基于注意力机制的图表示学习:GRAPH-BERT模型
人工智能咨询培训老师叶梓 转载标明出处
图神经网络(GNNs)在处理图结构数据方面取得了显著的进展,但现有模型在深层结构中存在性能问题,如“悬挂动画问题”和“过平滑问题”。而且图数据内在的相互连接特性限制了大规模图输入的并行化处理,这在内存限制下尤为突出。
针对这些问题,美国佛罗里达州立大学IFM实验室和伊利诺伊大学芝加哥分校以及北京邮电大学的研究者共同提出了一种新的图神经网络模型——GRAPH-BERT(基于图的BERT),该模型完全基于注意力机制,不依赖于任何图卷积或聚合操作。
GRAPH-BERT的创新之处在于,它不是通过图的链接来学习节点表示,而是通过在输入大型图数据中采样无链接的子图(称为linkless subgraphs)来进行训练。这种基于局部上下文的采样方法,使得GRAPH-BERT能够有效地解决现有GNNs模型中的性能问题,并提高了学习效率。
方法
GRAPH-BERT模型由几个关键部分组成(Figure 1)包括无链接子图批处理、节点输入向量嵌入、基于图的 Transformer 编码器、表示融合和功能组件这五个部分。

无链接子图批处理
首先提出了问题的设置。输入图数据可以表示为 G = (V, E, w, x, y),其中 V 和 E 分别表示图中的节点和链接集合。映射 w 将链接投影到其权重,而映射 x 和 y 可以将节点投影到其原始特征和标签。模型在预训练阶段不需要任何标签监督信息,但部分标签将用于后续的节点分类微调任务。
GRAPH-BERT不是在完整图 G 上工作,而是在从输入图中采样的无链接子图批次上进行训练。这样可以有效地并行化学习,即使是现有的图神经网络无法处理的极大规模图也适用。
节点输入向量嵌入
与图像和文本数据不同,图中的像素和单词/字符具有固有的顺序,而图中的节点是无序的。GRAPH-BERT模型实际上并不需要输入采样子图中的任何节点顺序。为了简化表示,建议将输入子图中的节点序列化为有序列表。
节点的输入向量嵌入包括四个部分:
- 原始特征向量嵌入(Raw Feature Vector Embedding):每个节点的原始特征向量被嵌入到共享特征空间中。
- Weisfeiler-Lehman 绝对角色嵌入(Weisfeiler-Lehman Absolute Role Embedding):Weisfeiler-Lehman算法可以根据图中的结构角色对节点进行标记。
- 基于亲密度的相对位置嵌入(Intimacy based Relative Positional Embedding):基于节点列表的顺序,可以提取子图中的局部信息。
- 基于跳数的相对距离嵌入(Hop based Relative Distance Embedding):可以视为绝对角色嵌入(全局信息)和基于亲密度的相对位置嵌入(局部信息)之间的平衡。
基于图变换器的编码器
基于上述计算的嵌入向量,可以将它们聚合在一起,定义子图中节点的初始输入向量。然后,基于图变换器的编码器将通过多个层(D层)迭代更新节点的表示。
GRAPH-BERT 学习
预训练包括两个任务:节点原始属性重建和图结构恢复。
- 节点原始属性重建:目标是捕获学习表示中的节点属性信息。
- 图结构恢复:重点更多地放在图连接信息上。
预训练后的GRAPH-BERT可以用于新任务,或者进行必要的调整,即微调。
- 节点分类:基于节点学习到的表示,可以推断出节点的标签。
- 图聚类:主要目标是对图中的节点进行分组。

Figure 2展示了GRAPH-BERT在节点重建和图恢复任务上的预训练过程。图中的x轴表示迭代次数,y轴表示训练损失。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
评论留言“参加”或扫描微信备注“参加”,即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory。关注享粉丝福利,限时免费录播讲解。
实验
实验在三个真实世界的基准图数据集上进行,分别是Cora、Citeseer和Pubmed。这些数据集在最新的图神经网络研究中被广泛使用。
实验使用了Cora、Citeseer和Pubmed数据集,这些数据集在图神经网络的研究中非常常见。实验中首先预计算节点亲密度得分,基于这些得分对子图批次进行采样,子图大小k 的范围是 {1, 2, ..., 10, 15, 20, ..., 50}。此外,还预计算了节点之间的跳数距离和Weisfeiler-Lehman (WL) 节点代码。通过最小化节点原始特征重构损失和图结构恢复损失,可以有效地预训练GRAPH-BERT。

