Flink系列知识之:Checkpoint原理
Flink系列知识之:Checkpoint原理
在介绍checkpoint的执行流程之前,需要先明白Flink中状态的存储机制,因为状态对于检查点的持续备份至关重要。
State Backends分类
下图显示了Flink中三个内置的状态存储种类。MemoryStateBackend和FsStateBackend在运行时存储在Java堆中。FsStateBackend仅在执行检查点时才以文件的形式持久地将数据保存到远程存储。RocksDBStateBackend使用RocksDB(一种LSM数据库,结合了内存和磁盘)来存储状态。

当使用基于堆的 state backend 保存状态时,访问和更新涉及在堆上读写对象。但是对于保存在 RocksDBStateBackend 中的对象,访问和更新涉及序列化和反序列化,所以会有更大的开销。但 RocksDB 的状态量仅受本地磁盘大小的限制。还要注意,只有 RocksDBStateBackend 能够进行增量快照,这对于具有大量变化缓慢状态的应用程序来说是大有裨益的。
下面是执行HeapKeyedStateBackend的方法:
- 支持异步检查点(默认):存储格式为CopyOnWriteStateMap。
- 仅支持同步检查点:存储格式为NestedStateMap。
当在MemoryStateBackend中使用HeapKeyedStateBackend时,默认情况下,基于检查点的数据序列化的最大数据量为5mb。
对于RocksDBKeyedStateBackend,每个状态都存储在一个单独的列族中。keyGroup、Key和Namespace被序列化并以键的形式存储在数据库中。
对于RocksDBKeyedStateBackend,每个状态都存储在一个单独的列族中。keyGroup、Key和Namespace被序列化并以键的形式存储在数据库中。

checkpoint执行流程
Flink容错机制的核心部分是绘制分布式数据流和算子状态的一致快照。这些快照充当一致的检查点,系统可以在发生故障时退回到这些检查点。它受到用于分布式快照的标准Chandy-Lamport算法的启发,并专门针对Flink的执行模型进行了定制。
自Flink 1.11以来,检查点可以在对齐或不对齐的情况下进行。在本节中,我们首先描述对齐的检查点。
Checkpoint barrier
Flink分布式快照的一个核心元素是stream barrier。这些barrier会被注入到数据流中,并作为数据流的一部分与记录一起流动。当 Flink 作业设置了检查点时,Flink 会在数据流中插入这些特殊记录,以确保在特定点上所有算子的状态都被一致地保存。barrier永远不会超过记录,它们严格地按顺序流动。barrier将数据流中的记录分隔为进入当前快照的记录集和进入下一个快照的记录集,相当于将连续的数据流切分为多个有限序列,对应多个 Checkpoint 周期。每个barrier都携带着包含了在它前面的记录的快照的ID。barrier不会中断数据流,因此非常轻巧。来自不同快照的多个barrier可以同时在数据流中,这意味着多种快照可能并发发生。整个过程是由 Flink 的执行引擎在运行时负责处理的,通过协调不同操作符之间的信号和状态来实现数据流中的 checkpoint barrier 插入。

Stream barrier首先会被注入到source流的并行数据流中。快照n的barrier被注入的点(我们称之为Sn)是source源流中快照所能覆盖的数据的位置。例如,在Apache Kafka中,这个位置将是分区中拉取数据的偏移量。这个插入点Sn会被报告给检查点协调器(Flink的JobManager)。
当中间操作符从其所有输入流接收到快照n的barrier时,它会开始执行快照,并将状态写入到State backend中,然后会将快照n的barrier继续向下游流动,发送到其所有传出流中。一旦sink操作符(流DAG的末端)从其所有输入流接收到barrier n,它就向检查点协调器确认快照n。在所有sink算子都确认了快照之后,就认为快照已经完成。
一旦快照n完成,作业就不会再向source算子请求Sn之前的记录,因为此时这些记录已经完整地流过了整个DAG数据拓扑。
checkpoint alignment
Checkpoint alignment 机制是 Apache Flink 中用于确保分布式检查点一致性的一种机制。对于接收多个输入流的算子需要在快照barrier上对齐输入流。如下图所示:

- 一旦算子从某个输入流通道中接收到快照barrier n,它就不能处理来自该流的任何一条记录(阻塞),直到它从其他所有输入流通道中都接收到barrier n。因为如果不阻塞的话,算子状态将会混合属于快照n的记录和属于快照n+1的记录。
- 在对齐的过程中,算子只会继续处理来自未出现 Barrier Channel 的数据,而其余 Channel 的数据会被写入输入队列,直至在队列满后被阻塞。
- 当从最后一个输入流通道中接收到barrier n时,算子开始执行快照,异步地将状态写入到State Backend中,然后将barrier n继续向下游所有输出通道流动。
比起其他分布式快照,该算法的优势在于辅以 Copy-On-Write 技术的情况下不需要 “Stop The World” 影响应用吞吐量,同时基本不用持久化处理中的数据,只用保存进程的状态信息,大大减小了快照的大小。
需要注意的是,对于具有多个输入流的操作符算子,以及在shuffle后接收多个上游子任务输出流的操作符算子,都需要对齐。
checkpoint执行流程
上面介绍完checkpoint的相关原理后,本节尝试逐步解释执行检查点的过程。如下图所示,左侧为checkpoint coordinator,中间为Flink job(由两个源节点和一个汇聚节点组成),右侧为persistent storage(大多数场景下由HDFS提供)。
Step 1) Checkpoint coordinator触发checkpoint执行信号到所有输入流操作符算子中。

Step 2) 源节点向下游广播一个checkpoint barrier。该checkpoint barrier是Chandy-Lamport分布式快照算法的核心。下游任务只有在接收到所有输入流通道的barrier后才执行checkpoint操作。

Step 3) 源操作符算子完成state状态备份后,向checkpoint coordinator(检查点协调器)发送备份数据地址,即状态句柄。同时,barrier继续流向下游。
这里分为同步和异步(如果开启的话)两个阶段:

同步阶段:task执行状态快照,并写入外部存储系统(根据状态后端的选择不同有所区别)执行快照的过程:
- 对 state 做深拷贝
- 将写操作封装在异步的 FutureTask 中,FutureTask 的作用包括:1)打开输入流;2)写入状态的元数据信息;3)写入状态;4)关闭输入流
⠀异步阶段:
- 执行同步阶段创建的 FutureTask
- 向 Checkpoint Coordinator 发送 ACK 响应
Step 4) 当下游sink节点接收到上游两个输入通道的barrier后,开始执行本地快照。下图演示了执行RocksDB增量检查点的过程。RocksDB将全部数据刷新到磁盘,如红色三角形所示。然后,Flink为未上传的文件实现持久备份,如紫色三角形所示。

Step 5) 在执行完sink操作符算子的检查点之后,sink操作符算子将状态句柄(state handle)返回给checkpoint coordinator检查点协调器。

Step 6) 当接收到所有任务算子的状态句柄(state handle)后,checkpoint coordinator确认全局的checkpoint已经完成,然后将checkpoint元文件备份到持久化存储中。

