LlamaIndex 的Node节点后处理器模块介绍
Node 后处理器模块
LlamaIndex 是一个旨在连接大型语言模型(LLMs)与外部数据的框架,允许开发者构建能够处理和回应复杂查询的应用程序。在这个框架内,NodePostProcessor 扮演着优化数据处理流程的重要角色。为了更好地理解 NodePostProcessor 在 LlamaIndex 中的作用及其具体实现方式,我们需要从其定义入手,并探讨其功能。
NodePostProcessor定义
在 LlamaIndex 的上下文中,NodePostProcessor 是一个在数据节点(Node)被处理之后进行额外操作的组件。这些操作可以包括但不限于数据的清洗、增强、过滤或转换等,目的是确保最终提供给LLM的数据是最优的,从而提高模型响应的质量。NodePostProcessor 是通过继承自 BaseNodePostprocessor 接口实现的,该接口定义了 _postprocess_nodes 方法,此方法接受一系列节点并返回经过处理后的节点列表。
NodePostProcessor功能详细介绍
数据清洗与隐私保护
NodePostProcessor 可用于对节点数据进行清洗,如移除无关的信息或者进行数据格式标准化。此外,它还能用于隐私信息的掩蔽(masking)。例如,NERPIINodePostprocessor 就是用来识别并掩蔽个人身份信息(PII)的 NodePostProcessor。通过使用命名实体识别(NER)模型,它可以检测并替换掉节点中的 PII 。
数据增强
另一个重要的功能是数据增强,这可以通过添加前后文相关的其他节点来实现,以此来丰富LLM的上下文理解。例如,PrevNextNodePostprocessor 可以用来向前或向后扩展节点,以便为模型提供更多的上下文信息,这对于提高问答系统的准确性和连贯性尤其有用 。
结果重排(Reranking)
在一些场景下,NodePostProcessor 也可以用来对检索到的结果进行重排。通过重新评估和排序检索出的文档片段,可以确保最相关的信息优先呈现给用户。这种重排可以通过自定义 Rerank 功能的 NodePostProcessor 来实现,例如在 RAG(Retrieval-Augmented Generation)系统中 。
动态捕捉视频后处理
虽然这不是 LlamaIndex 的直接应用场景,但从更广泛的视角来看,NodePostProcessor 的概念也被应用到了诸如动态捕捉视频数据的后处理中。在这种情况下,它被用来处理节点数据以创建运动捕捉视频 。尽管这超出了 LlamaIndex 的原始设计范围,但它展示了 NodePostProcessor 概念的灵活性和可扩展性。
总结来说,NodePostProcessor 在 LlamaIndex 中是一个极其灵活的工具,它不仅限于上述功能,还可以根据具体的应用需求进行定制开发。无论是为了改善数据质量、增加上下文信息、保护隐私还是优化检索结果,NodePostProcessor 都能够发挥关键作用,使得 LlamaIndex 成为一个强大的工具箱,帮助开发者构建更加智能和高效的应用程序。
相似性节点后处理器SimilarityPostprocessor
用于删除低于相似性分数阈值的节点。
from llama_index.core.postprocessor import SimilarityPostprocessorpostprocessor = SimilarityPostprocessor(similarity_cutoff=0.7)postprocessor.postprocess_nodes(nodes)
关键字节点后处理器 KeywordNodePostprocessor
用于确保排除或包含某些关键字。
from llama_index.core.postprocessor import KeywordNodePostprocessorpostprocessor = KeywordNodePostprocessor(required_keywords=["word1", "word2"], exclude_keywords=["word3", "word4"]
)postprocessor.postprocess_nodes(nodes)
元数据替换后处理器 MetadataReplacementPostProcessor
用于将节点内容替换为节点元数据中的字段。如果元数据中不存在该字段,则节点文本将保持不变。与
.SentenceWindowNodeParserfrom llama_index.core.postprocessor import MetadataReplacementPostProcessorpostprocessor = MetadataReplacementPostProcessor(target_metadata_key="window",
)postprocessor.postprocess_nodes(nodes)
LongContextReorder 长上下文重排序处理器
模型难以访问在扩展上下文中心找到的重要细节。一项研究观察到,当关键数据位于输入上下文的开头或结尾时,通常会出现最佳性能。此外,随着输入上下文的延长,性能会显著下降,即使在为长上下文设计的模型中也是如此。
此模块将对检索到的节点重新排序,这在需要大量 top-k 的情况下会很有帮助。
from llama_index.core.postprocessor import LongContextReorderpostprocessor = LongContextReorder()postprocessor.postprocess_nodes(nodes)
句子嵌入优化器 SentenceEmbeddingOptimizer
此后处理器通过删除与查询无关的句子来优化令牌使用(这是使用 embeddings 完成的)。
百分位截止值是使用相关句子的最高百分比的度量。
可以改为指定阈值截止值,它使用原始相似度截止值来选择要保留的句子。
from llama_index.core.postprocessor import SentenceEmbeddingOptimizerpostprocessor = SentenceEmbeddingOptimizer(embed_model=service_context.embed_model,percentile_cutoff=0.5,# threshold_cutoff=0.7
)postprocessor.postprocess_nodes(nodes)
Cohere重排处理器 CohereRerank
使用“Cohere ReRank”功能对节点重新排序,并返回前N个节点。
from llama_index.postprocessor.cohere_rerank import CohereRerankpostprocessor = CohereRerank(top_n=2, model="rerank-english-v2.0", api_key="YOUR COHERE API KEY"
)postprocessor.postprocess_nodes(nodes)
句子转换推理重排 SentenceTransformerRerank
使用包中的交叉编码器对节点重新排序,并返回前N个节点
from llama_index.core.postprocessor import SentenceTransformerRerank# We choose a model with relatively high speed and decent accuracy.
postprocessor = SentenceTransformerRerank(model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=3
)postprocessor.postprocess_nodes(nodes)
另请参阅 sentence-transformer 文档以获取更完整的模型列表(并且还显示了速度/准确性的权衡)。默认模型是 cross-encoder/ms-marco-TinyBERT-L-2-v2,它提供的速度最块的。
LLM 重新排名 LLMRerank
使用 LLM 对节点重新排序,方法是要求 LLM 返回相关文档及其相关性的分数。返回排名前 N 的节点。
from llama_index.core.postprocessor import LLMRerankpostprocessor = LLMRerank(top_n=2, service_context=service_context)postprocessor.postprocess_nodes(nodes)
