【MySQL】表的基本查询

目录
🌈前言🌈
📁 创建Creator
📂 插入数据
📂 插入否则更新
📂 替换
📁 读取Retrieve
📂 select列
📂 where条件
📂 结果排序
📂 筛选分页结果
📁 删除Delete
📂 删除指定行
📂 删除整张表
📂 截断表
📁 更新Update
📁 插入查询结果
📁 聚合函数
📁 group by子句的使用
📁 总结
🌈前言🌈
本期【MySQL】,主要讲解关于表的内容的操作,包含了如何在表中插入数据,查找数据,删除以及更新表的内容,此外在查找数据时,还会介绍聚合函数以及group by子句的使用。
关于表结构的基本操作,在下面这篇文章中会有介绍:
【MySQL】数据库和表的操作-CSDN博客

📁 创建Creator
在MySQL中使用insert into(可省略)来插入一行或者多行数据。
INSERT INTO table_name (column1, column2, column3, ...)VALUES (value1, value2, value3, ...);table_name: 表名
column_: 列名
value_: 具体数值📂 插入数据
如果我们想要插入全部的列,即全列插入,那么column_是可以省略的;指定列插入则必须写明要插入的列有哪些。
values后面可以是插入的单行数据,也可以是多行数据。
mysql> create table student( -> id int(10) primary key auto_increment,-> name varchar(20),-> age int(10));
Query OK, 0 rows affected, 2 warnings (0.03 sec)mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| age | int | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
我们首先创建一个学生的表格,接下来插入数据。
//全列 + 单行 插入
mysql> insert into student value (1,'刘备',18);
Query OK, 1 row affected (0.01 sec)//全列 + 多行插入
mysql> insert into student value (2,'关羽',18),(3,'张飞',18);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0//指定列 + 单行插入
mysql> insert into student (name,age) value ('曹操',19);
Query OK, 1 row affected (0.00 sec)//指定列 + 多行插入
mysql> insert into student (name,age) value ('孙权',21),('孙策',20);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 18 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 孙策 | 20 |
+----+--------+------+
6 rows in set (0.00 sec)
📂 插入否则更新
INSERT ... ON DUPLICATE KEY UPDATEcolumn = value [, column = value] ...由于主键或者唯一键冲突,导致无法插入数据而导致插入失败。
--0 row affected:表中有冲突数据,但冲突数据的值和update后的值相等。
--1 row affected:表中没有冲突数据,直接插入。
--2 row affected:表中有冲突数据,更新冲突数据。
//主键冲突
mysql> insert into student value (1,'董卓',30);
ERROR 1062 (23000): Duplicate entry '1' for key 'student.PRIMARY'//唯一键冲突如果age设置成唯一键unique,插入两个相同值的age就会产生唯一键冲突,这里就不演示了
产生了主键冲突,那么我们就可以使用on duolicate key update,插入否则更新。
//插入id为1的单行数据,如果表内有冲突,就更新冲突行mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 18 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 孙策 | 20 |
+----+--------+------+
6 rows in set (0.00 sec)mysql> insert into student value (1,'董卓',30) on duplicate key update age = 19;
Query OK, 2 rows affected (0.02 sec)mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 孙策 | 20 |
+----+--------+------+
6 rows in set (0.00 sec)
📂 替换
主键或者唯一键产生冲突,就删除冲突行,再插入新的行;没有冲突,直接插入。
mysql> replace into student value (7,'董卓',30);
Query OK, 1 row affected (0.01 sec)mysql> replace into student value (6,'吕布',25);
Query OK, 2 rows affected (0.00 sec)mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
+----+--------+------+
7 rows in set (0.00 sec)
--1 row affected:表中没有冲突数据,直接插入
--2 row affected:表中有冲突数据,删除后再插入。
📁 读取Retrieve
在MySQL中使用select语句来查询数据。
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC | DESC]]
[LIMIT number];● column1, column2, ... 是你想要选择的列的名称,如果使用 * 表示选择所有列。● table_name 是你要从中查询数据的表的名称。● WHERE condition 是一个可选的子句,用于指定过滤条件,只返回符合条件的行。● ORDER BY column_name [ASC | DESC] 是一个可选的子句,用于指定结果集的排序顺序,默认是升序(ASC)。● LIMIT number 是一个可选的子句,用于限制返回的行数。📂 select列
全列查询
不建议使用,但平常练习时可以使用。 1. 查询的列越多,意味着需要传输的数据量越大;2. 可能会影响到索引的使用。