Unaligned Checkpoint
上述对齐的chekcpoint基于Chandy-Lamport算法实现了分布式系统下的数据一致性快照。通过上面的原理可以看出,该方案在操作符算子具有多个输入流通道时,需要阻塞地等待所有输入通道的barrier都到达后才会开始执行快照。这在大多数情况下是没有问题的,但当某个输入流通道比其他输入流通道的数据流动更慢时,比如出现了反压、数据倾斜问题。会导致快照的完成时间变长甚至超时。其次,这种方案来说,Barrier对齐的过程本身就可能成为一个反压的源头,影响上游算法的效率,而这在某些情况下是不必要的。
为了解决这个问题,Flink在1.11版本中引入了Unaligned Checkpoint的特性。其基本思想是,只要输入通道中的的数据能成为操作符算子状态的一部分,那么checkpoint barrier就可以超越所有输入/输出通道中的数据。
Checkpointing can also be performed unaligned. The basic idea is that checkpoints can overtake all in-flight data as long as the in-flight data becomes part of the operator state.
如何来理解呢?
在上面对齐的checkpoint的原理介绍中可以发现,快照只包含了操作符算子的状态,而不关心输入/输出通道的数据记录。这是因为barrier对齐的checkpoint将本地快照延迟至所有barrier到达,也就是说当执行快照时,属于当前checkpoint周期内的数据记录都已经对该算子状态产生了影响,因而不必关心输入队列的剩余数据,同时输出队列又携带着barrier继续流向下一个算子的输入队列,因而输出队列的数据也不必关心,从而巧妙地避免了对算子输入/输出队列的状态进行快照。
但实际上,这和Chandy-Lamport算法是有一定出入的。举个例子,假设我们对两个数据流进行 equal-join,输出匹配上的元素。按照 Flink Aligned Checkpoint 的方式,系统的状态变化如下(图中不同颜色的元素代表属于不同的 Checkpoint 周期):

- 图 a: 输入 Channel 1 存在 3 个元素,其中 2 在 Barrier 前面;Channel 2 存在 4 个元素,其中 2、9、7 在 Barrier 前面。
- 图 b: 算子分别读取 Channel 一个元素,输出 2。随后接收到 Channel 1 的 Barrier,停止处理 Channel 1 后续的数据,只处理 Channel 2 的数据。
- 图 c: 算子再消费 2 个自 Channel 2 的元素,接收到 Barrier,开始本地快照并输出 Barrier。
对于相同的情况,Chandy-Lamport 算法的状态变化如下:

- 图 a: 同上。
- 图 b: 算子分别处理两个 Channel 一个元素,输出结果 2。此后接收到 Channel 1 的 Barrier,算子开始本地快照记录自己的状态,并输出 Barrier。
- 图 c: 算子继续正常处理两个 Channel 的输入,输出 9。特别的地方是 Channel 2 后续元素会被保存下来,直到 Channel 2 的 Barrier 出现(即 Channel 2 的 9 和 7)。保存的数据会作为 Channel 的状态成为快照的一部分。
两者的差异主要可以总结为两点:
- 快照的触发是在接收到第一个 Barrier 时还是在接收到最后一个 Barrier 时。
- 是否需要阻塞已经接收到 Barrier 的 Channel 的计算。
从这两点来看,新的 Unaligned Checkpoint 将快照的触发改为第一个 Barrier 且取消阻塞 Channel 的计算,算法上与 Chandy-Lamport 基本一致,同时在实现细节方面结合 Flink 的定位做了几个改进。
首先,不同于 Chandy-Lamport 模型的只需要考虑算子输入 Channel 的状态,Flink 的算子有输入和输出两种 Channel,在快照时两者的状态都需要被考虑。
其次,无论在 Chandy-Lamport 还是 Flink Aligned Checkpoint 算法中,Barrier 都必须遵循其在数据流中的位置,算子需要等待 Barrier 被实际处理才开始快照。而 Unaligned Checkpoint 改变了这个设定,允许算子优先摄入并优先输出 Barrier。 如此一来,第一个到达 Barrier 会在算子的缓存数据队列(包括输入 Channel 和输出 Channel)中往前跳跃一段距离,而被”插队”的数据和其他输入 Channel 在其 Barrier 之前的数据会被写入快照中(图中绿色部分)。

