【protobuf】ProtoBuf的学习与使用⸺C++

W...Y的主页 😊
代码仓库分享💕
 前言:之前我们学习了Linux与windows的protobuf安装,知道protobuf是做序列化操作的应用,今天我们来学习一下protobuf。
前言:之前我们学习了Linux与windows的protobuf安装,知道protobuf是做序列化操作的应用,今天我们来学习一下protobuf。
目录
⼀、初识ProtoBuf
步骤1:创建.proto文件
步骤2:编译contacts.proto⽂件,⽣成C++⽂件
步骤3:序列化与反序列化的使用
二、proto3语法详解
1. 字段规则
2. 消息类型的定义与使用
3. enum类型
4. Any类型
5. oneof类型
6. map类型
7. 默认值
8. 更新消息
9. 选项option
三、总结
⼀、初识ProtoBuf
对ProtoBuf的完整学习,将使⽤项⽬推进的⽅式完成教学:即对于ProtoBuf知识内容的展开,会对
⼀个项⽬进⾏⼀个版本⼀个版本的升级去讲解ProtoBuf对应的知识点。
在后续的内容中,将会实现⼀个通讯录项⽬。对通讯录⼤家应该都不陌⽣,⼀般,通讯录中包含了⼀批的联系⼈,每个联系⼈⼜会有很多的属性,例如姓名、电话等等。
步骤1:创建.proto文件

创建.proto文件
⽂件规范
• 创建.proto⽂件时,⽂件命名应该使⽤全⼩写字⺟命名,多个字⺟之间⽤_ 连接。例如:lower_snake_case.proto 。
• 书写.proto⽂件代码时,应使⽤2个空格的缩进。我们为通讯录1.0新建⽂件:contacts.proto。
指定proto3语法
Protocol Buffers语⾔版本3,简称proto3,是.proto⽂件最新的语法版本。proto3简化了Protocol
Buffers语⾔,既易于使⽤,⼜可以在更⼴泛的编程语⾔中使⽤。它允许你使⽤Java,C++,Python等多种语⾔⽣成?protocolbuffer代码。
在.proto⽂件中,要使⽤ syntax = "proto3"; 来指定⽂件语法为proto3,并且必须写在除去注释内容的第⼀⾏。如果没有指定,编译器会使⽤proto2语法。在通讯录1.0的contacts.proto⽂件中,可以为⽂件指定proto3语法,内容如下:
syntax = "proto3"; package声明符
package是⼀个可选的声明符,能表⽰.proto⽂件的命名空间,在项⽬中要有唯⼀性。它的作⽤是为了避免我们定义的消息出现冲突。
在通讯录1.0的contacts.proto⽂件中,可以声明其命名空间,内容如下:
syntax = "proto3";
package contacts;定义消息(message)
消息(message):要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容。这⾥再提⼀下为什么要定义消息
在⽹络传输中,我们需要为传输双⽅定制协议。定制协议说⽩了就是定义结构体或者结构化数据,
⽐如,tcp,udp报⽂就是结构化的。
再⽐如将数据持久化存储到数据库时,会将⼀系列元数据统⼀⽤对象组织起来,再进⾏存储。所以ProtoBuf就是以message的⽅式来⽀持我们定制协议字段,后期帮助我们形成类和⽅法来使⽤。在通讯录1.0中我们就需要为联系⼈定义⼀个message。.proto⽂件中定义⼀个消息类型的格式为:
message 消息类型名{
}
消息类型命名规范:使⽤驼峰命名法,⾸字⺟⼤写。为contacts.proto(通讯录1.0)新增联系⼈message,内容如下:
syntax = "proto3";
package contacts;
// 定义联系⼈消息
message PeopleInfo {}定义消息字段
在message中我们可以定义其属性字段,字段定义格式为:字段类型字段名=字段唯⼀编号;
• 字段名称命名规范:全⼩写字⺟,多个字⺟之间⽤ _ 连接。
• 字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
• 字段唯⼀编号:⽤来标识字段,⼀旦开始使⽤就不能够再改变。
该表格展⽰了定义于消息体中的标量数据类型,以及编译.proto⽂件之后⾃动⽣成的类中与之对应的字段类型。在这⾥展⽰了与C++语⾔对应的类型。
| .protoType | Notes | C++ Type |
| double | double | |
| float | float | |
| int32 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可能为负值,应使⽤sint32代替 | int32 |
| int64 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可能为负值,应使⽤sint64代替 | int64 |
| uint32 | 使⽤变⻓编码[1] | uint32 |
| uint64 | 使⽤变⻓编码[1] | uint64 |
| sint32 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于常规的int32类型 | int32 |
| sint64 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于常规的int64类型 | int64 |
| fixed32 | 定⻓4字节。若值常⼤于2^28则会⽐uint32更⾼效。 | uint32 |
| fixed64 | 定⻓8字节。若值常⼤于2^56则会⽐uint64更⾼效。 | uint64 |
| sfixed32 | 定⻓4字节 | int32 |
| sfixed64 | 定⻓8字节 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,⻓度不能超过2^32 | string |
| bytes | 可包含任意的字节序列但⻓度不能超过2^32 | string |
[1]变⻓编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数。
更新contacts.proto(通讯录?1.0),新增姓名、年龄字段:
syntax = "proto3";
package contacts;
message PeopleInfo {
string name = 1;
int32 age = 2;
}在这⾥还要特别讲解⼀下字段唯⼀编号的范围:
1~536,870,911(2^29-1),其中19000~19999不可⽤。
19000~19999不可⽤是因为:在Protobuf协议的实现中,对这些数进⾏了预留。如果⾮要在.proto
⽂件中使⽤这些预留标识号,例如将name字段的编号设置为19000,编译时就会报警:
// 消息中定义了如下编号,代码会告警:
// Field numbers 19,000 through 19,999 are reserved for the protobuf
implementation
string name = 19000;值得⼀提的是,范围为1~15的字段编号需要⼀个字节进⾏编码,16~2047内的数字需要两个字节
进⾏编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以1~15要⽤来标记出现⾮常频繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来。
步骤2:编译contacts.proto⽂件,⽣成C++⽂件
编译contacts.proto⽂件,⽣成C++⽂件
编译命令
编译命令⾏格式为:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
protoc 是 Protocol Buffer 提供的命令⾏编译⼯具。
--proto_path 指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -I
IMPORT_PATH 。如不指
定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他
.proto ⽂件时,
或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索⽬
录。
--cpp_out= 指编译后的⽂件为 C++ ⽂件。
OUT_DIR 编译后⽣成⽂件的⽬标路径。
path/to/file.proto 要编译的.proto⽂件。编译contacts.proto⽂件命令如下:
protoc --cpp_out=. contacts.proto 编译contacts.proto⽂件后会⽣成什么
编译contacts.proto⽂件后,会⽣成所选择语⾔的代码,我们选择的是C++,所以编译后⽣成了两个
⽂件: contacts.pb.h contacts.pb.cc 。
对于编译⽣成的C++代码,包含了以下内容:
• 对于每个message,都会⽣成⼀个对应的消息类。
• 在消息类中,编译器为每个字段提供了获取和设置⽅法,以及⼀下其他能够操作字段的⽅法。
• 编辑器会针对于每个 .proto ⽂件⽣成 .h 和 .cc ⽂件,分别⽤来存放类的声明与类的实现。contacts.pb.h部分代码展⽰
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const PeopleInfo& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const PeopleInfo& from) {
PeopleInfo::MergeImpl(*this, from);
}
static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {
return "PeopleInfo";
}
// string name = 1;
void clear_name();
const std::string& name() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_name(ArgT0&& arg0, ArgT... args);
std::string* mutable_name();
PROTOBUF_NODISCARD std::string* release_name();
void set_allocated_name(std::string* name);
// int32 age = 2;
void clear_age();
int32_t age() const;
void set_age(int32_t value);
}; 上述的例⼦中:
• 每个字段都有设置和获取的⽅法,getter的名称与⼩写字段完全相同,setter⽅法以set_开头。
• 每个字段都有⼀个clear_⽅法,可以将字段重新设置回empty状态contacts.pb.cc中的代码就是对类声明⽅法的⼀些实现,在这⾥就不展开了。
到这⾥有同学可能就有疑惑了,那之前提到的序列化和反序列化⽅法在哪⾥呢?在消息类的⽗类
MessageLite 中,提供了读写消息实例的⽅法,包括序列化⽅法和反序列化⽅法。
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写⼊⽂件
流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进⾏反序列化
动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
}; 注意:
• 序列化的结果为⼆进制字节序列,⽽⾮⽂本格式。
• 以上三种序列化的⽅法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使⽤。
• 序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,⽽是将序列化的结果
保存到函数⼊参指定的地址中。
• 详细message API可以参⻅完整列表。
步骤3:序列化与反序列化的使用
创建⼀个测试⽂件main.cc,⽅法中我们实现:
• 对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
• 对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
main.cc
#include <iostream>
#include "contacts.pb.h" // 引⼊编译⽣成的头⽂件
using namespace std;
int main() {
string people_str;
{
// .proto⽂件声明的package,通过protoc编译后,会为编译⽣成的C++代码声明同名的
命名空间
// 其范围是在.proto ⽂件中定义的内容
contacts::PeopleInfo people;
people.set_age(20);
people.set_name("张珊");
// 调⽤序列化⽅法,将序列化后的⼆进制序列存⼊string中
if (!people.SerializeToString(&people_str)) {
cout << "序列化联系⼈失败." << endl;
}
// 打印序列化结果
cout << "序列化后的 people_str: " << people_str << endl;
}
{
contacts::PeopleInfo people;
// 调⽤反序列化⽅法,读取string中存放的⼆进制序列,并反序列化出对象
if (!people.ParseFromString(people_str)) {
cout << "反序列化出联系⼈失败." << endl;
}
// 打印结果
cout << "Parse age: " << people.age() << endl;
cout << "Parse name: " << people.name() << endl;
}
}代码书写完成后,编译main.cc,⽣成可执⾏程序TestProtoBuf:
g++ main.cc contacts.pb.cc -o TestProtoBuf -std=c++11 -lprotobuf • -lprotobuf:必加,不然会有链接错误。
• -std=c++11:必加,使⽤C++11语法。
执⾏ TestProtoBuf ,可以看⻅people经过序列化和反序列化后的结果:
why@139-159-150-152:~/protobuf$ ./TestProtoBuf
序列化后的 people_str:
张珊
Parse age: 20
Parse name: 张珊由于ProtoBuf是把联系⼈对象序列化成了⼆进制序列,这⾥⽤string来作为接收⼆进制序列的容器。所以在终端打印的时候会有换⾏等⼀些乱码显⽰。
所以相对于xml和JSON来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf编码是相对安全的
 ProtoBuf是需要依赖通过编译⽣成的头⽂件和源⽂件来使⽤的。
ProtoBuf是需要依赖通过编译⽣成的头⽂件和源⽂件来使⽤的。
二、proto3语法详解