select * from table_name;mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
+----+--------+------+
7 rows in set (0.00 sec)
指定列插入,指定列的顺序不需要按定义表的顺序。
select column1[,column2...] from table_name;mysql> select id,name from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 刘备 |
| 2 | 关羽 |
| 3 | 张飞 |
| 4 | 曹操 |
| 5 | 孙权 |
| 6 | 吕布 |
| 7 | 董卓 |
+----+--------+
7 rows in set (0.00 sec)
查询字段为表达式。
mysql> select 10;
+----+
| 10 |
+----+
| 10 |
+----+
1 row in set (0.00 sec)mysql> select 10 + 10;
+---------+
| 10 + 10 |
+---------+
| 20 |
+---------+
1 row in set (0.00 sec)mysql> select id,name,age+100 from student;
+----+--------+---------+
| id | name | age+100 |
+----+--------+---------+
| 1 | 刘备 | 119 |
| 2 | 关羽 | 118 |
| 3 | 张飞 | 118 |
| 4 | 曹操 | 119 |
| 5 | 孙权 | 121 |
| 6 | 吕布 | 125 |
| 7 | 董卓 | 130 |
+----+--------+---------+
7 rows in set (0.00 sec)
为查询结果指定别名
SELECT column [AS] alias_name [...] FROM table_name;mysql> select id,name,age 年龄 from student;
+----+--------+--------+
| id | name | 年龄 |
+----+--------+--------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
+----+--------+--------+
7 rows in set (0.00 sec)mysql> ^C
mysql> select id,name,age as 年龄 from student;
+----+--------+--------+
| id | name | 年龄 |
+----+--------+--------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
+----+--------+--------+
7 rows in set (0.00 sec)
结果去重
需要读取不重复的数据可以在 select 语句中使用 distinct 关键字来过滤重复数据。
mysql> select distinct age from student;
+------+
| age |
+------+
| 19 |
| 18 |
| 21 |
| 25 |
| 30 |
+------+
5 rows in set (0.00 sec)
📂 where条件
where类似于高级语言中的if语句。
比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
关于like的使用:
% :匹配任意多个(包括 0 个)任意字符
_ :匹配严格的一个任意字符
mysql> select * from student;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
8 rows in set (0.00 sec)mysql> select * from student where name like '孙_';
+----+--------+------+
| id | name | age |
+----+--------+------+
| 5 | 孙权 | 21 |
+----+--------+------+
1 row in set (0.00 sec)mysql> select * from student where name like '孙%';
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 5 | 孙权 | 21 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
2 rows in set (0.00 sec)
其他运算符非常简单,有C/C++基础的同学能做到见名知义,只需要在where后面加上这些运算符即可。
📂 结果排序
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
mysql> select * from student order by age desc;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 7 | 董卓 | 30 |
| 6 | 吕布 | 25 |
| 5 | 孙权 | 21 |
| 1 | 刘备 | 19 |
| 4 | 曹操 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
8 rows in set (0.00 sec)mysql> select * from student order by age asc;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 8 | 孙尚香 | 18 |
| 1 | 刘备 | 19 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 7 | 董卓 | 30 |
+----+-----------+------+
8 rows in set (0.00 sec)📂 筛选分页结果
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
mysql> select * from student limit 5-> ;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
+----+--------+------+
5 rows in set (0.00 sec)mysql> select * from student limit 0,3;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
+----+--------+------+
3 rows in set (0.00 sec)mysql> select * from student limit 5 offset 0;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