上图描述了算子是如何处理非对齐的checkpoint barriers的:
- 当输入队列中接收到第一个chekcpoint barrier时,算子即开始执行相应处理。
- 它会立即将该barrier跳过前面的输入队列,并将其插入到输出队列的尾部。
- 算子在执行快照时,会把所有标记了跳过的数据记录(图中绿色部分),并将其一并写入到算子状态中。
此时,算子只需短暂停止处理输入队列以标记缓冲区、转发barrier并创建其状态的快照。
这样的主要好处是,如果本身算子的处理就是瓶颈,Chandy-Lamport 的 Barrier 仍会被阻塞(因为Chandy-Lamport仍然要等到第一个barrier到达算子时才开始触发快照执行,如果算子的处理本身比较慢,数据的流动仍然会很慢),但 Unaligned Checkpoint 则可以在 Barrier 进入输入 Channel 就马上开始快照。 这可以从很大程度上加快 Barrier 流经整个 DAG 的速度,从而降低 Checkpoint 整体时长。
回到之前的例子,用 Unaligned Checkpoint 来实现,状态变化如下:

- 图 a: 输入 Channel 1 存在 3 个元素,其中 2 在 Barrier 前面;Channel 2 存在 4 个元素,其中 2、9、7 在 Barrier 前面。输出 Channel 已存在结果数据 1。
- 图 b: 算子优先处理输入 Channel 1 的 Barrier,开始本地快照记录自己的状态,并将 Barrier 插到输出 Channel 末端。
- 图 c: 算子继续正常处理两个 Channel 的输入,输出 2、9。同时算子会将 Barrier 越过的数据(即输入 Channel 1 的 2 和输出 Channel 的 1)写入 Checkpoint,并将输入 Channel 2 后续早于 Barrier 的数据(即 2、9、7)持续写入 Checkpoint。
比起Aligned Checkpoint中不同Checkpoint周期的数据以算子快照为界限分隔得很清晰,Unaligned Checkpoint进行快照和输出Barrier时,部分本属于当前Checkpoint的输入数据还未计算(因此未反映到当前算子状态中),而部分属于当前Checkpoint的输出数据却落到Barrier之后(因此未反映到下游算子的状态中)。这也正是Unaligned的含义:不同Checkpoint周期的数据没有对齐,包括不同输入Channel之间的不对齐,以及输入和输出间的不对齐。而这部分不对齐的数据会被快照记录下来,以在恢复状态时重放。换句话说,从Checkpoint恢复时,不对齐的数据并不能由Source端重放的数据计算得出,同时也没有反应到算子状态中,但因为它们会被Checkpoint恢复到对应Channel中,所以依然能够提供只计算一次的准确结果。
Unaligned Checkpoint方案确保barrier可以尽可能快地在数据流中移动。它特别适合至少有一个缓慢移动的数据输入队列的应用,其对齐时间可能达到几个小时。但是,由于它增加了额外的I/O压力,所以当应用写入State Backend的I/O本身就是瓶颈时,非对齐Checkpoint方案并不会有明显帮助。
Exactly Once vs. At Least Once
为了实现EXACTLY ONCE的语义,Flink使用了输入缓存队列来缓存在对齐过程中队列中传入的数据。同时,我们经过上面Checkpoint原理介绍也能清晰地知道,使用对齐的方式来执行快照是能够实现EXACTLY ONCE的语义的。
需要注意的是,这里的EXACTLY ONCE语义并不意味着每个事件将被精确地处理一次,而是意味着每个事件只会影响Flink算子状态一次。同时,EXACTLY ONCE语义并不能实现端到端的数据EXACTLY ONCE,如果需要实现端到端的EXACTLY ONCE语义,需要sink算子能够实现写入的幂等和事务性。
通常,在checkpoint过程中额外的对齐时间延迟大约是几毫秒,但也可能会有一些异常值的延迟明显增加的情况。对于所有记录都需要超低延迟(几毫秒)的应用程序,Flink有一个开关,可以在检查点期间跳过对齐步骤。此时,当算子接收到每个输入队列的checkpoint barrier时不会阻塞,会继续处理barrier之后的数据记录。这就可能会导致本属于下一个checkpoint周期的数据记录影响了当前checkpoint周期的算子状态,从而导致恢复时数据重复消费的情况,因此,这种模式下只能保证At Least Once语义。
Checkpoint Exactly Once和At Least Once语义配置:
// 启用 Checkpoint 每 5 秒 一次,模式为 EXACTLY_ONCE
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);// 启用 Checkpoint 每 5 秒 一次,模式为 At Least Once
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
另外,Aligned过程只发生在具有多个输入队列(连接)的算子以及具有多个输出队列的算子(比如在重新分区/shuffle之后)。正因为如此,只有单并行度的操作算子(map(), flatMap(), filter(),…)的数据流实际上及时被设置为At Least Once语义,也能实现Exactly once语义(实际上就是单输入流的算子不需要barrier对齐)。
参考
Flink 1.11 Unaligned Checkpoint 解析
Stateful Stream Processing
Flink Checkpoints Principles and Practices: Flink Advanced Tutorials
相关文章:
Flink系列知识之:Checkpoint原理
Flink系列知识之:Checkpoint原理 在介绍checkpoint的执行流程之前,需要先明白Flink中状态的存储机制,因为状态对于检查点的持续备份至关重要。 State Backends分类 下图显示了Flink中三个内置的状态存储种类。MemoryStateBackend和FsState…...
智算中心动环监控:构建高效、安全的数字基础设施@卓振思众
在当今快速发展的数字经济时代,智算中心作为人工智能和大数据技术的核心支撑设施,正日益成为各行业实现智能化转型的重要基石。为了确保这些高性能计算环境的安全与稳定,卓振思众动环监控应运而生,成为智算中心管理的重要组成部分…...

