Java后端中的延迟队列实现:使用Redis与RabbitMQ的不同策略
Java后端中的延迟队列实现:使用Redis与RabbitMQ的不同策略
大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!
在后端开发中,延迟队列(Delayed Queue)是一种非常实用的设计,能够帮助我们在指定时间后处理某些任务。无论是订单超时处理、定时消息通知,还是需要延迟执行的任务,延迟队列都能为我们提供高效的解决方案。常见的实现延迟队列的策略有很多,其中Redis和RabbitMQ是两种流行的方案。本文将从这两种策略的角度探讨如何在Java后端中实现延迟队列。
一、什么是延迟队列?
延迟队列的基本原理是在消息被放入队列后,不会立即被消费,而是需要等到指定的时间后,消费者才能消费这些消息。延迟队列的典型应用场景包括:
- 延迟发送消息(如邮件或通知)
- 定时任务执行(如定期清理、自动过期)
- 超时订单的处理
下面,我们将分别介绍如何利用Redis和RabbitMQ实现延迟队列,并提供对应的Java代码示例。
二、基于Redis的延迟队列实现
Redis可以通过其Sorted Set(有序集合)和TTL机制来实现延迟队列。有序集合中的每个元素都有一个关联的分数,分数用于排序。我们可以将消息存入有序集合,并将当前时间戳加上延迟时间作为分数,这样我们就可以使用ZRANGEBYSCORE命令获取到期的消息。
Redis延迟队列的Java实现
package cn.juwatech.redis;import redis.clients.jedis.Jedis;import java.util.Set;public class RedisDelayQueue {private static final String DELAY_QUEUE_KEY = "delay_queue";private Jedis jedis;public RedisDelayQueue() {this.jedis = new Jedis("localhost", 6379);}// 添加任务到延迟队列public void addTask(String taskId, long delay) {long score = System.currentTimeMillis() + delay;jedis.zadd(DELAY_QUEUE_KEY, score, taskId);}// 轮询获取到期的任务public void pollTasks() {while (true) {long currentTime = System.currentTimeMillis();// 获取延迟时间已到的任务Set<String> tasks = jedis.zrangeByScore(DELAY_QUEUE_KEY, 0, currentTime);for (String task : tasks) {// 处理任务System.out.println("处理任务: " + task);// 移除已处理任务jedis.zrem(DELAY_QUEUE_KEY, task);}try {Thread.sleep(1000); // 每秒轮询一次} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}public static void main(String[] args) {RedisDelayQueue delayQueue = new RedisDelayQueue();delayQueue.addTask("task1", 5000); // 延迟5秒delayQueue.addTask("task2", 10000); // 延迟10秒// 启动轮询线程处理任务new Thread(delayQueue::pollTasks).start();}
}
代码解析:
- 我们使用Redis的有序集合来存储任务,每个任务有一个时间戳作为分数。
addTask方法将任务ID与延迟后的时间戳一同存入Redis。pollTasks方法定期从Redis中查询当前时间已到期的任务并处理。
Redis的延迟队列方案具有简单、轻量的优势,但由于需要轮询来检测任务是否到期,因此在高并发场景下可能存在性能瓶颈。
三、基于RabbitMQ的延迟队列实现
RabbitMQ提供了更专业的消息队列功能,并且可以通过插件的方式直接支持延迟队列。使用RabbitMQ的延迟队列有两种常见方式:一是基于TTL(Time-To-Live)和DLX(Dead Letter Exchange),二是使用RabbitMQ的延迟消息插件。
RabbitMQ延迟队列的Java实现
package cn.juwatech.rabbitmq;import com.rabbitmq.client.*;import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeoutException;public class RabbitMQDelayQueue {private static final String EXCHANGE_NAME = "delay_exchange";private static final String QUEUE_NAME = "delay_queue";private static final String DEAD_LETTER_EXCHANGE = "dead_letter_exchange";private Connection connection;private Channel channel;public RabbitMQDelayQueue() throws IOException, TimeoutException {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");this.connection = factory.newConnection();this.channel = connection.createChannel();// 声明死信交换机和队列Map<String, Object> args = new HashMap<>();args.put("x-dead-letter-exchange", DEAD_LETTER_EXCHANGE);// 声明延迟队列,指定TTLchannel.queueDeclare(QUEUE_NAME, true, false, false, args);channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);// 绑定队列到交换机channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "delay");}// 发送延迟消息public void sendDelayedMessage(String message, long delay) throws IOException {Map<String, Object> headers = new HashMap<>();headers.put("x-delay", delay);AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder().headers(headers).expiration(String.valueOf(delay)) // TTL.build();channel.basicPublish(EXCHANGE_NAME, "delay", properties, message.getBytes());System.out.println("发送延迟消息: " + message + " 延迟: " + delay + " 毫秒");}// 消费消息public void consumeMessage() throws IOException {channel.basicConsume(QUEUE_NAME, true, (consumerTag, message) -> {String body = new String(message.getBody());System.out.println("接收到消息: " + body);}, consumerTag -> {});}public static void main(String[] args) throws IOException, TimeoutException {RabbitMQDelayQueue delayQueue = new RabbitMQDelayQueue();delayQueue.sendDelayedMessage("task1", 5000); // 延迟5秒delayQueue.sendDelayedMessage("task2", 10000); // 延迟10秒// 启动消费端delayQueue.consumeMessage();}
}
代码解析:
- 交换机和队列声明:我们声明了一个死信交换机,用于接收延迟消息。
- 发送延迟消息:在发送消息时,我们设置了TTL(消息存活时间),消息会在指定时间后转发到死信交换机,并最终到达目标队列。
- 消费消息:消费者会从延迟队列中接收到消息,并进行处理。
RabbitMQ的延迟队列方案更加专业,适用于高并发、分布式环境下的消息延迟处理。而且,通过使用RabbitMQ的原生插件,我们可以轻松管理延迟消息的精度和性能。
四、Redis与RabbitMQ延迟队列的对比
| 特性 | Redis | RabbitMQ |
|---|---|---|
| 实现复杂度 | 简单,通过Sorted Set实现 | 较复杂,需要配置TTL和DLX机制 |
| 性能 | 适合中小型任务,性能取决于轮询效率 | 高并发场景表现优异,专业队列系统 |
| 延迟精度 | 受轮询间隔影响 | 延迟精度高,TTL直接控制 |
| 可扩展性 | 难以扩展,需依赖分布式锁等机制 | 天然支持分布式、消息队列 |
| 可靠性 | 数据持久化机制简单 | 提供强大的消息持久化与确认机制 |
五、应用场景分析
- Redis延迟队列更适合任务量不大、处理相对简单的场景,例如订单超时提醒、限时优惠处理等。
- RabbitMQ延迟队列适合需要处理高并发、大规模任务调度的场景,如电商订单、支付系统中的延时扣款和分布式任务调度等。
结语
在Java后端开发中,延迟队列是实现定时任务和延迟消息处理的有效手段。通过Redis和RabbitMQ这两种不同的技术栈,我们可以灵活选择适合自己业务场景的延迟队列方案。Redis简单易用,适合小型任务;Rabbit
MQ功能强大,能够处理复杂的分布式延迟任务。通过合理的选择和配置,我们可以提升系统的性能与可扩展性。
本文著作权归聚娃科技微赚淘客系统开发者团队,转载请注明出处!
相关文章:

Java后端中的延迟队列实现:使用Redis与RabbitMQ的不同策略
Java后端中的延迟队列实现:使用Redis与RabbitMQ的不同策略 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 在后端开发中,延迟队列(Delayed Queue)…...
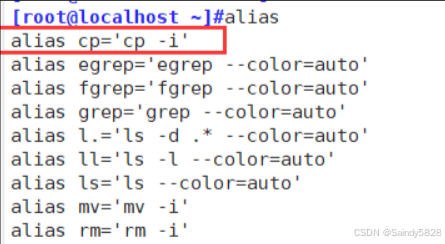
Linux中使用cp命令的 -f 选项,但还是提醒覆盖的问题
问题: linux 在执行cp的命令的时候,就算是执行 cp -f 也还是会提醒是否要进行替换。 问题原因: 查看别名,alias命令,看到cp的别名为cp -i,那就是说cp本身就是自带覆盖提醒,就算我们加上-f 的…...

互联网技术的持续演进:从现在到未来
互联网技术的持续演进:从现在到未来 在过去的十年里,互联网技术发生了飞速变化。无论是大数据、人工智能,还是5G网络和物联网,每一种技术的突破都在改变我们的生活方式和工作模式。作为现代社会的核心驱动力,互联网技…...
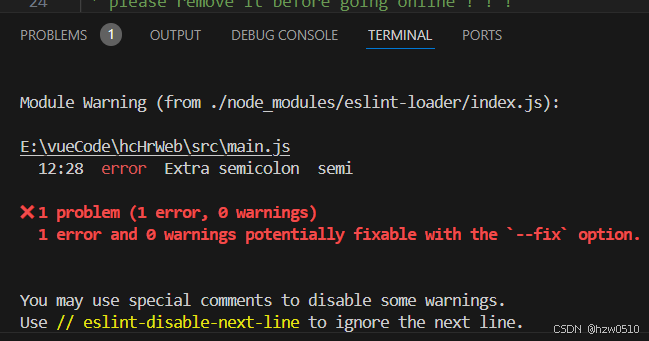
vscode安装ESLint与Vetur插件后自动修复代码不生效
vscode安装ESLint与Vetur插件后自动修复代码不生效 1、安装ESLint 和 Vuter 2、运行结果 2.1、代码保存时代码中的分号;能被检测出来,但是不会自动修复 2.2、手动运行ESLint 修复命令(在终端中执行 npx eslint . --fix)可以修复问题 3、解决办法 在.vscode目录下setti…...

2848、与车相交的点
2848、[简单] 与车相交的点 1、题目描述 给你一个下标从 0 开始的二维整数数组 nums 表示汽车停放在数轴上的坐标。对于任意下标 i,nums[i] [starti, endi] ,其中 starti 是第 i 辆车的起点,endi 是第 i 辆车的终点。 返回数轴上被车 任意…...