+----+--------+------+
5 rows in set (0.00 sec)
📁 删除Delete
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]📂 删除指定行
mysql> delete from student where name='董卓';
Query OK, 1 row affected (0.01 sec)mysql> select * from student where name='董卓';
Empty set (0.00 sec)mysql> select * from student;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
7 rows in set (0.00 sec)📂 删除整张表
mysql> select * from delete_table;
+------+
| id |
+------+
| 1 |
| 2 |
+------+
2 rows in set (0.00 sec)mysql> delete from delete_table;
Query OK, 2 rows affected (0.00 sec)mysql> select * from delete_table;
Empty set (0.00 sec)
📂 截断表
truncate [TABLE] table_name截断表的操作类似于delete删除整张表的操作,但是不能像delete一样针对部分数据操作;
实际上MySQL不对数据操作,所以比delete更快,但是truncate在删除数据的时候,并不经过真正的事务,所以无法回滚。
truncate会重置auto_increment,delete不会重置auto_increment。
📁 更新Update
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新。
mysql> select * from student;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 刘备 | 19 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
7 rows in set (0.00 sec)mysql> update student set age=20 where name='刘备';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from student;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 刘备 | 20 |
| 2 | 关羽 | 18 |
| 3 | 张飞 | 18 |
| 4 | 曹操 | 19 |
| 5 | 孙权 | 21 |
| 6 | 吕布 | 25 |
| 8 | 孙尚香 | 18 |
+----+-----------+------+
7 rows in set (0.00 sec)📁 插入查询结果
insert into table_name [(column [, column ...])] select ...删除表中的的重复复记录,重复的数据只能有一份。
-- 创建原数据表
CREATE TABLE duplicate_table (id int, name varchar(20));-- 插入测试数据
INSERT INTO duplicate_table VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
CREATE TABLE no_duplicate_table LIKE duplicate_table;-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table-- 通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table,
no_duplicate_table TO duplicate_table;SELECT * FROM duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+📁 聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
mysql> select count(*) from student;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
其他聚合函数也类似于count()函数一样,这里就不展示了。
指定列名,那么实际分组的时候,用该列不同的数据进行分组。组内一定是相同的,因此可以被聚合压缩。
分组,就是将一组按条件拆分成多组,进行各自组内的聚合统计。即一张表按照条件在逻辑上拆分成多个子表,分别对各自的子表进行聚合统计
📁 group by子句的使用
select column1, column2, .. from table group by column;在select中使用group by子句可以对指定列进行分组查询,分组的目的就是方便聚合统计。
mysql> select * from student;
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 9 | 刘备 | 18 |
| 10 | 关羽 | 18 |
| 11 | 张飞 | 18 |
| 12 | 曹操 | 19 |
| 13 | 孙策 | 20 |
| 14 | 孙权 | 20 |
| 15 | 孙尚香 | 20 |
+----+-----------+------+
7 rows in set (0.00 sec)mysql> select age 年龄,max(id) from student group by age;
+--------+---------+
| 年龄 | max(id) |
+--------+---------+
| 18 | 11 |
| 19 | 12 |
| 20 | 15 |
+--------+---------+
3 rows in set (0.00 sec)mysql> select age 年龄,max(id) from student group by age having age > 18;
+--------+---------+
| 年龄 | max(id) |
+--------+---------+
| 19 | 12 |
| 20 | 15 |
+--------+---------+
2 rows in set (0.00 sec)having是对聚合后的统计数据,进行条件筛选。
where是具体的任意列进行条件筛选;having是对分组聚合之后的结果进行条件筛选。
📁 总结
以上,就是本期内容了,主要讲解了MySQL中表的内容的操作CRUD,即插入数据,读取数据,更新数据,删除数据等内容。
如果感觉本期内容对你有帮助,欢迎点赞,关注,收藏Thanks♪(・ω・)ノ