在语法详解部分,依旧使⽤项⽬推进的⽅式。这个部分会对通讯录进⾏多次升级,使⽤2.x表⽰升级的版本,最终将会升级如下内容:
• 不再打印联系⼈的序列化结果,⽽是将通讯录序列化后并写⼊⽂件中。
• 从⽂件中将通讯录解析出来,并进⾏打印。
• 新增联系⼈属性,共包括:姓名、年龄、电话信息、地址、其他联系⽅式、备注。
1. 字段规则
消息的字段可以⽤下⾯⼏种规则来修饰:
• singular:消息中可以包含该字段零次或⼀次(不超过⼀次)。proto3语法中,字段默认使⽤该
规则。
• repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理
解为定义了⼀个数组。
更新contacts.proto, PeopleInfo 消息中新增 phone_numbers 字段,表⽰⼀个联系⼈有多个
号码,可将其设置为repeated,写法如下:
syntax = "proto3";
package contacts;
message PeopleInfo {
string name = 1;
int32 age = 2;
repeated string phone_numbers = 3;
}2. 消息类型的定义与使用
2.1 定义
在单个.proto⽂件中可以定义多个消息体,且⽀持定义嵌套类型的消息(任意多层)。每个消息体中的字段编号可以重复。
更新contacts.proto,我们可以将phone_number提取出来,单独成为⼀个消息:
// -------------------------- 嵌套写法 -------------------------
syntax = "proto3";
package contacts;
message PeopleInfo {
string name = 1;
int32 age = 2;
message Phone {
string number = 1;
}
}
// -------------------------- ⾮嵌套写法 -------------------------
syntax = "proto3";
package contacts;
message Phone {
string number = 1;
}
message PeopleInfo {
string name = 1;
int32 age = 2;
}2.2 使⽤
• 消息类型可作为字段类型使⽤
contacts.proto
syntax = "proto3";
package contacts;
// 联系⼈
message PeopleInfo {
string name = 1;
int32 age = 2;
message Phone {
string number = 1;
}
repeated Phone phone = 3;
}可导⼊其他.proto⽂件的消息并使⽤
例如Phone消息定义在phone.proto⽂件中:
syntax = "proto3";
package phone;
message Phone {
string number = 1;
}contacts.proto中的 PeopleInfo 使⽤Phone 消息:
syntax = "proto3";
package contacts;
import "phone.proto"; // 使⽤ import 将 phone.proto ⽂件导⼊进来 !!!
message PeopleInfo {
string name = 1;
int32 age = 2;
// 引⼊的⽂件声明了package,使⽤消息时,需要⽤ ‘命名空间.消息类型’ 格式
repeated phone.Phone phone = 3;
}注:在proto3⽂件中可以导⼊proto2消息类型并使⽤它们,反之亦然。
2.3 创建通讯录2.0版本
通讯录2.x的需求是向⽂件中写⼊通讯录列表,以上我们只是定义了⼀个联系⼈的消息,并不能存放通讯录列表,所以还需要在完善⼀下contacts.proto(终版通讯录2.0):
syntax = "proto3";
package contacts;
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}接着进⾏⼀次编译,编译后⽣成的 contacts.pb.h contacts.pb.cc 会将在快速上⼿的⽣成⽂件覆盖掉。contacts.pb.h更新的部分代码展示:
// 新增了 PeopleInfo_Phone 类
class PeopleInfo_Phone final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const PeopleInfo_Phone& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const PeopleInfo_Phone& from) {
PeopleInfo_Phone::MergeImpl(*this, from);
}
static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {
return "PeopleInfo.Phone";
}
// string number = 1;
void clear_number();
const std::string& number() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_number(ArgT0&& arg0, ArgT... args);
std::string* mutable_number();
PROTOBUF_NODISCARD std::string* release_number();
void set_allocated_number(std::string* number);
};
// 更新了 PeopleInfo 类
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const PeopleInfo& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const PeopleInfo& from) {
PeopleInfo::MergeImpl(*this, from);
}
static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {
return "PeopleInfo";
}
typedef PeopleInfo_Phone Phone;
// repeated .PeopleInfo.Phone phone = 3;
int phone_size() const;
void clear_phone();
::PeopleInfo_Phone* mutable_phone(int index);
::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::PeopleInfo_Phone >*
mutable_phone();
const ::PeopleInfo_Phone& phone(int index) const;
::PeopleInfo_Phone* add_phone();
const ::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::PeopleInfo_Phone >&
phone() const;
};
// 新增了 Contacts 类
class Contacts final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const Contacts& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const Contacts& from) {
Contacts::MergeImpl(*this, from);
}
static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {
return "Contacts";
}
// repeated .PeopleInfo contacts = 1;
int contacts_size() const;
void clear_contacts();
::PeopleInfo* mutable_contacts(int index);
::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::PeopleInfo >*
mutable_contacts();
const ::PeopleInfo& contacts(int index) const;
::PeopleInfo* add_contacts();
const ::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::PeopleInfo >&
contacts() const;
};上述的例⼦中:
• 每个字段都有⼀个clear_⽅法,可以将字段重新设置回empty状态。
• 每个字段都有设置和获取的⽅法,获取⽅法的⽅法名称与⼩写字段名称完全相同。但如果是消息
类型的字段,其设置⽅法为mutable_⽅法,返回值为消息类型的指针,这类⽅法会为我们开辟
好空间,可以直接对这块空间的内容进⾏修改。
• 对于使⽤repeated修饰的字段,也就是数组类型,pb为我们提供了add_⽅法来新增⼀个值,
并且提供了_size⽅法来判断数组存放元素的个数。
2.3.1 通讯录2.0的写⼊实现
write.cc(通讯录2.0)
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
using namespace contacts;
/**
* 新增联系⼈
*/
void AddPeopleInfo(PeopleInfo *people_info_ptr)
{
cout << "-------------新增联系⼈-------------" << endl;
cout << "请输⼊联系⼈姓名: ";
string name;
getline(cin, name);
people_info_ptr->set_name(name);
cout << "请输⼊联系⼈年龄: ";
int age;
cin >> age;
people_info_ptr->set_age(age);
cin.ignore(256, '\n');
for(int i = 1; ; i++) {
cout << "请输⼊联系⼈电话" << i << "(只输⼊回⻋完成电话新增): ";
string number;
getline(cin, number);
if (number.empty()) {
break;
}
PeopleInfo_Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
}
cout << "-----------添加联系⼈成功-----------" << endl;
}
int main(int argc, char *argv[])
{
/ GOOGLE_PROTOBUF_VERIFY_VERSION 宏: 验证没有意外链接到与编译的头⽂件不兼容的库版
本。如果检测到版本不匹配,程序将中⽌。注意,每个 .pb.cc ⽂件在启动时都会⾃动调⽤此宏。在使
⽤ C++ Protocol Buffer 库之前执⾏此宏是⼀种很好的做法,但不是绝对必要的。
GOOGLE_PROTOBUF_VERIFY_VERSION;
if (argc != 2)
{
cerr << "Usage: " << argv[0] << " CONTACTS_FILE" << endl;
return -1;
}
Contacts contacts;
// 先读取已存在的 contacts
fstream input(argv[1], ios::in | ios::binary);
if (!input) {
cout << argv[1] << ": File not found. Creating a new file." << endl;
}
else if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 新增⼀个联系⼈
AddPeopleInfo(contacts.add_contacts());
// 向磁盘⽂件写⼊新的 contacts
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
if (!contacts.SerializeToOstream(&output))
{
cerr << "Failed to write contacts." << endl;
input.close();
output.close();
return -1;
}
input.close();
output.close();
// 在程序结束时调⽤ ShutdownProtobufLibrary(),为了删除 Protocol Buffer 库分配的所
有全局对象。对于⼤多数程序来说这是不必要的,因为该过程⽆论如何都要退出,并且操作系统将负责
回收其所有内存。但是,如果你使⽤了内存泄漏检查程序,该程序需要释放每个最后对象,或者你正在
编写可以由单个进程多次加载和卸载的库,那么你可能希望强制使⽤ Protocol Buffers 来清理所有
内容。
google::protobuf::ShutdownProtobufLibrary();
return 0;
}2.3.2 通讯录2.0的读取实现
read.cc(通讯录2.0)
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
using namespace contacts;
/**
* 打印联系⼈列表
*/
void PrintfContacts(const Contacts& contacts) {
for (int i = 0; i < contacts.contacts_size(); ++i) {
const PeopleInfo& people = contacts.contacts(i);
cout << "------------联系⼈" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
int j = 1;
