【深度学习】2023李宏毅homework1作业一代码详解
研一刚入门深度学习的小白一枚,想记录自己学习代码的经过,理解每行代码的意思,这样整理方便日后复习也方便理清自己的思路。感觉每天时间都不够用了!!加油啦。
第一部分:导入模块
导入各个模块,代码如下:
# Numerical Operations
import math
import numpy as np# Reading/Writing Data
import pandas as pd
import os
import csv# For Progress Bar
from tqdm import tqdm# Pytorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split# For plotting learning curve
from torch.utils.tensorboard import SummaryWriter
在上面程序中,依次导入了
第二部分:切分数据集及预测
随机数,作用是切分训练集和验证集,代码如下:
def same_seed(seed): '''Fixes random number generator seeds for reproducibility.'''torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsenp.random.seed(seed)torch.manual_seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)
在上面程序中,先调用xxx函数,
接着根据随机数拆分数据集,代码如下:
ef train_valid_split(data_set, valid_ratio, seed):'''Split provided training data into training set and validation set'''valid_set_size = int(valid_ratio * len(data_set)) train_set_size = len(data_set) - valid_set_sizetrain_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))return np.array(train_set), np.array(valid_set)
在上面程序中,先调用xxx
接着做预测,下面这段预测程序也作为工具函数,
def predict(test_loader, model, device):model.eval() # Set your model to evaluation mode.preds = []for x in tqdm(test_loader):x = x.to(device) with torch.no_grad(): pred = model(x) preds.append(pred.detach().cpu()) preds = torch.cat(preds, dim=0).numpy() return preds
在上面程序中,先将模型调成evaluation模式,再设定一个预测结果preds列表,将x
第三部分:数据集
这一部分是数据集,代码如下:
class COVID19Dataset(Dataset):'''x: Features.y: Targets, if none, do prediction.'''def __init__(self, x, y=None):if y is None:self.y = yelse:self.y = torch.FloatTensor(y)self.x = torch.FloatTensor(x)def __getitem__(self, idx):if self.y is None:return self.x[idx]else:return self.x[idx], self.y[idx]def __len__(self):return len(self.x)
上面这段代码,
第四部分:模型
定义自己的模型,代码如下:
class My_Model(nn.Module):def __init__(self, input_dim):super(My_Model, self).__init__()# TODO: modify model's structure, be aware of dimensions. self.layers = nn.Sequential(nn.Linear(input_dim, 16),nn.ReLU(),nn.Linear(16, 8),nn.ReLU(),nn.Linear(8, 1))def forward(self, x):x = self.layers(x)x = x.squeeze(1) # (B, 1) -> (B)return x
上面这段代码定义了一个继承自nn.Module模块的My_Model类,先在__init__方法中定义层数layers属性,调用nn.Sequential方法列出了5个层,分别是线性层和ReLU层,注意维度分别是input_dim和16,16和8,8和1。接着在forward方法中 得到定义的模型x, 外界可以调用 。
第五部分:特征选择
def select_feat(train_data, valid_data, test_data, select_all=True):'''Selects useful features to perform regression'''y_train, y_valid = train_data[:,-1], valid_data[:,-1] # 只需要参考并预测最后一列即可raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data # update 1: 去掉第一列 update 2:在特征选择去掉第一列if select_all:feat_idx = list(range(raw_x_train.shape[1]))else:# update 1: 去掉belief和mental"""#feat_idx = [i for i in raw_x_train.shape[1] if i not in ["wbelief_masking_effective", "wbelief_distancing_effective", "wbelief_masking_effective", "worried_finances"]] # update: 不能读取列名,否则array维度不匹配#feat_idx = [i for i in raw_x_train.shape[1] if i not in [0, 39, 40, 47, 52, 57, 58, 65, 70, 75, 76, 83, 88]] # update: 遍历所有列名,排除不需要的#feat_idx = [i for i in raw_x_train.shape[1] if i != 0 | i != 39 | i != 40 | i != 47 | i != 52 | i != 57 | i != 58 | i != 65 | i != 70 | i != 75 | i != 76 | i != 83 | i != 88] #update: 整数不可迭代del_col = [0, 38, 39, 46, 51, 56, 57, 64, 69, 74, 75, 82, 87]raw_x_train = np.delete(raw_x_train, del_col, axis=1) # update: numpy数组增删查改方法raw_x_valid = np.delete(raw_x_valid, del_col, axis=1)raw_x_test = np.delete(raw_x_test, del_col, axis=1)"""#update 2:使用前三天的covid like illness和前二天的tested positive casesget_col = [35, 36, 37, 47, 48, 35+18, 36+18, 37+18, 47+18, 48+18, 35+18*2, 36+18*2, 37+18*2, 47+18*2, 48+18*2, 52, 52+18]raw_x_train = raw_x_train[:, get_col] # update: numpy数组取某几行某几列raw_x_valid = raw_x_valid[:, get_col]raw_x_test = raw_x_test[:, get_col]return raw_x_train, raw_x_valid, raw_x_test, y_train, y_valid#feat_idx = [1,1,2,3,4] # TODO: Select suitable feature columns.return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid
上面这段代码包含我自己修改的部分,跟着其他大佬的调参步骤更改,加了适当的注释,写在update后面。由列选择得到相应的列…
第六部分:训练
代码如下:
def trainer(train_loader, valid_loader, model, config, device):criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.# Define your optimization algorithm. # TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9) # update: momentum调整为0.9; #optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate']) # update: 用Adam优化器; writer = SummaryWriter() # Writer of tensoboard.if not os.path.isdir('./models'):os.mkdir('./models') # Create directory of saving models.n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0for epoch in range(n_epochs):model.train() # Set your model to train mode.loss_record = []# tqdm is a package to visualize your training progress.train_pbar = tqdm(train_loader, position=0, leave=True)for x, y in train_pbar:optimizer.zero_grad() # Set gradient to zero.x, y = x.to(device), y.to(device) # Move your data to device. pred = model(x) loss = criterion(pred, y)loss.backward() # Compute gradient(backpropagation).optimizer.step() # Update parameters.step += 1loss_record.append(loss.detach().item())# Display current epoch number and loss on tqdm progress bar.train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')train_pbar.set_postfix({'loss': loss.detach().item()})mean_train_loss = sum(loss_record)/len(loss_record)writer.add_scalar('Loss/train', mean_train_loss, step)model.eval() # Set your model to evaluation mode.loss_record = []for x, y in valid_loader:x, y = x.to(device), y.to(device)with torch.no_grad():pred = model(x)loss = criterion(pred, y)loss_record.append(loss.item())mean_valid_loss = sum(loss_record)/len(loss_record)print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')# writer.add_scalar('Loss/valid', mean_valid_loss, step)if mean_valid_loss < best_loss:best_loss = mean_valid_losstorch.save(model.state_dict(), config['save_path']) # Save your best modelprint('Saving model with loss {:.3f}...'.format(best_loss))early_stop_count = 0else: early_stop_count += 1if early_stop_count >= config['early_stop']:print('\nModel is not improving, so we halt the training session.')return
上面这段代码…
第七部分:参数
代码如下:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {'seed': 5201314, # Your seed number, you can pick your lucky number. :)'select_all': False, # Whether to use all features. update: select_all为False'valid_ratio': 0.2, # validation_size = train_size * valid_ratio'n_epochs': 5000, # Number of epochs. 'batch_size': 256, 'learning_rate': 1e-4, # update: 学习率加大为1e-4'early_stop': 600, # If model has not improved for this many consecutive epochs, stop training. 'save_path': './models/model.ckpt' # Your model will be saved here.
}
上面这部分代码定义了1个设备和8个参数,device是用if-else定义的bool值变量,config用字典表示。
第八部分:开始调用以上定义的方法、对象和参数
数据集处理,代码如下:
same_seed(config['seed'])
train_data, test_data = pd.read_csv('./covid_train.csv').values, pd.read_csv('./covid_test.csv').values # update: .values选中除第一行列名下面的所有行; .values输出的shape一样 (?)
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
上面这段代码中,前三行是读入训练和测试的两个.csv文件,得到总的训练集train_data和测试集test_data;再接着对训练集train_data进行切分,得到切分后的训练集train_data和验证集valid_data。
接着进行特征选择,代码如下:
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
上面这段代码,
接着加载数据,代码如下:
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \COVID19Dataset(x_valid, y_valid), \COVID19Dataset(x_test)# Pytorch data loader loads pytorch dataset into batches.
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
上面这段代码,train和valid的dataset进行了shuffle,而test的dataset不需要shuffle。
接着进行训练,代码如下:
model = My_Model(input_dim=x_train.shape[1]).to(device) # put your model and data on the same computation device.
trainer(train_loader, valid_loader, model, config, device)
上面这段代码,
接着进行预测,并保存预测结果,代码如下:
def save_pred(preds, file):''' Save predictions to specified file '''with open(file, 'w') as fp:writer = csv.writer(fp)writer.writerow(['id', 'tested_positive'])for i, p in enumerate(preds):writer.writerow([i, p])model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path'])) # update: tensor size mismatch,所以暂时先注释掉
preds = predict(test_loader, model, device)
save_pred(preds, 'pred.csv')
上面这段代码先定义了一个save_pred方法,调用open创建一个.csv文件…
相关文章:

【深度学习】2023李宏毅homework1作业一代码详解
研一刚入门深度学习的小白一枚,想记录自己学习代码的经过,理解每行代码的意思,这样整理方便日后复习也方便理清自己的思路。感觉每天时间都不够用了!!加油啦。 第一部分:导入模块 导入各个模块࿰…...
【软件测试】基础知识第二篇
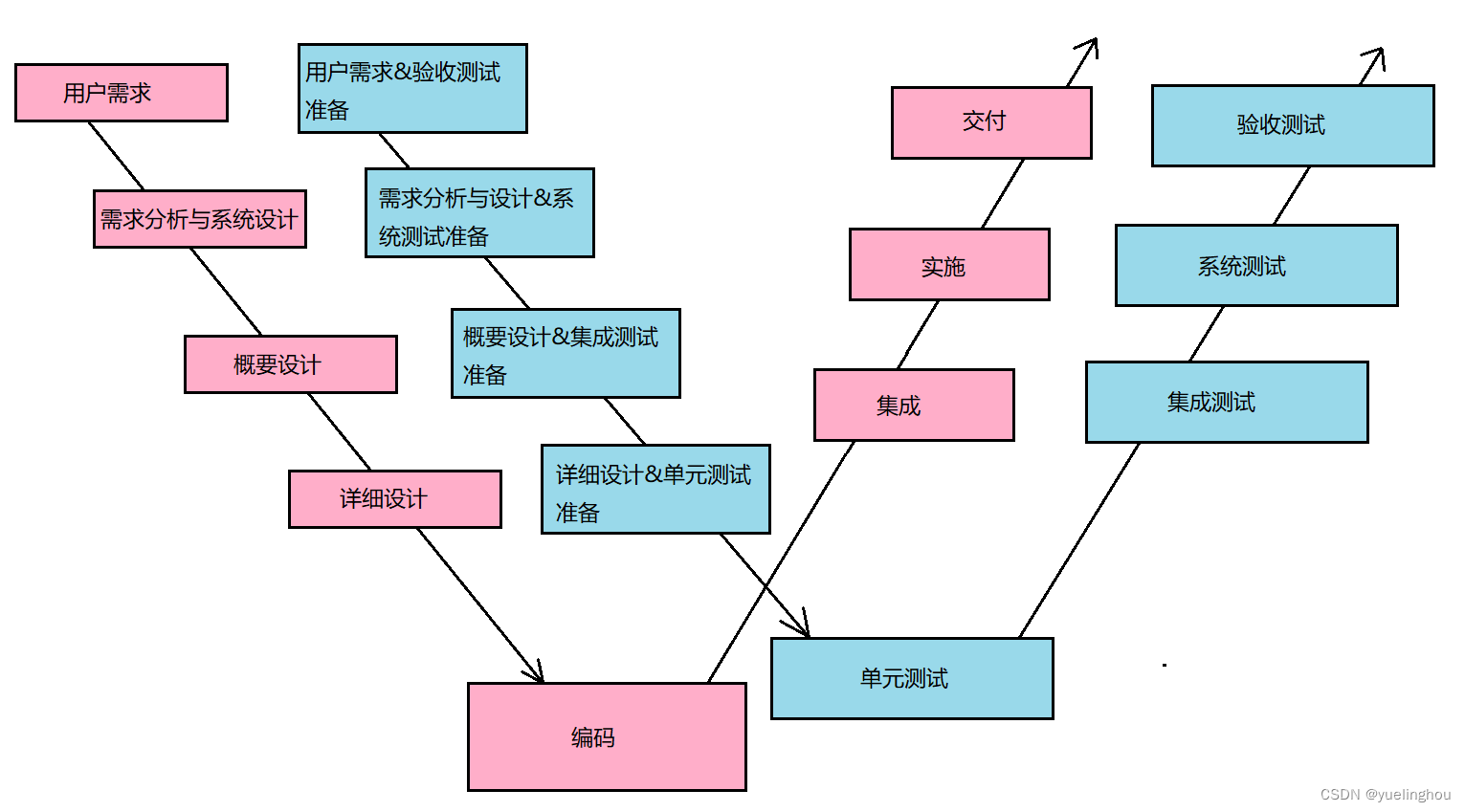
文章目录一. 开发模型1. 瀑布模型2. 螺旋模型3. 增量和迭代模型3.1 增量模型3.2 迭代模型3.3 增量和迭代模型的区别4. 敏捷模型4.1 敏捷宣言4.2 scrum模型二. 开发模型V 模型W 模型一. 开发模型 1. 瀑布模型 瀑布模型在软件工程中占有重要地位,是所有其他模型的基…...

