Scikit-learn (`sklearn`) 教程
Scikit-learn (sklearn) 教程
Scikit-learn 是 Python 中最流行的机器学习库之一,提供了丰富的机器学习算法、数据预处理工具以及模型评估方法,广泛应用于分类、回归、聚类和降维等任务。
在本教程中,我们将介绍如何使用 Scikit-learn 进行数据加载、特征处理、模型训练与评估,并展示一些常用的机器学习模型。
1. 安装 Scikit-learn
你可以使用以下命令安装 scikit-learn:
pip install scikit-learn
2. Scikit-learn 的核心组件
- 数据集:提供内置数据集和数据集加载工具。
- 特征工程:包括特征缩放、编码、缺失值处理等。
- 模型:提供分类、回归、聚类、降维等多种算法。
- 模型评估:包括交叉验证、网格搜索等。
3. 数据集
Scikit-learn 提供了多种内置数据集(例如 Iris、Boston),并且提供了用于加载外部数据集的工具。
3.1 加载内置数据集
例如,加载 Iris 数据集:
from sklearn.datasets import load_iris# 加载 Iris 数据集
iris = load_iris()
print(iris.feature_names) # 输出特征名称
print(iris.target_names) # 输出目标类别名称# 特征数据
X = iris.data
# 目标数据
y = iris.targetprint(X.shape, y.shape)
3.2 使用 Pandas 加载 CSV 数据
你也可以使用 Pandas 加载本地 CSV 数据:
import pandas as pd# 加载 CSV 数据
data = pd.read_csv('data.csv')# 分离特征和目标
X = data.drop('target_column', axis=1)
y = data['target_column']
4. 数据预处理
Scikit-learn 提供了一些常用的特征预处理工具,例如标准化、归一化、标签编码等。
4.1 标准化与归一化
- 标准化:将数据转换为均值为 0,方差为 1 的正态分布。
- 归一化:将数据缩放到 [0, 1] 或 [-1, 1] 的范围。
from sklearn.preprocessing import StandardScaler, MinMaxScaler# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 归一化
min_max_scaler = MinMaxScaler()
X_normalized = min_max_scaler.fit_transform(X)
4.2 标签编码
将分类标签转换为数字编码:
from sklearn.preprocessing import LabelEncoder# 标签编码
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
5. 训练/测试集拆分
在进行模型训练前,通常需要将数据集划分为训练集和测试集。Scikit-learn 提供了 train_test_split 函数来完成这一操作。
from sklearn.model_selection import train_test_split# 划分训练集和测试集,比例为 80:20
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print(X_train.shape, X_test.shape)
6. 模型训练
Scikit-learn 提供了丰富的机器学习算法。常见的分类、回归和聚类算法都可以通过 fit() 方法来训练模型。
6.1 分类任务示例:K 最近邻 (KNN)
K 最近邻算法是一种经典的分类算法。以下是使用 KNN 进行分类的示例:
from sklearn.neighbors import KNeighborsClassifier# 创建 KNN 模型
knn = KNeighborsClassifier(n_neighbors=3)# 训练模型
knn.fit(X_train, y_train)# 在测试集上进行预测
y_pred = knn.predict(X_test)
6.2 回归任务示例:线性回归
对于回归任务,可以使用线性回归模型进行训练:
from sklearn.linear_model import LinearRegression# 创建线性回归模型
lr = LinearRegression()# 训练模型
lr.fit(X_train, y_train)# 在测试集上进行预测
y_pred = lr.predict(X_test)
7. 模型评估
Scikit-learn 提供了多种评估指标,用于衡量模型的性能。
7.1 分类模型评估
- 准确率:分类模型中常用的评估指标,表示预测正确的样本占总样本的比例。
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')# 分类报告
print(classification_report(y_test, y_pred))# 混淆矩阵
print(confusion_matrix(y_test, y_pred))
7.2 回归模型评估
- 均方误差:常用的回归模型评估指标,衡量预测值与真实值的差距。
from sklearn.metrics import mean_squared_error, r2_score# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')# R^2 分数
r2 = r2_score(y_test, y_pred)
print(f'R^2 Score: {r2}')
8. 交叉验证
交叉验证是一种常用的模型评估方法,可以更稳健地评估模型性能。Scikit-learn 提供了 cross_val_score 来实现交叉验证。
from sklearn.model_selection import cross_val_score# 使用交叉验证评估模型性能,使用 5 折交叉验证
scores = cross_val_score(knn, X, y, cv=5)