相关文章:
【MySQL】表的基本查询
目录 🌈前言🌈 📁 创建Creator 📂 插入数据 📂 插入否则更新 📂 替换 📁 读取Retrieve 📂 select列 📂 where条件 📂 结果排序 📂 筛选分页结果…...

李宏毅2023机器学习HW15-Few-shot Classification
文章目录 LinkTask: Few-shot ClassificationBaselineSimple—transfer learningMedium — FO-MAMLStrong — MAML Link Kaggle Task: Few-shot Classification The Omniglot dataset background set: 30 alphabetsevaluation set: 20 alphabetsProblem setup: 5-way 1-sho…...
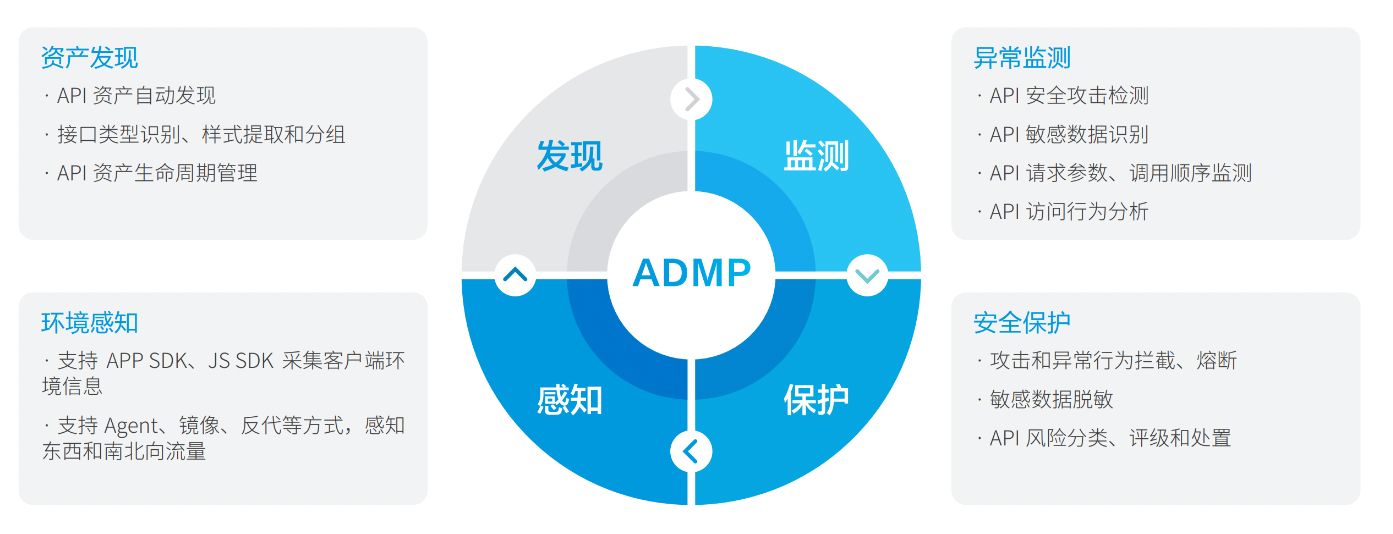
API安全推荐厂商瑞数信息入选IDC《中国数据安全技术发展路线图》
近日,全球领先的IT研究与咨询公司IDC发布报告《IDC TechScape:中国数据安全技术发展路线图,2024》。瑞数信息凭借其卓越的技术实力和广泛的行业应用,被IDC评选为“增量型”技术曲线API安全的推荐厂商。 IDC指出,数据安…...

1.5 计算机网络的性能指标
参考:📕深入浅出计算机网络 目录 速率 带宽 吞吐量 时延 时延带宽积 往返时间 利用率 丢包率 速率 速率是指数据的传送速率(即每秒传送多少个比特),也称为数据率(Data Rate)或比特率&am…...

