JSON合并工具
JSON合并工具
1. 项目概述
本项目旨在开发一个强大而灵活的JSON合并工具,能够合并多个JSON文件,处理复杂的嵌套结构,提供详细的合并报告,并实现全面的验证和错误处理机制。
2. 功能需求
2.1 基本合并功能
- 支持合并两个或多个JSON文件
- 处理嵌套的JSON结构
- 提供不同的合并策略选项(如覆盖、保留原值)
2.2 验证和错误处理
- JSON结构验证
- 数据类型一致性检查
- 文件大小限制检查
- 键名验证
- 详细的错误报告
- 警告系统
- 错误恢复机制
- 操作日志记录
2.3 合并报告生成
- 生成详细的合并过程报告
- 包含基本信息、合并统计、详细操作日志、警告和错误摘要、性能指标
2.4 多文件合并
- 支持任意数量的输入JSON文件
- 按指定顺序依次合并文件
- 为每个输入文件生成单独的统计信息
3. 技术设计
3.1 合并算法
使用递归方法处理嵌套的JSON结构:
- 遍历第二个JSON对象的所有键值对
- 如果键在第一个对象中不存在,直接添加
- 如果键存在且值都是字典,递归合并
- 如果键存在且值都是列表,合并列表
- 如果键存在但值类型不同,根据策略处理(覆盖或保留)
- 如果键存在且值类型相同,根据策略更新
3.2 验证机制
- JSON结构验证:使用json.loads()验证JSON格式
- 深度检查:递归检查JSON嵌套深度,设置最大深度限制
- 大小检查:在读取文件前检查文件大小
- 类型一致性:在合并过程中检查相同键的值类型
3.3 错误处理
- 使用try-except块捕获并处理异常
- 实现自定义异常类处理特定错误
- 使用logging模块记录警告和错误
- 对于非致命错误,提供继续处理的选项
3.4 报告生成
使用MergeReport类管理报告生成:
- 在合并过程中记录每个操作
- 统计新增、更新和冲突的键数量
- 记录警告和错误
- 生成性能指标(处理时间、内存使用)
- 格式化输出详细的报告
3.5 多文件处理
- 使用列表存储多个输入文件路径
- 逐个处理文件,将结果合并到一个主JSON对象中
- 在报告中分别记录每个文件的处理情况
3.6 命令行接口
使用argparse模块处理命令行参数:
- 输入文件路径(支持多个)
- 输出文件路径
- 合并策略选项
- 报告输出路径选项
4. 实现细节
4.1 主要类和函数
MergeReport类:管理报告生成merge_json()函数:实现JSON合并逻辑merge_json_files()函数:处理文件I/O和调用合并函数main()函数:处理命令行参数和orchestrate整个过程
4.2 数据结构
- 使用Python的字典表示JSON对象
- 使用列表存储多个输入文件路径
4.3 外部依赖
- json:用于JSON解析和序列化
- argparse:用于命令行参数处理
- logging:用于日志记录
- psutil:用于获取内存使用情况(可选)
5. 使用示例
python merge_json.py file1.json file2.json file3.json output.json --strategy overwrite --report merge_report.txt
6. 未来扩展
- 性能优化:实现流式处理或分块处理大文件
- 并行处理:使用多线程或多进程加速处理
- 配置文件:支持通过配置文件指定复杂的合并规则
- 可视化:生成合并过程的可视化表示
- GUI界面:开发图形用户界面,提高易用性
7. 结论
这个JSON合并工具提供了强大的功能,包括多文件合并、详细的报告生成、全面的验证和错误处理。考虑了灵活性和可扩展性,能够满足各种复杂的JSON合并需求。持续的优化和功能扩展,这个工具可以成为处理JSON数据的有力助手。
8.代码
import json
import sys
import os
import logging
import time
import argparse
from typing import Dict, Any, Listclass MergeReport:def __init__(self):self.start_time = time.time()self.total_keys = 0self.new_keys = 0self.updated_keys = 0self.conflict_keys = 0self.warnings = []self.errors = []self.detailed_log = []self.file_stats = {}def add_operation(self, file: str, key: str, operation: str, details: str = ""):self.detailed_log.append(f"{file} - {key}: {operation} - {details}")self.total_keys += 1if operation == "新增":self.new_keys += 1elif operation == "更新":self.updated_keys += 1elif operation == "冲突":self.conflict_keys += 1if file not in self.file_stats:self.file_stats[file] = {"新增": 0, "更新": 0, "冲突": 0}self.file_stats[file][operation] += 1def add_warning(self, message: str):self.warnings.append(message)def add_error(self, message: str):self.errors.append(message)def generate_report(self, input_files: List[str], output_file: str, strategy: str) -> str:end_time = time.time()process_time = end_time - self.start_timereport = f"""
合并报告
========基本信息:
- 合并时间: {time.strftime('%Y-%m-%d %H:%M:%S')}
- 输入文件:
{chr(10).join([' - ' + file for file in input_files])}
- 输出文件: {output_file}
- 合并策略: {strategy}合并统计:
- 总处理键数: {self.total_keys}
- 新增键数: {self.new_keys}
- 更新键数: {self.updated_keys}
- 冲突键数: {self.conflict_keys}文件统计:
"""for file, stats in self.file_stats.items():report += f"- {file}:\n"report += f" 新增: {stats['新增']}, 更新: {stats['更新']}, 冲突: {stats['冲突']}\n"report += f"""
详细操作日志:
{chr(10).join(self.detailed_log)}警告:
{chr(10).join(self.warnings) if self.warnings else "无"}错误:
{chr(10).join(self.errors) if self.errors else "无"}性能指标:
- 处理时间: {process_time:.2f} 秒
- 峰值内存使用: {self.get_peak_memory_usage()} MB"""return reportdef get_peak_memory_usage(self):import psutilprocess = psutil.Process(os.getpid())return process.memory_info().peak_wset / 1024 / 1024 # 转换为MBdef merge_json(data1: Dict[str, Any], data2: Dict[str, Any], strategy: str, report: MergeReport, file_name: str) -> Dict[str, Any]:result = data1.copy()for key, value in data2.items():if key in result:if isinstance(result[key], dict) and isinstance(value, dict):result[key] = merge_json(result[key], value, strategy, report, file_name)report.add_operation(file_name, key, "更新", "合并嵌套字典")elif isinstance(result[key], list) and isinstance(value, list):result[key] = result[key] + valuereport.add_operation(file_name, key, "更新", "合并列表")elif type(result[key]) != type(value):report.add_warning(f"类型不匹配: 文件 {file_name} 中的键 '{key}' 与现有数据类型不同")if strategy == 'overwrite':result[key] = valuereport.add_operation(file_name, key, "冲突", f"类型不匹配,使用新文件的值")else:report.add_operation(file_name, key, "冲突", f"类型不匹配,保留原值")elif strategy == 'overwrite':result[key] = valuereport.add_operation(file_name, key, "更新", "覆盖现有值")else:report.add_operation(file_name, key, "保留", "保留原有值")else:result[key] = valuereport.add_operation(file_name, key, "新增", "添加新键")return resultdef merge_json_files(input_files: List[str], output_file: str, strategy: str = 'overwrite') -> str:report = MergeReport()merged_data = {}try:for file in input_files:with open(file, 'r', encoding='utf-8') as f:data = json.load(f)merged_data = merge_json(merged_data, data, strategy, report, file)with open(output_file, 'w', encoding='utf-8') as out_file:json.dump(merged_data, out_file, ensure_ascii=False, indent=4)return report.generate_report(input_files, output_file, strategy)except Exception as e:report.add_error(f"合并过程中发生错误: {str(e)}")return report.generate_report(input_files, output_file, strategy)def main():parser = argparse.ArgumentParser(description="合并多个JSON文件并生成报告")parser.add_argument('input_files', nargs='+', type=str, help="输入JSON文件的路径列表")parser.add_argument('output', type=str, help="输出JSON文件的路径")parser.add_argument('--strategy', type=str, choices=['overwrite', 'keep'], default='overwrite',help="合并策略: 'overwrite' 覆盖重复键, 'keep' 保留原始值 (默认: overwrite)")parser.add_argument('--report', type=str, help="合并报告输出路径")args = parser.parse_args()try:report = merge_json_files(args.input_files, args.output, args.strategy)if args.report:with open(args.report, 'w', encoding='utf-8') as report_file:report_file.write(report)print(f"合并报告已保存到: {args.report}")else:print(report)except Exception as e:print(f"错误: {str(e)}")sys.exit(1)if __name__ == "__main__":main()
相关文章:

JSON合并工具
JSON合并工具 1. 项目概述 本项目旨在开发一个强大而灵活的JSON合并工具,能够合并多个JSON文件,处理复杂的嵌套结构,提供详细的合并报告,并实现全面的验证和错误处理机制。 2. 功能需求 2.1 基本合并功能 支持合并两个或多个…...

【网络编程】网页的显示过程
文章目录 1.URL 解析2.DNS 解析3.TCP三次握手4.服务器接收请求5.客户端接收响应 首先我们知道网页经过网络总共有应用层,传输层,网络层,数据链路层,物理层 1.URL 解析 将获得的网址解析出协议,主机名,域名…...

用nginx-rtmp-win32-master及ffmpeg模拟rtmp视频流
效果 使用nginx-rtmp-win32-master搭建RTMP服务 双击exe就可以了。切记整个目录不能有中文 README.md ,启用后本地的RTM路径: rtmp://192.168.1.186/live/xxx ffmpeg将地本地视频推RMTP F:\rtsp\ffmpeg-7.0.2-essentials_build\bin>ffmpeg -re -i F:\rtsp\123.mp4 -c c…...

使用python-pptx将PPT转换为图片:将每张幻灯片保存为单独的图片文件
哈喽,大家好,我是木头左! 本文将详细介绍如何使用python-pptx将PPT的每一张幻灯片保存为单独的图片文件。 安装python-pptx库 需要确保已经安装了python-pptx库。可以通过以下命令使用pip进行安装: pip install python-pptx导入所需库 接下来,需要导入一些必要的库,包…...

聊聊企业的低代码实践背景与成效
数字化转型的道路充满挑战是大家的普遍共识,许多企业仍未完全步入数字化的行列,它们面临的是系统的碎片化和操作的复杂性。在数字优先的今天,企业要想维持竞争力,比任何时期都更需要实施某种程度的数字化升级。如果一个组织难以提…...

zookeeper面试题
1. 什么是zookeeper zookeeper是一个开源的 分布式协调服务。他是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于Zookeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。 Zooke…...

Linux学习笔记13---GPIO 中断实验
中断系统是一个处理器重要的组成部分,中断系统极大的提高了 CPU 的执行效率,本章会将 I.MX6U 的一个 IO 作为输入中断,借此来讲解如何对 I.MX6U 的中断系统进行编程。 GIC 控制器简介 1、GIC 控制器总览 I.MX6U(Cortex-A)的中断控制器…...