基于k8s手动部署rabbitmq集群(Manually Deploying RabbitMQ Cluster Based on k8s)
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:Linux运维老纪的首页…...
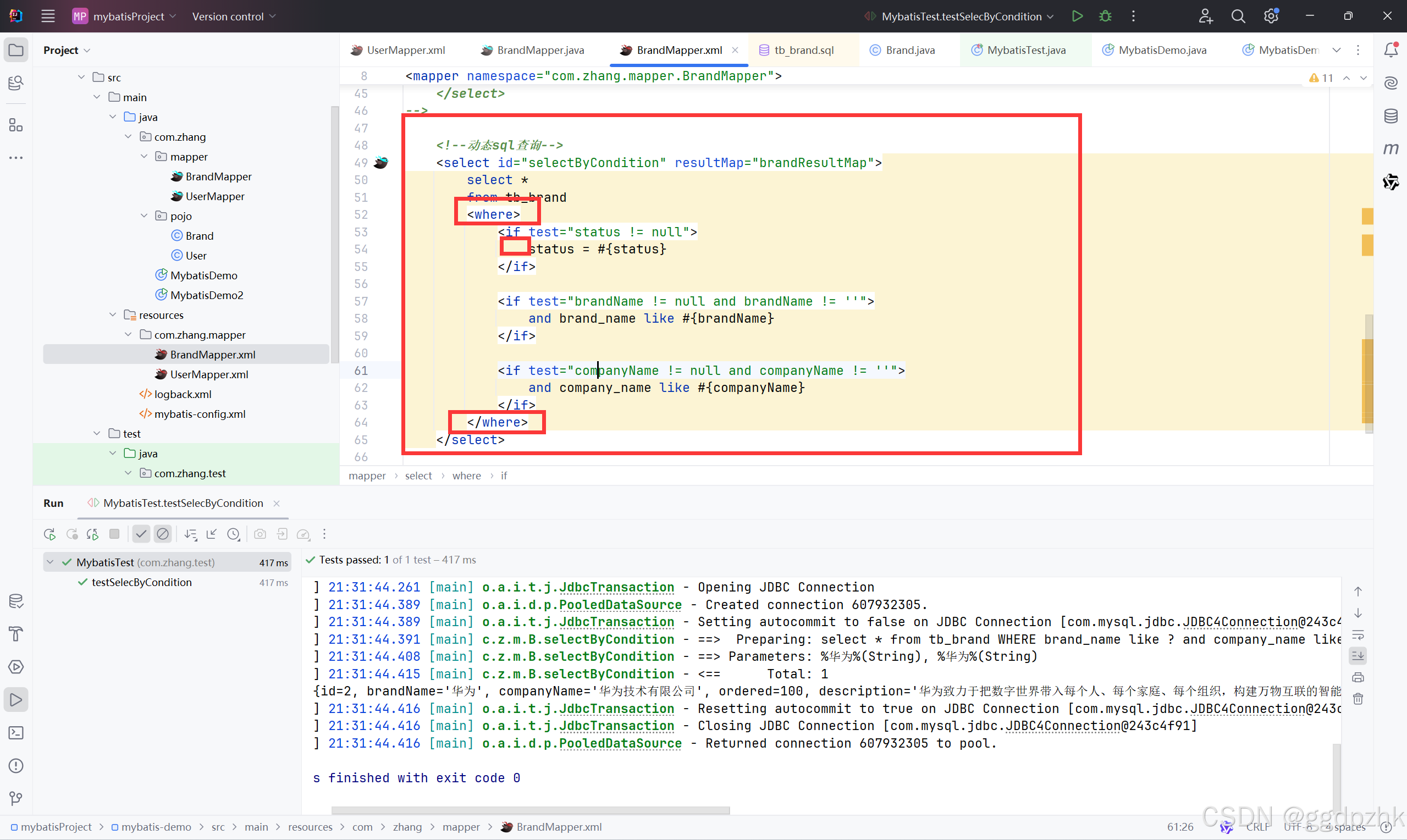
mybatis 配置文件完成增删改查(四) :多条件 动态sql查询
文章目录 就是你在接收数据时,有的查询条件不写,也能从查到相应的stauts也可能为空恒等式标签 代替where关键字 