PyTorch VGG16手写数字识别教程
手写数字识别教程:使用PyTorch和VGG16 1. 环境准备 确保你已安装以下库: pip install torch torchvision2. 导入必要的库 import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms import tor…...

安卓13删除下拉栏中的设置按钮 android13删除设置按钮
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 顶部导航栏下拉可以看到,底部这里有个设置按钮,点击可以进入设备的设置页面,这里我们将更改为删除,不同用户通过这个地方进入设置。也就是下面这个按钮。 2.问题分析…...

FDA辅料数据库在线免费查询-药用辅料
在药物制剂的研制过程中,需要确定这些药用辅料的安全用量。而美国食品药品监督管理局(FDA)的辅料数据库(IID)提供了其制剂研发中的关键参考资源,使得更多的医药研发相关人员及企业单位节省试验环节及时间成…...

git pull 报错 refusing to merge unrelated histories
这个对我来说非常常见,因为我都是先由本地项目,再想着传到github上去。 在本地项目中执行 git init git add . git commit -m “xxx” 在github上创建项目,添加了 README.md 文件。 git remote add origin https://github.com/raoxiaoya/x…...

STM32G431RBT6(蓝桥杯)串口(发送)
一、基础配置 (1) PA9和PA10就是串口对应在单片机上的端口 注意:一定要先选择PA9的TX和PA10的RX,再去打开异步的模式 (2) 二、查看单片机的端口连接至电脑的哪里 (1)此电脑->右击属性 (2)找到端…...

使用 typed-rest-client 进行 REST API 调用
typed-rest-client 是一个用于 Node.js 的库,它提供了一种类型安全的方式来与 RESTful API 进行交互。其主要功能包括: 安装 typed-rest-client 要使用 typed-rest-client,首先需要安装它,可以通过 npm 来安装: $ n…...

