【数据结构初阶】链式二叉树接口实现超详解
文章目录
- 1. 节点定义
- 2. 前中后序遍历
- 2. 1 遍历规则
- 2. 2 遍历实现
- 2. 3 结点个数
- 2. 3. 1 二叉树节点个数
- 2. 3. 2 二叉树叶子节点个数
- 2. 3. 3 二叉树第k层节点个数
- 2. 4 二叉树查找值为x的节点
- 2. 5 二叉树层序遍历
- 2. 6 判断二叉树是否是完全二叉树
- 3. 二叉树性质
1. 节点定义
用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址,其基本结构如下:
typedef int BTDataType;
typedef struct BinaryTreeNode
{BTDataType data; //数据struct BinaryTreeNode* left; //左孩子struct BinaryTreeNode* right; //右孩子
}BTNode;
链式二叉树的创建方式比较复杂,为了更好地对接口进行调试,我们先手动创建一棵链式二叉树进行测试:
//创建节点
BTNode* BuyBTNode(int val)
{BTNode * newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail");return NULL;}newnode->data = val;newnode->left = NULL;newnode->right = NULL;return newnode;
}
BTNode * CreateTree()
{BTNode * n1 = BuyBTNode(1);BTNode * n2 = BuyBTNode(2);BTNode * n3 = BuyBTNode(3);BTNode * n4 = BuyBTNode(4);BTNode * n5 = BuyBTNode(5);BTNode * n6 = BuyBTNode(6);BTNode * n7 = BuyBTNode(7);//手动将他们连接起来成为一棵二叉树n1->left = n2;n1->right = n4;n2->left = n3;n4->left = n5;n4->right = n6;n5->left = n7;return n1;
}
接下来就可以用这棵二叉树对接口进行测试。
2. 前中后序遍历
二叉树不同于之前的顺序结构,不能直接进行依次遍历,必须按照一定的规则进行遍历。
注:堆也是一种二叉树,但是堆不能进行遍历,所以没有这方面的考虑。
另外二叉树的链式结构是一个递归的结构,几乎所有的接口实现都需要用到递归的思想。

2. 1 遍历规则
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
- 前序遍历(Preorder Traversal,亦称先序遍历):访问根结点的操作发生在遍历其左右子树之前
访问顺序为:根结点、左子树、右子树 - 中序遍历(lnorder Traversal):访问根结点的操作发生在遍历其左右子树中间
访问顺序为:左子树、根结点、右子树 - 后序遍历(Postorder Traversal):访问根结点的操作发生在遍历其左右子树之后
访问顺序为:左子树、右子树、根结点
我们以前序遍历解释一下怎么遍历:

从根节点1开始遍历,先输出根节点数据1,然后来到左孩子2,输出2,来到2的左孩子3,输出3,来到3的左孩子NULL,回退至3,来到3的右孩子NULL,再回退,3节点遍历完毕,回退至2,来到2的右节点NULL,回退至2,2节点遍历完毕,回退至1,来到1的右孩子4,先输出4,再来到4的左孩子4,输出4,遍历左右俩孩子都为空,回退至上面的4,来到4的右孩子5,输出5后,俩孩子都为空,再最终回退至1,根节点遍历完成,该二叉树遍历完成。
前序遍历结果:123456
中序遍历结果:321546
后序遍历结果:315641
2. 2 遍历实现
在实现时,我们可以把每一个孩子都看成一个二叉树的根节点,以方便递归遍历。
//前序遍历
void BinaryTreePrevOrder(BTNode* root)
{if (!root)return;printf("%d ", root->data);BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);
}
//后序遍历
void BinaryTreePostOrder(BTNode* root)
{if (!root)return;BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);printf("%d ", root->data);
}
//中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (!root)return;BinaryTreePrevOrder(root->left);printf("%d ", root->data);BinaryTreePrevOrder(root->right);
}