【已解决】IDEA鼠标光标与黑块切换问题,亲测有效
前言 前两天我妹妹说她室友的idea光标变成黑块状了,解决不了跑来问我,这是刚入门开发者经常遇到的问题,这篇文章介绍一下这两种方式,方便刚入门的小伙伴儿们更清楚地了解idea,使用idea。 希望这篇文章能够帮助到遇到…...
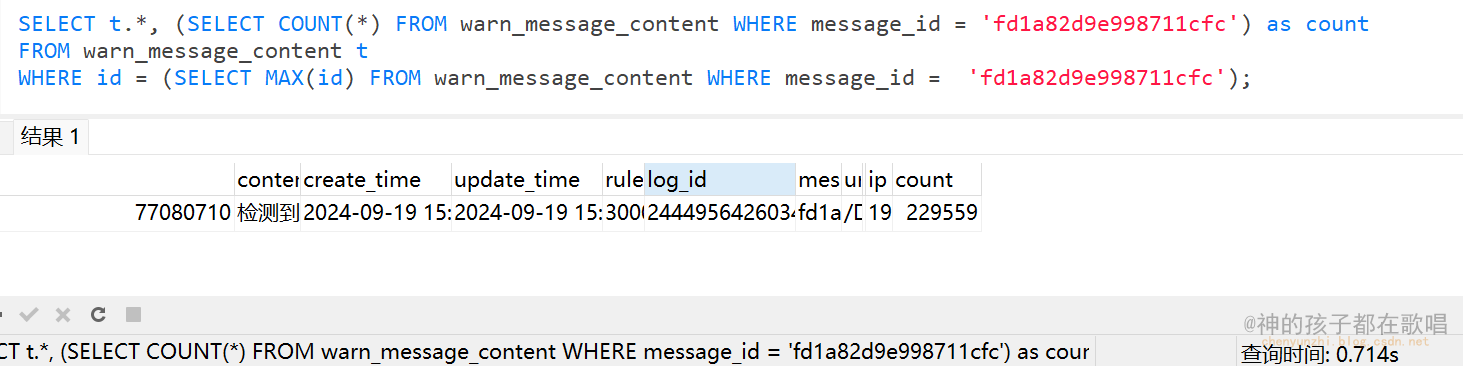
记一次sql查询优化
记一次sql查询优化 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 今天测试环境发现一个问题,就是测试同事在测试的时候,发现cpu一直居高不下,然…...
)
str函数的模拟(包括strn函数的模拟)
首先先说这些函数引用的头文件是<string.h> 1.strlen函数 int my_strlen(char* s1) { //这里只用最难的方法 if (*s1) { return my_strlen(s1 1) 1; } else return 0; } 这里使用了递归的方法(不创建新的变量࿰…...

畅阅读微信小程序
畅阅读微信小程序 weixin051畅阅读微信小程序ssm 摘 要 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用j…...

RHEL7(RedHat红帽)软件安装教程
目录 1、下载RHEL7镜像 2、安装RedHat7 注:如果以下教程不想看,可以远程控制安装V:OYH-Cx330 【风险告知】 本人及本篇博文不为任何人及任何行为的任何风险承担责任,图解仅供参考,请悉知!本次安装图解是在一个全新的演…...

CC 攻击:一种特殊的 DDoS 攻击
引言 分布式拒绝服务(Distributed Denial of Service,简称 DDoS)攻击是指攻击者利用多台计算机或其他网络资源对目标发起大量请求,使目标服务器不堪重负,无法正常响应合法用户的请求。CC(Challenge Collap…...

掌上高考爬虫逆向分析
目标网站 aHR0cHM6Ly93d3cuZ2Fva2FvLmNuL3NjaG9vbC9zZWFyY2g/cmVjb21zY2hwcm9wPSVFNSU4QyVCQiVFOCU4RCVBRg 一、抓包分析 二、逆向分析 搜索定位加密参数 本地生成代码 var CryptoJS require(crypto-js) var crypto require(crypto);f "D23ABC#56"function v(t…...

忘了SD吧,现在是Flux的时代
Stable Diffusion大量人员离职,不过离职后核心人员依然从事相关工作,Flux就是SD的原班人马创作的。 在SD3后推出不久,Flux横空出世。 可以说,优秀的Flux和付费版的MJ效果相差不大(前提是配置足够高,能进行…...

