Crack道路裂缝检测数据集——目标检测数据集
【Crack道路裂缝检测数据集】共3684张。
 目标检测数据集,标注文件为YOLO适用的txt格式。已划分为训练、验证集。
目标检测数据集,标注文件为YOLO适用的txt格式。已划分为训练、验证集。
图片分辨率:224*224
类别:crack


Crack道路裂缝检测数据集
数据集描述
该数据集是一个专门用于训练和评估基于YOLO(You Only Look Once)架构的目标检测模型的数据集,旨在帮助研究人员和开发者在道路图像中识别裂缝。数据集包含3684张高分辨率的道路图像,并提供了详细的边界框标注信息,支持直接用于训练目标检测模型。通过高质量的数据和详细的标注信息,该数据集为开发高效且准确的道路裂缝检测系统提供了坚实的基础。
数据规模
- 总样本数量:3684张图片
- 标注格式:YOLO txt格式
- 图片分辨率:224x224像素
- 类别:crack(裂缝)
图像特性
- 多样化场景:覆盖了多种道路条件下的图像,包括不同的天气条件、光照条件和背景。
- 高质量手工标注:每张图像都有详细的边界框标注,支持直接用于训练目标检测模型。
- 单类别支持:专注于检测道路中的裂缝。
- 无需预处理:数据集已经过处理,可以直接用于训练,无需额外的数据预处理步骤。
应用场景
- 智能监控:自动检测道路图像中的裂缝,辅助管理人员进行道路维护和管理。
- 无人机应用:集成到无人机系统中,实现对道路状况的实时检测和跟踪。
- 科研分析:用于研究目标检测算法在特定应用场景中的表现,特别是在复杂背景和低对比度条件下的鲁棒性。
- 教育与培训:可用于安全相关的教育和培训项目,帮助学生和从业人员更好地理解道路裂缝检测技术。
- 自动化管理:集成到智能交通管理系统中,实现对道路状况的自动化监测和管理。
数据集结构数据集目录结构如下:
1crack_detection_dataset/
2├── images/
3│ ├── train/
4│ │ ├── img_00001.jpg
5│ │ ├── img_00002.jpg
6│ │ └── ...
7│ ├── val/
8│ │ ├── img_00001.jpg
9│ │ ├── img_00002.jpg
10│ │ └── ...
11├── labels/
12│ ├── train/
13│ │ ├── img_00001.txt
14│ │ ├── img_00002.txt
15│ │ └── ...
16│ ├── val/
17│ │ ├── img_00001.txt
18│ │ ├── img_00002.txt
19│ │ └── ...
20├── scripts/
21│ ├── train_yolo.py
22│ ├── evaluate_yolo.py
23│ ├── visualize_annotations.py
24│ ├── data_augmentation.py
25├── config/
26│ ├── data.yaml # 数据集配置文件
27│ ├── model.yaml # 模型配置文件
28├── requirements.txt # 依赖库
29└── README.md # 数据说明文件数据说明
- 检测目标:以YOLO txt格式进行标注。
- 数据集内容:
- 总共3684张图片,每张图片都带有相应的txt标注文件。
- 标签类型:
- 边界框 (Bounding Box)
- 数据增广:数据集未做数据增广,用户可以根据需要自行进行数据增广。
- 无需预处理:数据集已经过处理,可以直接用于训练,无需额外的数据预处理步骤。
示例代码