Jina重排器 JinaRerank
使用 Jina ReRank 功能对节点进行重新排序,并返回前 N 个节点。
from llama_index.postprocessor.jinaai_rerank import JinaRerankpostprocessor = JinaRerank(top_n=2, model="jina-reranker-v1-base-en", api_key="YOUR JINA API KEY"
)postprocessor.postprocess_nodes(nodes)
FixedRecencyPostprocessor (固定新近度后处理器)
此 postproccesor 返回按日期排序的前 K 个节点。这假定每个节点的元数据中都有一个要解析的字段。date
from llama_index.core.postprocessor import FixedRecencyPostprocessorpostprocessor = FixedRecencyPostprocessor(tok_k=1, date_key="date" # the key in the metadata to find the date
)postprocessor.postprocess_nodes(nodes)
EmbeddingRecencyPostprocessor (嵌入近期后处理器)
这个后处理器在按日期排序后返回前K个节点,并在测量嵌入相似度后删除过于相似的旧节点。
from llama_index.core.postprocessor import EmbeddingRecencyPostprocessorpostprocessor = EmbeddingRecencyPostprocessor(service_context=service_context, date_key="date", similarity_cutoff=0.7
)postprocessor.postprocess_nodes(nodes)
TimeWeightedPostprocessor (时间加权后处理器)
该后处理器对每个节点应用时间加权重排序,返回前K个节点。每次检索节点时,都会记录检索节点的时间。这会使搜索偏向于那些尚未在查询中返回的信息。
from llama_index.core.postprocessor import TimeWeightedPostprocessorpostprocessor = TimeWeightedPostprocessor(time_decay=0.99, top_k=1)postprocessor.postprocess_nodes(nodes)
(Beta) PIINodePostprocessor (个人敏感信息处理器)
PII(个人可识别信息)后处理器可删除可能存在安全风险的信息。它通过使用NER(或者使用专用的NER模型,或者使用本地的LLM模型)来实现这一点。
LLM Version
from llama_index.core.postprocessor import PIINodePostprocessorpostprocessor = PIINodePostprocessor(service_context=service_context # this should be setup with an LLM you trust
)postprocessor.postprocess_nodes(nodes)
NER Version
这个版本使用的是当你运行.pipeline(“ner”)时加载的hug Face的默认本地模型。
from llama_index.core.postprocessor import NERPIINodePostprocessorpostprocessor = NERPIINodePostprocessor()postprocessor.postprocess_nodes(nodes)
A full notebook guide for both can be found here.
(Beta) PrevNextNodePostprocessor (上一页下一页节点处理器)
使用预定义的设置读取关系并获取前面、后面或两者的所有节点。节点
当您知道这些关系指向重要数据(在检索节点之前、之后或两者都指向重要数据)时,这些数据应该发送给LLM,这将非常有用。
from llama_index.core.postprocessor import PrevNextNodePostprocessorpostprocessor = PrevNextNodePostprocessor(docstore=index.docstore,num_nodes=1, # number of nodes to fetch when looking forawrds or backwardsmode="next", # can be either 'next', 'previous', or 'both'
)postprocessor.postprocess_nodes(nodes)
(Beta)AutoPrevNextNodePostprocessor 自动上一页下一页节点处理器)
与 PrevNextNodePostprocessor 相同,但让 LLM 决定模式(下一个、上一个或两者)。
from llama_index.core.postprocessor import AutoPrevNextNodePostprocessorpostprocessor = AutoPrevNextNodePostprocessor(docstore=index.docstore,service_context=service_context,num_nodes=1, # number of nodes to fetch when looking forawrds or backwards)
)
postprocessor.postprocess_nodes(nodes)
#(测试版)RankGPT( GPT排名处理器)
使用 RankGPT 代理根据相关性对文档进行重新排序。返回排名前 N 的节点。
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerankpostprocessor = RankGPTRerank(top_n=3, llm=OpenAI(model="gpt-3.5-turbo-16k"))postprocessor.postprocess_nodes(nodes)
ColbertRerank (Colbert重排处理器)
使用 Colbert V2 模型作为 reranker,根据 query token 和 passage token 之间的细粒度相似性对文档进行重新排序。返回排名前 N 的节点。
from llama_index.postprocessor.colbert_rerank import ColbertRerankcolbert_reranker = ColbertRerank(top_n=5,model="colbert-ir/colbertv2.0",tokenizer="colbert-ir/colbertv2.0",keep_retrieval_score=True,
)query_engine = index.as_query_engine(similarity_top_k=10,node_postprocessors=[colbert_reranker],
)
response = query_engine.query(query_str,
)
完整的笔记本指南可在此处获取。
rankLLM (LLM排名处理器)
使用rankLLM中的模型对文档进行重新排序。返回排名前 N 的节点。
from llama_index.postprocessor.rankllm_rerank import RankLLMRerank# RankZephyr reranker, return top 5 candidates
reranker = RankLLMRerank(model="rank_zephyr", top_n=5)
reranker.postprocess_nodes(nodes)
以上所有处理器用例参考 https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank/
相关文章:

LlamaIndex 的Node节点后处理器模块介绍
Node 后处理器模块 LlamaIndex 是一个旨在连接大型语言模型(LLMs)与外部数据的框架,允许开发者构建能够处理和回应复杂查询的应用程序。在这个框架内,NodePostProcessor 扮演着优化数据处理流程的重要角色。为了更好地理解 NodeP…...

Dubbo 如何使用 Zookeeper 作为注册中心:原理、优势与实现详解
Dubbo 是一个高性能的 Java 分布式服务框架,而 Zookeeper 常被用作 Dubbo 的服务注册中心。Zookeeper 提供了分布式一致性和协调服务,Dubbo 通过 Zookeeper 实现服务注册与发现功能,确保在分布式环境下服务实例的动态管理和可靠发现。 下面是…...

Linux:进程间通信之命名管道
Linux:进程间通信-CSDN博客 我们说匿名管道只能用于父子进程这样的关系通信,那么陌生进程怎么通信? 我们之前说父子进程能通信的最关键的地方就在于子进程复制了一份父进程的files_struct,从而通过文件的inode映射同一份文件来通…...

UE4_后期处理七—仿红外线成像效果
效果图展示: 参考文档:https://dev.epicgames.com/documentation/zh-cn/unreal-engine/using-fresnel-in-your-unreal-engine-materials?application_version5.4 二、所用知识点扩充 在创建电影或过场动画时,你常常需要想办法更好地突显角…...

静态路由和默认路由(实验)
目录 一、实验设备和环境 1、实验设备 2、实验环境 (1)实验拓扑图 (2)实验命令列表 二、实验记录 1、直连路由与路由表查看 步骤1:建立物理连接并运行超级终端。 步骤2:在路由器上查看路由表。 2、静态路由配置 步骤1:配…...