Figure 3展示了GRAPH-BERT在Cora数据集上节点分类任务的学习性能。图中展示了不同层数的GRAPH-BERT模型的训练和测试准确率,可以看出模型在训练集上的收敛速度非常快,并且随着模型深度的增加,GRAPH-BERT并没有出现悬挂动画问题。

Table 1 展示了GRAPH-BERT在节点分类任务上与现有基线方法相比的学习性能。结果表明,GRAPH-BERT在大多数情况下都能取得更好的性能。
在没有预训练的情况下,GRAPH-BERT能够独立应用于各种图学习任务。在Cora数据集上,展示了不同深度的GRAPH-BERT模型的学习收敛情况。实验结果表明,即使是非常深的GRAPH-BERT(50层)也能有效地响应训练数据并取得良好的学习性能。

Table 2 分析了在Cora数据集上不同子图大小 k 对模型性能(测试准确率和测试损失)和总时间成本的影响。结果表明,参数 k 对GRAPH-BERT的学习性能有很大影响。

Table 3展示了使用不同图残差项的GRAPH-BERT的学习性能。结果表明,使用graph-raw残差项的GRAPH-BERT表现更好。

Table 4展示了GRAPH-BERT在三个数据集上不同初始嵌入输入的学习性能。结果表明,原始特征嵌入对模型性能的贡献最大。Table 5展示了GRAPH-BERT在没有预训练的情况下,仅基于节点原始特征进行图聚类的学习结果。结果通过多种不同的指标进行评估。
在没有预训练的情况下,GRAPH-BERT在三个数据集上的图聚类学习结果被展示出来。聚类组件使用的是KMeans算法,它将节点的原始特征向量作为输入。
对于有预训练和没有预训练的GRAPH-BERT在微调任务上的实验结果。为了突出差异,这里只使用了正常训练周期的1/5来微调GRAPH-BERT。结果表明,对于大多数数据集,预训练为GRAPH-BERT提供了良好的初始状态,这有助于模型在只有很少的微调周期的情况下取得更好的性能。Figure 2 展示了GRAPH-BERT在节点属性重建和图结构恢复任务上的预训练学习性能,反映了模型在预训练任务上的快速收敛情况。
GRAPH-BERT的源代码和相关数据集可以通过以下链接访问:
https://github.com/jwzhanggy/Graph-Bert
论文链接:https://arxiv.org/pdf/2001.05140v2
相关文章:
基于注意力机制的图表示学习:GRAPH-BERT模型
人工智能咨询培训老师叶梓 转载标明出处 图神经网络(GNNs)在处理图结构数据方面取得了显著的进展,但现有模型在深层结构中存在性能问题,如“悬挂动画问题”和“过平滑问题”。而且图数据内在的相互连接特性限制了大规模图输入的并…...

linux服务器安装原生的php环境
在CentOS上安装原生的PHP环境相对简单。下面是一个详细的步骤指南,适用于CentOS 7及更高版本。 ### 第一步:更新系统 首先,确保你的系统是最新的: sudo yum update -y ### 第二步:安装EPEL和Remi仓库 1. **安装EP…...

数电学习基础(逻辑门电路+)
1.逻辑门电路 1.1逻辑门电路的简介 1.1.1各种逻辑门电路的简介 基本概念 (1)实现基本逻辑运算和常用逻辑运算的电路称为逻辑门电路,简称门电路。逻辑门电路是组成各种数字电路的基本单元电路。将构成门电路的元器件制作一块半导体芯片上再…...

【艾思科蓝】Spring Boot实战:零基础打造你的Web应用新纪元
第七届人文教育与社会科学国际学术会议(ICHESS 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看:https://ais.cn/u/nuyAF3 目录 一、Spring Boot简介 1.1 Spring Boot的诞生背景 1.2 Spring Boot的核心特性 二、搭建开发环境 2.1…...

C++ 二叉树
1. 二叉搜索树 1.1 二叉搜索树概念 二叉搜索树又称二叉排序树,他或者是一棵空树,或者是具有以下性质的二叉树: ①若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 ②若它的右子树不为空,则右子树上所有节…...

初探IT世界:从基础到未来
初探IT世界:从基础到未来 1. 引言 随着科技的不断发展,IT(信息技术)已经成为全球经济的支柱之一。从软件开发、网络安全到数据分析和人工智能,IT 领域为我们的日常生活提供了许多不可或缺的技术服务。无论你是初学者…...

