质上是一个非负的整数计数器,它…...

如何当个优秀的文档工程师?从 TC China 看技术文档工程师的自我修养
本文系 NebulaGraph Community Academic 技术文档工程师 Abby 的参会观感,讲述了她在中国技术传播大会分享的收获以及感悟。 据说,技术内容领域、传播领域的专家和决策者们会在中国技术传播大会「tcworld China 2022」大会上分享心得。作为一名技术文档工…...

如何学习k8s
学习Kubernetes可以遵循以下步骤: 了解Kubernetes的基本概念和架构。学习Kubernetes前,需要了解它的基本概念和组成部分,包括Pod、Service、ReplicaSet、Deployment、Namespace等等,同时也需要了解Kubernetes的整体架构和工作原理…...
)
【SSM】MyBatis(十.动态sql)
文章目录1.if2.where3.trim4.set5. choose when otherwise6.foreach6.1 批量删除6.2 批量增加7.sql1.if <select id"selectByMultiCondition" resultType"Car">select * from t_car where 1 1<if test"brand ! null and brand ! ">…...
最近很多人都在说 “前端已死”,讲讲我的看法
转自 : 掘金 作者 : Ethan_Zhou 现状 我记得去年脉脉的论调还都是 客户端已死,前后端还都是一片祥和,有秀工资的,有咨询客户端转前端的,怎么最近打开脉脉一看,风向变了? 随便刷几下,出来的信息…...

大家好,我是火旺技术
大家好,我是火旺技术 在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用。这其中,家乡特色推荐的网络应用已经成为外国家乡推荐系统的一种很普遍的方式。不过,在国内,管理网站可能还处于起步阶段。 …...
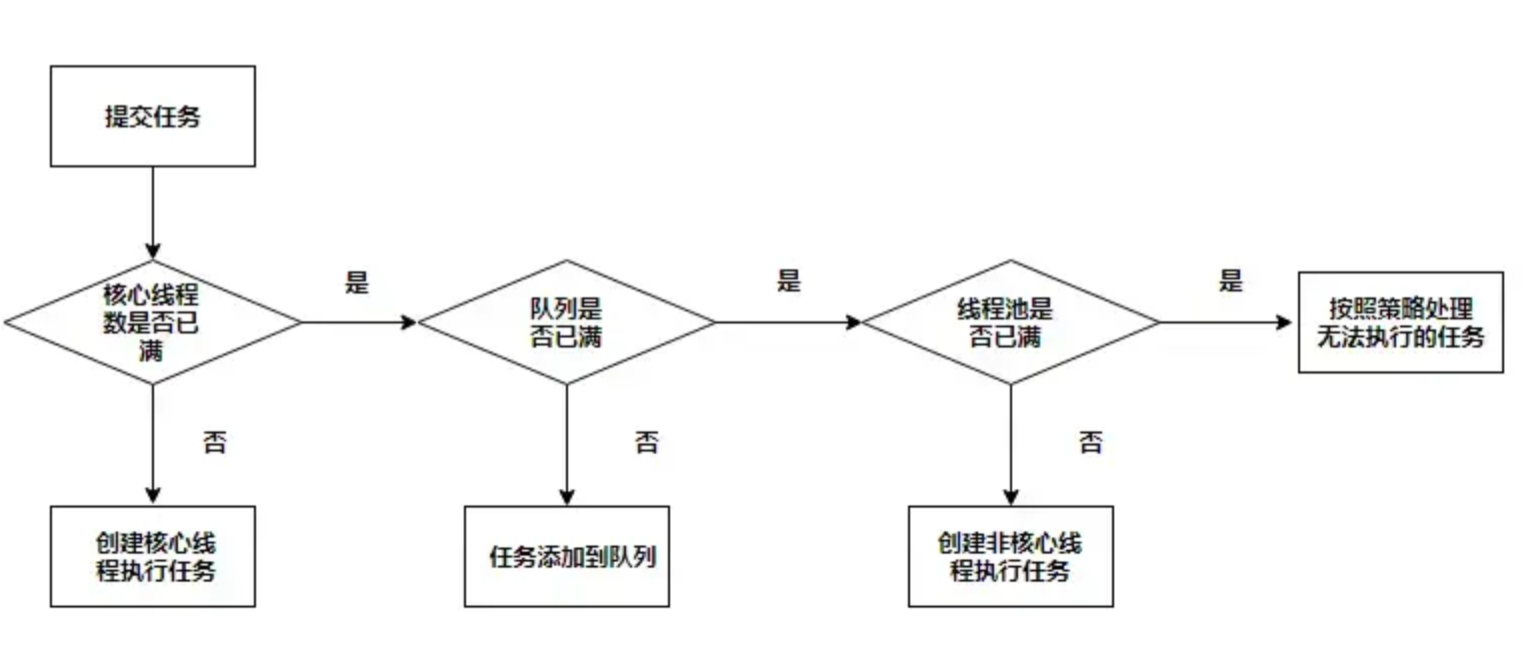
【Java并发编程系列】全方位理解多线程几乎包含线程的所有操作哦
文章目录一、概述及目录二、实现多线程的方式2.1 继承Tread类,重写run方法。start方法2.2 实现Runnable方法,并实现run接口方法2.3 实现Callable接口重写call方法,Feature.get()获取返回值三、线程的执行流程3.1 执行流程3.2 start方法和 run…...