for (const PeopleInfo_Phone& phone : people.phone()) {
cout << "电话" << j++ << ": " << phone.number() << endl;
}
}
}
int main(int argc, char* argv[]) {
GOOGLE_PROTOBUF_VERIFY_VERSION;
if (argc != 2) {
cerr << "Usage: " << argv[0] << "CONTACTS_FILE" << endl;
return -1;
}
// 以⼆进制⽅式读取 contacts
Contacts contacts;
fstream input(argv[1], ios::in | ios::binary);
if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 打印 contacts
PrintfContacts(contacts);
input.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
} 另⼀种验证⽅法--decode
我们可以⽤ protoc -h 命令来查看ProtoBuf为我们提供的所有命令option。其中ProtoBuf提供
⼀个命令选项 --decode ,表⽰从标准输⼊中读取给定类型的⼆进制消息,并将其以⽂本格式写⼊
标准输出。消息类型必须在.proto⽂件或导⼊的⽂件中定义。
3. enum类型
3.1 定义规则
语法⽀持我们定义枚举类型并使⽤。在.proto⽂件中枚举类型的书写规范为:
枚举类型名称:
使⽤驼峰命名法,⾸字⺟⼤写。例如: MyEnum
常量值名称:
全⼤写字⺟,多个字⺟之间⽤ _ 连接。例如: ENUM_CONST = 0;
我们可以定义⼀个名为PhoneType的枚举类型,定义如下:
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}要注意枚举类型的定义有以下⼏种规则:
1. 0值常量必须存在,且要作为第⼀个元素。这是为了与proto2的语义兼容:第⼀个元素作为默认
值,且值为0。
2. 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
3. 枚举的常量值在32位整数的范围内。但因负值⽆效因⽽不建议使⽤(与编码规则有关)。
将两个‘具有相同枚举值名称’的枚举类型放在单个.proto⽂件下测试时,编译后会报错:某某某常
量已经被定义!所以这⾥要注意:
• 同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
• 单个.proto⽂件下,最外层枚举类型和嵌套枚举类型,不算同级。
• 多个.proto⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都未声明package,每个proto⽂
件中的枚举类型都在最外层,算同级。
• 多个.proto⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都声明了package,不算同级。
// ---------------------- 情况1:同级枚举类型包含相同枚举值名称--------------------
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
enum PhoneTypeCopy {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
}
// ---------------------- 情况2:不同级枚举类型包含相同枚举值名称-------------------
-
enum PhoneTypeCopy {
MP = 0; // 移动电话 // ⽤法正确
}
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
}
// ---------------------- 情况3:多⽂件下都未声明package--------------------
// phone1.proto
import "phone1.proto"
enum PhoneType {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
TEL = 1; // 固定电话
}
// phone2.proto
enum PhoneTypeCopy {
MP = 0; // 移动电话
}
// ---------------------- 情况4:多⽂件下都声明了package--------------------
// phone1.proto
import "phone1.proto"
package phone1;
enum PhoneType {
MP = 0; // 移动电话 // ⽤法正确
TEL = 1; // 固定电话
}
// phone2.proto
package phone2;
enum PhoneTypeCopy {
MP = 0; // 移动电话
}更新contacts.proto(通讯录?2.1),新增枚举字段并使⽤,更新内容如下 :
syntax = "proto3";
package contacts;
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}
contacts.pb.h更新的部分代码展⽰:
/ 新⽣成的 PeopleInfo_Phone_PhoneType 枚举类
enum PeopleInfo_Phone_PhoneType : int {
PeopleInfo_Phone_PhoneType_MP = 0,
PeopleInfo_Phone_PhoneType_TEL = 1,
PeopleInfo_Phone_PhoneType_PeopleInfo_Phone_PhoneType_INT_MIN_SENTINEL_DO_NOT_U
SE_ = std::numeric_limits<int32_t>::min(),
PeopleInfo_Phone_PhoneType_PeopleInfo_Phone_PhoneType_INT_MAX_SENTINEL_DO_NOT_U
SE_ = std::numeric_limits<int32_t>::max()
};
// 更新的 PeopleInfo_Phone 类
class PeopleInfo_Phone final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
typedef PeopleInfo_Phone_PhoneType PhoneType;
static inline bool PhoneType_IsValid(int value) {
return PeopleInfo_Phone_PhoneType_IsValid(value);
}
template<typename T>
static inline const std::string& PhoneType_Name(T enum_t_value) {...}
static inline bool PhoneType_Parse(
::PROTOBUF_NAMESPACE_ID::ConstStringParam name, PhoneType* value) {...}
// .contacts.PeopleInfo.Phone.PhoneType type = 2;
void clear_type();
::contacts::PeopleInfo_Phone_PhoneType type() const;
void set_type(::contacts::PeopleInfo_Phone_PhoneType value);
}; 上述的代码中:
• 对于在.proto⽂件中定义的枚举类型,编译⽣成的代码中会含有与之对应的枚举类型、校验枚举
值是否有效的⽅法_IsValid、以及获取枚举值名称的⽅法_Name。
• 对于使⽤了枚举类型的字段,包含设置和获取字段的⽅法,已经清空字段的⽅法clear_。
更新write.cc部分代码:
cout << "选择此电话类型 (1、移动电话 2、固定电话) : " ;
int type;
cin >> type;
cin.ignore(256, '\n');
switch (type) {
case 1:
phone-
>set_type(PeopleInfo_Phone_PhoneType::PeopleInfo_Phone_PhoneType_MP);
break;
case 2:
phone-
>set_type(PeopleInfo_Phone_PhoneType::PeopleInfo_Phone_PhoneType_TEL);
break;
default:
cout << "⾮法选择,使⽤默认值!" << endl;
break;
}
}
cout << "-----------添加联系⼈成功-----------" << endl;
}更新read.cc部分代码:
for (const PeopleInfo_Phone& phone : people.phone()) {
cout << "电话" << j++ << ": " << phone.number();
cout << " (" << phone.PhoneType_Name(phone.type()) << ")" << endl;
}4. Any类型
字段还可以声明为Any类型,可以理解为泛型类型。使⽤时可以在Any中存储任意消息类型。Any类型的字段也⽤repeated来修饰。
Any类型是google已经帮我们定义好的类型,在安装ProtoBuf时,其中的include⽬录下查找所有google已经定义好的.proto⽂件。
4.1 升级通讯录至2.2版本
通讯录2.2版本会新增联系⼈的地址信息,我们可以使⽤any类型的字段来存储地址信息。
更新contacts.proto(通讯录?2.2),更新内容如下:
syntax = "proto3";
package contacts;
import "google/protobuf/any.proto"; // 引⼊ any.proto ⽂件
// 地址
message Address{
string home_address = 1; // 家庭地址
string unit_address = 2; // 单位地址
}
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 3; // 电话
google.protobuf.Any data = 4;
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}contacts.pb.h更新的部分代码展⽰:
// 新⽣成的 Address 类
class Address final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const Address& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const Address& from) {
Address::MergeImpl(*this, from);
}
// string home_address = 1;
void clear_home_address();
const std::string& home_address() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_home_address(ArgT0&& arg0, ArgT... args);
std::string* mutable_home_address();
PROTOBUF_NODISCARD std::string* release_home_address();
void set_allocated_home_address(std::string* home_address);
// string unit_address = 2;
void clear_unit_address();
const std::string& unit_address() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_unit_address(ArgT0&& arg0, ArgT... args);
std::string* mutable_unit_address();
PROTOBUF_NODISCARD std::string* release_unit_address();
void set_allocated_unit_address(std::string* unit_address);
};
// 更新的 PeopleInfo 类
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
// .google.protobuf.Any data = 4;
bool has_data() const;
void clear_data();
const ::PROTOBUF_NAMESPACE_ID::Any& data() const;
PROTOBUF_NODISCARD ::PROTOBUF_NAMESPACE_ID::Any* release_data();
::PROTOBUF_NAMESPACE_ID::Any* mutable_data();
void set_allocated_data(::PROTOBUF_NAMESPACE_ID::Any* data);
}; 上述的代码中,对于Any类型字段:
• 设置和获取:获取⽅法的⽅法名称与⼩写字段名称完全相同。设置⽅法可以使⽤mutable_⽅
法,返回值为Any类型的指针,这类⽅法会为我们开辟好空间,可以直接对这块空间的内容进⾏
修改。
之前讲过,我们可以在Any字段中存储任意消息类型,这就要涉及到任意消息类型和Any类型的互转。这部分代码就在Google为我们写好的头⽂件any.pb.h 中。对 any.pb.h 部分代码展⽰:
class PROTOBUF_EXPORT Any final : public ::PROTOBUF_NAMESPACE_ID::Message {
bool PackFrom(const ::PROTOBUF_NAMESPACE_ID::Message& message) {