Java中File类以及初步认识流
1、File类操作文件或目录属性 (1)在Java程序中通过使用java.io包提供的一些接口和类,对计算机中的文件进行基本的操作,包括对文件和目录属性的操作、对文件读写的操作; (2)File对象既可以表示…...
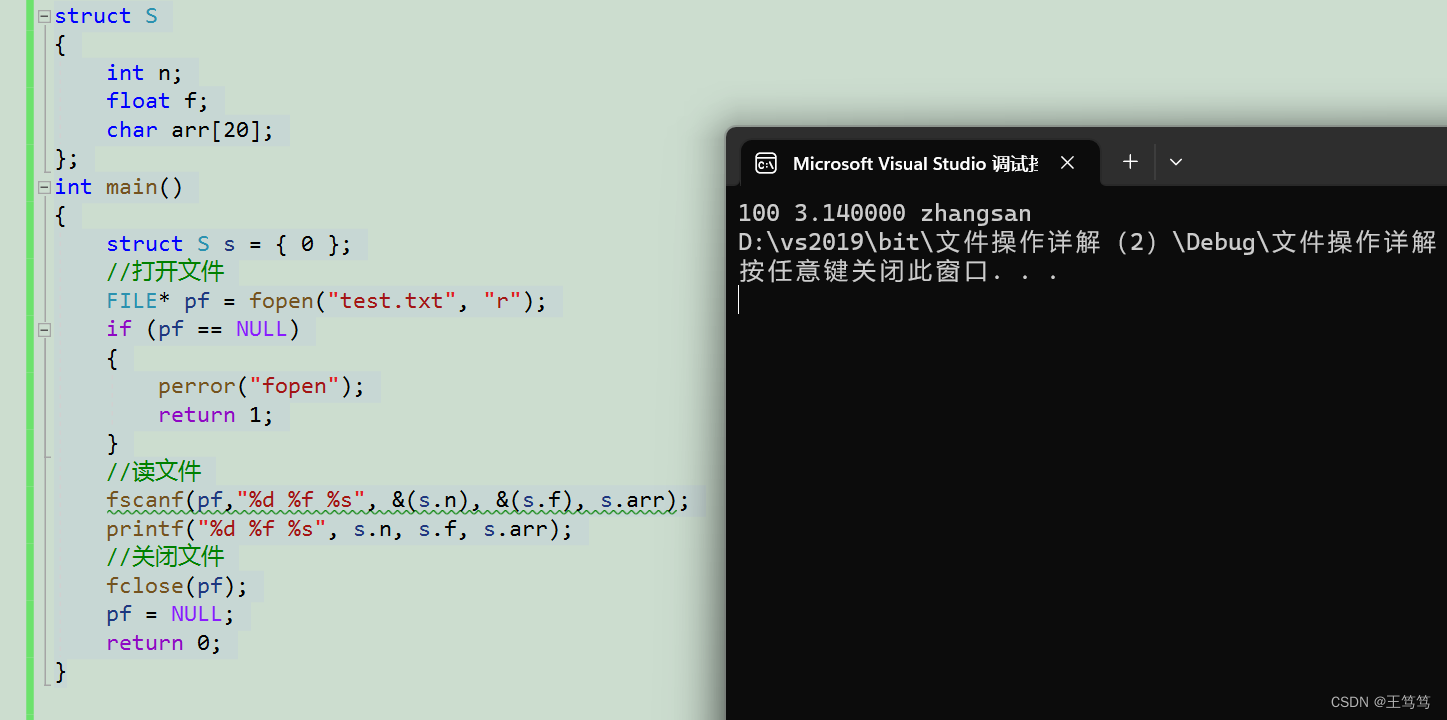
【C语言】文件操作详细讲解
本章要分享的内容是C语言中文件操作的内容,为了方便大家学习,目录如下 目录 1.为什么要使用文件 2.什么是文件 2.1 程序文件 2.2 数据文件 2.3 文件名 3.文件的打开和关闭 3.1文件指针 3.2打开和关闭 4.文件的顺序读写 4.1顺序读写函数介绍…...