天宝S6测量机器人/天宝S6全站仪参数/教程/Trimble 天宝全站仪
TRIMBLE DR PLUS技术 Trimble DR Plus™距离测量技术实现更大范围的直接反射测量,不使用棱镜也能进行长距离测量。难以抵达或不安全的测 量目标,对Trimble S6来说不再是问题。Trimble DR Plus结合 了MagDrive™磁驱伺服技术,使测量的快捷和…...

c++基础知识汇总
目录 1、基础 1.2 注释 1.3 变量 1.4 常量 1.5 关键字 1.6 标识符命名规则 2 数据类型 2.1 整型 2.2 sizeof关键字 2.3 实型(浮点型) 2.4 字符型 2.5 转义字符 2.6 字符串型 2.7 布尔类型 bool 2.8 数据的输入 1、基础 1.2 注释 作用&a…...
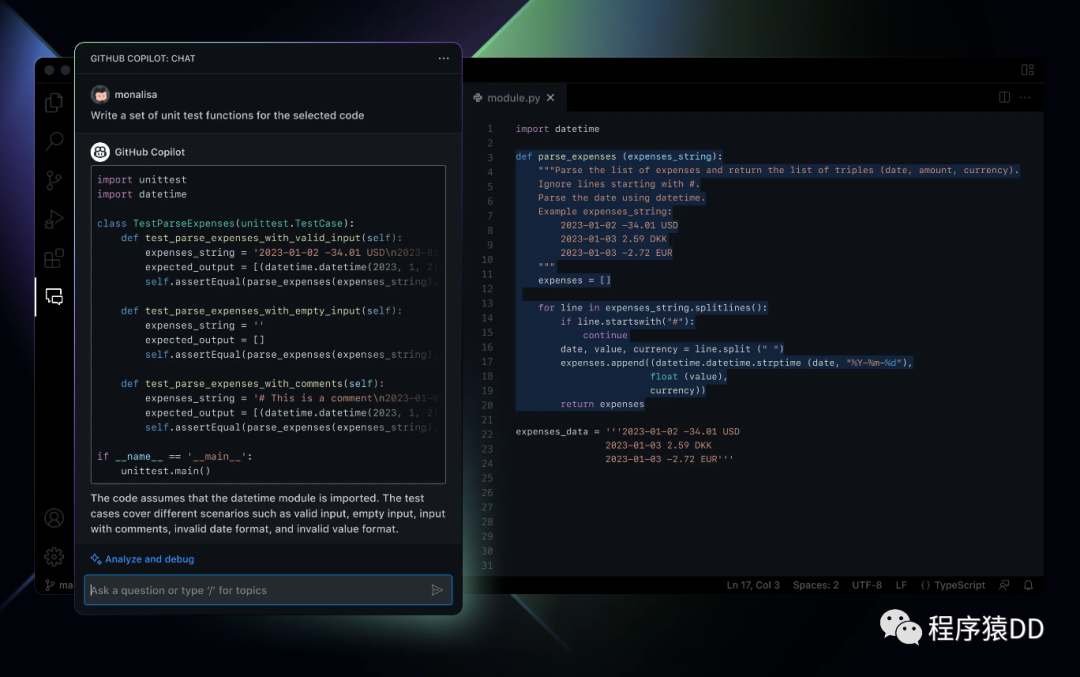
重磅!基于GPT-4的全新智能编程助手 GitHub Copilot X 来了!
GitHub Copilot相信大家一定不陌生了,强大的智能代码补全功能一度让媒体直呼程序员要被替代。随着OpenAI推出全新的GPT-4,GitHub Copilot也在3月22日,推出了全新一代产品:GitHub Copilot X 。最新的GitHub Copilot X 不仅可以自动…...
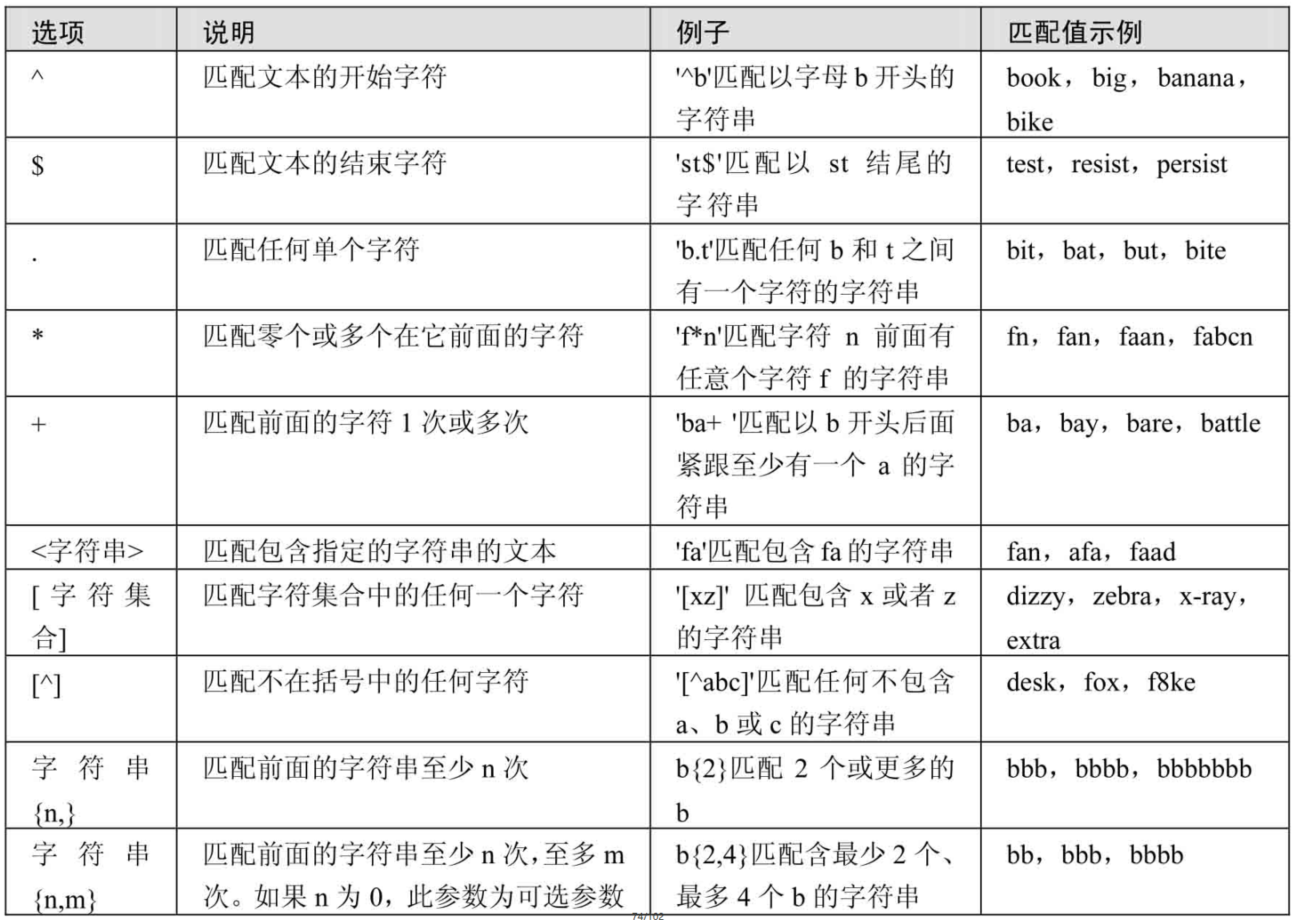
第04章_运算符
第04章_运算符 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前在某公…...