以下是一些常用脚本的示例代码,包括训练YOLO模型、评估模型性能、可视化标注以及数据增强。
脚本1: 训练YOLO模型
1# train_yolo.py
2import os
3import torch
4from yolov5 import train
5
6def main():
7 data_yaml = 'path/to/config/data.yaml' # 包含数据集路径和类别的配置文件
8 model_yaml = 'path/to/config/model.yaml' # 模型配置文件
9 weights = 'path/to/weights/yolov5s.pt' # 预训练权重(可选)
10 epochs = 100
11 batch_size = 8
12 img_size = 224
13
14 train.run(
15 data=data_yaml,
16 cfg=model_yaml,
17 weights=weights,
18 epochs=epochs,
19 batch_size=batch_size,
20 imgsz=img_size
21 )
22
23if __name__ == "__main__":
24 main()脚本2: 评估YOLO模型
1# evaluate_yolo.py
2import os
3import torch
4from yolov5 import val
5
6def main():
7 data_yaml = 'path/to/config/data.yaml' # 包含数据集路径和类别的配置文件
8 weights = 'path/to/best.pt' # 训练好的模型权重
9 img_size = 224
10
11 val.run(
12 data=data_yaml,
13 weights=weights,
14 imgsz=img_size
15 )
16
17if __name__ == "__main__":
18 main()脚本3: 可视化标注
1# visualize_annotations.py
2import os
3import cv2
4import numpy as np
5
6def load_image_and_boxes(image_path, label_path):
7 # 读取图像
8 image = cv2.imread(image_path)
9
10 # 读取YOLO格式的txt标注文件
11 with open(label_path, 'r') as f:
12 lines = f.readlines()
13
14 boxes = []
15 for line in lines:
16 class_id, x_center, y_center, width, height = map(float, line.strip().split())
17 x_min = int((x_center - width / 2) * 224)
18 y_min = int((y_center - height / 2) * 224)
19 x_max = int((x_center + width / 2) * 224)
20 y_max = int((y_center + height / 2) * 224)
21 boxes.append([x_min, y_min, x_max, y_max])
22
23 return image, boxes
24
25def show_image_with_boxes(image, boxes):
26 for box in boxes:
27 x_min, y_min, x_max, y_max = box
28 cv2.rectangle(image, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
29 label = 'Crack'
30 cv2.putText(image, label, (x_min, y_min - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
31
32 cv2.imshow('Image with Boxes', image)
33 cv2.waitKey(0)
34 cv2.destroyAllWindows()
35
36def main():
37 images_dir = 'path/to/images/train'
38 labels_dir = 'path/to/labels/train'
39
40 # 获取图像列表
41 image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
42
43 # 随机选择一张图像
44 selected_image = np.random.choice(image_files)
45 image_path = os.path.join(images_dir, selected_image)
46 label_path = os.path.join(labels_dir, selected_image.replace('.jpg', '.txt'))
47
48 # 加载图像和边界框
49 image, boxes = load_image_and_boxes(image_path, label_path)
50
51 # 展示带有边界框的图像
52 show_image_with_boxes(image, boxes)
53
54if __name__ == "__main__":
55 main()脚本4: 数据增强
1# data_augmentation.py
2import os
3import cv2
4import numpy as np
5import albumentations as A
6
7def load_image_and_boxes(image_path, label_path):
8 # 读取图像
9 image = cv2.imread(image_path)
10
11 # 读取YOLO格式的txt标注文件
12 with open(label_path, 'r') as f:
13 lines = f.readlines()
14
15 boxes = []
16 for line in lines:
17 class_id, x_center, y_center, width, height = map(float, line.strip().split())
18 x_min = int((x_center - width / 2) * 224)
19 y_min = int((y_center - height / 2) * 224)
20 x_max = int((x_center + width / 2) * 224)
21 y_max = int((y_center + height / 2) * 224)
22 boxes.append([x_min, y_min, x_max, y_max, class_id])
23
24 return image, boxes
25
26def save_augmented_data(augmented_image, augmented_boxes, output_image_path, output_label_path):
27 # 保存增强后的图像
28 cv2.imwrite(output_image_path, augmented_image)
29
30 # 保存增强后的标注
31 with open(output_label_path, 'w') as f:
32 for box in augmented_boxes:
33 x_min, y_min, x_max, y_max, class_id = box
34 x_center = (x_min + x_max) / 2.0 / 224
35 y_center = (y_min + y_max) / 2.0 / 224
36 width = (x_max - x_min) / 224
37 height = (y_max - y_min) / 224
38 f.write(f"{class_id} {x_center} {y_center} {width} {height}\n")
39
40def augment_data(image, boxes):
41 transform = A.Compose([
42 A.RandomRotate90(p=0.5),
