pytorch 加载模型参数后 如何测试数据,应用模型预测数据,然后连续变量转换成 list 或者numpy.array padans并保存到csv文件中
在PyTorch中,加载模型参数后测试数据通常涉及以下几个步骤:
1. **加载模型**:首先,你需要定义模型的结构,然后加载预训练的参数。
2. **加载数据**:准备你的测试数据集。确保数据集已经正确地预处理,以匹配训练时的格式。
3. **设置模型为评估模式**:在进行推理之前,将模型设置为评估模式,这会关闭Dropout和Batch Normalization层的训练行为。
4. **进行推理**:遍历测试数据集,使用模型进行预测。
5. **评估模型**:根据模型的输出和测试数据集的真实标签计算性能指标,如准确率、损失等。
下面是一个简化的代码示例,展示了这个过程:
```python
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 假设我们有一个预定义的模型结构
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定义模型层
# ...
def forward(self, x):
# 定义前向传播
# ...
return x
# 实例化模型
model = MyModel()
# 加载预训练的模型参数
model.load_state_dict(torch.load('model_parameters.pth'))
# 设置为评估模式
model.eval()
# 准备测试数据集
transform = transforms.Compose([
transforms.ToTensor(),
# 其他必要的转换
])
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 测试模型
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度,节省计算资源
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算准确率
accuracy = 100 * correct / total
print(f'Accuracy of the model on the test images: {accuracy}%')
```
在这个例子中,我们首先定义了一个模型类`MyModel`,然后加载了模型参数。接着,我们设置了模型为评估模式,并准备了一个测试数据集。最后,我们遍历测试数据集,计算模型的准确率。
如何预测呢
在PyTorch中进行预测通常涉及以下步骤:
1. **加载模型**:确保你的模型已经加载了预训练的参数。
2. **设置模型为评估模式**:使用`model.eval()`将模型设置为评估模式,这样可以关闭Dropout和Batch Normalization等仅在训练时使用的层。
3. **准备输入数据**:确保你的输入数据是正确的格式,并且已经进行了适当的预处理,比如缩放、归一化等。
4. **进行预测**:将输入数据传递给模型,获取输出。
5. **处理输出**:根据模型的输出进行后处理,比如转换为概率、选择最可能的类别等。
下面是一个具体的代码示例,展示如何使用PyTorch进行预测:
```python
import torch
from torchvision import transforms
from PIL import Image
# 假设模型已经加载并设置为评估模式
model.eval()
# 定义图像的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小
transforms.ToTensor(), # 将图像转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载图像
image = Image.open("path_to_your_image.jpg")
image = transform(image).unsqueeze(0) # 增加一个批次维度
# 进行预测
with torch.no_grad(): # 不计算梯度
outputs = model(image)
# 将输出转换为概率
probabilities = torch.nn.functional.softmax(outputs, dim=1)
# 获取最大概率的索引,即预测的类别
_, predicted = torch.max(probabilities, 1)
# 打印预测结果
print(f"Predicted class: {predicted.item()}")