服务器安装openssh9.9p1
11.81.2.19 更新 SSL 备份原有配置 1.1 查看 openssl 版本 openssl version OpenSSL 1.0.2k-fips 26 Jan 20171.2 查看 openssl 路径 whereis openssl openssl: /usr/bin/openssl /usr/lib64/openssl /usr/include/openssl /usr/share/man/man1/openssl.1ssl.gz1.3 备份 op…...
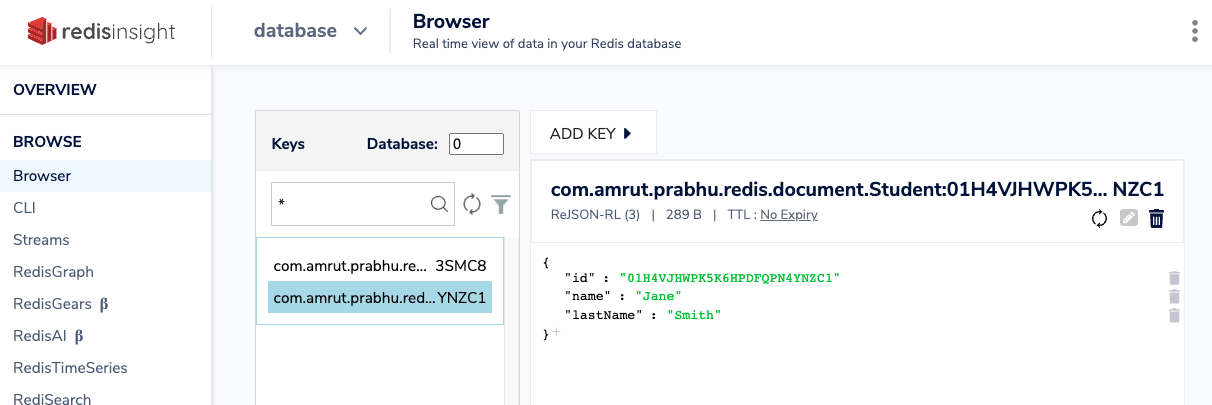
Spring Boot集成Redis Search快速入门Demo
1.什么是Redis Search? RedisSearch 是一个基于 Redis 的搜索引擎模块,它提供了全文搜索、索引和聚合功能。通过 RedisSearch,可以为 Redis 中的数据创建索引,执行复杂的搜索查询,并实现高级功能,如自动完…...

提升工作效率神器
这五款软件让你事半功倍 在当今快节奏的社会中,提高工作效率成为了每个人追求的目标。而在这个数字化时代,选择对的软件工具无疑是提高效率的关键。今天,我为大家推荐五款优秀的工作效率软件,帮助你在工作中事半功倍。 1、亿可达…...

统信服务器操作系统【targetcli部署】
targetcli部署方案 文章目录 功能概述功能介绍1.安装targetcli2.targetcli语法及参数说明3.示例1. 配置2.访问功能概述 SCSI 即小型计算机系统接口(Small Computer System Interface;简写:SCSI) iSCSI,internet SCSI 网络磁盘 ,提供一对一的网络存储, 主机A 提供xx存储设…...
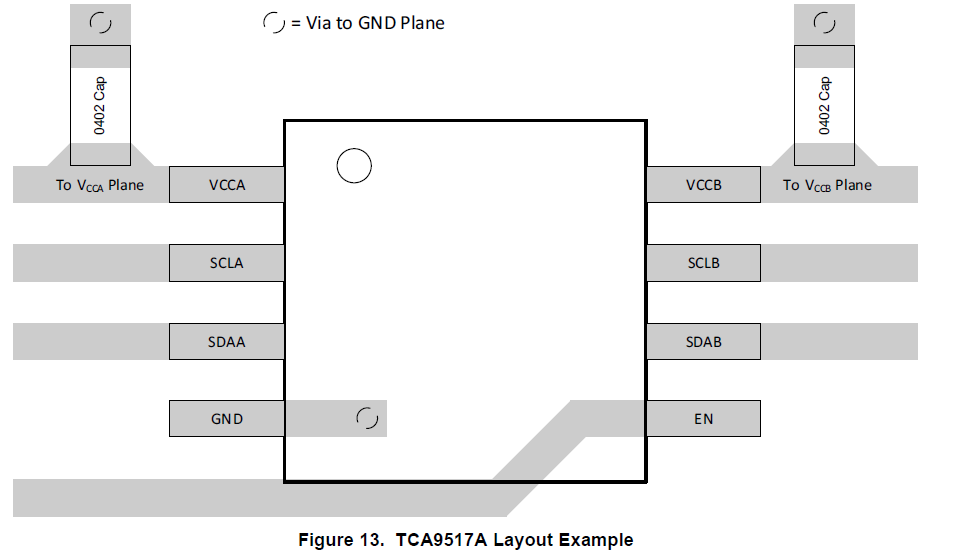
I2C中继器TCA9517A(TI)
一、芯片介绍 本芯片是一款具有电平转换功能的双向缓冲器,适用于I2C和SMBus系统,同时支持各种拓扑结构的扩展使用。芯片支持SCL和SDA缓冲,因此允许两条总线的负载电容达到400pF。 TCA9517A的A和B侧驱动器是不同的,但是均可耐受5…...