43 A.HorizontalFlip(p=0.5),
44 A.VerticalFlip(p=0.5),
45 A.RandomBrightnessContrast(p=0.2),
46 A.HueSaturationValue(p=0.2)
47 ], bbox_params=A.BboxParams(format='pascal_voc', label_fields=['category_ids']))
48
49 category_ids = [box[-1] for box in boxes]
50 bboxes = [box[:-1] for box in boxes]
51
52 transformed = transform(image=image, bboxes=bboxes, category_ids=category_ids)
53 transformed_image = transformed['image']
54 transformed_bboxes = transformed['bboxes']
55
56 return transformed_image, transformed_bboxes
57
58def main():
59 images_dir = 'path/to/images/train'
60 labels_dir = 'path/to/labels/train'
61 output_images_dir = 'path/to/augmented_images/train'
62 output_labels_dir = 'path/to/augmented_labels/train'
63
64 if not os.path.exists(output_images_dir):
65 os.makedirs(output_images_dir)
66
67 if not os.path.exists(output_labels_dir):
68 os.makedirs(output_labels_dir)
69
70 # 获取图像列表
71 image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
72
73 for image_file in image_files:
74 image_path = os.path.join(images_dir, image_file)
75 label_path = os.path.join(labels_dir, image_file.replace('.jpg', '.txt'))
76
77 # 加载图像和边界框
78 image, boxes = load_image_and_boxes(image_path, label_path)
79
80 # 增强数据
81 augmented_image, augmented_boxes = augment_data(image, boxes)
82
83 # 保存增强后的数据
84 output_image_path = os.path.join(output_images_dir, image_file)
85 output_label_path = os.path.join(output_labels_dir, image_file.replace('.jpg', '.txt'))
86 save_augmented_data(augmented_image, augmented_boxes, output_image_path, output_label_path)
87
88if __name__ == "__main__":
89 main()项目介绍
项目名称
基于YOLO的道路裂缝检测系统
项目描述
该项目旨在开发一个基于YOLO架构的道路裂缝检测系统。通过使用上述数据集,我们将训练一个高效的深度学习模型,能够在道路图像中实时检测裂缝。项目的主要目标是提高道路维护和管理的效率,同时为智能交通系统提供强大的视觉感知能力。
项目目标
- 实时检测:实现对道路图像中裂缝的实时检测。
- 高精度检测:能够准确地检测出不同大小和形状的裂缝。
- 鲁棒性:在不同天气条件、光照条件和背景下保持良好的检测性能。
- 易用性:提供易于部署和使用的接口,方便集成到现有的道路管理系统中。
项目结构
深色版本
1crack_detection_project/
2├── data/
3│ ├── crack_detection_dataset/
4│ │ ├── images/
5│ │ │ ├── train/
6│ │ │ ├── val/
7│ │ ├── labels/
8│ │ │ ├── train/
9│ │ │ ├── val/
10│ │ ├── scripts/
11│ │ ├── config/
12│ │ ├── requirements.txt
13│ │ └── README.md
14├── models/
15│ ├── yolov5s.pt # 预训练模型
16│ ├── best.pt # 最佳训练模型
17├── config/
18│ ├── data.yaml # 数据集配置文件
19│ ├── model.yaml # 模型配置文件
20├── scripts/
21│ ├── train_yolo.py
22│ ├── evaluate_yolo.py
23│ ├── visualize_annotations.py
24│ ├── data_augmentation.py
25│ ├── inference.py # 推理脚本
26├── notebooks/
27│ ├── data_exploration.ipynb # 数据探索笔记本
28│ ├── model_training.ipynb # 模型训练笔记本
29│ ├── model_evaluation.ipynb # 模型评估笔记本
30├── requirements.txt # 依赖库
31└── README.md # 项目说明文件项目流程
-
数据准备:
- 下载并解压数据集。
- 确认数据集已划分为训练集和验证集。
-
数据探索:
- 使用
data_exploration.ipynb笔记本探索数据集,了解数据分布和质量。
- 使用
-
数据增强:
- 使用
data_augmentation.py脚本对数据进行增强,增加数据多样性。
- 使用
-
模型训练:
- 使用
train_yolo.py脚本训练YOLO模型。 - 根据需要调整超参数和模型配置。
- 使用
-
模型评估:
- 使用
evaluate_yolo.py脚本评估模型性能。 - 生成混淆矩阵和分类报告。
- 使用
-
推理和应用:
- 使用
inference.py脚本进行实时检测。 - 将模型集成到道路管理系统或其他应用中。
- 使用
-
结果可视化:
- 使用
visualize_annotations.py脚本可视化检测结果。
- 使用
改进方向
如果您已经使用上述方法对该数据集进行了训练,并且认为还有改进空间,以下是一些可能的改进方向:
-
数据增强:
- 进一步增加数据增强策略,例如旋转、翻转、缩放、颜色抖动等,以提高模型的泛化能力。
- 使用混合增强技术,如MixUp、CutMix等,以增加数据多样性。
-
模型优化:
- 调整模型超参数,例如学习率、批量大小、优化器等,以找到最佳配置。
- 尝试使用不同的骨干网络(Backbone),例如EfficientNet、ResNet等,以提高特征提取能力。
- 引入注意力机制,如SENet、CBAM等,以增强模型对关键区域的关注。
-
损失函数:
- 尝试使用不同的损失函数,例如Focal Loss、IoU Loss等,以改善模型的收敛性能。
- 结合多种损失函数,例如分类损失和回归损失的组合,以平衡不同类型的任务。
-
后处理:
- 使用非极大值抑制(NMS)的改进版本,如Soft-NMS、DIoU-NMS等,以提高检测结果的质量。
- 引入边界框回归的改进方法,如GIoU、CIoU等,以提高定位精度。
-
迁移学习:
- 使用预训练模型进行微调,利用大规模数据集(如COCO、ImageNet)上的预训练权重,加快收敛速度并提高性能。
-
集成学习:
- 使用多个模型进行集成学习,通过投票或加权平均的方式提高最终的检测效果。
相关文章:
Crack道路裂缝检测数据集——目标检测数据集
【Crack道路裂缝检测数据集】共3684张。 目标检测数据集,标注文件为YOLO适用的txt格式。已划分为训练、验证集。 图片分辨率:224*224 类别:crack Crack道路裂缝检测数据集 数据集描述 该数据集是一个专门用于训练和评估基于YOLO࿰…...