```
### 详细步骤解释:
1. **加载模型**:
```python
model.eval()
```
使用`model.eval()`将模型设置为评估模式。
2. **定义图像预处理**:
```python
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小
transforms.ToTensor(), # 将图像转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
```
使用`transforms.Compose`定义一系列预处理步骤,包括调整图像大小、转换为Tensor和归一化。
3. **加载图像**:
```python
image = Image.open("path_to_your_image.jpg")
image = transform(image).unsqueeze(0) # 增加一个批次维度
```
使用`PIL`库加载图像,并应用预处理。`unsqueeze(0)`用于增加一个批次维度,因为模型期望批次维度。
4. **进行预测**:
```python
with torch.no_grad(): # 不计算梯度
outputs = model(image)
```
使用`torch.no_grad()`禁用梯度计算,这样可以节省内存并加速预测。将处理后的图像传递给模型,获取输出。
5. **处理输出**:
```python
probabilities = torch.nn.functional.softmax(outputs, dim=1)
_, predicted = torch.max(probabilities, 1)
```
使用`softmax`函数将模型输出转换为概率分布,然后使用`torch.max`获取最大概率的索引,即预测的类别。
6. **打印预测结果**:
```python
print(f"Predicted class: {predicted.item()}")
```
打印预测的类别。
这个示例展示了如何使用PyTorch进行图像分类的预测。如果你有其他类型的数据或任务(如回归、生成任务等),预测步骤可能会有所不同,但基本流程是类似的。如果你有具体的模型或任务,我可以提供更详细的帮助。
with torch.no_grad():
test_result = model(X_test)、
在PyTorch中,使用`with torch.no_grad():`块来执行模型的推理是一种常见的做法,特别是在进行预测或评估模型时。这个上下文管理器的作用是告诉PyTorch在这个代码块内不需要计算梯度,这样可以节省内存和计算资源。
当你写:
```python
with torch.no_grad():
test_result = model(X_test)
```
这意味着你正在将输入数据`X_test`传递给模型,并获取模型的输出,存储在变量`test_result`中。由于你已经处于`torch.no_grad()`上下文中,PyTorch不会跟踪在这个块内进行的任何操作的梯度,这对于推理阶段是必要的,因为在推理阶段你不需要进行反向传播。
这里的`X_test`应该是你的测试数据,它需要是适当的PyTorch张量格式,并且已经经过了与训练时相同的预处理步骤。
以下是使用这段代码进行预测的完整示例:
```python
import torch
from torch.utils.data import DataLoader
# 假设 model 已经被定义并加载了预训练的参数
model.eval()
# 假设 X_test 是你的测试数据集,这里是一个简化的例子
# 你需要根据你的数据集实际情况来加载和预处理数据
# X_test = ...
# 测试数据加载器
test_loader = DataLoader(X_test, batch_size=64, shuffle=False)
# 存储预测结果
predictions = []
# 不计算梯度,进行预测
with torch.no_grad():
for data in test_loader:
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
predictions.extend(predicted.cpu().numpy())
# 现在 predictions 包含了所有测试数据的预测结果
```
在这个例子中,我们遍历了测试数据加载器`test_loader`中的所有数据,对每个批次的数据进行预测,并将预测结果存储在`predictions`列表中。注意,我们使用`.cpu().numpy()`将预测结果从PyTorch张量转换为NumPy数组,以便进一步处理或评估。