爱奇艺万能联播使用教程
众所周知,爱奇艺是百度旗下的一款产品,所以今天用爱奇艺万能联播的方法实现下载百度网盘,并没有破解百度网盘,是官方正版下载渠道。软件是官方版本,大家双击安装即可。 安装完成以后,在软件中就有了“访问网…...
真题讲解-软件设计(三十七)
数据流图DFD(真题讲解)-软件设计(三十六)https://blog.csdn.net/ke1ying/article/details/129803164 在网络安全管理中,加强内防内控可采取的策略是? 终端访问权限,防止合法终端越权访问。加强…...

Android 上的协程(第一部分):了解背景
本系列文章 Android 上的协程(第一部分):了解背景 Android 上的协程(第二部分):入门 Android上的协程 (第三部分): 实际应用 Android 上的协程(第一部分):了解背景 这篇…...

【H3C】VRRP2 及Vrrp3基本原理 华为同用
文章目录VRRP2基本概念报文格式主备选举规则(优先级)0和255双Master原因VRRP认证VRRP状态机抢占模式VRRP主备切换状态项目场景VRRP3H3C参考致谢VRRP2 基本概念 VRRP路由器(VRRP Router):运行VRRP的设备,它…...
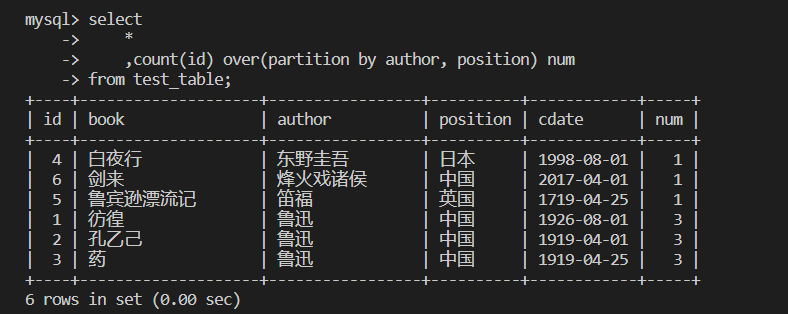
【数据库】SQL语法
目录 1. 常用数据类型 2. 约束 3. 数据库操作 4. 数据表操作 查看表 创建表格 添加数据 删除数据 修改数据 单表查询数据 多表查询数据 模糊查询 关联查询 连接查询 数据查询的执行顺序 4. 内置函数 1. 常用数据类型 整型:int浮点型:flo…...
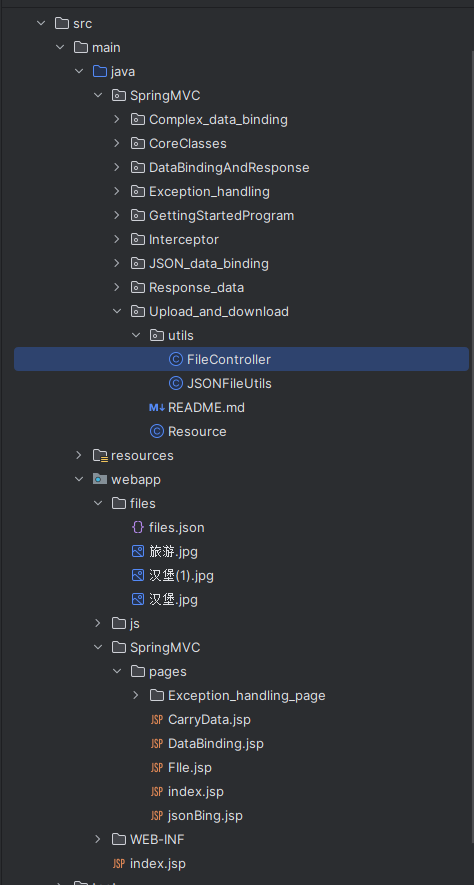
JavaEE简单示例——文件的上传和下载