基于单片机的智能电话控制系统设计
摘要: 为了能够使用电话实现电器设备的控制,文中通过单片机及双音多频解码集成电路,使用用 户通过电话输入相应的指令就能够实现远程设备的智能化控制。文章主要对系统的构成、软件及 硬件设计进行了简单的介绍,并且对其中的电路进行了简单的说明,比如语音提示、双音频解…...

Go 综合题面试题
1. Golang 中 make 和 new 的区别? #make 和 new 都用于内存分配1:接收参数个数不一样: new() 只接收一个参数,而 make() 可以接收3个参数2:返回类型不一样: new() 返回一个指针,而 make() 返回…...

【Python报错已解决】AttributeError: ‘Tensor‘ object has no attribute ‘kernel_size‘
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 专栏介绍 在软件开发和日常使用中,BUG是不可避免的。本专栏致力于为广大开发者和技术爱好者提供一个关于BUG解决的经…...
)
告别Qt默认英文!3分钟搞定QMessageBox按钮中文显示(附完整代码示例)
3分钟实现QMessageBox按钮中文显示的实战指南 刚接触Qt开发的程序员经常会遇到一个尴尬问题——精心设计的界面突然弹出英文按钮的对话框。这种"半中半英"的体验在交付给国内客户时尤为明显。今天我们就来解决这个看似简单却困扰很多开发者的问题,无需复杂…...

解锁Nintendo Switch游戏备份的终极指南:nxdumptool完全攻略
解锁Nintendo Switch游戏备份的终极指南:nxdumptool完全攻略 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirro…...

龙芯2K3000与国产OS在轨道交通AFC系统中的工程实践
1. 项目概述:当国产芯遇上城市动脉每天早晚高峰,地铁站里人头攒动,闸机开合的“嘀嘀”声此起彼伏。你可能没留意,支撑这套庞大自动售检票系统(AFC)稳定运行的“大脑”,正经历一场静默而深刻的变…...

抠图软件在线使用有哪些?2026年最全对比测试,找到适合你的工具
最近被问得最多的问题就是:"有没有特别好用的抠图软件?"说实话,这两年AI技术的发展真的改变了抠图这件事儿。我自己也用过不少抠图工具,从专业的PS到各种在线应用,今天就来好好聊聊抠图软件在线使用有哪些选…...

Python迭代器实战:构建高性能懒加载积分榜系统
1. 项目概述:从“可迭代”到“可控制”的数据流在Python的世界里,处理数据集合是家常便饭。无论是从数据库拉取用户列表,还是逐行读取一个巨大的日志文件,我们总在和各种序列打交道。但你是否想过,当你写下一个简单的f…...

SharpCompress实战:一个方法搞定C#里ZIP压缩打包,附赠RAR/7Z解压和TAR.GZ创建教程
C#压缩解压全能手册:用SharpCompress玩转ZIP/RAR/7Z/TAR.GZ 在开发日志管理系统、文件上传模块或数据备份工具时,文件压缩解压功能就像空气一样不可或缺。但面对ZIP、RAR、7Z、TAR.GZ这些格式各异的压缩包,不少开发者都会陷入API选择的困境。…...

QuickLookVideo:让Mac上的视频文件管理变得轻松直观
QuickLookVideo:让Mac上的视频文件管理变得轻松直观 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcode.…...

OpenRGB终极指南:如何用开源软件统一管理所有RGB设备,告别多软件混乱
OpenRGB终极指南:如何用开源软件统一管理所有RGB设备,告别多软件混乱 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcPr…...

GEO优化实战指南:中小企业如何精准提升本地服务获客效率?
随着线上营销的重要性日益凸显,中小企业面临着前所未有的机遇与挑战。GEO(生成式引擎优化)作为近年来兴起的一种技术手段,旨在帮助企业更高效地利用AI平台进行品牌推广与客户获取。本文将探讨中小企业如何通过GEO优化策略…...
)
从Demo到实战:手把手教你用OpenMMLab的MMDetection训练自己的第一个目标检测模型(附数据集制作)
从零构建目标检测模型:OpenMMLab实战指南与数据集制作全流程 当你第一次成功运行OpenMMLab的Demo时,那种成就感可能很快会被新的困惑取代——如何让这套强大的工具识别你自己的数据?本文将带你跨越从"跑通示例"到"训练自定义模…...