请确保你的`X_test`数据是正确预处理的,并且模型`model`已经设置为评估模式(`model.eval()`)。如果你需要进一步的帮助来准备数据或评估模型,请提供更多的信息。
转换成文本 保存到csv中
要将模型的预测结果`test_result`转换成文本并保存到CSV文件中,你可以使用Python的`csv`模块或`pandas`库。以下是使用`pandas`库将结果保存到CSV文件的步骤:
首先,确保你已经安装了`pandas`库。如果没有安装,可以使用`pip`安装它:
```bash
pip install pandas
```
然后,你可以使用以下代码将预测结果保存到CSV文件中:
```python
import torch
import pandas as pd
# 假设 model 已经被定义并加载了预训练的参数
model.eval()
# 假设 X_test 是你的测试数据集
# 你需要根据你的数据集实际情况来加载和预处理数据
# X_test = ...
# 进行预测
with torch.no_grad():
test_result = model(X_test)
# 将预测结果转换成CPU上的numpy数组(如果它们不在CPU上)
# 并且转换成一维数组(如果它们是多维的)
# 这里假设test_result是多维的,我们取每个样本的预测类别
_, predicted = torch.max(test_result, 1)
predicted = predicted.cpu().numpy()
# 将预测结果转换成DataFrame
df = pd.DataFrame(predicted, columns=['Predicted_Class'])
# 保存到CSV文件
df.to_csv('predictions.csv', index=False)
```
在这段代码中,我们首先使用`torch.max`获取每个测试样本的预测类别,然后使用`.cpu().numpy()`将它们转换为NumPy数组。接着,我们创建了一个`pandas` DataFrame,并将这个DataFrame保存到名为`predictions.csv`的CSV文件中。`index=False`参数的作用是在保存时不包括行索引。
如果你的预测结果是概率或其他连续值,你可能需要根据你的需求调整代码来保存这些值。
如果你不想使用`pandas`,也可以使用Python的内置`csv`模块,如下所示:
```python
import torch
import csv
# 进行预测
with torch.no_grad():
test_result = model(X_test)
# 将预测结果转换成CPU上的numpy数组
test_result = test_result.cpu().numpy()
# 打开一个文件用于写入
with open('predictions.csv', 'w', newline='') as file:
writer = csv.writer(file)
# 写入标题(如果有的话)
writer.writerow(['Predicted_Class'])
# 写入预测结果
for row in test_result:
writer.writerow(row)
```
在这个例子中,我们使用`csv.writer`对象来写入CSV文件。我们首先写入标题行(如果你有多个预测值,可以在这里添加更多的标题),然后遍历`test_result`数组,将每一行写入文件。记得在打开文件时使用`newline=''`参数,以防止在写入时出现额外的空行。
y_test.view(batch_size, datalen//batch_size, 1) 如何变成一个维度的张量呢
在PyTorch中,如果你想要将一个多维张量(例如,一个形状为`(batch_size, datalen//batch_size, 1)`的张量)变成一个一维张量,你可以使用`view`方法或者`reshape`方法来改变张量的形状,但要保持总元素数量不变。对于你提到的张量,我们可以通过移除中间的维度来实现这一点。
这里有两种方法可以实现:
### 方法1: 使用`view`方法
`view`方法可以重新排列张量的形状,但要求新形状的元素总数与原形状相同。对于你的例子,如果你想将`(batch_size, datalen//batch_size, 1)`形状的张量变为一维,可以这样做:
```python