print(f'Cross-validation scores: {scores}')
print(f'Average score: {scores.mean()}')
9. 模型调参
在实际应用中,找到最优的超参数组合非常重要。Scikit-learn 提供了 GridSearchCV 和 RandomizedSearchCV 来进行超参数调优。
9.1 网格搜索(Grid Search)
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_neighbors': [3, 5, 7],'weights': ['uniform', 'distance']
}# 进行网格搜索
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)# 输出最佳参数
print(f'Best parameters: {grid_search.best_params_}')
9.2 随机搜索(Randomized Search)
from sklearn.model_selection import RandomizedSearchCV# 定义随机搜索参数
param_distributions = {'n_neighbors': [3, 5, 7],'weights': ['uniform', 'distance']
}# 随机搜索
random_search = RandomizedSearchCV(KNeighborsClassifier(), param_distributions, cv=5, n_iter=10)
random_search.fit(X_train, y_train)# 输出最佳参数
print(f'Best parameters: {random_search.best_params_}')
10. 管道 (Pipeline)
Pipeline 是 scikit-learn 中的一个非常有用的工具,它将多个步骤组合在一起,形成一个工作流。通过 Pipeline,我们可以将数据预处理和模型训练整合为一个过程,方便进行交叉验证和超参数调优。
10.1 创建管道
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC# 创建一个包含标准化和 SVM 分类器的管道
pipeline = Pipeline([('scaler', StandardScaler()), # 数据标准化('svc', SVC()) # 支持向量机分类器
])# 使用管道进行训练和预测
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)# 评估模型
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
10.2 在管道中使用网格搜索
你可以在 Pipeline 中使用超参数调优,调整管道中的每个步骤的参数。
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'svc__C': [0.1, 1, 10],'svc__kernel': ['linear', 'rbf']
}# 使用管道进行网格搜索
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)# 输出最佳参数
print(f'Best parameters: {grid_search.best_params_}')# 使用最佳模型进行预测
best_pipeline = grid_search.best_estimator_
y_pred = best_pipeline.predict(X_test)# 评估结果
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
11. 特征选择
在机器学习中,特征选择是非常重要的一步。通过去除无用或冗余的特征,可以提升模型的性能。scikit-learn 提供了多种特征选择的方法。
11.1 使用 SelectKBest 进行特征选择
SelectKBest 是一种常见的特征选择方法,它根据某种评分标准(如 f_classif)选择前 K 个最重要的特征。
from sklearn.feature_selection import SelectKBest, f_classif# 使用 SelectKBest 选择前 2 个最重要的特征
selector = SelectKBest(f_classif, k=2)
X_new = selector.fit_transform(X_train, y_train)# 打印被选择的特征
print(X_new.shape)
11.2 在管道中使用特征选择
你可以将特征选择步骤集成到 Pipeline 中,以便与其他步骤(如标准化和模型训练)一起进行处理。
from sklearn.feature_selection import SelectKBest
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline# 创建一个包含特征选择、标准化和 SVM 分类器的管道
pipeline = Pipeline([('select', SelectKBest(f_classif, k=2)), # 特征选择('scaler', StandardScaler()), # 标准化('svc', SVC()) # 支持向量机
])# 训练模型
pipeline.fit(X_train, y_train)# 预测结果
y_pred = pipeline.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
12. 聚类
scikit-learn 提供了多种聚类算法。聚类是无监督学习中的一种任务,目标是将数据划分为多个组(簇),其中同一簇的对象相似度较高。
12.1 K-means 聚类
K-means 是一种经典的聚类算法,它通过最小化簇内的方差将数据划分为 K 个簇。
from sklearn.cluster import KMeans# 创建 K-means 模型,指定 3 个簇
kmeans = KMeans(n_clusters=3, random_state=42)# 训练模型