一区黏菌算法+双向深度学习+注意力机制!SMA-BiTCN-BiGRU-Attention黏菌算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测
一区黏菌算法双向深度学习注意力机制!SMA-BiTCN-BiGRU-Attention黏菌算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测 目录 一区黏菌算法双向深度学习注意力机制!SMA-BiTCN-BiGRU-Attention黏菌算法优化双向时间卷积双向门控循环单元…...

机器翻译之Bahdanau注意力机制在Seq2Seq中的应用
目录 1.创建 添加了Bahdanau的decoder 2. 训练 3.定义评估函数BLEU 4.预测 5.知识点个人理解 1.创建 添加了Bahdanau的decoder import torch from torch import nn import dltools#定义注意力解码器基类 class AttentionDecoder(dltools.Decoder): #继承dltools.Decoder写…...

MyBatis 入门教程-搭建入门工程
Maven作为一个优秀的项目构建和管理工具,在日常的开发中被大多数开发者使用,后续的项目也是基于Maven来构建。 创建一个Maven项目 利用IDEA创建项目工具来创建一个Maven项目 添加MyBatis的依赖 这里可以从Maven仓库地址中进行查看, https://mvnrepository.com/ 从这里可…...

CVE-2024-2389 未经身份验证的命令注入
什么是 Progress Flowmon? Progress Flowmon 是一种网络监控和分析工具,可提供对网络流量、性能和安全性的全面洞察。Flowmon 将 Nette PHP 框架用于其 Web 应用程序。 未经身份验证的路由 我们开始在“AllowedModulesDecider.php”文件中枚举未经身份验证的端点,这是一个描…...

C++初阶-list用法总结
目录 1.迭代器的分类 2.算法举例 3.push_back/emplace_back 4.insert/erase函数介绍 5.splice函数介绍 5.1用法一:把一个链表里面的数据给另外一个链表 5.2 用法二:调整链表当前的节点数据 6.unique去重函数介绍 1.迭代器的分类 我们的这个迭代器…...

【智能大数据分析 | 实验一】MapReduce实验:单词计数
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈智能大数据分析 ⌋ ⌋ ⌋ 智能大数据分析是指利用先进的技术和算法对大规模数据进行深入分析和挖掘,以提取有价值的信息和洞察。它结合了大数据技术、人工智能(AI)、机器学习(ML&a…...

Git 版本控制--git restore和git reset
git restore 和 git reset 是 Git 版本控制系统中两个用于撤销更改的命令,但它们的作用范围和用途有所不同。 git restore git restore 是 Git 版本控制系统中的一个命令,用于撤销工作目录中的更改,但不影响暂存区(staging area…...
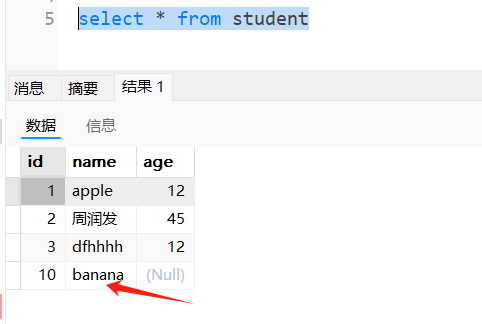
DBAPI如何实现插入数据前先判断数据是否存在,存在就更新,不存在就插入
DBAPI实现数据不存在即插入、存在即更新 场景 往数据库插入数据的时候,需要先判断一下记录是否在数据库已经存在,如果已经存在就更新记录,如果不存在,才插入数据。 实现方案 采用存储过程实现,以mysql为例子 创建存储过…...

【渗透测试】-灵当CRM系统-sql注入漏洞复现
文章目录 概要 灵当CRM系统sql注入漏洞: 具体实例: 技术名词解释 小结 概要 近期灵当CRM系统爆出sql注入漏洞,我们来进行nday复现。 灵当CRM系统sql注入漏洞: Python sqlmap.py -u "http://0.0.0.0:0000/c…...
)
c语言练习题1(数组和循环)
1实现一个对整形数组的冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历数列的工作是重复进行的,直到没有再需要交换的元…...

实验3 Hadoop集群运行环境搭建和使用
实验3 Hadoop集群运行环境搭建和使用 一、实验介绍 本节实验旨在引导学生通过实际操作搭建一个基本的Hadoop集群,并进行基本的使用验证。实验包括在集群节点上添加域名映射以实现节点间的相互识别,配置免密SSH登录以便无密码访问各节点,安装和配置JDK以满足Hadoop的运行需求…...