2. 3 结点个数
2. 3. 1 二叉树节点个数
int BinaryTreeSize(BTNode* root);
二叉树中只有结点,没有把数据个数存储起来,那么我们要怎么获取二叉树中元素的个数呢?
有两种思路,一个是创建全局变量,然后通过任意一种遍历方式遍历二叉树,每遍历一次都让这个变量++,那么就能得到节点的个数了,但是这样会带来两个问题:
- 全局变量每次都要归0,但是由于是递归进行遍历的,所以需要写一个子函数用于递归。
- 在函数内部调用全部变量可能会存在危险,因为这个变量是任何函数都能访问并修改的。
基于这样的原因,我们不采用这个方式。
而是通过计算这个节点本身+左子树节点的个数+右子树节点的个数的方式进行递归。
int BinaryTreeSize(BTNode* root)
{if (!root)return 0;return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right); //1就是该节点本身,再加上左右两棵子树
}
2. 3. 2 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
叶子节点的特点就是root->left == NULL && root->right == NULL,所以只要加上一个判断是否要+1,其他的就和计算节点个数的思路是一样的。
int BinaryTreeLeafSize(BTNode* root)
{//如果是叶子节点,就没必要继续向下传递了,直接回归就可以了if (!root)return 0;if (root->left == NULL && root->right == NULL)return 1;return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
2. 3. 3 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
在传递时增加一个参数k,来判断递归到哪一层了,如果是目标层数,就+1回归,其他与计算二叉树叶子节点个数思路一致。
int BinaryTreeLevelKSize(BTNode* root, int k)
{//同理,到目标层数之后就不需要继续向下传递了if (!root)return 0;if (k == 1)return 1;return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}
2. 4 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
在二叉树中遍历并对比数据,如果找到了就返回这个节点的指针,没找到就返回NULL。
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (!root)return NULL;if (root->data == x)return root;//需要分别判断左右子树中有没有这个数据//左BTNode* leftfind = BinaryTreeFind(root->left,x);if (leftfind)return leftfind;//右BTNode* rightfind = BinaryTreeFind(root->right,x);if (rightfind)return rightfind;//没找到,返回空return NULL;
}
2. 5 二叉树层序遍历
除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。
设二叉树的根结点所在层数为1,层序遍历就是从所在二叉树的根结点出发,首先访问第一层的根结点,然后从左到右访问第2层上的结点,接着是第三层的结点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
实现层序遍历需要额外借助队列这一数据结构。

层序遍历就是一层一层地从左到右地进行遍历,比如上面这棵二叉树的层序遍历就是:1 2 3 4 5 6 7
大致思路为:创建一个数据类型为BTNode*的队列,先将根节点入队列,然后分别将它的左右孩子入队列,接着出队列一次。然后把队头的左右孩子(如果不为NULL)入队列,再出队列一次,每次出队列前都要把它的值打印出来,循环以上过程直到队列为空。
注:这里的队列不再实现,可以看这篇博客。
void BinaryTreeLevelOrder(BTNode* root)
{//二叉树判空if (!root)printf("null\n");//创建队列并初始化Queue qu;QueueInit(&qu);//把根节点入队列QueuePush(&qu, root);while (!QueueEmpty(&qu)){//将队头的左右子树入队列,并将队头数据打印,再出队列一次BTNode* tmp = QueueFront(&qu);QueuePop(&qu);printf("%d ", tmp->data);if (tmp->left)QueuePush(&qu, tmp->left);if (tmp->right)QueuePush(&qu, tmp->right);}//销毁队列QueueDestroy(&qu);printf("\n");
}
2. 6 判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BTNode* root);
完全二叉树的特点是第X层没有完全放满时,X+1层不能有节点,且没有满的层的节点必须是从左往右排布的。
我们可以借助层序遍历来判断二叉树是不是完全二叉树。
步骤为:就算节点为空也要入队列,直到出队列时遇到了空节点时,开始连续出队列,如果队列中剩下的元素中有非空的节点,就说明不是完全二叉树。
我们以这棵二叉树为例:

当轮到4的左孩子(尽管不存在,但先这么理解一下)出队列时,开始不再入队列,只出队列并判断是否为空,这时队列中还有4的右节点7,那就判断出来了二叉树不是完全二叉树。
如果在第一次出队列的为空节点的之后的节点都是空节点(比如上面这个二叉树没有节点7),那就是完全二叉树。
bool BinaryTreeComplete(BTNode* root)
{assert(root);Queue qu;QueueInit(&qu);QueuePush(&qu, root);while (!QueueEmpty(&qu)){BTNode* tmp = QueueFront(&qu);//如果出队列的是空节点,就停止这个循环if (!tmp)break;QueuePop(&qu);QueuePush(&qu, tmp->left);QueuePush(&qu, tmp->right);}//这个循环只出不入while (!QueueEmpty(&qu)){//如果队列中还有空节点,就说明不是完全二叉树if (QueueFront(&qu)){QueueDestroy(&qu);return false;}QueuePop(&qu);}QueueDestroy(&qu);return true;
}
3. 二叉树性质
- 对任何一棵二叉树,如果度为 0 的叶结点个数为n0,度为 2 的分支结点个数为n2 ,则有
n0 = n2+1