10.3拉普拉斯金字塔
实验原理 拉普拉斯金字塔(Laplacian Pyramid)是一种图像表示方法,常被用于图像处理和计算机视觉领域。它是基于高斯金字塔的一种变换形式,主要用于图像融合、图像金字塔的构建等场景。下面简要介绍拉普拉斯金字塔的基本原理。 高…...
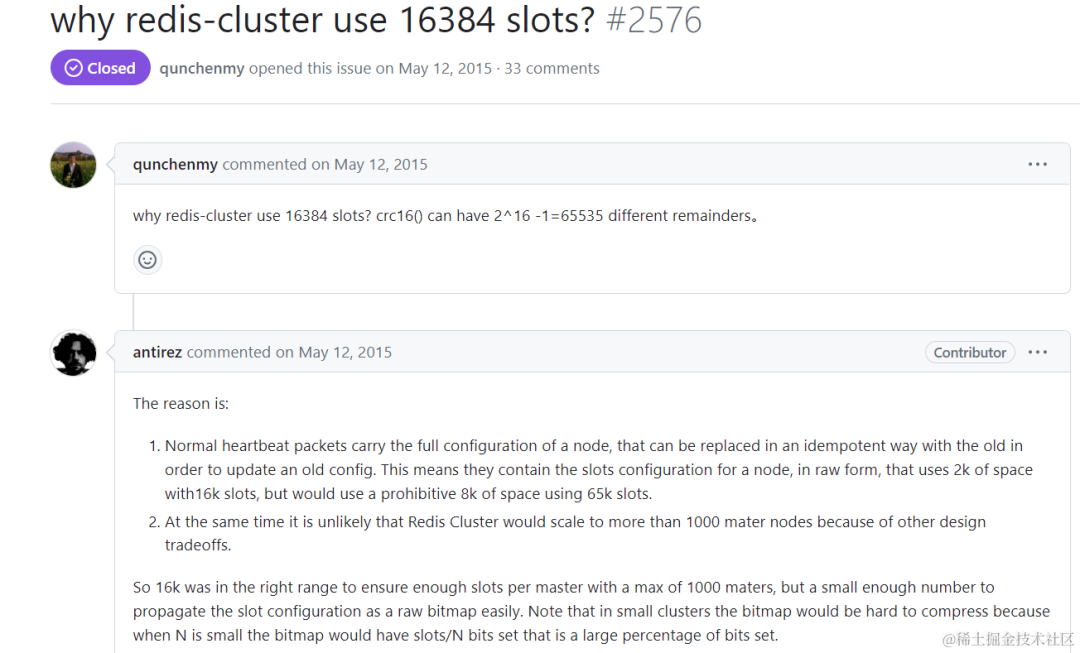
redis为什么不使用一致性hash
Redis节点间通信时,心跳包会携带节点的所有槽信息,它能以幂等方式来更新配置。如果采用 16384 个插槽,占空间 2KB (16384/8);如果采用 65536 个插槽,占空间 8KB (65536/8)。 今天我们聊个知识点为什么Redis使用哈希槽而不是一致性…...