前端文件上传全过程
特别说明:ui框架使用的是蚂蚁的antd 这里主要是学习前端上传接口的传递参数包括前端上传之前对于代码的整理 一、第一步将前端页面画出来 源代码: /** 费用管理 - IT费用管理 - 费用数据上传 */ import { useState } from "react"; import {…...

MySQL中的函数简单总结,以及TCL语句的简单讲解
文章目录 一、函数1、ifnull2、if3、case4、exists 存在5、字符串函数(重点)6、数学函数7、日期函数 二、TCL语句1、创建用户2、赋予权限3、修改mysql允许远程登录 一、函数 1、ifnull 当前⾯的值是null的时候,使⽤后⾯的默认值 ifnull(字段…...

GPS在Linux下的使用(war driving的前置学习)
1.ls /dev/tty* 列出所有与 tty 相关的设备文件。这些设备文件通常对应终端设备 ttyUSB0是GPS端口 2.cat /dev/ttyUSB0 用于读取并显示连接到 /dev/ttyUSB0 串口设备发送的原始数据 这种是GPS定位不全的,要拿到更开阔的地方 这种是GPS定位全的 因为会持续输出…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...

数据质量保证:确保数据准确性和可靠性
数据质量保证:确保数据准确性和可靠性 一、数据质量保证概述 1.1 数据质量保证的定义 数据质量保证是指通过一系列技术和流程,确保数据的准确性、完整性、一致性和及时性的过程。它涉及数据采集、存储、处理和使用的各个环节,确保数据符合业务…...

DDalkkak:逆向解析KakaoTalk数据库,实现聊天记录本地化备份与迁移
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫aristoapp/DDalkkak。乍一看这个仓库名,可能有点摸不着头脑,但如果你对韩国本土的即时通讯应用KakaoTalk有所了解,或者对数据迁移、备份工具有需求,那这个项…...

本地大模型Web API桥梁:llm-web-api部署与OpenAI兼容实践
1. 项目概述:一个为本地大语言模型提供Web API的轻量级桥梁如果你和我一样,热衷于在本地部署各种开源大语言模型(LLM),比如Llama、Qwen、Mistral,那么你一定遇到过这样的痛点:模型本身跑起来了&…...

FMCW雷达干扰抑制:分数傅里叶变换的工程实践
1. FMCW雷达干扰问题与分数傅里叶变换的机遇在79GHz频段工作的车载FMCW雷达,其线性调频连续波(LFM)信号极易受到同频段其他雷达设备的干扰。这种干扰会导致雷达检测性能显著下降——实测数据显示,强干扰环境下目标检测的虚警率可能…...

005 DevEco Studio OHPM同步404报错 解决文档
[cs]005 DevEco Studio OHPM同步404报错 解决文档 文档简介 本文解决鸿蒙开发中新建空白项目自动触发ohpm install时报错:ohos/hypium、ohos/hamock包404找不到、拉取依赖失败问题。 核心原则:不修改项目任何自带文件、不删除系统生成依赖、不改动业务代…...

深入解析Ayiks project-genesis-framework:模块化架构元框架的设计与实践
1. 项目概述与核心价值最近在梳理一些老项目的技术债,发现很多早期为了快速上线而写的代码,现在维护起来简直是一场灾难。业务逻辑和底层框架耦合得死死的,想换个数据库或者加个缓存层,都得把整个项目翻个底朝天。这种时候&#x…...

RK3288嵌入式开发实战:硬件架构、软件定制与典型应用场景解析
1. 项目概述:为什么RK3288至今仍是嵌入式开发的“硬通货”? 在嵌入式开发这个行当里,选型是个技术活,更是个经验活。你既要考虑当下的性能需求,又要掂量未来的扩展可能,还得平衡成本、功耗和开发周期。从业…...

记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录
记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录 1. 升级目的 最近需要本地部署大模型推理服务,目标是运行 Qwen3.6-35B 的 INT4 量化版本(AWQ 格式),并使用高性能推理引擎 vLLM 提供服务。由于模型采用 …...

降AI率软件越便宜越好吗?实测5个主流降AI工具,首选嘎嘎降!
一、前言:2026 年毕业必须通过 aigc 检测 2026 年各高校对学术论文的 AIGC 疑似度的审查全面变严, 均发布了具体 AIGC 检测报告和数值要求,211 和 985 高校规定本科论文 AI 率要低于 20%, 硕士要求 AI 率不高于 15%。普通高校一般要求 AI 率控制在 30% 以内。AIGC 检测率超标的…...