证明:
假设一个二叉树有 a 个度为 2 的节点,b 个度为 1 的节点,c 个叶节点,则这个二叉树的边数是 2a+b
另一方面,由于共有 a+b+c 个节点,所以边数等于 a+b+c-1
结合上面两个公式:
即 2a+b = a+b+c-1,即 a=c-1
题目练习
-
某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为( )
A 不存在这样的二叉树
B 200
C 198
D 199
有199个度为2的节点,那么在二叉树中,度为0的节点有199+1也就是200个,选B。 -
在具有 2n 个结点的完全二叉树中,叶子结点个数为()
A n
B n+1
C n-1
D n/2
设叶子节点有x个,那么度为2的节点为x-1个。有2n个节点,所以度为1的节点有2n-2x+1条,而完全二叉树中度为1的节点只有0或1个,但是这个二叉树的结点个数为偶数(由于根节点有1个,而其他的除了最后一层的结点个数都是偶数),所以度为1的结点个数为1。解方程2n-2x+1=1就可以得出x=n。选A。 -
一棵完全二叉树的结点数位为531个,那么这棵树的高度为()
A 11
B 10
C 8
D 12
完全二叉树每一层的节点个数为2n-1个,那么根据等比数列的求和公式,完全二叉树前n层的节点个数为2n-1,解方程2n-1>=531可得,n为10,选B。 -
一个具有767个结点的完全二叉树,其叶子结点个数为()
A 383
B 384
C 385
D 386
设叶子节点有x个,那么度为2的节点为x-1个,度为1的节点为768-2x个,通过第2题的分析我们可知度为1的节点为0个,就可以算出x=384,选B。
数据结构初阶的二叉树就到这里,想必你会发现这个二叉树我们没有实现插入删除的接口,因为二叉树的插入删除使用C语言实现过于复杂,会在高阶数据结构中讲解。
谢谢你的阅读,喜欢的话来个点赞收藏评论关注吧!
我会持续更新更多优质文章
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=10p1y5y691zy4
相关文章:
【数据结构初阶】链式二叉树接口实现超详解
文章目录 1. 节点定义2. 前中后序遍历2. 1 遍历规则2. 2 遍历实现2. 3 结点个数2. 3. 1 二叉树节点个数2. 3. 2 二叉树叶子节点个数2. 3. 3 二叉树第k层节点个数 2. 4 二叉树查找值为x的节点2. 5 二叉树层序遍历2. 6 判断二叉树是否是完全二叉树 3. 二叉树性质 1. 节点定义 用…...

力扣189 轮转数组 Java版本
文章目录 题目描述代码 题目描述 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4…...

RMAN异机恢复数据库记录
场景:数据库服务器宕机,无法恢复 处理:使用备份资料进行异地恢复 1.此处环境为同平台、同版本(操作系统版本可以不同,但数据库版本需相同),源机器和目标机器具有相同的目录结构。 2.目标机器只…...

JVM 调优篇7 调优案例4- 线程溢出
一 线程溢出 1.1 报错信息 每个 Java 线程都需要占用一定的内存空间,当 JVM 向底层操作系统请求创建一个新的 native 线程时,如果没有足够的资源分配就会报此类错误。报错信息:java.lang.outofmemoryError:unable to create new Native Thr…...

C++类与对象(三)
目录 1.再谈构造函数 1.1 构造函数体赋值 1.2 初始化列表 1.3 explicit关键字 2.STATIC成员 2.1 概念 2.2 特性 3.C中成员初始化的新玩法 4.友元 4.1 友元函数 4.2 友元类 5.内部类 6.再次理解封装 7.再次理解面向对象 本次内容大纲: 1.再谈构造函数 …...

云栖实录 | 阿里云 OpenLake 解决方案重磅发布:多模态数据统一纳管、引擎平权联合计算、数据共享统一读写
新一轮人工智能浪潮正在重塑世界,以生成式 AI 为代表的技术快速应用,推动了数据与智能的深化融合,同时也给数据基础设施带来了全新的变革与挑战。面向 AI 时代的数据基础设施如何构建?底层数据平台架构在 AI 时代如何演进…...