# 假设 y_test 是一个形状为 (batch_size, datalen//batch_size, 1) 的张量
y_test_flattened = y_test.view(-1) # '-1' 让 PyTorch 自动计算这个维度的大小
```
这里,`-1`告诉PyTorch自动计算这个维度的大小,以便保持总元素数量不变。这将使`y_test`变为一个一维张量。
### 方法2: 使用`reshape`方法
`reshape`方法与`view`类似,但`reshape`在某些情况下更灵活,因为它可以处理非连续张量。如果原始张量不是连续的,`reshape`会尝试返回一个视图,如果不可能,它会复制数据到一个新的连续张量。
```python
# 同样假设 y_test 是一个形状为 (batch_size, datalen//batch_size, 1) 的张量
y_test_flattened = y_test.reshape(-1)
```
### 检查结果
无论使用哪种方法,你都可以通过打印`y_test_flattened.shape`来验证结果,确保它现在是一维的。
### 注意
- 确保在调用`view`或`reshape`之前,张量是连续的。如果不是,你可能需要先调用`y_test.contiguous()`。
- 这两种方法都不会改变原始数据,它们只是改变了数据的视图。
这样,你就可以将任何形状的张量转换为一维张量,这对于某些操作(如保存到文件、进行某些类型的计算等)非常有用。
然后转换成 list 或者numpy.array 并保存到csv文件中
要将PyTorch张量转换成列表或NumPy数组,并保存到CSV文件中,你可以按照以下步骤操作:
### 1. 将张量转换为NumPy数组
首先,确保你的张量在CPU上(如果它在GPU上),然后使用`.numpy()`方法将其转换为NumPy数组。
```python
import torch
# 假设 y_test_flattened 是一个形状为 (batch_size * (datalen//batch_size),) 的一维张量
y_test_flattened = y_test.view(-1)
# 确保张量在CPU上
y_test_flattened = y_test_flattened.cpu()
# 转换为NumPy数组
y_test_numpy = y_test_flattened.numpy()
```
### 2. 将NumPy数组保存到CSV文件
使用NumPy的`savetxt`函数,你可以将数组保存到CSV文件中。
```python
import numpy as np
# 保存到CSV文件
np.savetxt('output.csv', y_test_numpy, delimiter=',', fmt='%d')
```
在这里,`fmt='%d'`指定了数组中的整数应该以整数格式保存。如果你的数据是浮点数,你可以使用`fmt='%.18e'`(或其他精度)来保存。
### 3. 使用Pandas保存到CSV
如果你更喜欢使用Pandas,这也是一个不错的选择,特别是当你需要更多的格式化选项时。
```python
import pandas as pd
# 将NumPy数组转换为DataFrame
df = pd.DataFrame(y_test_numpy, columns=['Label'])
# 保存到CSV文件
df.to_csv('output.csv', index=False)
```
这里,我们创建了一个单列的DataFrame,并将其保存到CSV文件中。`index=False`参数确保不将行索引写入文件。
### 完整示例
将以上步骤合并,得到一个完整的示例:
```python
import torch
import numpy as np
import pandas as pd
# 假设 y_test 是一个形状为 (batch_size, datalen//batch_size, 1) 的张量
y_test_flattened = y_test.view(-1).cpu()
# 转换为NumPy数组
y_test_numpy = y_test_flattened.numpy()
# 使用Pandas保存到CSV
df = pd.DataFrame(y_test_numpy, columns=['Label'])
df.to_csv('output.csv', index=False)
```
这个示例展示了如何将PyTorch张量转换为NumPy数组,然后使用Pandas将其保存到CSV文件中。这种方法适用于处理任何类型的数值数据,并可以轻松地调整以满足你的特定需求。
相关文章:

pytorch 加载模型参数后 如何测试数据,应用模型预测数据,然后连续变量转换成 list 或者numpy.array padans并保存到csv文件中
在PyTorch中,加载模型参数后测试数据通常涉及以下几个步骤: 1. **加载模型**:首先,你需要定义模型的结构,然后加载预训练的参数。 2. **加载数据**:准备你的测试数据集。确保数据集已经正确地预处理&…...
)
uni-app开发流程(开发、预览、构建和发布过程)
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,支持编写一次代码,生成可以在多个平台(如微信小程序、H5、App等)运行的应用。下面是 uni-app 的开发流程,包括从创建项目到部署的各个阶段。 1. 创建项目 通过 HB…...

Linux Shell: 使用 Expect 自动化 SCP 和 SSH 连接的 Shell 脚本详解
文章目录 0. 引言2. 解决方案3. 脚本详解脚本1:使用 SSH 和 Expect 自动化登录远端机器脚本说明 脚本2:使用 SCP 和 Expect 自动化文件上传脚本说明 脚本3:使用 SCP 和 Expect 自动化文件下载脚本说明 4. 脚本的使用方法5. 关键技术点5.1. Ex…...
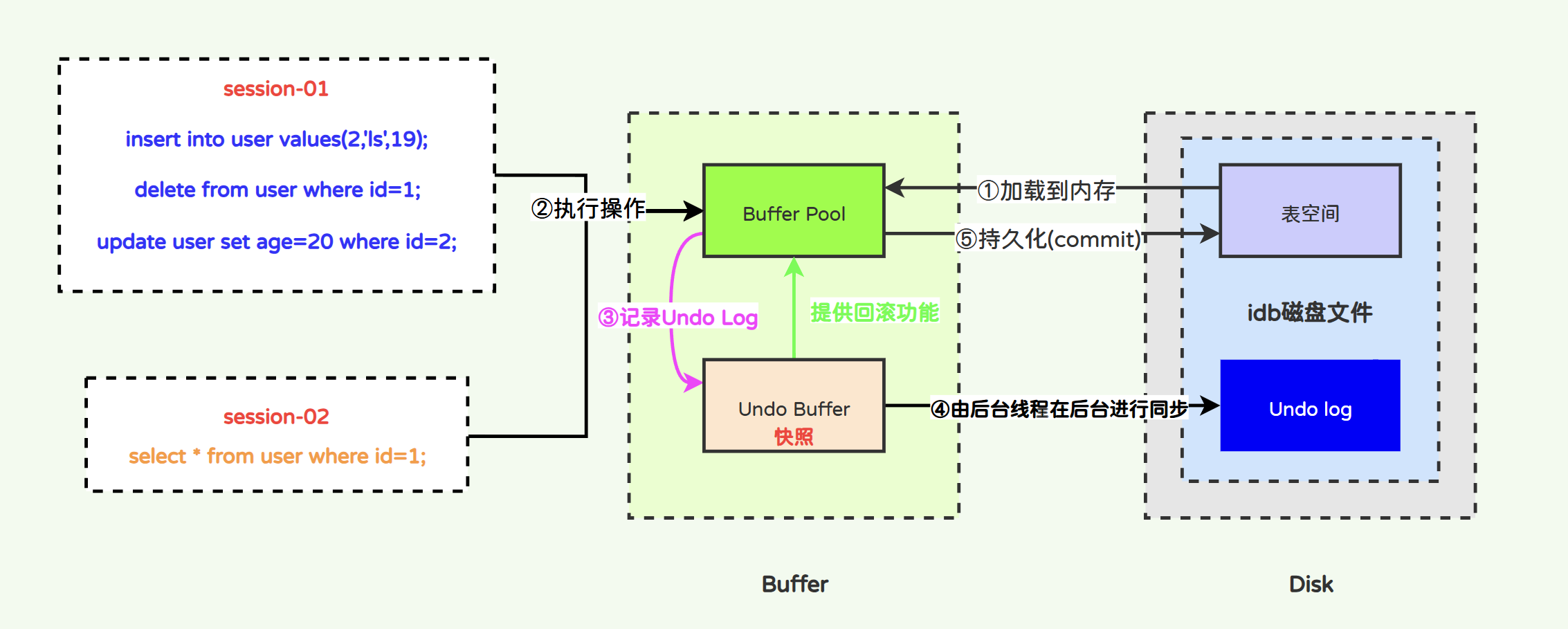
深入分析MySQL事务日志-Undo Log日志
文章目录 InnoDB事务日志-Undo Log日志2.1 Undo Log2.1.1 Undo Log与原子性2.1.2 Undo的存储格式1)insert类型Undo Log2)delete类型Undo Log3)update类型Undo Log 2.1.3 Undo Log的工作原理2.1.4 Undo Log的系统参数2.1.5 Undo Log与Purge线程…...
828华为云征文 | 在Huawei Cloud EulerOS系统中安装Docker的详细步骤与常见问题解决
前言 Docker是一种轻量级的容器技术,广泛用于应用程序的开发、部署和运维。在华为云的欧拉(Huawei Cloud EulerOS)系统上安装和运行Docker,虽然与CentOS有相似之处,但在具体实现过程中,可能会遇到一些系统…...
什么是数据增强中的插值法?
一、插值法的概念 在数据增强中,插值法是一种重要的技术,它通过数学模型在已知数据点之间估计未知数据点的值。这种方法可以帮助我们在不增加实际数据的情况下,通过生成新的数据点来扩展数据集。插值法基于这样的假设:如果已知的数…...