kmeans.fit(X)# 预测簇标签
y_kmeans = kmeans.predict(X)# 打印每个样本所属的簇
print(y_kmeans)
12.2 层次聚类 (Agglomerative Clustering)
层次聚类通过不断合并最近的簇来构建层次树结构。你可以指定合并停止的簇数量。
from sklearn.cluster import AgglomerativeClustering# 创建层次聚类模型
agg_clustering = AgglomerativeClustering(n_clusters=3)# 训练模型
y_agg = agg_clustering.fit_predict(X)# 打印簇标签
print(y_agg)
13. 降维
降维技术用于将高维数据映射到低维空间,减少维度,同时尽可能保留原始数据的信息量。常见的降维方法有主成分分析(PCA)和线性判别分析(LDA)。
13.1 PCA 降维
主成分分析(PCA)是一种线性降维技术,找到数据的主要方向,最大限度地保留数据的方差。
from sklearn.decomposition import PCA# 创建 PCA 模型,指定主成分数量为 2
pca = PCA(n_components=2)# 使用 PCA 进行降维
X_pca = pca.fit_transform(X)# 打印降维后的数据形状
print(X_pca.shape)
13.2 LDA 降维
线性判别分析(LDA)是一种监督学习的降维方法,通常用于分类任务。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA# 创建 LDA 模型
lda = LDA(n_components=2)# 使用 LDA 进行降维
X_lda = lda.fit_transform(X, y)# 打印降维后的数据形状
print(X_lda.shape)
14. 模型持久化
在完成模型训练后,你可以使用 joblib 或 pickle 将模型保存为文件,之后可以加载该模型进行预测,而无需重新训练。
14.1 保存模型
import joblib# 保存模型到文件
joblib.dump(knn, 'knn_model.pkl')
14.2 加载模型
# 从文件中加载模型
loaded_model = joblib.load('knn_model.pkl')# 使用加载的模型进行预测
y_pred = loaded_model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
15. 自定义估计器
除了使用 scikit-learn 提供的标准模型外,你还可以通过继承 BaseEstimator 和 ClassifierMixin 自定义自己的估计器。
from sklearn.base import BaseEstimator, ClassifierMixin
import numpy as npclass CustomClassifier(BaseEstimator, ClassifierMixin):def __init__(self, threshold=0.5):self.threshold = thresholddef fit(self, X, y):self.mean_ = np.mean(X, axis=0)return selfdef predict(self, X):return (np.mean(X, axis=1) > self.threshold).astype(int)# 创建并使用自定义分类器
clf = CustomClassifier(threshold=0.6)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
16. 完整示例:分类任务
下面是一个完整的例子,展示了如何加载数据、进行预处理、构建管道、训练模型、进行网格搜索、评估模型性能,并将模型保存。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.pipeline import Pipeline
import joblib# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建管道
pipeline = Pipeline([('scaler', StandardScaler()), # 标准化('knn', KNeighborsClassifier()) # KNN 分类器
])# 定义参数网格
param_grid = {'knn__n_neighbors': [3, 5, 7],'knn__weights': ['uniform', 'distance']
}# 网格搜索
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)# 最佳模型
print(f'Best parameters: {grid_search.best_params_}')# 在测试集上进行预测
y_pred = grid_search.predict(X_test)# 评估模型
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
print(classification_report(y_test, y_pred))# 保存最佳模型
joblib.dump(grid_search.best_estimator_, 'best_knn_model.pkl')
17. 总结
通过本教程,你已经了解了 Scikit-learn 的主要功能和使用方法,包括数据预处理、模型训练与评估、超参数调优、管道、特征选择、聚类、降维等。Scikit-learn 提供了强大且易用的 API,适合从简单的机器学习任务到更复杂的工作流构建。
相关文章:
 教程)
Scikit-learn (`sklearn`) 教程
Scikit-learn (sklearn) 教程 Scikit-learn 是 Python 中最流行的机器学习库之一,提供了丰富的机器学习算法、数据预处理工具以及模型评估方法,广泛应用于分类、回归、聚类和降维等任务。 在本教程中,我们将介绍如何使用 Scikit-learn 进行…...