[Redis][Hash]详细讲解
目录 0.前言1.常见命令1.HSET2.HGET3.HEXISTS4.HDEL5.HKEYS6.HVALS7.HGETALL8.HMGET9.HLEN10.HSETNX11.HINCRBY12.HINCRBYFLOAT 2.内部编码1.ziplist(压缩链表)2.hashtable(哈希表) 3.使用场景4.缓存方式对比1.原⽣字符串类型2.序列化字符串类型3.哈希类型 0.前言 在Redis中&am…...
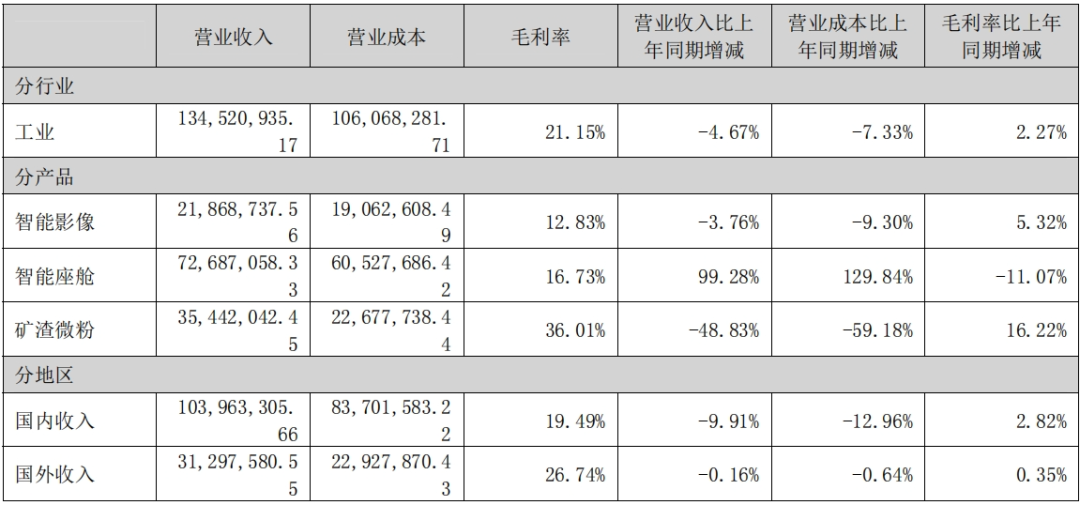
上半年亏损扩大/百亿资产重组终止,路畅科技如何“脱困”?
在智能网联汽车市场形势一片大好的前提下,路畅科技上半年的营收却出现了下滑,并且亏损也进一步扩大。 2024年半年度报告显示,路畅科技营业收入1.35亿元,同比下滑7.83%;实现归属上市公司股东的净利润为亏损2491.99万元…...

协议IP规定,576字节和1500字节的区别
576字节和1500字节的区别主要在于它们是IP数据报在数据链路层中的最大传输单元(MTU)的不同限制。 576字节:这个数值通常与IP层(网络层)的数据报有关,它指的是在不进行分片的情况下,IP数据…...

对抗攻击的详细解析:原理、方法与挑战
对抗攻击的详细解析:原理、方法与挑战 对抗攻击(Adversarial Attack)是现代机器学习模型,尤其是深度学习模型中的一个关键安全问题。其本质在于,通过对输入数据添加精微的扰动,人类难以察觉这些扰动&#…...

Python办公自动化教程(003):PDF的加密
【1】代码 from PyPDF2 import PdfReader, PdfWriter# 读取PDF文件 pdf_reader PdfReader(./file/Python教程_1.pdf) pdf_writer PdfWriter()# 对第1页进行加密 page pdf_reader.pages[0]pdf_writer.add_page(page) # 设置密码 pdf_writer.encrypt(3535)with open(./file/P…...

python全栈学习记录(十七)logging、json与pickle、time与datatime、random
logging、json与pickle、time与datatime、random 文章目录 logging、json与pickle、time与datatime、random一、logging二.json与pickle三.time与datatime四.random 一、logging logging模块用来记录日志信息。 import logging # 进行基本的日志配置 logging.basicConfig( fi…...

【艾思科蓝】JavaScript在数据可视化领域的探索与实践
【ACM出版 | EI快检索 | 高录用】2024年智能医疗与可穿戴智能设备国际学术会议(SHWID 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看 学术会议-学术交流征稿-学术会议在线-艾思科蓝 目录 引言 JavaScript可视化库概览 D3.js基础入门 1. 引入…...

【标准库的典型内容】std::declval
一、 d e c l v a l declval declval的基本概念和常规范例 s t d : : d e c l v a l std::declval std::declval 是 C 11 C11 C11标准中出现的一个函数模板。这个函数模板设计的比较奇怪(没有实现,只有声明),因此无法被调用&…...

深入了解package.json文件
在前端项目开发中,我们经常会遇到package.json文件。这个文件不仅是一个简单的配置文件,它还承担了项目管理的重任。下面,我们将深入探讨package.json文件的各个字段和作用,并通过实例来帮助你更好地理解和使用它。 package.json…...

【基础知识】网络套接字编程
套接字 IP地址 port(端口号) socket(套接字) socket常见API //创建套接字 int socket(int domain, int type, int protocol); //绑定端口 int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); //监听套接字…...