TCP: Textual-based Class-aware Prompt tuning for Visual-Language Model
文章汇总 存在的问题 原文:具有图像特定知识的图像条件提示符号在提升类嵌入分布方面的能力较差。 个人理解:单纯把"a photo of {class}"这种提示模版作为输入是不利于text encoder学习的 动机 在可学习的提示和每一类的文本知识之间建立…...

2024年软考网络工程师中级题库
1【考生回忆版】以下不属于5G网络优点的是(A) A.传输过程中消耗的资源少,对设备的电池更友好 B.支持大规模物联网,能够连接大量低功耗设备,提供更高效的管理 C.引入了网络切片技术,允许将物理网络划分为多个虚拟网络…...

CSS的盒子模型(Box Model)
所有HTML元素都可以看作盒子,在CSS中盒子模型是用来设计和布局的,CSS盒子模型本质上是一个盒子,分装周围的HTML元素包括:外边距,边框,内边距和实际内容。 Margin(外边距) 清除边框…...

用OpenSSL搭建PKI证书体系
1 创建PKI结构目录 mkdir 07_PKI cd 07_PKI mkdir 01_RootCA 02_SubCA 03_Client2 创建根CA cd 01_RootCA mkdir key csr cert newcerts touch index.txt index.txt.attr echo 01 > serial2.1 创建根CA密钥对 2.1.1 生成 长度为2048 bit 的RSA私钥。 cd key openssl gen…...
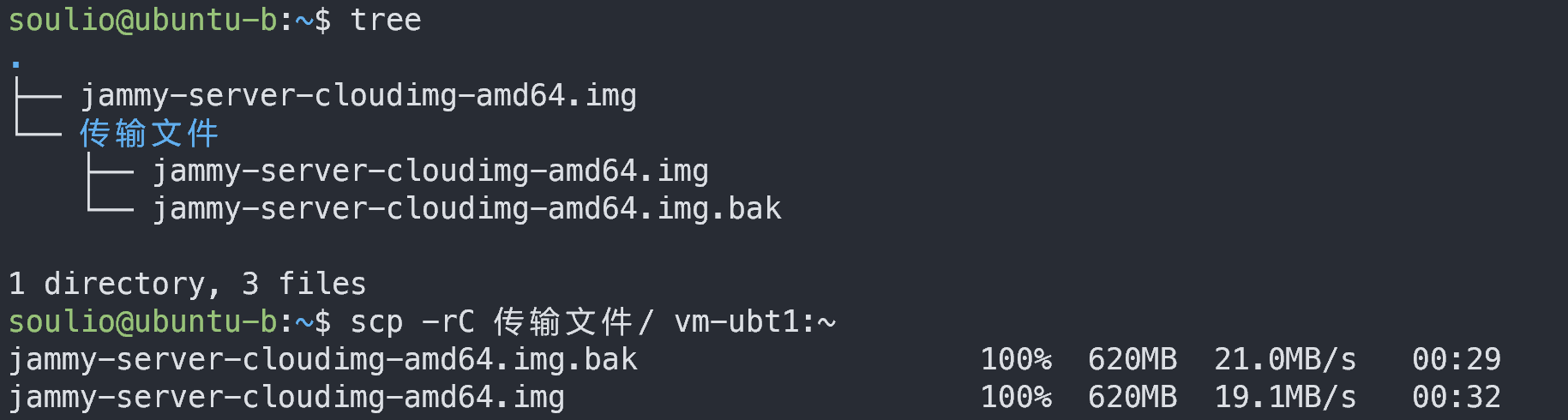
scp 命令:在两台主机间远程传输文件
一、命令简介 scp 命令使用 SSH 加密的方式在本地主机和远程主机之间复制文件。 二、命令参数 格式 scp [选项] 发送方主机和目录 接收方主机和目录注意:左边是发送方,右边是接收方。固定格式。 示例 #示例1 scp ~/test.txt soulio172.1…...

家用迷你洗衣机哪款质量高?五大热销高分单品强势来袭
迷你内衣洗衣机一般是为婴儿宝宝,或者一些有特殊需要的用户而设计使用的,宝宝衣物换洗频繁,而且对卫生方面的除菌要求高,而为避免交叉感染,所以一般不适合和大人的衣物放在一起洗,因此对于有宝宝的家庭来说…...

rpm 命令:RedHat底层包管理器
一、命令简介 rpm 是 Red Hat Package Manager 的缩写,是 Red Hat、CentOS、Fedora 等基于 Red Hat 的 Linux 发行版中用于管理和安装软件包的工具。它能够安装、卸载、升级、查询和验证软件包。 相关命令: rpm 是基础,提供了底层的软…...