就是你在接收数据时,有的查询条件不写,也能从查到相应的 注意是写字段名 还是 属性名 companyName不写也能查出满足…...
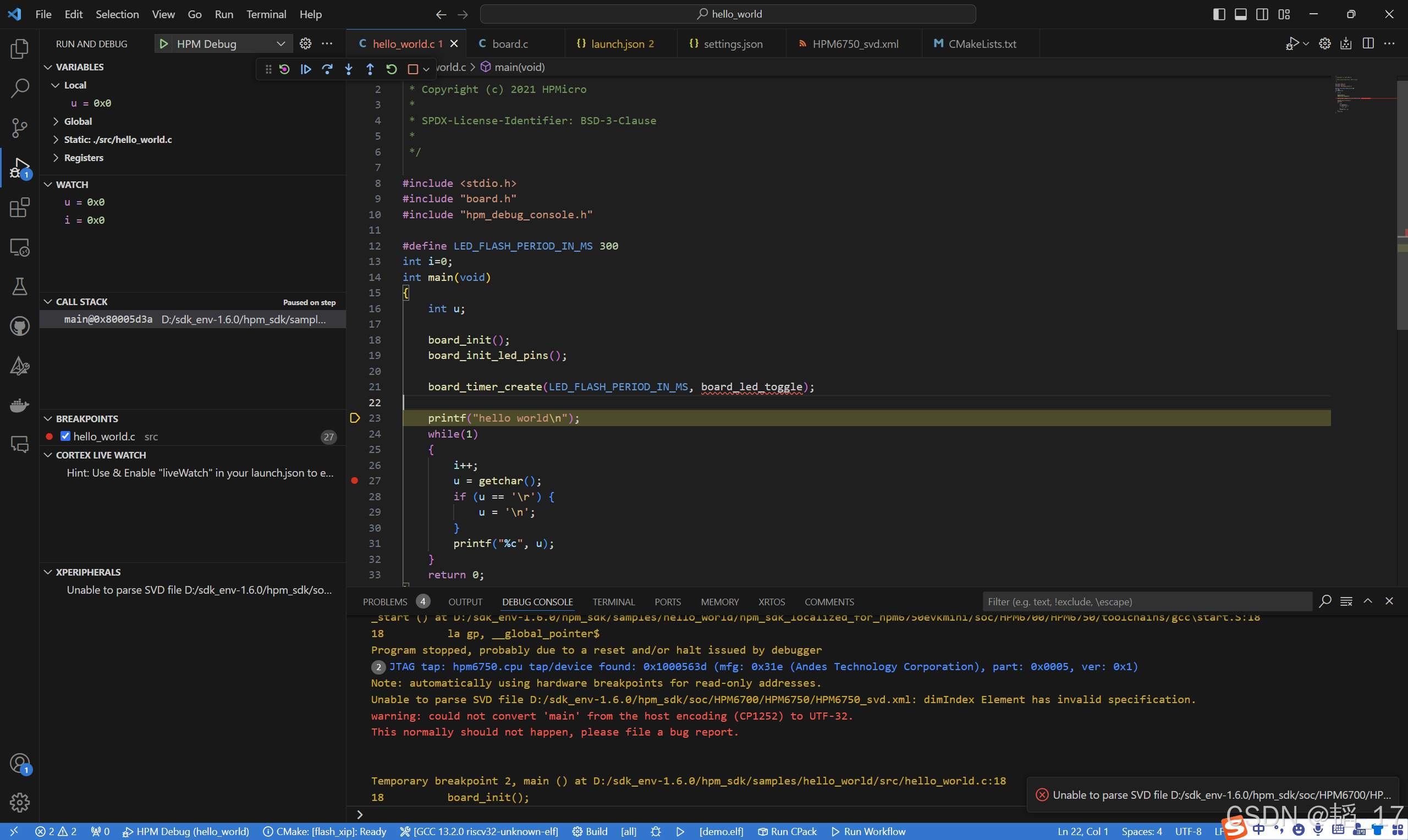
先楫HPM6750 Windows下VSCode开发环境配置
用的是EVKmini,ft2232作为调试器jtag接口调试 启动start_gui.exe 以hello_world为例,更改一下build path,可以generate并使用gcc compile 最后会得到这些 点击start_gui里面的命令行,用命令行启动vscode 新建.vscode文件夹&…...