...
}
bool UnpackTo(::PROTOBUF_NAMESPACE_ID::Message* message) const {
...
}
template<typename T> bool Is() const {
return _impl_._any_metadata_.Is<T>();
}
};
解释:
使⽤ PackFrom() ⽅法可以将任意消息类型转为 Any 类型。
使⽤ UnpackTo() ⽅法可以将 Any 类型转回之前设置的任意消息类型。
使⽤ Is() ⽅法可以⽤来判断存放的消息类型是否为 typename T。5. oneof类型
如果消息中有很多可选字段,并且将来同时只有⼀个字段会被设置,那么就可以使⽤ oneof 加强这
个⾏为,也能有节约内存的效果。
oneof other_contact { // 其他联系⽅式:多选⼀
string qq = 5;
string weixin = 6;
}注意:
• 可选字段中的字段编号,不能与⾮可选字段的编号冲突。
• 不能在oneof中使⽤repeated字段。
• 将来在设置oneof字段中值时,如果将oneof中的字段设置多个,那么只会保留最后⼀次设置的成
员,之前设置的?oneof?成员会⾃动清除。
contacts.pb.h更新的部分代码展⽰:
// 更新的 PeopleInfo 类
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
enum OtherContactCase {
kQq = 5,
kWeixin = 6,
OTHER_CONTACT_NOT_SET = 0,
};
// string qq = 5;
bool has_qq() const;
void clear_qq();
const std::string& qq() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_qq(ArgT0&& arg0, ArgT... args);
std::string* mutable_qq();
PROTOBUF_NODISCARD std::string* release_qq();
void set_allocated_qq(std::string* qq);
// string weixin = 6;
bool has_weixin() const;
void clear_weixin();
const std::string& weixin() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_weixin(ArgT0&& arg0, ArgT... args);
std::string* mutable_weixin();
PROTOBUF_NODISCARD std::string* release_weixin();
void set_allocated_weixin(std::string* weixin);
void clear_other_contact();
OtherContactCase other_contact_case() const;
};上述的代码中,对于oneof字段:
• 会将oneof中的多个字段定义为⼀个枚举类型。
• 设置和获取:对oneof内的字段进⾏常规的设置和获取即可,但要注意只能设置⼀个。如果设置
多个,那么只会保留最后⼀次设置的成员。
• 清空oneof字段:clear_⽅法
• 获取当前设置了哪个字段:_case⽅法
write.cc更新部分代码:
cout << "选择添加⼀个其他联系⽅式 (1、qq号 2、微信号) : " ;
int other_contact;
cin >> other_contact;
cin.ignore(256, '\n');
if (1 == other_contact) {
cout << "请输⼊qq号: ";
string qq;
getline(cin, qq);
people_info_ptr->set_qq(qq);
} else if (2 == other_contact) {
cout << "请输⼊微信号: ";
string weixin;
getline(cin, weixin);
people_info_ptr->set_weixin(weixin);
} else {
cout << "⾮法选择,该项设置失败!" << endl;
}read.cc更新部分代码:
switch (people.other_contact_case()) {
case PeopleInfo::OtherContactCase::kQq:
cout << "qq号: " << people.qq() << endl;
break;
case PeopleInfo::OtherContactCase::kWeixin:
cout << "微信号: " << people.weixin() << endl;
break;
case PeopleInfo::OtherContactCase::OTHER_CONTACT_NOT_SET:
break;
}6. map类型
语法⽀持创建⼀个关联映射字段,也就是可以使⽤map类型去声明字段类型,格式为:
map<key_type, value_type> map_field = N;
要注意的是:
• key_type 是除了float和bytes类型以外的任意标量类型。value_type 可以是任意类型。
• map字段不可以⽤repeated修饰
• map中存⼊的元素是⽆序的
最后,通讯录2.4版本想新增联系⼈的备注信息,我们可以使⽤map类型的字段来存储备注信息。
更新contacts.proto(通讯录2.4),更新内容如下:
syntax = "proto3";
package contacts;
import "google/protobuf/any.proto"; // 引⼊ any.proto ⽂件
// 地址
message Address{
string home_address = 1; // 家庭地址
string unit_address = 2; // 单位地址
}
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2;
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 3; // 电话
google.protobuf.Any data = 4;
oneof other_contact { // 其他联系⽅式:多选⼀
string qq = 5;
string weixin = 6;
}
map<string, string> remark = 7; // 备注
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}contacts.pb.h更新的部分代码展⽰:
// 更新的 PeopleInfo 类
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
// map<string, string> remark = 7;
int remark_size() const;
void clear_remark();
const ::PROTOBUF_NAMESPACE_ID::Map< std::string, std::string >&
remark() const;
::PROTOBUF_NAMESPACE_ID::Map< std::string, std::string >*
mutable_remark();
};上述的代码中,对于Map类型的字段:
• 清空map:clear_⽅法
• 设置和获取:获取⽅法的⽅法名称与⼩写字段名称完全相同。设置⽅法为mutable_⽅法,返回
值为Map类型的指针,这类⽅法会为我们开辟好空间,可以直接对这块空间的内容进⾏修改。
write.cc更新部分:
for(int i = 1; ; i++) {
cout << "请输⼊备注" << i << "标题 (只输⼊回⻋完成备注新增): ";
string remark_key;
getline(cin, remark_key);
if (remark_key.empty()) {
break;
}
cout << "请输⼊备注" << i << "内容: ";
string remark_value;
getline(cin, remark_value);
people_info_ptr->mutable_remark()->insert({remark_key, remark_value});
}更新read.cc(通讯录?2.4),更新内容如下:
if (people.remark_size()) {
cout << "备注信息: " << endl;
}
for (auto it = people.remark().cbegin(); it != people.remark().cend();
++it) {
cout << " " << it->first << ": " << it->second << endl;
}7. 默认值
反序列化消息时,如果被反序列化的⼆进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
• 对于字符串,默认值为空字符串。
• 对于字节,默认值为空字节。
• 对于布尔值,默认值为false。
• 对于数值类型,默认值为?0。
• 对于枚举,默认值是第⼀个定义的枚举值,必须为0。
• 对于消息字段,未设置该字段。它的取值是依赖于语⾔。
• 对于设置了repeated的字段的默认值是空的(通常是相应语⾔的⼀个空列表)。
• 对于 消息字段 、 oneof字段 和 any字段 ,C++和Java语⾔中都有has_⽅法来检测当前字段是否被设置。
8. 更新消息
8.1 更新规则
如果现有的消息类型已经不再满⾜我们的需求,例如需要扩展⼀个字段,在不破坏任何现有代码的情况下更新消息类型⾮常简单。遵循如下规则即可:
• 禁⽌修改任何已有字段的字段编号。
• 若是移除⽼字段,要保证不再使⽤移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使⽤。不建议直接删除或注释掉字段。
• int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的⼀个改为另⼀个,
⽽不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采⽤与C++⼀致的处理⽅案
(例如,若将64位整数当做32位进⾏读取,它将被截断为32位)。
• sint32和sint64相互兼容但不与其他的整型兼容。
• string和bytes在合法UTF-8字节前提下也是兼容的。
• bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。
• fixed32与sfixed32兼容,fixed64与sfixed64兼容。
• enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序
列化消息时会根据语⾔采⽤不同的处理⽅案:例如,未识别的proto3枚举类型会被保存在消息
中,但是当消息反序列化时如何表⽰是依赖于编程语⾔的。整型字段总是会保持其的值。
• oneof:
◦ 将⼀个单独的值更改为新oneof类型成员之⼀是安全和⼆进制兼容的。
◦ 若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新oneof类型也是可⾏的。
◦ 将任何字段移⼊已存在的?oneof?类型是不安全的。
8.2 保留字段reserved
如果通过删除或注释掉字段来更新消息类型,未来的用户在添加新字段时,有可能会使⽤以前已经
存在,但已经被删除或注释掉的字段编号。将来使用该.proto的旧版本时的程序会引发很多问题:数据损坏、隐私错误等等。
确保不会发生这种情况的⼀种方法是:使⽤reserved 将指定字段的编号或名称设置为保留项。当
我们再使⽤这些编号或名称时,protocol buffer的编译器将会警告这些编号或名称不可用。举个例
⼦:
message Message {
// 设置保留项
reserved 100, 101, 200 to 299;
reserved "field3", "field4";
// 注意:不要在⼀⾏ reserved 声明中同时声明字段编号和名称。
// reserved 102, "field5";
// 设置保留项之后,下⾯代码会告警
int32 field1 = 100; //告警:Field 'field1' uses reserved number 100
int32 field2 = 101; //告警:Field 'field2' uses reserved number 101
int32 field3 = 102; //告警:Field name 'field3' is reserved
int32 field4 = 103; //告警:Field name 'field4' is reserved
}8.2.1 创建通讯录3.0版本---验证错误删除字段造成的数据损坏
现模拟有两个服务,他们各⾃使⽤⼀份通讯录.proto⽂件,内容约定好了是⼀模⼀样的。
服务1(service):负责序列化通讯录对象,并写⼊⽂件中。
服务2(client):负责读取⽂件中的数据,解析并打印出来。
⼀段时间后,service更新了⾃⼰的.proto文件,更新内容为:删除了某个字段,并新增了⼀个字段,新增的字段使⽤了被删除字段的字段编号。并将新的序列化对象写进了⽂件。
但client并没有更新⾃⼰的.proto⽂件。根据结论,可能会出现数据损坏的现象,接下来就让我们来
验证下这个结论。
新建两个⽬录:service、client。分别存放两个服务的代码。
service⽬录下新增contacts.proto(通讯录3.0)
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}client⽬录下新增contacts.proto(通讯录3.0)
syntax = "proto3";
package c_contacts;
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
} 分别对两个⽂件进⾏编译,可⾃⾏操作。
继续对service⽬录下新增service.cc(通讯录3.0),负责向⽂件中写通讯录消息,内容如下:
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
using namespace s_contacts;
/**
* 新增联系⼈
*/
void AddPeopleInfo(PeopleInfo *people_info_ptr)
{
cout << "-------------新增联系⼈-------------" << endl;
cout << "请输⼊联系⼈姓名: ";
string name;
getline(cin, name);
people_info_ptr->set_name(name);
cout << "请输⼊联系⼈年龄: ";
int age;
cin >> age;
people_info_ptr->set_age(age);
cin.ignore(256, '\n');
for(int i = 1; ; i++) {
cout << "请输⼊联系⼈电话" << i << "(只输⼊回⻋完成电话新增): ";
string number;
getline(cin, number);
if (number.empty()) {
break;
}
PeopleInfo_Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
}
cout << "-----------添加联系⼈成功-----------" << endl;
}
int main(int argc, char *argv[])
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
if (argc != 2)
{
cerr << "Usage: " << argv[0] << " CONTACTS_FILE" << endl;
return -1;
}
Contacts contacts;
// 先读取已存在的 contacts
fstream input(argv[1], ios::in | ios::binary);
if (!input) {
cout << argv[1] << ": File not found. Creating a new file." << endl;
}
else if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 新增⼀个联系⼈
AddPeopleInfo(contacts.add_contacts());
// 向磁盘⽂件写⼊新的 contacts
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
if (!contacts.SerializeToOstream(&output))
{
cerr << "Failed to write contacts." << endl;
input.close();
output.close();
return -1;
}
input.close();
output.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
}client⽬录下新增client.cc(通讯录3.0),负责向读出⽂件中的通讯录消息,内容如下:
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
using namespace c_contacts;
/**
* 打印联系⼈列表
*/
void PrintfContacts(const Contacts& contacts) {
for (int i = 0; i < contacts.contacts_size(); ++i) {
const PeopleInfo& people = contacts.contacts(i);
cout << "------------联系⼈" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
int j = 1;
for (const PeopleInfo_Phone& phone : people.phone()) {
cout << "电话" << j++ << ": " << phone.number() << endl;
}
}
}
int main(int argc, char* argv[]) {
GOOGLE_PROTOBUF_VERIFY_VERSION;
if (argc != 2) {
cerr << "Usage: " << argv[0] << "CONTACTS_FILE" << endl;
return -1;
}
// 以⼆进制⽅式读取 contacts
Contacts contacts;
fstream input(argv[1], ios::in | ios::binary);
if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 打印 contacts
PrintfContacts(contacts);
input.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
}代码编写完成后,进⾏⼀次读写(读写前的编译过程省略,⾃⾏操作)。
hyb@139-159-150-152:~/project/protobuf/update/service$ ./service
../contacts.bin
../contacts.bin: File not found. Creating a new file.
-------------新增联系⼈-------------
请输⼊联系⼈姓名: 张珊
请输⼊联系⼈年龄: 34
请输⼊联系⼈电话1(只输⼊回⻋完成电话新增): 131
请输⼊联系⼈电话2(只输⼊回⻋完成电话新增):
-----------添加联系⼈成功-----------
hyb@139-159-150-152:~/project/protobuf/update/client$ ./client ../contacts.bin
------------联系⼈1------------
姓名:张珊
年龄:34
电话1: 131确认⽆误后,对service⽬录下的contacts.proto⽂件进⾏更新:删除age字段,新增birthday字
段,新增的字段使⽤被删除字段的字段编号。
更新后的contacts.proto(通讯录3.0)内容如下:
syntax = "proto3";
package s_contacts;
// 联系⼈
message PeopleInfo {
string name = 1; // 姓名
// 删除年龄字段
// int32 age = 2; // 年龄
int32 birthday = 2; // ⽣⽇
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}编译⽂件.proto后,还需要更新⼀下对应的service.cc(通讯录3.0):
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
using namespace s_contacts;
/**
* 新增联系⼈
*/
void AddPeopleInfo(PeopleInfo *people_info_ptr)
{
cout << "-------------新增联系⼈-------------" << endl;
cout << "请输⼊联系⼈姓名: ";
string name;
getline(cin, name);
people_info_ptr->set_name(name);
/*cout << "请输⼊联系⼈年龄: ";
int age;
cin >> age;
people_info_ptr->set_age(age);
cin.ignore(256, '\n'); */
cout << "请输⼊联系⼈⽣⽇: ";
int birthday;
cin >> birthday;
people_info_ptr->set_birthday(birthday);
cin.ignore(256, '\n');
for(int i = 1; ; i++) {
cout << "请输⼊联系⼈电话" << i << "(只输⼊回⻋完成电话新增): ";
string number;
getline(cin, number);
if (number.empty()) {
break;
}
PeopleInfo_Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
}
cout << "-----------添加联系⼈成功-----------" << endl;
}
int main(int argc, char *argv[]) {...} 我们对client相关的代码保持原样,不进⾏更新。
再进⾏⼀次读写(对service.cc编译过程省略,⾃⾏操作)。
hyb@139-159-150-152:~/project/protobuf/update/service$ ./service
../contacts.bin
-------------新增联系⼈-------------
请输⼊联系⼈姓名: 李四
请输⼊联系⼈⽣⽇: 1221
请输⼊联系⼈电话1(只输⼊回⻋完成电话新增): 151
请输⼊联系⼈电话2(只输⼊回⻋完成电话新增):
-----------添加联系⼈成功-----------
hyb@139-159-150-152:~/project/protobuf/update/client$ ./client ../contacts.bin
------------联系⼈1------------
姓名:张珊
年龄:34
电话1: 131
------------联系⼈2------------
姓名:李四
年龄:1221
电话1: 151 这时问题便出现了,我们发现输⼊的⽣⽇,在反序列化时,被设置到了使⽤了相同字段编号的年龄上!!所以得出结论:若是移除⽼字段,要保证不再使⽤移除字段的字段编号,不建议直接删除或注释掉字段。
那么正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使⽤。
正确service⽬录下的contacts.proto写法如下(终版通讯录3.0)。
syntax = "proto3";
package s_contacts;
// 联系⼈
message PeopleInfo {
reserved 2;
string name = 1; // 姓名
int32 birthday = 4; // ⽣⽇
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}编译.proto⽂件后,还需要重新编译下service.cc,让service程序保持使⽤新⽣成的pbC++⽂件。
hyb@139-159-150-152:~/project/protobuf/update/service$ ./service
../contacts.bin
-------------新增联系⼈-------------
请输⼊联系⼈姓名: 王五
请输⼊联系⼈⽣⽇: 1112
请输⼊联系⼈电话1(只输⼊回⻋完成电话新增): 110
请输⼊联系⼈电话2(只输⼊回⻋完成电话新增):
-----------添加联系⼈成功-----------
hyb@139-159-150-152:~/project/protobuf/update/client$ ./client ../contacts.bin
------------联系⼈1------------
姓名:张珊
年龄:34
电话1: 131
------------联系⼈2------------
姓名:李四
年龄:1221
电话1: 151
------------联系⼈3------------
姓名:王五
年龄:0
电话1: 110根据实验结果,发现‘王五’的年龄为0,这是由于新增时未设置年龄,通过client程序反序列化
时,给年龄字段设置了默认值0。这个结果显然是我们想看到的。
还要解释⼀下‘李四’?的年龄依旧使⽤了之前设置的⽣⽇字段‘1221’,这是因为在新增‘李四’
的时候,⽣⽇字段的字段编号依旧为2,并且已经被序列化到⽂件中了。最后再读取的时候,字段编号依旧为2。
还要再说⼀下的是:因为使⽤了reserved关键字,ProtoBuf在编译阶段就拒绝了我们使⽤已经保留
的字段编号。到此实验结束,也印证了我们的结论。
根据以上的例⼦,有的同学可能还有⼀个疑问:如果使⽤了 reserved 2 了,那么service给‘王五’设置的⽣⽇‘1112’,client就没法读到了吗?答案是可以的。继续观看下⾯的未知字段即可揭晓答案。
8.3 未知字段
在通讯录3.0版本中,我们向service⽬录下的contacts.proto新增了‘⽣⽇’字段,但对于client相
关的代码并没有任何改动。验证后发现新代码序列化的消息(service)也可以被旧代码(client)解析。并且这⾥要说的是,新增的‘⽣⽇’字段在旧程序(client)中其实并没有丢失,⽽是会作为旧程序的未知字段。
• 未知字段:解析结构良好的protocol buffer已序列化数据中的未识别字段的表⽰⽅式。例如,当
旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
• 本来,proto3在解析消息时总是会丢弃未知字段,但在?3.5?版本中重新引⼊了对未知字段的保留机制。所以在3.5或更⾼版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果
中。
了解相关类关系图
MessageLite类介绍(了解)
• MessageLite从名字看是轻量级的message,仅仅提供序列化、反序列化功能。
• 类定义在google提供的message_lite.h中。
Message类介绍(了解)
• 我们⾃定义的message类,都是继承⾃Message。
• Message最重要的两个接⼝GetDescriptor/GetReflection,可以获取该类型对应的Descriptor对象
指针和Reflection?对象指针。
• 类定义在google提供的message.h中。
//google::protobuf::Message 部分代码展⽰
const Descriptor* GetDescriptor() const;
const Reflection* GetReflection() const; Descriptor类介绍(了解)