【计网】从零开始掌握序列化 --- JSON实现协议 + 设计 传输\会话\应用 三层结构
唯有梦想才配让你不安, 唯有行动才能解除你的不安。 --- 卢思浩 --- 从零开始掌握序列化 1 知识回顾2 序列化与编写协议2.1 使用Json进行序列化2.2 编写协议 3 封装IOService4 应用层 --- 网络计算器5 总结 1 知识回顾 上一篇文章我们讲解了协议的本质是双方能够…...

Qt 模型视图(四):代理类QAbstractItemDelegate
文章目录 Qt 模型视图(四):代理类QAbstractItemDelegate1.基本概念1.1.使用现有代理1.2.一个简单的代理 2.提供编辑器3.向模型提交数据4.更新编辑器的几何图形5.编辑提示 Qt 模型视图(四):代理类QAbstractItemDelegate 模型/视图结构是一种将数据存储和界面展示分离的编程方…...

django+vue
1. diango 只能加载静态js,和flask一样 2. 关于如何利用vue创建web,请查看flask vue-CSDN博客 3. 安装django pip install django 4. 创建新项目 django-admin startproject myproject 5.django 中可以包含多个app 5.1 创建一个app cd myprojec…...

HCIA--实验十七:EASY IP的NAT实现
一、实验内容 1.需求/要求: 通过一台PC,一台交换机,两台路由器来成功实现内网访问外网。理解NAT的转换机制。 二、实验过程 1.拓扑图: 2.步骤: 1.PC1配置ip地址及网关: 2.AR1接口配置ip地址࿱…...

彻底解决:QSqlDatabase: QMYSQL driver not loaded
具体错误 QSqlDatabase: QMYSQL driver not loaded QSqlDatabase: available drivers: QSQLITE QMIMER QMARIADB QMYSQL QODBC QPSQL 检查驱动 根据不同安装目录而不同: D:\Qt\6.7.2\mingw_64\plugins\sqldrivers 编译驱动 如果没有,需要自行编译&…...

leetcode02——59. 螺旋矩阵 II、203. 移除链表元素
59. 螺旋矩阵 II class Solution {public int[][] generateMatrix(int n) {int[][] nums new int[n][n]; // 定义二维数组用于存储数据int startX 0; // 定义每循环一个圈的起始位置int startY 0;int loop 1; // 定义圈数,最少1圈int count 1; // 用来给矩阵中…...

Matlab Simulink 主时间步(major time step)、子时间步(minor time step)
高亮颜色说明:突出重点 个人觉得,:待核准个人观点是否有误 高亮颜色超链接 文章目录 对Simulink 时间步的理解Simulink 采样时间的类型Discrete Sample Times(离散采样时间)Controllable Sample Time(可控采样时间) Continuous Sample Times(…...

docker 升级步骤
Docker 升级的步骤通常取决于你所使用的操作系统。以下是针对常见操作系统(如 Ubuntu 和 CentOS)的 Docker 升级步骤: Ubuntu 更新现有的包索引: sudo apt-get update 升级 Docker: 您可以运行以下命令来升级 Docker…...

828华为云征文 | 云服务器Flexus X实例:one-api 部署,支持众多大模型
目录 一、one-api 介绍 二、部署 one-api 2.1 拉取镜像 2.2 部署 one-api 三、运行 one-api 3.1 添加规则 3.2 运行 one-api 四、添加大模型 API 4.1 添加大模型 API 五、总结 本文通过 Flexus云服务器X实例 部署 one-api。Flexus云服务器X实例是新一代面向中小企业…...

2024 SNERT 预备队招新 CTF 体验赛-Web
目录 1、robots 2、NOF12 3、get_post 4、好事慢磨 5、uploads 6、rce 7、ezsql 8、RCE 1、robots robots 协议又叫爬虫协议,访问 robots.txt 继续访问 /JAY.php 拿到 flag:flag{hello_Do_YOU_KONw_JAY!} 2、NOF12 F12 和右键都被禁用 方法&#…...