《线性代数》学渣笔记
文章目录 1 行列式1.1 克拉默法则1.2 基本性质1.3 余子式 M i j M_{ij} Mij1.4 代数余子式 A i j ( − 1 ) i j ⋅ M i j A_{ij} (-1)^{ij} \cdot M_{ij} Aij(−1)ij⋅Mij1.5 具体型行列式计算(化为基本型)1.5.1 主对角线行列式:主…...
对网页聊天项目进行性能测试, 使用JMeter对于基于WebSocket开发的webChat项目的聊天功能进行测试
登录功能 包括接口的设置和csv文件配置 这里csv文件就是使用xlsx保存数据, 然后在浏览器找个网址转成csv文件 注册功能 这里因为需要每次注册的账号不能相同, 所以用了时间函数来当用户名, 保证尽可能的给正确的注册数据, 时间函数使用方法如下 这里输入分钟, 秒…...
《程序猿之设计模式实战 · 适配器模式》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

Elasticsearch案例
目录 一、创建索引 二、准备数据 三、环境搭建 (1)环境搭建 (2)创建实体类 (3)实现Repository接口 四、实现自动补全功能 五、实现高亮搜索关键字功能 (1)在repository接口中…...

SpringBoot 项目如何使用 pageHelper 做分页处理 (含两种依赖方式)
分页是常见大型项目都需要的一个功能,PageHelper是一个非常流行的MyBatis分页插件,它支持多数据库分页,无需修改SQL语句即可实现分页功能。 本文在最后展示了两种依赖验证的结果。 文章目录 一、第一种依赖方式二、第二种依赖方式三、创建数…...

GSR关键词排名系统是针对谷歌seo的吗?
是的,GSR关键词排名系统专门针对谷歌SEO,具体通过外部优化手段快速提升关键词排名。不同于传统的SEO策略,GSR系统并不依赖于对网站内容的调整或内部优化,完全通过站外操作实现效果。这意味着,用户不需要花费精力在网站…...

HarmonyOS Next开发----使用XComponent自定义绘制
XComponent组件作为一种绘制组件,通常用于满足用户复杂的自定义绘制需求,其主要有两种类型"surface和component。对于surface类型可以将相关数据传入XComponent单独拥有的NativeWindow来渲染画面。 由于上层UI是采用arkTS开发,那么想要…...

什么是电商云手机?可以用来干什么?
随着电商行业的迅速发展,云手机作为一种创新工具正逐渐进入出海电商领域。专为外贸市场量身定制的出海电商云手机,已经成为许多外贸企业和出海电商卖家的必备。本文将详细介绍电商云手机是什么以及可以用来做什么。 与国内云手机偏向于游戏场景不同&…...

Python 2 和 Python 3的差异
Python 2 和 Python 3 之间有许多差异,Python 3 是 Python 语言的更新版本,目的是解决 Python 2 中的一些设计缺陷,并引入更现代的编程方式。以下是 Python 2 和 Python 3 之间的一些主要区别: 文章目录 1. print 语句2. 整除行为…...

Leetcode 第 139 场双周赛题解
Leetcode 第 139 场双周赛题解 Leetcode 第 139 场双周赛题解题目1:3285. 找到稳定山的下标思路代码复杂度分析 题目2:3286. 穿越网格图的安全路径思路代码复杂度分析 题目3:3287. 求出数组中最大序列值思路代码复杂度分析 题目4:…...
spring 注解 - @NotEmpty - 确保被注解的字段不为空,而且也不是空白(即不是空字符串、不是只包含空格的字符串)
NotEmpty 是 Bean Validation API 提供的注解之一,用于确保被注解的字段不为空。它检查字符串不仅不是 null,而且也不是空白(即不是空字符串、不是只包含空格的字符串)。 这个注解通常用在 Java 应用程序中,特别是在处…...