springboot实战学习(9)(配置mybatis“驼峰命名“和“下划线命名“自动转换)(postman接口测试统一添加请求头)(获取用户详细信息接口)
接着学习。之前的博客的进度:完成用户模块的注册接口的开发以及注册时的参数合法性校验、也基本完成用户模块的登录接口的主逻辑的基础上、JWT令牌"的组成与使用以及完成了"登录认证"(生成与验证JWT令牌)具体往回看了解的链接…...

之前做了抵押贷款,现在房市不景气,马上贷款要到期了该怎么办?
面对房贷的重压,特别是对于那些正承受高息贷款之苦的现有房产业主而言,探索有效的减负策略显得尤为重要。今天,我们共同探讨几种智慧策略,旨在帮助您巧妙减轻房贷的经济负担。 一、优化贷款结构:低息置换的魔力 当前&a…...

poi生成的ppt,powerPoint打开提示内容错误解决方案
poi生成的ppt,powerPoint打开提示内容错误解决方案 最近做了ppt的生成,使用poi制作ppt,出现一个问题。微软的powerPoint打不开,提示错误信息 通过xml对比工具发现只需要删除幻灯片的某些标签即可解决。 用的是XML Notepand 分…...

基于stm32物联网身体健康检测系统
在当今社会,由于经济的发展带来了人们生活水平不断提高,但是人们的健康问题却越来越突出了,各种各样的亚健康随处可在,失眠、抑郁、焦虑症,高血压、高血糖等等侵袭着人们的健康,人们对健康的关注达到了一个…...

BeautifulSoup4在爬虫中的使用
一、Beautiful Soup4简介 Beautiful Soup 提供一些简单的python函数来处理导航、搜索等功能。 它是一个工具箱,是python的一个库,最主要的功能是从网页获取数据。 二、Beautiful Soup4安装 在cmd下安装 pip install beautifulsoup4三、BeautifulSou…...

Laya2.x出包alipay小游戏
小游戏开发者工具,支付宝官方已经出了,不说了。 1.LAYA2.X打出得小游戏包中my-adapter.js这个文件需要替换,或者自行修改,替换3.x得; 2.unity导包出得模型文件命名需要注意,避免太长,路径也不…...

Vue极简入门
1.注册路由,如果是子路由,就加一个children import Vue from vue import Router from vue-router import Main from ../views/Main.vue import Login from ../views/Login.vueimport UserProfile from "../views/user/Profile.vue" import Us…...

系统敏感信息搜索工具(支持Windows、Linux)
目录 工具介绍 使用说明 search模块 browser模块 下载地址 工具介绍 可以快速搜索服务器中的有关username,passsword,账号,口令的敏感信息还有浏览器的账户密码。 使用说明 search模块 searchall64.exe search -p 指定路径 searchall64.exe search -p 指定路径 -s &q…...
Fyne ( go跨平台GUI )中文文档-容器和布局 (四)
本文档注意参考官网(developer.fyne.io/) 编写, 只保留基本用法 go代码展示为Go 1.16 及更高版本, ide为goland2021.2 这是一个系列文章: Fyne ( go跨平台GUI )中文文档-入门(一)-CSDN博客 Fyne ( go跨平台GUI )中文文档-Fyne总览(二)-CSDN博客 Fyne ( go跨平台GUI…...
文心智能体 恐怖类游戏
智能体名称:孤岛惊魂 链接:文心智能体平台AgentBuilder | 想象即现实 (baidu.com)https://agents.baidu.com/center/agent/preview/MFhBvA0K9EXXVdjHCcUumadWmWesKvw2 角色与目标设定 🧑🏻 角色:孤岛惊魂是一位虚拟…...

智慧城市运营模式--政府和社会资本合作
1、主要特征 政府和社会资本合作模式是政府与社会资本长期合作提供公共产品和服务的一种创新模式,主要集中在纯公共领域和准公共领域,通过建立“利益共享、风险共担”的长期合作伙伴关系,在增加公共产品和服务供给数量和提升质量的同时,达到减少财政资金支出、降低企业投资…...

【Python报错已解决】ValueError: cannot convert float NaN to integer
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 专栏介绍 在软件开发和日常使用中,BUG是不可避免的。本专栏致力于为广大开发者和技术爱好者提供一个关于BUG解决的经…...