亲测全网10大“免费”论文降重神器!论文写作必备!
在当今学术研究和论文写作中,AI技术的应用已经变得越来越普遍。为了帮助学者们更高效地完成论文撰写任务,以下将详细介绍十款必备的论文写作工具,其中特别推荐千笔-AIPassPaper。 1. 千笔-AIPassPaper 千笔-AIPassPaper是一款基于深度学习和…...

二分算法——优选算法
个人主页:敲上瘾-CSDN博客 个人专栏:游戏、数据结构、c语言基础、c学习、算法 本章我们来学习的是二分查找算法,二分算法的应用非常广泛,不仅限于数组查找,还可以用于解决各种搜索问题、查找极值问题等。在数据结构和算…...

Kafka 的基本概念
一、Kafka 主要用来做什么 作为消息系统:Kafka 具备系统解藕,流量削峰,缓冲,异步通信,扩展性,可恢复性等功能,以及消息顺序性保障和回溯消费 作为存储系统:Kafka 把消息持久化到磁…...
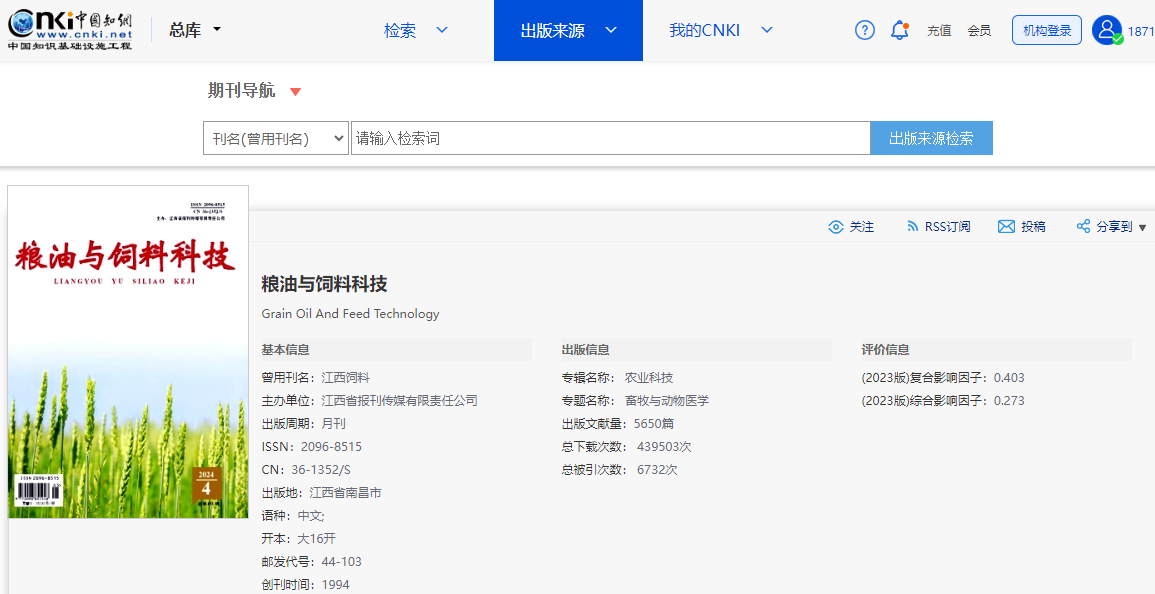
《粮油与饲料科技》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答 问:《粮油与饲料科技》是不是核心期刊? 答:不是,是知网收录的第一批认定 学术期刊。 问:《粮油与饲料科技》级别? 答:省级。主管单位:中文天地出版传媒集团股份有限公司…...

Python之一些列表的练习题
1.比较和对比字符串、列表和元组。例如,它们可以容纳哪类内容以及在数据结构上可以做哪些操作。 1. 内容类型:- 字符串: 只能包含字符(文本)。- 列表: 可以包含任意类型的数据,如数字、字符串、其他列表等。- 元组: 可以包含任意类型的数据,与列表类似。3. 操作:(1…...