文件的上传和下载的实现原理的简单介绍 表单的构成 首先,我们先来介绍我们的需要用到的表单,在这个表单中,首先值得我们注意的就是,在type为file的input标签中.这个控件是我们主要用来选择上传的文件的, 除此之外,我们要想实现文件的上传,还需要将method的属性的值设置为post…...
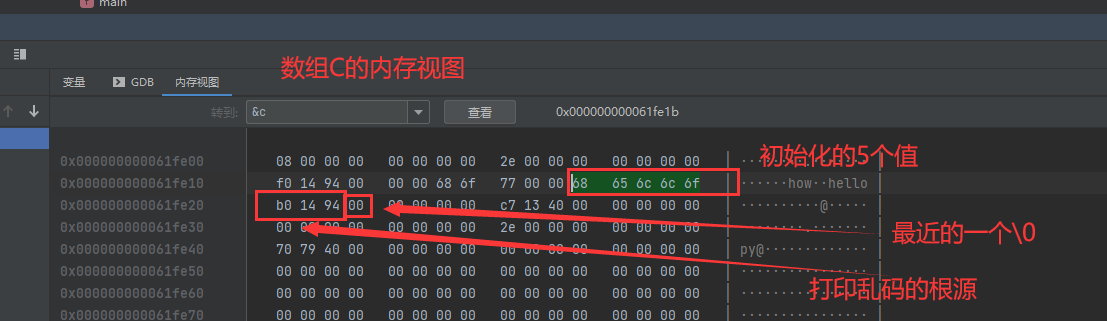
【C语言督学训练营 第五天】数组字符串相关知识
文章目录前言一、数组的定义1.一维数组①.如何定义②.声明规则③.内存分布④.初始化方法2.二维数组3.高维数组二、访问数组元素相关问题1.访问越界2.数组的传递三、Scanf与字符数组1.字符数组初始化2.scanf读取字符四、字符数组相关函数前言 今天的C语言训练营没有安排高维数组…...
GPT-4 免费体验方法
POE 在Quora上非常受欢迎的手机聊天机器人Poe App已经集成ChatGPT助手!除了最初集成的三个聊天机器人Sage、Claude和Dragonfly外,Poe现在还加入了第四位ChatGPT。由于使用了ChatGPT API,因此Poe拥有真正的ChatGPT。 现在更是第一批集成了GP…...

中断-屏蔽位
1.中断控制器(PIC:适用于单处理器、APIC) 1.定义 中断控制器可以看作是中断服务的代理,外设五花八门,如果没有一个中断的代理,外设想要给cpu发送中断信号来处理中断。那么只能是外设连接在cpu引脚上,由于cpu引脚很宝贵,所以不可能拿出那么多引脚来供外设连接,所以就有…...

【洛谷P1636】 Einstein学画画
题目描述:Einstein 学起了画画。此人比较懒~~,他希望用最少的笔画画出一张画……给定一个无向图,包含 n 个顶点(编号 1∼n),m 条边,求最少用多少笔可以画出图中所有的边。输入格式第一行两个整数…...

户外LED显示屏钢结构制作原则
户外LED显示屏在施工安装时是必须要制作固定钢结构的,因为户外LED显示屏工作环境相对比较恶劣,制作钢结构一是为了安全,二是为了提高防护等级。那么户外LED显示屏钢结构制作原则是什么呢?迈普光彩小编总结了一些分享个大家。 户外…...