【JavaScript】LeetCode:41-45
文章目录 41 排序链表42 合并k个升序链表43 LRU缓存44 二叉树的中序遍历45 二叉树的最大深度 41 排序链表 递归 归并排序找到链表中心点,从中心点将链表一分为二。奇数个节点找中心点,偶数个节点找中心左边的点作为中心点。快慢指针找中心点,…...

数据结构(Day18)
一、周学习内容 1、9.18 数据结构(Day15)-CSDN博客 2、9.19 数据结构(Day16)-CSDN博客 3、9.20 链表 目的 插入删除不需要移动任何节点(元素)。 不需要预估存储空间大小,长度动态增长或减小。…...

error: ‘InsertAtTop‘ was not declared in this scope
Qt编译错误记录: 报错:error: ‘InsertAtTop’ was not declared in this scope ui->comboBoxJob->setInsertPolicy(InsertAtTop);这行代码在Qt中编译就会报这个错误,原因是输入参数需要加类名限定,改为: ui-…...

MySQL缓冲池详解
Buffer Pool 本文参考开源项目:小林coding在线文档; 01-缓冲池概述 在MySQL查询数据的时候,是通过存储引擎去磁盘做IO来获取数据库中的数据,这样每次查询一条数据都要去做一次或者多次磁盘的IO,无疑是非常慢的。…...

【我的 PWN 学习手札】tcache stash with fastbin double free —— tcache key 绕过
参考看雪课程:PWN 探索篇 前言 tcache key 的引入使得 tcache dup 利用出现了困难。除了简单利用 UAF 覆写 key 或者House Of Karui 之外,还可以利用 ptmalloc 中的其他机制进行绕过。 一、Tcache Stash with Fastbin Double Free 之前是 double free …...

How can I stream a response from LangChain‘s OpenAI using Flask API?
题意:怎样在 Flask API 中使用 LangChain 的 OpenAI 模型流式传输响应 问题背景: I am using Python Flask app for chat over data. In the console I am getting streamable response directly from the OpenAI since I can enable streming with a f…...

什么是慢充优惠话费充值api?如何选择平台
一、话费充值api的定义 话费充值api是一种能够让开发者将话费充值功能集成到自己的平台的接口。通过接入话费充值api接口,就能够实现话费充值平台的搭建,从而为用户提供话费充值服务,这一接口主要适用于对话费充值有长期稳定需求的企业或者商…...

【MySQL 03】表的操作
目录 1.在数据库内创建表 2.表的查询 3.表的插入 往数据库中插入数据 4.表的修改 5.删除表 1.在数据库内创建表 create table 表名(字段1 字段1类型); 这样我们就创建好了一张表,我们可以进入hellosql目录下进行查看:所以在数据库内建立表…...

3、论文阅读:EnYOLO:一种基于图像增强的水下目标区域自适应实时检测框架
图像增强和目标检测的结合 前言介绍相关工作UIE 水下图像增强UOD 水下目标检测UDA 水下域自适应方法介绍训练过程推理过程网络概述多阶段训练策略Burn-In Stage(预热阶段)Mutual-Learning Stage(相互学习阶段)Domain-Adaptation Stage(领域适应阶段)多阶段训练策略算法介…...

MYSQL面试知识点手册
第一部分:MySQL 基础知识 1.1 MySQL 简介 MySQL 是世界上最流行的开源关系型数据库管理系统之一,它以性能卓越、稳定可靠和易用性而闻名。MySQL 主要应用在 Web 开发、大型互联网公司、企业级应用等场景,且广泛用于构建高并发、高可用的数据…...