小程序地图展示poi帖子点击可跳转
小程序地图展示poi帖子点击可跳转 是类似于小红书地图功能的需求 缺点 一个帖子只能有一个点击事件,不适合太复杂的功能,因为一个markers只有一个回调回调中只有markerId可以使用。 需求介绍 页面有地图入口,点开可打开地图界面地图上展…...

传统到AI 大数据分析的演变,颠覆智慧水电的未来?
传统到AI 大数据分析的演变,颠覆智慧水电的未来? 前言传统到AI 大数据分析的演变 前言 水电作为一种重要的能源形式,一直在我们的生活中扮演着至关重要的角色。而如今,随着科技的飞速发展,智慧水电和 AI 大数据应用的…...

while语句
1.while使用 打印1-10 #include<stdio.h> int main() {int a 1;while (10 > a){printf("%d\n", a);a 1;}return 0; } 2.while语句中的break,continue break: 跳出while语句 #include<stdio.h> int main() {int a 0;wh…...

折叠Cascode运放设计避坑指南:从90dB增益掉到60dB?可能是这5个细节没做好
折叠Cascode运放设计避坑指南:从90dB增益掉到60dB?可能是这5个细节没做好 在模拟IC设计的深水区,折叠Cascode运算放大器就像一位优雅的芭蕾舞者——看似轻盈的架构下隐藏着对每个技术细节的极致把控。当您精心设计的电路从仿真器中吐出60dB增…...
的血泪史与终极方案)
树莓派3B上跑通Apriltag识别:老设备配置Python环境(OpenCV+pupil_apriltags)的血泪史与终极方案
树莓派3B上跑通Apriltag识别:老设备配置Python环境(OpenCVpupil_apriltags)的血泪史与终极方案 当你在二手市场淘到一台树莓派3B,满心欢喜地想用它搭建一个视觉导航机器人时,现实往往会给你当头一棒。这款2016年发布的…...

如何彻底解决《神界:原罪2》模组冲突问题:Divinity Mod Manager 专业指南
如何彻底解决《神界:原罪2》模组冲突问题:Divinity Mod Manager 专业指南 【免费下载链接】DivinityModManager A mod manager for Divinity: Original Sin - Definitive Edition. 项目地址: https://gitcode.com/gh_mirrors/di/DivinityModManager …...
)
告别集群负载:用Docker Compose在外部机器部署Prometheus+Grafana监控K8S(附完整配置文件)
轻量化监控方案:Docker Compose 部署 PrometheusGrafana 监控 Kubernetes 集群 对于资源有限的中小团队或个人开发者来说,将监控系统与业务集群分离是一个明智的选择。传统的 Kubernetes 监控方案通常将 Prometheus 和 Grafana 部署在集群内部࿰…...

BIN文件操作指南:从字节视角到实战应用
1. 项目概述:为什么我们需要系统性地掌握BIN文件操作?在嵌入式开发、固件逆向、游戏修改乃至数据恢复这些领域里,我们经常会遇到一个后缀名为.bin的文件。很多新手朋友第一次接触时可能会有点懵,这既不是文本文件可以直接打开看&a…...

如何高效设计无刷直流电机控制器:Simscape Electrical完整解决方案指南
如何高效设计无刷直流电机控制器:Simscape Electrical完整解决方案指南 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Simsc…...

FFmpeg Batch AV Converter 实战指南:告别命令行,拥抱高效视频批量处理
FFmpeg Batch AV Converter 实战指南:告别命令行,拥抱高效视频批量处理 【免费下载链接】ffmpeg_batch FFmpeg Batch AV Converter 项目地址: https://gitcode.com/gh_mirrors/ff/ffmpeg_batch FFmpeg Batch AV Converter是一款强大的图形界面视频…...

保姆级教程:用HACS给追觅扫地机装Home Assistant插件,实现iPhone家庭App远程分区清扫
零门槛实现追觅扫地机HomeKit分区控制:HACS插件全流程指南 在智能家居生态中,苹果HomeKit以其出色的隐私保护和流畅的跨设备联动体验,成为许多iPhone用户的首选。但对于使用追觅X10/X20等型号扫地机的用户来说,官方App并未提供与…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...

CANN Ascend C数据转换临时空间API
GetTransDataMaxMinTmpSize 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: http…...