深入理解华为仓颉语言的数值类型
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在编程过程中,数据处理是开发者必须掌握的基本技能之一。无论是开发应用程序还是进行算法设计,了解不同数据类型的特性和用途都至关重要。本文将深入探讨华为仓颉语言中的基本数…...
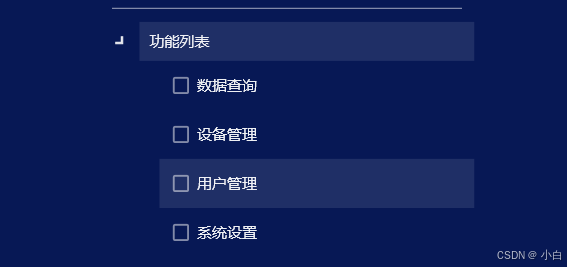
WPF 的TreeView的TreeViewItem下动态生成TreeViewItem
树形结构仅部分需要动态生成TreeViewItem的可以参考本文。 xaml页面 <TreeView MinWidth"220" ><TreeViewItem Header"功能列表" ItemsSource"{Binding Functions}"><TreeViewItem.ItemTemplate><HierarchicalDataTempla…...
解决并发问题)
使用Go语言的互斥锁(Mutex)解决并发问题
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在并发编程中,由于存在竞争条件和数据竞争,我们需要将某些代码片段设定为临界区,并使用互斥锁(Mutex)等同步原语来保护这些临界区。本文将详细介绍Go语言标准库中Mutex的使用方法,以及如何利用它来解决实际…...

AI Agent Harness恶意指令识别拦截
AI Agent Harness恶意指令识别拦截:构建新一代智能应用安全屏障摘要/引言 开门见山(Hook) 想象一下这个场景:你花了3个月精心搭建了一个**“全栈AI编程助手Agent集群”**——主Agent负责理解需求并拆解任务,代码生成Ag…...

简历投了全石沉大海?实测3个免费AI简历神器,HR秒通过、面试翻3倍!
3个实测免费的AI简历神器,不用花钱、不用登录,直接让简历过ATS、获面试,应届生/职场人闭眼冲!简历优化本身就讲究精准度,尤其是ATS筛选逻辑,很多工具要么收费高,要么改完还是不贴合JD࿰…...

对比直接使用官方API体验Taotoken在用量可视化方面的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在用量可视化方面的优势 效果展示类,分享开发者在同时使用官方渠道与Taotoken聚合服务…...

MXFP混合精度注意力机制优化LLM推理性能
1. 低比特MXFP混合精度注意力机制解析在大型语言模型(LLM)推理过程中,自注意力机制的计算开销一直是主要瓶颈。传统FP16/BF16精度计算虽然能保证模型质量,但存在显著的内存带宽浪费和计算资源利用率不足问题。MXFP(Microscaling Floating-Poi…...

基础知识丨JAVA序列化与反序列化漏洞
今天在学习的时候又接触到了JAVA反序列化漏洞。一直只知道JAVA反序列化就是利用反序列化工具进行攻击,在目标系统中执行命令,利用的就是传输对象时采用JAVA序列化。但是也只知道这么多了。所以,就想着今天再了解一下反序列化漏洞。顺便&#…...
)
python系列【仅供参考】;避开这些坑,你的Python爬虫才能稳定爬取IEEE Xplore(含反爬策略与MongoDB存储实战)
避开这些坑,你的Python爬虫才能稳定爬取IEEE Xplore(含反爬策略与MongoDB存储实战) 避开这些坑,你的Python爬虫才能稳定爬取IEEE Xplore(含反爬策略与MongoDB存储实战)---------------------避开这些坑,你的Python爬虫才能稳定爬取IEEE Xplore(含反爬策略与MongoDB存储…...
)
今日算法(依旧二叉树)
class Solution { public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {//递归进行,加回溯过程if(rootq||rootp||rootNULL) return root;TreeNode*leftlowestCommonAncestor(root->left,p,q);TreeNode*rightlowestCommonAncestor…...


告别繁琐组态:用SVG + JavaScript 5分钟为你的工业设备创建可交互HMI组件
工业设备HMI组件开发革命:5分钟用SVGJavaScript打造智能交互界面 在工业自动化领域,人机界面(HMI)是连接设备与操作者的关键纽带。传统HMI开发往往陷入两个极端:要么使用笨重的组态软件进行繁琐配置,要么投入大量时间开发定制化界…...
)
告别纯视觉追踪:手把手教你用Refer-KITTI数据集复现RMOT实验(含环境配置避坑指南)
告别纯视觉追踪:手把手教你用Refer-KITTI数据集复现RMOT实验(含环境配置避坑指南) 在计算机视觉领域,多目标跟踪(Multi-Object Tracking, MOT)一直是研究热点,而近年来结合语言特征的Referring Multi-Object Tracking(…...