Vue.js与Flask/Django后端配合
Vue.js与Flask/Django后端配合 在现代Web开发领域,前后端分离已成为一种流行的架构模式。Vue.js作为一款轻量级、高性能的前端框架,与Flask或Django这样的后端框架相结合,可以构建出强大且可扩展的Web应用。本文将详细介绍如何将Vue.js与Fla…...

ESP32 入门笔记02: ESP32-C3 系列( 芯片ESP32-C3FN4) (ESP-IDF + VSCode)
ESP32-C3 系列的 芯片 / 模组 / 开发板 ESP32-C3-DevKitM-1是乐鑫一款搭载 ESP32-C3-MINI-1 或 ESP32-C3-MINI-1U 模组的入门级开发板(内置 ESP32-C3FH4 或 ESP32-C3FN4 芯片)。 板上模组大部分管脚均已引出至两侧排针,可根据开发实际需求&a…...

Vue主题色实现
主题色实现 情境 配置平台支持多个主题色的选择,用户可通过在配置平台选择项目主题色。前端项目在骨架屏加载页面获取配置信息,设置项目主题色,实现同个项目不同主题色渲染的需求 实现 1.定义主题色变量 不同主题色根据不同js文件划分定…...

ChartLlama: A Multimodal LLM for Chart Understanding and Generation论文阅读
原文链接:https://arxiv.org/abs/2311.16483 代码与数据集:https://tingxueronghua.github.io/ChartLlama/ 本文启发:文章提出利用GPT-4合成大量图表数据,这些数据包含各种图表类型,包含丰富的instruction data。然后…...
:用户的登录注册)
ByteCinema(1):用户的登录注册
文章目录 主要功能生成图形验证码redis滑动窗口操作限流0.限流设计的必要性1.原理2.代码(邮箱发验证码为例)3. 问题与解决高并发环境下redis操作的原子性过时数据的积累 续约token实现长期登录0.设计的出发点1.前置知识:JWT什么是 JWT?JWT 的…...

电力电网电线变电站输电线绝缘子无人机类数据集/农业植物病虫害类数据集/光伏板/工程煤矿矿场类数据集/道路类数据集
电力电网电线变电站输电线红外缺陷类数据集 传送门链接: 1.电线覆盖物检测数据集 气球风筝鸟巢 1300张 voc yol-CSDN博客 2.变电站可见光缺陷数据集数据集包含8376张巡检图像,带xml标签,共包含17类巡检标签!具体缺陷分类见下图!…...

深度学习之表示学习 - 引言篇
序言 在数据爆炸的今天,如何从纷繁复杂的信息中抽取有价值的知识,成为了人工智能领域亟待解决的核心问题。深度学习,作为机器学习的一个重要分支,以其强大的特征表示能力和自动化学习特性,引领了这场数据革命的浪潮。…...

Linux驱动开发 ——架构体系
只读存储器(ROM) 1.作用 这是一种非易失性存储器,用于永久存储数据和程序。与随机存取存储器(RAM)不同,ROM中的数据在断电后不会丢失,通常用于存储固件和系统启动程序。它的内容在制造时或通过…...

Django一分钟:lookupAPI详解,使用django orm生成高效的WHERE子句
一、Lookup API概述 Lookup API是Django用于构建数据库查询WHERE子句的API。 Lookup API的核心包含两部分: RegisterLookupMixin:为子类提供注册lookup的方法Query Expression API:一个接口,规定了可以被注册为lookup的类需要实…...

信息安全工程师(8)网络新安全目标与功能
前言 网络新安全目标与功能在当前的互联网环境中显得尤为重要,它们不仅反映了网络安全领域的最新发展趋势,也体现了对网络信息系统保护的不断加强。 一、网络新安全目标 全面防护与动态应对: 目标:建立多层次、全方位的网络安全防…...

返利机器人在电商返利系统中的负载均衡实现
返利机器人在电商返利系统中的负载均衡实现 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天我们来聊一聊如何在电商返利系统中实现返利机器人的负载均衡,尤其是在面对高并发和大量…...

MATLAB中typecast函数用法
目录 语法 说明 示例 将整数转换为相同存储大小的无符号整数 将 8 位整数转换为单精度 将 32 位整数转换为 8 位整数 将 8 位整数转换为 16 位整数 提示 typecast函数的功能是在不更改基础数据的情况下转换数据类型。 语法 Y typecast(X,type) 说明 Y typecast(X,…...

植物大战僵尸【源代码分享+核心思路讲解】
植物大战僵尸已经正式完结,今天和大家分享一下,话不多说,直接上链接!!!(如果大家在运行这个游戏遇到了问题或者bug,那么请私我谢谢) 大家写的时候可以参考一下我的代码思…...