【内网穿透】使用Haproxy反向代理搭建企业私有云:神卓互联教程
神卓互联是一款强大的内网穿透工具,可以帮助企业搭建私有云,实现对内部资源的远程访问。在搭建私有云的过程中,使用HAProxy反向代理可以提高系统的性能和可靠性。本文将介绍如何使用神卓互联和HAProxy反向代理搭建私有云。 步骤如下…...

spring boot项目:实现与数据库的连接
步骤【写在前面】定义数据库连接信息:引入数据库驱动:创建数据源:创建JdbcTemplate:编写DAO层:使用Service注解标注Service层:使用RestController注解标注Controller层:示例代码:app…...
【gitlab部署】centos8安装gitlab(搭建属于自己的代码服务器)
这里写目录标题部署篇序言要求检查系统是否安装OpenSSH防火墙问题准备gitlab.rb 配置坑点一忘记root密码重置使用篇gitlab转换成中文git关闭注册入口创建用户部署篇 序言 在团队开发过程中,想要拥有高效的开发效率,选择一个好的代码开发工具是必不可少的…...
网络安全竞赛第三套试题A模块解析(超级详细))
2021年全国职业院校技能大赛(中职组)网络安全竞赛第三套试题A模块解析(超级详细)
2021年全国职业院校技能大赛(中职组) 网络安全竞赛试题 (3) (总分100分) 赛题说明 一、竞赛项目简介 “网络安全”竞赛共分A. 基础设施设置与安全加固;B. 网络安全事件响应、数字取证调查和应用安全;C. CTF夺旗-攻击;D. CTF夺旗-防御等四个模块。根据比赛实际情况…...

Hbase异步复制和同步复制解析
背景 Hbase是一个KV数据库,自然和Mysql以及Redis等会涉及到复制的问题,也有主从集群的概念,那么本文就来看下Hbase的复制逻辑 Hbase复制实现 首先我们先在回顾下,在Hbase实现中,每个RegionServer上面会包含多个Regi…...

如何用MPC-HC打造专业级音频体验:终极音频重采样配置指南
如何用MPC-HC打造专业级音频体验:终极音频重采样配置指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc 你是否曾经在观看电影或听音乐时&am…...

AI 术语通俗词典:卷积
卷积是数学、信号处理、图像处理、深度学习、卷积神经网络和人工智能中非常重要的一个术语。它用来描述一种用一个小窗口在数据上滑动,并对局部区域进行加权汇总的运算。换句话说,卷积是在回答:如何从图像、语音或序列数据中提取局部模式。如…...

基于GIS流域水文分析及水库库容计算实践技术
1、GIS水文分析的原理、DEM数据的获取与处理2、基于水文分析的流域边界、河道及分子流域提取3、暴雨情景下流域淹没区快速识别4、基于GIS的水库库容计算...

3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南
3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录手忙脚乱吗?是否曾因错过重要信息而懊恼?今天我要向…...

命令行媒体管理工具amem:本地化素材归档与自动化实践
1. 项目概述:一个被低估的本地化媒体管理工具最近在整理个人数字资产时,我遇到了一个老生常谈但又无比棘手的问题:如何高效、优雅地管理那些散落在硬盘各个角落的短视频、图片和音频文件?无论是手机拍摄的生活片段,还是…...

Space Thumbnails:Windows资源管理器的终极3D模型预览解决方案
Space Thumbnails:Windows资源管理器的终极3D模型预览解决方案 【免费下载链接】space-thumbnails Generates preview thumbnails for 3D model files. Provide a Windows Explorer extensions that adds preview thumbnails for 3D model files. 项目地址: https…...

【困难】不用任何比较判断找出两个数中较大的数-Java:解法一
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

PowerShdll源码深度分析:从DLL导出到控制台劫持的完整实现原理
PowerShdll源码深度分析:从DLL导出到控制台劫持的完整实现原理 【免费下载链接】PowerShdll Run PowerShell with rundll32. Bypass software restrictions. 项目地址: https://gitcode.com/gh_mirrors/po/PowerShdll PowerShdll是一个创新的PowerShell绕过工…...

SoC芯片设计全流程解析:从架构定义到流片制造
1. 项目概述:从“黑盒子”到“城市蓝图”当我们谈论智能手机、智能手表、路由器乃至汽车里的智能座舱时,我们谈论的核心,往往是一个被称为“片上系统”或SoC的硅片。对于很多刚入行的朋友,甚至是一些有经验的软件工程师来说&#…...
)
200块搞定AI视觉项目:手把手教你用Canmv K210训练识别模型(附完整代码)
200元打造AI视觉神器:Canmv K210从模型训练到落地实战指南 在AI技术快速普及的今天,动辄数千元的开发套件让许多创客和学生望而却步。Canmv K210开发板的出现彻底改变了这一局面——仅需200元预算,就能搭建完整的AI视觉识别系统。本文将带你从…...