MoFA: 迈向AIOS
再一次向朋友们致以中秋的祝福! MoFA (Modular Framework for Agents)是一个独特的模块化AI智能体框架。MoFA以组合(Composition)的逻辑和编程(Programmable)的方法构建AI智能体。开发者通过模版的继承、编程、定制智能体…...

c语言中define使用方法
在C语言中,#define指令是预处理指令,用于定义宏。其常用格式是: 定义常量: #define 常量名 常量值 例子: #define PI 3.14159 #define MAX_SIZE 100 这里,PI和MAX_SIZE在代码中会被替换为其对应的值。没有…...

尚品汇-秒杀商品定时任务存入缓存、Redis发布订阅实现状态位(五十一)
目录: (1)秒杀业务分析 (2)搭建秒杀模块 (3)秒杀商品导入缓存 (4)redis发布与订阅实现 (1)秒杀业务分析 需求分析 所谓“秒杀”࿰…...
——spring-boot-devtools)
第十一章 【后端】商品分类管理微服务(11.4)——spring-boot-devtools
11.4 spring-boot-devtools 官网:https://docs.spring.io/spring-boot/reference/using/devtools.html Spring Boot DevTools 是 Spring Boot 提供的一组易于使用的工具,旨在加速开发和测试过程。它通过提供一系列实用的功能,如自动重启、实时属性更新、依赖项的热替换等,…...

如何用BilibiliDown一键下载B站视频?3分钟掌握批量下载技巧
如何用BilibiliDown一键下载B站视频?3分钟掌握批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

FPGA+DSP异构核心板在工业控制与数据采集中的应用与开发指南
1. 项目概述:为什么选择FPGADSP异构核心板?在工业控制、伺服驱动、光伏逆变这些对实时性和算力要求都极高的领域里,选型一块合适的核心板往往是项目成败的第一步。过去,我们可能需要在“高灵活性的FPGA”和“高主频的通用处理器”…...

2026年国内酒吧管理系统有哪些?15款软件功能与适用场景
国内酒馆市场竞争摆在那里,靠手工记账和人盯人管理,越来越吃力。有行业统计显示,用了专业管理系统之后,酒吧的库存损耗平均能降18%,会员复购率提升25%以上。这笔账算下来,系统不是多出来的开支,…...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

STM32 HAL库驱动DS18B20避坑指南:单总线时序不准?试试用定时器精准延时
STM32 HAL库驱动DS18B20避坑指南:单总线时序不准?试试用定时器精准延时 在嵌入式开发中,温度传感器DS18B20因其单总线接口和数字输出特性广受欢迎。然而,许多开发者在使用STM32 HAL库驱动DS18B20时,常遇到温度读取失败…...
glTF-Transform:现代3D应用中的glTF模型优化与处理实战指南
glTF-Transform:现代3D应用中的glTF模型优化与处理实战指南 【免费下载链接】glTF-Transform glTF 2.0 SDK for JavaScript and TypeScript, on Web and Node.js. 项目地址: https://gitcode.com/gh_mirrors/gl/glTF-Transform 在当今的3D应用开发中…...

AArch64 TRCCNTCTLR寄存器详解与调试技巧
1. AArch64 TRCCNTCTLR寄存器概述在AArch64架构中,TRCCNTCTLR(Trace Counter Control Register)是嵌入式跟踪扩展(FEAT_ETE)功能的重要组成部分。作为系统调试和性能分析的核心组件,它负责控制跟踪计数器的…...

如何找到最适合你的私有化IM?
跳出公有云的舒适区,决心搭建私有化IM,并不是一件能一蹴而就的事。市面上打着私有化旗号的软件鱼龙混杂,有的安装环境要求极高,有的功能华而不实。如何在复杂的选型迷雾中,找到最适合组织基因的那一款?你可…...

CANN/pypto PASS组件错误码说明
PASS 组件错误码说明文档 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 范围:F40000-F44002本文档说明 PASS 组件的错误码定义、场…...

AI驱动的DNA分析平台:简化生物信息学流程
1. 项目概述:当生物信息学遇上“开箱即用”的AI逻辑引擎“BIOREASON”这个名字一出现,我就下意识在笔记本上画了个双螺旋和神经网络的交叉草图——不是为了炫技,而是因为过去八年里,我亲手调试过三十多套DNA分析流程,从…...