在Ubuntu 14.04上安装Solr的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Solr 是基于 Apache Lucene 的搜索引擎平台。它用 Java 编写,并使用 Lucene 库来实现索引。可以通过各种 REST API&am…...
LabVIEW提高开发效率技巧----使用LabVIEW工具
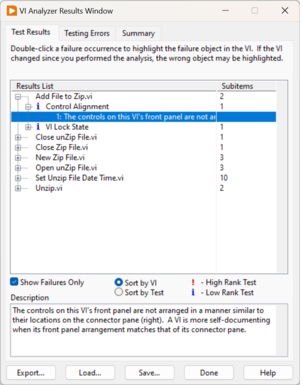
LabVIEW为开发者提供了多种工具和功能,不仅提高工作效率,还能确保项目的质量和可维护性。以下详细介绍几种关键工具,并结合实际案例说明它们的应用。 1. VI Analyzer:自动检查代码质量 VI Analyzer 是LabVIEW提供的一款强大的工…...
)
Pyspark dataframe基本内置方法(4)
文章目录 Pyspark sql DataFrame相关文章RDDrepartition 重新分区replace 替换sameSemantics dataframe是否相等sample 采样sampleBy 分层采样schema 显示dataframe结构select 查询selectExpr 查询semanticHash 获取哈希值show 展示dataframesort 排序sortWithinPartitions 分区…...

配置win10开电脑时显示可登录账号策略
有1台公用的windows10电脑,电脑上有N多用户,使用人员登录时选择相应的账号登录即可。但在某次使用脚本加固后,发现之前显示的用户都不能显示了。检查加固脚本,是脚本启用了“交互式登录:不显示上次登录”策略。因此&am…...
01-Mac OS系统如何下载安装Python解释器
目录 Mac安装Python的教程 mac下载并安装python解释器 如何下载和安装最新的python解释器 访问python.org(受国内网速的影响,访问速度会比较慢,不过也可以去我博客的资源下载) 打开历史发布版本页面 进入下载页 鼠标拖到页面…...

24 C 语言常用的字符串处理函数详解:strlen、strcat、strcpy、strcmp、strchr、strrchr、strstr、strtok
目录 1 strlen 1.1 函数原型 1.2 功能说明 1.3 案例演示 1.4 注意事项 2 strcat 2.1 函数原型 2.2 功能说明 2.3 案例演示 2.4 注意事项 3 strcpy 3.1 函数原型 3.2 功能说明 3.3 案例演示 3.4 注意事项 4 strcmp 4.1 函数原型 4.2 功能说明 4.3 案例演示 …...

数据驱动农业——农业中的大数据
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、埃域知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。 橙蜂智农的智慧农业产品涵盖了多方面的功能&…...

学习《分布式》必须清楚的《CAP理论》
分布式的理论基础CAP理论 当学习分布式的redis、mq等中间件时,都会看到有提到CAP。 CAP理论是学习分布式必备的一个概念知识点。 CAP理论由三个特性组成,分别是一致性(Consistency)、可用性(Availability࿰…...

navicat无法连接远程mysql数据库1130报错的解决方法
出现报错:1130 - Host ipaddress is not allowed to connect to this MySQL serve navicat,当前ip不允许连接到这个MySQL服务 解决当前ip无法连接远程mysql的方法 1. 查看mysql端口,并在服务器安全组中放开相应入方向端口后重启服务器 sud…...

JetPack01- LifeCycle 监听Activity或Fragment的生命周期
前提 阅读本文的前提是要了解观察者模式。本文没有讲述反射相关的内容,功能中有使用反射。 简介 监听Activity/Fragment的生命周期,使用观察者模式,Activity/Fragment是被观察者。 监听的生命周期有onCreate、onStart、onResume、onPause…...

OpenCSG推出StarShip SecScan:AI驱动的软件安全革新
OpenCSG 导读 如今,IT 技术迅速发展,软件安全不仅是企业稳健运营的基础,更是整个社会经济体系安全的保障。加强软件安全,尤其是在开发阶段识别和修补漏洞,是企业必须重视的问题。国际数据公司(IDC…...