Xilinx 使用DDS实现本振混频上下变频
文章目录 一、什么是混频?二、为什么要进行混频?三、Matlab实现混频操作四、FPGA实现混频上下变频操作4.1 例化IP4.2 仿真验证 一、什么是混频? 混频(Mixing)是信号处理中的一个核心概念,混频的本质是将两个…...
ClickHouse-Kafka Engine 正确的使用方式
Kafka 是大数据领域非常流行的一款分布式消息中间件,是实时计算中必不可少的一环,同时一款 OLAP 系统能否对接 Kafka 也算是考量是否具备流批一体的衡量指标之一。ClickHouse 的 Kafka 表引擎能够直接与 Kafka 系统对接,进而订阅 Kafka 中的 …...
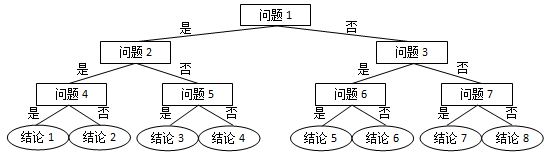
PTA L1-071 前世档案
L1-071 前世档案(20分) 网络世界中时常会遇到这类滑稽的算命小程序,实现原理很简单,随便设计几个问题,根据玩家对每个问题的回答选择一条判断树中的路径(如下图所示),结论就是路径终…...

解决mac下 Android Studio gradle 下载很慢,如何手动配置
抓住人生中的一分一秒,胜过虚度中的一月一年! 小做个动图开篇引题 前言 平时我们clone git 上项目,项目对应gradle版本本地没有,ide编译会自动下载,但是超级慢可能还下载失败,下面讲解下此问题如 如下图所示ÿ…...

第三篇 第17章 工程计量与支付
第三篇 工程计价 第17章 工程计量与支付 17.1 工程计量 17.1.1 工程计量的原则 承包人完成合同工程且应予计量的工程数量确定计量周期可以月为单位,也可以按其他时间节点、工程形象进度分段计量因承包人原因造成的超出合同工程范围施工或返工的工程量、发包人不予计量 17.1…...

[半导体检测-1]:半导体检测概述
前言: 半导体检测是半导体产业链中不可或缺的一环,它贯穿于产品生产制造流程的始终,对于提高产线良率、提升产品竞争实力具有关键作用。以下是对半导体检测的详细概述: 一、什么是半导体检测 半导体检测是指运用专业技术手段&a…...

公共字段自动填充
问题分析 总会有些公共字段,例如创建时间和创建人 实现思路 对mapper定义注解,使用切面思想来判断是不是更新和新增操作对于指定的操作来更新公共字段 自定义操作类型 package com.sky.enumeration;/*** 数据库操作类型*/ public enum OperationType {/*…...

超详细 Git 教程:二十篇博客,三万字干货
Git 是最流行的版本管理工具,可以说是任何程序员都应该掌握的工具。 当然,其他人也可以学习它用来进行版本控制 为此,我将之前学习 Git 时的笔记整理了下(预计有二十篇),作为博客发出来,希望能帮…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由
告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题
3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾删除Mac应用后,发…...

嵌入式测试学习第 12天:串口基础概念:UART、波特率、数据位、校验位
串口基础概念:UART、波特率、数据位、校验位一、串口整体基础概念1、什么是UART串口2、串口实物真实图片① 主板/开发板排针串口② USB转TTL串口模块③ 老式DB9工业串口公头母头二、串口四大核心参数1、波特率概念常用标准固定值通俗理解测试场景2、数据位概念作用3…...

83.人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验
人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验 一、问题场景:Word 文档能答,Excel 表格一问就错 很多企业知识库不只有 Word 和 PDF,还有大量表格: 1. 报销标准表 2. 产品价格表 3. 客户等级表 4. SLA 服务等级表 5. 部门…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

Excalidraw草图AI技能:从图形解析到自动化代码生成实战
1. 项目概述:一个能“读懂”你草图的AI技能如果你经常用Excalidraw画流程图、架构图或者UI草图,那你一定遇到过这样的场景:画完一张图,想把它整理成文档,或者想基于这张图生成一些代码,又或者想让它自己动起…...