• Descriptor:是对message类型定义的描述,包括message的名字、所有字段的描述、原始的
proto⽂件内容等。
• 类定义在google提供的descriptor.h中。
// 部分代码展⽰
class PROTOBUF_EXPORT Descriptor : private internal::SymbolBase {
string& name () const
int field_count() const;
const FieldDescriptor* field(int index) const;
const FieldDescriptor* FindFieldByNumber(int number) const;
const FieldDescriptor* FindFieldByName(const std::string& name) const;
const FieldDescriptor* FindFieldByLowercaseName(
const std::string& lowercase_name) const;
const FieldDescriptor* FindFieldByCamelcaseName(
const std::string& camelcase_name) const;
int enum_type_count() const;
const EnumDescriptor* enum_type(int index) const;
const EnumDescriptor* FindEnumTypeByName(const std::string& name) const;
const EnumValueDescriptor* FindEnumValueByName(const std::string& name)
const;
}Reflection类介绍(了解)
• Reflection接⼝类,主要提供了动态读写消息字段的接⼝,对消息对象的⾃动读写主要通过该类完
成。
• 提供⽅法来动态访问/修改message中的字段,对每种类型,Reflection都提供了⼀个单独的接⼝⽤于读写字段对应的值。
◦ 针对所有不同的field类型 FieldDescriptor::TYPE_* ,需要使⽤不同的 Get*()/Set*
()/Add*() 接⼝;
◦ repeated类型需要使⽤ GetRepeated*()/SetRepeated*() 接⼝,不可以和⾮repeated
类型接⼝混⽤;
◦ message对象只可以被由它⾃⾝的 reflection(message.GetReflection()) 来操
作;
• 类中还包含了访问/修改未知字段的⽅法。
• 类定义在google提供的message.h中。
UnknownFieldSet类介绍(重要)
• UnknownFieldSet包含在分析消息时遇到但未由其类型定义的所有字段。
• 若要将UnknownFieldSet附加到任何消息,请调⽤?Reflection::GetUnknownFields()。
• 类定义在unknown_field_set.h中
class PROTOBUF_EXPORT UnknownFieldSet {
inline void Clear();
void ClearAndFreeMemory();
inline bool empty() const;
inline int field_count() const;
inline const UnknownField& field(int index) const;
inline UnknownField* mutable_field(int index);
// Adding fields ---------------------------------------------------
void AddVarint(int number, uint64_t value);
void AddFixed32(int number, uint32_t value);
void AddFixed64(int number, uint64_t value);
void AddLengthDelimited(int number, const std::string& value);
std::string* AddLengthDelimited(int number);
UnknownFieldSet* AddGroup(int number);
// Parsing helpers -------------------------------------------------
// These work exactly like the similarly-named methods of Message.
bool MergeFromCodedStream(io::CodedInputStream* input);
bool ParseFromCodedStream(io::CodedInputStream* input);
bool ParseFromZeroCopyStream(io::ZeroCopyInputStream* input);
bool ParseFromArray(const void* data, int size);
inline bool ParseFromString(const std::string& data) {
return ParseFromArray(data.data(), static_cast<int>(data.size()));
}
// Serialization.
bool SerializeToString(std::string* output) const;
bool SerializeToCodedStream(io::CodedOutputStream* output) const;
static const UnknownFieldSet& default_instance();
};UnknownField类介绍(重要)
• 表⽰未知字段集中的⼀个字段。
• 类定义在unknown_field_set.h中。
class PROTOBUF_EXPORT UnknownField {
public:
enum Type {
TYPE_VARINT,
TYPE_FIXED32,
TYPE_FIXED64,
TYPE_LENGTH_DELIMITED,
TYPE_GROUP
};
inline int number() const;
inline Type type() const;
// Accessors -------------------------------------------------------
// Each method works only for UnknownFields of the corresponding type.
inline uint64_t varint() const;
inline uint32_t fixed32() const;
inline uint64_t fixed64() const;
inline const std::string& length_delimited() const;
inline const UnknownFieldSet& group() const;
inline void set_varint(uint64_t value);
inline void set_fixed32(uint32_t value);
inline void set_fixed64(uint64_t value);
inline void set_length_delimited(const std::string& value);
inline std::string* mutable_length_delimited();
inline UnknownFieldSet* mutable_group();
}; 8.4 前后兼容性
根据上述的例⼦可以得出,pb是具有向前兼容的。为了叙述⽅便,把增加了“⽣⽇”属性的service
称为“新模块”;未做变动的client称为“⽼模块”。
• 向前兼容:⽼模块能够正确识别新模块⽣成或发出的协议。这时新增加的“⽣⽇”属性会被当作未
知字段(pb3.5版本及之后)。
• 向后兼容:新模块也能够正确识别⽼模块⽣成或发出的协议。
前后兼容的作⽤:当我们维护⼀个很庞⼤的分布式系统时,由于你⽆法同时升级所有模块,为了保证
在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼
容”。
9. 选项option
.proto⽂件中可以声明许多选项,使⽤option标注。选项能影响proto编译器的某些处理⽅式
syntax = "proto2"; // descriptor.proto 使⽤ proto2 语法版本
message FileOptions { ... } // ⽂件选项 定义在 FileOptions 消息中
message MessageOptions { ... } // 消息类型选项 定义在 MessageOptions 消息中
message FieldOptions { ... } // 消息字段选项 定义在 FieldOptions 消息中
message OneofOptions { ... } // oneof字段选项 定义在 OneofOptions 消息中
message EnumOptions { ... } // 枚举类型选项 定义在 EnumOptions 消息中
message EnumValueOptions { .. } // 枚举值选项 定义在 EnumValueOptions 消息中
message ServiceOptions { ... } // 服务选项 定义在 ServiceOptions 消息中
message MethodOptions { ... } // 服务⽅法选项 定义在 MethodOptions 消息中
...由此可⻅,选项分为 ⽂件级、消息级、字段级 等等,?但并没有⼀种选项能作⽤于所有的类型。
9.2 常⽤选项列举
• optimize_for:该选项为⽂件选项,可以设置protoc编译器的优化级别,分别为 SPEED 、
CODE_SIZE 、 LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译.proto⽂件后⽣
成的代码内容不同。
◦ SPEED :protoc编译器将⽣成的代码是⾼度优化的,代码运⾏效率⾼,但是由此⽣成的代码
编译后会占⽤更多的空间。 SPEED是默认选项。
◦ CODE_SIZE :proto编译器将⽣成最少的类,会占⽤更少的空间,是依赖基于反射的代码来
实现序列化、反序列化和各种其他操作。但和 SPEED 恰恰相反,它的代码运⾏效率较低。这
种⽅式适合⽤在包含⼤量的.proto⽂件,但并不盲⽬追求速度的应⽤中。
◦ LITE_RUNTIME :⽣成的代码执⾏效率⾼,同时⽣成代码编译后的所占⽤的空间也是⾮常
少。这是以牺牲Protocol Buffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,
所以我们在链接BP库时仅需链接libprotobuf-lite,⽽⾮libprotobuf。这种模式通常⽤于资源
有限的平台,例如移动⼿机平台中。
option optimize_for = LITE_RUNTIME; allow_alias:允许将相同的常量值分配给不同的枚举常量,⽤来定义别名。该选项为枚举选项。
举个例⼦:
enum PhoneType {
option allow_alias = true;
MP = 0;
TEL = 1;
LANDLINE = 1; // 若不加 option allow_alias = true; 这⼀⾏会编译报错
}
9.3 设置⾃定义选项
ProtoBuf允许⾃定义选项并使⽤。该功能⼤部分场景⽤不到,在这⾥不拓展讲解。有兴趣可以参考:https://developers.google.cn/protocol-buffers/docs/proto?hl=zh-cn#customoptions![]() https://developers.google.cn/protocol-buffers/docs/proto?hl=zh-cn#customoptions
https://developers.google.cn/protocol-buffers/docs/proto?hl=zh-cn#customoptions
三、总结
| 序列化协议 | 通用性 | 格式 | 可读性 | 序列化大小 | 序列化性能 | 适用场景 |
| JSON | 通用(json、xml已成为多种 ⾏业标准的编 写⼯具) | ⽂本格式 | 好 | 轻量(使⽤键值对⽅式,压缩了⼀定的数据空间) | 中 | web项⽬。因为浏览器对于json数据⽀持⾮常好,有很多内建的函数支持。 |
| XML | 通用 | ⽂本格式 | 好 | 重量(数 据冗余, 因为需要 成对的闭 合标签) | 低 | XML作为⼀种扩展标记语⾔,衍⽣出了 HTML、RDF/RDFS,它强调数据结构化的能⼒和可读性。 |
| ProtoBuf | 独⽴ (Protobuf只 是Google公司 内部的⼯具) | 二进制格式 | 差(只能 反序列化 后得到真 正可读的 数据) | 轻量(⽐ JSON更轻量,传输起来带宽和速度会有优化) | 高 | 适合⾼性能,对响应速度有要求的数据传输场景。Protobuf⽐XML、JSON更⼩、更快。 |
小结:
1. XML、JSON、ProtoBuf都具有数据结构化和数据序列化的能⼒。
2. XML、JSON更注重数据结构化,关注可读性和语义表达能⼒。ProtoBuf?更注重数据序列化,关注效率、空间、速度,可读性差,语义表达能⼒不⾜,为保证极致的效率,会舍弃⼀部分元信息。
3. ProtoBuf的应⽤场景更为明确,XML、JSON的应⽤场景更为丰富。
最后在我的代码仓库中实现了以httplib-c++库中的网络通信,使用的序列化就是ProtoBuf,感兴趣的可以观看。以上就是对ProtoBuf的全部内容,感谢大家观看!
相关文章:
【protobuf】ProtoBuf的学习与使用⸺C++
W...Y的主页 😊 代码仓库分享💕 前言:之前我们学习了Linux与windows的protobuf安装,知道protobuf是做序列化操作的应用,今天我们来学习一下protobuf。 目录 ⼀、初识ProtoBuf 步骤1:创建.proto文件 步…...