变压器设备漏油数据集 voc txt
变压器设备漏油数据集 油浸式变压器通常采用油浸自冷式、油浸风冷式和强迫油循环三种冷却方式。该数据集采集于油浸式变压器的设备漏油情况,一般用于变电站的无人巡检,代替传统的人工巡检,与绝缘子的破损检测来源于同一课题。数据集一部分来自…...

算法练习题25——leetcode3279统计重新排列后包含另一个字符串的子字符串的数目(滑动窗口 双指针 哈希)
题目描述 解题思路 本题用到了滑动窗口 双指针 哈希 刚开始我是没读懂题的因为我笨 我想把我的思路说一下 左端不轻易缩小 只有找到跟word2匹配了 比如说abbcdd 遍历到c的时候才能匹配这个word2 对吧 那么之后加上以一个d或者俩d 都符合了 然后我们算完了 才能缩小左端 扩大…...

JavaEE: 深入探索TCP网络编程的奇妙世界(二)
文章目录 TCP核心机制TCP核心机制二: 超时重传为啥会丢包?TCP如何对抗丢包?超时重传的时间设定超时时间该如何确定? TCP核心机制 前一篇文章 JavaEE: 深入探索TCP网络编程的奇妙世界(一) 书接上文~ TCP核心机制二: 超时重传 在网络传输中,并不会一帆风顺,而是可能出现&qu…...

GPT1-GPT3论文理解
GPT1-GPT3论文理解 视频参考:https://www.bilibili.com/video/BV1AF411b7xQ/?spm_id_from333.788&vd_sourcecdb0bc0dda1dccea0b8dc91485ef3e74 1 历史 2017.6 Transformer 2018.6 GPT 2018.10 BERT 2019.2 GPT-2 2020…...

2007 Text 3
2007 Text 3...

ToClaw把AI自动化门槛降到零?先看清它到底解决了什么,没解决什么
先说结论ToClaw的核心价值在于封装了OpenClaw的复杂部署与Token计费,通过云端算力和签到积分机制,让非技术用户也能快速体验AI自动化。它更适合处理文件整理、定时任务、文档生成等中低复杂度场景,但在需要深度自定义或私有化部署的高阶需求上…...

同一篇80%AI率的论文,3种方法降完效果对比
为了给同学一个有说服力的参考,我用同一篇论文做了一个完整对比实验: 同一篇知网AI率80%的论文(经济学,3万字),分别用3种方法处理,然后统一检测,看最终结果。 下面是完整数据。 论…...

新手怎么部署OpenClaw?2026年本地1分钟超速搭建OpenClaw及大模型百炼APIKey配置
新手怎么部署OpenClaw?2026年本地1分钟超速搭建OpenClaw及大模型百炼APIKey配置。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI…...

Multisim仿真固定偏置电路
Multisim仿真固定偏置电路 Multisim软件版本 依次点击帮助→关于 NI Multisim 14.0 Multisim Power Pro Edition Multisim中绘制电路图 元器件 电源VCC VCCNPN晶体管 BJT_NPN 2N2222A偏置电阻RB Resistor集电极电RC Resistor接地GND DGND 仿真 万用表测量电压结果 电流测…...

脉冲注入法与电感法无刷电机BLDC控制器方案
脉冲注入法,持续注入,启动低速运行过程中注入,电感法,ipd,力矩保持,无霍尔无感方案,媲美有霍尔效果。 bldc控制器方案,无刷电机。 提供源码,原理图。一、文档引言 本文基…...

中大型团队必备:6款高口碑研发资源管理平台汇总
本文将深入对比6款多维度研发资源管理系统:PingCode、Worktile、致远互联协同云、明道云、织信 Informat、TAPD 在研发成本日益攀升的今天,“人才利用率”已成为企业研发提效的核心指标。很多研发团队面临资源分配不透明、人才忙闲不均、多项目并行时资源…...

PowerToys Image Resizer:三步解决全场景图片批量处理难题
PowerToys Image Resizer:三步解决全场景图片批量处理难题 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/Power…...

如何使用 ECharts 绘制 K 线图
在金融数据可视化领域,K 线图(又称蜡烛图)是展示股票、期货等价格走势的核心工具。它通过矩形实体和上下影线直观呈现开盘价、收盘价、最高价和最低价,帮助投资者快速捕捉市场趋势。本文将结合 ECharts 的官方文档和实战案例&…...

2026最权威的十大AI科研工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI技术于毕业论文写作里的应用愈发广泛,借助大语言模型,学生能够在选…...