排序算法的分析和应用
自己设计一个长度不小于10的乱序数组,用希尔排序,自己设定希尔排序参数 画出每一轮希尔排序的状态 自己设计一个长度不小于10的乱序数组,用堆排序,最终要生成升序数组,画出建堆后的状态 画出每一轮堆排序的状态 自…...

iptables限制网速
1、使用hashlimit来限速 #从eth0网卡进入INPUT链数据,使用模块hashlimit 限制网速为100kb/s或2mb/s,超过限制的数据包会被DROP。OUTPUT链同理,mode为srcip,有4个mode选项: srcip(默认匹配每个源地址IP,配置指定源地址…...

Unity 2D项目初始化实战:从零搭建可维护游戏骨架
1. 这不是“又一个Unity入门教程”,而是我带三个实习生从零做出第一个可玩Demo的真实路径你搜“Unity 2D 教程”,首页全是“5分钟创建角色”“10行代码实现跳跃”——画面很炫,但关掉视频后,你连项目文件夹里该删哪个.meta、该留哪…...

DCGAN原理解析:用卷积结构根治GAN模式坍缩
1. 项目概述:从手写数字到逼真猫脸,DCGAN如何让生成模型真正“看见”图像结构你有没有试过训练一个最基础的GAN,结果生成器输出的全是模糊的、像打了马赛克的灰扑扑色块?或者更糟——所有生成的图片都长得一模一样,只是…...

【笔记】HarmonyOS核心设计理念
HarmonyOS初衷不是为了平替,是看到了万物智联时代,对智能终端操作系统有许多新的诉求; 本内容主要帮助理解HarmonyOS核心设计理念的关键背景与创新驱动力; 第一节:回顾操作系统的发展历史 第一台通用计算机诞生于1946年…...

2026年,专业打造湖南美缝施工极致体验的宝藏公司你知道吗?
在湖南,装修市场日益繁荣,美缝作为装修中至关重要的一环,其品质直接影响着家居的整体美观与舒适度。今天,就带大家了解一家专业打造湖南美缝施工极致体验的宝藏公司——长沙匠心徐师傅美缝团队。一、高端服务体系贴合业主核心诉求…...

内部举报、纪检谈话等敏感场景,企业沟通工具需要具备哪些安全能力
一家组织处理内部举报时,沟通链路往往比事件本身更敏感。 举报人担心身份暴露,被举报部门担心信息扩散,纪检或内控人员需要核实事实,法务和审计又可能随后介入。一次谈话纪要、一张截图、一份附件、一个会议链接,都可能…...

SpaceX启动纳斯达克IPO,1.75万亿美元市值目标能否实现?
SpaceX启动纳斯达克IPO5月21日,马斯克旗下的商业航天、通信与AI巨头SpaceX向美国SEC公开提交S - 1注册声明,启动纳斯达克IPO流程。其承销商包括高盛、摩根士丹利、美国银行证券、花旗、摩根大通证券。这版S - 1文件暂未披露具体的发行股数和定价区间。不…...

系统设计 012:从用户系统出发,吃透缓存、数据库与高并发设计
系统设计 012:从用户系统出发,吃透缓存、数据库与高并发设计Bilibili 同步视频一、用户系统,藏着后端设计的核心考点💡二、4S 分析法:先读懂用户系统的流量挑战📊1. Scenario:四大需求ÿ…...
系统实战指南)
Godot 4.3+生产级3D反向运动学(IK)系统实战指南
1. 这不是“加个插件就动起来”的玩具,而是能进生产管线的IK系统 在Godot社区里,“反向运动学”这个词被提得太多,也太轻了。我见过太多人把 Skeleton3D 拖进场景,点开 IK 节点属性,勾上“启用”,然后…...

5个核心技术:深度掌握Sollumz在GTA V建模中的架构设计与实战应用
5个核心技术:深度掌握Sollumz在GTA V建模中的架构设计与实战应用 【免费下载链接】Sollumz Grand Theft Auto V modding suite for Blender. This add-on allows the creation of modded game assets: 3D models, maps, interiors, animations, etc. 项目地址: ht…...

软件开发行业的未来:AI编程将如何改变开发行业
在科技飞速发展的今天,人工智能(AI)正以前所未有的速度渗透到各个领域,软件开发行业也不例外。AI编程作为AI技术在软件开发领域的重要应用,正在深刻地改变着开发行业的格局。对于软件测试从业者来说,了解AI…...