【iOS】MVC架构模式
文章目录 前言MVC架构模式基本概念通信方式简单应用 总结 前言 “MVC”,即Model(模型),View(视图),Controller(控制器),MVC模式是架构模式的一种。 关于“架构模式”&a…...

ML 系列:机器学习和深度学习的深层次总结(08)—欠拟合、过拟合,正确拟合
ML 系列赛:第 9 天 — Under、Over 和 Good Fit 文章目录 一、说明二、了解欠拟合、过拟合和实现正确的平衡三、关于泛化四、欠拟合五、过拟合六、适度拟合七、结论 一、说明 在有监督学习过程中,对于指定数据集进行训练,训练结果存在欠拟合…...

Unity-物理系统-刚体加力
一 刚体自带添加力的方法 给刚体加力的目标就是 让其有一个速度 朝向某一个方向移动 1.首先应该获取刚体组件 rigidBody this.GetComponent<Rigidbody>(); 2.添加力 //相对世界坐标 //世界坐标系 Z轴正方向加了一个里 //加力过后 对象是否停止…...

深入探究PR:那些被忽视却超实用的视频剪辑工具
如果想要了解视频剪辑的工具,那一定听说过pr视频剪辑吧。如果你是新手其实我更推荐你从简单的视频剪辑工具入手,这次我就介绍一些简单好操作的视频剪辑工具来入门吧。 1.福晰视频剪辑 连接直达>>https://www.pdf365.cn/foxit-clip/ 这款工具操…...