占道经营检测-目标检测数据集(包括VOC格式、YOLO格式)
占道经营检测-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接:https://pan.baidu.com/s/1e4Ydsb7FaUeWcQ-76ClTpQ?pwdq7n7 提取码:q7n7 数据集信息介绍: 共有 1143 张图像和一一对应的标注文件 标…...

Yuzu模拟器进阶设置指南:图形选项怎么调?多核CPU如何利用?让你的《王国之泪》帧数翻倍
Yuzu模拟器进阶设置指南:图形选项与多核CPU优化实战 当《塞尔达传说:王国之泪》在Yuzu模拟器上运行时,你是否遇到过这些情况:画面闪烁不定、帧数剧烈波动、复杂场景突然卡顿?这些问题往往源于模拟器设置与硬件特性的不…...

告别烦人黑窗口!QT Creator控制台程序输出完美嵌入IDE的保姆级设置
告别烦人黑窗口!QT Creator控制台程序输出完美嵌入IDE的保姆级设置 每次调试C控制台程序时,那个突然弹出的黑窗口是否总让你分心?作为开发者,我们都渴望一个纯净的编码环境——所有信息集中在一处,无需在多个窗口间来回…...

微积分入门书籍之高考篇
导数的秘密(第二版)-2021.01 高考导数满分精讲(2021) 高考导数探秘:解题技巧与策略 董晟渤(2024.10) 微积分与高考数学(第2版)-2024 高考导数解题全攻略(2024…...

从U-Net到DocUNet:一个图像分割经典架构如何“跨界”解决文档矫正难题?
从U-Net到DocUNet:经典分割架构如何重塑文档图像矫正技术 当你在咖啡馆随手拍下一张皱巴巴的收据时,是否想过手机镜头捕捉的二维图像如何还原成平整的文档?这个看似简单的需求背后,隐藏着计算机视觉领域一个极具挑战性的几何变换问…...

虚幻引擎小白人下岗指南:三步搞定商城角色替换,附赠武器隐藏和动画修复彩蛋
虚幻引擎角色替换实战指南:从基础操作到进阶技巧 第一次打开虚幻引擎时,那个默认的"小白人"角色总让人感觉缺乏个性。作为开发者,我们都希望游戏中的角色能快速展现独特风格。本文将带你用最简洁的流程完成商城角色替换,…...

通过ip命令配置网络地址的方法
cat ../ip_cfg.sh # 为 end1 接口添加一个静态 IP 地址 (例如: 192.168.1.100/24) sudo ip addr add 196.12.0.100/24 dev end1# 激活 end1 接口 sudo ip link set end1 up# (可选)添加默认网关,例如 192.168.1.1 sudo ip route add default …...

如何高效实现30+输入法词库互转:一站式智能转换方案解放生产力
如何高效实现30输入法词库互转:一站式智能转换方案解放生产力 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 你是否曾因更换输入法而不得不放弃多年积累…...

Helix QAC 2023.1更新:编码标准覆盖率如何提升C/C++项目合规性
1. 项目概述:一次聚焦于“合规性”的精准升级最近在梳理团队今年的代码质量工具链时,Helix QAC 2023.1的更新通知引起了我的注意。作为一名常年与C/C代码质量、功能安全标准(如MISRA、AUTOSAR C14)打交道的开发者,我对…...

解决QGIS自定义投影难题:手把手教你添加中科院资源环境数据的Krasovsky_1940_Albers投影
QGIS自定义投影实战:精准处理Krasovsky_1940_Albers科研数据 第一次打开中科院资源环境数据中心下载的栅格数据时,那个扭曲变形的中国地图让我愣了几秒——这显然不是常见的WGS84或CGCS2000坐标系。右下角状态栏显示着一个陌生的名字:Krasovs…...

3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业
3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业 【免费下载链接】lilToon Feature-rich shaders for avatars 项目地址: https://gitcode.com/gh_mirrors/li/lilToon 如果你正在Unity中寻找一个既能满足专业需求又容易上手的卡通渲染解决方案&am…...