Excel 文件比较工具:xlCompare 11.0 Crack
(Excel 文件比较工具)xlCompare 11.0 下载并安装最新版本的 xlCompare。下载是一个功能齐全的版本。 筛选匹配的行 筛选不同的行 仅显示两个 Excel 文件中存在的行,并排除新(已删除)行 隐藏在另一张工作表上具有相应行…...

OpenAPI规范自动生成CLI工具:原理、实现与工程实践
1. 项目概述:从API文档到命令行工具的自动化革命如果你是一名后端开发者,或者经常需要与各种RESTful API打交道,那么下面这个场景你一定不陌生:产品经理或前端同事跑过来,递给你一份新鲜出炉的OpenAPI/Swagger规范文档…...

LED照明技术演进中的杰文斯悖论:从节能到光污染的双刃剑效应
1. 从“省电”到“光污染”:LED照明技术的双刃剑效应作为一名在电子工程和消费电子领域摸爬滚打了十几年的从业者,我见证了一波又一波的技术浪潮。从CRT到LCD,从机械硬盘到固态硬盘,每一次技术迭代都伴随着“更高效、更节能、更便…...

从零构建FreeRTOS认知:核心概念与实战框架精讲
1. 认识FreeRTOS:嵌入式系统的"交通指挥官" 第一次接触FreeRTOS时,我盯着文档里那些"任务"、"队列"、"调度器"之类的术语发懵,就像刚拿到驾照就被扔进了早高峰的十字路口。后来才发现,这…...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...

基于Agent架构的轻量级自托管部署工具Ship实战指南
1. 项目概述:一个为开发者而生的轻量级部署工具最近在折腾一个前后端分离的小项目,从本地开发到服务器部署,中间那套流程真是让人头大。代码提交、构建、测试、再到服务器上拉取、重启服务,一套组合拳下来,少说也得十几…...

矩阵本地化获客技术落地:同城流量精准匹配与合规运营方案
前言同城本地化流量是短视频生态中转化率最高、精准度最强的流量赛道,广泛适配本地生活服务、实体门店、同城咨询、区域服务商等各类业态。相比于泛全域流量,同城用户具备明确的地域消费属性、就近服务需求,成交意向更强烈,获客落…...

Armv8-A架构缓存维护指令详解与应用实践
1. A64系统指令中的缓存维护操作概述在Armv8-A架构中,缓存维护操作是确保系统内存一致性的关键机制。作为体系结构设计中最精妙的部分之一,缓存维护指令直接操控处理器缓存层次结构的状态,对系统性能、功能正确性和安全性都有着决定性影响。现…...
)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南) 呼吸灯效果是嵌入式开发中经典的PWM应用场景,不仅能直观展示定时器功能,还能为产品增添交互美感。对于STM32开发者而言,利用Cu…...

为LibraVDB定制内存池:提升稀疏体素数据处理性能
1. 项目概述:一个为LibraVDB设计的开源内存管理库最近在搞一些基于体素的数据处理项目,特别是用到了LibraVDB这个开源的稀疏体素数据库。玩过VDB格式的朋友都知道,它的核心优势在于对稀疏体数据的极致压缩和高效访问,但这也带来了…...
完全指南)
【LangChain】 输出解析器(Output Parsers)完全指南
LangChain 输出解析器(Output Parsers)完全指南2026 年最新版 | 覆盖所有内置解析器 完整代码示例一、什么是输出解析器 输出解析器是 LangChain 中连接"自由文本 LLM"与"结构化程序"的桥梁。LLM 天生输出自然语言,但应…...