Unity-麦克风输入相关
private AudioClip clip; 知识点一 获取设备麦克风信息 string[] strs Microphone.devices; for (int i 0; i < strs.Length; i) { print(strs[i]); } 知识点二 开始录制 参数一:设备名 传空使用默认设备 参数二:超过录…...

NLP--自然语言处理学习-day1
一.初步认识NLP 自然语言处理(Natural Language Processing, NLP)是计算机科学和人工智能(AI)的一个交叉领域,旨在使计算机能够理解、分析、生成和处理人类语言的能力。它结合了计算语言学、人工智能、机器学习和语言…...

ER论文阅读-Incomplete Multimodality-Diffused Emotion Recognition
基本介绍:NeurIPS, 2024, CCF-A 原文链接:https://proceedings.neurips.cc/paper_files/paper/2023/file/372cb7805eaccb2b7eed641271a30eec-Paper-Conference.pdf Abstract 人类多模态情感识别(MER)旨在通过多种异质模态&#x…...

Matlab自学笔记36:日期时间型的概念、分类和创建方法
1.概念 日期时间型(Dates and Time)数据具有灵活的显示格式和高达毫微秒的精度,并且可以处理时区、夏令时和平闰年等特殊因素 2.日期时间型数据有以下三种表示方式 (1)Datetime型,表示日期时间点&#x…...

Spring Boot自定义配置项
Spring Boot自定义配置项 配置文件 在application.properties文件添加需要的配置 比如: file.pathD:\\flies\\springboot\\ConfigurationProperties 注解 使用注解ConfigurationProperties将配置项和实体Bean关联起来,实现配置项和实体类字段的关联&…...

【C++篇】C++类与对象深度解析(六):全面剖析拷贝省略、RVO、NRVO优化策略
文章目录 C类与对象前言读者须知RVO 与 NRVO 的启用条件如何确认优化是否启用? 1. 按值传递与拷贝省略1.1 按值传递的概念1.2 示例代码1.3 按值传递的性能影响1.3.1 完全不优化 1.4 不同编译器下的优化表现1.4.1 Visual Studio 2019普通优化1.4.2 Visual Studio 202…...

什么时候用synchronized,什么时候用Reentrantlock
文章目录 使用 synchronized 的场景使用 ReentrantLock 的场景综合考虑 使用 synchronized 的场景 synchronized 是 Java 内置的同步机制,使用起来比较简单且常用于如下场景: 1、简单的同步逻辑:当你的同步逻辑非常简单,比如只需…...

[ffmpeg]音频格式转换
本文主要梳理 ffmpeg 中的音频格式转换。由于采集的音频数据和编码器支持的音频格式可能不一样,所以经常需要进行格式转换。 API 调用 常用 API struct SwrContext *swr_alloc(void); int swr_init(struct SwrContext *s); struct SwrContext *swr_alloc_set_opt…...

SSRF工具类-SsrfTool
为了帮助开发人员和安全研究人员检测和修复SSRF(Server-Side Request Forgery)漏洞,存在 多种工具。这里我将给出一个简单的工具类示例,这个工具类可以用来检查一个给定的URL是否可 能引发SSRF攻击。请注意,这个工具类主要用于教育目的,并不意味着它可以完全防止所有的…...

python集合运算介绍及示例代码
Python 中的集合(set)是一种数据类型,用于存储唯一元素的无序集合。集合支持多种运算,如并集、交集、差集和对称差集,方便执行数学上的集合操作。 1. 创建集合 可以使用大括号 {} 或者 set() 函数创建集合࿱…...
『功能项目』按钮的打开关闭功能【73】
本章项目成果展示 我们打开上一篇72QFrameWork制作背包界面UGUI的项目, 本章要做的事情是制作打开背包与修改器的打开关闭按钮 首先打开UGUICanvas复制button按钮 重命名为ReviseBtn 修改脚本:UIManager.cs 将修改器UI在UGUICanvas预制体中设置为隐藏 运…...

Linux 常用命令 - more 【分页显示文件内容】
简介 more 命令源自英文单词 more, 表示 “更多”,它是一个基于文本的程序,用于查看文本文件的内容。该命令会逐页显示文件内容,允许用户按页浏览大型文本文件。当用户完成当前页的阅读后,可以通过按键(空格键或回车键…...

Kotlin Android 环境搭建
Kotlin Android 环境搭建 1. 引言 Kotlin 已成为 Android 开发的官方语言之一,因其简洁、表达性强和易于维护的特点而受到广大开发者的喜爱。在本教程中,我们将详细介绍如何在您的计算机上搭建 Kotlin Android 开发环境。 2. 系统要求 在开始搭建 Kotlin Android 开发环境…...

常见协议及其默认使用的端口号
在网络通信中,端口号用于标识特定的应用程序或服务。IANA(Internet Assigned Numbers Authority)负责分配和管理这些端口号。端口号分为三个范围: 熟知端口(Well-Known Ports):0到1023…...
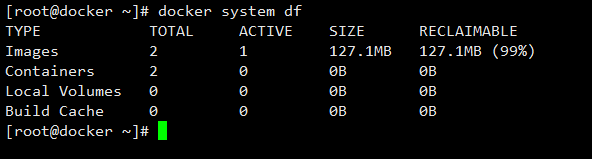
04-Docker常用命令
04-Docker常用命令 启动类命令 启动docker systemctl start docker停止docker systemctl stop docker重启docker systemctl restart docker查看docker状态 systemctl status docker开机启动docker systemctl enable docker帮助类命令 查看docker版本 docker version查…...

3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南
3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的情…...

英雄联盟自动化助手:5分钟告别繁琐操作,专注游戏策略的终极方案
英雄联盟自动化助手:5分钟告别繁琐操作,专注游戏策略的终极方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

LAV Filters终极实战指南:深度解析开源媒体解码器的性能优化与架构设计
LAV Filters终极实战指南:深度解析开源媒体解码器的性能优化与架构设计 【免费下载链接】LAVFilters LAV Filters - Open-Source DirectShow Media Splitter and Decoders 项目地址: https://gitcode.com/gh_mirrors/la/LAVFilters LAV Filters是一套基于FFm…...

Vue3组合式API进阶:深入理解和高效使用Composition API
Vue3组合式API进阶:深入理解和高效使用Composition API 前言 大家好,我是前端老炮儿!今天咱们来聊聊Vue3组合式API的进阶用法。 你以为ref和reactive就够了?那你可太天真了!Vue3的Composition API远比你想象的更强大。…...

用Python重写‘估值一亿的AI核心代码’:聊聊正则表达式与字符串处理的优雅解法
Python重构估值一亿的AI核心代码:正则表达式与字符串处理的优雅实践 当我们需要处理复杂的文本规则时,不同编程语言会展现出截然不同的解决思路。本文将以PTA L1-064题目为例,展示如何用Python的正则表达式和字符串处理方法,优雅地…...

从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证
从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证 在当今超大规模集成电路设计中,物理验证已成为确保芯片功能正确的最后一道防线。随着工艺节点不断微缩,设计复杂度呈指数级增长,传统的扁平化验证方法已难以应…...
)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588) 在智能家居日益普及的今天,家庭媒体中心已成为许多科技爱好者的必备设备。传统的解决方案往往依赖于昂贵的商业NAS或性能有限的树莓派,而基于RK3588芯…...
的预配置策略与实战价值)
当台风来袭时,电网如何“未雨绸缪”?聊聊应急移动电源(MPS)的预配置策略与实战价值
当台风来袭时,电网如何“未雨绸缪”?应急移动电源(MPS)的预配置策略与实战价值 台风过境时,医院ICU的呼吸机突然断电、通信基站的备用电池耗尽、交通信号灯集体瘫痪——这些场景并非虚构,而是真实发生在201…...

TLV320AIC3254音频编解码器:从DSP算法到低功耗设计的嵌入式开发全解析
1. 项目概述:从一颗音频编解码器芯片说起最近在做一个需要高保真音频采集与播放的项目,选型时又一次把目光投向了德州仪器(TI)的音频编解码器产品线。这次的主角是TLV320AIC3254,一颗在专业音频、消费电子和工业领域都…...