ClickHouse 与 Quickwit 集成实现高效查询
1. 概述 在当今大数据分析领域,ClickHouse 作为一款高性能的列式数据库,以其出色的查询速度和对大规模数据的处理能力,广泛应用于在线分析处理 (OLAP) 场景。ClickHouse 的列式存储和并行计算能力使得它在处理结构化数据查询时极具优势&…...

Facebook Marketplace无法使用的原因及解决方案
Facebook Marketplace是一项广受欢迎的买卖平台,然而,有时候用户可能会遇到无法访问或使用该功能的问题。通常,这些问题可以归结为以下几类原因: 地理位置限制: Facebook Marketplace并非在全球每个地区都可用。在某些…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...

RT-Thread SMP启动流程深度解析:从多核同步到调度就绪
1. 项目概述:从单核到多核,RT-Thread的启动逻辑变迁如果你是从RT-Thread 3.x版本一路用过来的老用户,或者刚开始接触RT-Thread 4.x,可能会发现一个显著的变化:启动流程变“复杂”了。以前,一个main函数或者…...

Arm Neoverse CMN-650架构解析与性能优化
1. Arm Neoverse CMN-650架构概览CMN-650是Arm Neoverse平台中的第三代一致性网格网络(Coherent Mesh Network)互连技术,专为高性能计算和数据中心场景设计。作为SoC内部的核心互连架构,它承担着连接处理器集群、内存控制器、I/O子系统以及加速器单元的关…...

零代码构建HomeKit运动检测系统:Adafruit IO与itsaSNAP实战指南
1. 项目概述:零代码构建HomeKit运动检测系统想给家里的走廊、储物间或者车库入口加个自动感应灯,但又不想折腾复杂的编程和服务器搭建?或者,你手头有一些非HomeKit原生设备,希望通过苹果的“家庭”App进行统一管理&…...

League Akari:英雄联盟玩家的智能游戏助手
League Akari:英雄联盟玩家的智能游戏助手 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否厌倦了在英雄联盟中重复繁琐的准备…...

从YOLOv1到v5:一个算法工程师的实战避坑与版本选择指南
从YOLOv1到v5:算法工程师的版本选择与实战避坑指南 在计算机视觉领域,目标检测一直是工业界和学术界关注的焦点。作为实时检测领域的标杆算法,YOLO系列从2015年诞生至今已经迭代了五个主要版本。不同于学术论文中的理论比较,本文…...

前端入门必学:CSS盒子模型与图片样式全解析前言
在学习前端开发的过程中,掌握 CSS 的基础知识是至关重要的一步。本文将详细介绍 CSS 盒子模型、标签宽高、边框、边距 以及 图片与背景图片 的使用方法,适合刚入门的同学系统学习和复习。一、CSS 盒子模型——页面布局的基石1. 什么是盒子模型࿱…...

如何实现抖音弹幕实时抓取:基于系统代理的技术突破指南
如何实现抖音弹幕实时抓取:基于系统代理的技术突破指南 【免费下载链接】DouyinBarrageGrab 基于系统代理的抖音弹幕wss抓取程序,能够获取所有数据来源,包括chrome,抖音直播伴侣等,可进行进程过滤 项目地址: https:/…...

Harness Engineering:用“确定性“驾驭AI的“不确定性“
上一篇 SDD 系列收尾时,留了一句话:“如何驾驭 AI 来赋能整个软件开发周期,将是另外一个值得深入探讨的话题。” 到现在有将近一个月没更新!期间除了偷懒,五一跑高速添堵之外,主要的原因是这个问题没怎么想…...

Metasploit 保姆级教程|从框架到实操,一篇就够
1.metasploit介绍 Metasploit framework,简称msf。 Metasploit是一个渗透测试平台,能够查找,利用和验证漏洞。 Metasploit是一个免费的、可下载的框架,通过它可以很容易的对计算机软件漏洞实施攻击。它本身附带数百个已知软件漏…...